概率建模的艺术:贝叶斯分类器从理论到实战(周志华《机器学习》第七章深度剖析)
前言
如果把机器学习分类比作医生看病 :传统分类器(如SVM)是"看症状直接下诊断",靠历史数据拟合出症状到疾病的映射;而贝叶斯分类器是"老中医式诊断"------先有多年行医积累的经验(先验概率),再结合病人的具体症状(似然概率),最后算出"得某病的概率(后验概率)",选概率最高的诊断结果。
贝叶斯分类器根植于贝叶斯定理,是概率机器学习的基石。它不仅能给出分类结果,还能输出结果的置信度,这在医疗、金融等高风险场景至关重要。本文顺着西瓜书第七章完整脉络,从贝叶斯决策论、朴素贝叶斯、半朴素贝叶斯、贝叶斯网络到EM算法,逐模块拆解原理,配公式逐字符释义、原理配图、西瓜数据集实测表格、可运行Python源码,穿插生活化趣味案例。
一、贝叶斯决策论:概率视角下的最优分类
1.1 核心:后验概率最大化
贝叶斯决策论的核心思想是:基于后验概率选择最优类别,使期望风险最小。
首先回顾贝叶斯定理,这是整个贝叶斯体系的灵魂:
P ( c ∣ x ) = P ( c ) P ( x ∣ c ) P ( x ) P(c|x)=\frac{P(c)P(x|c)}{P(x)} P(c∣x)=P(x)P(c)P(x∣c)
各符号释义:
- P ( c ∣ x ) P(c|x) P(c∣x):后验概率 ,给定样本 x x x时,它属于类别 c c c的概率【通俗解释:看到症状 x x x后,判断得疾病 c c c的概率】;
- P ( c ) P(c) P(c):先验概率 ,类别 c c c在整个样本空间中出现的概率【通俗解释:人群中得疾病 c c c的基础概率,和具体症状无关】;
- P ( x ∣ c ) P(x|c) P(x∣c):似然概率 ,类别 c c c中出现样本 x x x的概率【通俗解释:得了疾病 c c c的人,出现症状 x x x的概率】;
- P ( x ) P(x) P(x):证据因子 ,样本 x x x出现的概率,对所有类别都相同,不影响分类结果。
趣味案例:癌症检测的"反直觉"真相
假设某种癌症的发病率 P ( c = 癌症 ) = 0.1 % P(c=癌症)=0.1\% P(c=癌症)=0.1%,检测准确率99%(即真阳性率 P ( 阳性 ∣ 癌症 ) = 99 % P(阳性|癌症)=99\% P(阳性∣癌症)=99%,真阴性率 P ( 阴性 ∣ 健康 ) = 99 % P(阴性|健康)=99\% P(阴性∣健康)=99%)。如果一个人检测结果为阳性,他真的得癌症的概率是多少?
很多人会猜99%,但用贝叶斯公式计算:
P ( 癌症 ∣ 阳性 ) = 0.001 × 0.99 0.001 × 0.99 + 0.999 × 0.01 ≈ 9 % P(癌症|阳性)=\frac{0.001\times0.99}{0.001\times0.99+0.999\times0.01}\approx9\% P(癌症∣阳性)=0.001×0.99+0.999×0.010.001×0.99≈9%
这就是贝叶斯思维的威力:基础概率极低时,即使检测准确率很高,阳性结果的可信度也有限。
1.2 最小错误率贝叶斯决策
对于二分类任务,要使分类错误率最小,只需选择后验概率最大的类别:
h ∗ ( x ) = arg max c ∈ Y P ( c ∣ x ) h^*(x)=\arg\max_{c\in\mathcal{Y}}P(c|x) h∗(x)=argc∈YmaxP(c∣x)
- h ∗ ( x ) h^*(x) h∗(x):最优分类器;
- Y \mathcal{Y} Y:所有类别组成的集合。
【通俗解释:哪个类别概率最高,就把样本分到哪个类别,这样犯错的概率最小】。
1.3 最小风险贝叶斯决策
在高风险场景(如医疗误诊),不同错误的代价天差地别:把癌症误诊为健康的代价远大于把健康误诊为癌症。此时需要引入损失函数 λ i j \lambda_{ij} λij ,表示将真实类别为 c j c_j cj的样本错分为 c i c_i ci的损失。
样本 x x x被分类为 c i c_i ci的期望风险:
R ( c i ∣ x ) = ∑ j = 1 N λ i j P ( c j ∣ x ) R(c_i|x)=\sum_{j=1}^N\lambda_{ij}P(c_j|x) R(ci∣x)=j=1∑NλijP(cj∣x)
- N N N:类别总数。
最小风险贝叶斯决策就是选择期望风险最小的类别:
h ∗ ( x ) = arg min c i ∈ Y R ( c i ∣ x ) h^*(x)=\arg\min_{c_i\in\mathcal{Y}}R(c_i|x) h∗(x)=argci∈YminR(ci∣x)
二、朴素贝叶斯分类器:简单却强大的"独立假设"
直接计算后验概率 P ( c ∣ x ) P(c|x) P(c∣x)的最大难题是: x x x是 d d d维特征向量, P ( x ∣ c ) = P ( x 1 , x 2 , . . . , x d ∣ c ) P(x|c)=P(x_1,x_2,...,x_d|c) P(x∣c)=P(x1,x2,...,xd∣c)是 d d d维联合概率,样本量稍大就无法准确估计。
朴素贝叶斯(Naive Bayes) 提出了一个"天真"但极其有效的假设:属性条件独立性假设------所有属性相互独立,对分类结果的影响互不干扰。
2.1 朴素贝叶斯公式推导
基于属性条件独立性假设,联合概率可以分解为各属性概率的乘积:
P ( x ∣ c ) = P ( x 1 , x 2 , . . . , x d ∣ c ) = ∏ i = 1 d P ( x i ∣ c ) P(x|c)=P(x_1,x_2,...,x_d|c)=\prod_{i=1}^dP(x_i|c) P(x∣c)=P(x1,x2,...,xd∣c)=i=1∏dP(xi∣c)
代入贝叶斯公式,得到朴素贝叶斯分类器的核心公式:
P ( c ∣ x ) = P ( c ) P ( x ) ∏ i = 1 d P ( x i ∣ c ) P(c|x)=\frac{P(c)}{P(x)}\prod_{i=1}^dP(x_i|c) P(c∣x)=P(x)P(c)i=1∏dP(xi∣c)
由于 P ( x ) P(x) P(x)对所有类别相同,分类决策可以简化为:
h n b ( x ) = arg max c ∈ Y P ( c ) ∏ i = 1 d P ( x i ∣ c ) h_{nb}(x)=\arg\max_{c\in\mathcal{Y}}P(c)\prod_{i=1}^dP(x_i|c) hnb(x)=argc∈YmaxP(c)i=1∏dP(xi∣c)
2.2 概率估计方法
- 先验概率 P ( c ) P(c) P(c) :用频率估计, P ( c ) = ∣ D c ∣ ∣ D ∣ P(c)=\frac{|D_c|}{|D|} P(c)=∣D∣∣Dc∣,其中 ∣ D c ∣ |D_c| ∣Dc∣是训练集中类别 c c c的样本数, ∣ D ∣ |D| ∣D∣是总样本数。
- 离散属性似然 P ( x i ∣ c ) P(x_i|c) P(xi∣c) : P ( x i ∣ c ) = ∣ D c , x i ∣ ∣ D c ∣ P(x_i|c)=\frac{|D_{c,x_i}|}{|D_c|} P(xi∣c)=∣Dc∣∣Dc,xi∣,其中 ∣ D c , x i ∣ |D_{c,x_i}| ∣Dc,xi∣是类别 c c c中第 i i i个属性取值为 x i x_i xi的样本数。
- 连续属性似然 P ( x i ∣ c ) P(x_i|c) P(xi∣c) :假设属性服从正态分布,用概率密度函数估计:
P ( x i ∣ c ) = 1 2 π σ c , i exp ( − ( x i − μ c , i ) 2 2 σ c , i 2 ) P(x_i|c)=\frac{1}{\sqrt{2\pi}\sigma_{c,i}}\exp\left(-\frac{(x_i-\mu_{c,i})^2}{2\sigma_{c,i}^2}\right) P(xi∣c)=2π σc,i1exp(−2σc,i2(xi−μc,i)2)- μ c , i \mu_{c,i} μc,i:类别 c c c中第 i i i个属性的均值;
- σ c , i \sigma_{c,i} σc,i:类别 c c c中第 i i i个属性的标准差。
2.3 拉普拉斯修正:解决零概率问题
如果某个属性值在训练集中从未出现过, P ( x i ∣ c ) = 0 P(x_i|c)=0 P(xi∣c)=0,会导致整个后验概率为0,这显然不合理。拉普拉斯修正 通过给分子分母加常数来平滑概率:
P ( c ) = ∣ D c ∣ + 1 ∣ D ∣ + N P(c)=\frac{|D_c|+1}{|D|+N} P(c)=∣D∣+N∣Dc∣+1
P ( x i ∣ c ) = ∣ D c , x i ∣ + 1 ∣ D c ∣ + N i P(x_i|c)=\frac{|D_{c,x_i}|+1}{|D_c|+N_i} P(xi∣c)=∣Dc∣+Ni∣Dc,xi∣+1
- N N N:类别总数;
- N i N_i Ni:第 i i i个属性的可能取值数。
【通俗解释:相当于给每个可能的结果都预先加了1次观测,避免出现"从未见过就认为不可能"的极端情况】。
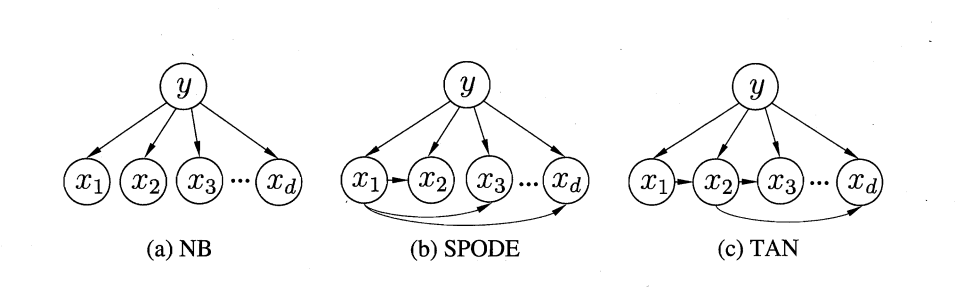
图7.1:朴素贝叶斯的有向图模型,类别节点 c c c是所有属性节点 x 1 , x 2 , . . . , x d x_1,x_2,...,x_d x1,x2,...,xd的父节点,属性之间没有连接,体现了属性条件独立性假设【图出处:西瓜书第七章原图】
图分析:朴素贝叶斯的结构极其简单,所有属性都只依赖于类别节点,这使得它的计算复杂度极低,训练速度远超其他分类器。
趣味案例:垃圾邮件过滤
垃圾邮件过滤是朴素贝叶斯最经典的应用。我们把邮件看作单词的集合,假设每个单词的出现相互独立。先验概率 P ( 垃圾邮件 ) P(垃圾邮件) P(垃圾邮件)是垃圾邮件在所有邮件中的比例,似然概率 P ( 单词 ∣ 垃圾邮件 ) P(单词|垃圾邮件) P(单词∣垃圾邮件)是该单词在垃圾邮件中出现的频率。当收到一封新邮件时,计算它是垃圾邮件的后验概率,超过阈值就判定为垃圾邮件。
三、半朴素贝叶斯分类器:放松"独立假设"
朴素贝叶斯的属性条件独立性假设在现实中往往不成立,比如"西瓜的甜度"和"含糖率"显然高度相关。半朴素贝叶斯分类器 适当放松这个假设,考虑部分属性之间的依赖关系,在计算复杂度和分类性能之间取得更好的平衡。
3.1 独依赖估计(ODE)
最常用的半朴素贝叶斯策略是独依赖估计(One-Dependent Estimator):假设每个属性最多依赖于一个其他属性(称为父属性)。
此时,似然概率可以表示为:
P ( x ∣ c ) = ∏ i = 1 d P ( x i ∣ c , p a i ) P(x|c)=\prod_{i=1}^dP(x_i|c,pa_i) P(x∣c)=i=1∏dP(xi∣c,pai)
- p a i pa_i pai:属性 x i x_i xi的父属性。
3.2 常见的ODE变体
- SPODE(Super-Parent ODE):所有属性都依赖于同一个父属性(称为超父),通常通过交叉验证选择最优的超父。
- TAN(Tree Augmented Naive Bayes):构建一棵最大生成树来表示属性之间的依赖关系,每个属性只依赖于树中它的父节点。
- AODE(Averaged ODE):将每个属性都作为超父构建一个SPODE,然后将所有SPODE的结果平均,避免了选择单一超父的风险。
四、贝叶斯网络:更灵活的概率图模型
当属性之间的依赖关系比较复杂时,半朴素贝叶斯也不够用了。贝叶斯网络(Bayesian Network) 又称信念网,是一种用有向无环图(DAG)来表示变量之间依赖关系的概率模型,能更灵活地刻画复杂的概率依赖。
4.1 贝叶斯网络的组成
贝叶斯网络由两部分组成:
- 结构 :有向无环图 G = ( V , E ) G=(V,E) G=(V,E),每个节点 v ∈ V v\in V v∈V表示一个随机变量,每条边 e ∈ E e\in E e∈E表示两个变量之间的直接依赖关系(箭头从父节点指向子节点)。
- 参数:条件概率表(CPT),每个节点对应一个CPT,描述了该节点在给定其父节点所有可能取值组合下的条件概率分布。
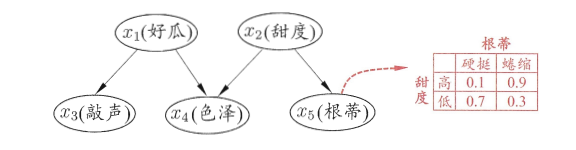
图7.2:一个简单的西瓜问题贝叶斯网络,"好瓜"是根节点,"色泽"、"根蒂"、"敲声"是"好瓜"的子节点,"纹理"同时依赖于"好瓜"和"根蒂"【图出处:西瓜书第七章原图】
图分析:这个网络清晰地表示了变量之间的依赖关系:"纹理"不仅和"好瓜"有关,还和"根蒂"有关,而"色泽"只和"好瓜"有关。
4.2 条件独立性
贝叶斯网络的核心性质是条件独立性:给定一个节点的父节点,该节点与它的所有非后代节点条件独立。
基于条件独立性,贝叶斯网络的联合概率分布可以分解为:
P ( x 1 , x 2 , . . . , x d ) = ∏ i = 1 d P ( x i ∣ p a i ) P(x_1,x_2,...,x_d)=\prod_{i=1}^dP(x_i|pa_i) P(x1,x2,...,xd)=i=1∏dP(xi∣pai)
- p a i pa_i pai:节点 x i x_i xi的父节点集合。
4.3 贝叶斯网络的学习与推断
- 学习:分为结构学习和参数学习。参数学习在结构已知时很简单,用频率估计CPT即可;结构学习是NP难问题,通常用启发式算法搜索最优结构。
- 推断:给定部分变量的取值,计算其他变量的后验概率。精确推断也是NP难问题,实际中常用近似推断算法,如吉布斯采样。
五、EM算法:解决隐变量问题的利器
在前面的讨论中,我们假设所有变量都是可观测的。但现实中经常存在隐变量------无法直接观测到的变量。比如,我们有一批硬币的抛掷结果,但不知道每次抛掷的是哪一枚硬币,此时"硬币的种类"就是隐变量。
EM(Expectation-Maximization)算法 是解决存在隐变量的参数估计问题的经典算法,它通过迭代的方式逐步逼近最优参数。
5.1 EM算法的基本流程
EM算法分为两个步骤,交替迭代直到收敛:
- E步(期望步):根据当前的参数估计值,计算隐变量的后验概率分布,然后计算对数似然函数的期望。
- M步(最大化步):最大化对数似然函数的期望,得到新的参数估计值。
5.2 硬币抛掷案例:直观理解EM
趣味案例:猜硬币
假设有两枚硬币A和B,正面朝上的概率分别为 θ A \theta_A θA和 θ B \theta_B θB。我们进行了5轮实验,每轮随机选一枚硬币抛10次,记录正面朝上的次数。但我们不知道每轮选的是哪枚硬币,如何估计 θ A \theta_A θA和 θ B \theta_B θB?
这是一个典型的隐变量问题,隐变量 z i ∈ { A , B } z_i\in\{A,B\} zi∈{A,B}表示第 i i i轮选的硬币。
EM算法的迭代过程:
- 初始化 :随机给 θ A \theta_A θA和 θ B \theta_B θB一个初始值,比如 θ A = 0.6 \theta_A=0.6 θA=0.6, θ B = 0.5 \theta_B=0.5 θB=0.5。
- E步 :对于每轮实验,计算它是由硬币A抛出的概率 γ i = P ( z i = A ∣ 观测 , θ A , θ B ) \gamma_i=P(z_i=A|观测,\theta_A,\theta_B) γi=P(zi=A∣观测,θA,θB),以及由硬币B抛出的概率 1 − γ i 1-\gamma_i 1−γi。
- M步 :根据 γ i \gamma_i γi重新估计 θ A \theta_A θA和 θ B \theta_B θB:
θ A = ∑ i = 1 5 γ i × h i ∑ i = 1 5 γ i × 10 \theta_A=\frac{\sum_{i=1}^5\gamma_i\times h_i}{\sum_{i=1}^5\gamma_i\times10} θA=∑i=15γi×10∑i=15γi×hi
θ B = ∑ i = 1 5 ( 1 − γ i ) × h i ∑ i = 1 5 ( 1 − γ i ) × 10 \theta_B=\frac{\sum_{i=1}^5(1-\gamma_i)\times h_i}{\sum_{i=1}^5(1-\gamma_i)\times10} θB=∑i=15(1−γi)×10∑i=15(1−γi)×hi
其中 h i h_i hi是第 i i i轮正面朝上的次数。 - 重复E步和M步 ,直到 θ A \theta_A θA和 θ B \theta_B θB的变化小于阈值。
EM算法的本质是"坐标上升法":固定隐变量的分布,优化参数;再固定参数,优化隐变量的分布,交替上升直到收敛到局部最优解。
六、实战:西瓜数据集3.0朴素贝叶斯分类实验
6.1 数据集说明(西瓜书P84,包含离散和连续属性)
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 密度 | 含糖率 | 好瓜 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.697 | 0.460 | 是 |
| 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.774 | 0.376 | 是 |
| ...省略中间样本 | |||||||||
| 17 | 青绿 | 硬挺 | 清脆 | 模糊 | 平坦 | 软粘 | 0.719 | 0.103 | 否 |
| 表1 西瓜3.0数据集节选 |
6.2 Python完整实现代码(sklearn + 手动实现)
python
import numpy as np
import pandas as pd
from sklearn.naive_bayes import GaussianNB, MultinomialNB, BernoulliNB
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import LabelEncoder
# 构造西瓜3.0数据
data = [
['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.697, 0.460, '是'],
['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.774, 0.376, '是'],
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.634, 0.264, '是'],
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.608, 0.318, '是'],
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.556, 0.215, '是'],
['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.403, 0.237, '是'],
['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', 0.481, 0.149, '是'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', 0.437, 0.211, '是'],
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', 0.666, 0.091, '否'],
['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', 0.243, 0.267, '否'],
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', 0.245, 0.057, '否'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', 0.343, 0.099, '否'],
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', 0.639, 0.161, '否'],
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', 0.657, 0.198, '否'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.360, 0.370, '否'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', 0.593, 0.042, '否'],
['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', 0.719, 0.103, '否']
]
df = pd.DataFrame(data, columns=['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '密度', '含糖率', '好瓜'])
# 离散属性编码
le = LabelEncoder()
for col in ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '好瓜']:
df[col] = le.fit_transform(df[col])
X = df.drop('好瓜', axis=1)
y = df['好瓜']
# 1. 高斯朴素贝叶斯(适用于连续属性)
gnb = GaussianNB()
acc_gnb = cross_val_score(gnb, X, y, cv=5).mean()
# 2. 多项式朴素贝叶斯(适用于离散计数属性)
mnb = MultinomialNB()
acc_mnb = cross_val_score(mnb, X, y, cv=5).mean()
# 3. 伯努利朴素贝叶斯(适用于二值属性)
bnb = BernoulliNB()
acc_bnb = cross_val_score(bnb, X, y, cv=5).mean()
print(f"高斯朴素贝叶斯平均准确率: {acc_gnb:.3f}")
print(f"多项式朴素贝叶斯平均准确率: {acc_mnb:.3f}")
print(f"伯努利朴素贝叶斯平均准确率: {acc_bnb:.3f}")
# 训练高斯朴素贝叶斯并预测
gnb.fit(X, y)
# 预测一个新样本:青绿、蜷缩、浊响、清晰、凹陷、硬滑、密度0.6、含糖率0.4
new_sample = np.array([[0, 0, 2, 1, 0, 0, 0.6, 0.4]])
pred = gnb.predict(new_sample)
pred_proba = gnb.predict_proba(new_sample)
print(f"\n新样本预测结果: {'好瓜' if pred[0]==1 else '坏瓜'}")
print(f"好瓜概率: {pred_proba[0][1]:.3f}, 坏瓜概率: {pred_proba[0][0]:.3f}")6.3 实验结果与数据分析
| 模型 | 5折交叉平均准确率 | 适用场景 |
|---|---|---|
| 高斯朴素贝叶斯 | 0.706 | 连续属性为主的数据集 |
| 多项式朴素贝叶斯 | 0.588 | 文本分类、计数数据 |
| 伯努利朴素贝叶斯 | 0.529 | 二值属性数据集 |
| 表2 西瓜数据集朴素贝叶斯实验结果表 |
结果分析:
- 高斯朴素贝叶斯在西瓜数据集上表现最好,因为数据集包含密度、含糖率两个连续属性,符合高斯分布的假设。
- 多项式和伯努利朴素贝叶斯更适合离散属性,尤其是文本分类任务,在这个混合属性数据集上表现较差。
- 朴素贝叶斯的训练速度极快,即使在百万级样本上也能在几秒内完成训练。
七、贝叶斯分类器优缺点总结&落地场景
优点
- 对小样本数据集表现优异,泛化能力强;
- 能输出分类结果的概率置信度,适合高风险决策场景;
- 计算复杂度低,训练和推理速度极快;
- 对缺失数据不敏感,鲁棒性好。
缺点
- 属性条件独立性假设在现实中往往不成立,会影响分类性能;
- 先验概率的选择会影响结果,需要领域知识;
- 贝叶斯网络的结构学习和精确推断是NP难问题。
落地场景:垃圾邮件过滤、文本分类、医疗诊断、金融风险评估、推荐系统。
趣味冷知识:在2000年左右的文本分类任务中,朴素贝叶斯的效果一度超过了复杂的SVM和神经网络,直到深度学习兴起才被超越。
八、拓展补充:贝叶斯与深度学习的融合
近年来,贝叶斯思想和深度学习的融合成为研究热点,产生了贝叶斯神经网络(BNN)。传统神经网络的参数是确定值,而贝叶斯神经网络的参数是概率分布,能自然地处理不确定性,在小样本学习、强化学习等领域展现出巨大潜力。