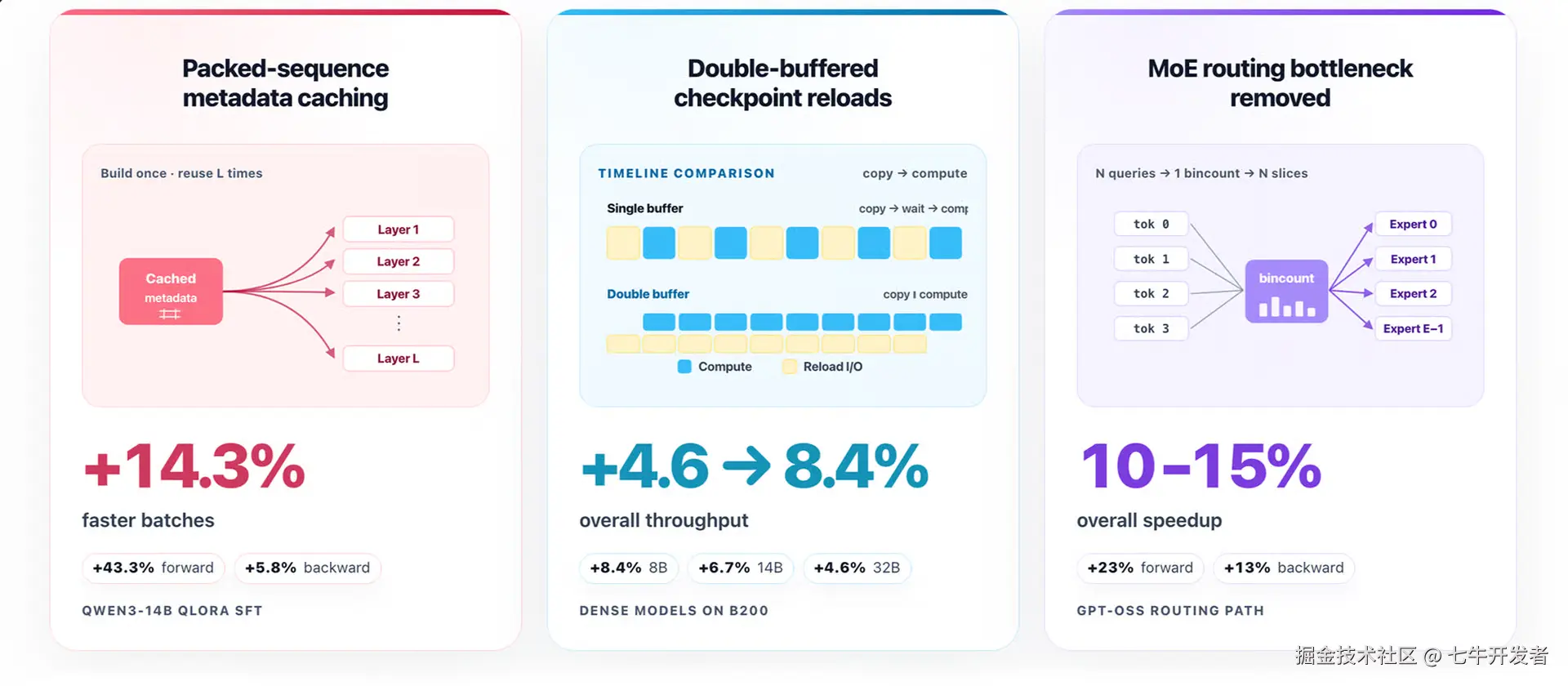
上图是 Unsloth 团队给出的性能提升汇总。这篇文章讨论的不是模型结构变化,而是一次训练系统优化实践:在不影响准确率的前提下,如何通过缓存 metadata、重叠 copy 与 compute、优化 MoE routing 等方式,在原本 2--5 倍训练加速之外继续提升性能。
以下内容从 Unsloth 团队视角展开:
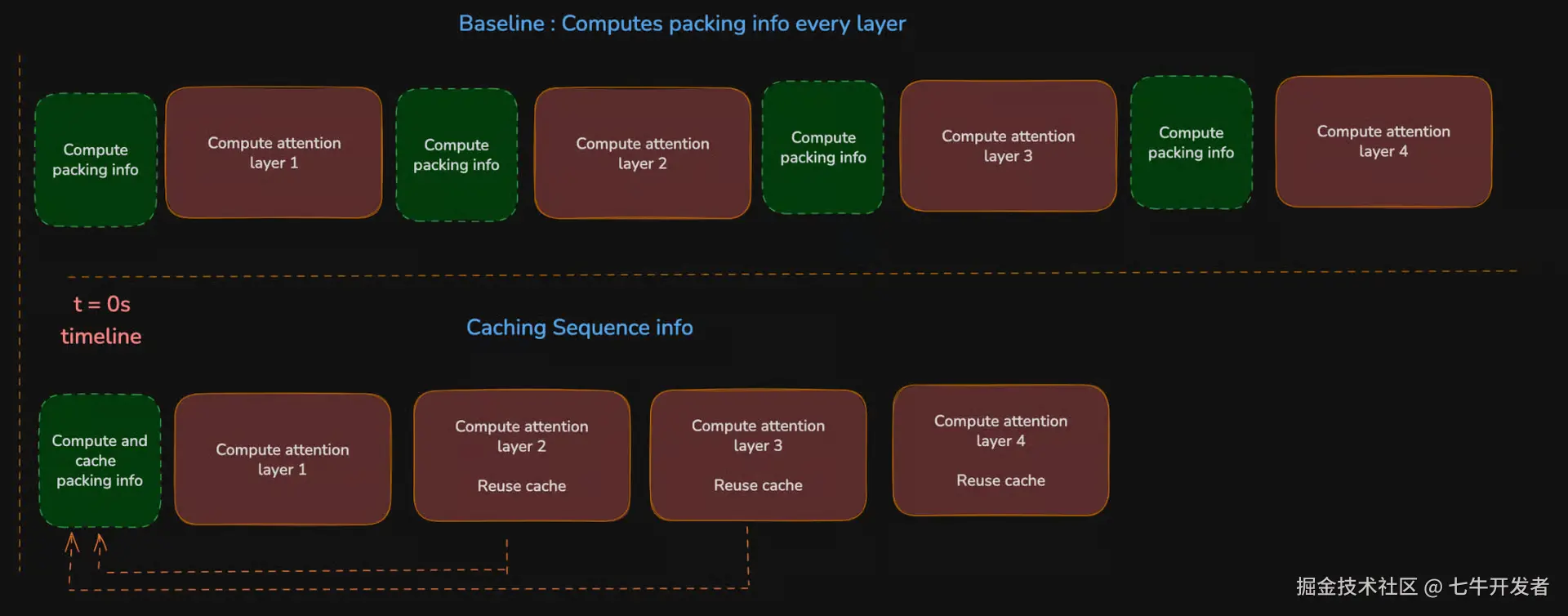
缓存 Packed-Sequence Metadata
假设我们有几个较短的训练样本。

与其把它们都 padding 到同样长度,并在 padding token 上浪费计算,不如把它们拼接成一个更长的 packed sequence。
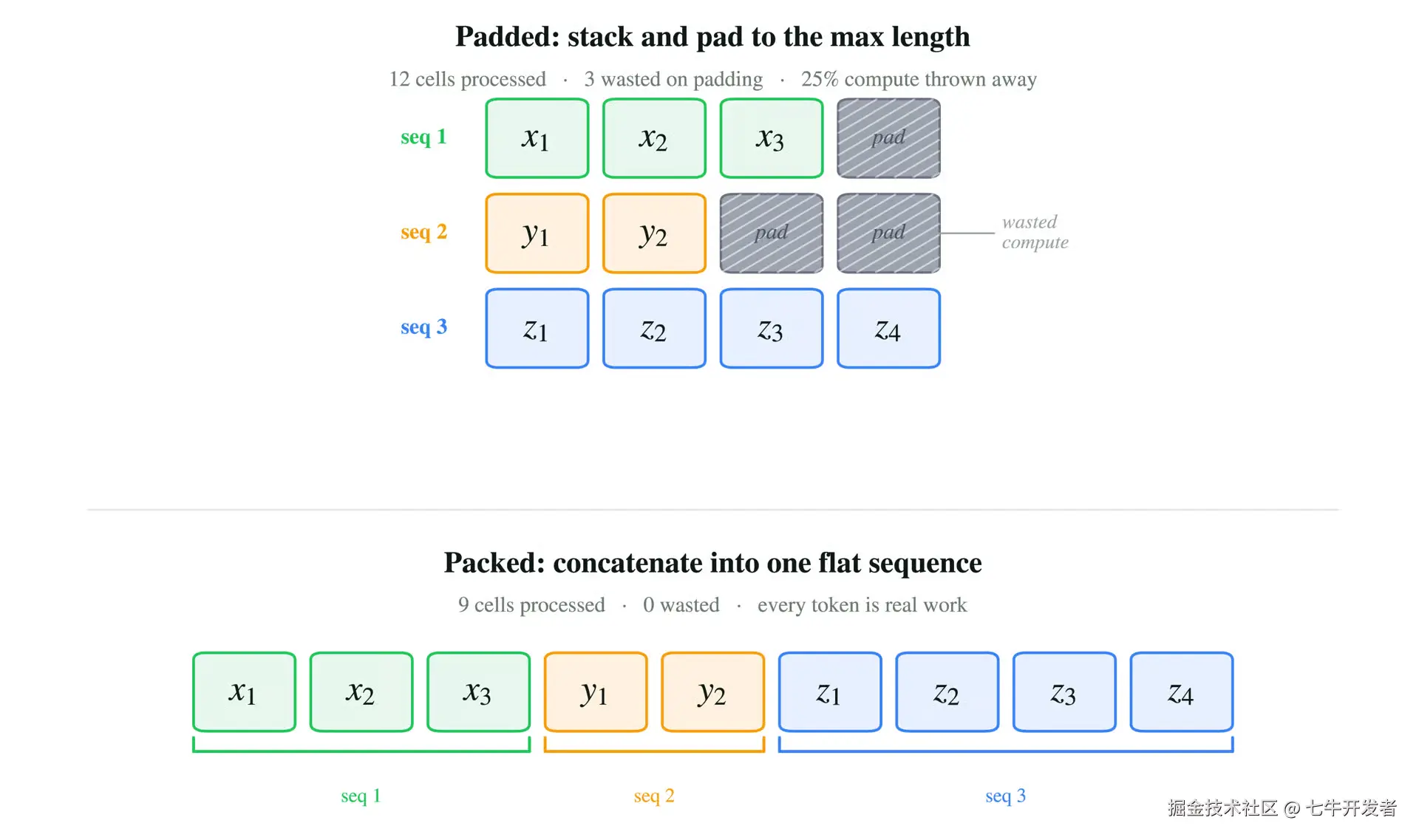
但是,模型仍然要知道每个原始序列从哪里开始、在哪里结束。因此,除了 packed tokens 之外,还得携带一些 sequence metadata,例如:
-
每个序列的长度,也就是 sequence lengths;
-
序列的累计偏移量,也就是 cu_seqlens,用来标记每段序列的起止位置;
-
当前 batch 中的最大序列长度;
-
基于这些信息生成的 attention 结构,比如 attention mask。
这里的关键点在:对于同一个 packed batch,这些 metadata 在每一层都是一样的。如果我们把一个 packed batch 的边界信息写成:B = { lengths, cu_seqlens, max_seqlen, mask structure },那么在这次 forward pass 中,每个 transformer layer 使用的都是同一个 B。
如果模型有 L 层,那么每一层都重新构建或重新同步一次 B,本质上是在重复处理同一份信息,并不会带来新的计算价值。
换句话说,有效的工作是:构建一次 B,使用 L 次。浪费的做法是:构建 B + 构建 B + ⋯ + 构建 B,一共 L 次。
这里的开销主要不是额外的 FLOPs。一些路径可能会触发 device-to-host synchronization,也就是 GPU 和 CPU 之间的同步等待。一旦这种同步发生在逐层执行的路径里,开销就会在每一层重复出现。
packed-sequence caching 这项改动减少的就是这类问题。它不再反复重建 packed sequence 信息、SDPA packed masks 和 xFormers block masks,而是针对当前 packed batch,在每个设备上缓存可复用的 metadata,以及由它推导出的 attention 相关结构。之后各层就可以复用这些缓存结构。
优化原理
Packed training 本来已经通过消除 padding 浪费来提升利用率。但如果 metadata 路径持续强制同步,其中一部分收益就会被一些和模型实际学习无关的开销吃掉。
缓存之所以有帮助,是因为它把重复的协调工作从热路径中移除了。forward pass 受益最大,因为相同的 packed metadata 会在很多层里被反复消费。
性能数据
在 Qwen3-14B QLoRA SFT 上:
-
forward:+43.3%
-
backward:+5.8%
-
per batch:+14.3%
forward pass 的收益最大,因为重复的 metadata 和 mask 准备会最直接地体现在这里。backward 也有提升,但幅度更小。节省的时间类似,但 backward pass,尤其是在使用 gradient checkpointing 时,本身耗时更长,所以相对收益看起来更小。
现在我们已经知道了测得的收益,可以问一个更简单的问题:这个量级合理吗?
合理性检查
如果假设每一层大致相似,我们可以把 packed-attention 路径建模为:T_uncached ≈ L · (A + s)。其中:
-
L 是层数;
-
A 是每层 attention 侧的有效工作;
-
s 是每层重复发生的 metadata 和 mask 准备开销。
有了缓存之后,这个重复开销不再是每层支付一次,而是每个 batch 只支付一次:T_cached ≈ L · A + s。所以节省的时间大约是:T_saved ≈ (L − 1) · s。
对于 packed SDPA 路径,我们在 NVIDIA Blackwell GPU 上做的 microbenchmark 显示,底层、host-visible 的 metadata 调用确实存在,但比较小,大约每次 0.2 ms。真正占主要部分的重复开销,不是单次 metadata 调用,而是 packed SDPA mask 的重复构建。在一个总计 2,048 个 packed tokens 的合成 packed batch 中,这个构建过程耗时约 13.7 ms。
对于 SDPA backend,更好的理解模型是:小的 stream fence + mask rebuild ≈ mask rebuild。这样就可以做一个更干净的一致性检查。假设一次 packed-mask rebuild 的成本是 m 毫秒,那么在一个 uniform-layer model 下:T_saved ≈ (L − 1) · m。当 m ≈ 13.7 ms 时,预测结果是:
-
16 层:(16 - 1) × 13.7 ≈ 206 ms
-
28 层:(28 - 1) × 13.7 ≈ 370 ms
更小的 packed-sequence 运行也显示了相同模式:
-
Llama-3.2-1B,16 层:每个 step 大约节省 199 ms,端到端 step time 降低约 11.5%
-
Qwen3-0.6B,28 层:每个 step 大约节省 319 ms,端到端 step time 降低约 14.8%
这些百分比是相对于完整训练 step time 而言的,所以它们仍然包含 packed-attention 路径之外的工作,例如 embeddings、MLP、LM head、loss 和 framework overhead。这个估算有意只关注 block 中 packed-attention 这一侧,而不是整个 transformer layer。它只是用来检查:对于 packed SDPA 路径来说,实测收益是否在合理范围内。
重叠 copy 与 compute 隐藏延迟
Activation checkpointing 是训练大模型时的一种标准技术。它的思路是:不要在 backward pass 中一直保留每个中间 activation,以此节省显存。作为交换,我们会在 backward 时付出一些额外计算成本。这种权衡通常是值得的,尤其是对于更大的模型。
但它也带来了另一个系统问题:如果某个 activation 已经被 offload 了,它要怎么回到 GPU 上参与 backward?
在 Unsloth 的 smart checkpointing 路径中,activation 可以先放在 pinned CPU memory 中,并在需要时拷贝回来。这可以节省 VRAM,但也可能引入瓶颈:
-
把 activation 从 CPU 拷贝到 GPU;
-
等待拷贝完成;
-
在这个 activation 上执行 backward compute;
-
开始下一次拷贝。

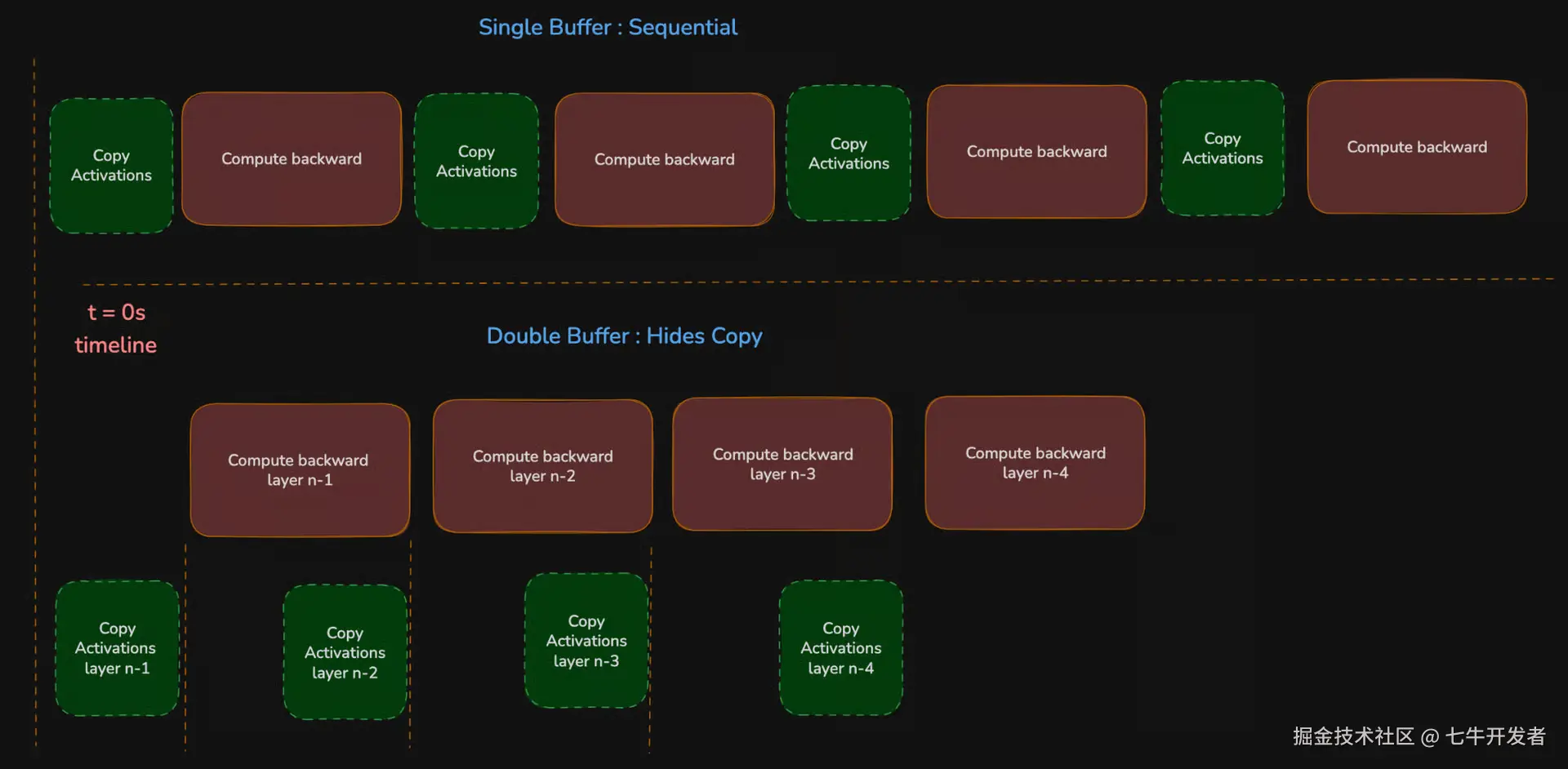
这是一个串行化模式。如果 copy 和 compute 复用同一个 buffer,copy stream 和 compute stream 就会一直轮流执行。
设 T_copy 为 activation reload 的时间,T_compute 为当前层 backward compute 的时间。使用单个 buffer 时,这部分 step 大致会受限于:T_single ≈ T_copy + T_compute,这就是串行化情况。我们几乎要一个接一个地完整支付两部分成本。
更高效的处理方式是使用两个 buffer。当 backward pass 在 buffer A 上运行时,copy stream 可以把下一个 activation 预加载到 buffer B。然后两者交换角色。这就形成了 pipeline overlap,虽然不是完美重叠。
Double buffering 并不会减少数学计算量。它是把 copy latency 隐藏在有用的 compute 背后。
优化原理
当模型足够大,backward compute 已经相当可观,但又没有大到让所有 copy overhead 都淹没在噪声里时,这种优化通常会变得更有效。对于更大的模型,更高的隐藏维度意味着更多数据移动,所以隐藏这部分移动会产生更大影响。更大的模型通常也有更多层,这也创造了更多把拷贝隐藏在计算背后的机会。
这也是为什么这类优化更适合较大的稠密模型:模型规模越大,backward 阶段的计算量越充足,activation 回拷就越有机会和计算过程重叠;同时,第二个 buffer 额外占用的显存相对有限。
在具体实现中,这项优化也保留了一些保护机制:
-
只有在显存充足时,才启用额外 buffer;
-
当内存预算紧张时,可以自动回退到普通路径;
-
整个过程不改变训练结果的正确性。
性能数据
在更大的稠密模型运行中,使用 NVIDIA B200 Blackwell GPU 进行 benchmark:
-
8B:0.3739 → 0.4053 steps/s,+8.40%
-
14B:0.2245 → 0.2395 steps/s,+6.70%
-
32B:0.1979 → 0.2070 steps/s,+4.61%
显存开销保持在较小范围内:
-
8B:+0.37 GB
-
14B:+0.47 GB
-
32B:+0.23 GB
在这些运行中,final losses 基本没有变化。
加速在更大的稠密模型上保持一致,同时额外显存成本也相对较小。
当我们知道了测得的收益后,自然的后续问题是:这个量级合理吗?
合理性检查
如果假设有 L 个启用了 checkpointing 的层,并且每层大致相似:
-
每次 reload 花费时间 c;
-
每个 backward compute chunk 花费时间 g。
这也会随着 batch size、sequence length 以及其他影响数据移动和计算的因素而变化。为了简洁,这里省略这些项。
使用一个 buffer 时:T_single ≈ L · (c + g);使用两个 buffer 时,第一层仍然要等待 activation 到达,最后一层也仍然要完成计算。所以一个更好的近似是:T_double ≈ c + (L − 1) · max(c, g) + g。
因此节省的时间大约是:T_saved ≈ (L − 1) · min(c, g)。
这个结果的有用解读是:
-
第一次 copy 仍然暴露在外;
-
最后一次 compute 仍然暴露在外;
-
但在 pipeline 中间部分,copy 和 compute 可以重叠。
如果重叠效果不错,中间每层的成本会更接近:T_middle ≈ max(T_copy, T_compute)。
根据更大模型的实测结果,每个 training step 节省的时间大约是:
-
8B:约 207 ms
-
14B:约 279 ms
-
32B:约 222 ms
这些 host buffer 分配在 pinned memory 上,也就是 CPU 侧的页锁定内存。因此,这里真正相关的是 pinned memory 到 GPU 的传输带宽,而不是普通 pageable memory 的传输带宽。在我们的 NVIDIA B200 Blackwell 系统上,这个带宽大约是 55.7 GB/s;64 GB/s 可以作为一个有用的 PCIe 上限来对照。
如果我们用额外 buffer size 粗略代理一次 activation reload,那么每次 reload 自然就在几毫秒量级:
-
8B,0.37 GB:在 55.7 GB/s 下约 6.6 ms;按 64 GB/s 上限约 5.8 ms
-
14B,0.47 GB:在 55.7 GB/s 下约 8.4 ms;按 64 GB/s 上限约 7.3 ms
-
32B,0.23 GB:在 55.7 GB/s 下约 4.1 ms;按 64 GB/s 上限约 3.6 ms
为了说明观测到的每步节省时间,我们大概需要隐藏几十次这样的 reload:
-
8B:在 55.7 GB/s 下约 31 次 reload;按 64 GB/s 约 36 次
-
14B:在 55.7 GB/s 下约 33 次 reload;按 64 GB/s 约 38 次
-
32B:在 55.7 GB/s 下约 54 次 reload;按 64 GB/s 约 62 次
在几十个使用了 activation checkpointing 的层中隐藏一次这样的 reload,最后会落在每个 step 节省几百毫秒这个范围内,这正是我们观察到的量级。
再次强调,这部分节省时间只是完整端到端训练 step 的一部分。它并不是要解释 embeddings、LM head、loss、optimizer work 或其他所有非 checkpointed 部分。这里只是说明:我们可以隐藏的通信量足够大,能够合理解释测得的 step-time 收益。
范围更小但有用的 MoE 优化
第三项改动更专门一些,但它在 MoE 路由中展示了同样的模式。
在我们考察的 PyTorch-based GPT-OSS MoE 路径中,路由中一个昂贵的部分是判断哪些 tokens 会被送到哪些 expert。一个朴素实现可能会这样写:
Plain
for expert_idx in range(num_experts):
token_idx, _ = torch.where(router_indices == expert_idx)乍看之下,这似乎没有问题。但这里的 torch.where 是一种依赖数据内容的动态索引操作:每个 expert 分到的 token 数量会随着 batch 变化,输出大小并不固定。这可能引入 CPU 和 GPU 之间的同步等待,或带来额外的运行时开销。如果每个 expert 都执行一次 torch.where,那么动态查询的数量就会随着 num_experts 增加。更好的做法是一次性把所有东西分组:
-
展平所有 expert assignments;
-
按 expert ID 做 stable sort;
-
用一次 bincount 得到每个 expert 的 token 数量;
-
根据这些 count 构建 offsets;
-
按 expert 切分已经分组的 token 列表。
我们改变的不是路由逻辑本身,而是减少了让运行时反复回答"哪些 token 分给了哪个 expert"这类动态索引问题的次数。
原来大致是:dynamic-query overhead ∝ num_experts。因为我们对每个 expert 做一次动态查询。现在则更接近:dynamic-query overhead ∝ 1,再加上一些开销很小的 bookkeeping 工作。
这是同一主题在一个更专门场景里的体现:先分组一次,然后复用 offsets,而不是反复请求动态 token 列表。
性能数据
注意,这些优化适用于任何使用 native_torch backend 的 MoE。
对于这项 GPT-OSS-specific routing 改进:
-
团队验证显示,在 GPT-OSS 配置上大约有 10--15% 加速;
-
在目标 routing path 中,我们看到 forward +23%,backward +13%。
改动背后的原理
虽然这三项优化位于技术栈的不同位置,但它们解决的是同一类问题。关键的优化机会并不在主计算 kernel 本身,而是在主 kernel 周围的 glue code,也就是那些负责连接数据准备、状态管理和运行时调度的辅助代码中:
-
反复重建已经存在的 metadata;
-
对本可以缓存的信息反复进行同步;
-
让 copy 和 compute 串行执行,而不是重叠执行。
这也解释了为什么这些改进在思路上可以组合起来。随着主计算 kernel 越来越快,过去不明显的额外开销,开始在完整的单步训练耗时中占据更明显的比例。
这里有一个有用的工程经验:当数学计算相关的 kernel 已经被充分优化之后,想要继续"更快",通常意味着两件事:
-
少做不必要的重复工作;
-
让不可避免的工作尽量并行发生。
这三项优化做的正是这件事。