前言
目前,关于 DeepSeek V4 的解读已十分丰富。如大家比较关心的领域 ------ 写代码(尤其是 Agentic coding 的能力);一些与白领工作相关的能力,如数据分析、内容创作以及创意类写作等 ... AI 感比较弱,用户的反馈还是不错的。

官方给出的核心数据解释,DeepSeek V4 的综合能力大概达到了 Anthropic Claude 4.5 的级别,和大众实际使用体感是比较接近的,能力大致对齐 Anthropic 2025 年 12 月左右的模型水平。
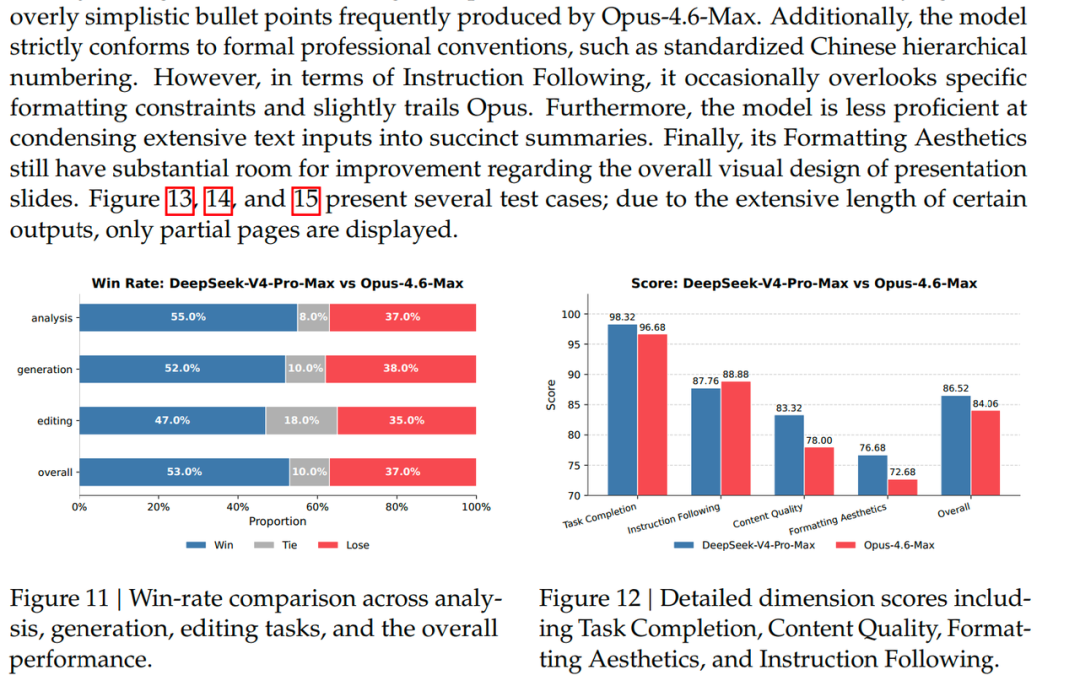
技术报告最后指出,整个 DeepSeek V4 所做的架构创新和 Infra 方面的优化工作,实际上是为了实现在未来这种 Agent 长程任务中,在超长上下文场景下,提供足够高的输出质量和处理效率。下面,我们先来探讨核心问题:长程任务与长上下文的内在关联。
为什么长程任务一定要解决长上下文推理
以 Agent Code 为例,我们来看一下这个所谓的"长程任务"。
假设,我们设计一个项目,首先肯定要设计方案,规划它的能力边界、架构和技术选型;然后我们会将其拆解为一个一个的功能和一级模块,去执行并生成代码。在生成代码的过程中使用了大量工具,如查看所需依赖的 API 文档,Web Search 等,某些模块生成完以后对它做静态编译检测,这个过程中发现一些错误,再定位修改,将修改结果 append 到新一轮的对话中,如此往复...
一个项目在进行大量迭代交互的过程中,如增加功能、修复 bug、重构等等...会产生一轮又一轮的上下文对话。长程 任务越复杂,所需的上下文自然就越长。
Agent 这个时代到来以后,长上下文处理能力可以说是基本能力。它不是聊天,而是像人类一样,通过不断获取上下文,更新自己的信息,最终交付自己的工作。
以下的几个章节,我们会来一步一步地看 DeepSeek 是如何交付这种长上下文的推理能力的。
Transformer 架构
为了解答这个问题,我们必须回到语言模型和 Transformer 这个架构本身。
语言本身有的时候表达的是推理,有的时候表达的是事实,但无论是表达的什么东西,**它都是以一种前后有相关性的序列的形式在出现。**例如实现写代码或者是创意写作的能力,就是利用了 Transformer 架构去抽取语言内部的这种关系,并把它内化为模型。
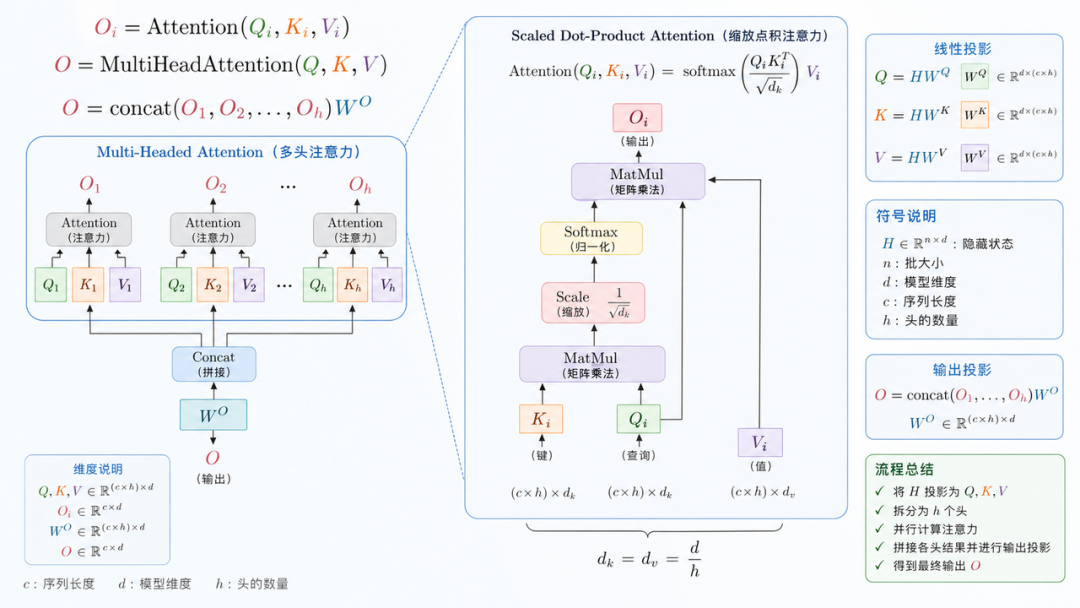
目前,大部分语言模型的 Transformer 变体,核心是 Attention 和 FFN 所构成的模块的堆叠。
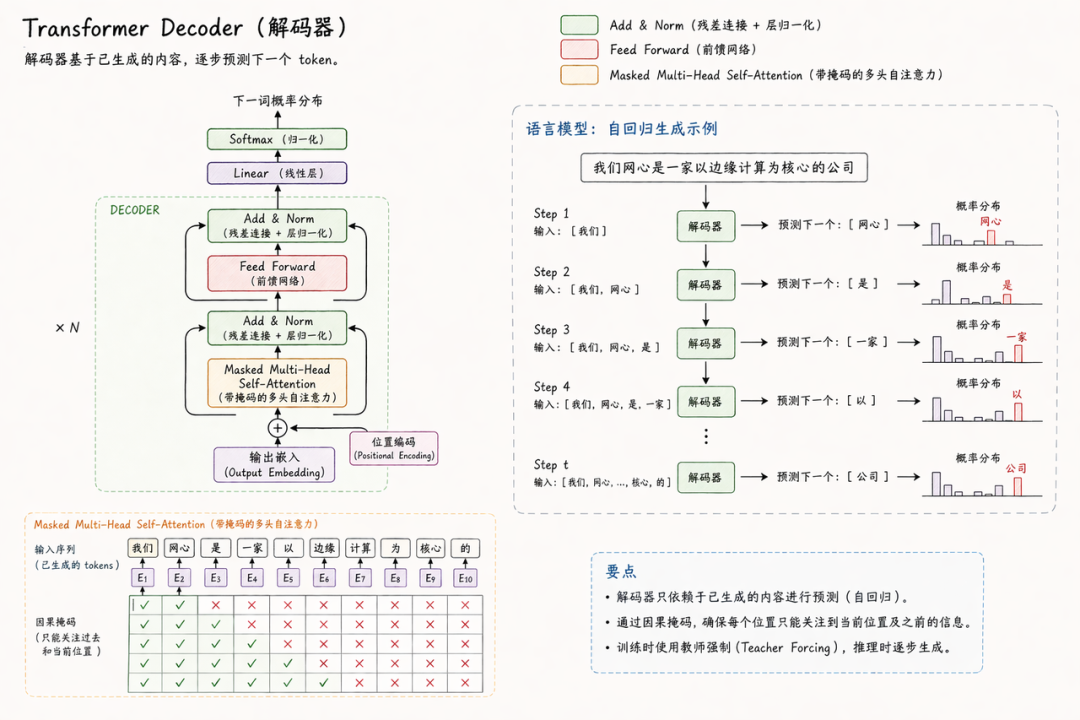
✅ Attention
我们可以简单地理解为,它在抽取语言序列中当前应该产生的 token 与之前的文字之间,到底存在什么样的依赖关系,也就是 context,也可以理解为,我要知道过去所有的输入 token 到底对当下有什么影响。
✅ FNN
这是一个无状态的计算,它按照自己记住的世界知识分布对 Attention 层所输出的、抽取完成后的 context 进行计算。
另外一个核心模块就是 Residual 残差网络,其核心作用是让我们能够以更稳定的方式训练更深的网络。
而此次,**DeepSeek V4 对以上的模块都有调整,尤其是关于 Attention 和残差网络的调整较多,**后面我们一个一个地来分析。
但是在开始这些讨论之前,我们必须要知道,DeepSeek V4 为何要调整,它又是受到了哪些影响和限制。因此,我们决定:所有开启讨论的前提,是需要先摸清当下当前 AI 所使用的硬件。
那些 AI Accelerator
现在的人工智能所使用的,无论是所谓的 GPGPU(通用图形处理器)还是 NPU(神经网络处理器),其核心都是依赖一些高速的并行计算。而为了实现这种高速的并行计算,硬件设计具有以下特性:
-
投入到任务调度上的晶体管数量有限。
-
对于矩阵计算的能力远高于对 Scalar(标量)计算的能力。
-
显存的配置是有限的,显存的大小和带宽的增长远低于算力的增长。
-
低精度的算力远高于高精度的算力。例如:FP4 > FP8 > FP16 > FP32
下图是一个 H100 图式:
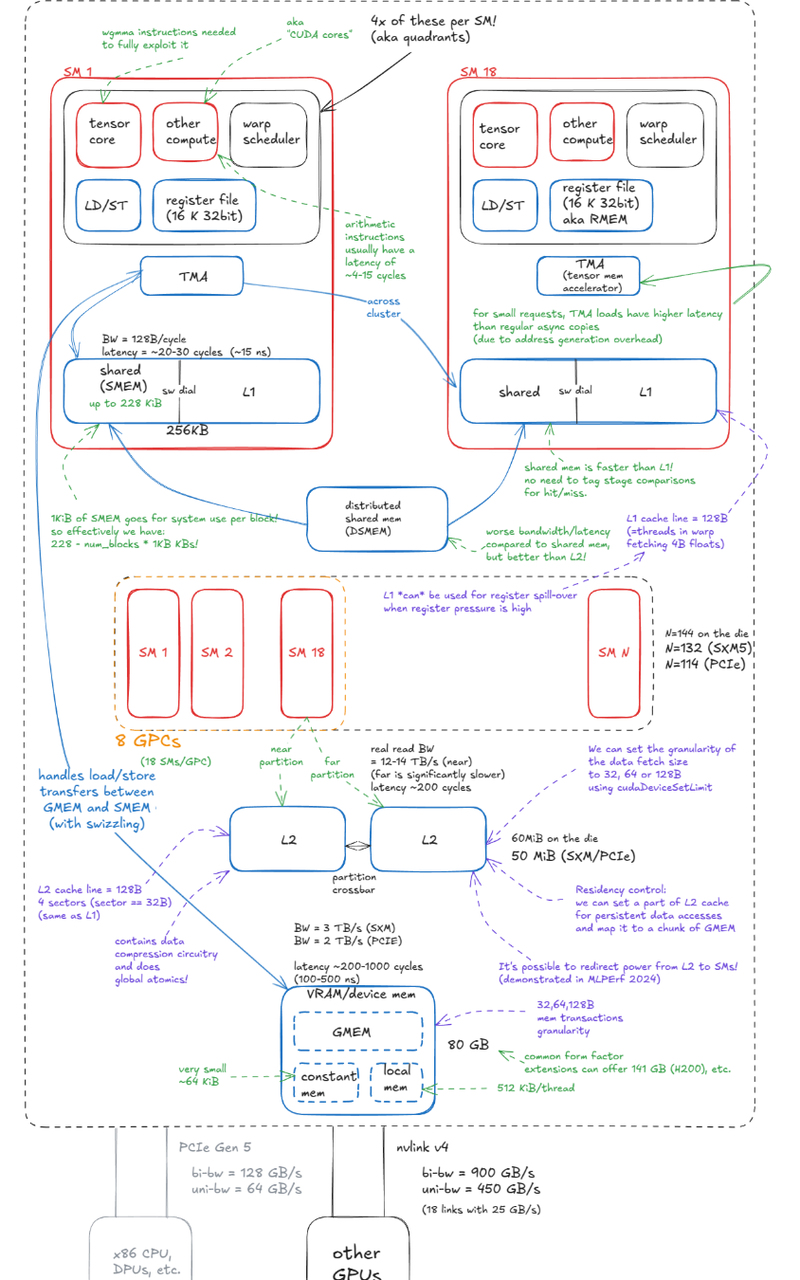
一张价值几十万的 H100,它只有 80GB 的显存,而这个显存所提供的带宽即使在 SXM5 下也只有 3TB/s。在 SXM5 封装的情况下,一共有 132 个激活的 SM 进行计算,也就是传说中 1000 TFLOPS 左右的 FP8 算力。
下图是经典的整个英伟达显卡的发展历程:无论是显卡的带宽还是显存的大小,其增长速度都远跟不上算力的增长。
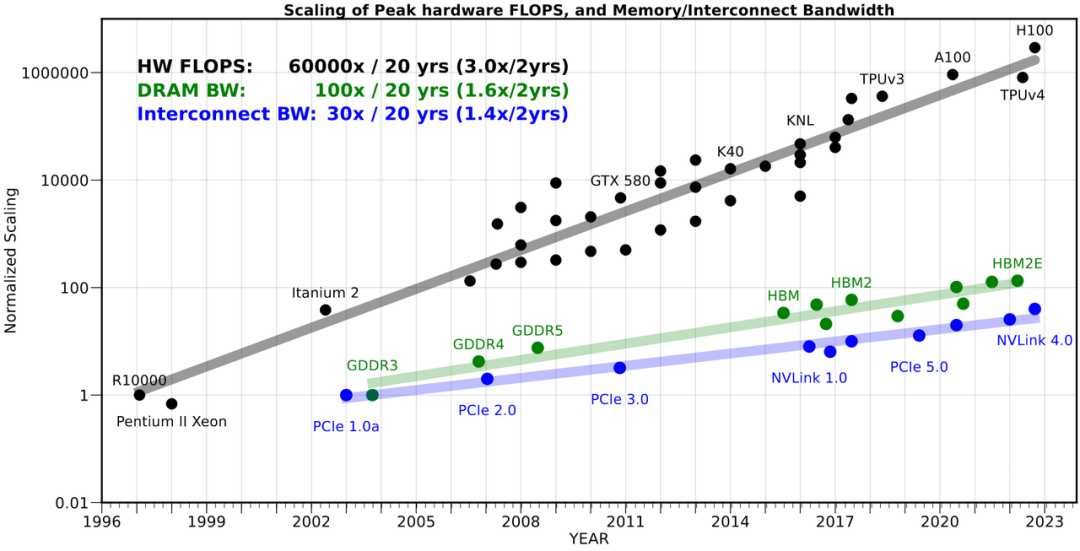
有了这些硬件的简单图景认知,我们才能聊聊模型之所以要做这个改造的原因 ------ 如果算力是无限的,显存的大小和带宽也都是无限的情况下,我们理应要做的事情是去提高 Attention 的质量,而不是去降低它的计算复杂度,或者去考虑降低它的大小和对显存带宽的压力。
Attention 是核心瓶颈
让我们看一看关于 Attention 的调整,以及为什么要这么调整?
在之前的文章中:
我们分析过目前一般使用的 Attention 的计算,是当前的 query 和历史上所有的 key 的内积所产生的 attention score,然后对所有历史输入 token 的 value 进行加权平均后得到 context。当然这里也可以引入很多别的 Attention 类似于 RNN,通过不断的 recursive 去提取之前 token 对现在的影响。
但无论是哪一种,长序列的处理复杂度都和序列的长度以及单次的计算复杂度有关系。
那么,为什么现在主流 Attention 还是上面提到这种内积的计算方式,因为这种 Attention 所提供出来的模型能力,产出质量是最高的。
为了避免每一次都对 token 进行它的 key 和 value 的计算,这里衍生出了"KV Cache "这一推理优化技术,也就是将历史上的所有 key 和 value 都缓存在显存里,以备后续生成过程中直接读取使用。
而在有了 KV Cache 的情况下,序列单个 token 生成的 Attention 计算复杂度是O(L²)。在长上下文场景下,KV Cache 会变得非常庞大,读取时会占用巨量显存带宽,因为在处理长序列时,它的计算复杂度很高,HBM 存储压力、显存带宽压力就都非常大。所以 Attention 也就成了长序列所需要优化的一个核心瓶颈点了。
关于 Attention 有大量的优化,比如说 MQA,GQA,MLA。
在讨论前,我们先回到 Multi-Head Attention。Multi-Head Attention 是对于最原始、最简单的 Attention 的一个变体,它尝试从多个角度去抽取 Token 的信息。每一个 QKV 关注到了它所对应的 Token 的一个角度的信息。而 MQA 和 GQA 相当于分别对这些里面的 head 进行一定的抽取,来实现 attention 的计算,以此来降低 KV Cache 的量。
关于 MQA,GQA:
MQA,GQA 可以粗略的类比于对一批货物进行有无坏品的判断过程,我们可以只从这批货抽取一个进行检查,或者对这批货按照某种规则抽取一部分进行检查。前者对应着 MQA ,后者对应着 GQA。这样的优化可以使得缓存的独立 KV 变少,既降低了 KV Cache 的对 HBM 容量方面的压力,也降低了对显存带宽的要求。当然,这样的抽取可能会让我们损失某些角度的信息。但从实际的结果来看,大规模的 Transformer 网络在使用 MQA,GQA 后所展现出来的质量还是非常好的。
关于 MLA:
MLA 更复杂一些,是对每一个 token 都进行压缩。所谓压缩就是损失一部分高频的信号,留下一些核心的、最重要的、最显著的特征。实测的效果也很不错。虽然,MLA 针对单个 Token 的 KV Cache 的大小得到了压缩,但对于长上下文这种长序列,它本身的计算(尤其是 Attention 的计算)并没有得到很多缓解。
为了优化这个计算的复杂度,DeepSeek V3.2 引入了 DSA 的特性 :对参与计算的序列进行一次 Top-K 的抽取。为了完成这个抽取,其引入了一个低复杂度的 indexer,成功地把 Attention 的计算复杂度压缩到了O(LK)。而即便计算复杂度下降了,但它本身在长上下文场景下仍有不足。

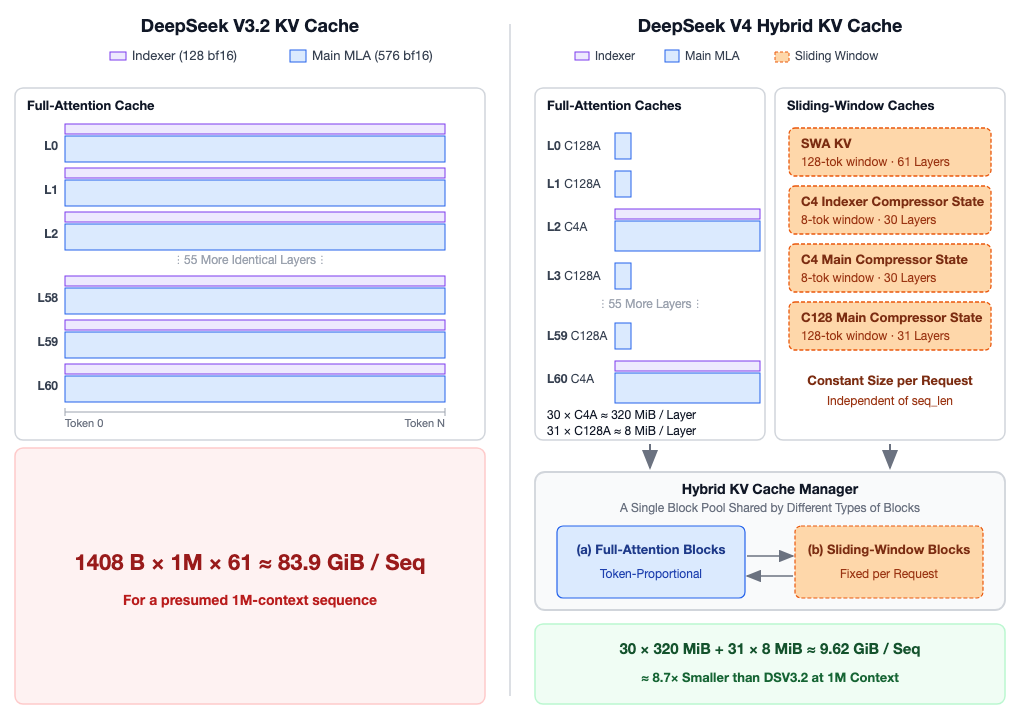
就像这幅 vLLM 所提到的计算一样:在这种情况下缓存本身并没有变少,还增加了Indexer 的 cache。DeepSeek V3.2 只是降低了 Attention 计算的复杂度,但同时引入了 indexer 的计算复杂度,而在长序列下,这个 indexer 的计算复杂度并不能算低。
针对以上问题,智谱提出了一个 Index Cache 的方法,而 SGLang 则提出了 HiSparse。
智谱利用了模型层间的相似性(即相邻两层同一个 token 所参考的前面 token 的数量应该比较接近),来压缩 DSA 的 indexer cache 数量以及针对 indexer 的计算,进一步压低 cache 和计算量。

SGLang 的 HiSparse 则是利用到序列间的统计关系:相邻两个 token 所依赖的前序序列基本接近,可能只有其中少部分KV不一样,所以设计了一个利用 CPU memory 来管理 KV cache 的系统,如使用一个 LRU Cache 来存储并管理显存中的这部分 KV Cache。DSA 的 Indexer 选取了这些缓存以后,从 CPU 里面换入新 token 所需的、但当前显存中不存在的那些 KV 值,同时换出一些符合 LRU 判断的、到目前为止没有被调用过的 KV 到 CPU memory 内,以此来降低对于显存的使用。
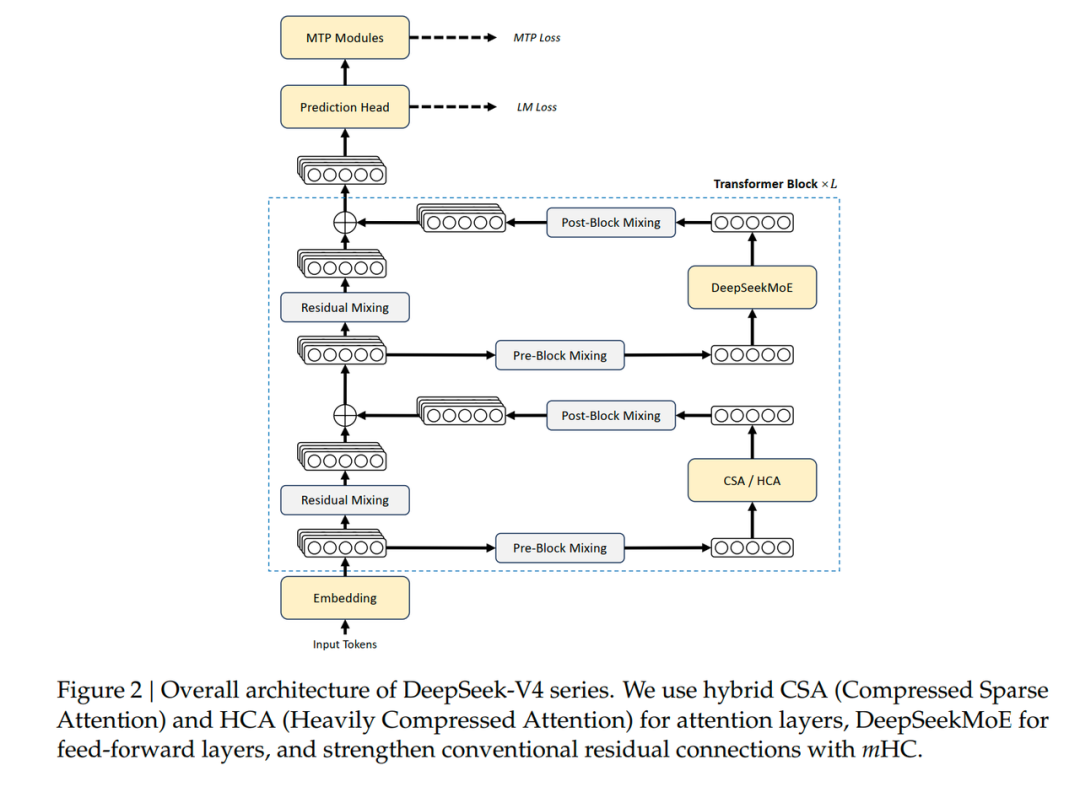
即便如此,DeepSeek 没有满意,它设计了更精妙的 Attention 机制:在一些层使用 SWA + CSA + DSA 的方式,在另外一些层使用 SWA + HCA + Dense Attention 的方式,来进一步压缩计算量和缓存量。下图是 DeepSeek V4 的整体结构:
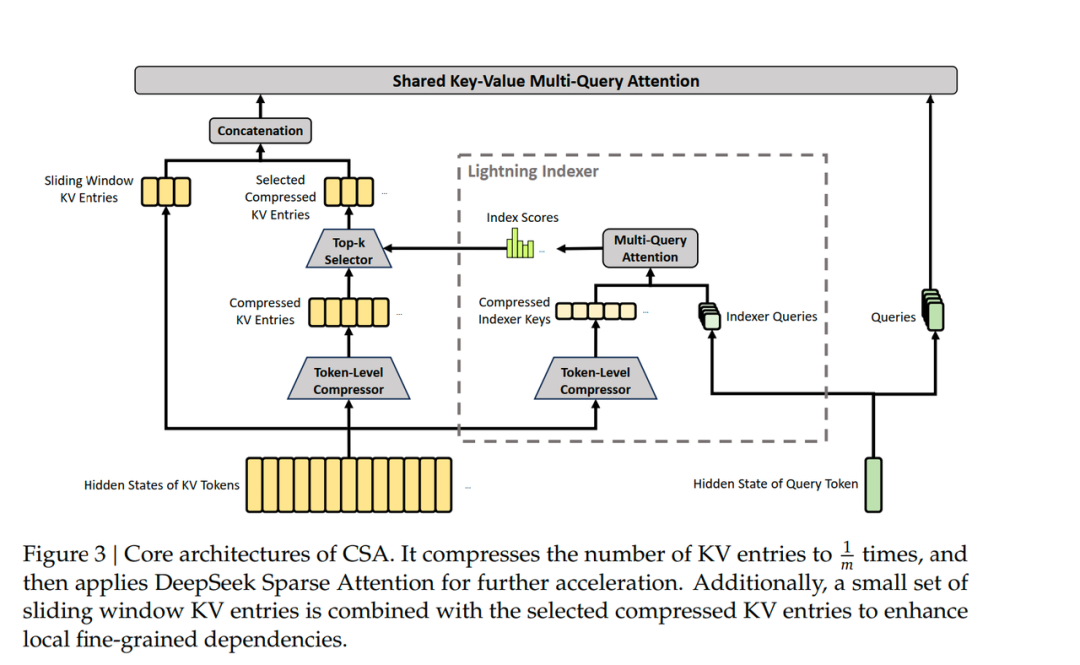
下图也就是 SWA + CSA 和 DSA(通过将 m 个 V4 pro 是 4 个 KV cache entry 压缩成一个来节省使用空间。Sliding Window 是固定的,对于长序列来说它可以不计,核心在于这里产生了 4 倍的压缩,同时还通过 DSA 来节省空间。所以,这里实际上可以结合 SGLang 的 HiSparse 方法,来进一步压低缓存大小):
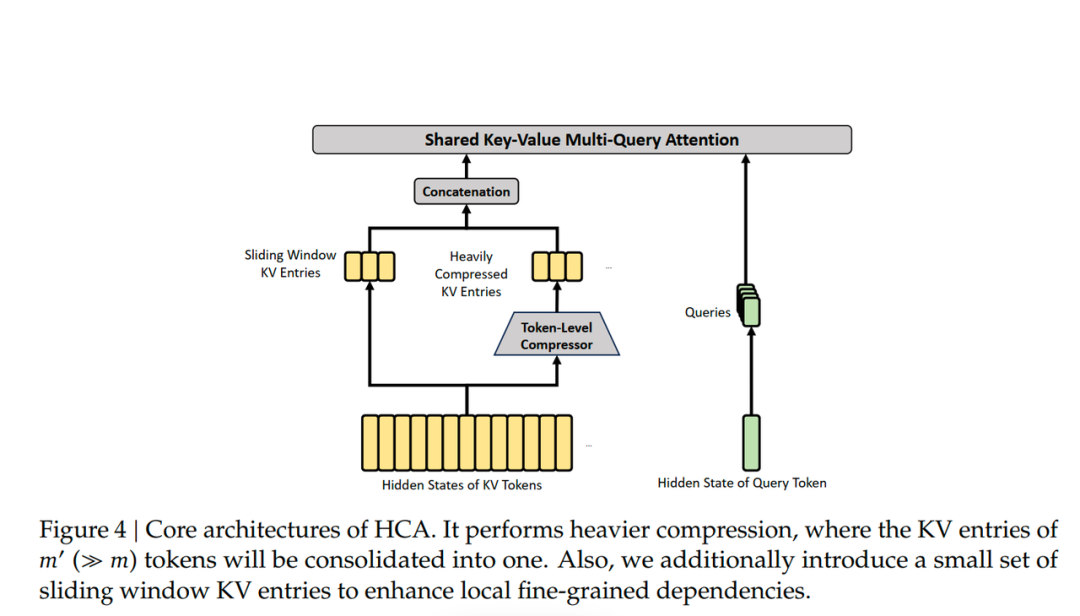
下图就是 SWA + HCA 和 Dense Attention(这一层它通过高强度的压缩,使用一个远大于 m 的系数,比如说 DeepSeek V4 Pro 使用了 128,来对 KV 进行压缩):
当然,我们永远要记住,性能的前提是质量,输出的质量必须满足最后的诉求。从目前的结果来看,以上的处理没有让 DeepSeek V4 失去很强的表达力,它的产出质量还是非常高的。
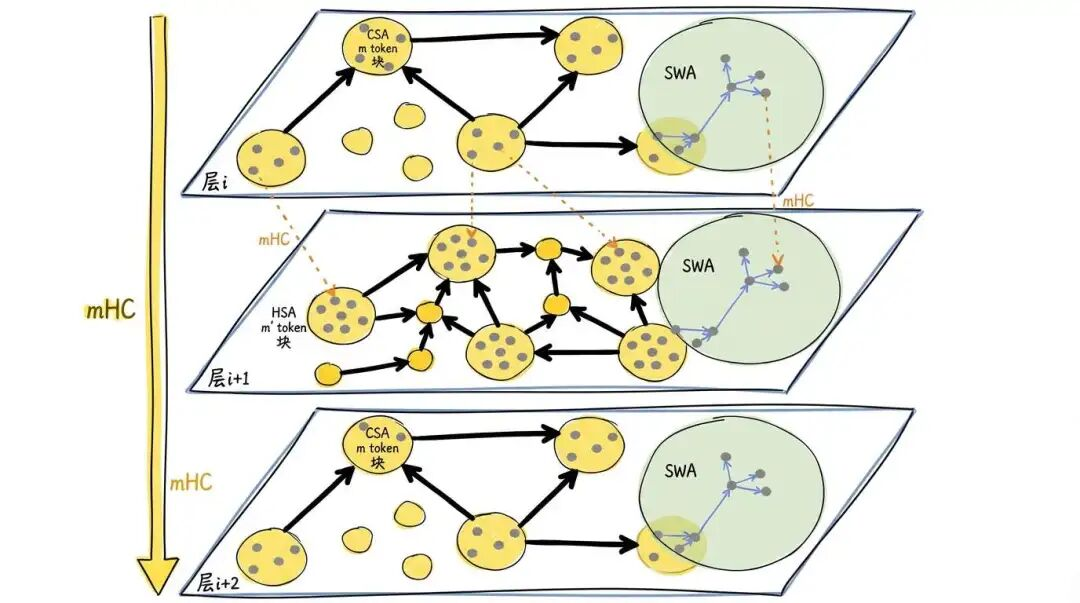
正如这幅图想要表达的,穿插的 CSA 和 HSA 层在局部都有 SWA 的保证,在一定范围内(比如说 128 token 内)看到局部信息的全量信息。而 CSA 做的轻量压缩,又通过 DSA Top-K 的形式去选举一定的历史 Token 来进行参考长距离的主干信息。压缩最多的 HSA 则像一幅略缩图,展现了低密度的全局的信息。
这种架构设计使得模型既看到了细部,又看到了全局,而计算量和缓存量都极低,这确实是一个非常精妙的设计。
我们来看看实际的效果,在都不使用 HiSparse 的情况下,1M上下文的对比结果如下:
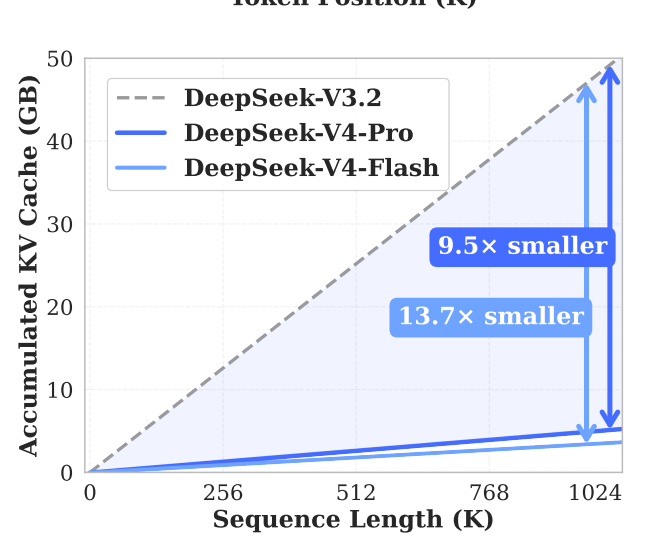
当然,从官方的角度来看,算力的节约也是非常多的。V4 Pro 跟 V3.2 比起来,有 3.7 倍的降低。
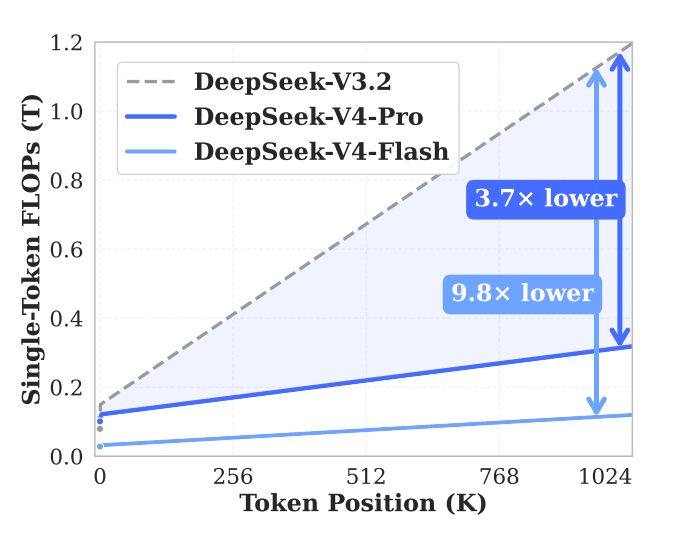
正如下页两图所示,其实现的复杂度本身也有了很大的提升。
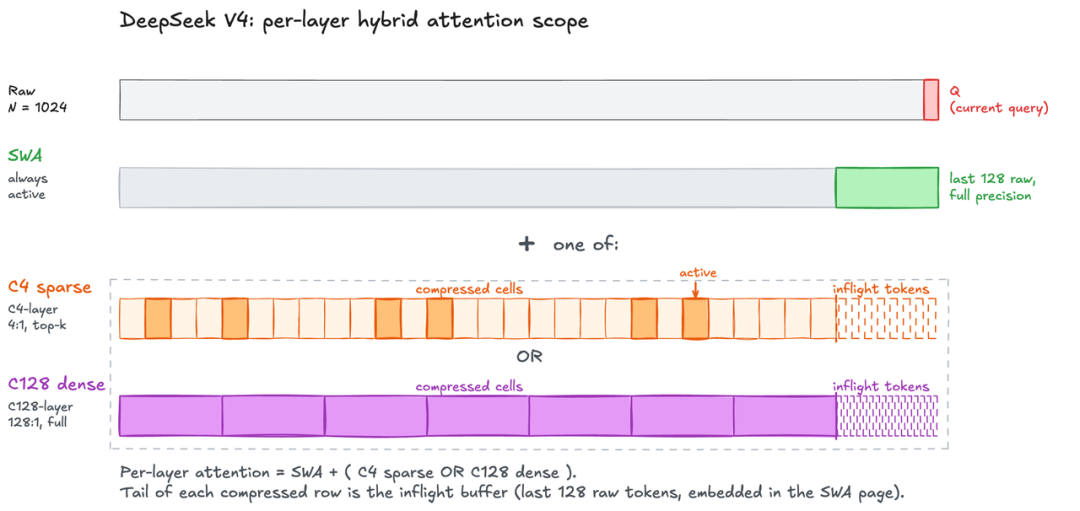
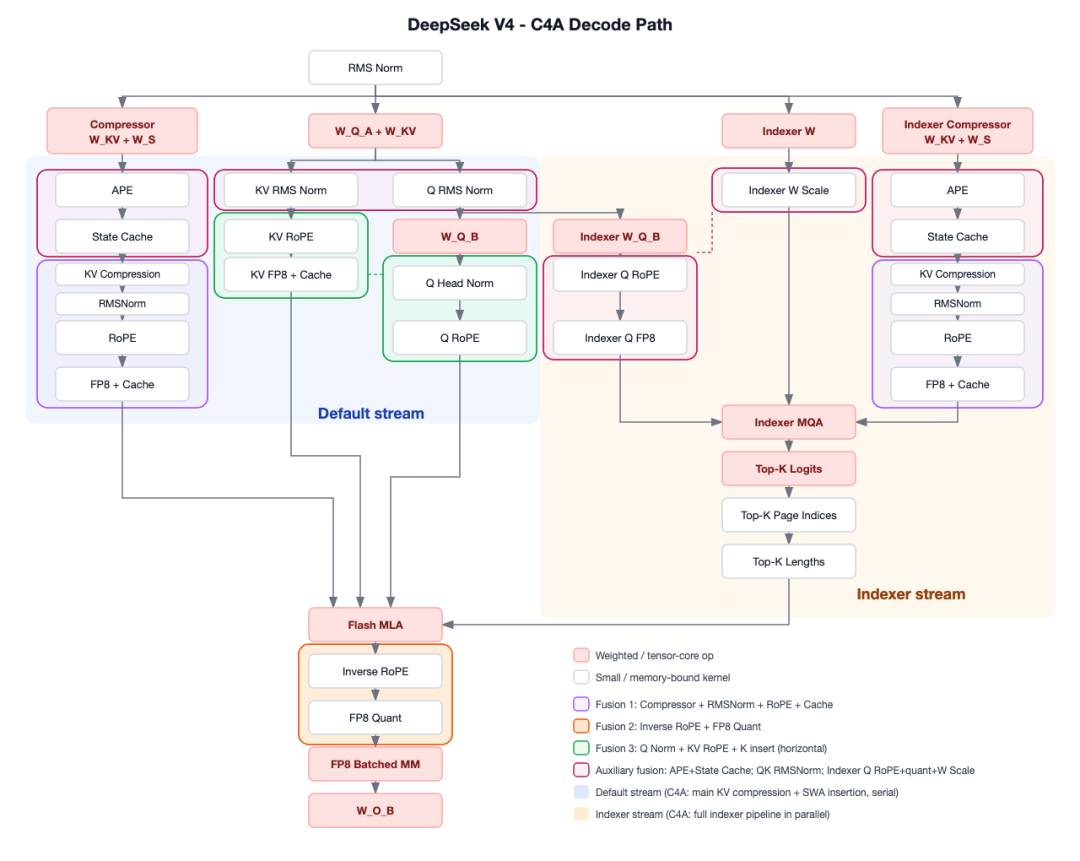
因为每一层都不一样,要维护一个 sliding window,要压缩,这给实现带来了一定挑战。其复杂度可以从第二图中直观体会(更多的实现复杂度可以参考 SGLang 和 vLLM 的博客,见参考资料)。但这个工程的复杂度看起来是有意义的,也可以很好地适应国产芯片,比如说昇腾就得到了很好的支持。


Attention 改造是当前硬件限制条件下实现长上下文的关键改造。正如我们开篇所说的,这个改造在各种评测中都体现出了极大的质量。后续我们可以预期,它会经过更多的训练和进一步架构上的雕琢,展现出更好的实力。经过 3-6 个月,它有望追上 Opus 4.6 Max 的长上下文处理能力以及 Agent Coding 的能力。
FFN 层的改造
DeepSeek V4 和 V3.2 对比起来,其针对 FFN 层的改造是有限的。核心改造主要有两点:
-
前三层的 Dense 层改成了统一的 MoE
-
后续的 MoE 门路由函数发生了变化
第一个改造,其门函数使用的是 Hash。使用 Hash 相当于预先对 Vocabulary 里面的 Token 进行了分组。每一次固定的 Token 进来以后,都会路由到固定的专家上,以此来降低在超大规模网络的情况下,对于前三层 FFN 一定程度上的计算浪费。
第二个改造,是关于 MoE 的门函数发生了变化,这里可以引用一下 zartbot 的分析:
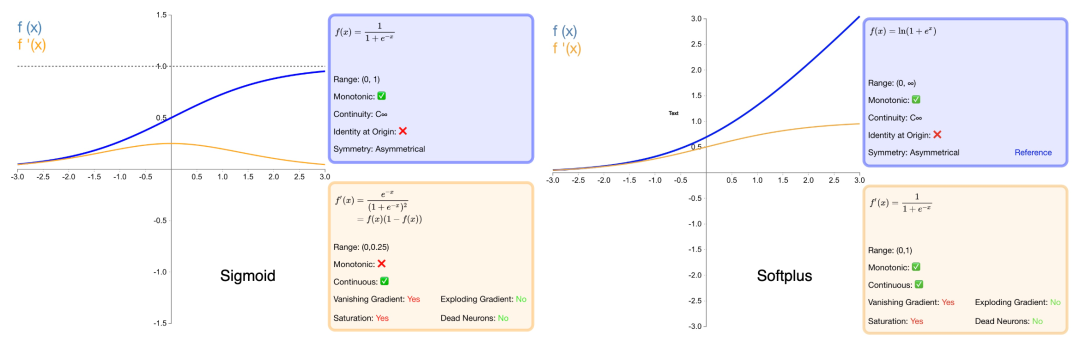
在值的输出范围上,Sigmoid在 区间有上界,而 Softplus 为 当某个专家确实非常匹配时, Sqrt(Softplus) 能给出更高的分数, 区分度更好。然后通过采用 Sqrt 压缩, 防止分数差异过大导致路由权重过于集中在单一专家。另外我们还可以注意到在DeepSeek开源的Tilelang Kernel中, 还设计了一个阈值(20)避免 Softplus 过大。
另一方面我们来看它的导数:
-
对于 Sigmoid,当路由网络输出一个大的正值(表示对某个专家有强烈的偏好)时,导数趋近于 0,梯度会饱和, 导致无法进一步增强这种偏好, 也无法在需要时减弱这种偏好。
-
对于 Sqrt(Softplus),当输入 x 很大时,梯度永远不会变为0。这意味着即使路由器已经对某个专家产生了极强的亲和度,它仍然能接收到有效的梯度信号来进行微调,这使得路由策略更加稳定。
mHC 的引入
在 DeepSeek 之前,我们能看到的所有开源模型核心所使用的还是残差网络。正如前面所说,残差网络的核心作用是让训练更稳定,但传统残差流(Residual Stream)因为只有一个流,所引入的信息有限,而字节提出的HC 虽然拓宽了信息流,但引入了一个深层网络有可能会爆炸的缺点。
参考下图完整的代数推导过程:

传统的残差网络实际是恒等变换,不管网络叠多少层,这条直接通路的矩阵相乘结果永远是单位矩阵,信号强度始终稳定在 1 倍,不会被放大或缩小,训练很安全。
但 HC 的层间的代数表达如下:
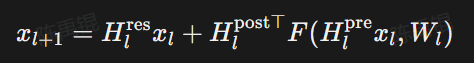
多层堆叠后:
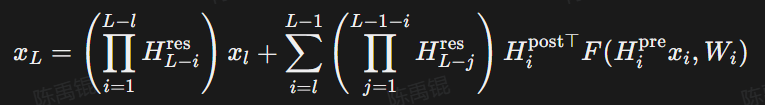
等式右侧第一项里左乘矩阵:
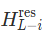
是无约束的可学习矩阵,当网络层数很深时,非单位矩阵的连乘的结果会失控,导致训练的时候爆掉。
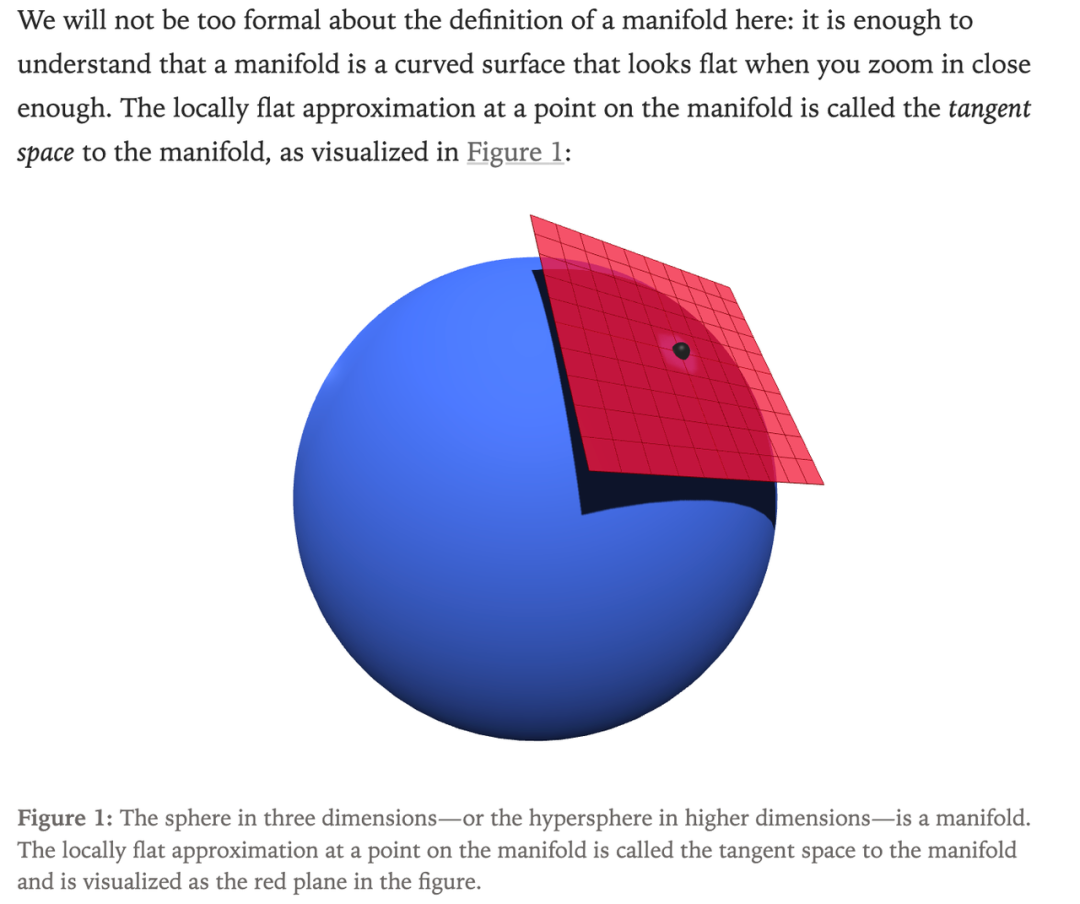
DeepSeek V4 引入的 mHC 实际上是增加了对 HC 这个缺点的限制:传统 HC 直接用无约束矩阵去做变换,相当于强行在整个球面上做线性映射,很容易扭曲、放大信号,导致爆炸。mHC 的思路,是把高维的非线性流形,在局部近似成一个"平面"------ 就像地球是个球体,但我们生活的局部看起来是平面一样。它通过给
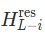
加上正交 / 半正交约束,让矩阵成为保范数变换(类似单位矩阵的稳定特性),限制多层矩阵连乘时的信号增益,既保留了多流混合的信息容量,又保证了深层网络训练的稳定性。
实际的实现本质上就是一个双随机矩阵的乘法,通过一定的计算复杂度,引入了更稳定的训练和更强大的网络。对于这个算法感兴趣的读者,可以参考文末的参考文档一些详细解读。
其他的改造以及工程优化
当然,以上主要是提到了一些核心结构上的改造。为了训练这么一个网络,DeepSeek V4 还做了很多其他的优化工作。
- 引入了通过 Kimi 验证过的 Muon 优化器,通过搭配 AdamW 来进行整个网络的训练。
如何理解训练?文档本身经过向量化以后,是一个函数分布。训练的目的,是为了拟合这个分布。而优化器的目的,是为了让我们在归纳这个数据分布的过程中,前进得更平滑。但是 AdamW 的计算量比较大,因为它既要去寻找一阶矩,还要去计算二阶矩,同时它占用的空间也非常大。Muon 就是为了优化它的这两个问题,让训练更高效。
-
Indexer 引入了一个 FP4,使用了最新的硬件提供的FP4 的支持。正如我们前面硬件章节所讲到的:FP4 的算力更高。它的表示方式更精简,可以让存储空间变得更小。
-
引入 Attention sink, 使得注意力分数不一定等于 1,甚至可以接近 0。
具体来说,在标准的注意力机制中,经过 Softmax 归一化后,注意力分数的总和强制为 1。这意味着模型必须输出一个概率分布,将 100% 的"注意力"分配给所有可见的 tokens(包括无关的、冗余的或是需要压缩的块)。加入这个可学习的 sink logit 后,当模型在处理某个 token 时,如果觉得上下文中的信息都无关紧要,它能让无关 tokens 的权重迅速衰减,甚至趋近于 0。从而避免模型被迫将注意力强制分配给某些确实无关紧要的初始 token(如 <sos>),让模型忽略掉无用的信息,只保留真正有用的信息。
-
训练和推理过程的 Batch 不变性,以及增强学习过程中训练和推理的R3的遵循。
-
引入 OPD,实现了高性能的 microVM 和 fullVM,让增强学习的环境准备变得更高效。
什么是OPD:We can use a mechanism called distillation: training the student to match the output distribution of a teacher model. We train on teacher trajectories: the complete sequence of generated tokens including intermediate thinking steps. We can use the teacher's full next-token distribution at each step (often called "logit distillation") or just sample given sequences. In practice, sampling sequences provides an unbiased estimation of the teacher's distribution and arrives at the same objective. The student updates towards each token in the sequence in proportion to how unlikely it was to generate that token itself, represented by darker color in the example below:

对 OPD 的简单理解就是:我们先训练出一个小的、只对单科很厉害的"小老师",然后对这个大的模型在训练过程中,完全按照这个"小老师"输出的概率分布来吸收他的知识。
-
为了适配国产芯片,和北大一起合作实现了 Tilelang 这样的 DSL,来完成 Kernel 的开发,从而跳出传统的 C++ CUDA 或者 Triton 的开发框架,开发了 MegaMoE 这样高性能的 kernel。
-
引入 GRM 来实现对于代码这种易于验证之外的场景(比如说人类语言写作)中,那些没有明确规则、难以验证的场景的训练,以此提高模型的效果。
-
多模态能力也是值得关注的一块。在我们写这篇文章的时候,DeepSeek 已经上线了一个识图的能力。

还有很多值得关注的细节,有待我们去发掘。
总结
DeepSeek V4 从架构到训练方法都做了大量改进,在当前硬件的限制条件下,为未来 Agent 的场景提供了它所需要的长程任务执行的能力基础。我们可以畅想 DeepSeek V4 的后续版本会通过更多的实验,将这一版架构中还不够完美的地方进一步完善。
未来,基于这个架构已呈现出的原生能力的基础上,如果我们给它一些更高质量的数据,让它学到更多世界知识的同时,补充更高强度的强化学习过程,一定会展现出更强的能力。就像论文结尾所说的,有了这个架构,我们甚至有可能做到 online learning(在线学习),从而实现模型本身的进化。
当模型的能力更强,能够解决更长时长,更复杂的工作时,我们非常期待用它来真正做到对人力的解放,让人去发挥更高的创造性,探索更多未知和可能。
参考资料:
https://arxiv.org/pdf/1706.03762
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
https://www.aleksagordic.com/blog/matmul
https://arxiv.org/pdf/2603.12201
https://www.lmsys.org/blog/2026-04-10-sglang-hisparse/
https://vllm.ai/blog/deepseek-v4
https://www.lmsys.org/blog/2026-04-25-deepseek-v4
https://mp.weixin.qq.com/s/F-0_bbwvQjlYaHVFW_uPNw