
1. 引言
在传统并发模型里,"池化"几乎是一种政治正确。但在 Java 虚拟线程(Project Loom)与 Go goroutine 时代,线程池/协程池的意义,正在迅速下降。
很多开发者在使用虚拟线程、goroutine 时,仍然下意识地:
- 搞一个固定大小线程池
- 搞一个 goroutine worker pool
- 配队列
- 配拒绝策略
- 配各种并发参数
但问题是:
这些东西,真的是必须的吗?
或者说:
我们是不是正在用旧时代的思维,限制新时代的并发模型?
这篇文章,我们就从 Java 与 Go 两种主要语言出发,其他的语言顺带一提,聊聊:
- 为什么传统线程池是必要的?
- 为什么虚拟线程/协程改变了基础假设?
- 为什么"池化思维"开始逐渐变成一种过度设计?
- 什么场景下仍然需要 pool?
2. 传统线程池为什么存在
先说结论:线程池并不是为了"高级",而是因为 OS 线程太贵了。
OS 线程是重量级资源
传统 Java Thread 本质上对应:
- Linux pthread
- Windows thread
每个线程都需要:
- 独立栈空间
- 内核调度
- 上下文切换
- 系统资源分配
例如:
java
new Thread(() -> {
doTask();
}).start();这段代码背后其实代价并不低。
线程创建成本很高
传统线程:
- 创建慢
- 销毁慢
- 内存占用大
- 切换成本高
如果你疯狂创建线程:
java
for (int i = 0; i < 100000; i++) {
new Thread(task).start();
}系统大概率直接崩。
因为:
- 内存扛不住
- 调度器扛不住
- 上下文切换爆炸
所以线程池诞生了
线程池的核心目标其实就两个:
复用线程
避免反复创建/销毁线程。
限制并发数量
例如:
java
ExecutorService pool = Executors.newFixedThreadPool(200);本质上是在说:系统最多同时运行 200 个线程。这是传统并发模型下非常合理的设计。
因为:线程是昂贵资源。
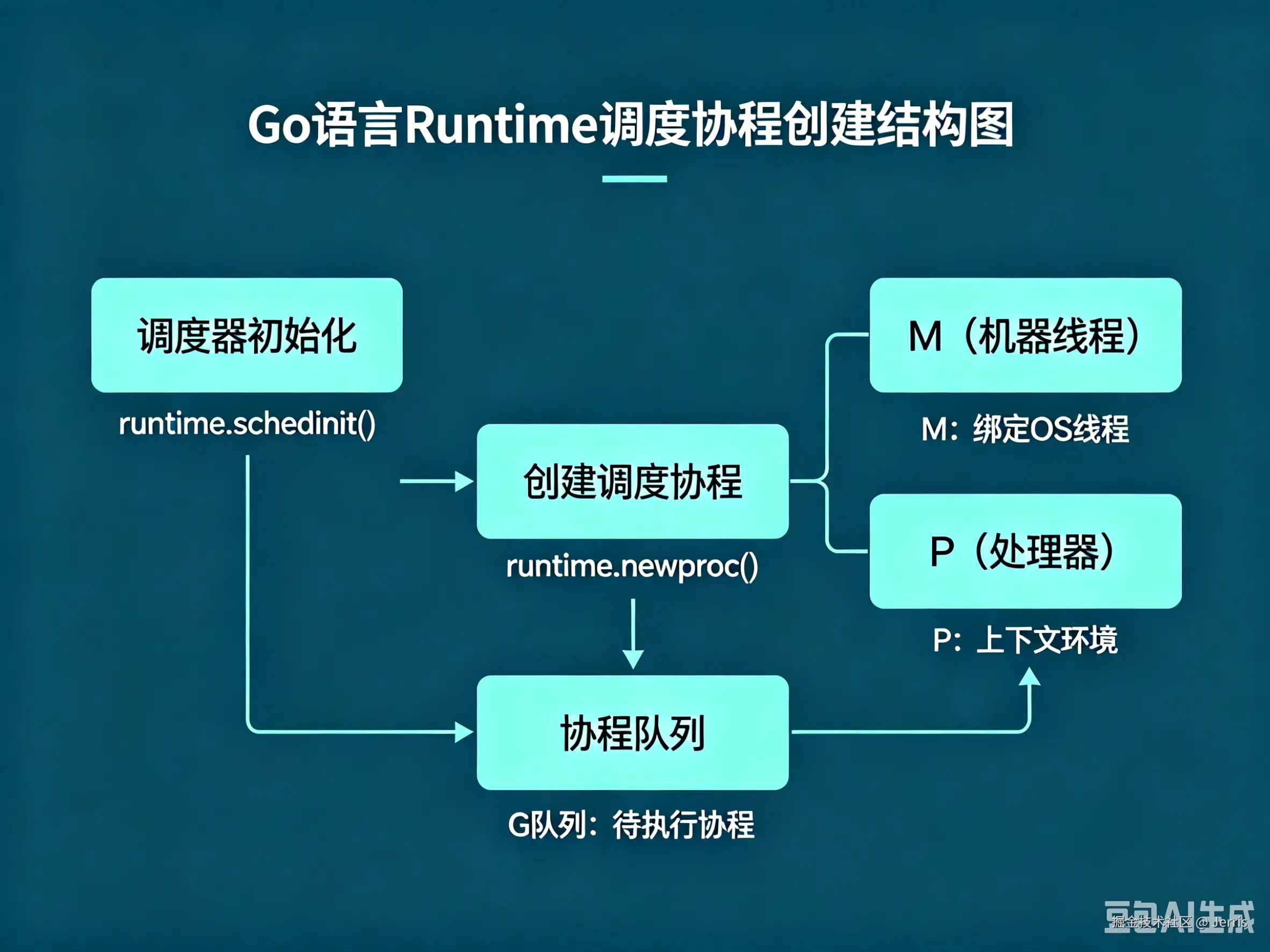
3. Go 协程模型已经"内建调度"
Go 为什么很少强调"协程池"
Go 是一个非常有意思的对照组。因为 Go 从诞生开始,就默认:"不要把 goroutine 当线程。"
goroutine到底轻在哪里?
Go runtime 做了很多事情:
- M:N 调度模型
- 用户态调度
- 动态栈扩容
- work-stealing
- goroutine 挂起恢复
go
go func() {
task()
}()goroutine 创建成本极低。goroutine 初始栈甚至只有 2KB 大小。
Go runtime 已经"内建线程池"
很多人没意识到:Go runtime 本身已经是一个超级调度器。
它内部已经在做:
- goroutine 调度
- OS线程复用
- 阻塞管理
- 负载均衡
也就是说:
txt
goroutine
↓
Go Scheduler
↓
OS Thread那为什么很多人还喜欢写 goroutine pool?
经典代码:
go
jobs := make(chan Task)
for i := 0; i < 10; i++ {
go worker(jobs)
}
这类代码本质上:
- 限制 goroutine 数量
- 使用 channel 排队
- 人工做调度
问题在于:你正在用户层重复实现 runtime 的调度逻辑。
4. Java 虚拟线程彻底改变游戏规则
如果说 Go 是从一开始就设计了协程模型。那么:Java Loom 则是在 JVM 世界里,重新定义了 Thread。
虚拟线程到底是什么?
Java 21:
java
Thread.startVirtualThread(() -> {
handleRequest();
});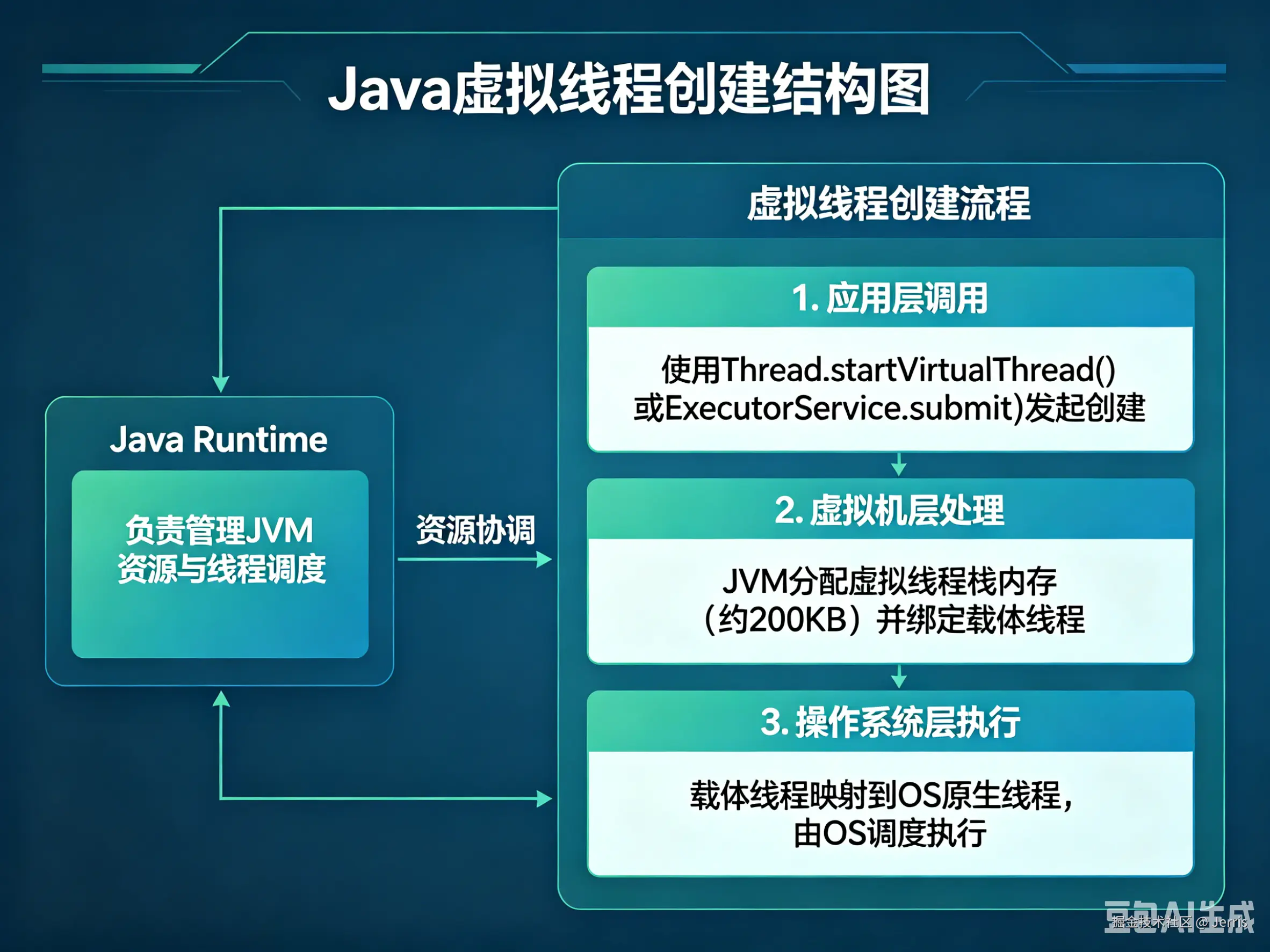
这里的 Thread:
- 不再直接绑定 OS Thread
- 不再是重量级对象
- 阻塞时可以挂起
- 挂起时释放 carrier thread
也就是说:"阻塞"不再意味着浪费线程。
传统线程池为什么突然开始尴尬?
以前:
txt
请求 → 线程池 → Worker Thread是合理的,因为线程很贵。
但现在:
txt
请求 → Virtual Thread本身已经很轻量。
你再搞:
txt
请求 → 队列 → 虚拟线程池 → 调度就会开始出现一个问题:你到底在池化什么?
池化思维开始失效的核心原因
你在限制一个已经不昂贵的东西
传统逻辑:
txt
线程昂贵 → 必须复用现在:
txt
虚拟线程 / goroutine 很便宜那 pool 的意义自然开始下降。
Pool 会引入额外排队
线程池最大的问题其实不是线程。
而是:队列。
例如:
java
new ThreadPoolExecutor(
100,
100,
0,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>()
);请求会:
txt
任务
↓
队列等待
↓
worker执行问题:
- 排队增加延迟
- head-of-line blocking
- 请求堆积
而虚拟线程本来可以:
txt
请求直接运行Pool 增加了大量复杂度
传统线程池需要:
corePoolSizemaxPoolSizequeueSizerejectPolicy
你需要:
- 调参
- 压测
- 分析阻塞
- 看队列积压
而虚拟线程很多时候:
java
Executors.newVirtualThreadPerTaskExecutor();就够了。
你在重复实现调度器
这一点最关键。
Go runtime:
- 已经会调度 goroutine
JVM Loom:
- 已经会调度 virtual thread
而你:
- 又加一层 pool
- 又加一层 queue
- 又加一层 worker
这就变成:
txt
用户层调度器
↓
runtime调度器
↓
OS调度器系统开始出现:
- 双重排队
- 双重调度
- 双重限流
官方的解释
我在 Oracle 的官方网站到了一段关于虚拟线程不要池化的说明:
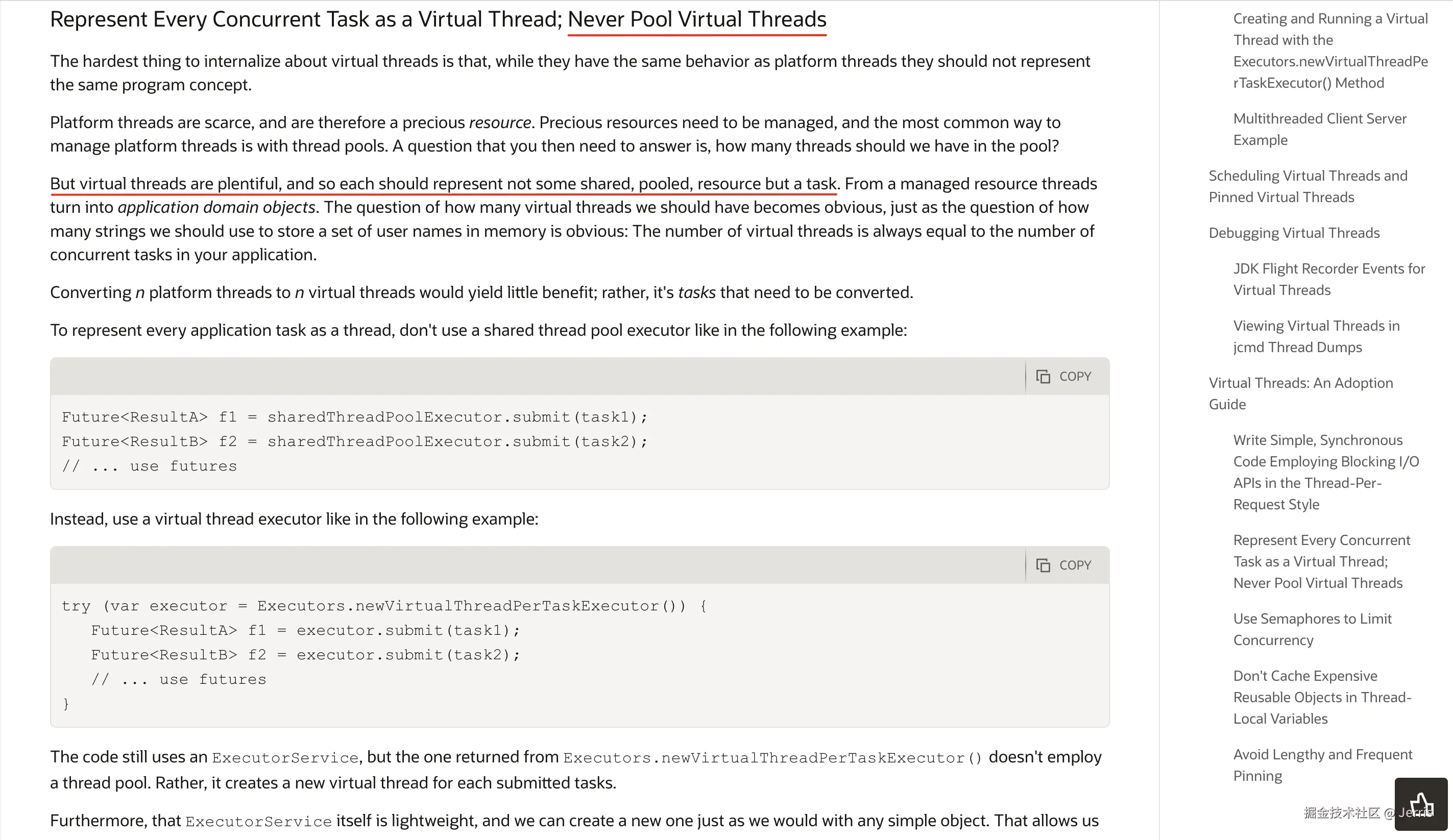
简单说就是虚拟线程数量众多,因此每个线程都不应代表某种共享的、池化的资源,而应代表一个任务(用完就扔)。
5. Python、Kotlin、Rust、C++的方案
Python:解释器驱动的协程
Python 的协程本质:
py
async def foo():
await bar()背后是:
- 生成器(Generator)演化而来
yield->yield from->await- 运行时事件循环调度
Python 协程不是操作系统线程。它本质是:"可暂停的函数对象"。
但是它非常轻量:
- 没有线程切换
- 没有系统调用
- 没有线程栈
Kotlin:真正工业级协程体系
Kotlin 协程是目前 JVM 世界最完整的方案之一。
核心:
kt
suspend fun foo()它不是线程。编译器会把 suspend 函数:编译成状态机(State Machine)。
Kotlin 协程底层:
例如:
kt
suspend fun test() {
delay(1000)
println("hello")
}编译后类似:
java
switch(state) {
case 0:
delay()
state = 1
return COROUTINE_SUSPENDED
case 1:
println("hello")
}这和 Rust 很像。
Rust:零成本协程
Rust 的 async 是目前最"硬核"的方案之一。
核心:
rs
async fn foo()编译后:
- 不是运行时对象
- 而是一个状态机类型
Rust async 本质:
rs
async fn foo()编译后类似:
rs
enum FooFuture {
State1,
State2,
Done,
}然后实现:
rs
Future trait核心:
rs
poll()C++ 20:Coroutine
编译器生成:
- coroutine frame
- 状态机
和:
- Kotlin
- Rust
越来越像。
下面是一个非常简单的 C++20 coroutine 示例。
这个例子演示:
co_await- coroutine 的暂停与恢复
- 手动
resume()
cpp
#include <coroutine>
#include <iostream>
struct Task {
struct promise_type {
Task get_return_object() {
return Task{
std::coroutine_handle<promise_type>::from_promise(*this)
};
}
std::suspend_always initial_suspend() {
return {};
}
std::suspend_always final_suspend() noexcept {
return {};
}
void return_void() {}
void unhandled_exception() {
std::exit(1);
}
};
std::coroutine_handle<promise_type> handle;
explicit Task(std::coroutine_handle<promise_type> h)
: handle(h) {}
~Task() {
if (handle) {
handle.destroy();
}
}
void resume() {
handle.resume();
}
};
Task helloCoroutine() {
std::cout << "1. coroutine start\n";
co_await std::suspend_always{};
std::cout << "2. coroutine resume\n";
}
int main() {
auto task = helloCoroutine();
std::cout << "main: before resume\n";
task.resume();
std::cout << "main: after resume\n";
return 0;
}运行结果:
txt
main: before resume
1. coroutine start
main: after resume6. 虚拟线程时代,Pool 的角色正在变化
以前:
txt
Pool = 线程复用工具现在:
txt
Pool = 资源保护工具这是本质变化。
什么时候仍然需要 Pool?
CPU 密集型任务
例如:
- 图像处理
- 编码压缩
- AI推理
- 大规模计算
CPU 核数仍然有限。
这里限制并发仍然有意义。
外部资源保护
例如:
- MySQL
- Redis
- Kafka
- 第三方支付接口
这些系统都有容量上限。
限流与熔断
很多 pool 本质上:不是线程池。
而是:
txt
背压系统7. 客观评价
线程池不会彻底消失,但它的定位正在发生根本变化。
传统时代:
txt
线程很贵
↓
必须池化现在:
txt
虚拟线程 / goroutine 很便宜
↓
池化不再天然正确未来:Pool 更像"资源护栏",而不是"并发核心"。
所以真正应该淘汰的:
不是线程池,而是"线程昂贵,所以必须池化"的旧时代思维。