3-4 inode和数据块的映射
• inode内部存在 __le32 i_blockEXT2_N_BLOCKS;/* Pointers to blocks */ , EXT2_N_BLOCKS =15,就是用来进行inode和block映射的
• 这样文件=内容+属性,就都能找到了。
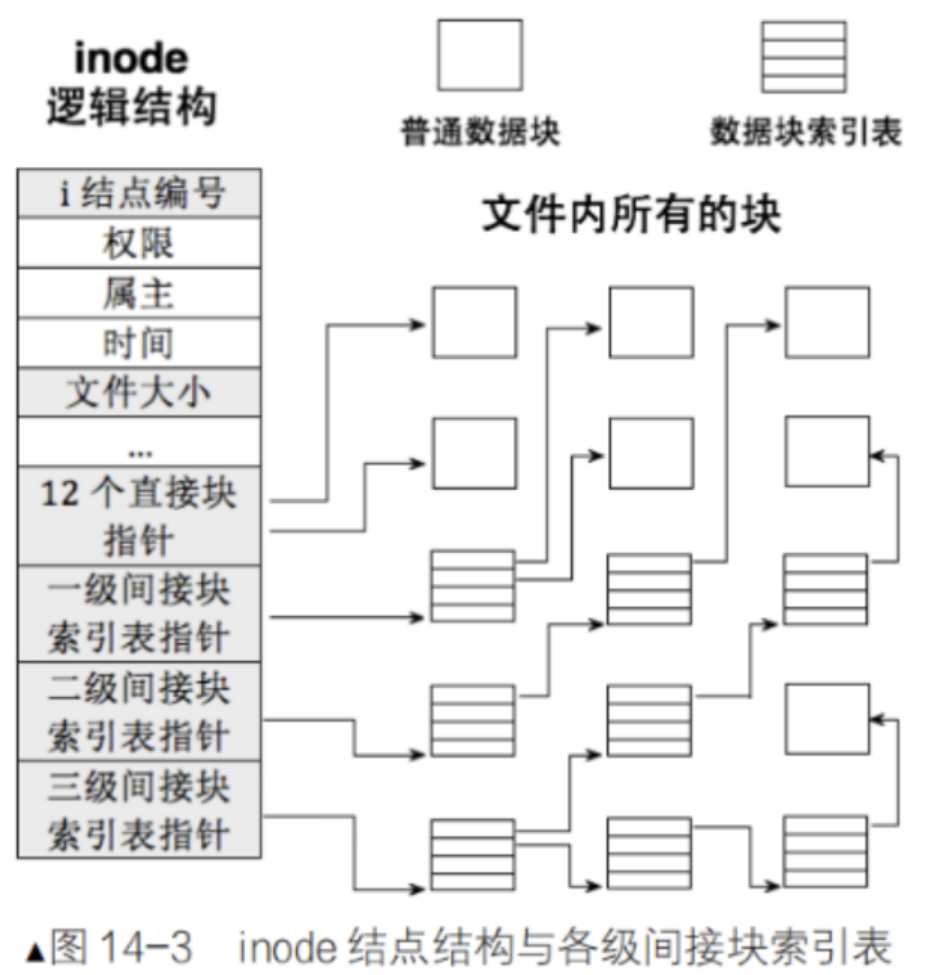
前面我们知道inode里有个 i_block[15] 数组,它就是inode找到数据块的"地图"。
15个指针的分工
i_block[0] ~ i_block[11] → 12个直接块指针,直接指向数据块
i_block[12] → 一级间接块指针
i_block[13] → 二级间接块指针
i_block[14] → 三级间接块指针直接块指针(小文件够用)
inode
└── i_block[0] ──→ 数据块A
i_block[1] ──→ 数据块B
i_block[2] ──→ 数据块C
...
i_block[11] ──→ 数据块L12个直接指针 → 管理 12 × 4KB = 48KB 的文件。小于48KB的文件只用直接块就够了。
一级间接块指针(中等文件)
当文件超过48KB时,用到 i_block[12]:
inode
└── i_block[12] ──→ 间接块(这个块里不存数据,存的是块号列表)
┌──────────────────────────────┐
│ 块号1 │ 块号2 │ 块号3 │ ... │ 一个块4KB,每个块号4字节
└───┬───┴───┬───┴───┬───┴─────┘ 所以能存 4096÷4 = 1024个块号
↓ ↓ ↓
数据块 数据块 数据块一级间接能管:1024 × 4KB = 4MB
二级间接块指针(大文件)
inode
└── i_block[13] ──→ 二级间接块
├── 块号1 ──→ 索引块 ──→ 1024个数据块
├── 块号2 ──→ 索引块 ──→ 1024个数据块
└── ...二级间接能管:1024 × 1024 × 4KB = 4GB
三级间接块指针(超大文件)
同理再套一层:1024 × 1024 × 1024 × 4KB = 4TB
汇总
| 级别 | 能管理的大小 |
|---|---|
| 12个直接块 | 48KB |
| + 一级间接 | 48KB + 4MB ≈ 4MB |
| + 二级间接 | + 4GB ≈ 4GB |
| + 三级间接 | + 4TB ≈ 4TB |
设计思想 :小文件走直接块,速度最快(一次磁盘IO就拿到数据)。大文件才需要间接块,多几次IO但能支持大文件。这是时间和空间的平衡。
面试可能问:ext2怎么用inode找到文件数据?→ 先走直接块,不够走一级间接,再不够走二级、三级,层层递进。
思考: 假设你知道一个文件的inode号 ,在指定分区内,对文件的四种操作本质上在做什么:
查(读取文件)
1. 根据inode号 → 定位到哪个块组 → 在inode表中找到inode结构
2. 从inode中读取文件属性(大小、权限、时间等)
3. 从inode的 i_block[15] 中拿到数据块编号
4. 根据块编号读取数据块,拿到文件内容核心就一句话:inode号 → inode → 数据块 → 内容。
改(修改文件内容)
分两种情况:
修改已有内容(不增加大小):
1. 根据inode号找到inode
2. 从i_block拿到数据块编号
3. 直接修改对应数据块中的内容
4. 更新inode中的 i_mtime(修改时间)追加内容(文件变大):
1. 根据inode号找到inode
2. 在块位图中找空闲的数据块
3. 把新数据写入空闲块
4. 把新块编号填入inode的i_block中
5. 更新inode的 i_size(文件大小)
6. 更新inode的 i_mtime
7. 更新块位图(标记新块为已占用)增(创建新文件)
1. 在inode位图中找一个空闲inode → 分配inode号
2. 在块位图中找空闲数据块 → 分配块号
3. 把文件属性写入inode(权限、大小=0、时间等)
4. 在当前目录的数据块中添加一条记录:(inode号, 文件名)
5. 更新inode位图(标记新inode为已使用)
6. 更新块位图(标记新块为已使用)
7. 更新目录inode的 i_size(目录变大了)注意第4步:创建文件本质上是在目录的数据块里加一条映射记录。
删(删除文件)
1. 根据inode号找到inode
2. 在目录的数据块中,删除 (inode号, 文件名) 这条记录
3. 将inode的 i_links_count(硬链接数)减1
4. 如果硬链接数减到0:
a. 在inode位图中释放该inode(标记为空闲)
b. 在块位图中释放该文件的所有数据块(标记为空闲)
c. 文件真正被删除
5. 如果硬链接数不为0 → 文件还在,只是少了一个名字这就是为什么删除文件只是"取消链接" :删的是目录里的映射记录,不是直接擦除数据。硬链接数归零后数据块才被释放。所以数据恢复软件能找回刚删的文件,因为数据块里的内容还没被覆盖。
总结一张图
增 删 查 改
│ │ │ │
┌────┴────┐ ┌────┴────┐ ┌────┴────┐ ┌────┴────┐
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
分配inode 分配数据块 删目录记录 释放inode 找inode 读数据块 找inode 写数据块
写属性 写数据 链接数-1 释放数据块 读属性 拿内容 改属性 改内容
加目录记录 更新位图 链接数=0? 更新位图 读i_block 更新i_block
更新位图 释放所有操作都围绕三样东西转 :inode位图 (分配/释放inode)、块位图 (分配/释放数据块)、目录数据块(维护文件名↔inode的映射)。
这就是文件系统的工作本质:管理位图 + 维护映射 + 读写数据块。
结论:
• 分区之后的格式化操作,就是对分区进行分组,在每个分组中写入SB、GDT、Block Bitmap、Inode Bitmap等管理信息,这些管理信息统称: 文件系统
• 只要知道文件的inode号,就能在指定分区中确定是哪一个分组,进而在哪一个分组确定 是哪一个inode
• 拿到inode文件属性和内容就全部都有了
3-5 目录与文件名
核心问题
我们平时访问文件都用文件名,从来没用过inode号。那文件名到底存在哪?
答案:文件名存在目录的数据块里,不在inode里。
目录也是文件
磁盘上没有"目录"这个东西,只有文件。目录也是文件,它的属性存在inode里,它的内容存在数据块里。
目录的数据块里存的是什么?------ 文件名到inode号的映射表:
目录的数据块内容:
┌──────────┬──────────┐
│ inode号 │ 文件名 │
├──────────┼──────────┤
│ 263136 │ . │ ← 当前目录自己
│ 263488 │ .. │ ← 上级目录
│ 263563 │ abc │
│ 263563 │ def │ ← 和abc同一个inode(硬链接)
│ 261678 │ abc.s │
└──────────┴──────────┘这就解释了为什么文件名不在inode里:
- 文件名不是文件本身的属性,而是目录对文件的引用
- 同一个文件可以有多个文件名(硬链接),如果文件名在inode里就无法实现
- 文件名属于目录,不属于文件本身
那访问文件的流程是什么?
你想访问 test.c
↓
1. 打开当前目录(当前目录也是文件,也有inode和数据块)
↓
2. 读取当前目录的数据块,找到 "test.c" 对应的inode号
↓
3. 根据inode号找到inode,拿到属性和数据块指针
↓
4. 读取数据块,拿到文件内容关键结论 :访问文件必须要有目录 + 文件名 = 路径。没有路径就找不到文件。
用代码验证
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <dirent.h>
#include <sys/types.h>
#include <unistd.h>
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "Usage: %s <directory>\n", argv[0]);
exit(EXIT_FAILURE);
}
DIR *dir = opendir(argv[1]); // 打开目录
if (!dir) {
perror("opendir");
exit(EXIT_FAILURE);
}
struct dirent *entry;
while ((entry = readdir(dir)) != NULL) { // 逐个读取目录项
if (strcmp(entry->d_name, ".") == 0 || strcmp(entry->d_name, "..") == 0) {
continue;
}
printf("Filename: %s, Inode: %lu\n", entry->d_name, (unsigned long)entry->d_ino);
}
closedir(dir);
return 0;
}运行 ./readdir / 就能看到根目录下所有文件名和对应的inode号。每个 struct dirent 里就有 d_ino(inode号)和 d_name(文件名),这就是目录数据块里的内容。
3-6 路径解析
问题
上一节说"访问文件必须有路径",那路径是怎么解析的?
比如你要访问:
/home/whb/code/test/test.c解析过程
你不能直接就找到 test.c,必须从根目录开始,一层一层往下找:
步骤1: 打开 "/"(根目录)
根目录的inode号是固定的,开机就知道,不需要查找
读取根目录的数据块,找到 "home" 对应的inode号
步骤2: 打开 "/home"
用home的inode号找到它的数据块
读取数据块,找到 "whb" 对应的inode号
步骤3: 打开 "/home/whb"
用whb的inode号找到它的数据块
读取数据块,找到 "code" 对应的inode号
步骤4: 打开 "/home/whb/code"
找到 "test" 的inode号
步骤5: 打开 "/home/whb/code/test"
找到 "test.c" 的inode号
步骤6: 拿到test.c的inode,访问完成这就是路径解析:从根目录开始,逐级解析路径中的每一层目录,每次都是一次"在目录数据块里查找文件名→拿inode号"的过程。
几个重要细节
1. 为什么需要根目录?
路径解析的"出口"就是根目录 /。根目录的inode号是固定的(通常是2),系统开机就知道,不需要查找。所以解析路径总是从根目录开始,这是起点。
根目录inode号固定为2
/ 的数据块内容:
┌──────────┬──────────┐
│ 2 │ . │ ← 根目录自己
│ 2 │ .. │ ← 上级还是自己
│ 262145 │ etc │
│ 786433 │ home │
│ 131073 │ dev │
│ ... │ ... │
└──────────┴──────────┘2. 路径是谁提供的?
进程提供的。进程有自己的当前工作目录(CWD) ,存在进程的 fs_struct 里。你用相对路径时,就是从CWD开始解析;用绝对路径时,从根目录开始解析。
3. 为什么要路径才能访问文件?
因为文件名在目录的数据块里,你必须先打开目录才能知道文件名对应哪个inode。目录也是文件,要打开目录就得打开它的上级目录......层层递归,最终出口就是根目录。
4. Linux为什么要有那些默认目录?
因为路径解析需要目录结构。系统和用户在磁盘上创建目录文件,就是在构建路径树。/home、/etc、/usr 这些目录都是在格式化或安装系统时创建的,天然就形成了路径结构。
3-7 路径缓存
问题
每次访问文件都要从根目录开始逐级解析,这也太慢了吧?
比如你连续访问:
/home/whb/a.txt
/home/whb/b.txt
/home/whb/c.txt难道每次都解析 / → home → whb?前两级完全一样,重复解析浪费。
解决方案:dentry缓存
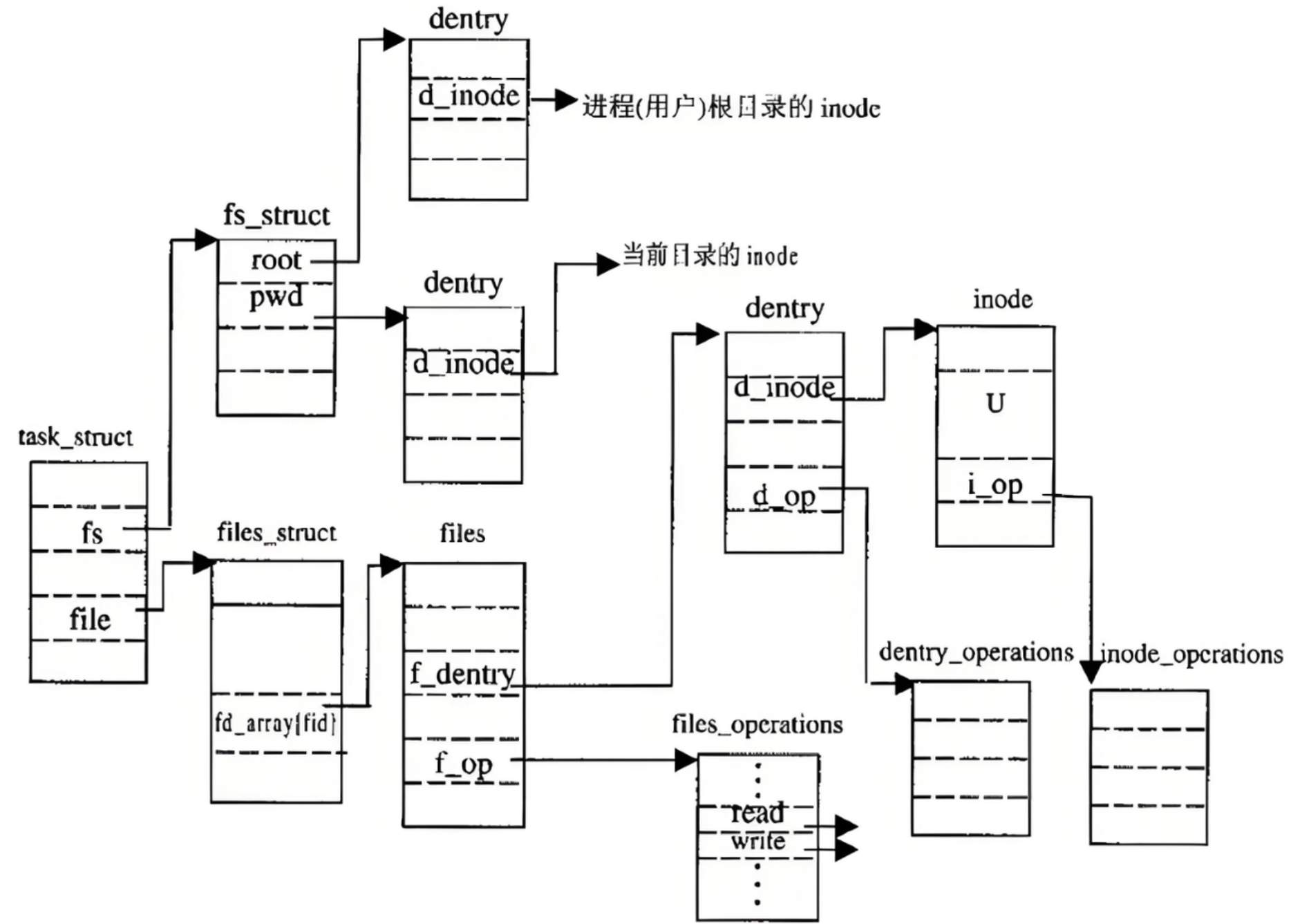
Linux在内存中维护了一棵路径树 ,用 struct dentry 结构体表示:
struct dentry {
struct inode *d_inode; // 这个目录项对应的inode
struct dentry *d_parent; // 父目录
struct qstr d_name; // 文件名
struct list_head d_subdirs; // 子目录列表
struct hlist_node d_hash; // 哈希表节点,加速查找
struct list_head d_lru; // LRU链表,用于淘汰
// ...
};dentry树长什么样
内存中的dentry树:
dentry("/")
│
┌─────┼─────┐─────────┐
↓ ↓ ↓ ↓
dentry dentry dentry dentry
("home") ("etc") ("dev") ("usr")
│
↓
dentry("whb")
│
┌──┴──┐
↓ ↓
dentry dentry
("a.txt")("b.txt")每个被打开过的文件和目录 都会有一个dentry节点在内存中。所有节点连成一棵树,就是Linux的目录树缓存。
dentry的三个重要归属
1. 树形结构 ------ 组成路径树,方便路径解析
2. 哈希表 ------ d_hash 字段,把dentry放进哈希表,查找时直接根据路径名哈希定位,不用遍历树,O(1)查找
3. LRU链表 ------ d_lru 字段,内存有限,不可能缓存所有路径。最近最少使用的dentry会被淘汰掉,腾出内存
路径解析时怎么用缓存?
你要访问 /home/whb/a.txt
↓
1. 先在dentry缓存树中查找整个路径
↓
2. 如果找到了(缓存命中)→ 直接拿到inode,跳过磁盘读取,极快
↓
3. 如果没找到(缓存未命中)→ 从根目录开始逐级解析,每解析一级
就在缓存中添加一个新的dentry节点,下次就不用再解析了举个例子:
第一次访问 /home/whb/a.txt:
缓存为空,从根目录解析到底
解析过程中,"home"、"whb"、"a.txt" 的dentry都被加入缓存
第二次访问 /home/whb/b.txt:
"home" 和 "whb" 的dentry已经在缓存中,命中!
只需要解析最后一级 "b.txt",读一次目录数据块就够了关键细节
- dentry缓存在内存中,不在磁盘上。系统重启就没了,重新构建
- 不是所有文件都有dentry,只有被访问过的才会缓存
- dentry和inode是多对一关系:多个dentry可以指向同一个inode(硬链接就是多个文件名对应一个inode)
总结
进程调用 open("/home/whb/a.txt")
↓
1. 路径解析(先查dentry缓存,没命中就从磁盘逐级解析)
"/" → "home" → "whb" → "a.txt"
每一级:目录数据块中找文件名 → 拿到inode号
↓
2. 最终拿到 a.txt 的 inode
↓
3. inode中有 i_block[15],指向数据块
↓
4. 读取数据块,拿到文件内容整个ext2文件系统的核心就是这条链路:路径 → 目录 → inode → 数据块。
3-8 挂载分区
问题
前面说inode号不跨分区 ,块号也不跨分区。那Linux可以有多个分区,我怎么知道我在访问哪个分区?
比如你有两个分区,分区1有inode号263466,分区2也有inode号263466,同一个inode号指向不同文件。路径解析的时候怎么区分?
解决方案:挂载
分区格式化写入文件系统后,不能直接使用,必须"挂载"到一个目录上才能用。
挂载就是把分区和目录关联起来。挂载之后,访问这个目录就等于访问那个分区。
实验过程
# 第1步:创建一个5MB的空文件,模拟一个磁盘分区
$ dd if=/dev/zero of=./disk.img bs=1M count=5
# 第2步:格式化为ext4文件系统(写入SB、GDT、位图等管理信息)
$ mkfs.ext4 disk.img
# 第3步:创建一个空目录,作为挂载点
$ mkdir /mnt/mydisk
# 第4步:查看当前已挂载的分区(还没有disk.img)
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 50G 20G 28G 42% /
...
# 第5步:挂载
$ sudo mount -t ext4 ./disk.img /mnt/mydisk/
# 第6步:再看,多了一条
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 50G 20G 28G 42% /
/dev/loop0 4.9M 24K 4.5M 1% /mnt/mydisk挂载后,访问 /mnt/mydisk/ 就是在访问 disk.img 这个分区:
$ echo "hello" > /mnt/mydisk/test.txt
$ ls /mnt/mydisk/
test.txt
# 卸载
$ sudo umount /mnt/mydisk
$ ls /mnt/mydisk/
# 空了!因为分区已经脱离了这个目录挂载的本质
挂载前:
/mnt/mydisk → 只是一个普通目录,属于根分区
挂载后:
/mnt/mydisk → 变成了 disk.img 分区的"入口"
访问 /mnt/mydisk/xxx 就是访问 disk.img 里的 xxx路径解析怎么知道在哪个分区?
靠路径前缀判断:
/home/whb/a.txt
└── 以 "/" 开头,解析 "/" 时知道根目录在 /dev/vda1 分区
→ 后续所有路径都在这个分区里找
/mnt/mydisk/test.txt
└── 解析到 "/mnt/mydisk" 时,发现这个目录是挂载点
→ 后续路径切换到 /dev/loop0 分区里找内核维护一个挂载表,记录每个挂载点对应哪个分区。路径解析到某个目录时,检查它是不是挂载点,如果是就切换到对应的分区继续解析。
/dev/loop0 是什么?
循环设备(loop device),是一种伪设备,能把文件模拟成块设备 。本来 disk.img 只是一个普通文件,但通过loop设备,OS把它当成一个磁盘分区来用。这就是为什么 mount 能直接挂载一个文件。
关键结论
- 分区格式化 = 写入文件系统(SB、GDT、位图、inode表等管理信息)
- 分区挂载 = 把分区和目录关联,访问目录就是访问分区
- 路径前缀决定在哪个分区查找文件
- inode号和块号都不跨分区,所以不同分区可以有相同的inode号
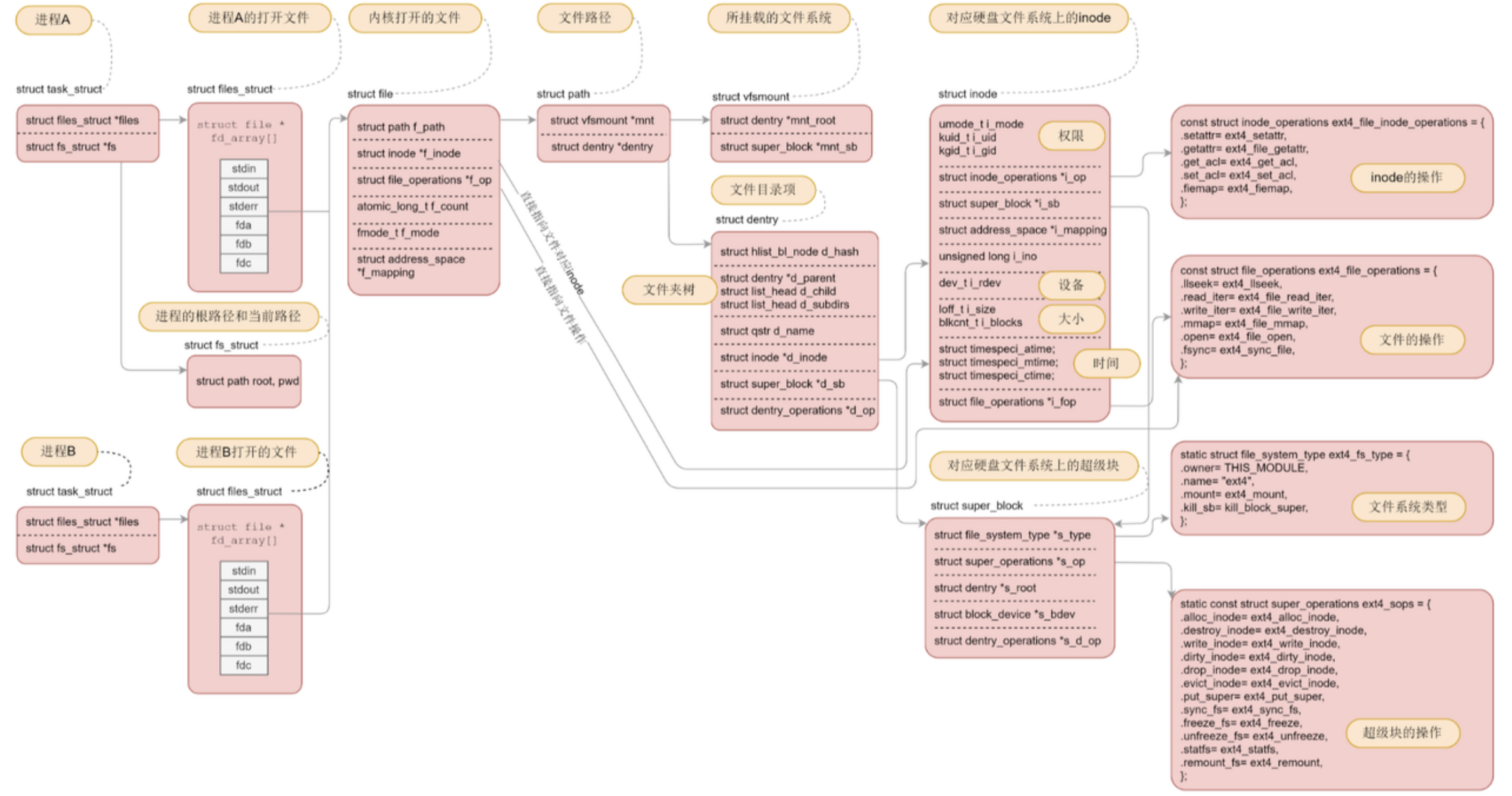
3-9 文件系统总结
图1:内核视角下的文件系统结构
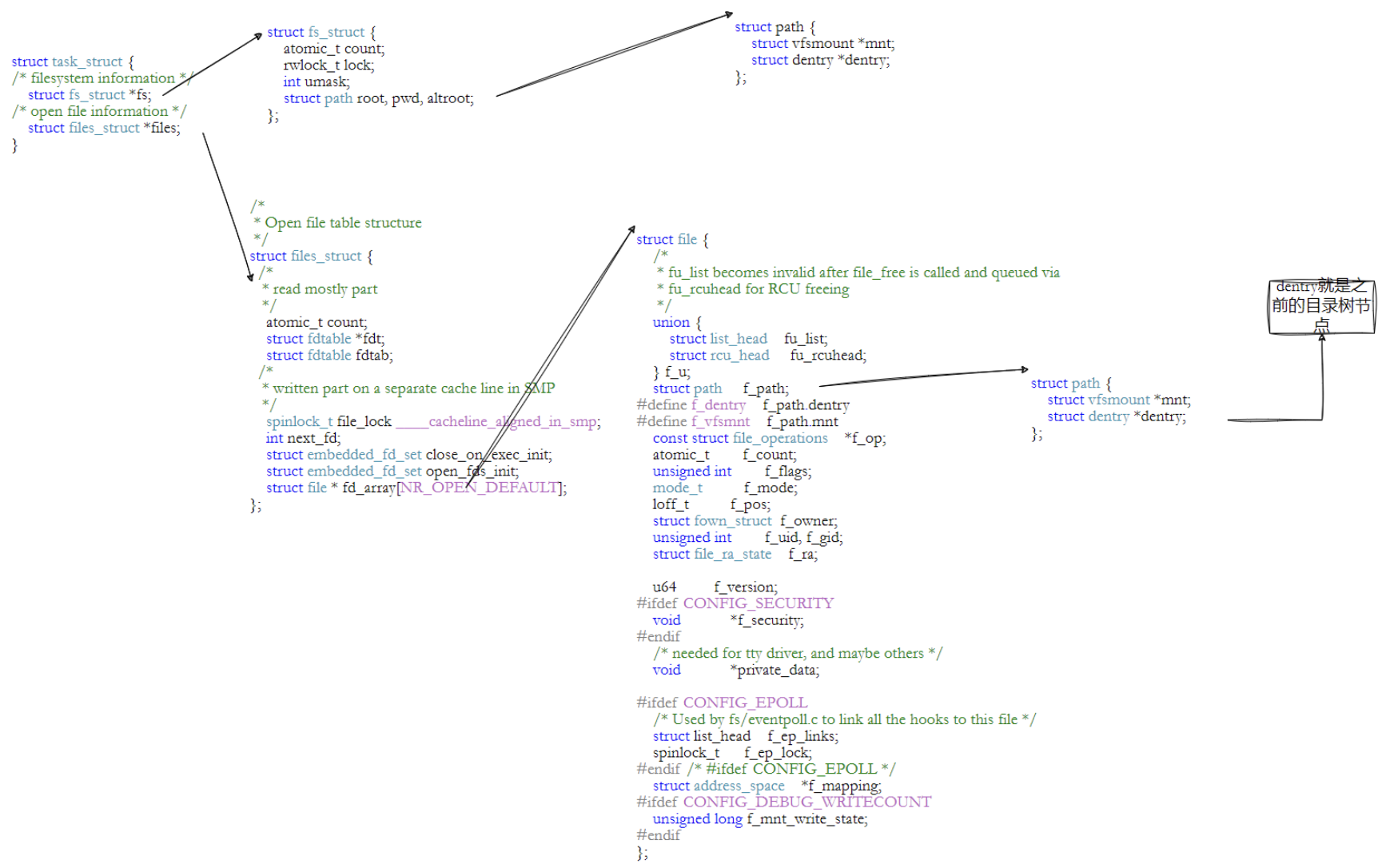
task_struct(进程)
├── fs_struct(文件系统信息)
│ ├── root ──── dentry ──── d_inode ──── 进程根目录的inode
│ └── pwd ──── dentry ──── d_inode ──── 当前工作目录的inode
└── files_struct(打开的文件表)
└── fd_array[]
└── fd_array[fd] → struct file
├── f_dentry ──── dentry ──── d_inode ──── 文件的inode
├── f_op ──── file_operations(read/write函数指针)
├── f_flags(打开方式)
└── f_pos(当前读写位置)这就是把之前学的进程→fd→file→dentry→inode→数据块整条链路串起来了:
进程用fd找到 → struct file(记录打开方式和读写位置)
file找到 → dentry(路径缓存)
dentry找到 → inode(文件属性和数据块位置)
inode找到 → 数据块(文件内容)图2:多个进程打开同一个文件
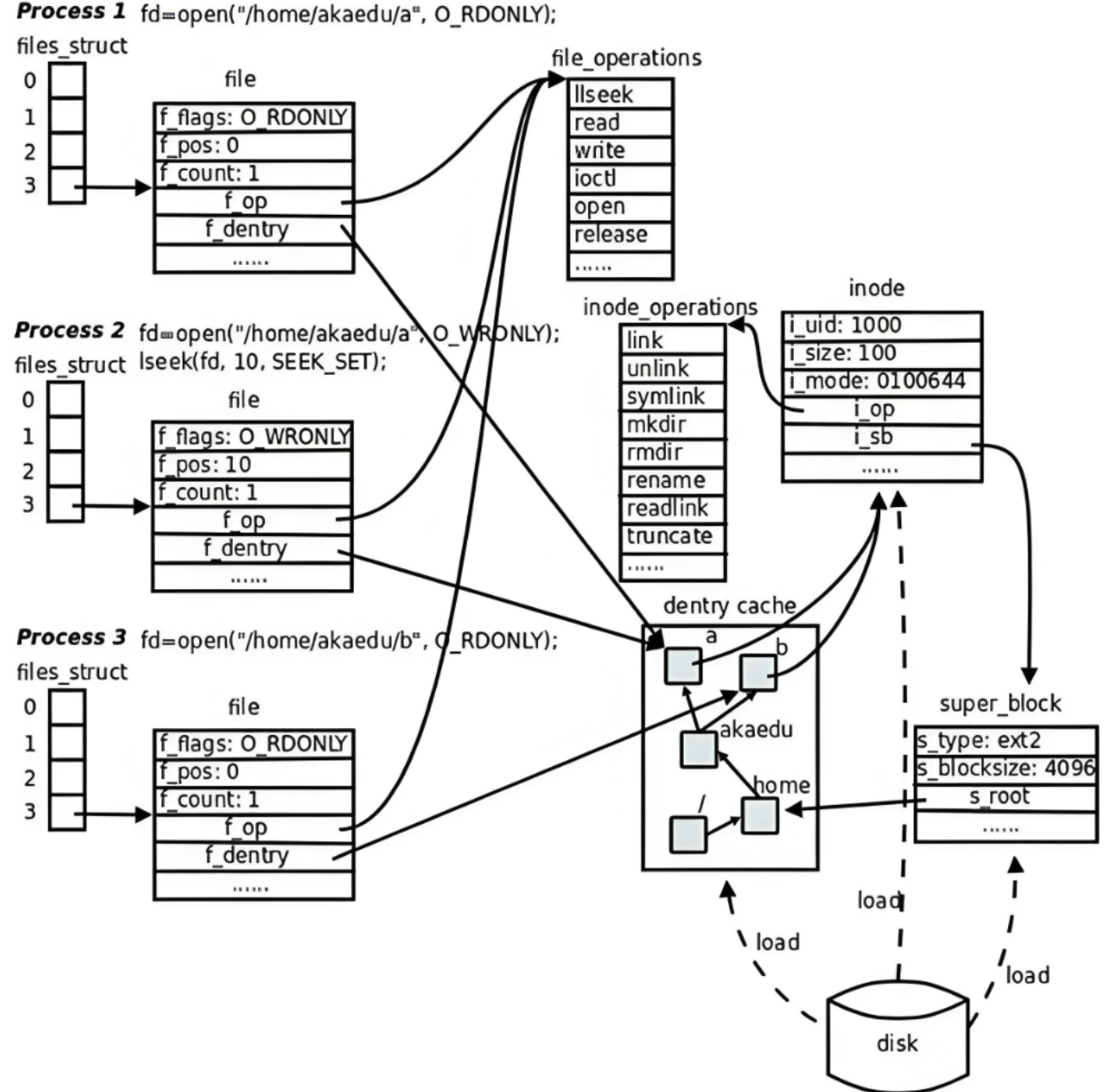
进程1: open("/home/akaedu/a", O_RDONLY)
fd_array[3] → file { f_flags: O_RDONLY, f_pos: 0 }
进程2: open("/home/akaedu/a", O_WRONLY); lseek(fd, 10, SEEK_SET)
fd_array[3] → file { f_flags: O_WRONLY, f_pos: 10 }
进程3: open("/home/akaedu/b", O_RDONLY)
fd_array[3] → file { f_flags: O_RDONLY, f_pos: 0 }关键点:
- 进程1和进程2打开的是同一个文件a ,但每个进程有各自的file结构体 ,各自维护自己的
f_pos(读写位置)和f_flags(打开方式) - 进程3打开的是不同文件b,指向不同的inode
- 但同一个文件的多个file结构体最终都指向同一个dentry和inode
全章总结
ext2文件系统的核心就一句话:
路径解析找inode,inode找数据块,数据块里是内容。
完整流程:
你: open("/home/whb/test.c", O_RDONLY)
↓
1. 路径解析:/ → home → whb → test.c
(先查dentry缓存,没命中就读磁盘上每一级目录的数据块)
(解析到挂载点时切换分区)
↓
2. 拿到 test.c 的 inode
↓
3. inode里有 i_block[15]
小文件:直接块指针 → 数据块
大文件:间接块指针 → 索引块 → 数据块
↓
4. 内核创建 file 结构体,关联 inode
↓
5. 返回 fd 给进程,后续用 fd 读写面试高频考点汇总:
| 考点 | 答案要点 |
|---|---|
| 文件名存在哪? | 目录的数据块里,不在inode里 |
| inode存什么? | 文件属性(权限、大小、时间等)+ 数据块指针,不含文件名 |
| 怎么根据路径找到文件? | 从根目录开始逐级解析,每级在目录数据块中找文件名→inode号 |
| 什么是硬链接? | 多个文件名指向同一个inode |
| 什么是挂载? | 把分区和目录关联,访问目录就是访问分区 |
| dentry是什么? | 内存中的路径缓存,加速路径解析 |
| 块和扇区的关系? | 1块 = 8扇区 = 4KB,块是文件存取的最小单位 |
4. 软硬链接
4-1 硬链接
什么是硬链接
我们知道,真正找到文件靠的是inode号 ,不是文件名。那能不能让多个文件名指向同一个inode?可以,这就是硬链接。
# 创建一个文件
$ touch abc
$ ls -li abc
263466 -rw-r--r-- 1 root root 0 9月 15 17:45 abc
# ↑
# 硬链接数 = 1
# 创建硬链接
$ ln abc def
# 再看
$ ls -li abc def
263466 -rw-r--r-- 2 root root 0 9月 15 17:45 abc
263466 -rw-r--r-- 2 root root 0 9月 15 17:45 def
# 同一个inode号 同样的属性 硬链接数变成了2abc和def是同一个文件的两个名字,它们:
- inode号相同(263466)
- 指向同一份数据
- 权限、大小、时间完全一样
- 硬链接数 = 2
目录数据块里发生了什么
目录数据块:
┌──────────┬──────────┐
│ inode号 │ 文件名 │
├──────────┼──────────┤
│ 263136 │ . │
│ 263488 │ .. │
│ 263466 │ abc │ ← 指向inode 263466
│ 263466 │ def │ ← 也指向inode 263466
└──────────┴──────────┘硬链接没有创建新文件 ,只是在目录数据块里多加了一条映射记录。
硬链接数(link count)
inode里有个字段 i_links_count,记录有多少个文件名指向这个inode。
创建abc: links_count = 1
ln abc def: links_count = 2
ln abc ghi: links_count = 3
rm def: links_count = 2
rm abc: links_count = 1
rm ghi: links_count = 0 → 文件真正被删除,数据块释放links_count = 0 时文件才真正消失。这就是为什么rm只是"取消链接"而不是直接擦数据。
硬链接的限制
不能跨分区创建硬链接。因为inode号以分区为单位,不同分区的inode号空间是独立的,无法指向同一个inode。
不能对目录创建硬链接(系统不允许)。因为会造成路径解析的循环:
如果对目录 /home/whb 创建硬链接 /home/whb/link
那么解析 /home/whb/link/link/link/link/... 就无限循环了不过 . 和 .. 是例外,它们就是系统自动创建的硬链接:
. → 指向当前目录自己的inode(当前目录的硬链接)
.. → 指向上级目录的inode(上级目录的硬链接)所以目录的硬链接数至少为2(自己 + .),每有一个子目录还会+1(因为子目录的 .. 指向它):
$ mkdir test
$ ls -ld test
drwxr-xr-x 2 root root 4096 ... test
# ↑
# 硬链接数 = 2(test自己 + test/.)
$ mkdir test/sub1
$ ls -ld test
drwxr-xr-x 3 root root 4096 ... test
# ↑
# 硬链接数 = 3(test自己 + . + sub1/..)4-2 软链接(符号链接)
什么是软链接
硬链接是通过inode引用另一个文件。软链接是通过文件名引用另一个文件 ,本质上是一个独立的新文件,内容是另一个文件的路径。
# 创建软链接
$ ln -s abc abc.s
$ ls -li
263563 -rw-r--r-- 2 root root 0 9月 15 17:45 abc
263563 -rw-r--r-- 2 root root 0 9月 15 17:45 def
261678 lrwxrwxrwx 1 root root 3 9月 15 17:53 abc.s -> abc
# ↑ ↑ ↑ ↑
# 不同的inode 类型是l 硬链接=1 指向abc
# 大小=3字节("abc"三个字符)关键区别:
- abc.s 有自己的inode(261678),和abc的inode(263563)不同
- abc.s 是一个独立文件,它的内容就是字符串 "abc"(3字节)
lrwxrwxrwx中的l表示这是一个符号链接
目录数据块里长什么样
目录数据块:
┌──────────┬──────────┐
│ inode号 │ 文件名 │
├──────────┼──────────┤
│ 263563 │ abc │
│ 263563 │ def │
│ 261678 │ abc.s │ ← 不同的inode!
└──────────┴──────────┘软链接的原理
你访问 abc.s
↓
1. 找到abc.s的inode(261678)
↓
2. 读取abc.s的数据块,内容是 "abc"
↓
3. OS发现abc.s是软链接,自动用 "abc" 重新发起路径解析
(在当前目录下找 "abc")
↓
4. 找到abc的inode(263563),拿到数据软链接就是一个"路标",里面写着"去哪找真正的文件"。OS看到路标就自动转向。
软链接的大小
$ ls -l abc.s
lrwxrwxrwx 1 root root 3 9月 15 17:53 abc.s -> abc
# ↑
# 大小 = 3字节为什么是3?因为软链接的内容就是目标路径名 "abc",三个字符。如果目标路径是 /home/whb/abc,那软链接大小就是15字节。
特殊情况:如果路径很短(大约60字节以内),内容直接存在inode里,不占用数据块,省空间。
软链接可以跨分区
因为软链接是通过文件名引用,不是通过inode号。只要目标路径存在就行,不在乎在哪个分区。
软链接可以指向不存在的文件
$ ln -s nonexistent dangling_link
$ ls -l dangling_link
lrwxrwxrwx 1 root root 13 ... dangling_link -> nonexistent
$ cat dangling_link
cat: dangling_link: No such file or directory软链接只是存了一个字符串,它不管目标是否存在。这就是悬空链接(dangling link)。
4-3 软硬链接对比
| 硬链接 | 软链接 | |
|---|---|---|
| 本质 | 目录中多一条文件名→inode的映射 | 一个独立的新文件,内容是目标路径 |
| inode号 | 和原文件相同 | 有自己的inode |
| 文件类型 | 普通文件 - |
符号链接 l |
| 跨分区 | 不可以 | 可以 |
| 对目录 | 不可以(会循环) | 可以 |
| 原文件删除 | 不影响,还能访问(inode还在) | 链接失效(悬空链接) |
| 文件大小 | 和原文件一样 | 目标路径名的长度 |
| 硬链接数 | 创建时+1 | 不影响原文件的链接数 |
最核心的区别:硬链接是"同一个文件的另一个名字",软链接是"一个写着别人地址的新文件"。
4-4 软硬链接的用途
硬链接用途
1. . 和 .. ------ 每个目录都有,系统自动创建
2. 文件备份/保护 ------ 创建硬链接防止误删
$ ln important.dat important.dat.bak
# 现在有两个名字指向同一个文件
# 即使rm important.dat,数据还在,通过 important.dat.bak 还能访问3. 节省空间 ------ 多个名字指向同一份数据,数据只存一份
软链接用途
1. 快捷方式 ------ 最常见的用法
$ ln -s /usr/local/bin/myapp /usr/bin/myapp
# 不用敲完整路径就能运行2. 版本管理 ------ 切换版本只改软链接
$ ls -l /usr/bin/python
python -> python3.11 # 当前指向3.11
$ sudo ln -sf /usr/bin/python3.12 /usr/bin/python
# 一行命令切换到3.12,不需要复制文件3. 库文件管理
$ ls -l /lib/x86_64-linux-gnu/libc.so.6
libc.so.6 -> libc-2.31.so
# libc.so.6是软链接,指向实际的库文件
# 升级libc时只需改软链接指向4-5 文件的三个时间(ACM)
这个和链接关系不大,这里讲一下。
$ stat test.c
Access: 2024-10-25 22:15:52 # A - Access:最后访问时间
Modify: 2024-10-17 19:06:11 # M - Modify:最后修改内容的时间
Change: 2024-10-17 19:06:11 # C - Change:最后修改属性(权限等)的时间| 时间 | 含义 | 什么时候更新 |
|---|---|---|
| Access | 最后读取时间 | 读文件内容时(cat、less等) |
| Modify | 最后修改内容时间 | 写文件内容时(echo、vim保存等) |
| Change | 最后修改属性时间 | 改权限、改名字、修改内容(内容变了大小也变了,所以属性也变了) |
注意:Modify变了,Change一定也跟着变。因为修改内容会改变文件大小,大小是属性,所以Change也会更新。但Change也可以单独变,比如只改权限:
$ chmod 777 test.c # 只改了属性,没改内容
# Change更新,Modify不变面试可能问 :Access时间为什么有时不更新? → Linux为了性能,默认开启了 relatime 选项,只有当Access时间比Modify时间旧时才更新Access,避免频繁写磁盘。
第4节总结
硬链接 = 同一个inode,多个文件名
┌── abc ──┐
│ ↓
inode 263466 ← 数据块
↑
└── def ──┘
软链接 = 新文件,内容是别人的路径名
inode 261678 ──→ 数据块内容="abc" ──→ 解析路径找到 abc ──→ inode 263466