在大模型竞相追求参数规模和云端算力的今天,OpenBMB 团队却选择了一条截然不同的道路:他们刚刚发布的 MiniCPM-V 4.6 ,是一个仅有 0.8B 参数 的多模态大语言模型(MLLM),却能在手机上流畅运行,并在多项基准测试中超越体积数倍于自己的竞争对手。这不仅是技术优化的胜利,更代表着一种全新的 AI 发展理念:真正的智能,应该触手可及。
极致效率:用更少的资源做更多的事
MiniCPM-V 4.6 的核心亮点在于其超高的计算效率 。模型基于 SigLIP2-400M 视觉编码器和 Qwen3.5-0.8B 语言模型构建,却在 Artificial Analysis Intelligence Index 基准测试中取得了 13 分 的成绩------这个分数不仅超越了同样基于 Qwen3.5-0.8B 的标准版本(10 分),token 成本却只有其 1/19;更令人惊讶的是,它还超过了参数量更大的 Ministral 3 3B(11 分)和 Qwen3.5-0.8B-Thinking(11 分,token 成本是 MiniCPM-V 4.6 的 43 倍)。
这种效率提升并非简单的参数压缩,而是源于架构层面的创新 。MiniCPM-V 4.6 采用了最新的 LLaVA-UHD v4 技术 ,将视觉编码的计算量(FLOPs)减少了 50% 以上 。更重要的是,模型引入了混合 4x/16x 视觉 token 压缩机制,允许用户在精度和速度之间灵活切换:当需要快速响应时,使用 16x 压缩模式;当需要精细识别时,切换到 4x 模式保留更多视觉细节。
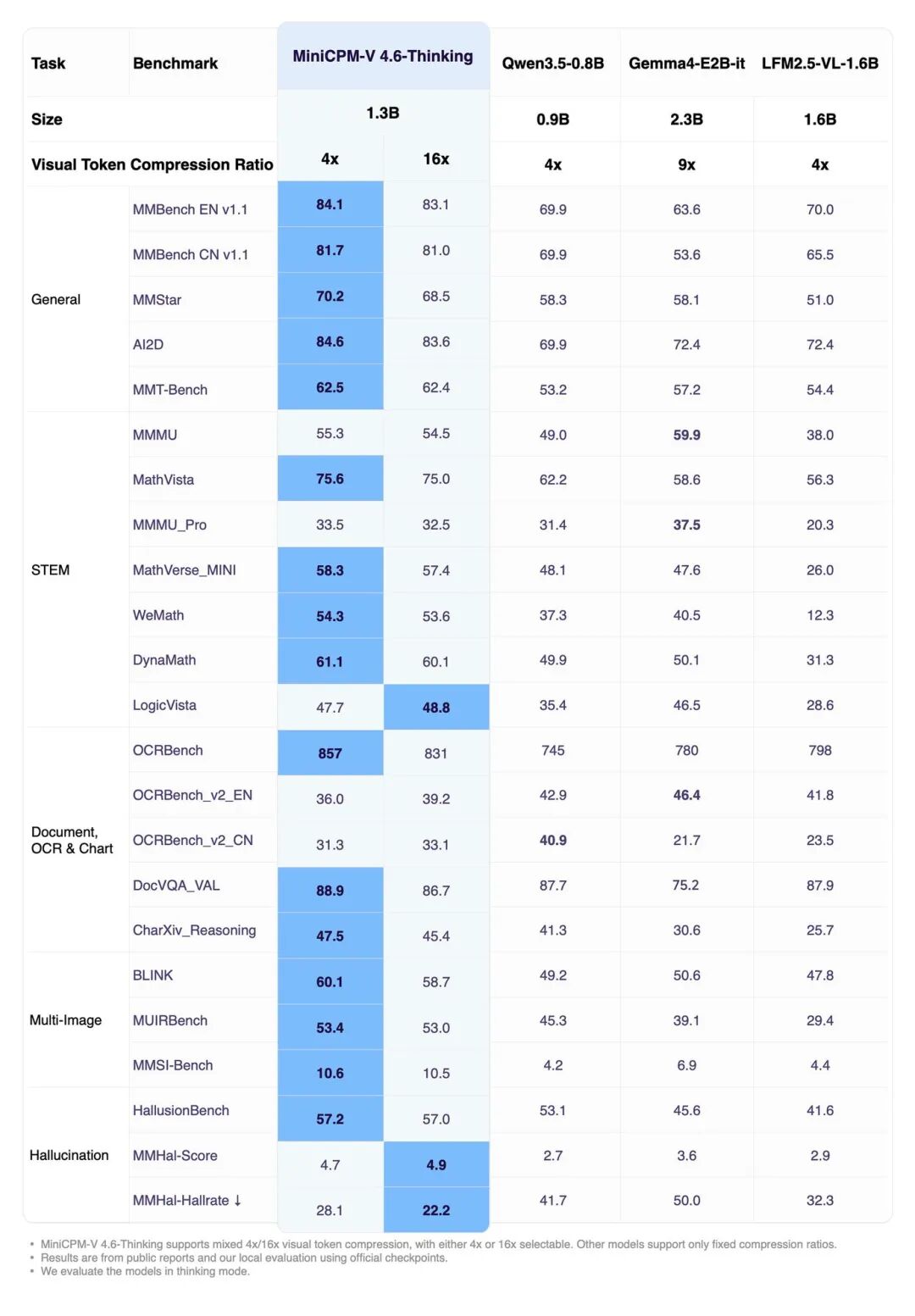
在实际性能测试中,MiniCPM-V 4.6 的吞吐量达到了 Qwen3.5-0.8B 的 1.5 倍。在高并发场景下,这种效率优势更加明显。单请求的首 token 响应时间(TTFT)也保持在极低水平,确保了流畅的交互体验。
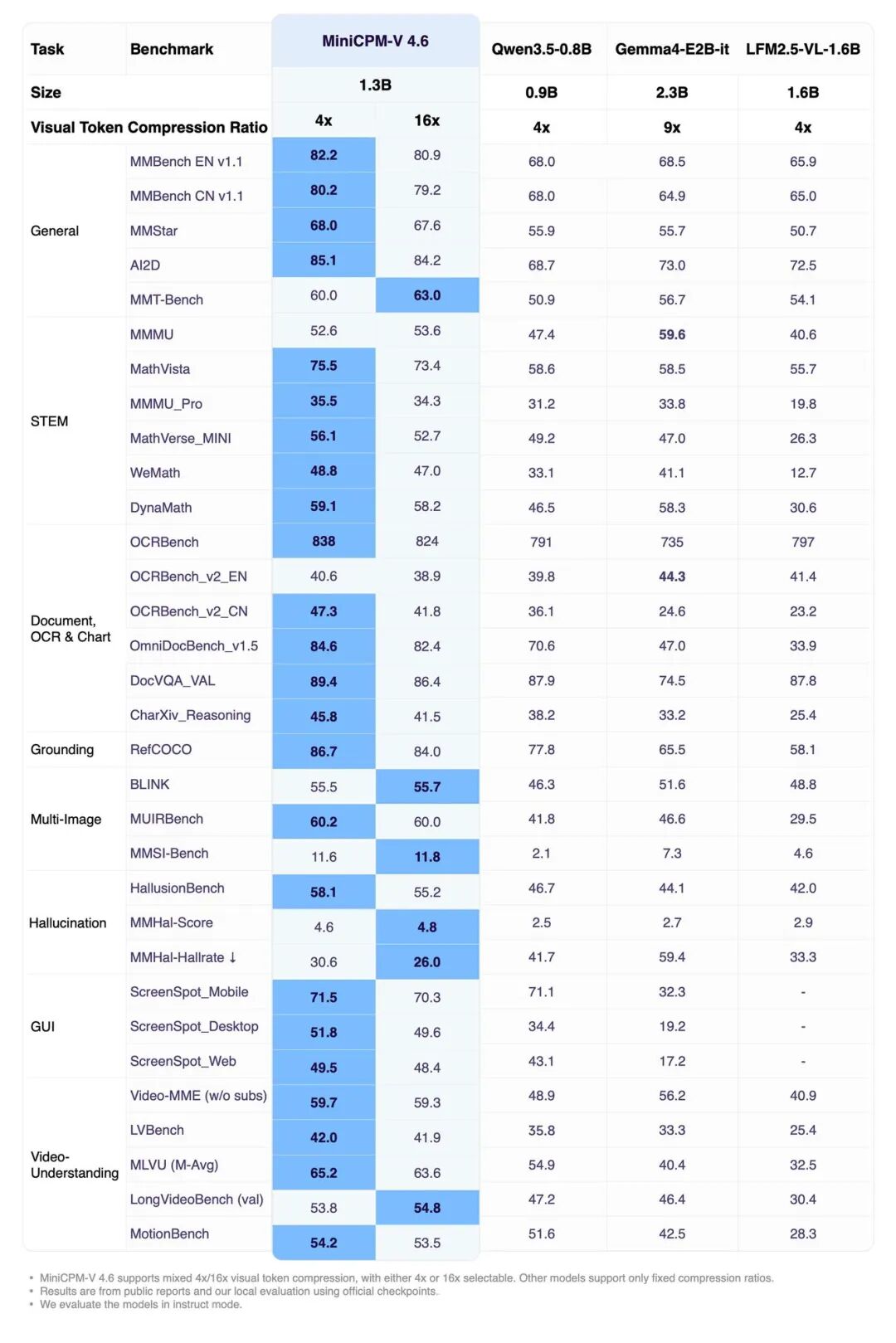
从上图可以看到,MiniCPM-V 4.6 在 Artificial Analysis Intelligence Index、OpenCompass、RefCOCO、HallusionBench、MUIRBench 和 OCRBench 等多个基准测试中,都展现出了超越同等规模甚至更大规模模型的能力。
全能视觉理解:图像、视频、多模态一个不落
尽管体积小巧,MiniCPM-V 4.6 继承了 MiniCPM-V 家族在单图、多图和视频理解 方面的强大能力。在视觉-语言理解任务中,它在大多数基准测试上超越了 Qwen3.5-0.8B,并在 OpenCompass、RefCOCO、HallusionBench、MUIRBench 和 OCRBench 等多个测试中达到了 Qwen3.5 2B 的水平。
这意味着什么?在实际应用中,MiniCPM-V 4.6 可以:
精准识别图像内容:无论是自然场景、文档截图还是复杂图表,模型都能准确理解并回答相关问题。在 OCRBench 测试中的优异表现表明,它对文字密集型图像的处理能力尤为出色。
理解视频时序信息 :模型支持最多 128 帧的视频输入,能够跟踪画面变化、理解动作序列、识别屏幕文字和界面变化。这使其特别适合视频内容分析、教学视频理解、监控视频解析等场景。
处理多图关系:在需要对比多张图片、理解图片序列或分析多角度信息时,MiniCPM-V 4.6 能够建立图像之间的关联,提供综合性的理解。
减少幻觉问题:在 HallusionBench 测试中的良好表现说明,模型在生成答案时能够更好地基于实际视觉内容,而不是凭空臆测。
值得注意的是,MiniCPM-V 4.6 还提供了 Thinking 版本,通过引入思维链推理机制,进一步提升了复杂问题的解答能力。在需要多步推理、逻辑分析的视觉问答任务中,Thinking 版本展现出了更强的能力。
移动端部署:真正的"随身 AI 助手"
MiniCPM-V 4.6 最令人兴奋的特性,是其全面的移动平台覆盖能力 。OpenBMB 团队已经将模型适配到 iOS、Android 和 HarmonyOS 三大主流移动平台,并且所有边缘端适配代码完全开源。
这不是简单的技术演示,而是真正可用的产品级部署。团队发布的演示视频展示了在真实手机设备上的原始录屏(未经剪辑),模型在移动端的响应速度和理解能力令人印象深刻。开发者可以在几步之内复现这种设备端体验,将强大的视觉理解能力直接嵌入自己的移动应用中。
移动端部署的意义远不止于"炫技"。它意味着:
隐私保护:敏感图像和视频无需上传到云端,所有处理都在本地完成。
离线可用:不依赖网络连接,在飞行模式下也能正常工作。
低延迟:省去了网络传输时间,响应更加即时。
成本优势:无需为每次 API 调用付费,特别适合高频使用场景。
对于开发者而言,OpenBMB 提供了详细的边缘部署代码库和下载页面,可以直接下载预编译的应用进行体验,或根据平台特定的构建指南进行定制开发。
开发者友好:丰富的生态支持
MiniCPM-V 4.6 在开发者生态方面做得相当完善,支持多种主流的推理和训练框架:
推理框架:
-
Transformers:官方支持,提供了完整的图像和视频推理示例
-
vLLM:支持高并发部署,并内置工具调用(function calling)能力
-
SGLang:另一个高性能推理选择
-
llama.cpp:提供 GGUF 量化版本,适合资源受限环境
-
Ollama:最简单的本地部署方式,一行命令即可运行
训练框架:
-
LLaMA-Factory:支持 LoRA 微调,可在消费级 GPU 上快速定制模型
-
ms-swift:另一个流行的微调工具,同样支持 MiniCPM-V 4.6
量化支持 :模型提供了 GGUF、BNB、AWQ 和 GPTQ 多种量化格式,开发者可以根据部署环境选择合适的精度-性能平衡点。
特别值得一提的是,Transformers 5.7.0+ 版本内置了轻量级的 OpenAI 兼容服务器,可以通过简单的命令启动本地 API 服务:
transformers serve openbmb/MiniCPM-V-4.6 --port 8000 --continuous-batching
这使得将 MiniCPM-V 4.6 集成到现有应用中变得极为简单------只需将 API 端点从 OpenAI 切换到本地服务器即可。
灵活参数:针对不同场景的精细控制
MiniCPM-V 4.6 提供了丰富的参数选项,让开发者能够针对具体应用场景进行优化:
downsample_mode :控制视觉 token 的下采样率。16x 模式牺牲一些细节换取更快的速度和更低的显存占用;4x 模式保留 4 倍的 token 数量,适合需要精细识别的场景(如 OCR、细节检测)。
max_slice_nums:控制高分辨率图像的切片数量。对于图像任务,推荐设置为 36 以保留更多细节;对于视频任务,推荐设置为 1 以控制总 token 数量。
max_num_frames:视频任务中采样的主帧数量,默认 128 帧,可以根据视频长度和内容复杂度调整。
stack_frames:视频的子帧堆叠策略。设置为 1 表示只使用主帧;设置为 3 或 5 会在每秒的主帧之间插入子帧网格,提供更密集的时序信息。
use_image_id:是否为每个图像/帧添加 ID 标签。图像任务推荐开启,视频任务推荐关闭。
这些参数的灵活组合,使得同一个模型可以适应从快速预览到精细分析的各种需求。
实际应用场景:从概念到落地
MiniCPM-V 4.6 的技术特性使其在多个实际场景中展现出独特价值:
移动端智能助手:集成到手机应用中,提供实时的视觉问答能力。用户可以拍照询问"这是什么植物"、"这道菜怎么做"、"这个标志是什么意思",所有处理都在本地完成。
教育辅助工具:学生可以拍摄题目或课本内容,获得即时解答和讲解。由于支持视频理解,还可以分析教学视频,提取关键知识点。
无障碍辅助:为视障人士提供实时的场景描述、文字识别和物体检测服务,帮助他们更好地理解周围环境。
工业质检:在生产线上部署边缘设备,实时分析产品图像,检测缺陷和异常。低延迟和本地处理的特性使其特别适合这类实时性要求高的场景。
内容审核:对用户上传的图片和视频进行内容理解和分类,识别违规内容。边缘部署可以在上传前就完成初步筛查,减轻服务器压力。
智能监控:分析监控视频流,识别异常行为、统计人流、检测安全隐患。支持离线运行,即使网络中断也能持续工作。
技术细节:如何实现极致效率
MiniCPM-V 4.6 的效率提升来自多个层面的优化:
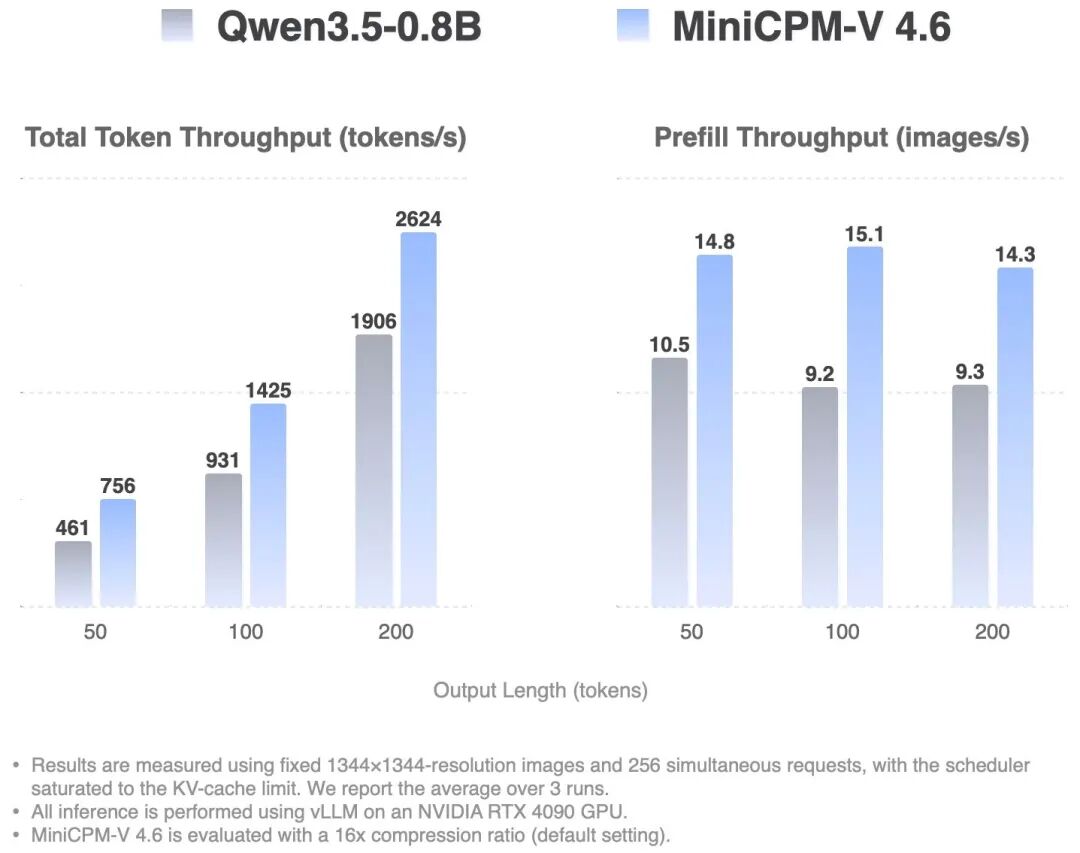
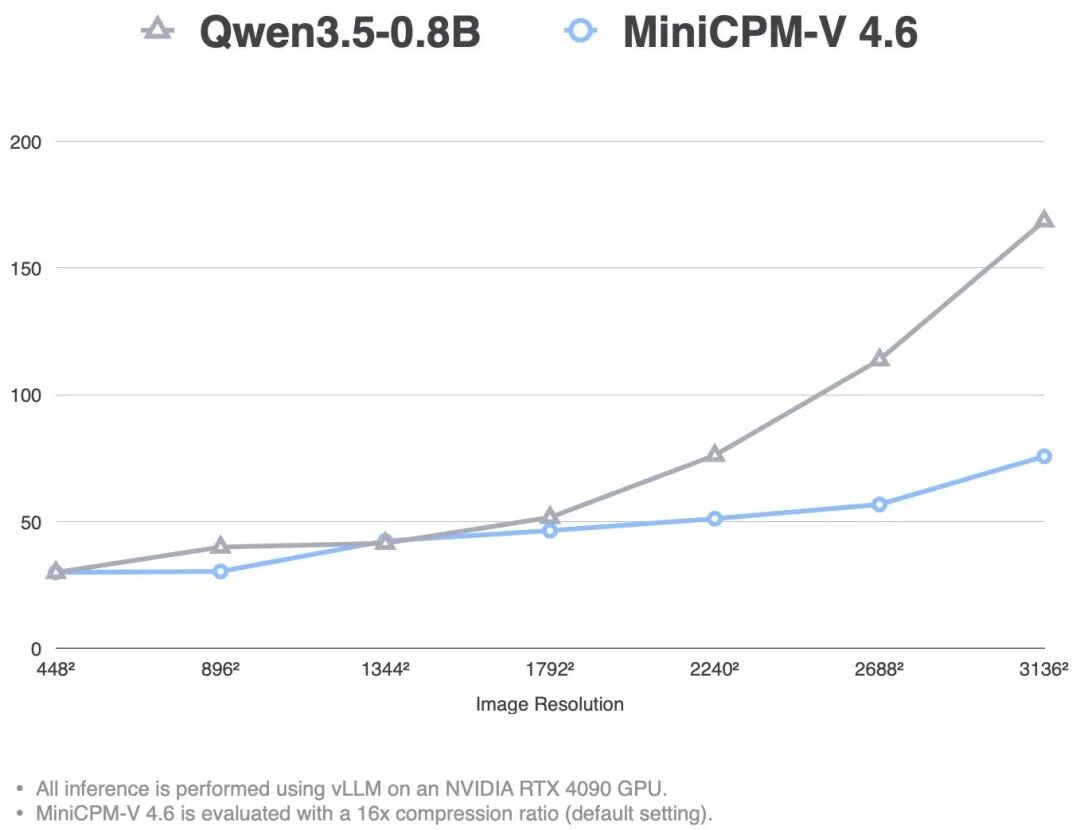
从上面两张图可以看到,MiniCPM-V 4.6 在高并发吞吐量和首 Token 响应时间方面都表现出色,这得益于以下几个方面的优化:
视觉编码器优化:采用 LLaVA-UHD v4 技术,通过更高效的特征提取和 token 压缩策略,在保持视觉理解能力的同时大幅降低计算量。
混合压缩机制:4x 和 16x 两种压缩率可以根据任务需求动态切换,在速度和精度之间找到最佳平衡点。
小型语言模型:Qwen3.5-0.8B 虽然参数量小,但经过精心训练,在理解和生成能力上并不逊色。配合高质量的视觉特征,能够产生出色的多模态理解效果。
推理优化:支持 Flash Attention 2,在多图和视频场景下显著降低显存占用并提升速度。量化版本进一步压缩模型大小,使其能够在移动设备上流畅运行。
工具调用支持:vLLM 部署时可以启用工具调用功能,使模型不仅能理解视觉内容,还能根据需要调用外部工具完成复杂任务。
开源与社区
MiniCPM-V 4.6 采用宽松的开源协议,所有模型权重、推理代码和边缘部署代码都完全开放。开发者可以在 Hugging Face 和 ModelScope 等平台获取模型,根据自身需求进行定制化开发。
OpenBMB 团队还提供了详细的 CookBook,涵盖了从基础使用到高级部署的各个方面。社区成员可以通过 GitHub 提交问题、贡献代码,或加入飞书群组进行交流。
团队的开放态度和完善的文档,大大降低了开发者的使用门槛。无论是研究人员进行学术探索,还是企业开发者构建商业应用,都能快速上手并获得支持。
展望未来:边缘智能的新时代
MiniCPM-V 4.6 的发布,标志着多模态 AI 进入了一个新的发展阶段。它证明了高性能和低资源占用并非不可兼得,通过精心的架构设计和优化,我们可以将强大的 AI 能力装进每个人的口袋。
这种"边缘优先"的设计理念,与当前云端为中心的主流思路形成了鲜明对比。它不是要取代云端大模型,而是为 AI 应用提供了一个新的选择:对于那些对隐私、延迟、成本敏感的场景,边缘端的小型高效模型可能是更好的答案。
随着移动设备算力的持续提升和模型优化技术的不断进步,我们有理由相信,未来会有越来越多像 MiniCPM-V 4.6 这样的模型出现,让 AI 真正成为每个人触手可及的智能助手。
社区地址
OpenCSG社区:https://opencsg.com/models/OpenBMB/MiniCPM-V-4.6
hf社区:https://huggingface.co/openbmb/MiniCPM-V-4.6
关于 OpenCSG
OpenCSG 是全球领先的开源大模型社区平台,致力于打造开放、协同、可持续生态,AgenticOps是人工智能领域的一种AI原生方法论, 由OpenCSG(开放传神)提出。AgenticOps是Agentic AI的最佳落地实践也是方法论。核心产品 CSGHub 提供模型、数据集、代码与 AI 应用的 一站式托管、协作与共享服务,具备业界领先的模型资产管理能力,支持多角色协同和高效复用。