本文作者 :羡林 - OceanBase seekdb 研发负责人 ,诣舟 - OceanBase Cloud 产品负责人
写在前面
过去三十年,数据库的设计里有一个从未被明说的假设:操作数据库的是人。
这个假设决定了数据库的一切设计优先级。人的操作是低频的------每次执行前会思考;人的操作是有意图的------知道自己在改什么;人的操作是可追责的------出了问题能描述发生了什么。围绕这三个特征,数据库构建了事务、锁、审计日志,这已经足够。
Agent 打破了这三个假设。
一个典型的 Vibe Coding session 里,Agent 会在无人监督的情况下执行数十次 INSERT、UPDATE、DELETE------这是高频、无监督 的写入。Agent 的每一次写入都是概率性推理的结果,它不确定自己的输出是否正确------这是无意图可言 的修改。当你发现数据出了问题,Agent 无法告诉你"我在第几步做了什么"------这是不可追责的操作。
这不是极端场景。这是 RAG 持续优化、Multi-Agent 协作、AI 驱动的数据清洗管道的日常工作状态。
这一个月里,我们的用户社区里出现了一个越来越高频的问题:
"AI 改了我的数据,我怎么回到之前的状态?"

有人丢失了经过数周特征工程才调优好的数据集,原因是一次 Vibe Coding session 里 Agent 自动执行了一个"看起来无害"的清洗脚本;有人的 RAG 知识库被一个出错的 Agent 写入了大量低质量内容,而他们甚至无法确定污染是从哪个时间点开始的;有人在多 Agent 协作系统里发现,两个 Agent 的写入互相覆盖,导致知识库的状态完全不可预测。
这个问题,翻译成架构语言只有一句话:
Agent 需要一个沙箱。
不是备份,不是只读快照,而是一个完整的、可读写的、与主库隔离的私有空间------Agent 在里面随意读写,出了问题直接丢弃,验证通过了再合并回主线。就像每个开发者都有自己的代码分支一样,每个 Agent 都应该有自己的数据分支。
这篇文章,就是关于这个沙箱应该长什么样,以及为什么它必须是数据库的一等公民,而不是一个附加功能。
一个正在发生的范式断层
2025 年,一件事悄悄改变了软件开发的底层假设:AI 开始直接操作数据。
不是辅助开发者写 SQL,而是 AI Agent 自主地读取、修改、写入数据库。Vibe Coding 让 AI 生成并执行数据变更;Multi-Agent 系统让多个 AI 并行地更新共享知识库;RAG 管道的持续优化让 embedding 数据以前所未有的频率被重构和替换。
这不是渐进式演化。这是一次断层。
过去三十年,数据库的设计假设是:操作数据库的是人。人的操作频率有限,人会在执行前思考,人犯错了会记得自己做了什么。因此,数据库围绕"事务一致性"和"持久化"构建,这已经足够。
但 AI 不是人。AI 的操作频率以毫秒计,AI 的"思考"是概率性的,AI 的错误往往在扩散之后才被发现。原有的数据库范式,在 AI 面前开始失效。
软件工程已经解决过这个问题
有趣的是,软件开发领域曾经面临过完全类似的困境。
2005 年之前,代码协作依赖的是锁定-修改-提交的线性模式。多人并行开发、快速实验、安全回滚------这些需求在 CVS 和 SVN 时代都是奢侈品,代价高昂。
然后 Git 出现了。
Git 的核心洞察只有一句话:分支应该是免费的。当创建分支的成本趋近于零,开发者的行为模式就会发生根本性改变------从"谨慎地在主线上做修改"变成"随时开分支,大胆实验,合并最优解"。这不只是一个工具的进步,而是一种思维方式的解放。
GitHub 的崛起,开源协作的繁荣,CI/CD 的普及------这一切的地基,都是 Git 把 branching 变成了一等公民。
今天,数据正站在 2005 年代码所站的位置上。
AI 工作流的本质是并行实验
让我们直视 AI 开发的真实工作流:
一个数据科学家同时验证三种特征工程方案;一个 AI 团队对同一份生产数据跑两套 Prompt 策略的 A/B 测试;一个 Multi-Agent 系统中,五个 Agent 并行地从共享知识库读取、学习、写入------每个 Agent 的行为都有可能污染其他 Agent 的上下文。
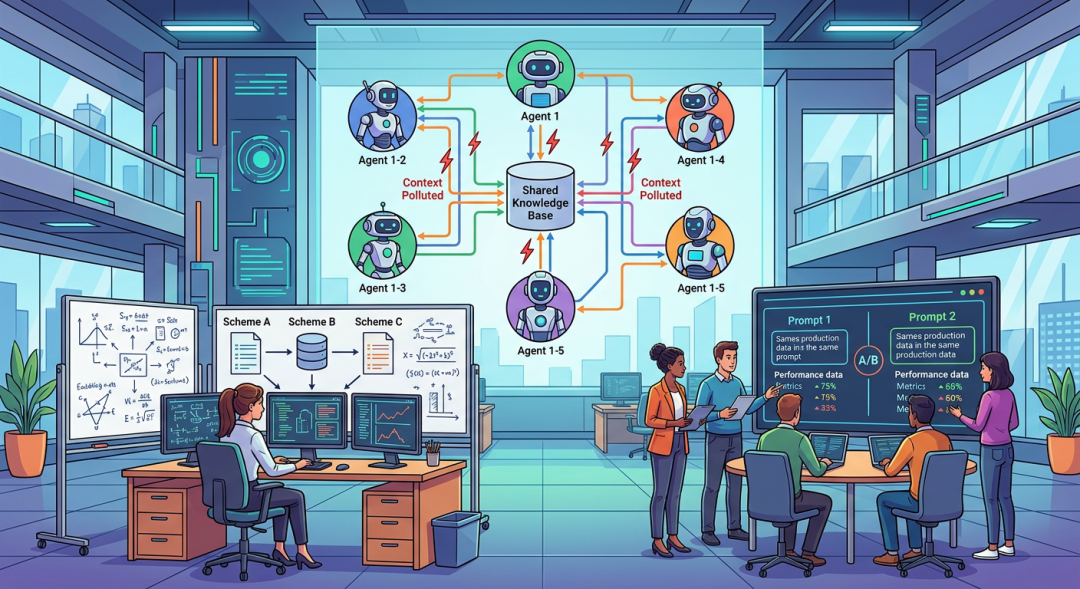
这些场景有一个共同的结构:同一份数据,多条并行的演化路径,最终需要选择最优结果。
这就是分支的本质结构。
但现实中,AI 开发者在做什么? CREATE TABLE features_v1 AS SELECT ...,CREATE TABLE features_v2 AS SELECT ...,CREATE TABLE features_v2_final AS SELECT ...,CREATE TABLE features_v2_final_REAL AS SELECT ...。
这不是版本管理,这是数字垃圾的堆积。更糟糕的是,在 TB 级数据面前,每一次"复制表"都意味着小时级的等待和成倍的存储成本。等待时间扼杀实验意愿,高成本扼杀迭代速度------而迭代速度,恰恰是 AI 时代最核心的竞争力。
现有方案的局限
Neon 把 Branching 带入了 PostgreSQL,这是一个重要的先行信号。Chroma 的 collection fork,LanceDB 的 time-travel------社区正在从各个方向感受到同一个压力。
但这些方案都面临一个共同的边界:它们是在现有数据库范式之上打补丁,而不是从 AI 工作负载的第一性原理出发重新设计。
关系型数据库的 branching 方案天然地不理解向量索引的 fork 语义------当你 fork 一张含有 HNSW 索引的向量表时,索引应该共享还是重建?快照隔离和向量近似搜索的一致性如何协调?这些问题,在为 OLTP 设计的系统里没有原生答案。
AI 原生数据库需要的不是一个附加功能,而是一套从存储引擎到查询层都为 branching 语义重新设计的架构。
什么是"一等公民"
把 Branching 作为一等公民,意味着三条不可妥协的标准:
第一,零成本创建。创建分支的时间复杂度必须是 O(1),与数据量无关。不是"优化过的复制",而是存储引擎架构层面的原生能力------这两者之间有本质差异,前者是工程优化,后者是设计哲学。
第二,完全的读写隔离。 分支不是快照(只读),而是完整的、可读写的沙箱。每个 Agent、每个实验都应拥有一个与主库行为完全等价的私有空间,隔离是强保证而非尽力而为。
第三,可组合的生命周期管理。 分支需要原生的 promote、discard 和 merge 语义。数据演化的路径不应止步于手动 INSERT INTO main SELECT * FROM experiment,正如代码协作不应止步于手动 copy-paste。
AI 原生开发的新工作流
当 Branching 成为数据库一等公民之后,有一件事会系统性地改变:开发者对数据的态度,会从"谨慎保护"变成"大胆实验"。
Vibe Coding 可以在每次变更前自动打快照;A/B 测试可以在数据同源的两个分支上公平运行;多个 Agent 各自持有独立沙箱而不再争抢同一份知识库;模型训练的特征版本可以被锁定,实验因此变得可复现。
这些场景背后有一个共同的行为模式转变------与其花大量精力防止数据被"改坏",不如让"改坏了也能回来"成为基础设施的默认能力。这正是 Git 对代码开发做过的事:不是让开发者更加小心,而是让"犯错的代价"趋近于零。
这不是功能,是基础设施
我想说清楚一件事:我们不认为 Fork Table 是 OceanBase seekdb 的一个"功能"。
我们认为,数据的版本化分支协作,是 AI 时代数据基础设施的基本组成部分,就像事务一致性是 OLTP 时代的基本组成部分一样。
区别只在于:事务一致性是在关系型数据库诞生之初就作为核心设计目标存在的;而数据 branching,因为历史上没有 AI 这样的高频、并行、概率性操作者,从未被认真对待过。
现在,时代变了。AI 成了数据库最重要的用户之一。这个用户的行为模式,要求数据库重新回答一个根本性的问题:当同一份数据需要同时沿着多条路径演化时,数据库应该提供什么样的原生支持?
我们的答案是:Branching 作为一等公民。
路线图:branching 能力的边界在哪
Fork Table 解决的是单表粒度的分支问题。但真实的 AI 应用很少只操作一张表------一个 Agent 的知识库可能横跨结构化数据、向量索引和元数据表,它们需要在同一个一致性快照点上被整体 fork。这是 Fork Database 要解决的问题:一条命令,克隆整个数据库,环境即代码。
更长远地,数据版本化需要补上 Git 的剩余能力:Branch Diff (分支间数据差异的可视化)、Selective Merge (将分支的部分变更合并回主线)、Branch-Aware Query(感知分支拓扑的查询语义)。

代码世界用了二十年走完这条路,数据世界会快得多------因为需求已经在 2026 年摆在那里了。
结语:我们在建造什么
2005 年,Linus Torvalds 用两周时间写出了 Git 的第一个版本。他并不知道这会催生 GitHub,并不知道这会重塑整个软件工程的协作范式。他只是清楚地看到了一件事:现有的工具,与开发者真正需要的工作方式之间,存在一道无法弥合的鸿沟。
今天,AI 开发者与他们的数据之间,存在着同样的鸿沟。
OceanBase seekdb 的使命,是建造这座桥。不是用补丁,而是从第一性原理出发,重新设计数据库应该如何支持 AI 时代的数据工作流。
让每一个 AI 开发者都能像管理代码一样,轻松、自信、高效地管理持续演化的数据。
波澜已起,未来已来。