第一次认真思考"AI记忆"这个问题,是在一个深夜调戏Claude的时候。
我跟它聊了我最近在看的几个项目,聊了我的困惑,聊了我觉得有意思的方向。第二天再打开窗口,它一脸茫然。"你之前说的那个项目是什么来着?""就是那个让你觉得兴奋的关于知识图谱的 idea 啊。"它:???
当时我就愣住了。
就是你明明感觉你们之间已经建立了一种默契,结果第二天它完全不记得你是谁。这种"断崖式失忆"在AI助手身上太常见了。上下文窗口撑死了也就几百万token。
但这个问题,Graphiti想得很清楚。
01 不是给AI装硬盘,是给它造一个"海马体"
很多人理解错了"AI记忆"这件事。
他们觉得"记忆"就是"把之前聊过的东西存起来,下次翻出来"。就像电脑把文件存到硬盘里,需要的时候读出来。这是一种"检索式思维"------记忆 = 存储 + 查询。也就是传统的RAG模式
但Graphiti不是这么干的。
Graphiti做的是"构建时序知识图谱"。听起来很学术,但翻译成人话就是------它不只是存储信息,它在追踪信息"什么时候变成真的,什么时候不再是真的"。
举个例子。
你说"张三喜欢跑步"。这条信息在2023年是真的,但2024年张三膝盖受伤了就不跑步了。传统的RAG系统会怎么干?它会存两条记录,但不会告诉你这两条信息之间的关系。
Graphiti怎么干?它会记录:
- 张三→喜欢→跑步 valid_at: 2023-01-01 invalid_at: 2024-03-15
- 张三→喜欢→游泳 valid_at: 2024-03-16 invalid_at: null
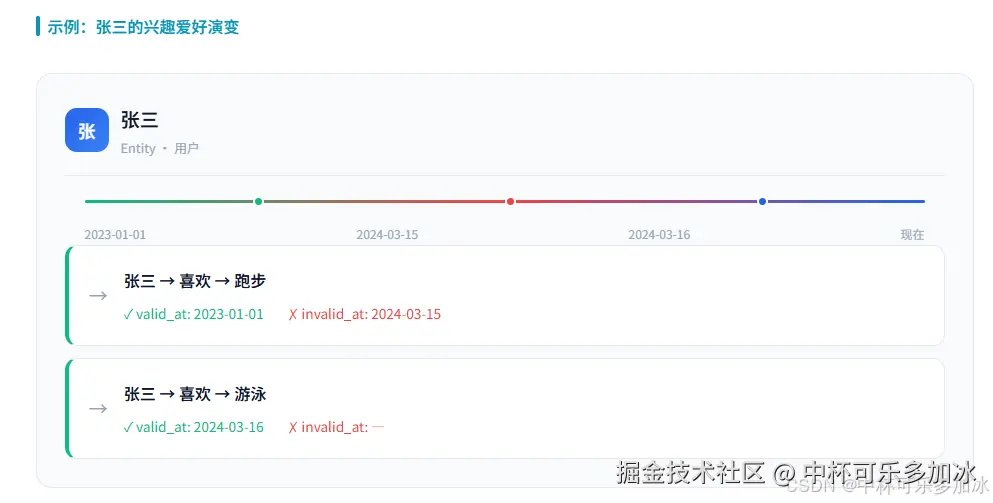
每一条边(关系)都有两个时间戳。一个是"什么时候开始是真的",一个是"什么时候不再是真的是"。这就是Graphiti的核心设计------双时态数据模型(Bi-temporal Data Model)。
你问"张三现在喜欢什么?",它给你的是当前有效的那条。你问"2023年张三喜欢什么?",它给你的是那个时间点有效的。这个能力,传统RAG给不了你。
02 三个核心概念:Episode、Entity、Edge
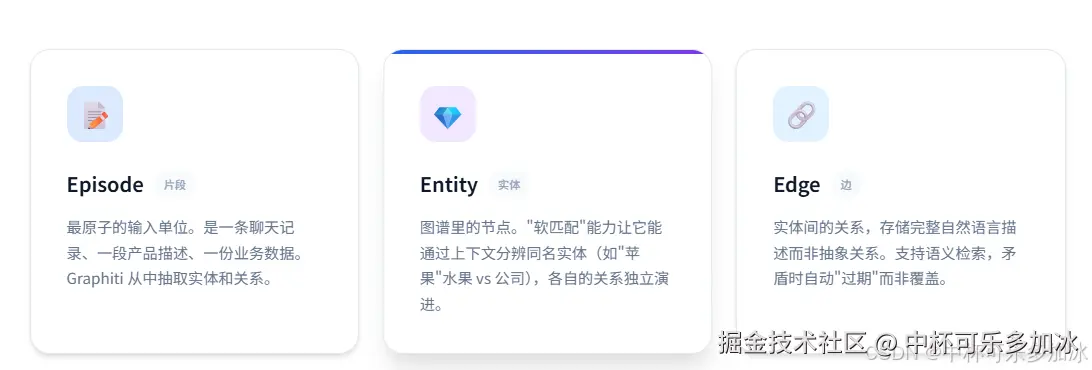
Graphiti的图谱里只有三种东西,理解它们就理解了整个系统。
Episode(片段) 是最原子的单位。
就是你输入的原始数据。可以是一条聊天记录、一段产品描述、一份JSON格式的业务数据。Episode就是"原始素材",是所有推导的源头。
每次你调用 add_episode(),Graphiti做的事情是:
- 接收原始文本/数据
- 用LLM从里面"抽取"出实体和关系
- 去重、合并、更新图谱
- 返回这次处理的结果
注意第3步。"去重、合并、更新"这几个字背后有一套很重的逻辑。新信息来了,它不是简单append,它要判断:这个实体是不是已经在图谱里了?这个关系是不是跟之前矛盾?如果矛盾,怎么处理?
Entity(实体) 是图谱里的节点。
人、地方、概念、产品,任何你希望AI关注的东西都可以是Entity。每个Entity有个 summary 字段,是AI生成的、关于这个实体周围关系的摘要。
Entity有一个很聪明的设计------它的 name 允许重复。
等等,允许重复?这不是数据库大忌吗?
不是。举个例子。"苹果"可能是水果苹果,也可能是苹果公司。如果你说的是水果苹果,那它跟"乔布斯"不应该有关系。但如果有一次你聊的是"水果苹果很甜",另一次聊的是"苹果股价创新高",Graphiti会自动学会------哦,这两个"苹果"指的是不同的事物,它们各自的summary和关系会独立演进。
这就是Graphiti的"软匹配"能力。不用你手工打标签,它自己会通过上下文来分辨。
Edge(边) 是实体之间的关系。
"Kendra喜欢Adidas shoes",这整句话是一条边,从Kendra节点指向Adidas shoes节点。边的 fact 字段存储的是完整的自然语言描述,不是"喜欢"这样一个抽象关系。
为什么要存完整描述?因为 fact 是要生成embedding的。检索的时候,query和fact做语义匹配,而不是抽象关系匹配。这个设计让Graphiti能做真正的"语义检索",而不是关键词匹配。
边的设计里还有一个精妙之处------invalid_at。
当新的边和已有的边矛盾的时候(同一个source指向同一个target,但事实相反),Graphiti不会覆盖旧的边,而是给旧的边打上 invalid_at 时间戳。这个"过期"机制保证了图谱里永远留有历史,你随时可以回溯。
03 搜索才是核心能力,Graphiti做了三层混合检索
如果只是存储,那只能说Graphiti是个"带时间戳的图数据库"。它的真正价值在于检索。
AI需要记忆不是为了存,是为了用。每次用户问问题,AI需要从记忆里取出"最相关的那几条"。Graphiti的搜索系统做了三层混合: 
第一层:BM25关键词检索
这是最传统的文本检索。用TF-IDF家族的打分方式,找到字面上最匹配的内容。BM25的好处是"精确",你知道你在找什么关键词的时候,它很靠谱。
第二层:向量相似度检索
把query和所有实体的name、边的fact都向量化,然后找余弦距离最近的。向量检索的好处是"语义",你知道你想表达什么意思,但不知道用哪个词。
第三层:图遍历(BFS)
从某个实体出发,按深度一层层往外扩。BFS的好处是"关系",你能找到跟某个实体在图上相邻的所有节点。
三层结果是"融合"的。Graphiti用了一套叫RRF(Reciprocal Rank Fusion)的算法,把三个检索结果按权重合并。Reranker还可以用Cross-Encoder再做一轮精细排序。
这种"混合检索"的思路其实来自信息检索领域的经典研究。Elasticsearch在企业搜索里用的也是这套组合。Graphiti把它搬到了知识图谱上,效果是------你不用纠结"我是用语义搜索还是关键词搜索",它给你融合结果。
还有一个很骚的功能:Center Node Reranking。
如果你已经知道某个实体是"主角",你可以把它传进去,Graphiti会按"到主角的图距离"重新排序结果。跟主角近的边排前面,远的后退。这对于"围绕某个实体追问"这种使用场景特别有用。
04 社区发现:把图谱切成"话题圈"
Graphiti还有一个让我眼前一亮的功能------社区发现(Community Detection)。
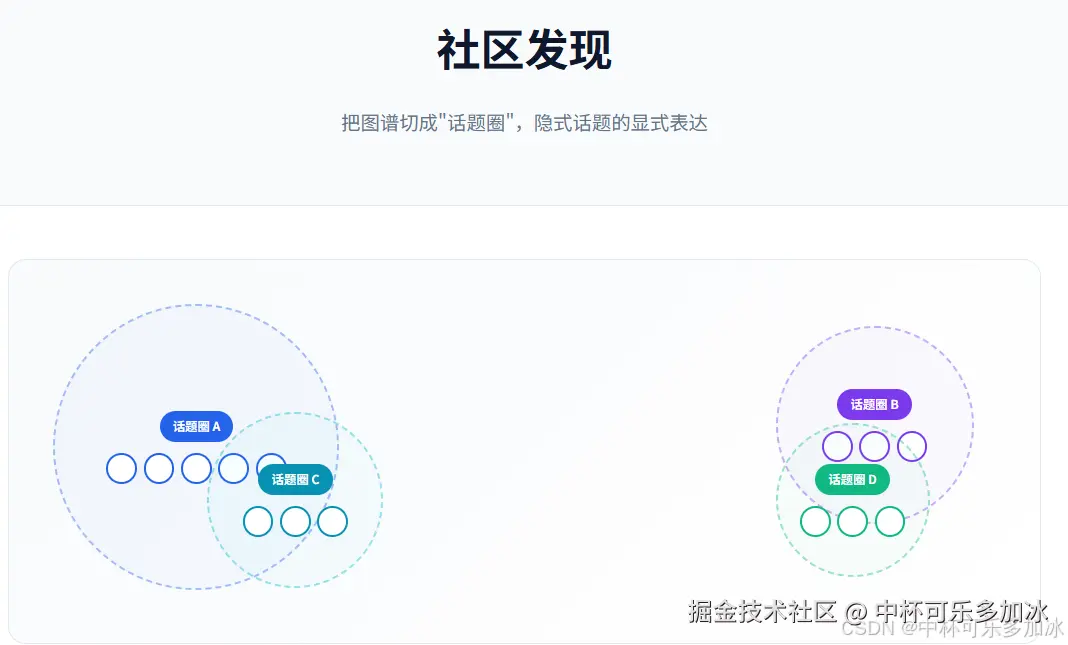
当你往图谱里塞了几千条episode之后,实体会越积越多,关系越来越密。这个时候如果要做检索,图会变得很"平"------所有边的重要性都差不多,找不到重点。
社区发现做的事,是用图聚类算法(比如Label Propagation)把图谱切成若干"话题圈"。每个社区有一个 CommunityNode,里面存了这个社区的摘要------"这个圈子主要在聊什么"。
你可以把社区看成"隐式话题"的显式表达。不用你手工打标签,它自己从结构里学出来哪些实体经常一起出现,哪些边属于同一个讨论线索。
检索的时候,你可以选择"只搜某个社区内",也可以让社区摘要作为context直接传给LLM。效果是------LLM看到的不是一坨混乱的边,而是一个个"话题包"。
05 Saga:给episode们排个队
Saga是Graphiti里比较"隐形"但很实用的一个设计。 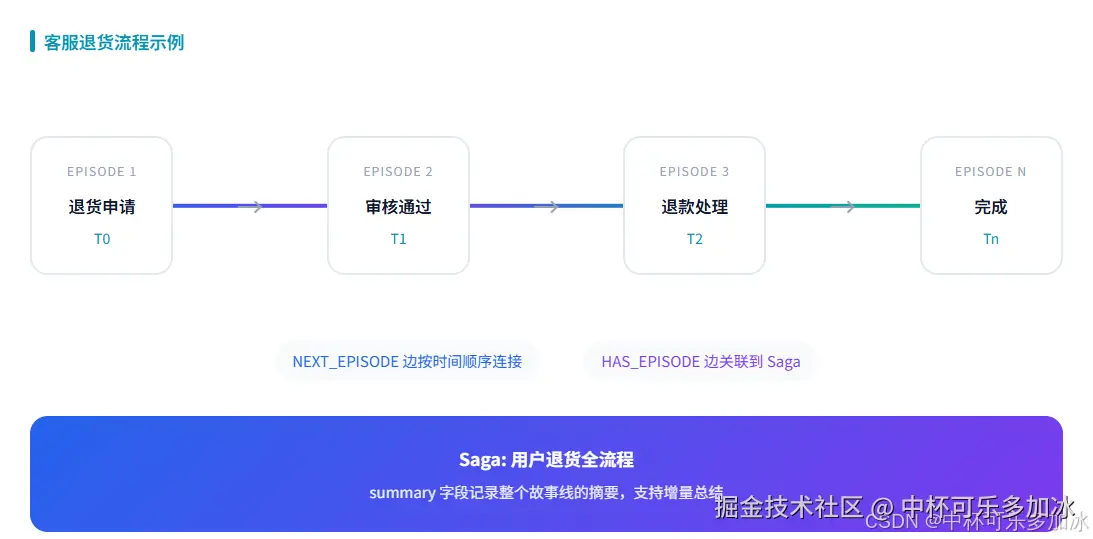 它解决的是"episode之间的顺序和逻辑关系"这个问题。
它解决的是"episode之间的顺序和逻辑关系"这个问题。
举个例子。你在做一个客服机器人。用户发了一条消息"我要退货",你处理了退款。这是两个episode,但它们是"同一个事件的前因后果"。
Saga做的事情是:
- 把相关的episode串成一条"故事线"
- 用
NEXT_EPISODE边按时间顺序连接相邻episode - 用
HAS_EPISODE边把episode跟Saga节点关联 - Saga自己有一个
summary字段,记录"这个saga讲了什么"
有了Saga,你可以做"增量总结"------每次加新的episode,只总结新加的内容,不从头来过。这对于"会话追踪"类场景特别有用,比如客服对话、多轮交互、或者是AI"看到"某个用户的一系列行为。
06 我怎么看Graphiti
说实话,Graphiti解决的不只是"AI记不住"的问题,它解决的是"AI没有结构化的记忆"的问题。
普通RAG的逻辑是"Embedding匹配 + 相似度检索",本质上是"最近的邻居"逻辑。你聊过的话题、你在哪个行业、你喜欢什么风格------这些信息分散在上百条chunk里,检索的时候很难精确命中。 
Graphiti把世界抽象成了"实体-关系-时间"的三元组。每一次交互,不是在往一个巨大的向量数据库里append chunk,而是往一个结构化的图谱里生长节点和边 。这个图谱有自己的拓扑结构,有时间维度,有"过期"机制。 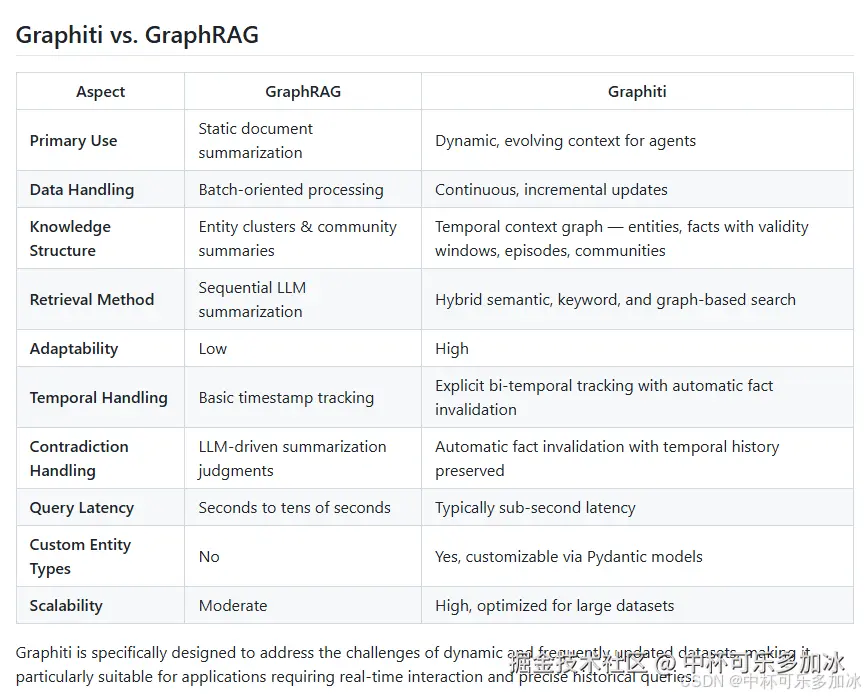
这种结构化的好处是------推理成本降低。
当你想知道"这个用户最近在关心什么",你不需要用复杂的query去试探embedding空间,你只需要找到这个用户对应的Entity节点,看看它最近的边是什么。当你想知道"这个产品的用户典型画像是什么",你不需要做聚类分析,你只需要看看这个产品节点周围的Community是什么。
结构化数据比非结构化数据更容易被推理。这是常识,但在AI记忆这个领域长期被忽视。大家都忙着把上下文窗口撑大,忘了建好索引比塞更多数据重要得多。
Graphiti的设计哲学是"增量构建 + 适时失效"。旧信息不是删掉,而是标记为"不再有效"。新信息来了,不是覆盖旧信息,而是加一条新的并让旧的"过期"。这个"双时态"的思路,其实来自数据库领域的经典理论------每条记录有两个时间维度:有效时间(valid_time)和事务时间(transaction_time)。
把它用在AI记忆上,是Graphiti的核心创新。
07 一些局限和思考
说了这么多优点,也要说说我观察到的一些局限。
LLM抽取的质量决定了一切。
Graphiti的实体抽取、边抽取、属性抽取都依赖LLM。如果LLM在这个环节出了问题------漏抽、错抽、抽取不一致------图谱的质量就会受影响。Graphiti虽然有deduplication和resolution机制,但这些都是"事后补救",不是"源头控制"。如果你用的LLM本身不够稳定,图谱会慢慢变得"脏"。
多图谱管理没有很好的方案。
当前Graphiti的设计是一个实例对应一个图谱。但如果你的应用需要"为每个用户维护一个独立的图谱",那你需要自己去做隔离。group_id可以做一些分区,但跨用户的数据隔离需要自己设计。
实时性有代价。
每次 add_episode 都需要调用LLM做抽取和生成embedding,这个延迟是几十秒级别的。对于需要毫秒响应的场景,Graphiti不是最合适的选择。它更适合"离线积累 + 按需检索"的模式。
这些都是工程层面的权衡,不影响Graphiti作为"AI记忆基础设施"的核心价值。
总之。AI的记忆问题,RAG不是终点,Graphiti才是更彻底的解法。它把"记忆"从"存储"升级成了"结构化建模",把"检索"从"相似度匹配"升级成了"图遍历+时序推理"。
我是真的觉得,这个方向值得更多人去探索。