手把手构建一个轻量级AI Agent:支持记忆、计算与搜索的ReAct实践
🔍 引言
在大语言模型时代,如何让 AI 不仅能"思考",还能"行动"?ReAct(Reasoning + Acting)框架给出了答案。本文将带你深入理解 ReAct 模式,并通过一个完整的实战项目,手把手教你实现一个能使用工具的智能代理。
🎯 技术背景
什么是 ReAct?
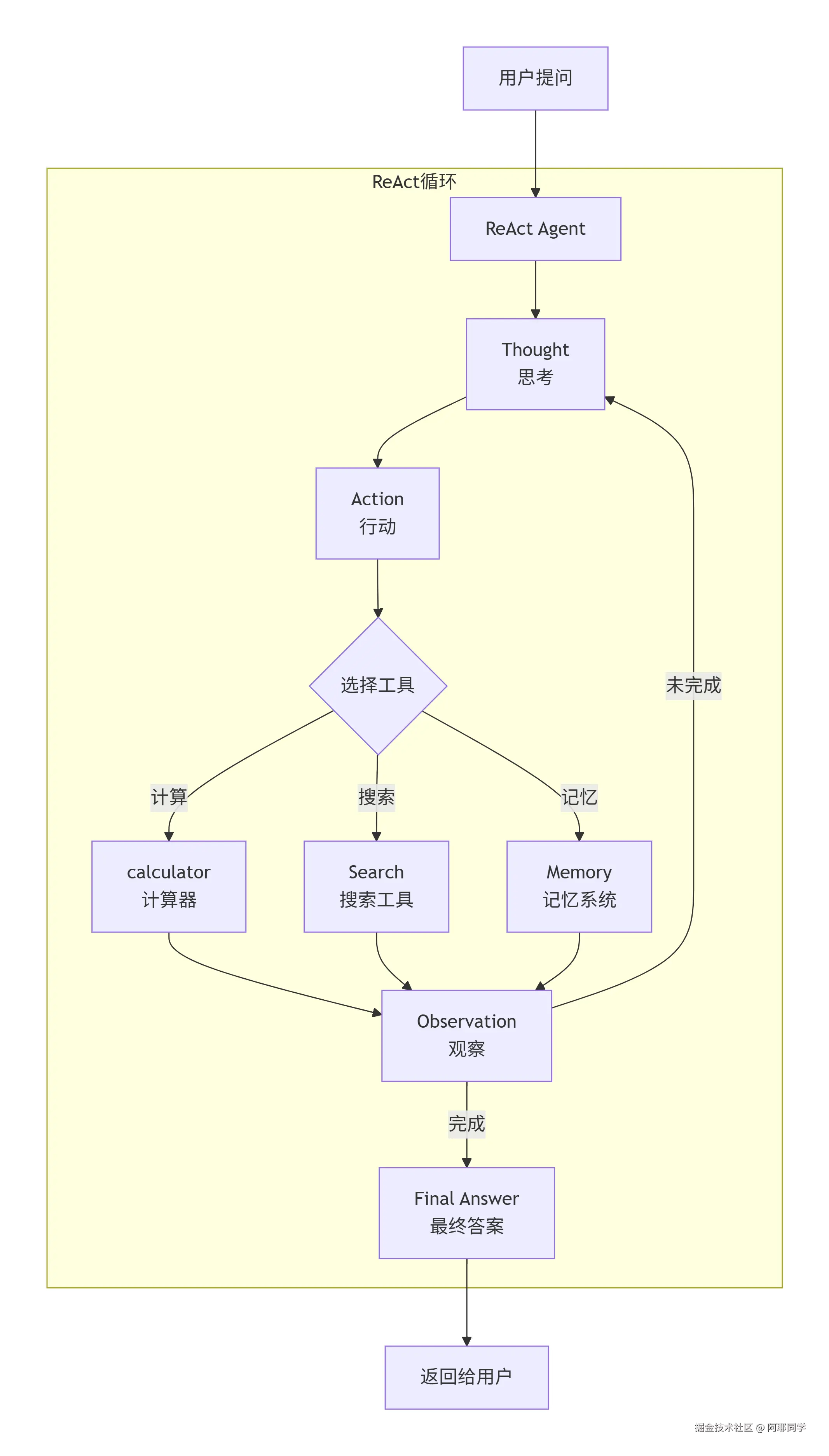
ReAct 是一种让大语言模型通过"思考-行动-观察"循环来解决问题的范式:
- Thought(思考):分析问题,决定下一步做什么
- Action(行动):调用工具获取信息或执行操作
- Observation(观察):获取工具返回的结果
- Final Answer(最终答案):综合所有信息给出结论
为什么需要 ReAct?
- 🧠 解决复杂问题:单一思考无法解决的多步骤任务
- 📡 获取实时信息:突破模型训练数据的时间限制
- 🧮 执行精确计算:避免大模型的计算误差
- 📝 可解释性:每一步决策都清晰可见
🏗️ 整体架构
🚀 核心功能实现
1. 工具定义与安全计算
python
def calculator(expression: str) -> str:
"""安全计算数学表达式,仅允许数字、运算符和小数点"""
allowed = set("0123456789.+-*/() ")
if not all(c in allowed for c in expression):
return "Error: 表达式包含非法字符"
try:
return str(eval(expression, {"__builtins__": {}}, math.__dict__))
except Exception as e:
return f"Error: {str(e)}"技术要点:
- 白名单机制防止代码注入攻击
- 清空
__builtins__避免危险函数调用 - 仅传入
math模块支持常用数学运算
2. 搜索工具实现
python
def search(keyword: str) -> str:
fake_results = {
"北京天气": "北京今天晴,气温30°C",
"首都": "中国的首都是北京",
"Python": "Python是一种高级编程语言",
"奥斯卡最佳影片": "我的世界",
"IMDb评分":"89"
}
for k, v in fake_results.items():
if k in keyword:
return v
return f"Error:关于'{keyword}'的搜索结果:未找到相关信息。"说明:这是一个模拟实现,实际应用中应调用真实的搜索引擎 API。
3. 记忆系统
python
memory = {} # 全局记忆字典
# 在工具调用中使用记忆
elif tool == "remember":
match = re.match(r"(\w+)\s*,\s*(.+)", inp)
if match:
var_name = match.group(1)
var_value = match.group(2).strip()
memory[var_name] = var_value
obs = f"已记忆: {var_name} = {var_value}"亮点:支持跨步骤变量存储,实现复杂的多步骤计算任务。
4. LLM 输出解析
python
def parse_output(txt: str):
thought = re.search(r"Thought:\s*(.*)", txt)
final = re.search(r"Final Answer:\s*(.*)", txt, re.DOTALL)
action = re.search(r"Action:\s*(\w+)\s*[\[(]([^)\]]+)[)\]]", txt)
return {
"thought": thought.group(1).strip() if thought else None,
"final_answer": final.group(1).strip() if final else None,
"action": action.group(1) if action else None,
"action_input": action.group(2).strip() if action else None,
}核心逻辑:通过正则表达式从 LLM 输出中提取结构化信息。
5. 代理主循环
python
def run_agent(query):
system_prompt = open("sys_prompt", "r").read().strip()
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": query}
]
for i in range(max_iterations):
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=messages,
temperature=0,
stop=["Observation:"]
)
reply = resp.choices[0].message.content.strip()
messages.append({"role": "assistant", "content": reply})
parsed = parse_output(reply)
tool, inp, final = parsed["action"], parsed["action_input"], parsed["final_answer"]
if final:
return final # 任务完成
# 执行工具调用...
messages.append({"role": "assistant", "content": f"Observation: {obs}"})📝 系统提示词设计
sys_prompt 文件定义了代理的行为规范:
scss
你是一个能使用工具的智能助手。可用工具:
- calculator(表达式): 数学计算,例如 calculator(2+3)
- search(关键词): 搜索实时信息,例如 search(北京天气)
严格按照以下格式:
Thought: 你的思考
Action: 工具调用,包含函数名+表达式
Observation: 工具返回(由系统填入)
Final Answer: 最终答案设计要点:
- 明确可用工具列表
- 定义严格的输出格式
- 提供多个示例帮助 LLM 理解
- 包含错误处理规则
💡 使用示例
示例 1:多步骤计算任务
python
query = "计算 3 * 4 得到的结果存入x,然后计算 x + 5 再存入y,最后告诉我x、y分别是多少?"执行过程:
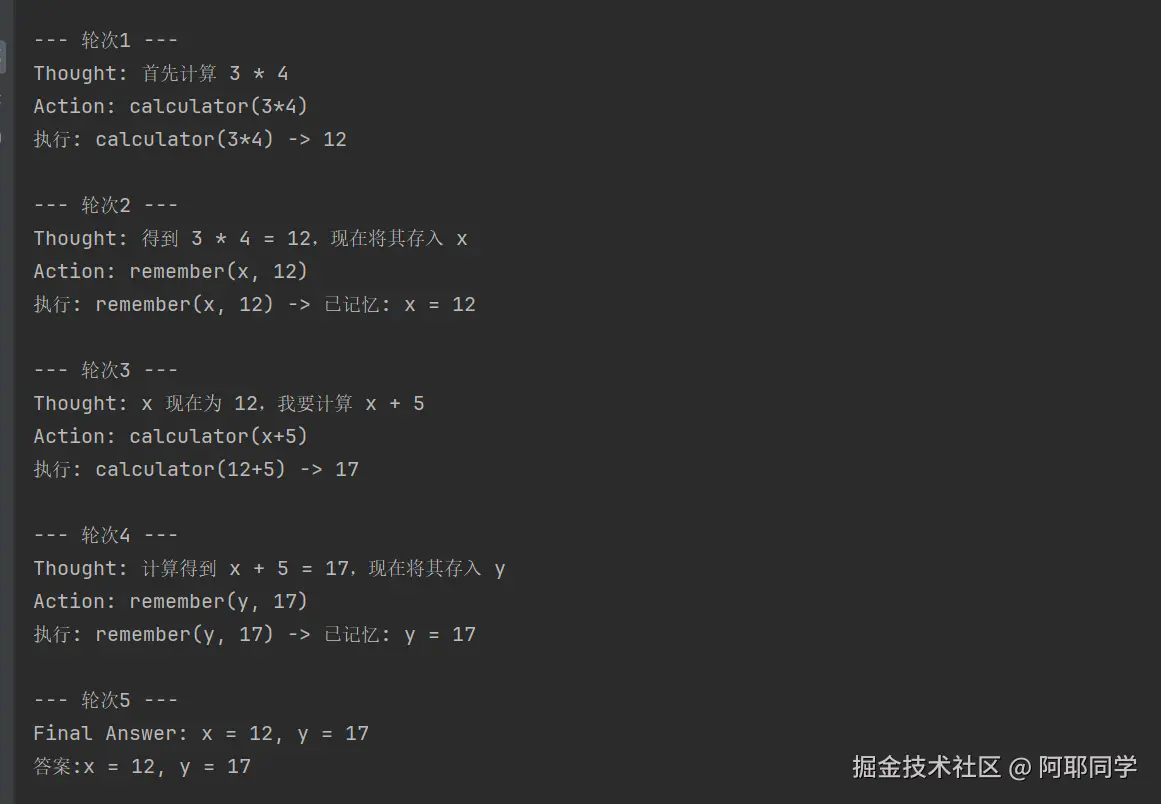
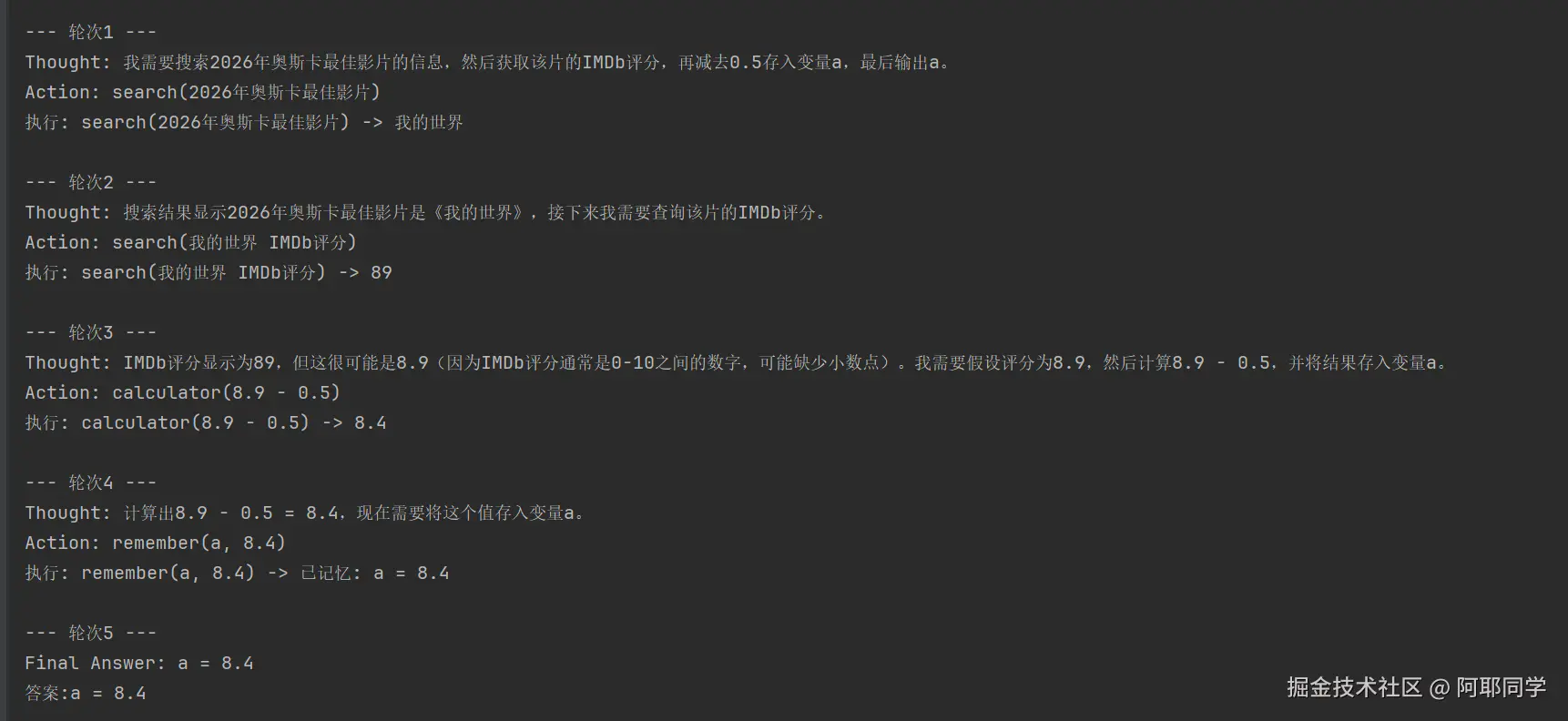
示例 2:链式任务
python
query = "搜索今年(2026年)的奥斯卡最佳影片,然后搜索该片的IMDb评分,再把这个评分减去0.5存在变量a里,最后告诉我a是多少。"执行过程:
🔧 安装与运行
环境依赖
bash
pip install openai ollama配置说明
- 使用 OpenAI API(DeepSeek):
python
client = OpenAI(
api_key="sk-xxx",
base_url="https://api.deepseek.com"
)- 使用 Ollama 本地模型:
python
# 可以选择本地模型
response = ollama.chat(model=model, messages=messages, options={"temperature": 0})
reply = response["message"]["content"]运行方式
bash
python main.py🚀 技术洞察
1. 提示词工程的重要性
系统提示词是 ReAct 代理的"灵魂",一个好的提示词需要包含:
- 角色定义
- 工具列表和使用方式
- 输出格式规范
- 示例演示
2. 安全考虑
在实现工具调用时必须注意:
- 输入验证(如计算器的白名单)
- 避免执行任意代码
- 限制工具调用权限
3. 多模型支持策略
项目支持两种模型调用方式:
- API 模式:适合需要高性能模型的场景
- 本地模式:适合隐私敏感或离线环境
4. 迭代优化策略
可以从以下方向改进:
- 添加更多工具(文件读写、数据库查询等)
- 实现工具选择的自动化
- 添加错误重试机制
- 优化提示词减少 token 消耗
📊 性能优化建议
| 优化方向 | 具体措施 |
|---|---|
| 减少 API 调用 | 批量处理相似请求 |
| 缓存搜索结果 | 避免重复搜索相同内容 |
| 精简提示词 | 只保留必要信息 |
| 异步处理 | 并行执行多个工具调用 |
🎯 总结与展望
本文要点
- ✅ 理解 ReAct 模式的核心概念
- ✅ 实现工具调用框架
- ✅ 设计系统提示词
- ✅ 构建记忆机制
- ✅ 支持多模型切换
未来方向
- 🔄 工具市场:支持动态加载第三方工具
- 🧠 反思机制:让代理能够评估自己的决策
- 📊 性能监控:追踪代理执行效率
- 🌐 多模态支持:处理图像、语音等多种输入
📮 互动交流
如果你有任何问题或想法,欢迎在评论区留言!如果觉得本文对你有帮助,请点赞、收藏、关注三连支持一下~