KV Cache 的数学建模与原理解析
简单来说,它的本质是"空间换时间"。在 Transformer 模型逐字生成文本(Autoregressive Decoding)时,模型为了生成当前 Token,需要计算当前 Token 与之前所有已生成 Token 的注意力权重。如果没有 KV Cache,模型在每生成一个新词时,都要把前面所有的词重新计算一遍,这会造成极大的算力浪费。
为了避免这种重复计算,系统会将之前计算过的所有 Token 的 Key (K) 和 Value (V) 向量缓存下来。当生成新 Token 时,只需要计算当前新 Token 的 Q、K、V,然后提取缓存中历史 Token 的 K 和 V 进行注意力计算。
将时间复杂度从 O(t2)O(t^2)O(t2) 降低至 O(t)O(t)O(t),空间复杂度是从 O(1)O(1)O(1) 变成了 O(t)O(t)O(t)。空间是指显存的占用,但是一直占用还是比直接算的临时变量占用要小的。
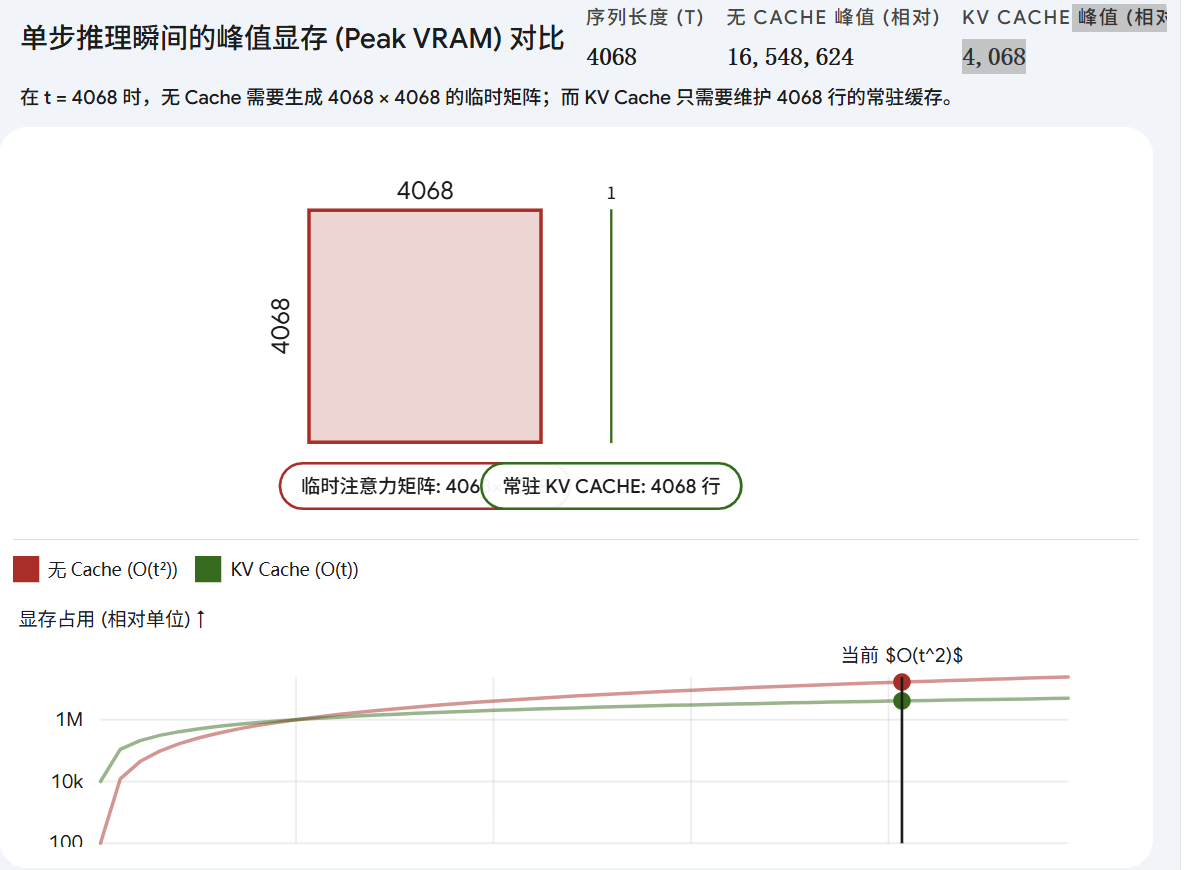
LLM生成的过程中,因为是自回归的,所以Q的seq_len永远是1,KV充当memory的作用,seq_len是当前生成的序列长度
1. 自回归解码的数学表示与计算冗余
在标准的 Transformer 架构中,注意力机制(Scaled Dot-Product Attention)的通用公式定义为:
Attention(Q,K,V)=softmax(QKTdk)V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk QKT)V
对于自回归生成任务,假设当前模型已经生成了长度为 t−1t-1t−1 的序列,其特征矩阵表示为 X1:t−1∈R(t−1)×dX_{1:t-1} \in \mathbb{R}^{(t-1) \times d}X1:t−1∈R(t−1)×d(其中 ddd 为隐层维度)。
当预测第 ttt 个 Token 时,如果不加优化,模型会将当前所有已知的 ttt 个 Token 一起输入进行线性映射:
Q1:t=X1:tWQ,K1:t=X1:tWK,V1:t=X1:tWV Q_{1:t} = X_{1:t}W_Q, \quad K_{1:t} = X_{1:t}W_K, \quad V_{1:t} = X_{1:t}W_V Q1:t=X1:tWQ,K1:t=X1:tWK,V1:t=X1:tWV
此时,K1:tK_{1:t}K1:t 和 V1:tV_{1:t}V1:t 的维度均为 t×dkt \times d_kt×dk。由于因果掩码(Causal Mask)的存在,前 t−1t-1t−1 个 Token 的状态计算包含了大量的重复映射。为了消除这种冗余,我们引入了 KV Cache 机制。
2. KV Cache 的状态更新方程(维度拆解)
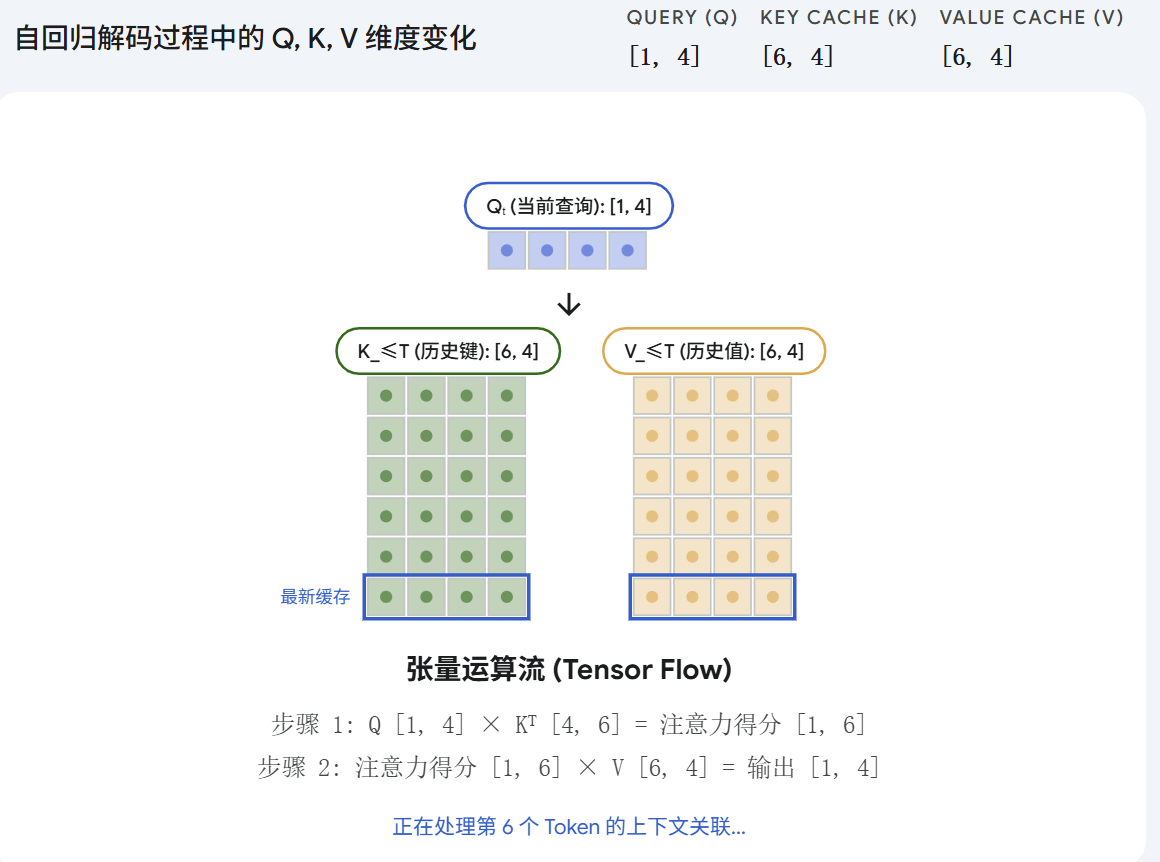
在 KV Cache 机制下,我们将推理过程解耦为增量计算 。在预测第 ttt 个 Token 时,模型实际上只需要处理当前最新生成的那一个 Token ,即 xt∈R1×dx_t \in \mathbb{R}^{1 \times d}xt∈R1×d。
2.1 查询向量(Query)的瞬时性建模
由于当前的目标仅仅是基于 xtx_txt 提取历史信息以预测下一个词,因此我们需要且仅需要计算当前时间步的 Query 向量:
qt=xtWQ q_t = x_t W_Q qt=xtWQ
此时,qtq_tqt 的维度严格为 1×dk1 \times d_k1×dk。这在数学上表征了当前单步的"瞬时查询意图"。
2.2 键值对(Key-Value)的增量拼接
针对当前的输入 xtx_txt,我们同样计算其对应的单步 Key 和 Value:
kt=xtWK∈R1×dk k_t = x_t W_K \in \mathbb{R}^{1 \times d_k} kt=xtWK∈R1×dk
vt=xtWV∈R1×dv v_t = x_t W_V \in \mathbb{R}^{1 \times d_v} vt=xtWV∈R1×dv
此时,显存中已经维护了前 t−1t-1t−1 步的缓存矩阵 K≤t−1K_{\le t-1}K≤t−1 和 V≤t−1V_{\le t-1}V≤t−1。状态更新方程表现为矩阵在序列长度维度(Sequence Length Dimension)上的拼接(Concatenation):
K≤t=Concat(K≤t−1,kt)∈Rt×dk K_{\le t} = \text{Concat}(K_{\le t-1}, k_t) \in \mathbb{R}^{t \times d_k} K≤t=Concat(K≤t−1,kt)∈Rt×dk
V≤t=Concat(V≤t−1,vt)∈Rt×dv V_{\le t} = \text{Concat}(V_{\le t-1}, v_t) \in \mathbb{R}^{t \times d_v} V≤t=Concat(V≤t−1,vt)∈Rt×dv
2.3 单步 Attention 结果计算
基于更新后的矩阵,第 ttt 步的注意力输出计算如下:
ht=softmax(qtK≤tTdk)V≤t h_t = \text{softmax}\left(\frac{q_t K_{\le t}^T}{\sqrt{d_k}}\right) V_{\le t} ht=softmax(dk qtK≤tT)V≤t
维度验算:
- 投影计算:qt (1×dk)×K≤tT (dk×t)=Scorest (1×t)q_t \ (1 \times d_k) \times K_{\le t}^T \ (d_k \times t) = \text{Scores}_t \ (1 \times t)qt (1×dk)×K≤tT (dk×t)=Scorest (1×t)
- 加权求和:Scorest (1×t)×V≤t (t×dv)=ht (1×dv)\text{Scores}t \ (1 \times t) \times V{\le t} \ (t \times d_v) = h_t \ (1 \times d_v)Scorest (1×t)×V≤t (t×dv)=ht (1×dv)
最终输出的 hth_tht 恰好为一个 Token 的隐特征表示,直接用于后续 FFN 层的计算。
3. 为什么 KV 可以复用?(不变性证明)
KV Cache 成立的理论基础在于自回归机制下的状态局部不变性。
对于序列中的任意历史位置 iii(i<ti < ti<t),其输入特征为 xix_ixi。在因果掩码的约束下,xix_ixi 的生成仅依赖于 X1:iX_{1:i}X1:i,与未来的输入 X>iX_{>i}X>i 严格解耦。
同时,投影矩阵 WKW_KWK 和 WVW_VWV 在推理阶段是全局共享且冻结的常数矩阵。
因此,映射函数 fK(xi)=xiWKf_K(x_i) = x_i W_KfK(xi)=xiWK 和 fV(xi)=xiWVf_V(x_i) = x_i W_VfV(xi)=xiWV 满足:
∀t>i,∂ki∂xt=0,∂vi∂xt=0 \forall t > i, \quad \frac{\partial k_i}{\partial x_t} = 0, \quad \frac{\partial v_i}{\partial x_t} = 0 ∀t>i,∂xt∂ki=0,∂xt∂vi=0
这意味着,无论序列如何向后延伸,历史位置 iii 所计算出的 kik_iki 和 viv_ivi 恒定不变 。这种数学上的绝对静态性,使得我们可以将它们直接缓存在 GPU 的显存中,避免 O(t2)O(t^2)O(t2) 的重复矩阵乘法计算。
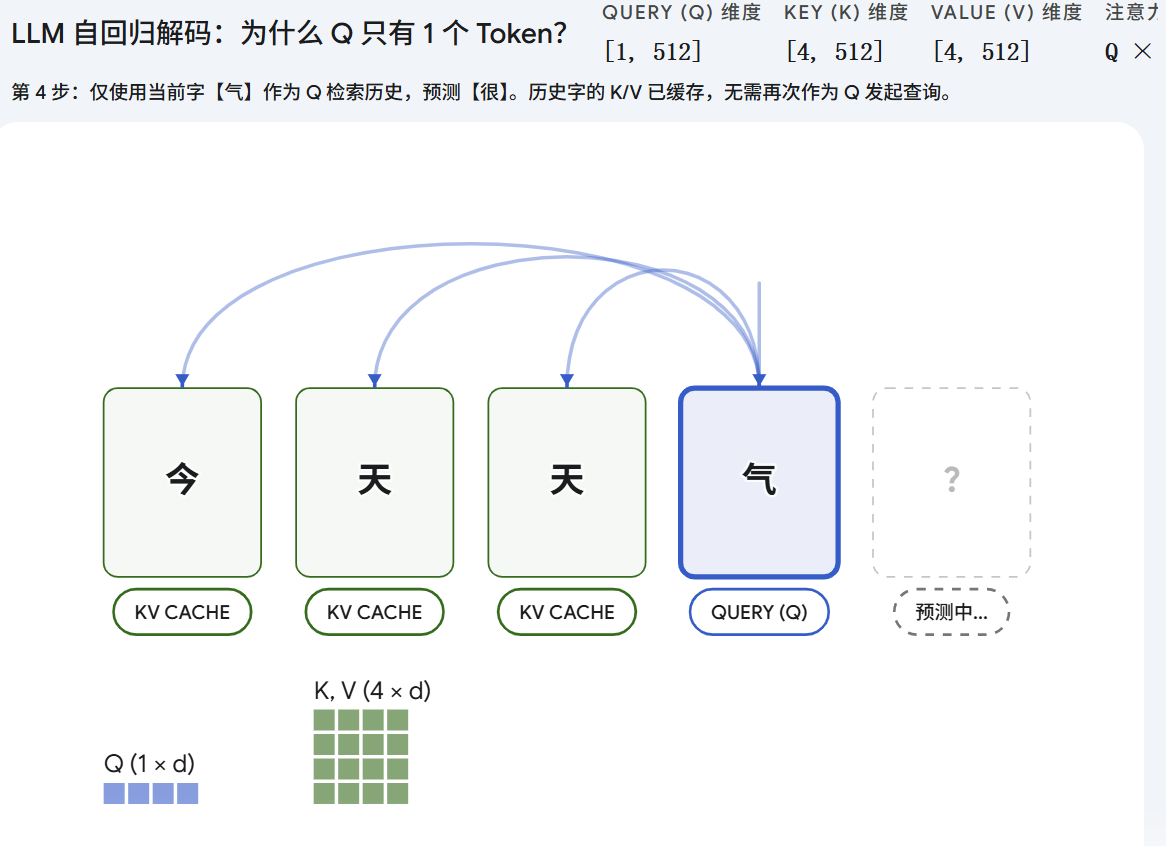
4. 为什么没有 Q Cache?(查询的映射解耦)
理解不缓存 QQQ 的核心在于明确 Attention 机制的数学本质:Attention 本质上是当前状态与历史状态之间的相似度度量(内积空间投影)。
在时刻 ttt,注意力得分矩阵的第 ttt 行元素构成为:
Scoret,j=qt⋅kjTdk(j≤t) \text{Score}_{t, j} = \frac{q_t \cdot k_j^T}{\sqrt{d_k}} \quad (j \le t) Scoret,j=dk qt⋅kjT(j≤t)
我们可以观察到:
- qtq_tqt 的生命周期仅限于当前时刻 ttt 。它是用来衡量 xtx_txt 与历史 K≤tK_{\le t}K≤t 之间相关性的算子。
- 当时间步推进到 t+1t+1t+1 时,模型需要度量的是新输入 xt+1x_{t+1}xt+1 与历史信息的相似度,即计算 qt+1⋅K≤t+1Tq_{t+1} \cdot K_{\le t+1}^Tqt+1⋅K≤t+1T。
- 历史查询向量集合 Q<t=q1,q2,...,qt−1Q_{<t} = q_1, q_2, \\dots, q_{t-1}Q<t=q1,q2,...,qt−1 参与的是过去时刻的输出计算,它们不参与 第 ttt 时刻的任何代数运算。
结论:
KKK 和 VVV 构成了全局累加的上下文特征基(Contextual Basis) ,需要被持久化保存;而 QQQ 则是游离于特征基之外的瞬时算子(Instantaneous Operator) 。用完即弃的数学属性决定了无需且不能为 QQQ 分配显存缓存。
关于 KV Cache 的必须了解的核心知识
为了应对工业级的大模型部署,尤其是需要处理超长上下文或多模态任务时,以下几个维度是必须掌握的:
1. 推理的两个阶段:Prefill 与 Decode
理解 KV Cache,首先要明白 LLM 推理的两个截然不同的阶段:
- Prefill(预填充阶段): 处理用户的输入 Prompt。此时所有 Token 都是已知的,模型会并行计算所有输入 Token 的 K 和 V,并存入 KV Cache。这个阶段是计算密集型(Compute-Bound),GPU 算力拉满。
- Decode(解码阶段): 模型开始逐字生成回复。此时模型需要频繁从显存(HBM)中把过去所有 Token 的 KV Cache 搬运到计算单元(SRAM)中参与计算。由于每次只生成一个 Token,计算量很小,但数据搬运量极大。因此这个阶段是访存密集型(Memory-Bound)。
prefill就是用户提问计算嵌入的过程,decode就是llm开始生成answer的过程。
2. KV Cache 的显存占用计算
KV Cache 是 LLM 爆显存的罪魁祸首之一。随着序列长度(Sequence Length)的增加,它会线性膨胀。一个 Token 的 KV Cache 占用字节数计算公式如下:
Bytes per Token=2×L×Hnum×Hdim×B×Pbytes\text{Bytes per Token} = 2 \times L \times H_{\text{num}} \times H_{\text{dim}} \times B \times P_{\text{bytes}}Bytes per Token=2×L×Hnum×Hdim×B×Pbytes
- 222:代表 K 和 V 两个矩阵。
- LLL:Transformer 的层数(Layers)。
- HnumH_{\text{num}}Hnum:注意力头数(Heads)。
- HdimH_{\text{dim}}Hdim:每个头的维度(Head Dimension)。
- BBB:Batch Size。
- PbytesP_{\text{bytes}}Pbytes:精度占用的字节数(例如 FP16 为 2 bytes)。
举例: 在标准 LLaMA-2-7B(FP16)中,如果 Batch Size 为 1,每个 Token 的 KV Cache 大约占用 0.5 MB。如果上下文长度达到 128k,仅单条请求的 KV Cache 就需要 64 GB 的显存。
3. 工业界应对 KV Cache 压力的三大优化方向
在实际的工程部署中,直接使用朴素的 KV Cache 是不可行的,必须结合以下优化技术:
A. 架构层面:MQA 与 GQA
为了从模型结构上减少 KV Cache 的大小,现在的主流模型(如 LLaMA-3, Qwen)普遍放弃了标准的多头注意力(MHA),转而使用:
- MQA (Multi-Query Attention): 所有 Query 头共享同一组 K 和 V 头。KV Cache 极小,但可能损失一定的模型表现力。
- GQA (Grouped-Query Attention): MHA 和 MQA 的折中方案。将 Query 头分组,每组共享一组 K 和 V。这是目前工业界最主流的做法,能在保证性能的同时大幅缩减 KV Cache。
B. 系统工程层面:PagedAttention (vLLM)
在传统的 KV Cache 管理中,系统通常会为每个请求预先分配一块连续的显存,这会导致严重的显存碎片化(浪费高达 60%)。
- PagedAttention 引入了类似 Linux 操作系统中虚拟内存分页(Paging)的思想。它将 KV Cache 划分为固定大小的块(Blocks),在物理显存中非连续存储,并通过一张映射表来管理。这使得显存利用率接近 100%,极大地提升了系统并发吞吐量。
C. 算法与量化层面:
- KV Cache Quantization: 将原本 FP16/BF16 的缓存量化为 INT8、INT4 甚至更低比特,直接将显存占用砍半或更多。
- 上下文截断与滑动窗口(如 StreamingLLM / Attention Sinks): 发现只有最前面的几个 Token(System Prompt/注意力基底)和最近生成的 Token 最重要。因此可以只缓存这些关键 Token,丢弃中间的 Token,从而实现理论上的"无限长度"生成而不爆显存。
如果说 KV Cache 解决的是"生成新词时,如何避免重复计算"的问题,那么 FlashAttention 解决的就是"处理超长文本时,如何打破 GPU 内存读写的物理瓶颈"的问题。特别是你在向 VLM/VLA 或长文本大模型方向转型的过程中,FlashAttention 及其变体是必问的核心考点。
1. 痛点:标准 Attention 为什么"慢"且"吃显存"?
在标准 Transformer 中,计算 Attention 的公式是:
Attention(Q,K,V)=softmax(QKTdk)VAttention(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)VAttention(Q,K,V)=softmax(dk QKT)V
假设输入序列长度(上下文长度)为 NNN。
- Q,K,VQ, K, VQ,K,V 矩阵的大小是 N×dN \times dN×d。
- QQQ 和 KTK^TKT 相乘,会生成一个 N×NN \times NN×N 的注意力分数矩阵(Attention Matrix)。
- 接着对这个 N×NN \times NN×N 矩阵做 Softmax。
- 最后再和 VVV 相乘。
物理硬件的噩梦(Memory Wall):
GPU 的计算单元(ALU)计算速度极快,但它的主显存(HBM,High Bandwidth Memory,比如 80GB 的显存)读写速度相对较慢。
在标准 Attention 中,GPU 需要把那个庞大的 N×NN \times NN×N 矩阵从计算单元写回到 HBM,然后再读出来做 Softmax,再写回去,再读出来和 VVV 相乘。
当上下文 NNN 变大时(比如 32k, 128k),这个 N×NN \times NN×N 矩阵会呈平方级爆炸。模型 90% 的时间没有在做数学计算,而是在"等显存搬运数据" 。这就叫访存密集型瓶颈(Memory-Bound)。
2. FlashAttention 的破局点:硬件感知(Hardware-Aware)
FlashAttention 的作者(Tri Dao 等人)敏锐地发现:GPU 除了有一块很大但慢的 HBM(主显存),还有一块很小但极快的片上缓存(SRAM)。
FlashAttention 的核心思想就是:想尽一切办法,把计算过程留在 SRAM 里,绝不把中间那个 N×NN \times NN×N 的庞大矩阵写回主显存 HBM。
为了做到这一点,它引入了两个硬核创新:
核心机制一:分块计算 (Tiling)
既然 SRAM 太小,装不下整个 N×NN \times NN×N 的矩阵,那就把输入矩阵 Q,K,VQ, K, VQ,K,V 切成小块(Blocks) 。
每次只从主显存(HBM)中搬一小块 QQQ 和一小块 K,VK, VK,V 到 SRAM 中,在高速缓存里直接计算它们的分块 Attention 结果,然后动态更新最终结果。通过这种"蚂蚁搬家"的方式,直接绕过了生成全局 N×NN \times NN×N 矩阵的需求。
核心机制二:在线 Softmax (Online Softmax)
分块计算遇到了一个巨大的数学障碍:Softmax 怎么分块?
标准的 Softmax 需要知道一整行的所有元素,先找出最大值,再求指数和,作为分母。如果你只拿到了一小块数据,你是算不出真正的 Softmax 的。
FlashAttention 使用了巧妙的代数技巧(基于 Safe Softmax 的缩放原理),在每次处理一个新块时,动态保存并更新两个局部变量(当前的最大值和当前的指数和)。这样,即便不看全貌,也能一步步通过局部更新,算出和全局 Softmax 一模一样的精确结果。
3. 为什么它叫"Flash"?
因为引入了 Tiling 和 Online Softmax,显存的读写次数(Memory Accesses)发生了质的改变:
- 标准 Attention 读写复杂度:O(N2)O(N^2)O(N2)
- FlashAttention 读写复杂度:O(N)O(N)O(N)
虽然在数学上,它执行的乘加计算量(FLOPs)并没有减少(甚至因为重计算稍微多了一点点),但因为它大大减少了慢速显存的读写等待时间,实际运行速度(Wall-clock time)反而快了 2 到 4 倍。
关键考点:精确无损
过去很多试图解决 O(N2)O(N^2)O(N2) 问题的算法(如 Sparse Attention, Linformer 等)都是"近似算法",会损失模型精度。而 FlashAttention 是精确注意力(Exact Attention),它的计算结果与标准 Attention 没有任何区别(在浮点误差允许范围内),这使得它能无缝替换所有大模型底层的注意力代码。
4. 训练与推理(结合 KV Cache)视角的差异
你需要将 FlashAttention 和前文讲的 KV Cache 结合起来看:
| 维度 | FlashAttention | KV Cache (PagedAttention) |
|---|---|---|
| 主要解决什么问题 | 解决 N×NN \times NN×N 注意力矩阵带来的显存读写瓶颈 (Memory Wall)。 | 解决解码时历史 Token 重复计算的问题。 |
| 显存复杂度变化 | 将 Attention 过程的峰值显存从 O(N2)O(N^2)O(N2) 降到 O(N)O(N)O(N)。 | 将每个生成步骤的计算量从 O(N)O(N)O(N) 降到 O(1)O(1)O(1)(但占据庞大显存)。 |
| 推理阶段的作用 | 在 Prefill(预填充) 阶段绝对关键!因为需要一次性处理极长的 Prompt,必须用 FA 加速。 | 在 Decode(解码) 阶段绝对关键!因为逐字生成,必须缓存历史。 |
注:在 Decode 阶段,因为每次只生成 1 个 Token,Q 的长度是 1,此时计算的不再是矩阵乘矩阵(GEMM),而是矩阵乘向量(GEMV),此时也有专门针对这种场景优化的 FlashDecoding 技术。
5. 面试/工业界常考演进:FA2 与 FA3
如果你在面试算法工程岗,知道最初的 FA 是不够的:
- FlashAttention-2 (FA2): 进一步减少了非矩阵乘法(non-matmul)操作的比例,优化了线程块(Thread block)在 GPU 上的工作分配(Work Partitioning),特别是在多头注意力之间做了更好的负载均衡,使其更逼近硬件的理论极限(可达 GPU 峰值性能的 70%+)。
- FlashAttention-3 (FA3): 为最新的 Hopper 架构(如 H100 显卡)量身定制,引入了异步计算(计算与显存加载完全重叠)并原生支持了 FP8 低精度计算格式。
总结来说: KV Cache 让大模型"能够一边记一边聊",而 FlashAttention 让大模型"能够一眼看完整本财报而 GPU 不爆炸"。这两个技术的结合,才是当下长文本大模型(如 Kimi、Claude 3 200k)得以落地的物理基石。