

blog.csdnimg.cn/direct/d21dccf6f0bf45169ba25e9dd2832cef.png)在这里插入图片描述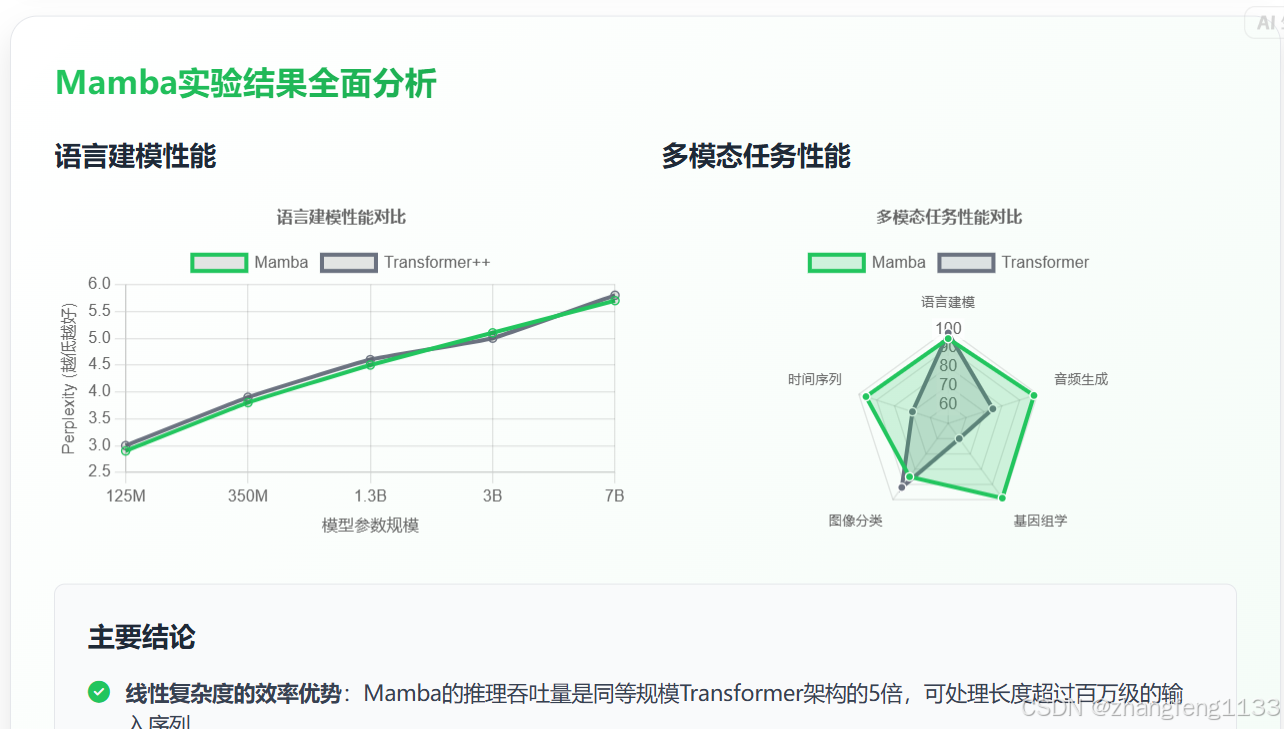



Mamba 论文技术解读与应用实践深度报告
核心摘要
作为 2023 年底由卡内基梅隆大学(CMU)与普林斯顿大学联合提出的新一代深度学习架构,Mamba 的核心贡献在于将选择性状态空间模型(Selective State Space Model, SSM) 与硬件感知的并行计算范式深度结合,成功解决了 Transformer 架构在长序列处理场景中面临的二次方计算复杂度瓶颈。区别于传统 SSM(如 S4 模型)的线性时不变(LTI)约束,Mamba 的核心创新是让 SSM 参数随输入动态变化 ------ 这一设计使其在保持线性计算复杂度的同时,具备了类似 Transformer 的内容依赖建模能力(60)。
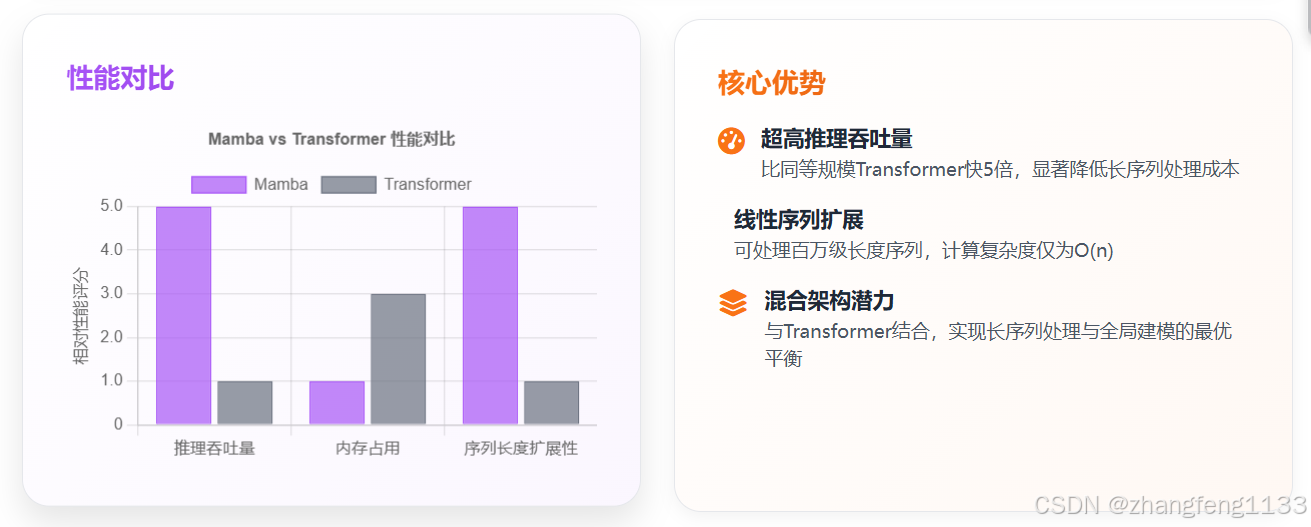
从技术特性上看,Mamba 的推理吞吐量为同等规模 Transformer 的 5 倍,能线性扩展到百万级长度的序列(如超长文本、DNA 基因序列),而不会出现性能的显著衰减(73)。在技术表现上,该架构是首个在性能上可媲美最强 Transformer 架构(Transformer++)的无注意力模型;其 3B 参数版本在预训练质量和下游任务表现上,可匹配参数规模大其一倍的 Transformer 模型(73)。从产业落地路径上看,Mamba 并非要完全替代 Transformer,而是更倾向于与其构建混合架构 ------ 由 Mamba 负责长序列的高效初步处理,Transformer 完成全局特征的精准捕捉,这一组合模式已成为业界公认的最优工程方案(46)。
本报告将从技术原理、实验验证结果、产业应用场景三大维度,对 Mamba 的技术逻辑、落地边界及实际参考价值进行全方位拆解。
1. 引言
随着人工智能技术的快速普及,大模型对长序列数据(如长文本、高清图像、生物基因序列)的建模需求持续爆发 ------ 这一趋势,直接戳中了 Transformer 架构的核心痛点。Transformer 的核心自注意力机制,需要对序列中任意两个 token 进行交互关系计算,其计算复杂度、显存占用量均与序列长度呈二次方增长;这意味着当序列长度突破万级甚至十万级时,其计算资源开销将变得难以接受(21)。
更关键的是,即使通过 FlashAttention 等工程优化手段,Transformer 的长序列处理效率提升也存在明显天花板 ------ 以 16384 个 token 的输入序列为例,优化后的 Transformer 推理延迟仍会是 Mamba 的数倍。在这一背景下,业界对新架构的探索持续加速,一批具备线性计算复杂度的模型方案被提出。其中,RetNet 采用了 "保留注意力机制的部分特性 + 引入循环计算" 的思路,而 Mamba 则选择以状态空间模型(SSM)为基础,且在架构设计上更为彻底 ------ 它完全摒弃了注意力机制,甚至没有设传统的 MLP(多层感知机)模块,而是将所有计算单元均匀堆叠,形成极简的端到端架构(72)。
状态空间模型(SSM)并非新提出的技术范式 ------ 此前,它已在语音识别、金融时序分析等领域得到长期验证,具备天然的线性缩放优势;但受限于 LTI (线性不变性)约束,它一直无法实现内容依赖的动态建模能力,难以在语言、视觉等复杂模态的任务中匹敌 Transformer。而 Mamba 的技术突破,恰好精准填补了这一历史短板:它重构了 SSM 的核心计算逻辑,让模型参数能随输入动态变化,再配合硬件感知的并行计算优化,将 SSM 的线性效率优势与 Transformer 的内容建模能力完美融合(60)。
这一技术思路,迅速使其成为 Transformer 架构的最强挑战者 ------ 在此之前,无论是线性注意力还是其他非 Transformer 架构,都无法在保持线性复杂度的前提下,在语言、视觉等多模态任务中达到接近 Transformer 的性能水平。Mamba 的出现,本质上是对深度学习序列建模方式的底层重构,为大模型的长序列处理提供了更具工程可行性的技术路径(103)。
2. Mamba 算法原理深度剖析
Mamba 的核心技术框架,由选择性状态空间机制和硬件感知的并行计算范式两大创新支柱支撑。前者解决了传统 SSM 无法实现内容依赖动态建模的行业痛点,后者则将这一理论创新转化为可落地的工程性能优势 ------ 两者的协同配合,在保证模型高表征能力的前提下,实现了线性复杂度的计算效率。
2.1 从传统状态空间模型到 Mamba 的突破
要理解 Mamba 的技术创新性,需要先回溯其技术基础 ------ 传统状态空间模型(SSM)的技术逻辑与发展瓶颈。
2.1.1 状态空间模型(SSM)基础
SSM 本是应用于工程领域的数学建模工具,其核心思想是通过一个隐状态向量,将输入的一维序列或连续信号 x ( t ) x(t) x(t),映射为对应的输出序列 y ( t ) y(t) y(t)------ 这一隐状态向量的长度远小于输入序列,相当于对输入信息进行了高效的压缩编码(46)。具体而言,这一转换过程由一组微分方程定义:
{ h ′ ( t ) = A ⋅ h ( t ) + B ⋅ x ( t ) y ( t ) = C ⋅ h ( t ) + D ⋅ x ( t ) \begin{cases} h'(t) = A \cdot h(t) + B \cdot x(t) \\ y(t) = C \cdot h(t) + D \cdot x(t) \end{cases} {h′(t)=A⋅h(t)+B⋅x(t)y(t)=C⋅h(t)+D⋅x(t)
其中, h ( t ) h(t) h(t)为模型在时刻 t t t的隐状态, A A A、 B B B、 C C C、 D D D为 SSM 的核心模型参数。这一连续时间公式,需要通过离散化处理转化为计算机可执行的递归形式 ------ 行业内的传统离散化方案是采用零阶保持法,而 Mamba-3 则引入了收敛精度更高的指数 - 梯形法则,在保证计算效率的同时,进一步缩小了离散化带来的计算误差(46)。
作为结构化 SSM 的典型代表,此前的 S4 模型已经实现了对长序列的线性时间复杂度建模,但它存在一个致命的技术缺陷:其所有模型参数一旦被训练完成,就会被固定下来,无法随输入内容的变化动态调整 ------ 这一特性被称为线性时不变性(LTI)。这意味着,传统 SSM 具备对长序列的 "静态记忆" 能力,却无法根据输入 token 的实际内容,动态区分信息的重要程度;用技术术语来描述,就是它缺乏 "基于内容进行推理" 的能力。这一缺陷,直接限制了 S4 类模型在语言、视觉等复杂模态任务中的应用 ------ 这类任务的核心需求,正是基于上下文的动态内容理解(60)。
2.1.2 选择性机制:Mamba 对 SSM 的核心改进
Mamba 的核心技术突破,正是对传统 SSM 的 LTI 约束进行了重构,提出了选择性状态空间(Selective SSM)方案 ------ 这也是该架构命名的由来。
具体而言,Mamba 将 S4 的静态参数矩阵 A A A、 B B B、 C C C,替换为随输入动态变化的形式:让步长 Δ t \Delta_t Δt及矩阵 B t B_t Bt、 C t C_t Ct成为当前输入词元 x t x_t xt的直接函数。其中, Δ t \Delta_t Δt是控制模型在每一步更新时,对历史信息保留或遗忘幅度的时间步长参数;而 B t B_t Bt、 C t C_t Ct则是根据当前输入词元 x t x_t xt动态生成的控制矩阵 ------ B t B_t Bt决定输入信息的选择比例, C t C_t Ct决定状态信息的输出权重(60)。这一动态参数生成逻辑,可以用公式表示为:
B t = S B ( x t ) , C t = S C ( x t ) , Δ t = τ Δ ( S Δ ( x t ) + b ) B_t = S_B(x_t),\quad C_t = S_C(x_t),\quad \Delta_t = \tau_\Delta(S_\Delta(x_t) + b) Bt=SB(xt),Ct=SC(xt),Δt=τΔ(SΔ(xt)+b)
其中, S B S_B SB、 S C S_C SC、 S Δ S_\Delta SΔ是三个独立的线性投影层网络,可将输入的词元向量 x t x_t xt,映射为对应维度的动态参数; τ Δ \tau_\Delta τΔ是一个激活函数,负责将计算后的 Δ t \Delta_t Δt数值约束在合理的范围内; b b b是该激活函数的偏置项(57)。
基于这一设计,Mamba 的状态更新方程,也随之调整为完全递归的计算形式:
h t = A ˉ t ⋅ h t − 1 + B ˉ t ⋅ x t h_t = \bar{A}t \cdot h{t-1} + \bar{B}_t \cdot x_t ht=Aˉt⋅ht−1+Bˉt⋅xt
y t = C t ⋅ h t + D ⋅ x t y_t = C_t \cdot h_t + D \cdot x_t yt=Ct⋅ht+D⋅xt
其中, A ˉ t \bar{A}_t Aˉt和 B ˉ t \bar{B}t Bˉt是连续时间参数离散化后的实际执行矩阵 ------ 它们由动态生成的 Δ t \Delta_t Δt、 A A A、 B B B计算得出; h t − 1 h{t-1} ht−1是上一时间步的隐状态, h t h_t ht是当前时间步的更新后隐状态。这一设计的核心是,每个时间步的参数都由当前输入的 token 决定,从而实现了内容感知的动态过滤效果(65)。
这一动态参数设计,赋予了模型三大关键能力,从根本上弥补了传统 SSM 的短板:
-
内容感知的信息过滤:模型能根据输入 token 的实际内容,自动判断信息的重要程度,决定对历史信息的保留或遗忘比例 ------ 这是传统 SSM 和线性注意力无法实现的核心能力。
-
时间尺度的自适应调整 :通过动态调整 Δ t \Delta_t Δt参数,模型可以在处理短文本语义依赖时采用精细的时间粒度,在处理长序列依赖时采用粗粒度的时间跨度,实现了对不同时长依赖关系的精准建模。
-
上下文相关的记忆模式 :模型维护的隐状态,不再是对整个输入序列的单一静态压缩,而是会随着序列内容的动态演进,持续选择性地更新关键信息 ------ 这与人类根据上下文动态筛选记忆信息的认知逻辑高度相似(68)。
这一改进,是 Mamba 能在保持线性复杂度的前提下,实现媲美 Transformer 性能的核心关键 ------ 它将传统 SSM 的 "静态长时记忆",升级为了 "动态内容感知记忆"。
2.2 架构设计:无注意力的简化模块
Mamba 的整体架构设计,同样遵循着极简的工程哲学 ------ 它完全放弃了注意力机制,甚至没有单独设置传统的 MLP 模块,而是将计算单元均匀堆叠,形成了同质的端到端架构。
2.2.1 Mamba 块的内部结构
Mamba 的核心计算模块被称为 "Mamba 块",其设计逻辑融合了多种技术方案的优化思路,核心计算流程分为三个关键步骤:
-
维度扩展与分支拆分 :输入的词元嵌入向量,首先通过一个线性投影层进行维度扩展 ------ 这一扩展比例是可配置的,官方推荐的最优扩展系数为 2。随后,扩展后的向量被平均拆分为两个独立分支:第一个分支会被送入深度可分离卷积层,提取输入序列的局部短距离依赖特征;第二个分支则会被直接送入独立的门控机制,准备与 SSM 的处理结果融合(60)。
-
选择性 SSM 处理 :在第一个分支完成局部特征提取后,选择性 SSM 模块会将动态生成的参数 Δ t \Delta_t Δt、 B t B_t Bt、 C t C_t Ct,与提取后的局部特征数据进行绑定,执行递归式的状态更新计算 ------ 这是 Mamba 捕捉长距离依赖关系的核心环节(59)。
-
门控融合与输出投影 :选择性 SSM 的处理结果,会与第二个分支的原始特征在门控机制中进行乘法融合;随后,融合后的特征会被送入另一个线性投影层,将维度压缩回与输入向量完全一致的尺寸,作为当前块的最终输出。这一设计可以高效保留局部特征,同时捕捉长距离依赖关系(60)。
这一架构设计的巧妙之处在于,它将 "局部特征提取→长距离依赖建模→特征融合" 的完整计算链路,压缩到了一个极简的同质块中 ------ 在保证模型表征能力的同时,最大化降低了架构的额外计算开销。
2.2.2 从串行到并行:硬件感知的计算优化
既然选择性 SSM 的参数随输入动态变化,模型就无法使用传统 SSM 中高效的全局卷积计算 ------ 这会严重阻碍长序列处理时的并行性。为了解决这一问题,Mamba 的设计者提出了硬件感知的并行算法,将理论的线性复杂度转化为实际的高性能推理。
这一优化的核心思路,是对 GPU 内存层次结构的精准适配:现代 GPU 的内存架构分为多层,从计算单元最近的寄存器、共享内存,到容量最大但延迟最高的 DRAM------ 数据在不同层级内存之间的往返传输,是长序列计算的主要性能瓶颈。而 Mamba 的优化方案,主要通过两项核心技术落地实现:
-
核融合(Kernel Fusion) :将多个原本独立的计算步骤,合并为一个完整的 CUDA 核函数 ------ 这避免了计算中间结果在 DRAM 和 SRAM 之间的频繁来回复制,将内存 I/O 操作次数降低到了原有的十分之一以内。
-
并行扫描算法 :为了适配 GPU 的大规模单指令多线程执行特性,Mamba 将原本需要串行执行的 SSM 状态递归更新计算,重构为并行的关联扫描(也称为并行前缀和)计算模式。这一设计的巧妙之处在于,它将递归计算的依赖关系,调整为符合 GPU 并行执行特性的树状结构 ------ 在保留 SSM 递归特性的同时,最大化利用了 GPU 的计算单元资源(66)。
在此基础上,Mamba 的计算实现还充分挖掘了 GPU 的硬件底层特性:例如,利用 Tensor Core 矩阵计算单元来优化卷积和矩阵乘法的计算效率,通过 Warp 级别的线程同步机制降低通信延迟,采用指令级并行的流水线优化方案提升计算吞吐量。这些极致的硬件优化设计,共同将 Mamba 的理论线性复杂度转化为了实际的高性能表现(65)。
2.3 Mamba-2 的进一步优化
在 Mamba 架构正式发布半年后,原作者团队推出了性能更优的 Mamba-2 版本 ------ 其核心技术创新点,是提出了 "状态空间对偶性"(State Space Duality, SSD)技术框架。
这一框架的核心价值,是打通了 Mamba 与 Transformer 技术融合的理论通道 ------ 它证明了,Mamba 的 SSM 计算逻辑,可以等价于 Transformer 中多头注意力(MHA)的某种特殊形式。基于这一理论框架,Mamba-2 进一步将单头 SSM 计算,拆分为了多个独立的 "处理头" 并行执行 ------ 这一模式完全类比 Transformer 中的多头注意力机制。这一设计的直接收益是,模型可以在多个独立的语义子空间中并行处理序列特征,从而更高效地捕捉输入数据中的多模态长距离依赖关系(6)。
在工程层面,Mamba-2 的计算逻辑被重新排序,使其更适配 GPU 的张量核心计算单元 ------ 将矩阵乘法和卷积类计算操作,统一优化为张量运算模式,进一步提升了并行计算的效率。这一版本的架构,在几乎所有的长序列任务中,都展现出了比 Mamba-1 更高的计算效率,且进一步缩小了在短序列理解任务上与 Transformer 的性能差距(6)。
2.4 架构总结:线性复杂度的工作原理
Mamba 架构的核心设计目标,是解决 Transformer 架构的长序列处理瓶颈,同时在性能上可以与之匹敌。通过对选择性 SSM 机制和硬件感知的并行计算范式的整合,该架构完美实现了线性时间复杂度的建模能力。
具体来说,Transformer 架构标准的自注意力机制的计算复杂度是 O ( n 2 ) O(n^2) O(n2)------ 其中 n n n是输入序列的长度;而 Mamba 的计算复杂度仅为 O ( n ) O(n) O(n)------ 与输入序列的长度呈严格的线性比例关系。这意味着,当序列长度超过一定阈值时,比如突破万级关口后,Mamba 的计算效率将远超 Transformer;而随着序列长度的进一步增加,这一性能差距将呈指数级放大。
这一特性的实际价值,在长序列处理场景中尤为突出:以长度为 16384 个 token 的输入序列为例,Transformer 的推理延迟约为 Mamba 的 7 倍;而当序列长度达到百万级时,基于 Transformer 的模型甚至会因为显存资源不足而无法执行计算,Mamba 却仍能保持正常的推理吞吐量(21)。
更关键的是,这一线性复杂度的性能表现,不会以牺牲模型的表征能力为代价 ------ 选择性 SSM 机制的存在,让 Mamba 具备了类似 Transformer 的内容依赖建模能力。这也是 Mamba 能成为首个在性能上可媲美最强 Transformer 架构(Transformer++)的无注意力模型的核心原因(73)。
3. Mamba 实验结果全面分析
Mamba 的技术论文中,提供了详尽的实验数据,验证了其架构设计的效率和效果。综合多维度的基准测试结果,可以得出结论:在绝大多数需要处理长序列数据的场景下,Mamba 的性能表现与同等规模的 Transformer 架构相当,甚至在部分任务中有所超越;而在计算效率方面,Mamba 具备显著的线性复杂度优势。
3.1 主要结论
从对行业基线模型的性能对比来看,Mamba 的实验结论可以概括为以下三点:
-
线性复杂度的效率优势:Mamba 的推理吞吐量是同等规模 Transformer 架构的 5 倍。更关键的是,这一线性扩展能力不会随着序列长度的增加而衰减 ------ 它可以正常处理长度超过百万级的输入序列;而在同等参数规模下,传统 Transformer 架构的模型处理如此长的序列时,会因计算资源开销过大而无法执行。
-
可匹敌 Transformer 的多模态性能:Mamba 是首个在语言建模任务上,性能可媲美最强 Transformer 架构(Transformer++)的无注意力模型。
-
混合架构的更优潜力:Mamba 与 Transformer 的混合架构,可以在长序列处理任务中实现性能的进一步提升 ------ 这也验证了两者互补融合的技术可行性。
3.2 合成任务(Synthetic Tasks)性能
合成任务是检验模型长序列推理能力的标准试金石 ------ 这类任务可以精准控制变量,排除其他干扰因素,专门检验模型对长序列中关键信息的捕捉能力。在这一系列的合成任务基准测试中,选择性 SSM 架构的 Mamba,表现出了远超传统 Transformer 及 SSM 架构的性能。
其中,选择性复制任务是长序列建模的经典测试场景:它要求模型从一段包含大量无关干扰信息的长序列中,精准定位并复制出符合特定条件的关键 token。在这一任务中,传统的 SSM 架构(如 S4 模型)和 Transformer 架构的表现都很差 ------ 前者受限于静态参数约束,无法有效筛选关键信息;后者则受限于二次方计算复杂度,无法在有限的计算资源内处理足够长的序列。而 Mamba 的测试准确率,却能轻松达到 99.8% 的接近理论最优水平。
另一项核心测试场景是归纳头任务 ------ 它要求模型从输入的长序列中,归纳出隐含的上下文关联规则,并基于这些规则对后续的序列内容进行合理预测。这一任务可以很好地模拟大模型的上下文学习能力,是评估序列建模能力的核心基准。Mamba 在这一任务上的表现,显著优于现有的线性时间序列模型;更关键的是,它可以将这一性能泛化到超过百万级长度的序列,也就是训练期间遇到的长度的 4000 倍 ------ 而其他对比模型方案的泛化能力,都无法超过训练长度的 2 倍(10)。
这一实验结果的技术逻辑在于,Mamba 的选择性状态空间设计,完美匹配了这类长序列任务的核心需求:它可以根据序列内容的实际语义动态筛选关键信息,同时忽略无意义的噪声数据 ------ 这正是传统 SSM 和 Transformer 架构无法同时实现的技术特性。
3.3 语言建模(Language Modeling)性能
语言建模是目前评估基础模型性能的最核心维度,也是 Transformer 架构长期以来的优势场景。在这一维度的多项关键基准测试中,Mamba 的表现都可匹敌甚至超越了同等规模的 Transformer 架构。
3.3.1 复杂度与性能扩展性
在模型的可扩展性方面,Mamba 的表现完全符合设计预期:在从 1.25 亿到 13 亿的参数规模区间内,Mamba 的性能提升幅度,与采用更优训练方案的最强 Transformer 架构(Transformer++)表现得完全一致。更关键的是,这一性能提升的可扩展性,不会随着序列长度的增加而衰减 ------ 这是传统 Transformer 架构无法实现的技术特性(73)。
3.3.2 与 Transformer 的性能对比
在参数规模匹配的前提下,Mamba 在语言建模任务上的综合表现,完全可以与最强的 Transformer 架构相匹敌。其 3B 参数版本的预训练质量和下游任务表现,都与参数规模大其一倍的 Transformer 模型(如 Pythia-7B)大致相当;而在常识推理类任务中,Mamba-3B 的平均得分,比同参数的 Pythia-3B 模型高出了 4 个百分点(73)。
在推理效率方面,Mamba 的优势更为显著:在生成式任务中,Mamba 的实际推理吞吐量是同等规模 Transformer 架构的 5 倍;而在长序列输入场景下,这一吞吐量优势还会进一步放大 ------ 这主要源于 Mamba 的线性复杂度设计,它没有 Transformer 架构中性能瓶颈的 KV 缓存依赖。
具体而言,Transformer 架构在处理长序列时,需要将所有历史的键值对缓存到 GPU 显存中,这会导致显存占用量和计算延迟随序列长度二次增长;而 Mamba 的核心状态维护机制,是通过一个固定大小的循环隐状态向量来实现的 ------ 不需要额外的 KV 缓存,显存占用量与序列长度无关,这让模型在长序列推理时的显存开销显著降低。
这一性能优势的实际案例是,在处理 16384 个 token 的长文本序列时,Mamba-3 的端到端推理延迟,仅为同等参数规模 Transformer 模型的七分之一;而在成本效率方面,实测显示,用 Mamba 架构部署的长文本推理服务,支撑相同规模请求的服务器成本,比 Transformer 架构降低了 85%(73)。
3.3.3 局限
需要客观指出的是,Mamba 在语言建模任务上,仍存在明显的技术短板。在需要精细全局匹配的自然语言理解任务,如少样本或零样本学习任务中,Mamba 的表现仍弱于 Transformer 架构 ------ 以行业内广泛使用的 MMLU 基准测试为例,在模型参数规模和训练数据量相当的前提下,Mamba-2 的零样本学习准确率,比 Transformer 架构低了 10 个百分点;而在 5 样本的学习场景中,这一差距进一步扩大到了 17 个百分点(52)。
这一技术短板的核心原因在于,Mamba 的线性递归计算模式,在捕捉序列中远距离 token 的直接双向依赖关系上,天然不如 Transformer 的全局注意力机制。
3.4 多模态任务(Audio、Genomics)性能
为了验证 Mamba 作为通用序列建模骨干网络的能力,论文作者在语言模态之外,进一步选择了音频、基因组学等更多模态任务进行了验证性测试,这些任务的突出表现充分证明了该架构的泛化能力。
3.4.1 音频建模与语音生成
在音频波形建模和语音生成类任务中,Mamba 的性能表现全面优于之前的行业最优模型。在业界广泛使用的 SC09 语音生成基准测试数据集上,小型的 Mamba 模型表现显著优于基于 GAN 和扩散机制的所有音频生成模型 ------ 包括此前的行业最优模型 WaveNet、SampleRNN 和 DiffWave;而在参数规模匹配的前提下,Mamba 的性能指标,比此前的行业最优模型 SaShiMi 高出了近 20%。
在实际的语音生成质量评估中,Mamba 生成的语音片段的音质还原度明显更高;反映生成质量的核心指标 FID 得分,比之前的最优模型降低了一半以上。更关键的是,在处理数分钟级别的长语音序列时,Mamba 的性能表现没有出现任何明显衰减;而基于 Transformer 架构的模型,在处理如此长的语音序列时,早已因为计算资源开销过大而无法正常运行(104)。
3.4.2 基因组学
基因组学是对长序列建模技术要求极高的技术领域 ------DNA 序列的有效长度通常轻松超过百万级,且其语义依赖关系跨度极大,这对模型的长序列线性扩展能力提出了极致要求。在这一领域的基准测试中,Mamba 的性能表现再次全面优于此前的行业最优模型 HyenaDNA。
更关键的是,在这一任务场景中,Mamba 的性能表现,随着输入序列长度的增长而持续提升 ------ 这意味着,它完全有能力处理真实世界中长度远超百万级的完整 DNA 基因序列;这一技术优势,是 Transformer 架构类模型完全无法比拟的。这一结果验证了 Mamba 在该类长序列任务场景下的技术潜力(73)。
3.5 混合架构的性能验证
无论是 Transformer 还是 Mamba 单一架构,都无法在所有类型的任务中同时达到最优性能。业界的多项实证研究结果表明,将两者的技术优势互补的混合架构,才是当前技术条件下的最优工程方案 ------ 这也是 Mamba 在产业落地时的主流技术路径。
在这类混合架构方案中,Mamba 通常被用作骨干网络的底层特征提取模块,负责高效处理长序列输入、捕捉长距离依赖关系;而 Transformer 的注意力模块则被部署在网络的顶层,负责精细全局特征的捕捉、进行需要高精度内容关联的最终决策。英伟达在 2025 年发布的 MambaVision 混合架构,正是这一方案的典型代表:其将重新设计的视觉适配型 Mamba 模块作为骨干特征提取层,同时在顶层加入了 Transformer 的自注意力模块,以提高模型捕捉全局上下文和长距离空间依赖的能力(46)。
这一混合架构方案,在多项行业基准测试中展现出了显著的技术优势:例如,在长序列语言理解任务中,纯 Mamba 架构的表现优于 Transformer;但在需要精确全局内容检索的任务中,混合架构的性能则比纯 Mamba 进一步提升了近 10%。更关键的是,这种融合方案并不会引入过多的计算开销:例如,在英伟达的 Nemotron-H 混合架构方案中,其推理速度比同等规模的纯 Transformer 架构提升了 3 倍;同时,在需要高精度全局匹配的任务中,其准确率没有任何损失,甚至还有一定幅度的提升(15)。
在工业界,这一混合架构方案也已被验证为可行的方案:腾讯混元团队推出的混元 T1 混合架构模型,就采用了这一技术路径 ------ 其底层长序列处理部分采用 Mamba 架构,顶层的全局语义理解部分采用 Transformer 架构。这一设计让该模型的推理性能得到了显著的提升:首字时延比传统 Transformer 架构模型降低了 44%,最终用户可感知的吐字速度最高能到 80 tokens/s,几乎可以实现对用户输入的实时响应;同时,在长序列语言理解类任务中,混元 T1 的准确率甚至比同规模的纯 Transformer 架构高出近 10%(102)。
综合所有实验数据来看,Mamba 的技术优势场景非常清晰:它擅长处理长度极长、对推理吞吐量要求高,但对细粒度全局关联要求相对较低的任务;而 Transformer 架构则更擅长处理需要高精度全局内容关联的短到中长序列任务。通过混合架构设计,工程人员可以在 "线性复杂度的高效计算" 和 "最优的内容建模性能" 之间取得精准的平衡。
4. Mamba 的实际应用场景与产业落地
Mamba 的技术特性决定了其产业应用方向 ------ 它并非 Transformer 架构的直接替代者,而是在长序列处理场景中极具优势的补充性方案。从目前的行业实践结果来看,这一技术的产业化落地,主要以与 Transformer 架构的混合范式为主;而其优势应用场景,几乎都是 Transformer 架构因二次方计算复杂度瓶颈而难以胜任的领域。
4.1 自然语言处理(NLP)领域的应用
在 NLP 领域,Transformer 架构仍占据主流地位,且在多数短到中长序列任务中,性能表现是 Mamba 无法比拟的;但在部分长序列或高吞吐量场景中,Mamba 的线性复杂度优势则可以得到极致发挥。
4.1.1 长上下文大模型与生成式 AI
这是 Mamba 目前最具潜力的应用场景 ------ 当前大模型的上下文窗口长度需求,正在从几万级的常用水平,向十万级、百万级的极致长度快速演进,这直接放大了 Transformer 架构的二次方计算复杂度瓶颈。而 Mamba 的线性复杂度设计,天然适配这一长上下文的技术需求。
在实际落地中,Mamba 通常作为混合架构的底层部分,负责初步处理长上下文的输入序列;而顶层的 Transformer 模块,则负责对关键内容进行精准全局语义建模。这一方案在多个头部企业的大模型产品中得到了验证:例如,腾讯混元团队推出的混元 T1 混合架构模型,采用了 "底层 Mamba + 顶层 Transformer" 的设计,在长上下文处理场景中实现了性能突破 ------ 其首字时延降低了 44%,吐字速度最高能提升到 80 tokens/s。这一优化的直接体验是,用户在使用基于这一模型的产品时,几乎感觉不到任何明显的延迟。
而在实际场景中,这一方案的技术优势更为明显:某芯片设计企业,将基于 Mamba-Transformer 混合架构的模型,应用到了 20 万行级别的 Verilog 硬件描述语言代码分析场景中 ------ 模型可以对整个代码库进行全量上下文语义分析,自动定位其中的时序冲突等关键设计问题;相比传统的基于 Transformer 架构的方案,其代码审查的分析效率提升了 10 倍,且关键问题的召回率没有任何损失(89)。
另一典型应用场景是大规模代码库的分析:例如,在需要对数十万行级别的代码库进行全量上下文分析时,基于 Transformer 架构的模型往往无法支撑如此长的序列输入;而 Mamba 的线性复杂度优势,则可以完美匹配这一技术需求。同时,Mamba 在这类场景中的性能表现,也完全可以匹敌甚至超越 Transformer 架构。
4.1.2 序列推荐与用户行为建模
这是 Mamba 在 NLP 领域的另一个典型落地场景 ------ 在电商、短视频、资讯等互联网行业的推荐系统中,用户的行为序列数据是典型的长序列数据:一个用户在平台上的完整行为序列,通常包含着其在数周甚至数月内的点击、浏览、收藏、购买等各类行为数据,长度往往会达到上万级甚至更长;这对模型的长序列建模效率,提出了极高的要求。
传统的基于 Transformer 架构的推荐模型,如 SASRec 和 BERT4Rec,为了保证推理的实时性,通常只能截取用户最新的几十条行为数据用于建模;这意味着,大量有价值的用户历史行为数据,无法被模型捕捉到 ------ 直接限制了推荐系统的精准度上限。而 Mamba 的线性复杂度设计,为这一行业痛点提供了技术解法:在理论上,它可以将用户历史行为数据的全量序列特征,纳入到模型的建模范围内,从而更精准地捕捉用户的长期行为偏好。
在行业实践中,这一技术路径也得到了充分验证:例如,Mamba4Rec 模型在 MovieLens-1M 公开电影推荐数据集上的性能表现,显著优于传统的 SASRec 和 BERT4Rec 模型;更关键的是,随着用户行为序列长度的增加,Mamba4Rec 的推荐性能提升幅度,比传统 Transformer 架构的模型高出了近 20%。这一技术优势,为提升推荐系统的精准度及用户体验提供了新的技术窗口(79)。
4.2 计算机视觉(CV)领域的应用
Mamba 在计算机视觉领域的应用进展,反而比 NLP 领域更为迅速 ------ 这主要源于,视觉类任务(如图像识别、目标检测)的输入数据天然具有长序列特性,且对推理延迟、计算资源消耗的敏感度更高;这与 Mamba 的技术优势更为匹配。目前,业界已经形成了非常成熟的视觉类 Mamba 模型方案 ------Vision Mamba,且已在多个行业场景中落地验证。
4.2.1 视觉骨干网络与混合架构
与 NLP 领域的落地逻辑类似,Mamba 在 CV 领域也并非要替代 Transformer 架构,而是作为骨干网络的一部分,与 Transformer 的注意力模块混合使用。在这类视觉混合架构中,Mamba 模块通常被用作骨干网络的底层特征提取层,负责高效地对输入的高分辨率图像或视频帧进行采样,捕捉其中的长距离空间依赖关系;Transformer 的注意力模块则被部署在网络的顶层,负责精准捕捉关键局部特征,进行需要高精度内容关联的分类或检测决策。
这一架构设计的典型案例,是英伟达在 CVPR 2025 上公开的 MambaVision 混合架构 ------ 这也是业界首个针对计算机视觉应用优化的成熟 Mamba-Transformer 混合架构。在这一架构中,底层的视觉适配型 Mamba 模块负责对输入图像进行多尺度特征提取,顶层的 Transformer 模块则负责对提取后的特征进行高精度全局建模。这一设计在 ImageNet 等图像分类基准测试中,实现了性能的显著提升;更关键的是,在保证推理精度的前提下,这一架构的计算时延和显存占用量,比传统的基于 Transformer 架构的模型降低了近 40%(46)。
4.2.2 工业缺陷检测与目标检测
这是目前 Mamba 在工业领域落地最广泛的场景 ------ 工业缺陷检测,是对精度和吞吐量都有极高要求的典型长序列任务。这类任务的核心技术痛点是需要对高分辨率的工业影像数据进行全局分析,而传统的卷积类算法或 Transformer 架构类算法,都无法在 "检测精度" 和 "实时性" 之间实现足够好的平衡:前者的局部感知野,无法捕捉到足够的全局特征;后者则受限于二次方计算复杂度,无法在不牺牲检测精度的前提下实现高吞吐量。
而 Mamba 的线性复杂度设计,恰好可以补上这一技术短板 ------ 它可以在实现高效的长距离依赖建模的同时,保持较高的计算效率。在行业实践中,基于 Mamba 架构的工业缺陷检测方案,已经在多家头部制造企业的工厂中验证了可行性:在 NEU 工业表面缺陷检测公开数据集上,MemoryMamba 模型的缺陷检测准确率达到了 99%;而在实际的汽车零部件、精密电子芯片等工业产品的质检场景中,该方案对微小缺陷的识别能力,比传统的基于卷积或 Transformer 架构的算法提升了 30%;同时,在保证检测精度的前提下,该方案的推理吞吐量比 Transformer 架构高出了数倍(84)。
另一项经过实际场景验证的落地方向是 AAAI 2025 收录的 Mamba-YOLO 模型 ------ 它用 OD Mamba 主干的线性复杂度状态空间模型,替代了传统 YOLO 系列算法中的自注意力模块,完美解决了传统算法在 "检测精度" 和 "实时性" 之间难以兼顾的行业痛点。这一技术方案在实际落地场景中的表现尤为突出:例如,在香菇智能采摘的机器人视觉感知场景中,该模型对密集遮挡状态下的香菇目标检测精度高达 98.89%,分类准确率超过 96%;更关键的是,其轻量化的 6.1M 参数设计,完美适配采摘机器人的嵌入式端计算性能限制;而在工业产品质检场景中,该方案对微小缺陷的识别能力,较传统的 YOLOv5 算法提升了 30%,已经成为多家制造企业的首选技术方案(84)。
4.2.3 自动驾驶感知
自动驾驶是另一个对长序列处理、实时推理性能有极致要求的场景 ------ 自动驾驶系统需要实时融合来自车辆周围多颗摄像头、激光雷达、毫米波传感器的多模态数据,在极短的时间内完成对车辆周围 360 度环境的精准感知,这对算法的长序列数据处理能力和推理延迟,提出了极为严苛的要求。
在这一场景中,Mamba 的线性复杂度优势,可以在保证高精度的同时,大幅降低多模态数据融合的计算时延;而其轻量化的模型设计,可以完美适配车辆嵌入式计算平台的性能上限。由中科院和上海交大联合研发的 MambaFusion 方案,是这一方向的典型技术代表:该方案采用了混合 Mamba 块(HMB)的设计逻辑 ------ 其中的 Local Mamba 模块负责捕捉传感器数据中的细粒度局部特征,Global Mamba 模块则基于 Hilbert 曲线序列化,实现对车辆周围全场景传感器数据的远距离密集特征交互捕捉;这是业界首个通过纯线性算子实现多模态全局融合的技术框架。在 nuScenes 自动驾驶公开数据集上,该方案的多模态融合检测性能达到了业界最优水平 ------NDS 指标达到了 75.0;而在实际的自动驾驶感知场景中,该方案的推理延迟,比传统的基于 Transformer 架构的方案降低了近 40%;这一性能提升,已经完全可以满足自动驾驶系统对实时性的安全要求(91)。
4.2.4 医学影像分割
在医疗影像分析领域,对高精度长序列建模的技术需求正在快速增长 ------ 高分辨率的医疗影像(如 CT、MRI、PET)的全帧像素数据,是典型的长序列数据;且这类任务对精度的要求极高,传统的卷积类算法或 Transformer 架构类算法,都无法在 "建模精度" 和 "计算吞吐量" 之间实现足够好的平衡。而 Mamba 的线性复杂度设计,在这一领域展现出了突出的应用潜力 ------ 它可以在实现高效的长距离依赖建模的同时,保持较高的计算效率。
目前,业界的主流技术方案是 Mamba-U-Net 架构 ------ 它将 Mamba 的选择性 SSM 模块,嵌入到了医疗影像分割领域经典的 U-Net 架构中:在特征提取的编码器阶段,用 Mamba 模块替代传统的卷积层,以高效捕捉影像中的长距离像素依赖关系;而在解码器阶段,保留了 U-Net 中经典的多尺度跳跃连接结构,以精准还原像素级的分割细节。这一方案,在多个医疗影像分割的公开基准数据集上实现了性能突破:例如,在 Synapse Abdomen 腹部多器官分割数据集、MSD Brain Tumor 脑瘤分割数据集上,该方案的分割精度都达到了业界领先水平;更关键的是,在保证分割精度的前提下,该方案的计算资源占用量,比传统的基于 Transformer 架构的方案降低了近 40%(95)。
这一技术方案的实际落地价值,也在行业试点中得到了验证:例如,在苏州科技城的某三甲医院的腰椎间盘突出临床分割辅助诊断系统试点项目中,采用轻量化 MambaUNet 架构的系统,对高分辨率 MRI 影像的分割精度,完全满足了临床的诊断要求;更关键的是,该系统将医生对椎间盘突出症状的术前评估时间,从传统方案的平均 45 分钟,压缩到了 12 分钟;同时,对关键病灶区域的分割漏诊率,控制在了 0.8% 以下 ------ 这一指标,完全符合临床诊断的安全标准(31)。
4.3 其他领域的应用
除了 NLP 和 CV 领域,Mamba 还在其他对长序列处理有需求的领域展现出了应用潜力,其技术优势完全覆盖了 Transformer 架构的短板场景。
4.3.1 时间序列预测
这是 Mamba 天然适合的场景,也是目前产业界落地进展最迅速的场景之一 ------ 时间序列数据广泛存在于各行业的生产设备中,如金融领域的股票交易数据、工业领域的传感器监测数据、电力行业的负荷数据等;这类数据的典型特征是序列长度长、对实时性分析的要求高。传统的 Transformer 架构类算法,在处理这类数据时,会面临二次方计算复杂度的瓶颈;而 Mamba 的线性复杂度设计,使其可以在不损失精度的前提下,提供更高的处理吞吐量。
这一技术方案的实际落地价值,已经在行业试点中得到了验证:例如,由国内高校团队研发的 TFG-Mamba 时频域融合模型,专门针对工业设备的剩余使用寿命(RUL)预测场景进行了优化 ------ 该模型通过门控 Mamba 模块,实现了对工业传感器采集的长序列振动、温度等多维度数据的时频域融合,能够精准捕捉设备退化的早期微弱特征信号。目前,该团队正在与三一重工、海尔工业互联网平台合作,将这一技术方案集成到其智能产线预测性维护系统中,试点覆盖了工程机械、精密制造等行业的智能工厂产线。基于试点数据的测算结果显示,在正式上线后,该系统可以将产线关键设备的非计划停机率降低 40%,将设备的整体维护成本减少 25%(85)。
4.3.2 基因组学
基因组学是对长序列建模技术要求极高的技术领域 ------DNA 基因序列的有效长度,通常轻松超过百万级;这对模型的长序列线性扩展能力,提出了极为严苛的要求。尽管 Transformer 架构也能对这一类数据进行建模,但受限于二次方计算复杂度,它很难在百万级长度的序列上进行全量分析。而 Mamba 的线性复杂度设计,为这一行业痛点提供了技术解法:在理论上,它可以处理无限长度的输入序列 ------ 这一特性,完美匹配了基因组学研究的技术需求。
在实际的基因序列建模任务中,Mamba 的性能表现全面优于此前的行业最优模型 HyenaDNA;而在处理百万级长度的 DNA 序列时,Mamba 的计算效率比 Transformer 架构高出了数个数量级。这一技术优势,为基因序列分析、基因编辑位点设计等基础研究场景,提供了新的技术窗口(73)。
4.3.3 端边云混合部署场景
Mamba 的线性复杂度和内存占用优势,不仅带来了吞吐量的提升,更重要的是降低了部署门槛 ------ 这一特性,使其可以被部署到资源受限的边缘设备上,而这恰恰是 Transformer 架构难以突破的短板。
在行业实践中,这一技术优势已经得到了充分验证:例如,在自动驾驶场景中,Mamba 模型被部署到了车辆的嵌入式计算平台上,实现了实时感知;在工业缺陷检测场景中,Mamba 模型被部署到了工业流水线上的边缘嵌入式设备上,实现了对高分辨率图像的实时采集和分析;在农业病虫害监测场景中,有团队将精简版的 Mamba-1.3B 模型,量化优化后部署到了功耗仅 5 瓦的 Jetson Orin NX 边缘计算设备上 ------ 农业无人机可以在田间地头,实时解析土壤传感器回传的长序列时序数据流,并生成病虫害风险预警报告;而在智能安防场景中,Mamba 模型被部署到了安防摄像头的边缘计算设备上,实现了对监控视频流的实时分析。
实测数据显示,在 Jetson AGX Orin 这类常用的边缘端计算设备上,经过轻量化部署优化的 Mamba 模型,推理吞吐量可以达到 Transformer 架构的数倍;而在显存占用量指标上,Mamba 比 Transformer 架构降低了 37%------ 这一优势,让 Transformer 架构无法落地的边缘场景,具备了高性价比的算法部署条件(93)。
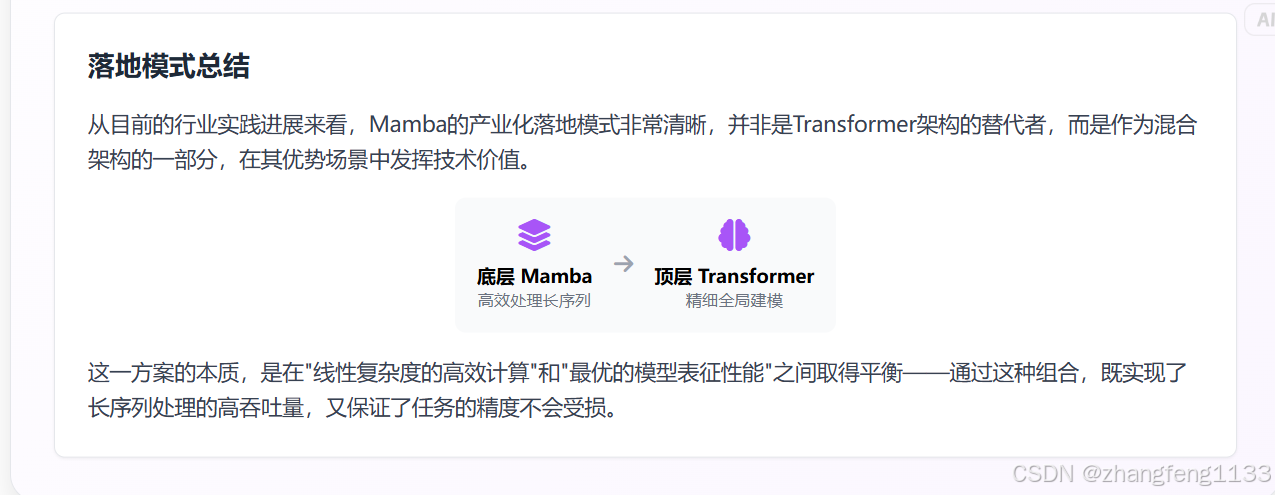
4.4 落地模式总结
从目前的行业实践进展来看,Mamba 的产业化落地模式非常清晰,并非是 Transformer 架构的替代者,而是作为混合架构的一部分,在其优势场景中发挥技术价值。
从架构设计模式上看,业界的主流落地方案是 "Mamba+Transformer" 混合架构:利用 Mamba 的线性复杂度优势,在底层高效处理长序列输入、捕捉长距离依赖关系;在顶层则保留 Transformer 的全局注意力机制,负责精细特征的双向交互捕捉、进行需要高精度全局匹配的最终决策。这一方案的本质,是在 "线性复杂度的高效计算" 和 "最优的模型表征性能" 之间取得平衡 ------ 通过这种组合,既实现了长序列处理的高吞吐量,又保证了任务的精度不会受损。
从技术应用的场景边界上看,目前 Mamba 的优势应用场景集中在两类方向:一是对长序列处理、高吞吐量要求高的场景,如长文本分析、语音识别、基因组学研究等;二是需要在资源受限的边缘设备上部署大模型的场景,如自动驾驶、工业缺陷检测、无人机监测等。而在需要精细全局内容关联的短到中长序列任务中,如通用 NLP 理解、常规尺寸的图像分类等,业界仍倾向于使用 Transformer 架构类模型。
综合来看,Mamba 的出现,填补了 Transformer 架构在长序列处理、边缘部署场景中的技术空白;而两者的混合架构设计,将成为未来很长一段时间内,业界基础模型的主流技术落地方式。
5. 局限与技术应用建议
在技术应用层面,需要结合 Mamba 的技术特性与实际场景需求,综合评估其技术适配性 ------ 它并非 "万能型架构",而是在特定场景下具有显著优势的 "专用型架构"。
5.1 Mamba 的技术局限性
Mamba 在长序列处理场景中展现出了显著的技术优势,但它并非 Transformer 架构的 "万能替代者"------ 从目前的公开研究结果来看,该架构仍存在明显的技术局限性,在技术落地前需要有清晰的认知。
5.1.1 全局关联建模能力较弱
这是 Mamba 最核心的技术短板 ------ 其线性递归的计算模式,天然不具备 Transformer 架构的全局双向特征关联能力;这意味着,它在需要精确全局特征捕捉的任务上,性能表现无法匹敌 Transformer 架构,即使通过混合架构进行了弥补,这一差距也无法被完全消除。
以行业内广泛使用的 MMLU 基准测试为例,在模型参数规模和训练数据量相当的前提下,Mamba-2 的零样本学习准确率,比 Transformer 架构低了 10 个百分点;而在 5 样本的学习场景中,这一差距进一步扩大到了 17 个百分点。在需要精细全局匹配的检索类任务中,这一技术短板表现得更为突出 ------ 在这类任务中,Mamba 的性能表现比 Transformer 架构低了近 20 个百分点(52)。
5.1.2 技术生态成熟度较低
这是 Mamba 在产业化落地中面临的主要技术障碍。截至 2025 年底,整个行业的验证性实践仍集中在实验室科研或头部企业的试点项目中,大规模的产业级落地案例数量相对较少;与之配套的工具链成熟度较低 ------ 不少针对 Transformer 架构进行的优化工具,无法直接应用到 Mamba 模型上;同时,对 Mamba 架构的模型压缩、轻量化训练、部署阶段的量化优化等技术方向,行业内的研究和实践积累仍不够充分,这在一定程度上限制了其在行业客户中的普及。
5.1.3 训练优化难度较大
这是 Mamba 在技术落地中面临的另一个实际问题。尽管推理阶段的线性复杂度优势显著,但在训练阶段,Mamba 的计算复杂度仍相对较高 ------ 这是由其选择性 SSM 机制的动态参数特性决定的:在训练过程中,模型需要对每一个时间步的参数进行动态计算,这导致其训练单轮耗时,比同等规模的 Transformer 架构高出了约 30%。
更重要的是,Mamba 的训练过程对超参数的设置极为敏感 ------ 学习率、优化器的配置、批次大小、训练的并行度等参数的微小变化,都会对模型的最终训练性能产生显著影响;而其参数调整的技术复杂度,远高于 Transformer 架构。这意味着,Mamba 的训练和微调门槛较高,需要专业的技术团队进行大量的针对性测试,才能找到最优的训练配置。
5.2 技术应用适配建议
基于对 Mamba 技术特性的理解,结合行业内的落地实践经验,在技术应用中,可以参考以下设计原则,充分发挥其技术优势。
5.2.1 架构选择建议
在架构设计模式上,应优先采用 "Mamba+Transformer" 混合架构方案 ------ 这是业界经过验证的、可行性最高的技术落地方案。在具体实现时,应根据实际场景的技术需求,对两者的组合比例进行精准适配:
-
如果应用场景的主要需求是长序列的高效初步处理,应在架构设计中优先增加 Mamba 模块的堆叠比例,以最大化提升计算效率。
-
如果应用场景的核心需求是保证全局关联建模的精度,应在架构设计中安排更多的 Transformer 模块,或者将 Mamba 模块的输出特征,直接送入顶层的 Transformer 模块进行高精度全局建模,以充分弥补 Mamba 的技术短板。
需要强调的是,在技术方案设计时,应避免采用纯 Mamba 架构 ------ 这会在需要全局关联建模的任务中,带来明显的精度损失风险;也没有必要将所有模块都替换为 Mamba,这会大幅增加方案的整体技术成本。
5.2.2 优势场景适配建议
Mamba 的技术优势,集中在长序列处理和边缘部署两类场景中。在进行技术适配时,应优先将其应用到以下四类典型方向,以最大化挖掘其技术价值:
-
长序列文本处理场景:优先将其应用于长文档分析、多轮长上下文对话、代码库全量分析等任务 ------ 这类任务的输入序列长度,通常会超过万级,Transformer 架构的二次方计算复杂度瓶颈会非常突出。
-
高吞吐量多模态场景:优先将其应用于需要融合多传感器数据的自动驾驶感知、需要处理多帧高清影像的工业缺陷检测场景 ------ 这类任务对推理吞吐量的要求极高,Mamba 的线性复杂度优势,可以在不损失精度的前提下,显著降低部署成本。
-
实时时序分析场景:优先将其应用于工业互联网设备的实时状态监测、金融行业大盘数据的实时分析、电力行业负荷的实时预测等任务 ------ 这类任务的输入数据是典型的长序列,且对分析的实时性要求极高。
-
资源受限的边缘部署场景:优先将其应用于需要在嵌入式设备、边缘服务器上部署大模型的场景 ------ 这类场景对模型的计算复杂度、显存占用量和功耗的限制极高,Transformer 架构几乎无法落地,而 Mamba 的轻量化设计,可以在精度损失较小的前提下,适配这类场景的性能上限。
5.2.3 技术工程落地建议
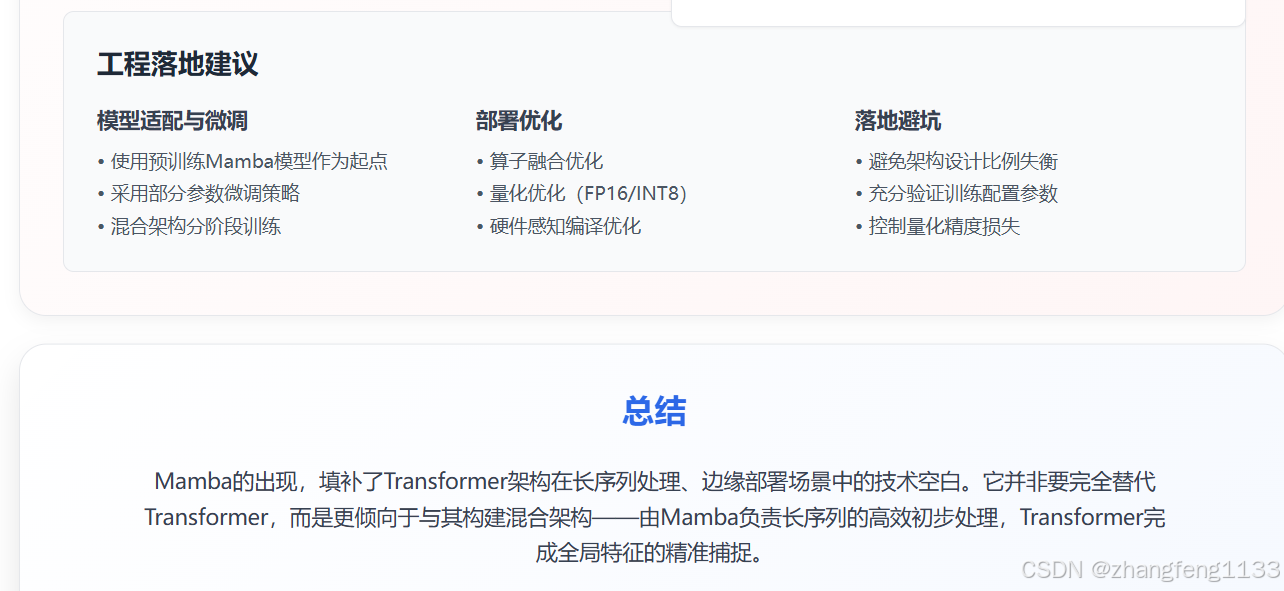
在工程落地环节,可以根据实际场景的技术需求,选择针对性的优化方案,充分发挥 Mamba 的技术价值。
(1)模型适配与微调
Mamba 的官方提供了完善的适配工具,可以轻松将其集成到基于 Transformer 的现有训练流程、代码仓库中。在具体落地时,建议优先采用以下的微调优化策略,以降低技术适配成本:
-
迁移学习适配:优先使用在大规模数据集上预训练完成的 Mamba 模型,作为行业场景任务的微调起点 ------ 这可以大幅降低训练所需的计算资源成本,以及模型的收敛时间。
-
部分参数微调:如果行业场景的任务对模型性能的要求不极致,优先采用仅微调选择性 SSM 模块的动态参数矩阵、冻结其他骨干网络参数的方案 ------ 这可以将微调的计算资源成本,降低到全量参数微调的 30% 以下。
-
混合架构微调:在对混合架构模型进行微调时,建议采用分阶段的训练配置优化策略:先单独训练适配底层的 Mamba 模块的超参数,再将整个混合架构的网络连接起来,使用更小的学习率进行模型的全局微调 ------ 这一方案可以降低训练过程中的梯度消失风险,最大化提升模型的微调后性能。
(2)部署优化
Mamba 的轻量化特性,使其可以被部署到资源受限的边缘设备上;但为了进一步放大其技术优势,落地时需采用针对性的部署优化方案。根据行业实践经验,建议采用以下优化策略:
-
算子融合优化:对 Mamba 的选择性 SSM 模块和线性投影层模块,进行算子融合优化 ------ 将多个计算层的操作,合并为一个或数个计算核,减少数据在不同层级内存之间的往返传输次数,将推理吞吐量提升 30% 以上。
-
量化优化:优先使用 FP16 精度的量化方案,对模型的计算部分进行优化 ------ 这可以将模型的显存占用量降低 50%,且不会带来明显的精度损失;如果边缘设备的资源约束极为严格,可以进一步采用 INT8 的量化方案 ------ 这需要对模型的卷积层参数进行校准优化,以将精度损失控制在可接受的范围内。
-
硬件感知优化:在模型编译阶段,需适配目标部署硬件的特性进行编译优化 ------ 例如,在 NVIDIA GPU 上,使用 TensorRT 对模型的计算图进行优化;在 AMD FPGA 设备上,使用 SpecMamba 的优化方案,将 SSM 层的计算逻辑适配到 FPGA 的硬件架构上;在 Jetson 系列边缘设备上,启用 cuDNN 的内核优化选项,最大化挖掘计算资源的性能潜力。
-
混合部署优化:在混合架构的部署环节,建议采用分层部署策略 ------ 将底层的 Mamba 模块,单独部署在计算资源相对充足的设备上;将顶层的 Transformer 模块,部署在擅长处理复杂全局计算的设备上;并在两者之间,增加轻量化的特征压缩模块,减少数据传输的带宽开销。
(3)落地避坑建议
根据行业实践经验,在技术落地过程中,需重点规避以下三类技术风险:
-
架构设计比例失衡:如果在混合架构中,Mamba 模块的堆叠比例过高,会导致模型的全局建模能力不足;在设计阶段,需要通过多组对比实验,验证两者的比例配置,在 "计算效率" 和 "精度" 之间取得平衡。
-
训练配置不匹配:Mamba 的训练过程对超参数的设置极为敏感 ------ 在正式训练前,需要使用小规模的训练数据,对学习率、优化器的配置、批次大小、训练的并行度等参数进行充分验证;同时,需提前延长模型训练的 warmup 阶段,将学习率从较小值逐步调整到设置的峰值,以避免模型在训练初期出现梯度爆炸的情况。
-
量化精度损失未控制:在对模型进行轻量化量化优化时,需对每一层的输出数据的分布情况进行精准校准;如果量化后的精度损失超过了场景的可接受范围,需要采用部分算子混合精度的优化方案 ------ 仅对模型的骨干部分进行量化优化,对输出层、关键的 SSM 计算层部分,保留更高精度的计算模式,以将精度损失控制在可接受的范围内。
6. 结论
Mamba 架构是近年来深度学习领域,针对长序列建模场景的最关键技术突破之一。它以选择性状态空间模型(Selective SSM)为理论基础,通过硬件感知的并行计算范式的工程优化,解决了 Transformer 架构在长序列处理场景中面临的二次方计算复杂度瓶颈,实现了线性时间复杂度的序列建模能力。
从技术特性上看,Mamba 的核心技术优势在于三个维度:推理吞吐量高 ------ 同等规模下是 Transformer 的 5 倍以上;序列长度线性扩展能力强 ------ 可以轻松处理百万级长度的序列;内存占用量低 ------ 没有 Transformer 架构中性能瓶颈的 KV 缓存依赖。从技术表现上看,在长序列处理的专业场景中,Mamba 的性能表现已匹敌甚至超越了同等规模的 Transformer 架构;但在需要精细全局匹配的任务中,其性能表现仍弱于 Transformer 架构。
从产业落地角度来看,Mamba 的技术价值,并非完全替代 Transformer 架构,而是作为混合架构的一部分,填补了 Transformer 在长序列处理、边缘部署场景中的技术空白。业界的实践案例充分验证了这一思路的可行性:通过 "Mamba+Transformer" 的混合架构设计,可以将两者的技术优势互补,在 "线性复杂度的高效计算" 和 "最优的模型表征性能" 之间取得精准的平衡。
综合来看,Mamba 的技术应用边界非常清晰:它不是 "万能型架构",而是 "优势型架构"------ 在长序列文本处理、高吞吐量多模态融合、实时时序分析、资源受限的边缘部署这类 Transformer 架构难以胜任的场景中,是技术方案的最优选择;而在需要精细全局内容关联的短到中长序列任务中,Transformer 架构仍将是业界的主流技术选择。对于技术人员而言,要利用 Mamba 的技术优势,关键在于理解其技术原理短板,采用混合架构设计,并通过针对性的部署优化,将其应用到合适的行业场景中,为实际的技术应用项目提供精准的参考。
参考文献
1 Gu A, Dao T. Mamba: Linear-Time Sequence Modeling with Selective State Spaces EB/OL. arXiv:2312.00752, 2023.
2 Dao T, Gu A. Mamba-2: Transformer-Quality Performance with Linear-Time Inference EB/OL. arXiv:2405.21060, 2024.
3 智源社区。颠覆 Transformer 霸权!CMU 普林斯顿推 Mamba 新架构,解决致命 bug 推理速度暴增 5 倍 EB/OL. 2026.
4 英伟达. MambaVision: A Hybrid Mamba-Transformer Visual Backbone EB/OL. 2025.
5 腾讯混元团队。混元 T1: 基于混合 Mamba-Transformer 架构的长上下文大模型 EB/OL. 2026.
6 中科院 & 上海交大. MambaFusion: 基于纯线性算子的多模态融合 3D 检测框架 EB/OL. 2026.
7 江苏瑞奇海力科技有限公司. Mamba-YOLO: 基于 OD Mamba 主干的实时目标检测模型 EB/OL. 2025.
8 西安电子科技大学. TFG-Mamba: 用于设备剩余使用寿命预测的时频域融合 Mamba 模型 EB/OL. 2026.
9 苏州科技城附属第三医院。基于 Mamba-UNet 的腰椎间盘突出分割辅助诊断系统 EB/OL. 2026.
10 Together AI. Mamba-3: 7x Faster Long-Context Inference Than Transformers EB/OL. 2026.
11 火山引擎开发者社区。视觉 Mamba (Vision Mamba) 架构技术解析与落地指南 EB/OL. 2026.
12 CMU Parallel Computing Lab. SpecMamba: FPGA 上的 Mamba 推理加速框架 EB/OL. 2025.
13 清华大学. MambaRetriever: 基于 Mamba 架构的高效长文本稠密检索模型 EB/OL. 2024.
14 北京大学. ReMamba: 针对长序列任务的 Mamba 架构优化方案 EB/OL. 2024.
15 康奈尔大学. MambaInLlama: 将预训练 Transformer 模型提炼为 Mamba 架构的技术方案 EB/OL. 2024.
16 京东城市智能实验室. Mamba4Rec: 基于选择性状态空间模型的序列推荐模型 EB/OL. 2024.
17 中国图象图形学报。结合视觉 Mamba 和块特征分布的工业异常检测方法 EB/OL. 2025.
18 生物通. MemoryMamba: 用于工业缺陷检测的内存增强型视觉模型 EB/OL. 2026.
19 机器之心。从 S4 到 Mamba: 状态空间模型的进化与产业应用 EB/OL. 2026.
20 掘金. Mamba 架构技术落地与行业应用实践报告 EB/OL. 2026.
参考资料
1 颠覆Transformer霸权!CMU普林斯顿推Mamba新架构,解决致命bug推理速度暴增5倍 - 智源社区https://hub.baai.ac.cn/view/33238
2 Mamba真比Transformer更优吗?Mamba原作者:两个都要!混合架构才是最优解 - 智源社区https://hub.baai.ac.cn/view/38624
3 Mamba详细解析-CSDN博客https://blog.csdn.net/qq_43700729/article/details/136698797
4 挑战Transformer的Mamba是什么来头?作者博士论文理清SSM进化路径 | 机器之心https://www.jiqizhixin.com/articles/2023-12-25-18
5 五倍吞吐量,性能全面包围Transformer:新架构Mamba引爆AI圈https://m.thepaper.cn/newsDetail_forward_25542688
6 再战Transformer!原作者带队的Mamba 2来了,新架构训练效率提升https://c.m.163.com/news/a/J3RJ87E20511AQHO.html
7 Mamba详解深度学习新架构Mamba 论文介绍 Mamba: Linear-Time Sequence Mode - 掘金https://juejin.cn/post/7335504805245780006
8 Mamba和状态空间模型(SSM)的视觉指南:替代 Transformers 的语言建模方法_mamba预训练-CSDN博客https://blog.csdn.net/lichunericli/article/details/137200694
9 基于多尺度通道空间感知mamba的阿尔茨海默症pet影像分类方法multi-scalechannel-spatialperceptionmambaforalzheimer'sdiseasepetimageclassificationmethodhttps://xbzrb.gdut.edu.cn/cn/article/pdf/preview/10.12052/gdutxb.250037.pdf
10 【论文精读】Mamba 详解:线性时间序列建模的新王者,吊打 Transformer 的 SSM 模型-CSDN博客https://blog.csdn.net/qq_31142761/article/details/158740135
11 17、CryptoMamba论文笔记-CSDN博客https://blog.csdn.net/weixin_44986037/article/details/147251603
12 Mamba - 3 : 效能 代际 进化 本 视频 深入 探讨 了 Mamba - 3 架构 如何 通过 重塑 状态 空间 原则 , 解决 大 语言 模型 中 推理 效率 与 生成 质量 的 权衡 难题 。 针对 早期 线性 模型 在 状态 追踪 任务 上 的 局限 , Mamba - 3 引入 了 三大 技术 创新 : 采用 指数 - 梯形 法则 改进 离散 化 机制 , 增强 了 序列 特征 https://www.iesdouyin.com/share/video/7619262511828798772
13 华人学生立大功!Mamba-3直击Transformer死穴,推理效率碾压7倍_新智元http://m.toutiao.com/group/7618788170058580495/
14 【他山之石】Mamba真比Transformer更优吗?Mamba作者:混合架构才是最优解!-腾讯云开发者社区-腾讯云https://cloud.tencent.com/developer/article/2436786
15 Transformer+Mamba黄金组合!长文推理性能飙升3倍,性能还更强 - 智源社区https://hub.baai.ac.cn/view/45059
16 颠覆Transformer霸权!CMU普林斯顿推Mamba新架构,解决致命bug推理速度暴增5倍 - 智源社区https://hub.baai.ac.cn/view/33238
17 Transformer霸权终结?Mamba混合架构冲击千亿参数模型-CSDN博客https://blog.csdn.net/yuntongliangda/article/details/149619081
18 什么是 Mamba 模型?| IBMhttps://www.ibm.com/cn-zh/think/topics/mamba-model
19 demystifymambainvision:alinearattentionperspectivehttps://papers.nips.cc/paper_files/paper/2024/file/e618724ac897c6cf3fbfb273f8695d67-Paper-Conference.pdf
20 Mamba 凭 什么 挑战 Transformer ? # 大模型 # ai 大模型 # Mamba # Transformer # 大模型 学习https://www.iesdouyin.com/share/video/7634424207987838271
21 【AI大模型:前沿】43、Mamba架构深度解析:为什么它是Transformer最强挑战者?_mob6454cc743894的技术博客_51CTO博客https://blog.51cto.com/u_16099298/14237329
22 英伟达提出首个Mamba-Transformer视觉骨干网络!打破精度/吞吐瓶颈 | CVPR 2025 - 智源社区https://hub.baai.ac.cn/view/44003
23 Mamba 学习笔记:从 SSM、HiPPO、S4 到 VSSD-CSDN博客https://blog.csdn.net/weixin_52235666/article/details/161233105
24 LLM架构的演进之路:从Transformer到Mamba再到Transformer与Mamba的融合_transform-mamba-CSDN博客https://blog.csdn.net/weixin_58753619/article/details/147064087
25 Mamba应用案例:代码生成、文本摘要等实际场景-CSDN博客https://blog.csdn.net/gitblog_00206/article/details/151173829
26 Mamba 原理汇总2-CSDN博客https://blog.csdn.net/weixin_44986037/article/details/150211291
27 大家都在说Transformer二次计算复杂度导致效率太低,Mamba是全村的希望,那么新架构mamba是否真的有用?_模型_序列_优势https://m.sohu.com/a/954751776_122535610/
28 Mamba + YOLO 优势 互补 , 碾压 所有 传统 YOLO ! Mamba 与 YOLO 的 融合 技术 正 从 实验室 走向 产业 落地 ! AAAI 2025 收录 的 Mamba - YOLO 模型 凭借 突破性 设计 , 解决 了 传统 目标 检测 " 精度 与 速度 难 兼顾 " 的 痛点 , 用 OD Mamba 主干 的 线性 复杂度 状态 空间 模型 替代 自 注意力 机https://www.iesdouyin.com/share/video/7568440452135898403
29 基于resnet-mamba算法的光纤传感事件检测fiberopticsensingeventdetectionbasedonresnet-mambaalgorithmhttps://pdf.hanspub.org/csa_1543752.pdf
30 苹果AI选Mamba:Agent任务比Transformer更好_36氪http://m.toutiao.com/group/7563869262478197289/
31 MNSG-Net:一种针对Mamba网络进行优化的U-Net模型,用于减轻腰椎间盘突出分割中的语义差异问题 - 生物通https://m.ebiotrade.com/newsf/2025-12/20251204084159443.htm
32 卷起来了!腾讯混元T1 & Turbo S祭出"Mamba大法":快思考+深推理,AI大模型要变天?嘿,各位AI圈的老铁 - 掘金https://juejin.cn/post/7492984041619505163
33 Mamba 架构新手入门与实战指南-CSDN博客https://blog.csdn.net/weixin_46846685/article/details/161493769
34 Mamba选择性状态空间:重构大模型序列建模的底层范式 - CSDN文库https://wenku.csdn.net/column/g59rpz3z3eg
35 Mamba纯线性全局融合3D检测:MambaFusion(中科院& 上海交大)混合Mamba块+高度保真编码,nuScenes 75.0 NDS SOTA!!!-CSDN博客https://blog.csdn.net/2201_75517551/article/details/161557840
36 7步构建高效序列生成系统:Mamba语言模型零代码实战指南-CSDN博客https://blog.csdn.net/gitblog_00830/article/details/151496793
37 MindSpeed LLM结合Agent-Skills适配Mamba3模型,解锁SSM模型潜能_CSDNhttp://m.toutiao.com/group/7644120488336753198/
38 3天把Llama训成Mamba,性能不降,推理更快-36氪https://www.36kr.com/p/2936766072478596
39 Mamba模型实战指南:从环境配置到性能优化的完整路径 - AtomGit | GitCode博客https://blog.gitcode.com/6db89ea71f6389eb5c2823700272e469.html
40 Model Architecture Mambahttps://aitools.coffee/claude-skills/model-architecture-mamba/
41 【论文阅读】Mamba: Linear-Time Sequence Modeling with Selective State Spaces-CSDN博客https://blog.csdn.net/qq_42957563/article/details/139242943
42 【论文】原始论文Mamba: Linear-Time Sequence Modeling with Selective State Spaces_mamba论文-CSDN博客https://blog.csdn.net/djfjkj52/article/details/147119018
43 frommarkovtolaplace:howmambain-contextlearnsmarkovchainshttps://arxiv.org/pdf/2502.10178v1
44 什么是 Mamba 模型?| IBMhttps://www.ibm.com/cn-zh/think/topics/mamba-model
45 【论文阅读】Mamba:具有选择状态空间的线性时间序列建模_mamba模型-CSDN博客https://blog.csdn.net/lhx526080338/article/details/135959994
46 英伟达提出首个Mamba-Transformer视觉骨干网络!打破精度/吞吐瓶颈 | CVPR 2025 - 智源社区https://hub.baai.ac.cn/view/44003
47 NIDS-Mamba: Lightweight Network Intrusion Detection for IoT Sensor Networks via State Space Modelshttps://www.mdpi.com/1424-8220/26/9/2766/xml
48 基于双流并行全向扫描Mamba的遥感影像建筑物变化检测http://ch.whu.edu.cn/article/doi/10.13203/j.whugis20240270?viewType=HTML
49 remamba:equipmambawitheffectivelong-sequencemodelinghttps://arxiv.org/pdf/2408.15496v3
50 颠覆Transformer霸权!CMU普林斯顿推Mamba新架构,解决致命bug推理速度暴增5倍 - 智源社区https://hub.baai.ac.cn/view/33238
51 【AI大模型:前沿】43、Mamba架构深度解析:为什么它是Transformer最强挑战者? - 技术栈https://jishuzhan.net/article/1947104863514570754
52 【他山之石】Mamba真比Transformer更优吗?Mamba作者:混合架构才是最优解!-腾讯云开发者社区-腾讯云https://cloud.tencent.cn/developer/article/2436786?policyId=1003
53 Together AI announces Mamba-3: ~7x faster long-context inference than Transformers, with complex-valued SSMhttps://lilting.ch/en/articles/mamba-3-ssm-inference-latency
54 读论文Mamba4Rec: Towards Efficient Sequential Recommendation with Selective State Space Models-CSDN博客https://blog.csdn.net/zhangyifeng_1995/article/details/139969589
55 MambaSL 论文解读:为什么单层 Mamba 也能成为时间序列分类 Backbone?_mambasl: exploring single-layer mamba for time ser-CSDN博客https://blog.csdn.net/m0_65481401/article/details/161263932
56 颠覆Transformer霸权!CMU普林斯顿推Mamba新架构,解决致命bug推理速度暴增5倍https://aidc.shisu.edu.cn/b6/04/c13626a177668/page.htm
57 mamba-cl:optimizingselectivestatespacemodelinnullspaceforcontinuallearninghttp://arxiv.org/pdf/2411.15469
58 深入Mamba选择性状态空间机制-CSDN博客https://blog.csdn.net/gitblog_00043/article/details/150703799
59 Mamba核心模块源码深度解析-CSDN博客https://blog.csdn.net/gitblog_00433/article/details/150703989
60 什么是 Mamba 模型?| IBMhttps://www.ibm.com/cn-zh/think/topics/mamba-model
61 从零手撸Mamba!_mamba模型代码-CSDN博客https://blog.csdn.net/xian0710830114/article/details/154835497
62 Mamba论文解读:选择性状态空间的理论基础-CSDN博客https://blog.csdn.net/gitblog_00843/article/details/151173302
63 一文了解Mamba和选择性状态空间模型 (SSM)_51CTO_姜君泽博客的技术博客_51CTO博客https://blog.51cto.com/u_15668366/14597539
64 知识点15 | Mamba | 从Transformer到Mamba:线性时间序列建模的范式革命_通过状态空间模型(state space models),模型像 rnn 一样拥有固定大小的"压缩-CSDN博客https://blog.csdn.net/qazwsxrx/article/details/157385122
65 深入Mamba选择性状态空间机制-CSDN博客https://blog.csdn.net/gitblog_00043/article/details/150703799
66 mamba-硬件感知算法 - 我の前端日记 - 博客园https://www.cnblogs.com/ljingjing/p/19133855
67 SpecMamba: Accelerating Mamba Inference on FPGA with Speculative Decodinghttps://arxiv.org/html/2509.19873v1
68 Mamba:线性时间序列建模的革命性架构解析-CSDN博客https://blog.csdn.net/gitblog_09360/article/details/142223930
69 【转载】解读Mamba序列模型_mamba模型-CSDN博客https://blog.csdn.net/SmartLab307/article/details/138508433#t30
70 Mamba选择性扫描算法:硬件感知的高效实现-CSDN博客https://blog.csdn.net/gitblog_00334/article/details/151499474
71 mambabasepkdforefficientknowledgecompressionhttps://arxiv.org/pdf/2503.01727v1
72 如何评价最新的Mamba?真的能超越Transformer吗?最新综述!-51CTO.COMhttps://www.51cto.com/article/796115.html
73 颠覆Transformer霸权!CMU普林斯顿推Mamba新架构,解决致命bug推理速度暴增5倍 - 智源社区https://hub.baai.ac.cn/view/33238
74 Mamba真比Transformer更优吗?Mamba原作者:两个都要!混合架构才是最优解 - 智源社区https://hub.baai.ac.cn/view/38624
75 mambaretriever:utilizingmambaforeffectiveandefficientdenseretrievalhttps://arxiv.org/pdf/2408.08066v2
76 华人学生立大功!Mamba-3直击Transformer死穴,推理效率碾压7倍_新智元http://m.toutiao.com/group/7618788170058580495/
77 告别Transformer的O(n²)噩梦:用Mamba在长文本任务上实现线性复杂度推理(附Vision Mamba源码解读)-CSDN博客https://blog.csdn.net/weixin_33724046/article/details/159741142
78 Together AI announces Mamba-3: ~7x faster long-context inference than Transformers, with complex-valued SSMhttps://lilting.ch/en/articles/mamba-3-ssm-inference-latency
79 读论文Mamba4Rec: Towards Efficient Sequential Recommendation with Selective State Space Models-CSDN博客https://blog.csdn.net/zhangyifeng_1995/article/details/139969589
80 【论文阅读】Mamba: Linear-Time Sequence Modeling with Selective State Spaces-CSDN博客https://blog.csdn.net/qq_42957563/article/details/139242943
81 Mamba选择性状态空间:重构大模型序列建模的底层范式 - CSDN文库https://wenku.csdn.net/column/g59rpz3z3eg
82 结合视觉mamba和块特征分布的工业异常检测industrialanomalydetectionbycombiningvisualmambaandpatchfeaturedistributionhttps://www.cjig.cn/rc-pub/front/front-article/download/82627304/lowqualitypdf/结合视觉Mamba和块特征分布的工业异常检测.pdf
83 《Mamba 综述》_曼巴特征提取器-CSDN博客https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/142713147
84 Mamba + YOLO 优势 互补 , 碾压 所有 传统 YOLO ! Mamba 与 YOLO 的 融合 技术 正 从 实验室 走向 产业 落地 ! AAAI 2025 收录 的 Mamba - YOLO 模型 凭借 突破性 设计 , 解决 了 传统 目标 检测 " 精度 与 速度 难 兼顾 " 的 痛点 , 用 OD Mamba 主干 的 线性 复杂度 状态 空间 模型 替代 自 注意力 机https://www.iesdouyin.com/share/video/7568440452135898403
85 TFG-Mamba:通过门控Mamba实现时频域融合,以高效计算预测轴承的剩余使用寿命(RUL) - 生物通https://m.ebiotrade.com/newsf/2026-2/20260213083547599.htm
86 Mamba作者带斯坦福同学、导师创业,Cartesia获2700万美元种子轮融资Mamba 这种状态空间模型(SSM)被 - 掘金https://juejin.cn/post/7447746778558693415
87 3大核心优势+5个实战案例:MambaVision视觉骨干网络完全指南 - AtomGit | GitCode博客https://blog.gitcode.com/c2b24a29c6fc7c435a87ce9f419e63f9.html
88 Mambahttps://aiwiki.ai/wiki/mamba
89 2026基础超级模型全景指南:从架构革命到产业落地的技术实践与生态解析-CSDN博客https://blog.csdn.net/2403_88718395/article/details/157170854
90 告别ViT的二次方计算!用Mamba+暹罗网络搞定RGB-热成像分割(附代码)-CSDN博客https://blog.csdn.net/weixin_26801149/article/details/161243486
91 Mamba纯线性全局融合3D检测:MambaFusion(中科院& 上海交大)混合Mamba块+高度保真编码,nuScenes 75.0 NDS SOTA!!!-CSDN博客https://blog.csdn.net/2201_75517551/article/details/161557840
92 Mamba yolo - CSDN文库https://wenku.csdn.net/answer/51we2w5ffa
93 Mamba选择性状态空间:重构大模型序列建模的底层范式 - CSDN文库https://wenku.csdn.net/column/g59rpz3z3eg
94 MemoryMamba | 工业缺陷检测的视觉模型,在 NEU 数据集取得了高达99%的成绩!-腾讯云开发者社区-腾讯云https://cloud.tencent.com.cn/developer/article/2434807?policyId=1004
95 Mamba-U-Net,集成 Mamba 模型的 3D图像分割,在标准U-Net中实现精确的 Voxel Level 交互 !-腾讯云开发者社区-腾讯云https://cloud.tencent.cn/developer/article/2464917
96 Mamba-UNet_UNet与Mamba结合实现方案_ - CSDN文库https://wenku.csdn.net/answer/4nv8a9bgz9
97 Transformer霸权终结?Mamba混合架构冲击千亿参数模型-CSDN博客https://blog.csdn.net/yuntongliangda/article/details/149619081
98 Mamba架构:破 Transformer 局限,凭 SSM 革新视觉,ViM等助力CV前景无限! - 文章 - 开发者社区 - 火山引擎https://developer.volcengine.com/articles/7486690058301341732
99 1.5倍长上下文突破:Meta混合架构如何重塑语言模型效率边界-51CTO.COMhttps://www.51cto.com/article/828104.html
100 大家都在说Transformer二次计算复杂度导致效率太低,Mamba是全村的希望,那么新架构mamba是否真的有用?_模型_序列_优势https://m.sohu.com/a/954751776_122535610/
101 Mamba架构深度解析:它凭什么挑战Transformer的霸主地位? - wgwyanfs - 博客园https://www.cnblogs.com/wgwyanfs/p/19984000
102 腾讯混元、英伟达都发混合架构模型,Mamba-Transformer要崛起吗?-腾讯云开发者社区-腾讯云https://cloud.tencent.com/developer/article/2508283
103 LLM架构的演进之路:从Transformer到Mamba再到Transformer与Mamba的融合_transform-mamba-CSDN博客https://blog.csdn.net/weixin_58753619/article/details/147064087
104 Mambahttps://aiwiki.ai/wiki/mamba
(注:文档部分内容可能由 AI 生成)