1. 深度学习概述
深度学习(Deep Learning)
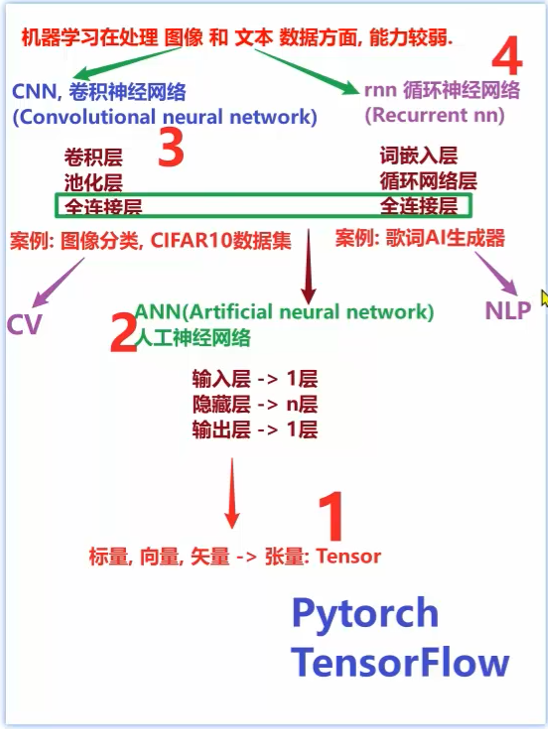
(机器学习有一个问题:机器学习在处理 图像 和文本 数据方面,能力较弱。所以在这里要分别针对 图像 和文本类的数据做一些进阶:(深度学习 主要来处理图像和文本,图像有 CNN 卷积神经网络、文本有 RNN 循环神经网络);1. 如针对图像类的有 CNN(Convolutional Neural Network 卷积神经网络):即 卷积神经网络 CNN 主要是处理图像 -- > CV;处理文本类的有RNN(Recurrent Neural Network 循环神经网络):即 循环神经网络 RNN 主要处理文本 --> NLP;2. 接下来是他们的分层,
对于 CNN:1️⃣ 卷积层:提取图像局部特征的,会涉及到一个卷积核 又叫滤波器,会得到一个特征胡,叫feature Map;2️⃣ 池化层(用来做两个动作,准确来说是两个字:"降维",因为他会提取到大量的特征,而池化一定要降维,因为图像一般我们用的是 HWC 这三个参数,HWC 指的是:高、宽、通道,如 写一个 32 * 32 * 3 指的就是 高和宽都是32像素、3指的是3通道即 RGB 3通道;图像是这样来做的,但层在处理时就不是了,层在处理时我们需要把 C 放在前面即 CHW,意味着需要的结果是 (3, 32, 32) 即 3个32 * 32 像素图,就R 和 G 和 B 就红绿蓝,这种情况下,需要学习一下如何对 32 * 32 * 3 这个维度做转换,把维度从 32 * 32 * 3 转成 (3, 32, 32) ,这就是张量要学习的内容;3️⃣ 全连接层;
对于 RNN:1️⃣ 词嵌入层;往下有 2️⃣ 循环网络层;最后也是叫 3️⃣ 全连接层;难点在词嵌入 和 循环网络,尤其是词嵌入;
后期会做案例:
CNN 案例是 图像分类,CIFAR10数据集 即CNN会做一个图像分类的案例,用到 CIFAR10数据集,此数据集很大:训练集5万张图片、测试集 1 万张图片,整个数据集加起来是 177MB(兆B),需要把文件夹整个加到项目目录下进行使用;
RNN 案例是 歌词AI生成器:之前在python进阶中学习闭包装饰器时,有一个杰伦歌词的数据集,数据加载器分批生成数据的,文件文本中共有5819条数据,此中对此数据进行切词,用到街8分词器,前面 在朴素贝叶斯(唯一一个靠概率进行分类的机器学习的算法) 的学习中做了一个商品评论、情感分析的案例:一共20条评论,先通过 J街8 L Cart对它进行切词,朴素贝叶斯切完词后得到 37个词,把这37个词带入到每个评论中,如果评论中有这个词就用 1表示、没有就用 0表示,所以最终所有的文本全都是一个 37 01 01的列表组成。此案例中用到的歌词数据集和之前的一样,也是5819条数据,对这些歌词进行切词,切词后去重 会得到 5703个去重后的词,要把这些词生成序号,生成对应的维度即数值,再来做预测,如给到一个词 星星,则围绕 星星 这两个字,再给到一个长度,来生成 50个词,凑成一段歌词;给到的词必须是前面去重后的 5703中的已有的词,如果没有的话就无法实现;
3. 全连接层是 CNN和 RNN两者都有的一个层,对于全连接有一个叫 ANN (Artificial neural network 人工神经网络),它是由3层组成:1️⃣ 输入层,只会有1层;2️⃣ 隐藏层,可以有n层;3️⃣ 输出层,也是只能有1层,所以说 后面提到的 深度学习的神经网络的深度,它和 隐藏层有关,所以 隐藏层就是 层的深度,一般是越深越好,但具体还要看业务需求;
4. 学习时无论是CNN、RNN、ANN 其底层都是通过张量(Tensor)来做处理的,后面就不会涉及到 标量、向量、矢量的概念了(标量是一个值的、向量可理解为一个列表、矢量是多维的),这些在这里统一都被称之为张量。张量是学习其他内容的基础,如 图像是靠 高宽通道即 HWC,要转成 CHW,就是利用张量来完成的,张量中有很多函数都能实现,如 reshape重构...。张量的学习使用 Pytorch 框架,之前的 TensorFlow框架已过时,Pytorch 框架和TensorFlow框架的主要区别是:① 第一点:关于生成的计算步骤(即计算路径):TensorFlow 生成的是一个静态湖 即当构建完执行流程后,除非模型训练完,中间是不能做修改的;Pytorch 生成的执行图是一个 动态图,可以边生成边修改,这样会更加灵活;② 第二点 Pytorch 的API很简单、TensorFlow 的API过于复杂;所以一般用 Pytorch 它是动态图的,且 API 简单、功能强大;
所以学习步骤:张量 Pytorch(2days) --> ANN人工神经网络(2days+) --> CNN 卷积神经网络(1day+) --> RNN 循环神经网络
RNN 放在 CNN 之后学习的原因是:CNN 进阶中有一个框架 CV(Computer Version 计算机视觉);RNN 中的技术 NLP(自然语言处理);)
ANN 只能处理二维数据,给到 RNN和 CNN的数据时,需要对数据降维 ;文本一般用二维,图像、语音一般都是多维的;图像 一般用 CNN,语音、文本一般用 RNN,可以通过频谱图技术把语音转换成数值,接着对语音做分析;
2. 什么是深度学习
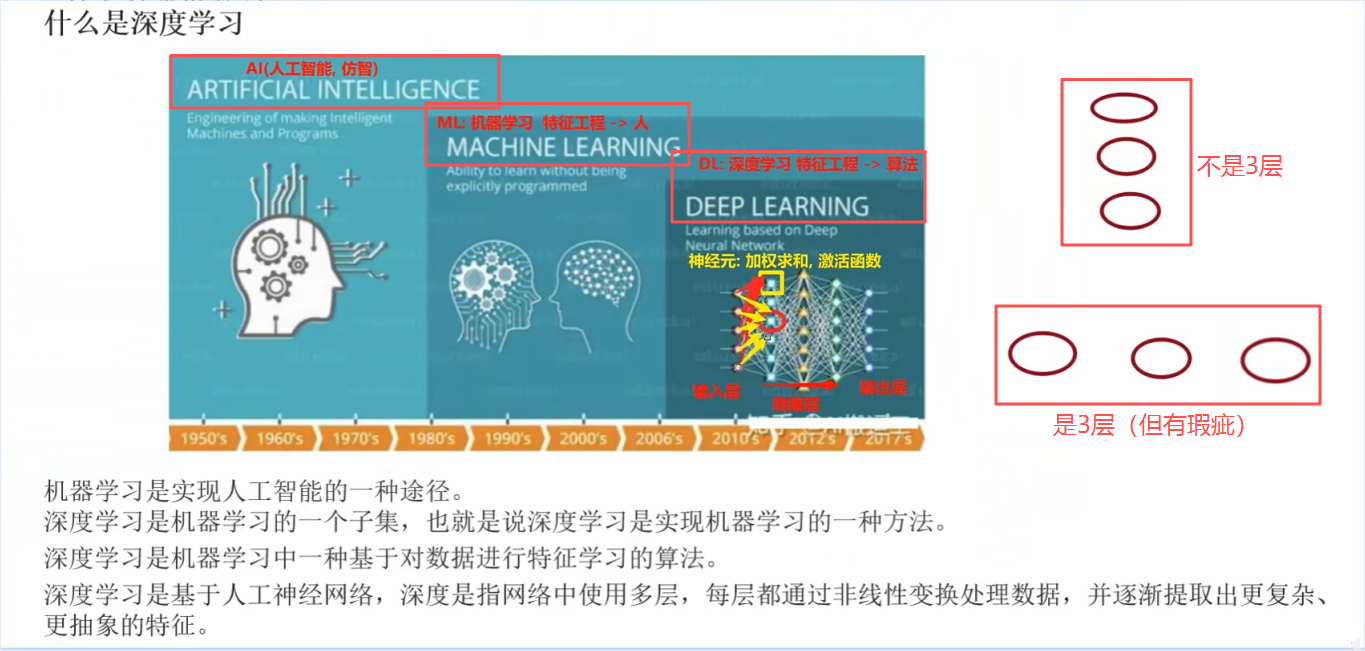
(Artificial Intelligence AI 人工智能 ,仿智即用电脑模仿人类,让电脑像人类那样理性的思考;
1. AI 包含 Machine Learning ML 机器学习: 机器学习中最重要的是 特征工程这一块,是由人来做 特征工程这个事的;1️⃣ 机器学习的步骤:加载数据、数据预处理、特征工程、模型训练、模型预测、模型评估;2️⃣ 特征工程:特征提取、特征预处理、特征降维、特征选择、特征组合;3️⃣ 特征预处理:归一化、标准化:归一化是将值映射到 0, 1 之间,(当前值 - 该列最小值) /(该列最大值 - 该列最小值),但它容易受到异常值的影响,因为只考虑了最大和最小值;所以需要标准化 :使用到该列的均值和方差。
2. ML包含 Deep Learning DL深度学习: 深度学习的特征工程不仅可以人来做、也可以算法来做 ,如图中的就是神经网络:左边是输入层、右边是输出层、中间的一大段是隐藏层:蓝色是隐藏层1、黄色是隐藏层2、右边蓝色是隐藏层3、可以有更多的4,5,...层;里面连接线的一个个点叫 做神经元,每个神经元做两件事:加权求和、激活函数 ;
3. 机器学习是实现人工智能的一种途径。深度学习是机器学习的一个子集 ,也就是说深度学习是实现机器学习的一种方法。深度学习是机器学习中一种基于对数据进行特征学习的算法。深度学习是基于人工神经网络,深度是指网络中使用多层:如图画出的3个神经元(竖着的),并不是3层,横着的才是 3层 :即便每层只有一个,也还是 3层,但每层一个是有问题的,正常不会每层只有一个,每层神经元至少两个;每层都通过非线性变换处理数据,并逐渐提取出更复杂、更抽象的特征:输入层对接的是特征 ,一行样本可以有多列数据,一列数据称为特征 即输入层的神经元的个数与特征列有关,样本有几个特征 (或者说几列),则输入层就有几个神经元 ;对于隐藏层的第一层(中间部分第一层):假设有100个神经元,它会和输入层的每个神经元连接 即下一层的所有神经元会和上一层的每个神经元建立连接,此为全连接层 (图一中 RNN 和 CNN 都有的 全连接层);全连接一般有两个单词:Neal、FC(Full Connect);
即 假设第1层有4个特征,第2层有100个神经元,则算法就会从前一层的4个特征中抽取出 100个特征 ,用于第 2层,怎么抽的、抽的哪个特征都不知道,因为看到的都是数值;若第 3层有100个神经元,则会从 第2层的100个特征中抽取 100个特征用于第 3层,即写了几个就会通过算法抽取多少个;)
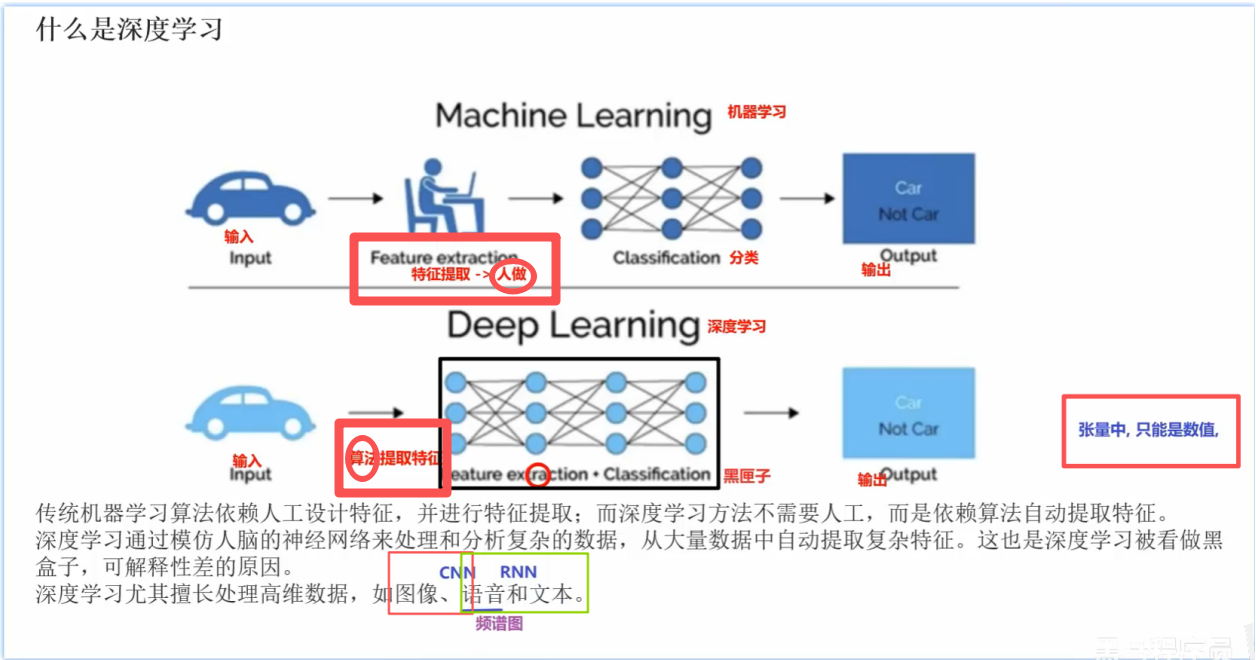
(对于机器学习:1️⃣ Input是输入、2️⃣ Output是输出、中间要经历:3️⃣ Feature extraction 特征提取 --> 由 人 来做的、4️⃣ Classification 分类:机器学习中有3类问题:分类、回归、聚类,聚类算法在实际项目中只有在项目初期时才会用到(K-Means算法实际工作中基本用不到)、分类问题用的最多,熟练了解分类问题的指标 如精确度、召回率、F1值、ROC曲线 、AUC值等;
对于深度学习:1️⃣ Input是输入、2️⃣ Output是输出、中间要经历:3️⃣ Feature extraction + Classification 由 算法 来做特征提取,里面是黑盒的,它的可解释性差,如 图中为什么是3 层,每层3个神经元 这样的效果好 这是由算法来计算决定的,无法解释;如果前一层传的是张三、李四,不能抽取出 体积<8 这种,所以 张量中只能是数值 且只能是浮点型 或者布尔值,因为布尔值会把 true看成1、false看成0 来做处理,所以可说成 张量中只能是数值,即从前一层的一堆数字中 基于某些公式再次抽取 一些数字用于后一层 ,层层如此,最终基于这些数值之间的关系来做预测,输出结果;图中每一个圆圈就叫一个神经元,一个神经元做两件事:先做加权求和、再做激活函数;激活函数 就是把加权求和的结果映射成一个概率,类似于逻辑回归 ,这么做的原因是:假设没有激活函数,则整个神经网络全部都在做 加权求和,意味着整个神经网络只能做线性问题,不能做分类问题,正是因为在加权求和的基础上做了激活函数,有了概率神经元才能做分类问题,换言之 深度学习既能做分类问题、又能做回归问题 ;
所以 ML 和 DL 两者最大的区别是特征工程到底是 人做 还是 算法做,人做就是 机器学习 ML,算法做就是深度学习 DL;)
3. 深度学习的特点
(多层非线性变换:
(每一层都有神经元,每个神经元都要做 加权求和 和 激活函数,所以1️⃣ 多层非线性的意思是:①深度学习由多个层次组成;②每一层都应用非线性激活函数对输入数据进行变换,每个神经元都先做加权求和,在做激活函数,这样做的目的是让深度学习既能处理回归、也能处理分类,此为多层非线性变换,这个非线性指的就是激活函数,增加了一个分类的概率的值;2️⃣ 自动特征提取:由算法自动帮忙提取,每个神经元都会和前层所有神经元连接,此为全连接的由来;3️⃣ 大数据和计算能力,严格意义上讲与深度学习的关系并不大,主要在硬件上;4️⃣ 可解释性差;)
3.1 什么叫反向传播?
对于正向传播 :数据(特征)从左到右逐层传递,即先给到输入层,输入层处理完后给到隐藏层,隐藏层再给到输出层,此为正向传播;
对于反向传播 :后一层的每一个神经元都要与前一层的每一个神经元做加权求和(即多元线性回归,加权求和:y =wx + b;对于黄色框的神经元来讲,它需要6个参数:即 5w+b,5即此神经元所在层的上一层即输入层有 5个神经元,即x=5,再加一个b,所以此神经元共有6个参数;所在层的其它神经元也有6各参数;对于它后一层的每个神经元都有 7个参数:6个w + b = 7)。正向传播,传播到最后一层,拿到结果了就能算出损失,算出损失后,基于损失 逆向传播(即反向传播)来更新权重;更新权重:每一层都有很多 w +b即 w参数,所以会基于这次的损失 来逆向更新w,所有的参数更新完后,再进行一次正向传播,又可以再预测一次结果,再算出损失,再来反向更新 w参数,这样会导致 参数越来越接近正确值,模型拟合效果就会越来越好;
总结:正向传播就是从前往后算出结果的过程,逆向(反向)传播是拿着结果来反推,更新前面的参数,此为反向传播;
4. 常见的深度学习模型
主要记住 CNN 卷积神经网络、RNN 循环神经网络;

(卷积神经网络CNN:卷积层、池化层、全连接层,这些是隐藏层、还有输入层、输出层;他们的区别都在于隐藏层;卷积神经网络 CNN 主要是处理图像 -- > CV;
循环神经网络RNN:主要处理文本 --> NLP;
自编码器:Transformer...
总结:深度学习 主要来处理图像和文本,图像有 CNN 卷积神经网络、文本有 RNN 循环神经网络)
5. 深度学习的应用场景
一共四个方面:
1️⃣ 计算机视觉(Computer Version): 处理图像的;
2️⃣ 自然语言处理(Natural Language Processing NLP):处理语言的;
3️⃣ 大语言模型(Large Language Model) :...;(3️⃣ 推荐系统(Recommendation Systems):基于历史的评分和行为,推荐相关的电影、音乐、电视剧;
4️⃣ 多模态大模型(VLM/ MMM);(什么叫多模态?:之前的大模型只处理一种,如倾向处理文本的、倾向处理视频的、倾向处理音频的,即一种模型只处理一种;但多模态大模型的一个大模型可以处理所有的任务,只要用这一个模型即可;)