Day 4:让 Agent 记住你------短期记忆实现
《7天从零手搓 AI Agent》第4篇 · 今日成果:Agent 能记住对话历史,支持真正的多轮对话
 大家好,欢迎来到小撒的私房菜,我是小撒。
大家好,欢迎来到小撒的私房菜,我是小撒。
做了3天,你的 Agent 现在面临一个很尴尬的问题。
你告诉它:"我叫小明,我想了解 Python。"
然后你问:"刚才我说我叫什么来着?"
它不知道。
因为它天生失忆。
为什么 AI 天生失忆
每次你调用 OpenAI API,对 AI 来说都是一个全新的请求。
上一次调用发生了什么?它不知道。
API 本身是无状态的,就像 HTTP 请求一样,每一次都是独立的。
那 ChatGPT 是怎么做到记住你之前说的话的?
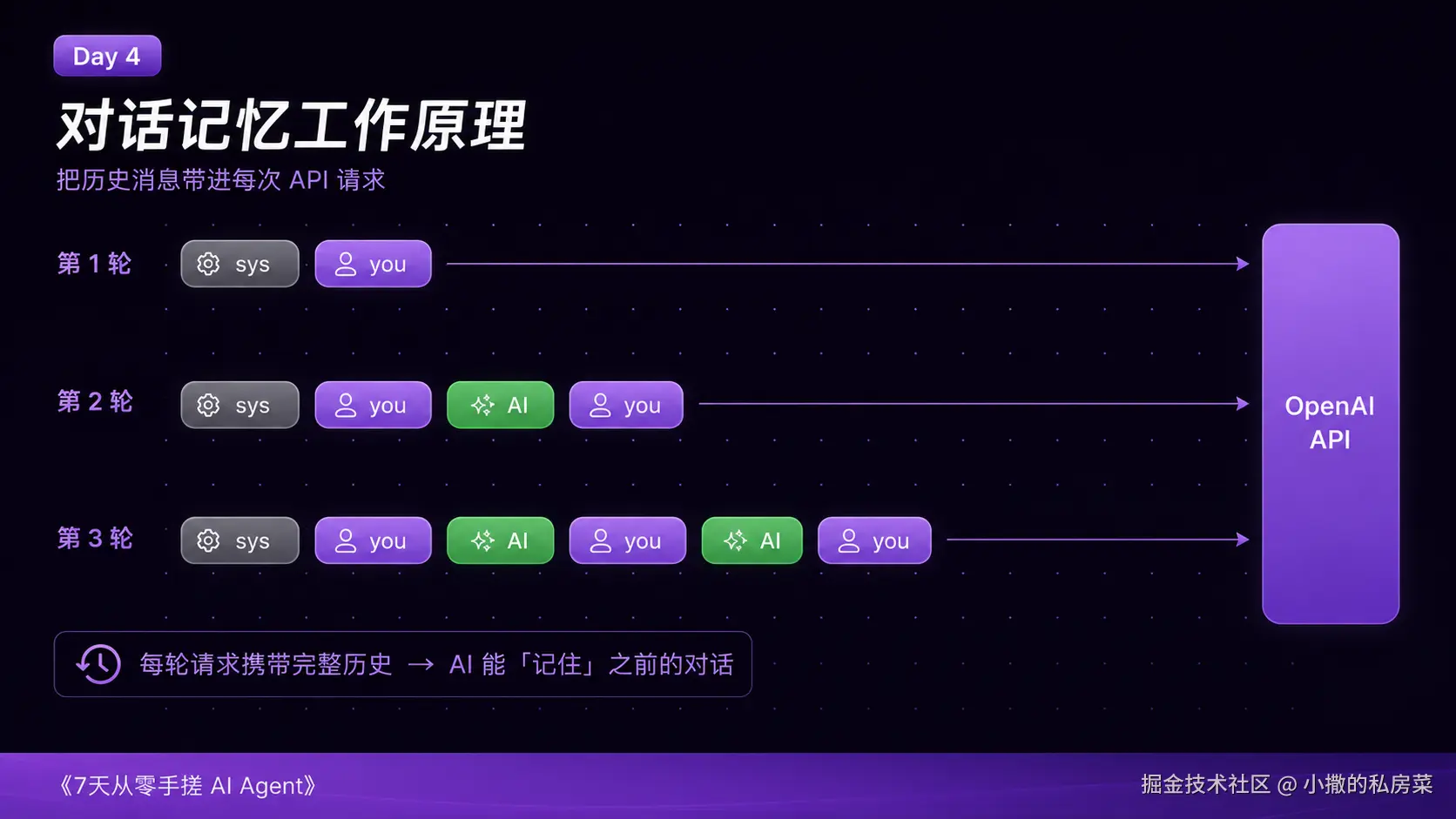
它把所有历史消息都带进了每次 API 请求里。
发给 API 的不只是你这次说的话,而是:
css
[你第1次说的话]
[AI 第1次回答]
[你第2次说的话]
[AI 第2次回答]
[你第3次说的话] ← 当前问题把这一长串消息都塞进请求,AI 就能"看到"之前发生了什么,就好像它记得一样。
记忆的本质:把历史消息带进每次请求。
短期记忆实现
新建 memory/short_term.py:
python
# memory/short_term.py
from dataclasses import dataclass, field
from typing import Literal
MessageRole = Literal["system", "user", "assistant"]
@dataclass
class Message:
role: MessageRole
content: str
@dataclass
class ShortTermMemory:
"""
保存对话历史,控制上限。
system 消息永远保留;超出上限时删除最旧的非 system 消息。
"""
max_messages: int = 20
_messages: list[Message] = field(default_factory=list)
def add(self, role: MessageRole, content: str) -> None:
self._messages.append(Message(role=role, content=content))
self._trim()
def _trim(self) -> None:
"""超过上限时,删除最旧的非 system 消息。"""
non_system = [m for m in self._messages if m.role != "system"]
while len(non_system) > self.max_messages:
for i, msg in enumerate(self._messages):
if msg.role != "system":
self._messages.pop(i)
break
non_system = [m for m in self._messages if m.role != "system"]
def to_api_format(self) -> list[dict]:
"""转成 OpenAI API 需要的格式。"""
return [{"role": m.role, "content": m.content} for m in self._messages]
def clear_non_system(self) -> None:
"""清除对话历史(保留系统提示)。"""
self._messages = [m for m in self._messages if m.role == "system"]
def count(self) -> int:
return len([m for m in self._messages if m.role != "system"])把记忆接入 Agent
把 agent.py 里的函数改成一个类:
python
# agent.py
import json
import re
from llm import chat
from tool_registry import get_tools_description, execute_tool
from memory.short_term import ShortTermMemory
SYSTEM_PROMPT_TEMPLATE = """你是一个智能助手,可以使用工具,也能记住对话历史。
{tools_description}
每次回复必须是 JSON,格式二选一:
使用工具:
{{"action": "use_tool", "tool": "工具名", "params": {{"参数名": "参数值"}}}}
直接回答:
{{"action": "answer", "content": "你的回答"}}
只返回 JSON。"""
def safe_parse_json(text: str) -> dict:
try:
return json.loads(text)
except json.JSONDecodeError:
pass
match = re.search(r'\{.*\}', text, re.DOTALL)
if match:
try:
return json.loads(match.group())
except json.JSONDecodeError:
pass
return {"action": "answer", "content": text}
class Agent:
def __init__(self) -> None:
self.memory = ShortTermMemory(max_messages=20)
# 系统提示只加一次,永远保留
self.memory.add("system", SYSTEM_PROMPT_TEMPLATE.format(
tools_description=get_tools_description()
))
def chat(self, user_input: str) -> str:
# 把用户消息存入记忆
self.memory.add("user", user_input)
# 带上完整历史调用 AI
ai_response = chat(self.memory.to_api_format())
print(f"[AI 决策]: {ai_response}")
# 把 AI 回复也存入记忆
self.memory.add("assistant", ai_response)
decision = safe_parse_json(ai_response)
if decision["action"] == "answer":
return decision.get("content", ai_response)
if decision["action"] == "use_tool":
tool_name = decision.get("tool", "")
params = decision.get("params", {})
print(f"[执行工具]: {tool_name},参数:{params}")
tool_result = execute_tool(tool_name, params)
print(f"[工具结果]: {tool_result}")
# 把工具结果存入记忆,让 AI 基于结果给出最终答案
self.memory.add("user",
f"[工具 {tool_name} 返回结果]:{tool_result}\n"
f"请基于此结果,用自然语言回答用户的问题。"
)
final = chat(self.memory.to_api_format())
final_parsed = safe_parse_json(final)
final_text = final_parsed.get("content", final)
self.memory.add("assistant", final_text)
return final_text
return f"(未知 action:{decision.get('action')})"
def clear(self) -> None:
self.memory.clear_non_system()为什么要改成类?
因为现在 Agent 有了状态(记忆)。有状态的东西,用类来管理比用函数更自然。self.memory 跟着实例存在,跨多次 chat() 调用保持。
更新 main.py
python
# main.py
from agent import Agent
def main() -> None:
print("=== Day 4 Agent:有记忆了!===")
print("命令:/clear 清除记忆 | quit 退出\n")
agent = Agent()
while True:
user_input = input("你:").strip()
if not user_input:
continue
if user_input.lower() in ("quit", "exit"):
print("再见!")
break
if user_input.lower() == "/clear":
agent.clear()
print("记忆已清除,开始新对话。\n")
continue
result = agent.chat(user_input)
print(f"Agent:{result}")
print(f"(当前记忆:{agent.memory.count()} 条消息)\n")
if __name__ == "__main__":
main()效果演示
arduino
你:我叫小明,我在学 Python
Agent:你好小明!Python 是一门很棒的编程语言...
(当前记忆:2 条消息)
你:刚才我说我叫什么名字?
Agent:你说你叫小明,并且正在学习 Python。
(当前记忆:4 条消息)
你:/clear
记忆已清除,开始新对话。
你:我叫什么名字?
Agent:您还没有告诉我您的名字。
(当前记忆:2 条消息)为什么需要 max_messages 上限
每条消息都占用 token(AI 的"计费单位")。
对话越长,每次请求携带的 token 越多,两个后果:
- 费用增加(按 token 计费)
- 超过模型上限会报错(gpt-4o-mini 上限128K token,很难超,但别的模型可能更小)
max_messages=20 是个合理默认值。超过就自动删最旧的消息。
System 消息为什么永远保留?
System 消息里有工具说明和行为规范。如果被删掉,AI 就不知道有哪些工具可以用了。所以删消息时跳过 system。
一个常见误解
有人以为"记忆"是 AI 把对话内容"学进去了"。
不是的。
每次对话结束,这些消息就消失了。下次新建一个 Agent() 对象,记忆是空的。
这叫短期记忆(Session Memory)------只在当前会话里有效。
如果你想让记忆跨会话持久化(比如第二天还记得你上次说的话),需要把消息存到文件或数据库,这是长期记忆,是更进阶的话题。
今天的项目结构
bash
my_agent/
├── .env
├── llm.py
├── agent.py # 重构成 Agent 类,集成记忆
├── tool_registry.py
├── memory/
│ ├── __init__.py
│ └── short_term.py # 新增:短期记忆
├── tools/
│ ├── __init__.py
│ ├── search.py
│ ├── weather.py
│ ├── calculator.py
│ └── datetime_tool.py
└── main.py小结
今天做了一件看起来简单但非常重要的事:
让 AI "记住"对话历史,本质是把历史消息带进每次 API 请求。
这是所有对话型 AI 应用的基础机制,包括 ChatGPT 本身。
ShortTermMemory 这个类,你在 LangChain 里会看到对应的 ConversationBufferMemory,在 OpenAI Assistants API 里会看到 thread------都是同一个思路,只是封装程度不同。
明天,Day 5:《Agent Loop------整个系列里最关键的一天》
Agent 真正的力量,在于它能反复思考、反复使用工具,直到任务完成。
这就是 ReAct 模式。明天讲。
代码在 GitHub,文末有链接。
如果本教程对你有所帮助,留下一个免费的三连吧,这是对我最大的鼓励♥️!