
导读
日常生活中,视频里的动作、场景、人物往往高度重复。现有视频字幕模型独立处理每个片段,导致大量片段获得完全相同的描述------在 Ego4D 数据集中,使用现成字幕器生成的片段中 66%与至少另一个片段共享相同字幕。这种重复性严重影响了基于文本的视频检索:用户必须线性浏览所有相似片段才能找到想要的。
布里斯托大学与牛津大学合作提出 "Captioning by Discriminative Prompting (CDP)",通过观察一组视觉相似片段,预测能够区分它们的"判别性提示",从而为每个片段生成唯一字幕。在自建的第一视角和循环电影评测基准上,CDP 将 text→video R@1 分别提升了 15%和10%,Cycle@1 提升最高达 35.1%。该方法即插即用,无需微调字幕模型,推理速度仅增加约 1.3 秒/片段。
文章信息
- 标题:It's Just Another Day: Unique Video Captioning by Discriminative Prompting
-
作者:Toby Perrett, Tengda Han, Dima Damen, Andrew Zisserman
-
机构:布里斯托大学(University of Bristol)、牛津大学(University of Oxford)
-
发表:International Journal of Computer Vision (IJCV), 2026
一、重复片段带来的检索困境
生活是充满重复的。日常活动的视频不可避免地包含视觉上相似的事件、场所、人物和动作。当使用现成的视频字幕模型(如 Zhao et al. 2023)时,每个片段被独立处理,结果就是大量片段获得了完全相同的描述。在 Ego4D 数据集中,**66%**的片段与至少另一个片段共享相同的字幕,因此没有唯一标识。
这种字幕的唯一性缺失严重影响了基于文本的检索。当用户搜索"打开冰箱"时,会得到几十条完全相同的字幕结果,必须逐一浏览才能找到目标片段。现有的字幕模型专注于生成高质量的描述,却从未考虑过"唯一性"这一需求。
本文提出的 CDP 框架首次系统性地解决了视频片段的唯一字幕生成问题。它的核心思路是:与其让字幕器独立工作,不如让它"看到"所有相似片段,然后找出每个片段独有的特征,并用这些特征来引导生成。
二、CDP 方法:从判别性提示到唯一字幕
2.1 问题形式化
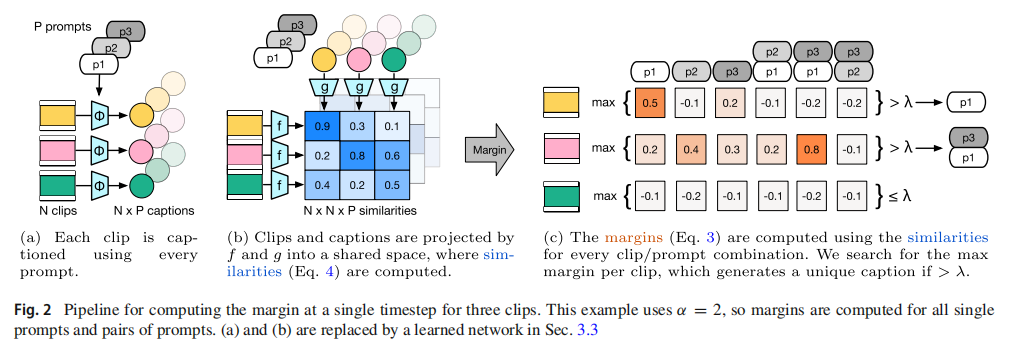
给定 N 个视频片段集合 V = {v₁, v₂, ..., v_N},目标是输出一组唯一的字幕 C = {c₁, c₂, ..., c_N}。模型假设已有一个冻结的视频字幕器 Θ(v, p)(可接受可选提示 p)和一个双编码器视频‑文本模型(编码器 f 和 g)。唯一性由余弦相似度条件严格定义(原文 Eq.1):v_i 与 c_i 的相似度必须大于 v_i 与任何其他 c_j 的相似度,也大于任何其他 v_j 与 c_i 的相似度。
2.2 判别性提示与组合搜索
方法的核心是使用一组固定提示库 B(例如从训练集叙述中提取的高频 N‑gram)。对于每个片段 v_i,系统尝试每个提示 p,计算视频‑字幕相似度 s(v_i, v_i, p)。并定义唯一性余量M(v_i, p) = s(v_i, v_i, p) - max( max_{j≠i} s(v_j, v_i, p), max_{j≠i} s(v_i, v_j, p) )。选择使余量最大的提示作为判别性提示。当单个提示不够时,允许组合最多 α 个提示(默认 α=3),取平均相似度。如果最大余量仍低于阈值 λ(默认 0.1),则通过时间扩展:将片段延长,观察后续不同发展(如"X 然后 Y" vs "X 然后 Z")。
2.3 CDPNet:高效近似搜索
组合全搜索计算量巨大(O(NP^α))。为此,训练一个轻量级网络 CDPNet,只用视频片段和提示直接预测相似度,避免实际生成字幕和计算嵌入。CDPNet 是一个 2 层 4 头的 Transformer,总参数量仅 1.6M,预测误差均值为 0,标准差 0.11。最终,CDP 将单片段字幕时间从 4.5 秒增加到 5.8 秒,而不用 CDPNet 的穷举搜索需要 300 秒。
图片来源于原论文
三、数据集与评测基准
为评估唯一字幕生成,作者构建了两个新基准:
3.1 第一视角基准(Egocentric Benchmark)
基于 Ego4D 的 NLQ 训练集,抽取 30K 条重复次数 ≥10 次的叙述,每条随机采样 10 个片段(可跨视频),生成 300K 片段的训练集。评估集为 300 组 × 10 片段,来自 NLQ 验证集,固定不变。提示库从训练集叙述中选取频率最高的 10 个 N‑gram,并手工去除语义相似的条目。最终提示包括:"holding", "carrying", "looking at", "picks up", "walks", "opens" 等。
3.2 循环电影基准(Timeloop Movies Benchmark)
利用 Wikipedia 列出的时间循环电影(共 71 部),手工标注重复片段时间戳。要求每部电影至少 3 个重复时刻,且这些时刻视觉上几乎相同。最终得到 10 部电影、63 个片段,每组大小 3-10。由于数据稀缺,训练集使用 Condensed Movie Dataset(非循环电影)构造视觉相似度 >0.92 的 30K 组片段作为代理。
3.3 评测指标
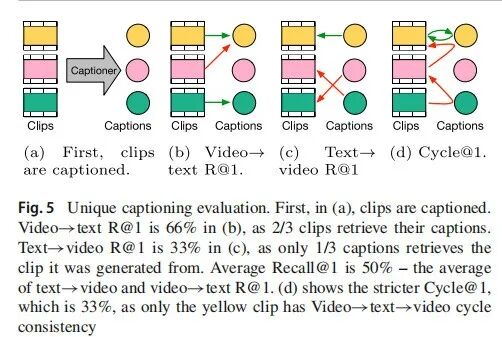
采用标准检索指标:Text→Video R@K, Video→Text R@K, Avg R@1(两者平均值),以及更严格的 Cycle@1(要求 v_i 检索到 c_i 且 c_i 检索回 v_i,等价于 Eq.1 的唯一性条件)。图 5 清晰展示了这些指标的区别。
图片来源于原论文
四、实验结果与关键数据
4.1 第一视角基准 (LaViLa VCLM 作为基础字幕器)
| T (秒) | 方法 | Text→Video R@1 | Avg R@1 | Cycle@1 |
|---|---|---|---|---|
| +0s | LaViLa VCLM | 40% | 34.3% | 22.0% |
| +0s | + CDP | 55% (+15) | 45.0% (+11) | 26.0% (+4) |
| +5s | LaViLa VCLM | 42% | 36.3% | 23.0% |
| +5s | + CDP | 69% (+27) | 57.0% (+21) | 38.6% (+16) |
| +10s | LaViLa VCLM | 45% | 40.5% | 25.3% |
| +10s | + CDP | 77% (+32) | 65.0% (+25) | 47.1% (+22) |
| +30s | LaViLa VCLM | 47% | 43.0% | 27.2% |
| +30s | + CDP | 86% (+39) | 76.0% (+33) | 62.3% (+35) |
T=+0s 表示仅使用当前 5 秒片段;T=+30s 表示可额外访问后续 30 秒内容(共 7 个片段)。CDP 在所有时间步和所有指标上均显著优于基线。
4.2 循环电影基准 (Video-LLaMA 作为基础字幕器)
| T (秒) | 方法 | Text→Video R@1 | Avg R@1 | Cycle@1 |
|---|---|---|---|---|
| 0s | Video-LLaMA | 37% | 35.0% | 18.3% |
| 0s | + CDP | 47% (+10) | 42.0% (+7) | 25.0% (+7) |
| 2s | Video-LLaMA | 39% | 36.5% | 25.4% |
| 2s | + CDP | 51% (+12) | 48.0% (+12) | 32.0% (+7) |
| 4s | Video-LLaMA | 38% | 36.5% | 18.4% |
| 4s | + CDP | 62% (+24) | 53.0% (+17) | 37.4% (+19) |
| 10s | Video-LLaMA | 36% | 35.5% | 18.2% |
| 10s | + CDP | 73% (+37) | 63.0% (+28) | 44.5% (+26) |
循环电影中,随着时间的推移,故事线出现分歧,CDP 能捕获这些差异并生成独特字幕。最大改善为 Avg R@1 +25%,Cycle@1 +26.3%。
4.3 长视频案例研究
在 10 条平均 40.3 分钟的真实第一视角长视频上(每条约 483 个连续 5 秒片段),进行 text→video 检索。CDP(使用 T=+5s)将 R@1 从 12%(LaViLa VCLM)提升至 32%(+20%),R@3 从 20% 提升至 48%(+28%),R@5 从 26% 提升至 56%(+30%)。定性示例中,CDP 能区分"在洗手池前的两个片段"、"推手推车的两个片段(一个走向出口,一个绕仓库)"以及"使用钢笔的不同时刻"。
4.4 消融实验
-
提示组合数 α:α=1 时 Avg R@1 为 47.6%;α=2 时提升至 56.3%;α=2 且增加时间到 +10s 后达到 66.8%。α=3 性能最佳,且性能高于 α=2 的增益随 T 增大更明显。
-
提示贡献:与主动物品(holding, carrying, picks up, looks at)相关的提示被选择最多,且单独使用效果最好。
-
余量阈值 λ:增大 λ 会使得被判定为"唯一"的片段减少,但 Cycle@1 提高,λ=0.1 时两者平衡良好。
-
CDPNet 精度:预测相似度与真实相似度之间误差均值为 0,标准差 0.11,大多数误差在 0.1 以内。
4.5 其他字幕模型验证
在 LaViLa 和 Video-LLaMA 之外,CDP 也提升了 VideoBLIP 模型在 egocentric 基准上的 Avg R@1(从 48.7% 到 52.4%)和 Cycle@1(从 37.5% 到 46.5%),表明方法具有模型无关性。
4.6 定性展示
图 8‑11 展示了丰富的定性结果。例如,egocentric 中三个"looks around the shelves"的片段,CDP 通过"the other man is talking"(clip1)、"looks at shopping list"(clip2)和"picks up"(clip3, 需向后 10s)加以区分。在《土拨鼠之日》中,三个"a man wakes up"片段,CDP 在 2s 时靠"lying down"、6s 时靠"window"特征、10s 时靠其他角色和地点实现唯一标识。

图片来源于原论文
五、总结与未来方向
CDP 首次提出了唯一视频字幕生成任务,并通过判别性提示(从固定提示库中选择)以及可选的时间扩展,为重复性视频片段生成可区分的描述。在两个新基准(第一视角日常视频、时间循环电影)上,CDP 显著提升了 text→video 和 video→text 检索性能,并提供了严格的 Cycle@1 指标来评估完整唯一性。该方法无需微调字幕模型,即插即用,计算开销小。
未来方向包括:学习提示而非使用固定库、跨整个数据集的唯一字幕生成、以及利用多个具有不同专长的字幕模型协同工作。代码和数据完全开源,可从项目网站获取。
