微调
什么是NLP四范式
NLP任务四种范式数据集&训练集要求对比表
|--------------------|-----------------------|------------------------------------|----------------------------------|-------------------------------------------------------------------------------------------------------------|-------------------------------------|---|---|
| | | | | | | | |
| 模型类型 | 核心定位 | 核心任务 | 数据形式 | 训练集核心要求 | 适用数据类型 | | |
| 第一范式(传统机器学习范式) | 传统规则+机器学习的NLP处理方案 | 文本分类、情感分析、简单语义匹配等基础NLP任务 | 结构化标注数据、人工设计特征的文本数据 | 1. 依赖人工设计的特征工程(如TF-IDF、词袋模型);2. 需要大量标注数据,数据质量直接影响模型效果;3. 模型泛化能力弱,对领域数据适配性差;4. 训练数据需和任务场景高度匹配 | 标注好的分类数据集、规则化的文本语料、领域内小规模标注数据 | | |
| 第二范式(深度学习范式) | 端到端深度学习的NLP处理方案 | 序列标注、文本生成、机器翻译、语义理解等复杂NLP任务 | 连续文本序列、分布式向量表示的文本数据 | 1. 依赖预训练的词向量/字向量(如word2vec、GloVe);2. 减少了人工特征工程的工作量;3. 模型精度相比第一范式有显著提升;4. 仍需要大量标注数据,对数据规模要求较高 | 大规模无标注语料(用于预训练词向量)、任务相关的标注数据集、长文本语料 | | |
| 第三范式(预训练+微调范式) | 大模型预训练+下游任务微调的通用NLP方案 | 全品类NLP任务,包括文本理解、生成、翻译、摘要、问答等 | 大规模无标注文本语料(预训练)+ 下游任务小规模标注数据(微调) | 1. 预训练阶段使用海量无标注文本语料,学习通用语言知识;2. 微调阶段仅需少量任务相关标注数据,即可适配下游任务;3. 模型精度显著提升,泛化能力大幅增强;4. 对训练数据的标注成本要求大幅降低 | 全网大规模无标注文本语料、各领域小规模标注数据集、多任务混合训练数据 | | |
| 第四范式(预训练+Prompt范式) | 零样本/少样本的通用NLP处理方案 | 零样本分类、少样本学习、指令跟随、通用问答等无需大量标注的NLP任务 | 指令化Prompt文本、少量示例样本、无标注原始文本 | 1. 无需大量标注数据,仅通过Prompt指令即可引导模型完成任务;2. 零样本场景下无需任何任务相关标注数据;3. 少样本场景下仅需少量示例样本即可达到不错的效果;4. 大幅降低了NLP任务的落地门槛,适配性极强 | 无标注原始文本、少量示例样本、指令化Prompt语料、跨领域通用文本 | | |
| 在整个NLP领域,整个发展历程是朝着精度更高、少监督,甚至无监督的方向发展的。而 Prompt-Tuning是目前学术界向这个方向进军最新也是最火的研究成果。 |||||| | |
Fine-Tuning回顾
Fine-Tuning属于一种迁移学习方式,在自然语言处理(NLP)中,Fine-Tuning是用于将预训练的语言模型适应于特定任务或领域。Fine-Tuning的基本思想是采用已经在大量文本上进行训练的预训练语言模型,然后在小规模的任务特定文本上继续训练它.
解决方法:Prompt-Tuning, 通过添加模板的方法来避免引入额外的参数,从而让模型可以在小样本(few-shot)或者零样本(zero-shot)场景下达到理想的效果.
Prompt-Tuning技术介绍
基于Fine-Tuning的方法是让预训练模型去迁就下游任务,而基于Prompt-Tuning的方法可以让下游任务去迁就预训练模型, 其目的是将Fine-tuning的下游任务目标转换为Pre-training的任务.
Prompt-Tuning入门方法

Prompt-Tuning:相当于给模型出了一道填空题:"我很喜欢这部电影。Overall, it was MASK.",让模型用它本来就会的「完形填空」能力,间接帮你完成分类任务。
- 原始任务
判断句子:我觉得这部电影超好看! 是积极还是消极。
- 传统 Fine-tuning
- 把句子丢给模型,模型的
[CLS]输出再喂给一个新训练的分类器,让它直接输出 "积极 / 消极"。 - 缺点:模型得专门学 "怎么直接输出情感标签",需要大量数据,容易学偏。
- Prompt-Tuning(三步走)
① 搭模板:给句子加个带空的 prompt,变成填空题:
我觉得这部电影超好看!Overall, it was [MASK].
② 让模型填空 :模型会用它预训练好的完形填空能力,给[MASK]位置打分:
amazing(太棒了):90%terrible(糟透了):1%
③ 映射标签:提前说好规则:
- 填的词是
amazing/awesome/good→ 积极 - 填的词是
terrible/bad/awful→ 消极所以这个句子,就被判定为积极。
Fuine区别
| 方法 | 核心逻辑 | 优点 | 缺点 |
|---|---|---|---|
| 硬 Prompt | 手写固定文本模板 | 简单、零训练 | 效果靠模板设计,不稳定 |
| 软 Prompt | 可训练的向量模板 | 效果好、通用 | 比硬 Prompt 多一点训练成本 |
| 前缀 / 后缀 / 上下文 | 模板放的位置不同 | 适配不同任务 | 位置不对会影响模型理解 |
- 硬 Prompt(Hard Prompt)
核心概念:用固定的、人类手写的文本做模板,就是你 PPT 里那种 "It was MASK" 的形式。
特点:
模板是固定的字符串,不会变,也不参与训练。
完全靠模型的预训练能力和模板的设计质量,来完成任务。
例子:情感分类的模板固定为:句子 这句话的情感是MASK。
- 软 Prompt(Soft Prompt,也叫连续 Prompt)
核心概念:不手写模板,而是用 ** 可训练的向量(embedding)** 代替固定文本,直接拼在输入前面 / 后面,只训练这些向量,模型主体不动。
特点:
模板不是文字,是一串可学习的 "虚拟 token"。
这些向量会在训练中自动优化,比手写模板效果更好,也更通用。
例子:在输入句子前加 10 个可训练的虚拟 token V1V2...V10,模型只微调这 10 个向量,BERT 主体冻结。
- 只调 Prompt 参数(冻结大模型)
核心概念:大模型(BERT/GPT 等)的所有参数都完全不动,只训练 Prompt 部分的参数(软 prompt 向量、MLM 头)。
特点:
训练成本极低,只需要很少的显存和数据。
完全保留大模型的通用知识,不会 "学偏"。
对应你 PPT 里的例子:只微调 MLM 头,BERT 主体不动。
- 轻量微调 + Prompt(半参数微调)
核心概念:冻结大模型主体,只微调模型的少量附加层 / 适配器(Adapter),配合 Prompt 一起优化。
特点:
比纯 Prompt 效果更好,又比全量微调省资源。
常见的比如 Prefix Tuning、Adapter Tuning,本质都是 "Prompt + 少量参数微调"。
方法
GPT-3 开创了不修改模型,只靠提示词就能学习的玩法,核心有两个:
-
**In-context Learning(上下文学习)**不给模型更新参数,只在提问时给它几个 "例子",它就能照着例子的格式和逻辑回答。比如情感分析任务:
例子 1:Review: Delicious food! Sentiment: Positive例子 2:Review: The food is awful. Sentiment: Negative新问题:Review: Good meal! Sentiment: ?模型一看例子,就知道要输出 Positive/Negative,直接给出 Positive。
-
**Demonstrate Learning(示范学习)**就是上面这种 "给例子" 的方式,让模型知道任务的语义和格式,不用专门训练。
局限性:这种纯靠自然语言提示的方法,对模型规模要求极高,小模型用不了;而且提示词的设计对结果影响巨大,同一个任务换个提示词效果可能直接崩盘。
例子:情感分析
例子 1:评论:这家火锅太好吃了!情感:正面例子 2:评论:服务太差,再也不来了。情感:负面新问题:评论:味道不错,很满意。情感:?
模型一看例子,就知道要输出:正面
PET 就是:把任务变成 BERT 最擅长的填 MASK
两个核心:
-
Pattern(模板)
-
Verbalizer(标签映射)
-
Pattern(模板)
套一个带 [MASK] 的句子:
评论:文本。整体感受是 MASK。
- Verbalizer(标签映射)
把分类结果,映射成一个词:
- 正面 → 好
- 负面 → 差
完整例子
输入文本:这家奶茶超好喝
套模板:
评论:这家奶茶超好喝。整体感受是 MASK。
BERT 填 [MASK],概率最高的是 好 → 就判断为 正面
PET 的问题
-
模板要人工写
-
换个模板,准确率差很多
- 模板 A:准确率 92%
- 模板 B:准确率 86
| 方法 | 核心思路 | 改不改模型 | 优点 | 缺点 |
|---|---|---|---|---|
| Hard Prompt | 手写中文提示词 | 不改 | 零成本 | 效果不稳定 |
| Prompt Tuning | 前缀软向量 | 不改 | 低成本多任务 | 小模型差 |
| P-Tuning V1 | 学习提示向量 | 不改 | 比人工提示稳 | 小模型一般 |
| P-Tuning V2 | 每层都加提示 | 不改 | 效果稳、通用 | 调参稍麻烦 |
| Prompt 全量微调 | 用提示格式 + 改模型 | 改 | 效果最好 | 大模型太贵 |
进阶
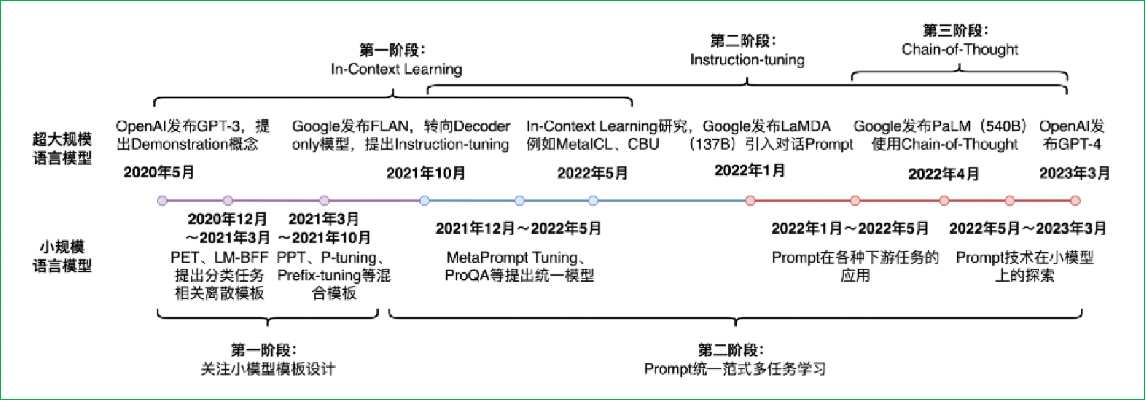
超大规模参数模型Prompt-Tuning方法
- 对于10 亿参数以上的超大模型(比如 GPT-3),Prompt-Tuning 比传统 Fine-tuning 效果更好、成本更低。
- 根本原因:大模型学过海量语料、预训练任务足够有效,只需要给对提示,就能直接完成任务,不用再改模型参数。
| 方法名称 | 核心概念(大白话) | 操作方式 | 举个例子 | 适用场景 |
|---|---|---|---|---|
| 上下文学习 In-Context Learning | 给模型看几个「示例」,让它照着例子学 | 输入里加少量标注好的样本当提示 | 例:1+1=2;2+3=5;问题:4+5=? |
少样本 / 零样本任务,快速上手 |
| 指令学习 Instruction-Tuning | 教模型听懂「指令」,按指令干活 | 用大量 "指令 + 回答" 数据微调模型 | 训练数据:指令:把这句话翻译成英文;输入:你好;输出:Hello |
让模型适配多任务、多指令 |
| 思维链 Chain-of-Thought (CoT) | 让模型像人一样「一步步想」,别直接给答案 | 在提示里加上 "一步步推理" 的引导 | 问题:10个苹果吃了3个又买了5个,剩几个?思考:先算吃了3个剩7个,再算买了5个是12个,所以答案是12 |
推理类任务(数学、逻辑题) |
指令学习方法的应用
上下文学习方法的应用
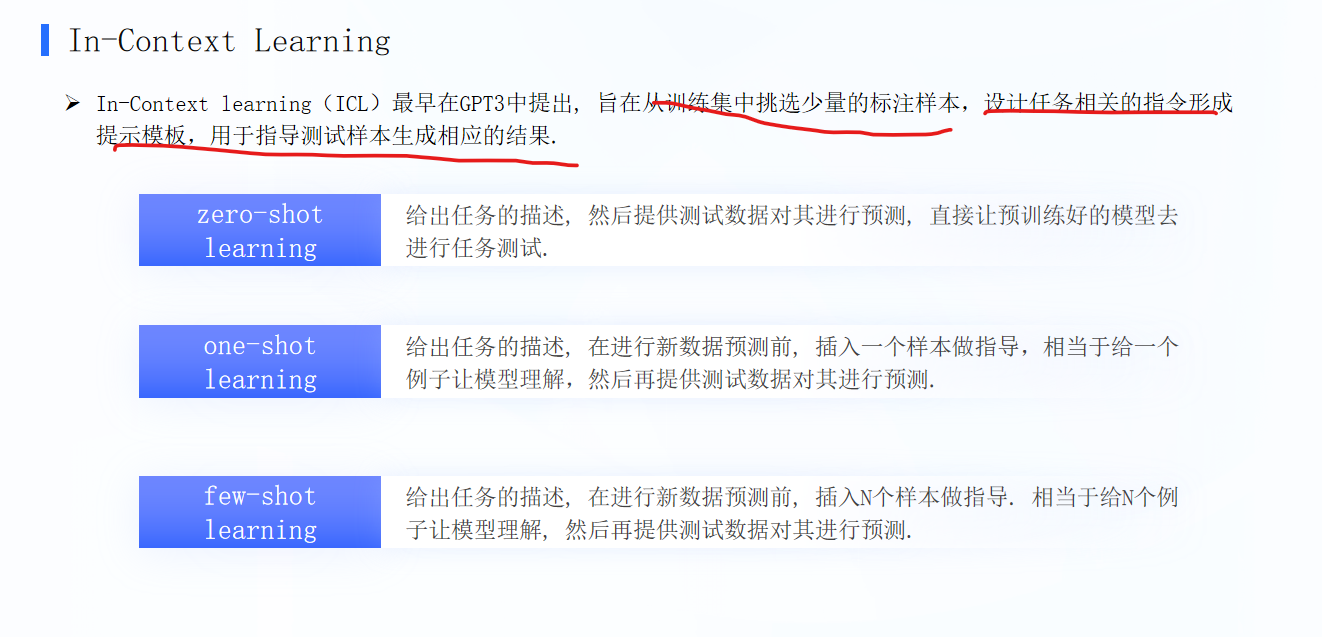
- Zero-Shot:啥例子都不给,纯靠模型自己悟
- 任务:判断下面这句话的情感,输出"积极"或"消极"。 句子:这部电影拍得太烂了,我全程快进。 情感:
- One-Shot:给 1 个例子,教它怎么干活
- 任务:判断句子的情感,输出"积极"或"消极"。 例子: 句子:这部电影拍得超棒,我看了三遍。 情感:积极 句子:这部电影拍得太烂了,我全程快进。 情感:
- Few-Shot:给好几个例子,让它照着模板抄作业
指令学习方法的应用
Instruction-Tuning(指令学习),本质就是:用「指令 + 任务」的格式,给模型做微调,让它学会听懂不同任务的 "人话指令",并按要求输出结果。它是让模型从 "会补全句子",变成 "会听指令干活" 的关键步骤。
| 模式 | 例子 | 核心逻辑 |
|---|---|---|
| Prompt(提示) | 带女朋友去了一家餐厅,她吃的很开心,这家餐厅太__了! |
激发模型的补全能力,靠完形填空 / 续写来间接完成任务 |
| Instruction(指令) | 判断这句话的情感:带女朋友去了一家餐厅,她吃的很开心。选项:A=好,B=一般,C=差 |
激发模型的理解能力,用明确的指令告诉模型 "做什么 + 怎么输出" |
Prompt 是让模型 "猜",Instruction 是让模型 "听命令",后者对模型来说更简单、更可控。
Instruction-Tuning 怎么实现?
核心是给同一个任务,设计多个不同的指令模板,然后用这些模板训练模型:
举个例子(文本蕴含任务):
原始数据:
- 前提:
俄罗斯宇航员Valery Polyakov在1994-1995年创造了连续太空停留438天的记录- 假设:
俄罗斯人保持着最长太空停留记录- 目标标签:
yes(蕴含)设计多个指令模板:
基于上面的段落,我们能得出<假设>吗?选项:yes/no我们能从这段话推断出以下内容吗?<假设> 选项:yes/no阅读下面的内容,判断假设是否能从前提中推断出来:前提:<前提> 假设:<假设> 选项:yes/no训练方式:用这些模板把数据包装成「指令 + 输入 + 输出」的格式,喂给模型微调,让它学会不管指令怎么说,都能正确完成任务。
-
能力激发方向不同
- Prompt:激发模型的补全 / 续写能力(比如完形填空、接句子)
- Instruction-Tuning:激发模型的指令理解与执行能力(比如按要求分类、翻译、回答)
-
对模型的要求不同
- Prompt:不用微调模型,直接给提示就能用,靠模型预训练知识 "猜"
- Instruction-Tuning:必须微调模型,用大量「指令 + 任务」数据训练,让它学会理解指令模式
-
适用场景不同
- Prompt:适合零样本 / 少样本快速测试,或模型无法微调的场景
- Instruction-Tuning:适合打造通用大模型(比如 ChatGPT),让它能听懂各种不同的用户指令
区别
| 阶段 | 主体是谁 | 发生了什么 | 对应你说的场景 |
|---|---|---|---|
| Instruction-Tuning(训练阶段) | 模型开发者 | 用海量「指令 + 任务」数据微调模型,教它听懂指令 | 你给豆包发提示词不是这个阶段 |
| 指令执行(使用阶段) | 你和豆包 | 你给模型发提示词,模型用训练好的能力执行任务 | 你给豆包发提示词就是这个阶段 |
Instruction-Tuning 是 **"教模型听懂指令的过程",而你给豆包发提示词,是"模型学会之后,你给它发指令让它干活"**,完全是两码事。
- 老师教你数学题(Instruction-Tuning)
- 你做题的时候,给你出一道应用题让你解(指令执行,也就是你发提示词)
思维链方法的实现
思维链(Chain-of-Thought, CoT) 是一种专门提升大模型复杂推理能力 的提示策略,核心是:让模型在给出最终答案前,先写出一步步的推理过程,像人做题时写 "解题步骤" 一样,避免模型直接 "蒙答案" 出错。
它本质是一种上下文学习(ICL)的特殊形式,通过在提示中加入 "推导步骤",引导模型模仿人类的逻辑链来解决问题。
- 标准 Prompt(无思维链)
输入:罗杰有5个网球。他又买了两盒网球,每盒有3个网球。他现在有多少网球?
模型输出(错误):答案是27
问题:模型跳过计算步骤,直接猜答案,很容易出错。
- CoT Prompt(带思维链)
输入:
plaintext
问:罗杰有5个网球。他又买了两盒网球,每盒有3个网球。他现在有多少网球?
答:罗杰一开始有5个网球,2盒3个网球,一共就是2*3=6个网球。5+6=11。答案是11。
问:食堂有23个苹果,如果他们用掉20个后又买了6个。他们现在有多少个苹果?
模型输出(正确):
食堂原来有23个苹果,他们用掉20个,所以还有23-20=3个。他们又买了6个,所以现在有3+6=9个。答案是9。
效果:模型跟着示例,先写清每一步计算,再得出答案,正确率大幅提升。
- 模型输出(正确):
食堂原来有23个苹果,他们用掉20个,所以还有23-20=3个。他们又买了6个,所以现在有3+6=9个。答案是9。 - 效果:模型跟着示例,先写清每一步计算,再得出答案,正确率大幅提升
| 类型 | 核心逻辑 | 输入示例 |
|---|---|---|
| Few-shot CoT(少样本思维链) | 在提示里给模型几个「问题 + 推理步骤 + 答案」的例子,让它照着学 | 上面的数学题例子,就是典型的 Few-shot CoT |
| Zero-shot CoT(零样本思维链) | 不给例子,直接用一句话引导模型自己写步骤,比如加一句:Let's think step by step |
罗杰有5个网球...他现在有多少网球?Let's think step by step. |
- 逻辑性:每一步推理都要前后关联,形成完整的逻辑链条,不能跳步或矛盾。
- 全面性:思考过程要覆盖所有关键信息,避免遗漏条件(比如题目里的 "两盒""每盒 3 个")。
- 可行性:每一步推导都要符合实际逻辑,比如数学题的计算步骤要能算通。
- 可验证性:每一步都可以用事实 / 数据验证对错,比如计算过程可以反向验算。
| 维度 | 你给我写的 "一步步计算" 提示词 | 论文里的 Chain-of-Thought |
|---|---|---|
| 本质 | 你在使用阶段,通过提示词手动引导我做推理 | 一种专门的提示策略,是大模型上下文学习的一种技术方案 |
| 触发方式 | 完全靠你写的指令引导,模型被动执行 | 可以通过 Few-shot(给例子)或 Zero-shot(一句话引导)两种方式触发 |
| 目标场景 | 你用来解决自己的具体问题(比如算数学题、做逻辑题) | 用来系统性提升大模型在推理任务上的通用性能 |
PEFT大模型参数高效微调方法原理
给大模型做 "轻量定制" 的技术,不用全改模型,只微调一点点参数,就能适配你的任务。
大模型就像一个功能齐全的万能厨师,全量微调相当于:
- 把厨师整个换一遍,重新教他只做川菜,成本极高,还容易把他本来会的粤菜、西餐全忘光。
而 PEFT 就相当于:
- 只给厨师一本「川菜定制菜谱」,厨师本身的手艺完全不动,只照着这本菜谱学做川菜。
- 成本极低,还不影响他做其他菜,甚至效果和 "换厨师" 差不多。
核心优势
- 省成本:不用高性能显卡,普通电脑也能玩大模型
- 不遗忘:模型的通用能力完全保留,不会学偏
- 易部署:每个任务只需要存一份很小的 "定制菜谱",不用存整个模型
| 方法 | 大白话解释 | 类比 |
|---|---|---|
| Prefix/Prompt-Tuning | 在输入句子前面加一串 "可训练的虚拟提示词",只改这些词的参数 | 给厨师的菜谱开头加一句 "今天客人要吃辣的川菜",让他自动按这个要求做菜 |
| Adapter-Tuning | 在模型的每一层里插几个 "小插件",只训练这些插件 | 给厨师的锅加个 "川菜专用调味器",只调这个调味器,锅本身不动 |
| LoRA | 用两个很小的矩阵,近似模拟模型参数的变化,只训练这两个矩阵 | 给厨师的手戴个 "微调手套",只通过手套控制他的动作,手本身不用改 |
一句话:PEFT 的一种,专门在输入句子前面加 "可训练的前缀提示",只微调这些前缀,让模型按你的要求干活。
核心逻辑(大白话)
固定大模型:大模型本身的所有参数,完全不动,就像厨师本身的手艺不变。
加虚拟前缀:在你输入的句子前面,加一串 "可训练的虚拟词"(不是你写的,是模型自己学出来的),就像菜谱开头的 "任务要求"。
只训练前缀:只调整这些虚拟词的参数,让它们学会引导模型输出你想要的结果。
举个例子
比如你想让模型把中文翻译成英文:
传统全量微调:把整个模型改成 "只会中英互译" 的版本,成本极高。
Prefix-Tuning:
在输入句子前面加一串虚拟前缀:V1V2V3 我今天吃了苹果
只训练这 3 个虚拟词,让它们学会告诉模型 "接下来要做翻译任务"。
模型看到这些前缀,就会自动把后面的句子翻译成英文,大模型本身完全不用改。
| 方法 | 核心区别 | 大白话类比 |
|---|---|---|
| Prompt-Tuning | 只在输入层加可训练提示,是 Prefix-Tuning 的简化版 | 只在菜谱开头写一句话要求 |
| P-Tuning | 提示词位置不固定,可以插在句子中间 | 可以在菜谱的不同位置加备注 |
| Prefix-Tuning | 在模型的每一层都加可训练前缀,效果更强 | 不仅菜谱开头,连做菜的每一步都加了引导提示 |
Adapter Tuning
在大模型的每一层之间,插入几个小小的 "适配器插件",只训练这些插件,模型主体完全不动。
打个比方
还是拿万能厨师举例:
- 全量微调:把厨师整个换掉,只教他做川菜。
- Prefix-Tuning:在菜谱开头加一句 "今天做川菜" 的提示词。
- Adapter Tuning:给厨师的锅,加一个「川菜专用调味器」,只调这个调味器的参数,锅本身完全不用改。
- 加插件:在模型的每一层之间,都插入一个小小的 Adapter 模块。
- 只训插件:训练时,模型主体的所有参数都冻住,只调 Adapter 的参数。
- 插件原理 :
- 先把高维数据压缩成低维(down-project)
- 经过一个简单的非线性层处理
- 再把低维数据还原回原来的高维(up-project)
- 加了一个 "跳过连接",保证就算插件没调好,也不会影响模型正常工作。
为什么需要 LoRA?
Adapter Tuning 有两个小问题:
插件插在模型中间,推理时会增加额外计算,导致速度变慢(延迟问题)。
Prefix-Tuning 会占用输入的长度,压缩下游任务的可用序列。
于是微软推出了LoRA(低秩适应),解决了这些问题。
核心逻辑(一句话)
在模型的线性层旁边,加两个很小的矩阵 A 和 B,只训练这两个矩阵,模型主体完全不动。训练完可以把 A+B 合并到原模型里,推理时不会有任何额外开销。
打个比方
Adapter Tuning:给锅加调味器,每次做菜都要过一遍调味器,会慢一点。
LoRA:给锅的 "操作手柄" 加一个「微调补丁」,训练时只调这个补丁,做完直接把补丁焊死在锅上,做菜时和原来的锅一样快。
它的工作方式(大白话)
冻住原模型:大模型的所有参数完全不动。
加 "旁支" 矩阵:在每个线性层旁边,加两个矩阵 A 和 B:
A:把数据从高维压缩到低维(比如从 768 维压到 8 维)
B:再把低维数据还原回高维
训练时只更新 A 和 B,原模型的权重不变。
训练后合并:训练完成后,把 A 和 B 的结果,直接加到原模型的权重里。这样推理时,和原模型的结构完全一样,没有任何额外开销。
| 方法 | 改造位置 | 推理时是否有额外开销 | 核心优势 |
|---|---|---|---|
| Prefix-Tuning | 输入层 / 模型各层开头 | 无(只在输入加提示) | 实现简单,适合生成任务 |
| Adapter Tuning | 模型层之间插插件 | 有(插件会增加计算) | 效果稳定,通用性强 |
| LoRA | 线性层旁加低秩矩阵 | 无(可合并进原模型) | 速度快、无延迟,目前最通用 |