https://github.com/alibaba/otter/wiki
一、Otter 整体架构图(官方)
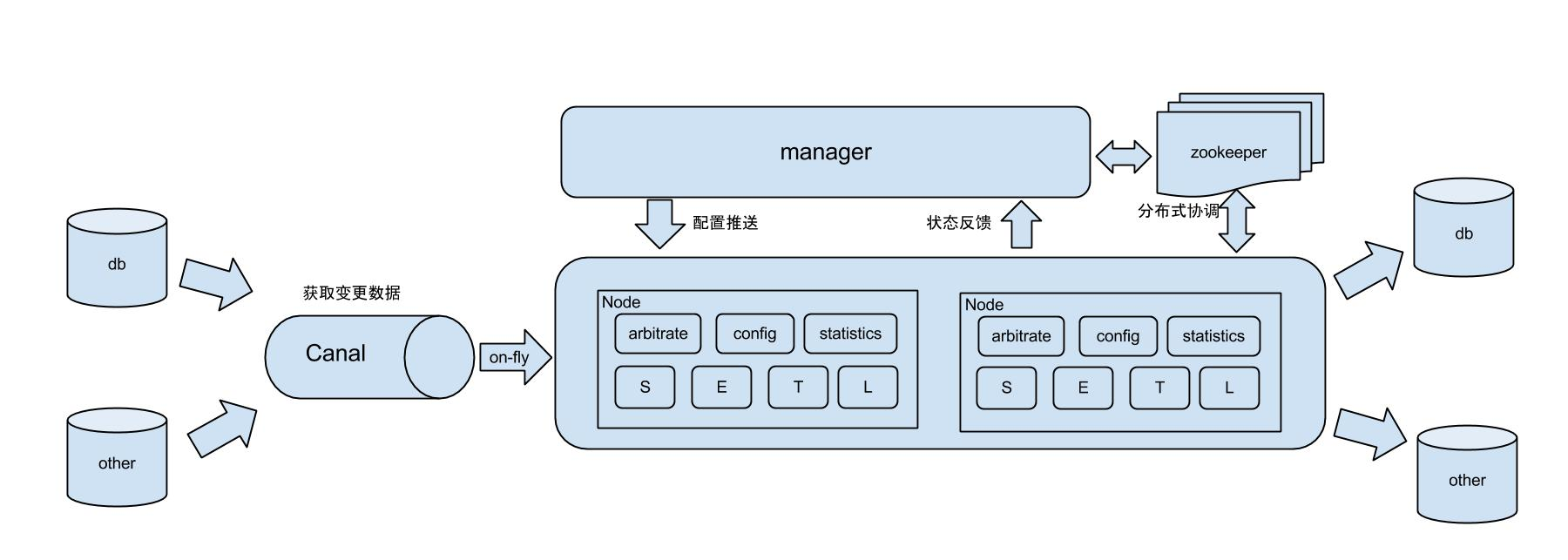
组件关系:
- 左边:源数据库(MySQL/Oracle)
- 中间:Canal → Otter Node → Zookeeper → Otter Manager
- 右边:目标数据库(MySQL/Oracle)
二、文字版架构图(更清晰)
+----------------+ +---------+
| 源库 MySQL | | Zookeeper|
| (binlog=ROW) |<------>| (协调调度)|
+--------+-------+ +----+------+
| ^
v |
+----------------+ +---------+------+
| Canal Server| | Otter Manager |
| (解析binlog) | | (Web UI/配置) |
+--------+-------+ +---------+------+
| ^
v |
+----------------+ +---------+------+
| Otter Node |<--------| 配置下发/状态回传
| (SETL执行) | +----------------+
+--------+-------+
|
v
+----------------+
| 目标库 MySQL |
+----------------+三、核心原理(一句话)
Otter 基于 Canal 模拟 MySQL Slave 拉取 binlog,在 Node 节点完成 Select→Extract→Transform→Load(SETL),由 Manager 统一管理配置与监控,Zookeeper 负责分布式调度与容错。
四、各组件作用
- 源库
- 开启 binlog,格式必须是 ROW
- 授权 canal 账号:
REPLICATION SLAVE
- Canal
- 伪装成 MySQL Slave,实时拉取并解析 binlog
- 输出标准化的增量数据事件(INSERT/UPDATE/DELETE)
- Otter Node(核心worker)
- S(Select):接收 Canal 数据
- E(Extract):解析、过滤
- T(Transform):字段映射、数据转换
- L(Load):批量写入目标库
- Zookeeper
- 集群协调、节点选举、任务分配
- 保证多个 Node 高可用与负载均衡
- Otter Manager
- Web 管理界面:配置数据源、Channel、Pipeline、映射规则
- 推送配置到 Node 、收集同步状态/延迟/位点
- 监控告警、位点管理、重置同步
五、同步流程(极简五步)
- 源库写入 → 生成 binlog
- Canal 拉取 binlog → 解析成数据变更事件
- Node 接收事件 → 过滤/转换/拼装 SQL
- Node 批量执行 SQL → 写入目标库
- Manager 监控进度 → 异常告警
六、核心概念对照
- Channel:同步通道(单向=1个Pipeline,双向=2个Pipeline)
- Pipeline:源→目标的完整同步链路
- DataMediaPair:源表 ↔ 目标表 映射
- ColumnPair :字段映射(如源
user_name→目标name)