宏观架构:两端分离
|--------|---------------|---------------------------------------------------------------------------------|
| 业务模块 | 核心关联表 | 测开设计用例的突破点 |
| B端商品上架 | pms_product | 验证异常边界:如果前端不传必填项 product_category_id(分类ID),后端是优雅报错还是直接抛出 500 异常? |
| C端前台浏览 | pms_sku_stock | 数据驱动验证:当 pms_product 表中有 10 万条数据时,前台接口的加载时间是否会因为缺少索引导致严重的慢查询(Slow Query)? |
| C端核心下单 | oms_order | 状态机流转断言:用户下单未付款,状态是否为 0;当利用 RabbitMQ 取消超时订单时,状态是否能准确变更为 4(已关闭),且库存成功回滚? |
1.mall-admin (B端-后台管理系统):
主要给内部运营人员使用,负责"造物"(例如上架商品、设置秒杀活动、处理退款) 。它的特点是接口逻辑极其复杂,但并发量很低 。我们后续为了压测而准备海量测试数据,依据的就是 B 端的业务逻辑
1.1 pms_ (商品模块 - 核心造物):
运营人员上架商品的数据在这里
pms_product (商品主表):里面的字敦就是造数据的基础属性
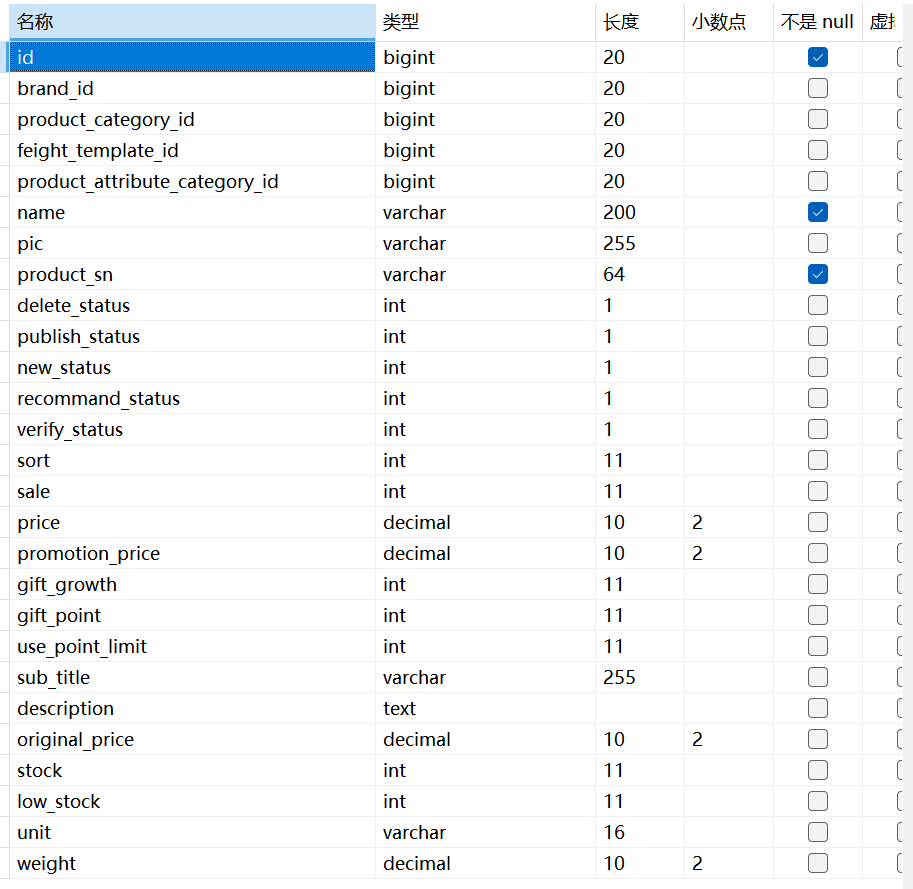
注意:
造数据时选择核心字段:
(1)数据库底层强制必填项:表中不是null的项,绝对不为空的项需要造出来
(2)业务链路必填项:满足业务逻辑的数据需要造出来
表单独立性:
每个表的字段属性都是独立的,只有关系型数据库需要表之间设计范式加入的product_category_id、brand_id 等字段,像"钩子"一样去关联其他的表,而不是把名字、价格等属性再在其他表里复制一遍。
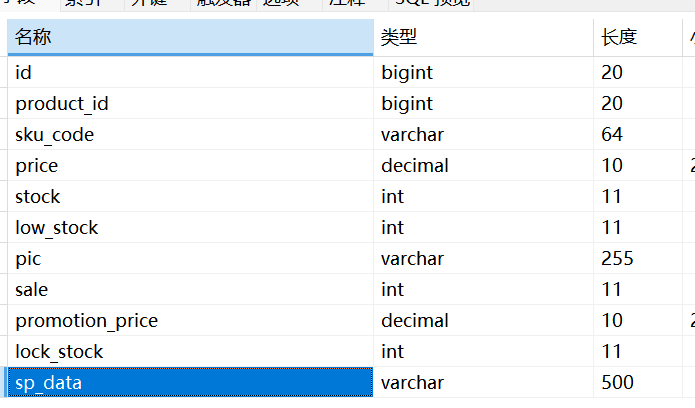
1.2.pms_sku_stock(SKU 库存表):
理解一个商品比如 (iPhone 15)如何裂变到SKU(比如 黑色 128G、白色 256G)并且进行标价,这是高并发的重灾区
1.3.oms_ (订单模块-核心管理):
oms_order (订单主表):里面的status 字段叫状态机,显示商品购买后的状态(0->待付款;1->待发货;2->已发货;3->已完成;4->已关闭;5->无效订单)
1.4.ums_(用户与权限模块)
动态映射(Swagger 触发,Navicat 抓包)
进行一次实际的业务操作:新增商品->更新商品状态,查看后台数据库信息是否更新
1.4.1 进入登录接口并获取token
在使用 api 接口修改数据前,需要获得管理员权限才可以修改数据库数据
在swagger里找到类似 UmsAdminController (后台用户管理) 相关的分组
找到登录接口,路径通常是 /admin/login
点击 Try it out,在请求体中输入默认的管理员账号和密码(通常账号是 admin,密码是 macro123,如果不确定,可以去 Navicat 查看 ums_admin 表)。
这里注意:后端数据库只能查到账号信息,密码信息用BCrypt算法加密成密文,该密码由前端输入用户名和密码后连接到数据库,数据库对密码进行加密得到,且这个密文是无法逆向破解的,所以无法通过数据库得到密码值
点击 Execute 执行。如果账号密码正确,你会看到响应体(Response body)里返回了一个长长的字符串,这个字段通常叫 token 。把这个长字符串复制下来
获取到的token是
eyJhbGciOiJIUzUxMiJ9.eyJzdWIiOiJhZG1pbiIsImNyZWF0ZWQiOjE3Nzg1ODkxMzQyODMsImV4cCI6MTc3OTE5MzkzNH0.LNYj4rfN2wQYOAc7P6H_VfpBktz-PDubxeXuvWcDd54B0U5R4n0Bg7-dJdTDUrY_Q_GzKY3l8srrHuRskwfvPA
回到swagger顶部页面,点击带锁的 Authorize 按钮,输入Bearer (一定有空格)+token后,确定🔒关闭后,重新更新接口并填入修改数据
1.4.2 添加新的商品信息
在填入数据前查看该表pms_product中必须填入数据的属性,这些是添加商品信息时必写的内容
在swagger中选择创建商品,输入修改的内容,点击excute,观察响应体是否为"操作成功",返回值200,data为1
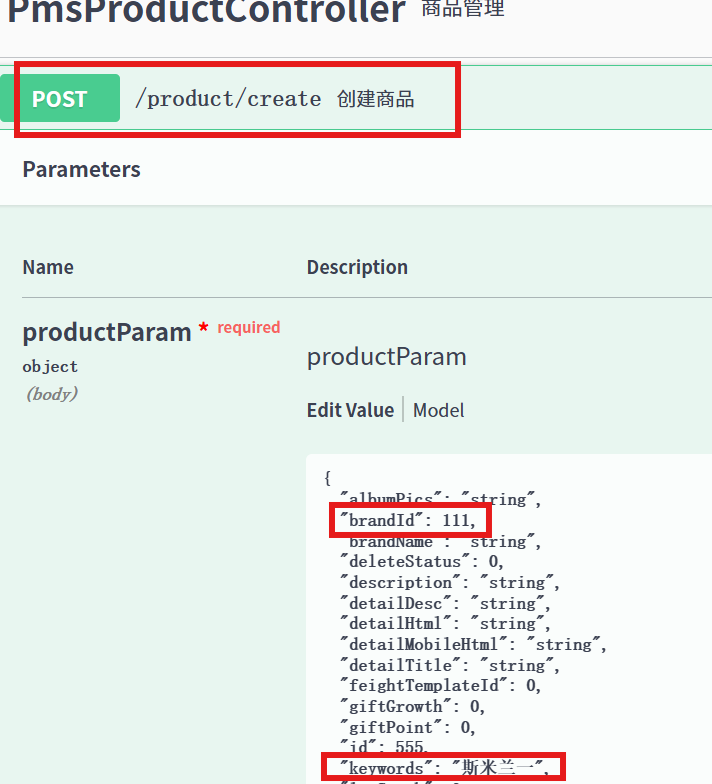
在后端数据库刷新pms_product表,查询到对应数据,操作成功

2.mall-portal(C端-前台移动端):
这是面向海量真实买家的端,主要负责"消费"(例如浏览商品、加入购物车、高并发秒杀、提交订单) 。它的特点是性能瓶颈的高发地,也是用 JMeter 压测,寻找系统极限的压测主战场 。
2.1 ums_ (会员认证模块):
普通买家在前台登录->请求 UmsMemberController ->查询会员表 ums_member-?返回 C端 专属 Token
2.2 pms_ (商品与营销模块):
买家刷新首页->调用 /home/content->高速从 Redis 缓存或 pms_product 表中读取你之前用 Python 灌入的 10 万条商品数据
2.3 oms_(订单与分布式事务模块):
核心下单流转:买家点击"提交订单" -> 调用 OmsPortalOrderController -> 触发严格的订单状态机(0: 待付款 -> 异步发送消息给消息队列 RabbitMQ -> 扣减 pms_sku_stock 库存 -> 最终持久化落盘至订单主表 oms_order )
3.本项目的压测架构:
服务器:VMware 内存6GB
VNMware 桥接网络:确保虚拟机和客户机连通,数据成功打入
客户机:Windows系统的PyCharm
数据库:navicat通过 3306 端口,实时拉取了虚拟机里 MySQL 的画面
被测服务器:VMware虚拟机
运行 MySQL、Redis 以及后续的后端 Java 代码。它模拟的是真实的"大厂生产环境服务器"
特点:分配了6GB内存,防止后续高并发流量打过来,MYSQL内存不够造成OOM
施压机:电脑本机Windows
用PyCharm写脚本造10W条数据,为后续Jmeter模拟压测做准备,这是一个极其消耗 CPU 计算能力和内存的动作。
特点: 本机的 CPU 绝大部分都要用来支撑 JMeter 的多线程引擎和 Python 的循环逻辑。
注意:为什么绝对不能把 Python/JMeter 放到虚拟机里跑?
资源互相踩踏: 虚拟机总共就 6G 内存。如果你在里面跑 JMeter,JMeter 发起高并发可能就要吃掉 3G 内存,那留给 MySQL 的就只剩 3G 了。最终系统崩溃,你根本不知道是被压垮的,还是 JMeter 把资源抢光了。
监控数据失真: 压测的核心是监控虚拟机的 CPU 和内存使用率,CPU到100%时无法判断是Jmeter脚本占CPU多还是后端代码太复杂导致CPU过高
内存占用问题:
在做压测时windows系统和虚拟机都占内存 ,PyCharm造的数据最终会以.ibd结尾的数据文件形式存到虚拟机虚拟磁盘里,Windows内存不占用
但在运行过程中Windows本机 Pycharm 运行消耗内存,IDEA的JAVA 程序也吃内存
虚拟机里收到10W条数据内存会升高
PyCharm 运行停止本机内存会释放,虚拟机的数据会放在硬盘里