线上接口突然变慢时,最忌讳直接猜 SQL 哪里不对。一个更稳的排查方式是先定位慢请求,再定位慢 SQL,再用执行计划看数据库为什么慢,最后围绕索引、返回字段、表设计和架构做优化。
这篇文章把慢 SQL 排查拆成一条闭环:监控发现问题 -> 慢查询日志定位 SQL -> EXPLAIN 分析原因 -> 针对性优化 -> 再验证效果 。
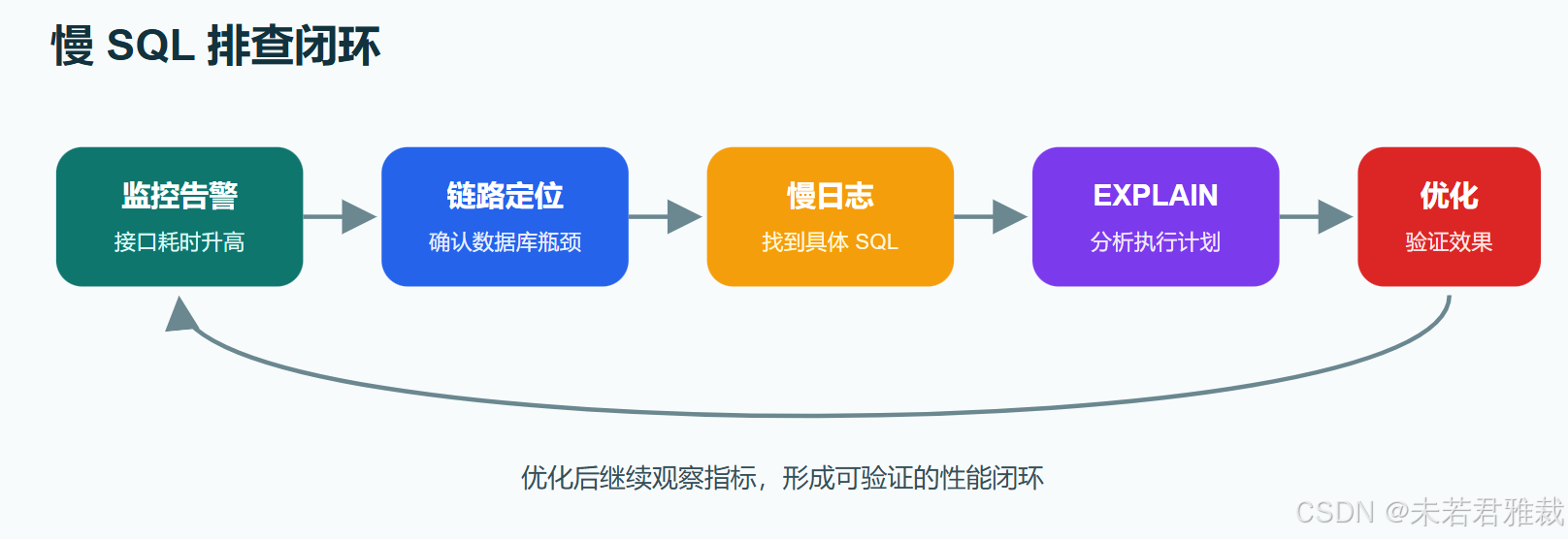
如果把排查动作画成一条线,大概是这样:
否
是
否
是
是
否
接口响应变慢
链路追踪是否指向数据库
继续排查应用代码或远程调用
查看慢查询日志
拿到具体 SQL
执行 EXPLAIN
是否命中合适索引
补索引或改写查询条件
是否扫描过多或发生回表
优化返回字段、联合索引、分页方式
检查排序、分组、Join 和表设计
压测或对比执行计划
先判断慢在哪里
接口慢不一定是数据库慢。一次请求可能慢在网关、应用代码、远程调用、缓存、消息队列,也可能慢在数据库。排查时可以先用链路追踪或监控工具确定瓶颈位置。
常见工具可以分成两类:
| 类型 | 工具 | 适合做什么 |
|---|---|---|
| 应用调试 | Arthas | 在线观察方法耗时、线程、调用栈 |
| 链路监控 | SkyWalking | 看接口链路、服务调用、慢方法和慢 SQL |
| 指标监控 | Prometheus | 观察 QPS、响应时间、连接数、资源指标 |
| 数据库日志 | MySQL 慢查询日志 | 记录超过阈值的 SQL |
如果链路追踪显示某个接口耗时主要集中在数据库访问,就可以进入 SQL 层面继续查。
开启慢查询日志
MySQL 自带慢查询日志,可以记录执行时间超过 long_query_time 的 SQL。调试环境或压测环境中,可以把阈值设置得短一些,例如 2 秒,方便快速暴露问题。
ini
slow_query_log=1
long_query_time=2配置后重启 MySQL,再观察慢查询日志文件。常见位置类似:
text
/var/lib/mysql/localhost-slow.log慢查询日志能回答两个问题:哪些 SQL 慢,以及慢到了什么程度。但它还不能直接告诉你为什么慢。下一步需要用 EXPLAIN。
用 EXPLAIN 看执行计划
EXPLAIN 或 DESC 可以查看 MySQL 准备如何执行一条 SELECT 语句。
sql
EXPLAIN
SELECT id, name, status
FROM tb_user
WHERE name = 'Tom' AND status = 1;执行计划里最常看的字段有四个:

| 字段 | 重点看什么 | 常见判断 |
|---|---|---|
possible_keys |
可能使用哪些索引 | 如果为空,通常说明可用索引不足 |
key |
实际使用哪个索引 | 有索引不代表一定会被优化器选择 |
key_len |
使用了索引的多少字节 | 联合索引中可辅助判断用到了几列 |
type |
访问类型 | 越靠近 const 越好,all 往往需要重点优化 |
Extra |
额外信息 | 关注 Using filesort、Using temporary、是否能覆盖索引 |
看执行计划时,不要只盯一个字段。更实用的顺序是先看有没有索引,再看扫描方式,最后看额外成本:
是
否
是
否
是
否
是
否
拿到 EXPLAIN 结果
key 是否为空
优先检查索引缺失或索引失效
type 是否为 all 或 index
扫描范围可能过大
Extra 是否出现 filesort 或 temporary
优化排序、分组或联合索引顺序
是否需要返回很多非索引列
可能大量回表,考虑覆盖索引或减少字段
执行计划基本健康,继续看数据量和业务链路
改完后重新 EXPLAIN
type 字段怎么看
type 可以理解为 MySQL 找数据的方式。一般来说,性能从好到差大致如下:
text
NULL > system > const > eq_ref > ref > range > index > all| type | 含义 | 优化关注点 |
|---|---|---|
const |
通过主键或唯一索引命中一条记录 | 通常很好 |
eq_ref |
连接时使用主键或唯一索引 | 通常很好 |
ref |
使用普通索引匹配 | 常见且可接受 |
range |
范围扫描 | 注意范围右侧联合索引可能失效 |
index |
扫描整棵索引树 | 比全表扫描好,但仍可能很重 |
all |
全表扫描 | 大表上通常需要重点处理 |
看到 all 不要立刻只想着加索引,还要结合返回字段、过滤条件、数据分布和排序分组方式一起看。
慢 SQL 常见原因
慢 SQL 的原因通常集中在这几类:
- 查询条件没有合适索引,导致全表扫描。
- 建了索引但写法不对,导致索引失效。
- 返回字段太多,触发大量回表,尤其是
select *。 - 多表关联顺序不合理,大表驱动小表。
- 排序、分组、去重产生临时表或额外排序。
- 数据量过大,普通分页越翻越慢。
- 表字段设计不合理,导致存储和比较成本过高。
SQL 优化可以从哪里下手
优化不要只盯着单条 SQL。更完整的思路应该包括表结构、SQL 写法、索引、连接方式和架构。
1. 表设计优化
字段类型越合适,存储和比较成本越低。能用 tinyint 就不要随手用 bigint,能明确长度就不要无限放大。
字符串字段也要区分 char 和 varchar:
| 类型 | 特点 | 适合场景 |
|---|---|---|
char |
定长,空间可能浪费,但比较稳定 | 固定长度编码、状态码 |
varchar |
变长,空间更灵活 | 用户名、标题、地址等 |
2. 查询字段优化
尽量避免:
sql
SELECT * FROM tb_user WHERE name = 'Tom';更推荐明确字段:
sql
SELECT id, name, status FROM tb_user WHERE name = 'Tom';这样不仅减少网络传输,也更容易利用覆盖索引,避免回表。
3. 避免索引失效写法
典型写法包括:在索引列上做函数或表达式运算、字符串不加引号、like '%keyword'、联合索引不满足最左前缀法则等。索引失效时,执行计划中的 key、type、rows 会给出明显信号。
4. union all 优先于 union
union 会做去重,通常需要额外排序或临时处理。如果业务允许重复,优先使用:
sql
SELECT id FROM t_user WHERE id > 2
UNION ALL
SELECT id FROM t_user WHERE id < 5;5. Join 关注驱动表
多表关联时,尽量让小结果集驱动大结果集。对于 inner join,优化器有机会调整顺序;对于 left join、right join,连接方向会限制优化空间,所以使用外连接时更要注意驱动表和索引。
面试回答模板
可以这样组织回答:
我会先通过链路追踪或监控确认慢点是不是数据库访问。如果确认是 SQL 慢,再看慢查询日志定位具体 SQL。拿到 SQL 后用 EXPLAIN 分析执行计划,重点看
type、key、key_len、rows、Extra。如果是全表扫描,就检查查询条件和索引设计;如果有回表,就看能否用覆盖索引或减少返回字段;如果有 filesort 或 temporary,就优化排序分组字段和联合索引;如果是深分页,就考虑覆盖索引加子查询或基于游标翻页。最后压测或对比执行计划,验证优化是否真的生效。
小结
慢 SQL 优化不是一句"加索引"就结束。更可靠的闭环是:先用工具定位问题,再用慢日志拿到 SQL,再用 EXPLAIN 看执行路径,最后根据具体原因处理。这样的回答既有排查顺序,也能体现你真的理解数据库如何执行查询。