导读
本文核心论述了在AI Agent参与前端开发时,必须让其具备感知浏览器实际渲染结果的能力,因为Web界面的正确性取决于代码、样式、数据、容器尺寸等多因素在运行时的组合效果,无法仅通过静态代码分析保证。为此,作者团队开发了基于Chrome DevTools Protocol的开源工具,使Agent能够操作真实浏览器,从路径、内容、视觉、交互、控制台和网络六个维度进行验证。
01 为什么需要 Browser Use
我们的业务是交付 Web 产品。最终面向用户的,不是代码,而是浏览器里渲染出来的界面。
代码正确不等于界面正确。编译、构建、类型检查只能证明代码没有明显工程错误,却无法证明用户打开页面后看到的内容不是空白、控制台是否存在报错、交互效果符合预期、甚至是布局元素是否被裁切等。
很多问题只能在运行时暴露出来,比如接口返回慢导致 loading 卡死、容器宽度变化导致按钮换行、fixed footer 遮住底部操作区、文本过长后整个卡片布局崩掉、路由跳转成功了但页面内容没更新,存在异步的时序问题导致页面展示不符合预期。这些场景有个共同特点:代码层面看不出任何问题,只有渲染出来才知道坏了。
这背后的原因也不复杂:前端界面的最终结果是组件代码、CSS cascade、运行时数据、容器尺寸、异步状态等因素共同作用的产物。代码里写了 width: 330px,但实际渲染受 max-width、box-sizing、flex-shrink 影响,计算值可能完全不同。Web 界面的正确性不是代码的静态属性,而是运行时的组合结果,你无法通过只阅读代码来推断出来完全正确的界面渲染。
我们自己开发的时候一直在做这件事:写完代码,切到浏览器,刷新页面,看一眼,回去改。这个循环如此自然,以至于我们几乎没有意识到它的重要性。但当 Agent 接手编码工作时,这个循环断掉了。Agent 只看到代码,看不到代码渲染出来的结果。
一切现状都指向这一处:我们需要 Agent 感知浏览器中的界面。
02 我们的解决方案
基于这个判断,我们开发了一套 Skill,并将其开源:github.com/hixuanxuan/...
仓库里包含多个browser操作相关的 Skill,这里着重讲一下visual-verify,面向日常前端开发验收。让Agent 能够主动打开真实浏览器,检查元素是否存在、布局是否溢出、交互状态是否正确、控制台是否报错,最终输出带截图和断言结果的验收记录。让前端改动的正确性,只由浏览器实际渲染的结果决定,Agent可以边看边改,像一个前端工程师一样基于效果出发,不断的调整代码,达到最终效果。
可以通过下面的命令安装:
sql
npx skills add hixuanxuan/browser-automation --skill visual-verify下面基于我们的想法、历程和实践来详细聊聊解决了什么问题。
03 看什么
明确了要让 Agent "看浏览器"之后,下一个问题是:到底要看什么?
我们可以把浏览器里的验证分成六个维度。
路径。从进入系统到目标界面,路径是否通畅。能不能正常登录、能不能通过导航到达目标页面、中间有没有报错或跳转异常。如果 Agent 连页面都打不开,后面的一切都无从谈起。
内容。页面上的元素是否齐全,该出现的都出现了。列表有没有渲染出来、标题文案是不是预期的、按钮有没有被条件隐藏掉。这一层特别适合用结构化的方式表达。与其让 Agent 截图然后"看起来差不多",不如写成明确的 Contract:点击"重新分析"按钮后,页面不应出现 400 错误;弹窗打开后,面板至少有一个内容子元素;提交空表单后,必填提示可以正常出现。该展示什么元素是可以被明确定义的, 模型通过这个断言描述就可以去验证。
视觉 。布局是否符合预期。有没有明显的错位、元素意外换行、间距异常、文字截断。这一层单凭代码是最难自检的,不渲染出来,永远不知道是什么元素的 overflow: hidden 把什么内容吃掉了。
交互。点击按钮之后的反应是不是对的。弹窗能不能弹出来、表单能不能提交、Tab 切换后内容有没有更新。交互验证需要 Agent 具备"操作元素后再去观察结果"的能力链。
控制台 。页面运行过程中是否有异常信号。比如 JS error、React 渲染报错、资源加载失败、字段访问 undefined 等。控制台的异常信息是当Agent发现页面的渲染不符合预期时的辅助工具,帮助Agent更快更准确定位,少做一些猜测。
网络。全过程中后端接口是否正常,请求有没有报错,响应数据是否符合预期。这一层容易被忽视,但它往往是定位问题的关键。同一个"页面没有展示内容"的表象,根因可能是组件没写对、状态没更新、接口没返回、字段名错了、权限失败、后端返回了空数组。只看 DOM 和截图根本分不清,必须结合网络信息才能定位。
这六个维度合在一起,基本覆盖了一个 Web 产品"能不能用"的问题。
04 怎么做
4.1 环境架设
Agent 要操作浏览器,首先需要一个可程序化控制的环境。我们选择了 Chrome DevTools Protocol (CDP) 作为核心通道。
CDP 是 Chrome 内置的远程调试协议,它允许外部程序连接来控制浏览器:导航页面、点击元素、注入脚本、截取屏幕,几乎所有开发者手动做的事情都可以通过 CDP 自动化完成。Agent 不需要"盯着"浏览器窗口,它通过 CDP 与浏览器对话,用截图来"看"渲染结果。
启动方式也比较简单,给 Chrome 加上 --remote-debugging-port=9222 参数即可启用 CDP。关于运行形态,有几种选择:
带界面的 Chrome:直接在开发机上启动,Agent 和开发者可以同时看到浏览器窗口。好处是调试直观,出了问题能一眼看到。
Headless Chrome:不启动图形界面,纯后台运行。适合 CI 环境或服务器部署,资源占用更少,但调试时看不到画面。
NoVNC 方案:在远程容器中跑带界面的 Chrome,通过 NoVNC 提供一个 Web 端的"远程桌面"。Agent 通过 CDP 控制浏览器,人类通过 NoVNC 在浏览器里看另一个浏览器的画面。适合协同调试场景。
同时,本地开发项目需要能自动启动。Agent 不应该每次都问人"帮我把项目跑起来",而是能够通过脚本自动完成并通过 CDP 在 Chrome 中打开它。
4.2 前置知识
Agent 需要知道两件事:CDP 在哪里,以及开发环境怎么打开。
CDP 的位置通常是 localhost:9222,Agent 通过访问 http://localhost:9222/json 可以列出当前所有 Tab 的信息,包括 Tab ID 和 WebSocket 地址。后续所有操作(导航、截图、注入脚本)都通过这些信息来定位目标 Tab。
开发环境的打开方式因项目而异,但核心信息是固定的:
-
用什么命令启动项目启动命令:如
npm run dev。 -
什么状态算启动完成了:如命令输出包含了
http://localhost:<port>,或者某个端口发HTTP请求有响应了。 -
本地调试环境的URL:通常能够根据项目的配置推理出来,或者启动命令的输出中有明确信息。
把这些整合起来,作为一个"Start Dev Server"如章节写在AGENTS.md或start-dev-server之类的Skilll中,让模型能够快速正确地启动服务开始调试,而不是在启动过程中就浪费了近10轮模型请求、30+K上下文。
4.3 重要约束
一个 CDP 端口上可能运行着多个 Tab。当多个 Agent 对话同时运行时,如果不做隔离,就会出现争抢和竞态。比如一个 Agent 正在截图,另一个 Agent 把页面导航走了。
解决方式很直接:一个对话独占一个 Tab。每个 Agent 对话在开始时通过 CDP 创建自己的 Tab,记住 Tab ID,后续所有操作都只对这个 Tab 执行。绝不在中途重新查询 Tab 列表来"重新发现" Tab,因为那可能会拿到别的对话的 Tab。
这个约束在我们的 chrome-cdp Skill 中被固化为设计原则:脚本支持 --tab <id> 参数来精确指定 Tab,如果不指定会报错,要求Agent必须独占Tab而不能偷懒,所有工作流都要求在开头固定 Tab ID,整个会话期间不变。
4.4 能力供给
CDP 给 Agent 提供的能力远不止"截个图"。下面列出我们实际用到的核心能力和它们各自解决的问题:
页面导航与等待。让 Agent 能打开目标页面、等待特定元素加载完成。这是所有后续操作的前提,解决的是"进得去"的问题。
DOM 查询与操作。在页面中执行 JavaScript,读取元素的文本、尺寸、computed style,也可以点击按钮、填写表单。这是 Agent 与页面交互的主要通道,覆盖了内容验证和交互验证。
截图。全页面截图或裁剪到特定元素。这是 Agent "看见"页面的方式,主要用于布局验证和视觉回归对比。
Console 监听 。通过 CDP 的 Runtime.consoleAPICalled 和 Runtime.exceptionThrown 事件,Agent 可以捕获页面运行时的 console 输出和未捕获异常。这个能力很容易被忽视,但实际很有用:页面上看起来正常,但 console 里一堆红色报错,说明有隐藏的运行时问题。Agent 可以主动获取 console 信息来辅助定位。
网络拦截。通过 CDP 的 Network domain,Agent 可以观察页面发出的请求和收到的响应,包括状态码、响应体、请求时序。对排查"页面空白到底是前端问题还是接口问题"特别有帮助。
脚本注入。往页面中注入自定义脚本,比如注入 VET 覆盖层做视觉对比,或者注入标注脚本在截图上画框。这是各种辅助分析能力的基础。
在这些底层能力之上,我们封装了一组脚本,统一接口,降低使用门槛,通过脚本复用也能节省Token:
arduino
navigate.mjs --- 导航到指定 URL
click.mjs --- 点击元素
fill.mjs --- 填写输入框
wait.mjs --- 等待元素出现
screenshot.mjs --- 截取页面或元素截图
eval.mjs --- 在页面中执行 JavaScript
get-text.mjs --- 读取元素文本
get-html.mjs --- 读取元素 HTML
console-check.mjs --- 收集 console 输出和异常这些脚本统一接受 --tab、--cdp 参数,形成一致的调用接口。Agent 不需要直接处理 WebSocket 和 CDP 协议细节,只需要用这些脚本组合出工作流。
在此基础上,element-screenshot Skill 提供了元素级截图的隔离模式,隐藏目标元素之外的所有内容,让截图干干净净。annotate-screenshot.mjs 则可以在截图上用红框、绿框标出特定元素的位置和尺寸,附上测量数据作为标签。这让 Agent 不只能"看",还能"指",就像我们自己用 DevTools 量尺寸一样,在截图上标出证据。这部分在后续的实践环节具体展开说。
4.5 核心契约
所有这些工具和流程背后,有一条核心原则:只有网页内容才是唯一信源,代码只是参考。
这句话听起来像是常识,但对 Agent 来说需要被反复强调。Agent 天然倾向于通过读代码来判断正确性。它看到组件的 width 写了 330px,就认为宽度是 330px。但实际渲染受父容器 max-width、box-sizing、padding、flex-shrink 等因素影响,最终的计算值可能完全不同。
所以我们在 Skill 设计中明确约定:所有断言的依据必须来自 CDP 获取的 computed style 或 getBoundingClientRect() 返回的实际尺寸,而不是源代码中的声明值。代码是手段,渲染结果才是真相。
05 工作流
Contract 模式
直接让 Agent "测试这个页面"太模糊了。它会漫无目的地到处截图、到处点击,消耗大量 Token 却没有重点。
我们的做法是用例先行。用 JSON 定义"要测什么",哪些元素应该存在、哪些交互应该正常工作、哪些尺寸应该在特定范围内。Agent 按照用例逐条执行,通过测试结果来推进任务。
但用例不是一开始就全部建立的。在 visual-verify 的工作流中,用例是分阶段构建的:先探索页面、建立认知、记录笔记,然后基于已知信息写出第一批 Checkpoint,跑一轮验证。根据验证结果,再补充和调整下一批 Checkpoint。
一个典型的 Checkpoint JSON:
json
{
"id": "CP-2",
"desc": "面板展开/收起完整场景",
"steps": [
{
"desc": "点击快捷短语按钮后面板出现",
"action": {
"type": "click",
"selector": ".quick-phrase-btn"
},
"assertions": [
{
"id": "C1",
"type": "visible",
"selector": ".quick-phrase-panel",
"desc": "面板可见"
},
{
"id": "C2",
"type": "content",
"selector": ".quick-phrase-panel",
"includes": "添加短语",
"desc": "面板包含添加按钮"
}
]
},
{
"desc": "再次点击后面板消失",
"action": {
"type": "click",
"selector": ".quick-phrase-btn"
},
"assertions": [
{
"id": "C3",
"type": "custom",
"desc": "面板不可见",
"script": "return { pass: !document.querySelector('.quick-phrase-panel')?.offsetParent, reason: 'panel visibility' }"
}
]
}
]
}Checkpoint 写好后,先跑 contract-lint 做静态校验(检查 assertion type 是否支持、必填字段是否齐全),避免格式问题浪费浏览器执行。再跑 dom-assert 在真实浏览器里执行断言。所有通过的结果写入 contract.md 作为验收记录:
yaml
## CP-2: 面板展开/收起
--- ✅ 2026-05-02
- C1: 面板可见 ✅
- C2: 面板包含添加按钮 ✅
- C3: 再次点击后面板不可见 ✅
- Baseline: panel-open.png这种渐进式的用例管理方式,既避免了前期过度规划的成本,又确保了测试覆盖随工作深入而自然扩展。
06 真实的验证过程是什么样
下面是一个完整的浏览器验证 Session,让Agent 实现"快捷短语面板"功能后自动激活 visual-verify进行验证。
环境准备
首先Agent开始启动dev环境, 这就要求在项目rules里面清晰的告诉Agent如何dev启动项目,面向Agent友好需要是非交互式的,可以直接执行的。然后尝试连接 CDP,导航到对应的页面,截取首屏截图确认页面加载正常,获取基线。
△ baseline的截图
UI 展现验证
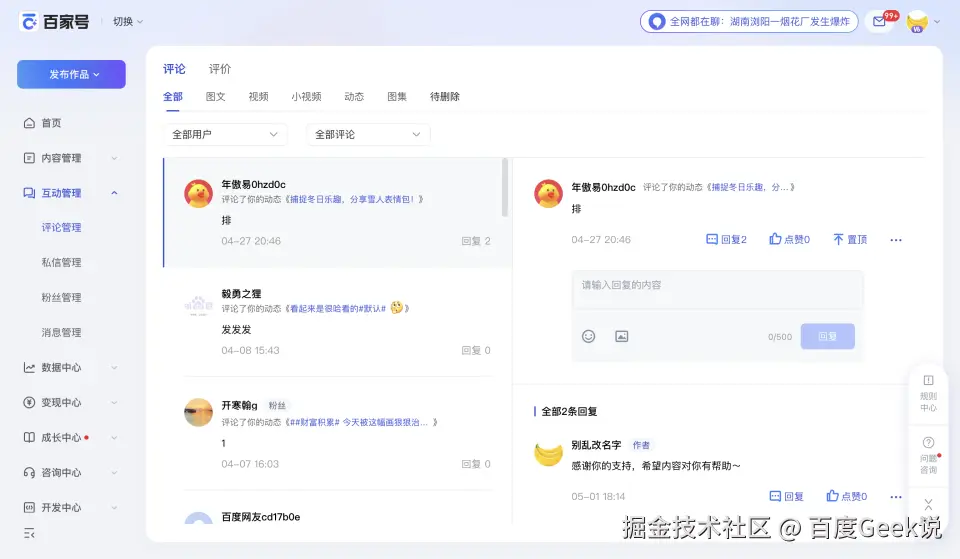
Agent 先通过 eval.mjs 读取页面 DOM 文本,确认评论列表内容已加载。
接下来要找到回复按钮。Agent 第一次用 .comment-operation .reply 查询,报 Element not found。于是它退一步,用 eval.mjs 获取评论操作区的实际 HTML 结构,发现真实类名是 comment-reply 而不是 .reply。修正选择器后成功定位。
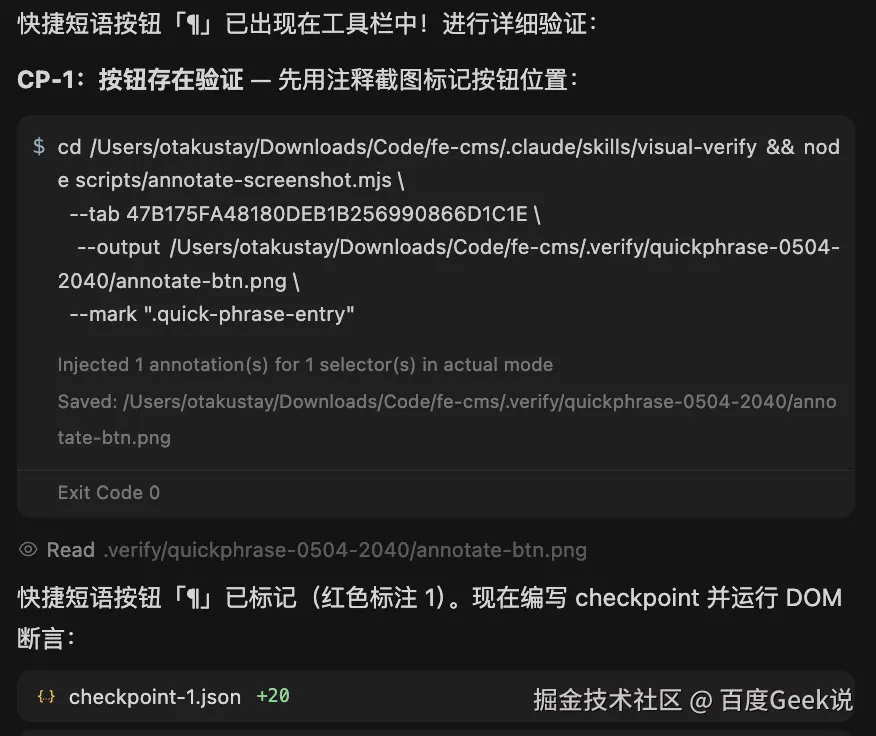
经过一次探索的过程,Agent通过检查Dom发现了问题,拿到了获取到Dom元素的正确办法,这个失败和修正被记录到 task-notes.md 中:
markdown
## Failed Selectors / Anti-patterns
### replyButton- Do not use: `.comment-operation .reply`
- Reason: 实际类名是 `comment-reply`,无嵌套- Use instead: `.comment-reply`Agent 点击快捷短语按钮,点击后 Agent 立即查询面板是否弹出,结果 hasPanel: false。但 Agent 没有立即判定功能失败,而是做了第二次更详细的查询,检查 Popover 的各层 DOM 结构,发现面板实际已经渲染,第一次查询的时机偏早,Popover 的异步渲染还没完成。这个时序信息被记录到笔记中:
yaml
## Timing / State Transitions
### popoverOpen
- Action: click .quick-phrase-btn
- Observed delay: popover DOM 渲染有 ~200ms 延迟- Reuse: 点击后等 500ms 再查询在发现问题后Agent再次 点击回复按钮展开回复框,确认快捷短语按钮已出现(hasQBtn: true),截取回复框截图,并用 annotate-screenshot 对回复框中的关键元素添加标注。
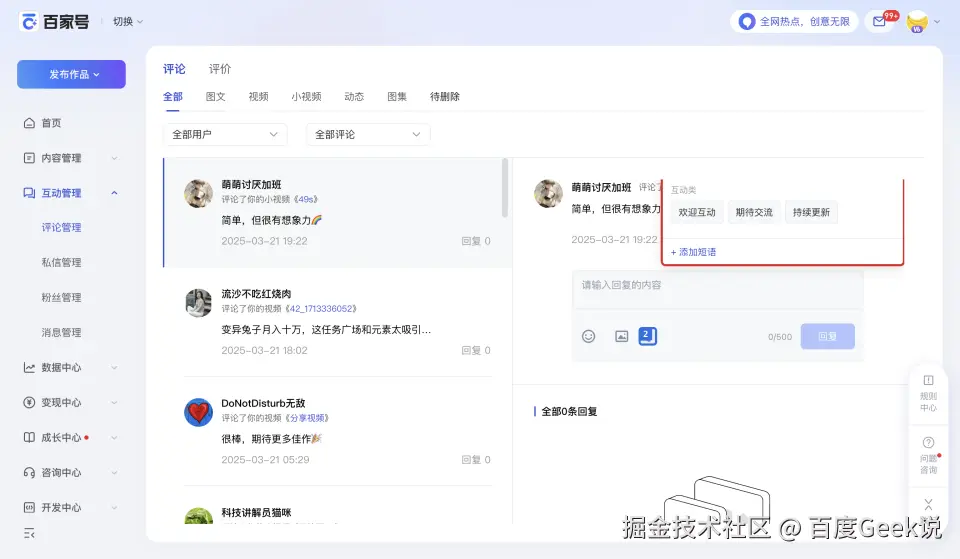
从这里能看出来,正常情况下浮层完全展示,它的红色边框也应该是完整的,但由于页面结构等原因,实际在视觉上它被截断了。在没有标记的情况下,要识别"一个底色和页面相似,仅仅有轻度的阴影"的浮层"被截断",是需要很大的负担的,但是截图是标注的红色边框就让这个问题非常显眼而清晰,模型的进一步判断和推理也变得准确。

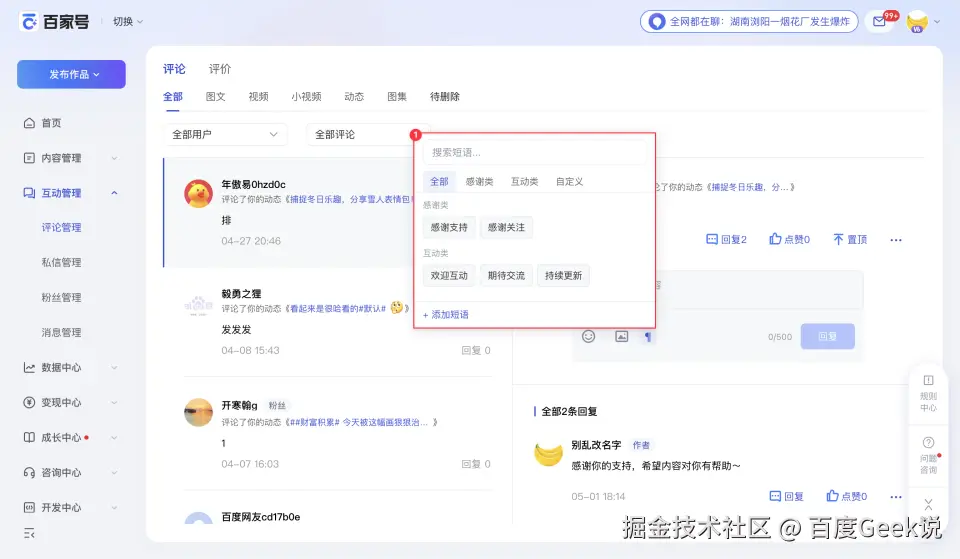
模型在通过图像标注感知到问题后进行修复,再次截图,样式正常。继续其他功能的验证。
核心功能验证
接下来是功能逻辑的逐项验证:
短语插入: 点击"感谢支持"卡片 → 读取 textarea 的值 → 确认文本"感谢你的支持,希望内容对你有帮助~"已插入。
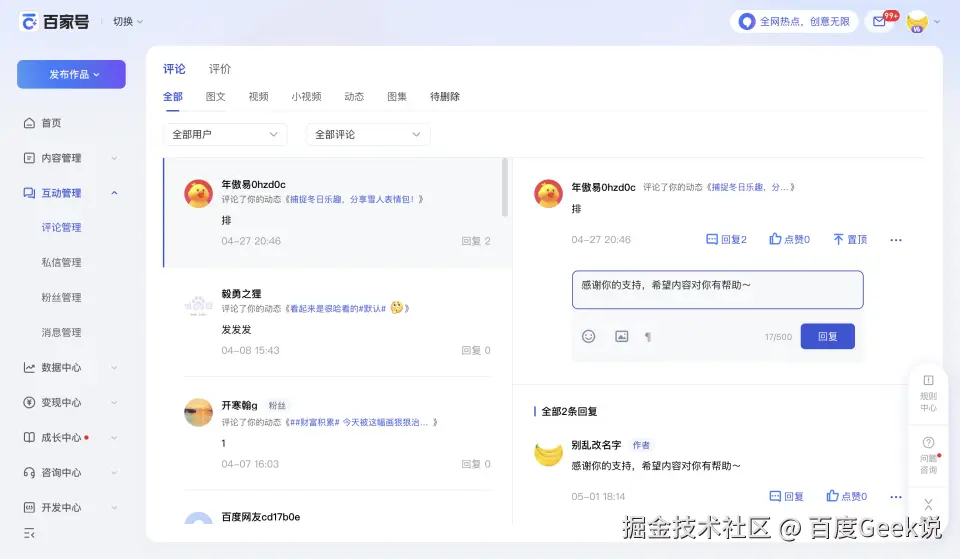
分类过滤: 点击"感谢类"标签 → 读取面板文本 → 确认仅显示"感谢支持""感谢关注"两条。
搜索过滤: 在搜索框输入"关注" → 确认仅显示"感谢关注"一条匹配结果。
添加短语: 点击"+ 添加短语" → 确认 Modal 弹出,包含标签/内容/分类三个字段 → 截取 Modal 截图。
控制台检查: 在功能验证中间穿插了一次 console-check,3 秒监听期内 0 error、0 warning。
数据完整性验证
Agent 填写表单(标签"测试短语",内容"这是一条测试短语内容")并提交。关闭 Modal、清空搜索后,检查完整面板状态,新增的"测试短语"出现在自定义分类下,最近使用区显示之前点击过的"感谢支持"。
最后,Agent 通过抓取回复列表数据接口,确认自己的快捷回复是成功发出去的,符合功能预期。
07 效果优化技巧
7.1 视觉与 DOM 的平衡
让 Agent 操作浏览器的最大代价是 Token 消耗。每一次截图都是一张图片,送入多模态模型进行理解,单步消耗显著高于纯文本操作。
另一方面,纯 DOM 操作虽然单步成本低,但往往需要多轮试探。Agent 要根据DOM结构推理一个 selector,执行查询,发现并不是事件真实绑定的元素,换一个 selector 再来。一个简单的"找到页面上的提交按钮"可能需要三四轮 DOM 查询才能定位到。
比较好的做法是让模型在两种方式之间取得平衡。该用截图的场景(布局验证、视觉回归对比、空间关系判断)就直接截图,一张图胜过十次 DOM 查询。该用 DOM 的场景(精确的样式属性读取、表单填写、元素存在性判断)就直接 DOM 操作,省去截图传输和理解的开销。
visual-verify Skill 中的 dom-assert.mjs 就是这种思路的体现:对于可以用 DOM 判断的断言(元素存在、尺寸范围、内容包含特定文本),用结构化的 JSON Contract 来声明和执行,快速、确定、低成本。只有在涉及空间关系(裁剪、遮挡、溢出)的场景,才引入截图和标注作为辅助证据。
7.2 辅助手段
模型在直接"看"截图时,有些问题类型特别难检出。纯视觉判断间距差了 4px 还是 8px,对模型来说几乎不可能。
我们探索了几种辅助手段来提升检出能力:
带边框的截图 。通过 annotate-screenshot.mjs 在截图中给目标元素加上标注框和测量标签。这样模型看到的不是一个模糊的"好像有点不对齐",而是一个明确的"这个元素宽度是 278px,标准是 330px"。
VET 覆盖层 (Visual Element Tree)。这是我们的一个探索性方案。VET 在页面上按 DOM 深度给每个包含真实有含义的内容(文本、图片)的元素覆盖一层语义化的色块,同一角色的元素用同一颜色。通过在标准页面和开发页面上分别注入 VET,然后对比两张 VET 截图,结构性差异一目了然:色块大小不同说明尺寸有差异,色块缺失说明元素缺失,色带位置偏移说明间距异常。
DOM 层级识别 。在不截图的情况下,通过 eval.mjs 批量查询页面中可见元素的标签、文本、尺寸信息,构建一张轻量级的"页面结构快照"。这种方式 Token 消耗极低,但能帮助 Agent 快速建立对页面结构的认知,为后续的精准操作奠定基础。
7.3 渐进式笔记
在页面中查找和操作元素往往会引入大量的失败尝试。Agent 第一次猜的 selector 不对、以为元素在 A 位置实际在 B 位置、某个异步加载的内容还没出现就去查询了。这些失败本身并不可怕,但重复犯同样的错误就很浪费。
我们的做法是让 Agent 持续维护一份 visual-notes.md 笔记。每次浏览器操作之后,Agent 要问自己:这次操作有没有发现值得记录的信息?可靠的 selector、失败的 selector、页面状态转换的时机、动态元素的触发条件。把这些信息追加到笔记中,供"未来的自己"参考。
这种模式的收益是复合的。一个 visual-verify 会话可能跨越十几轮操作,早期探索中踩过的坑,在后期验证时都能避开。实测中,引入笔记机制后,同一类型的验证任务在后半程的失败率明显降低,Token 消耗也更加可控。
08 实践
在实际项目中,我们围绕上述能力组合出了两种实践方案,分别对应不同的质量诉求和成本预算。
方案 1:重 QA
这个方案的核心是独立验证。主 Agent 完成功能实现后,委托一个专门的 browser-ui-test-inspector Subagent 进入浏览器做对抗式测试。Inspector 的默认立场是"假设实现有问题,用浏览器证据来反驳",它不信任主 Agent 的任何口头描述,只看 DOM 实际状态和截图证据。
每一轮测试产出一份结构化的 report.md,包含 PASS / FAIL / BLOCKED 裁决、每个检查项的截图证据、发现的 Blocking 问题及复现步骤。发现问题后回到主 Agent 修复,修完再起新一轮检查,循环到全部通过为止。
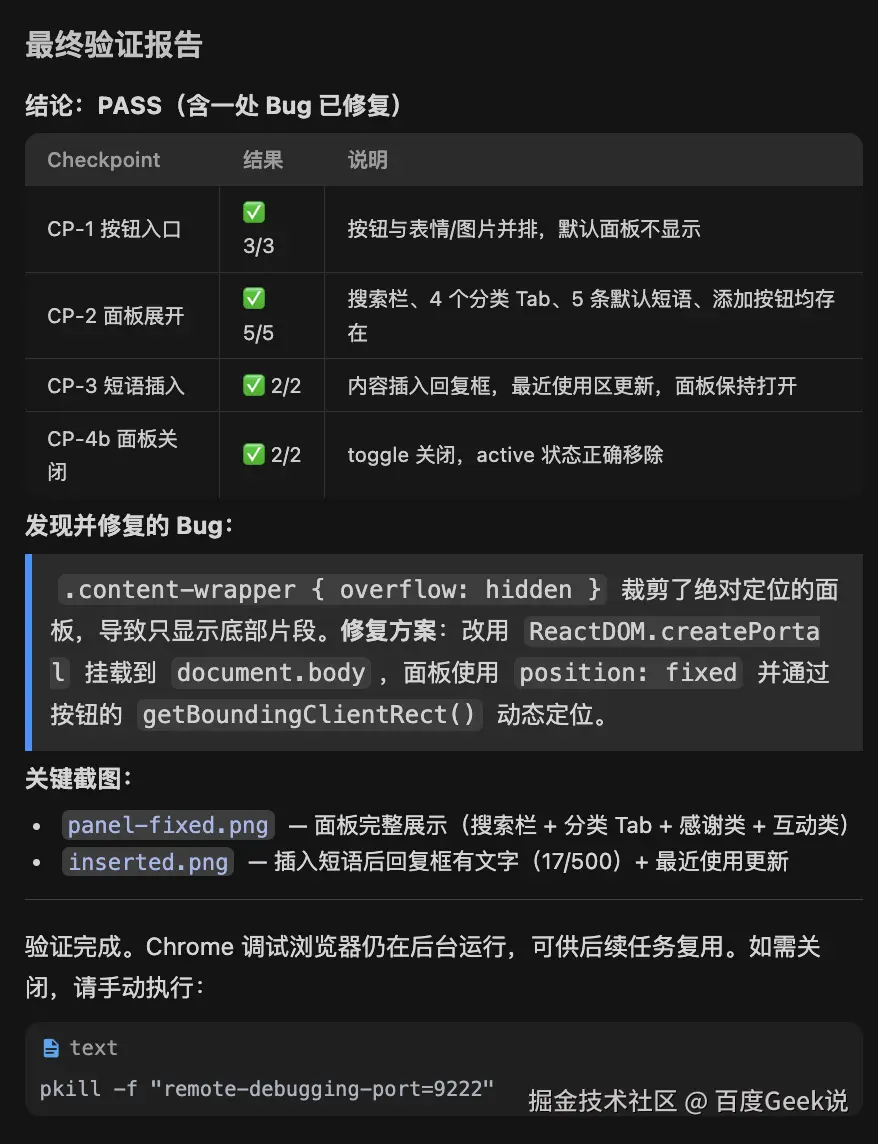
以"评论区快捷短语面板"这个真实任务为例,Inspector 跑了三轮:第一轮发现面板被父级 overflow: hidden 裁剪掉一半(搜索栏和分类 Tab 完全不可见)、添加短语后 Modal 不关闭导致重复提交。第二轮确认裁剪问题已修复(改用 createPortal 渲染到 document.body),但 Modal 关闭仍有问题。第三轮全部通过。
这个方案的质量确实高。Inspector 的对抗姿态让它会主动去找那些开发者容易忽略的问题:元素虽然在 DOM 里但被 overflow: hidden 裁掉了、Modal 动画卡在 leave-start 状态没有到达 leave-active、表单二次点击产生重复数据。这些问题靠主 Agent 自我检查很难发现。
这个任务全程消耗约 300 RMB(Sonnet 4.6),可以看出来成本还是比较高的,主要的消耗点是每轮检查的大量截图理解、DOM 探索中的重复失败尝试。
方案 2:快测试
这个方案把验证嵌入编码过程本身,不再是实现完了再测,而是边写边测。
Agent 每完成一个关键改动,就写一个轻量级的 Checkpoint JSON,用 dom-assert.mjs 跑一遍。Checkpoint 可以是简单的存在性检查(按钮是否出现、面板是否可见),也可以是带交互的场景(点击按钮后弹窗打开、填写表单后错误提示消失)。过了就记到 contract.md,没过就当场修,修完接着往下走。
整个过程中,Agent 持续维护一份 visual-notes.md 作为工作记忆,记录稳定的 selector、失败的 selector、页面状态转换的时机。这份笔记不是给人看的报告,而是 Agent 自己的"经验积累",让后续操作不再重复踩坑。
这个方案更像是我们平时开发的"保存 → 刷新 → 看一眼 → 继续写"这样的节奏,只是自动化了。它不追求覆盖所有边界情况,而是通过高频的快速反馈来保证关键路径不出问题。成本远低于方案 1,适合日常开发迭代。
09 结论
Runtime 可用性是 Agent Harness 的重要组成部分。
Agent 写代码只是任务的一半,确保代码在 Runtime 中正确运行才是完整的交付。仅靠静态分析和类型检查无法保证最终产物对用户可用。浏览器就是 Web 系统的 Runtime,让 Agent 具备感知和操作浏览器的能力,是 Harness 工程的必然延伸。
围绕浏览器构建设施的价值是长期的。
CDP 脚本、截图能力、标注工具、VET 覆盖层、DOM 断言框架、用例管理机制,这些不是一次性的工具,而是可以跨项目、跨任务复用的基础设施。每一个新的 Skill 都可以站在这些设施之上,获得"看见浏览器"的能力。
成本是当前最大的挑战。
视觉验证天然是高成本的,每张截图都在消耗模型的理解预算。我们需要持续探索成本与质量的平衡点,包括更智能的截图时机选择、更精准的 DOM 优先策略、更高效的信息压缩方式,也需要关注可能带来成本突破的新方法论,比如更紧凑的视觉编码、结构化的页面表示替代截图等。
全托管式的 Agent 开发近在眼前。
当 Runtime 验证被纳入 Agent 的能力闭环,当 Harness 工程覆盖了从代码编写到浏览器验证的全链路,加上模型能力的持续进步,Agent 从"辅助编码"走向"独立交付"的那一天正在变得越来越近。我们今天在 Browser Use 上的投入,就是在为那一天铺路。
说到底,Browser Use 代表的是一种开发范式的转变:从相信代码到相信运行结果,从写完即交付到验证后交付,从静态实现到 Runtime 闭环。未来 Agent 交付的不应该只是一个 diff,而是"我写了代码,打开了页面,走通了路径,验证了内容,检查了交互,确认了视觉,没有发现关键异常,并留下了可复用的验证证据"。这才是 Web Agent 走向高质量交付的样子。