本文从硬件原理出发,系统讲解 Linux 磁盘体系的每一个核心概念与操作命令,最终通过 VMware 实战实验贯穿所有知识点。
实验环境说明
本文所有命令演示与实验操作均基于以下环境,读者可参考搭建相同或相近的环境进行复现:
| 项目 | 配置 |
|---|---|
| 虚拟化平台 | VMware Workstation |
| 操作系统 | 麒麟 Linux V10 SP3(Kylin Linux Advanced Server V10 SP3) |
| 内核架构 | x86_64 |
| 物理内存 | 4 GB |
| 虚拟 CPU | 2 核 |
| 系统磁盘 | 50 GB 虚拟 SCSI 磁盘(/dev/sda,已划分系统分区) |
| 实验磁盘 | 10 GB 虚拟磁盘(/dev/sdb,新增,实验专用,系统盘零改动) |
系统盘初始磁盘布局:
sda(50G)
├─sda1(1G) → /boot
└─sda2(49G) → LVM
├─klas-root(45.1G)→ /
└─klas-swap(3.9G) → [SWAP]实验章节的所有操作均在新增的
sdb上进行,不触碰现有系统盘,可安全复现。
第一章 物理磁盘基础
1.1 磁盘的两种类型
是什么?
- HDD(Hard Disk Drive,机械硬盘):通过机械臂驱动磁头在高速旋转的磁性盘片上读写数据。盘片转速通常 5400~15000 RPM,磁头需要物理移动到目标位置才能读写。
- SSD(Solid State Drive,固态硬盘):没有任何机械部件,通过 NAND 闪存芯片存储数据,用电信号直接寻址任意存储单元,无需物理移动。
为什么要区分?
两者物理结构的差异决定了截然不同的 I/O 特性:机械盘的随机访问延迟高(毫秒级),固态盘几乎无延迟(微秒级)。识别磁盘类型是后续配置 I/O 调度算法(第八章)的前提。
怎么判断? 见本章 1.3 节。
特性对比:
| 特性 | HDD(机械硬盘) | SSD(固态硬盘) |
|---|---|---|
| 存储介质 | 磁性盘片 + 机械磁头 | 闪存芯片 (NAND Flash) |
| 寻道方式 | 机械旋转寻道,毫秒级延迟 | 电子寻址,微秒级,几乎无延迟 |
| 随机 IOPS | 低(100~200) | 极高(数万~数十万) |
| 顺序读写 | 较好 | 更好 |
| 适用场景 | 冷备份、归档、大文件顺序存储 | 高并发业务、服务器数据目录 |
| 推荐 I/O 调度算法 | mq-deadline / deadline |
none / noop |
1.2 Linux 中的磁盘命名规则
是什么? Linux 遵循"一切皆文件"哲学,所有硬件设备包括磁盘,都被内核抽象成文件,放在 /dev/(devices)目录下。这类代表存储设备的文件称为块设备 (Block Device)------"块"指它以固定大小的数据块为单位读写,区别于键盘、串口等以单个字符为单位的"字符设备"。
为什么这样命名? 内核按照识别到硬件的顺序依次分配字母:第一块盘 sda,第二块 sdb,以此类推。分区在盘符后追加数字编号,整盘路径无数字后缀,分区路径有数字后缀。
设备路径对照表:
| 设备名 | 类型 | 含义 |
|---|---|---|
/dev/sda |
整盘 | 第 1 块 SATA/SCSI/SAS/虚拟磁盘 |
/dev/sdb |
整盘 | 第 2 块磁盘 |
/dev/sda1 |
分区 | 第 1 块磁盘的第 1 个分区 |
/dev/sda2 |
分区 | 第 1 块磁盘的第 2 个分区 |
/dev/nvme0n1 |
整盘 | 第 1 块 NVMe 固态盘(命名稍有不同) |
/dev/nvme0n1p1 |
分区 | 第 1 块 NVMe 固态盘的第 1 个分区(用 p 分隔) |
规律:字母递增代表第几块盘(a→b→c...),末尾数字代表第几个分区(1→2→3...)。
1.3 查看磁盘类型:判断 SSD 还是 HDD
命令一:lsblk -d -o name,rota
bash
[root@localhost ~]# lsblk -d -o name,rota
NAME ROTA
sda 1
sr0 1参数解释:
-d(nodeps):只列出整盘,不递归显示其分区子项。-o name,rota(output):自定义输出列,这里只要设备名和旋转标志。ROTA=1:有旋转结构 → 机械盘 (HDD)。ROTA=0:无旋转结构 → 固态盘 (SSD)。
命令二:读内核参数文件
bash
# 以 sda 为例,输出 1 = HDD,输出 0 = SSD
[root@localhost ~]# cat /sys/block/sda/queue/rotational
1第二章 核心概念:从物理盘到可用目录的完整路径
一块新磁盘从插入到可用,有两条路径:
路径一:基础路径(直接分区挂载)
物理磁盘 (/dev/sdb)
↓ 分区 (fdisk) ← 切割磁盘
分区 (/dev/sdb1)
↓ 格式化 (mkfs.xfs) ← 建立文件系统
文件系统 (XFS / EXT4 / ...)
↓ 挂载 (mount) ← 关联到目录
目录 (/mydata) ← 用户在这里读写数据路径二:LVM 路径(生产环境推荐)
物理磁盘 (/dev/sdb)
↓ 初始化为物理卷 (pvcreate) ← LVM 第一步
物理卷 PV (/dev/sdb)
↓ 加入卷组 (vgcreate) ← LVM 第二步:合并为资源池
卷组 VG (datavg)
↓ 划出逻辑卷 (lvcreate) ← LVM 第三步:按需切割"虚拟磁盘"
逻辑卷 LV (/dev/datavg/lv_data)
↓ 格式化 (mkfs.xfs) ← 与基础路径相同
文件系统 (XFS)
↓ 挂载 (mount) ← 与基础路径相同
目录 (/mydata) ← 用户在这里读写数据两条路径的区别 :LVM 路径在"分区"和"文件系统"之间多了三个步骤(PV→VG→LV),引入了一个灵活的"虚拟磁盘"层。这个中间层的核心价值是:空间用满时可以在线无损扩容,而基础路径一旦空间满了,扩容必须停机迁移数据。
本章先把基础路径的四个核心概念(分区、文件系统、挂载、UUID)讲清楚,LVM 的三个概念(PV、VG、LV)在第七章详细展开。
2.1 概念一:分区 (Partition)
什么是分区?
将一块物理硬盘切割成若干独立区域,每个区域可以独立格式化、独立挂载。就像把一整块地分成若干块宅基地,每块都能盖不同的房子。
为什么要分区?
- 不同用途的数据(系统、数据、备份)物理隔离,互不影响。
- 某个分区写满不影响其他分区。
- 便于管理权限和配额。
分区表类型:
分区表是写在磁盘最开头的一张"地块登记册",记录了这块盘被分成了几块,每块从哪里开始、到哪里结束。MBR 和 GPT 是两种不同格式的登记册标准。
列含义说明:
- 最大支持磁盘:分区表格式能寻址的最大容量上限,超过这个容量则无法正确识别磁盘。
- 最多主分区数:分区表结构中硬编码的分区槽位数量,决定了最多能划出多少个独立分区。
| 类型 | 全称 | 最大支持磁盘 | 最多主分区数 | 说明 |
|---|---|---|---|---|
| MBR | Master Boot Record(主引导记录) | 2TB:因为 MBR 用 32 位整数记录扇区地址,最多可寻址 2³²=42亿 个扇区,每个扇区 512 字节,合计上限恰好约 2TB | 4 个:MBR 结构中只有 4 个分区描述槽位。若要超过 4 个分区,需把其中一个设为"扩展分区",在扩展分区内再划"逻辑分区" | 旧标准,2TB 以下磁盘常用 |
| GPT | GUID Partition Table(全局唯一标识分区表) | 18EB(约 1800 万 TB):GPT 用 64 位整数记录扇区地址,理论上限极高,现代服务器不受此限制 | 128 个:GPT 在磁盘头部预留了 128 个分区描述符槽位,且全部为"主分区",无需扩展分区概念 | 新标准,现代服务器和 2TB 以上磁盘必须使用 |
2.2 概念二:文件系统 (File System)
什么是文件系统?
分区只是划定了地盘,文件系统才是在地盘上铺设的"道路网络",规定了文件如何命名、如何组织、如何存储。没有文件系统的分区无法存储任何文件,格式化操作就是在创建文件系统。
常见文件系统对比:
| 文件系统 | 特点 | 适用场景 |
|---|---|---|
| XFS | 高性能,尤其擅长大文件和高并发元数据操作;支持在线扩容;不支持在线缩小 | 服务器数据目录首选,高 I/O 生产环境主流标准 |
| EXT4 | 成熟稳定,兼容性好,支持缩小,日志式(崩溃可自动恢复) | Linux 系统分区(/、/boot 等)、普通数据存储 |
| EXT3 | EXT4 的前身,性能较低 | 老旧系统兼容场景 |
| SWAP | 不存储普通文件,专用于内存交换的特殊格式 | 虚拟内存(交换空间) |
2.3 概念三:挂载 (Mount) 与挂载点
什么是挂载?
Linux 没有 Windows 的 C 盘、D 盘概念。所有存储设备必须"挂载"到文件系统树中的某个目录 ,才能被访问。这个目录叫做挂载点 (Mount Point)。
/ ← 根目录(必须存在)
├── boot ← /dev/sda1 挂在这里(引导分区)
├── dmdata ← /dev/sdb1 挂在这里(数据目录)
├── home
└── tmp类比理解:
- 磁盘分区 = 一个仓库
- 挂载点(目录)= 仓库的入口门
mount命令 = 给仓库开一扇门umount命令 = 把门关上- 没有挂载 = 仓库存在,但没有门,进不去
挂载点的要求:
-
必须是一个已存在 的目录(不存在就先
mkdir创建)。 -
通常选用空目录作为挂载点,原因如下:
挂载本质上是"把磁盘的根覆盖在目录上"。如果挂载点目录里原本就有文件,挂载后这些文件不会被删除,但会被新磁盘的内容"挡住",暂时看不见也摸不着。卸载后,原来的文件会重新出现。
举个例子:
# 假设 /mnt 里已有文件 old_file.txt ls /mnt old_file.txt # 把 /dev/sdb1 挂载到 /mnt mount /dev/sdb1 /mnt # 现在 /mnt 只显示 /dev/sdb1 里的内容,old_file.txt 不见了 ls /mnt (显示 sdb1 里的文件,old_file.txt 不显示) # 卸载后,old_file.txt 重新出现 umount /mnt ls /mnt old_file.txt因此实践中总是选用空目录,避免产生混淆。
2.4 概念四:UUID(设备唯一标识符)
为什么需要 UUID?
设备路径(如 /dev/sdb)在以下情况会发生漂移(变化):
- 服务器重启,内核识别顺序改变。
- 插拔硬盘,盘符重新分配。
- 增加新磁盘后,原来的
sdb变成sdc。
UUID 是格式化时写入分区元数据的全球唯一标识符,无论盘符怎么变,UUID 永远不变。
bash
# 查看分区 UUID
[root@localhost ~]# blkid /dev/sda1
/dev/sda1: UUID="abc12345-1234-5678-abcd-ef0123456789" TYPE="xfs"2.5 概念五:LVM(逻辑卷管理器)--- 了解即可,详见第七章
是什么?
LVM(Logical Volume Manager,逻辑卷管理器)是在分区和文件系统之间插入的一个抽象层。它把一块或多块磁盘的空间统一收进一个"资源池",然后按需从这个池子里划出"虚拟磁盘"(称为逻辑卷 LV),逻辑卷对文件系统来说和普通分区完全一样,可以照常格式化和挂载。
用一句话理解 LVM 的位置:
普通路径: 物理磁盘 → [分区] → 文件系统 → 目录
LVM 路径: 物理磁盘 → [分区 → PV → VG → LV] → 文件系统 → 目录
↑↑↑
这三步就是 LVM 干的事为什么要用 LVM?
普通分区一旦创建、格式化后,大小就固定了。空间用满时,需要停机、重新分区、迁移数据,风险极高。而 LVM 的逻辑卷可以在线(不停机)直接扩大,数据完全不受影响。这是生产环境优先选择 LVM 的核心原因。
实际环境示例(以本文实验环境为例):
本文环境中的 klas-root 和 klas-swap 就是两个逻辑卷,它们是从 sda2 这块分区建出来的 LVM 卷:
sda2(普通分区)
└─ klas(卷组 VG)
├─ klas-root(逻辑卷 LV)→ 格式化为 XFS → 挂载到 /
└─ klas-swap(逻辑卷 LV)→ 格式化为 SWAP → 用作交换空间此处无需深入 PV/VG/LV 的细节,只需知道"LVM 是分区和文件系统之间的一层"即可。第七章会从零开始完整讲解 LVM 的三层架构和所有操作命令。
第三章 查看磁盘状态的常用命令
3.1 lsblk:查看磁盘树状结构
bash
[root@localhost ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 50G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 49G 0 part
├─klas-root 253:0 0 45.1G 0 lvm /
└─klas-swap 253:1 0 3.9G 0 lvm [SWAP]
sr0 11:0 1 1024M 0 rom各列含义:
| 列名 | 含义 | 示例解读 |
|---|---|---|
| NAME | 设备名 | sda 是整盘,sda1 是分区,klas-root 是 LVM 逻辑卷(见 2.5 节) |
| MAJ:MIN | 主:次设备号,内核用于识别驱动程序 | 8:0 表示第一块 SCSI/SATA 盘 |
| RM | 是否可移动设备 | 0 固定盘,1 可移动(U盘、光驱) |
| SIZE | 容量大小 | 50G、1G、3.9G |
| RO | 是否只读 | 0 可读写,1 只读(如光盘) |
| TYPE | 设备类型 | disk 整块磁盘,part 普通分区,lvm LVM 逻辑卷(虚拟分区),rom 光驱 |
| MOUNTPOINT | 挂载点 | /boot、/、[SWAP],空白表示未挂载 |
环境解读示例 :本文实验环境中,
sda2(49GB)的 TYPE 是part(普通分区),但它被用作 LVM 的原料,从中建出了klas-root和klas-swap两个逻辑卷(TYPE=lvm)。这两个逻辑卷对操作系统来说和普通分区一样,可以直接格式化和挂载。LVM 的详细机制见第七章。
3.2 df -h:查看已挂载分区的空间使用
bash
[root@localhost ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
devtmpfs 3.8G 0 3.8G 0% /dev
tmpfs 3.9G 0 3.9G 0% /dev/shm
/dev/mapper/klas-root 45G 12G 33G 27% /
/dev/sda1 1014M 230M 785M 23% /boot各列含义:
| 列名 | 含义 |
|---|---|
| 文件系统 | 对应的块设备路径 |
| 容量 | 分区总大小 |
| 已用 | 已占用空间 |
| 可用 | 剩余可写入空间 |
| 已用% | 使用率,数据库场景超过 80% 需立即关注 |
| 挂载点 | 该分区对应的目录 |
df -T可额外显示文件系统类型列(TYPE),用于确认是否为 XFS。
3.3 fdisk -l:列出磁盘分区表详情
bash
[root@localhost ~]# fdisk -l /dev/sda
Disk /dev/sda: 50 GiB, 53687091200 bytes, 104857600 sectors
# 磁盘总容量:50GB,共 104857600 个扇区
Disk model: VMware Virtual S
# 磁盘型号:VMware 虚拟磁盘
Units: sectors of 1 * 512 = 512 bytes
# 每个扇区 512 字节
Device Boot Start End Sectors Size Id Type
/dev/sda1 * 2048 2099199 2097152 1G 83 Linux
# sda1: 引导分区(*表示可引导),大小1GB,类型 Linux
/dev/sda2 2099200 104857599 102758400 49G 8e Linux LVM
# sda2: LVM 类型分区(Id=8e),大小 49GB3.4 free -m:查看内存与 SWAP 使用情况
bash
[root@localhost ~]# free -m
total used free shared buff/cache available
Mem: 7821 1203 5012 108 1605 6262
Swap: 3999 0 3999参数 -m :以 MB 为单位显示(-g 以 GB,-h 自动换算)。
各列含义:
| 行/列 | 含义 |
|---|---|
| Mem / total | 物理内存总量 |
| Mem / used | 已使用内存(包含缓存) |
| Mem / available | 真正可用内存(这个才是实际剩余) |
| Swap / total | SWAP 总大小 |
| Swap / used | 已使用的 SWAP。此值大于 0 说明内存吃紧 |
第四章 磁盘分区与格式化操作
4.1 fdisk 分区(MBR 磁盘,2TB 以内)
是什么? fdisk 是 Linux 内置的交互式磁盘分区编辑工具。进入 fdisk 后是一个命令菜单界面,所有操作都是先预览、最后用 w 一次性写入,不会实时改变磁盘。
为什么用 fdisk? 新磁盘插入后是一块"空地",必须先用分区工具在磁盘上建立分区表和分区,才能进行后续格式化和挂载。fdisk 适合 2TB 以内的 MBR 磁盘,是最常用的分区工具。
怎么做?
bash
# 对 /dev/sdb 进行分区(整盘操作,不加数字)
[root@localhost ~]# fdisk /dev/sdb
# 进入交互模式后,常用命令:
# m 显示帮助菜单
# p Print,打印当前分区表(查看现有分区)
# n New,新建一个分区
# d Delete,删除一个分区
# w Write,将改动写入磁盘并退出(保存生效)
# q Quit,不保存退出
Command (m for help): n # 新建
Partition type:
p primary (主分区,最多4个)
e extended (扩展分区,解决4个主分区限制)
Select: p
Partition number (1-4): 1 # 分区编号,填 1
First sector: (回车,使用默认起始扇区)
Last sector: +10G # 结束位置,+10G 表示划 10GB
Command (m for help): w # 保存并退出注意 :
w之前所有操作都是预览,w之后才真正写入,请谨慎操作。
4.2 mkfs 格式化(创建文件系统)
是什么? mkfs(make filesystem)是在分区上创建文件系统的命令。分区建好后只是划定了边界,内部是空白未组织的空间,操作系统无法使用。格式化就是在这片空白上建立文件系统的数据结构(目录树、inode 表等),让系统能够管理文件。
为什么必须格式化才能挂载? 没有文件系统,内核不知道如何在磁盘上定位和组织文件。尝试挂载未格式化的分区会直接报错。
⚠️ 格式化会清空分区内所有数据,执行前务必核对路径,确认目标分区正确。
bash
# 格式化为 XFS(达梦数据库规范要求)
[root@localhost ~]# mkfs.xfs /dev/sdb1
# mkfs = make filesystem
# .xfs = 文件系统类型(也可以是 .ext4、.ext3)
# /dev/sdb1 = 目标分区路径(注意:是分区,不是整盘 /dev/sdb)
# 等价写法:
[root@localhost ~]# mkfs -t xfs /dev/sdb1第五章 挂载操作详解
第二章介绍了挂载的概念。本章聚焦具体操作命令。核心区别:临时挂载 (重启失效)用
mount命令;永久挂载 (重启生效)将规则写入/etc/fstab文件。
5.1 临时挂载(重启失效)
是什么? 直接在终端运行 mount 命令,将分区关联到目录。只修改了内核的内存状态,不写入任何配置文件,所以重启后失效。
为什么用? 临时测试、应急读取数据、挂载 U 盘等一次性场景,或在写入 fstab 前先验证挂载是否正常。
怎么做?
bash
# 第一步:创建挂载点目录(若不存在)
[root@localhost ~]# mkdir -p /dmdata
# mkdir:创建目录
# -p:递归创建,若父目录不存在一并创建,已存在也不报错
# 第二步:挂载
[root@localhost ~]# mount /dev/sdb1 /dmdata
# mount:挂载命令
# /dev/sdb1:要挂载的分区(块设备)
# /dmdata:挂载点(目录)
# 验证是否挂载成功
[root@localhost ~]# df -h | grep dmdata
/dev/sdb1 10G 33M 10G 1% /dmdata
# 卸载(先确保没有进程在使用该目录)
[root@localhost ~]# umount /dmdata
# 若提示 device is busy,用下面命令查看谁在占用
[root@localhost ~]# lsof /dmdata5.2 永久挂载(修改 /etc/fstab)
/etc/fstab 是 Linux 开机自动挂载的配置文件,每行代表一条挂载规则。
文件格式(共 6 列):
<设备> <挂载点> <文件系统> <挂载选项> <dump> <pass>
UUID=xxxx... /dmdata xfs defaults 0 0各列详解:
| 列 | 名称 | 含义 |
|---|---|---|
| 第1列 | 设备标识 | 支持三种格式:UUID=...(推荐)、/dev/sdb1(不推荐)、LABEL=... |
| 第2列 | 挂载点 | 目标目录,必须已存在 |
| 第3列 | 文件系统类型 | xfs、ext4、swap 等 |
| 第4列 | 挂载选项 | defaults 包含了 rw(读写)、auto(开机自动挂载)等常用选项 |
| 第5列 | dump | 0 表示不参与 dump 备份工具扫描,生产环境一般填 0 |
| 第6列 | pass(fsck顺序) | 0 不自检,1 最先检查(根分区用),2 其次检查。XFS 填 0 即可 |
操作步骤:
bash
# 第一步:获取分区 UUID
[root@localhost ~]# blkid /dev/sdb1
/dev/sdb1: UUID="a1b2c3d4-1234-5678-abcd-ef0123456789" TYPE="xfs"
# 第二步:编辑 fstab
[root@localhost ~]# vi /etc/fstab
# 在文件末尾追加以下内容:
UUID=a1b2c3d4-1234-5678-abcd-ef0123456789 /dmdata xfs defaults 0 0
# 第三步:验证配置是否正确(不重启的情况下测试)
[root@localhost ~]# mount -a
# mount -a:读取 /etc/fstab 并挂载其中所有未挂载的条目
# 如果没有报错,说明配置正确⚠️ fstab 写错会导致系统无法启动! 每次修改后必须执行
mount -a验证,确认无报错再重启。
第六章 SWAP 交换空间
6.1 什么是 SWAP?
SWAP(交换空间)是 Linux 在物理内存不足时使用的磁盘区域,作为内存的"溢出区",防止系统因内存耗尽(OOM,Out Of Memory)而崩溃杀死进程。
工作原理:
物理内存 (RAM)
↕ 当 RAM 不足时,内核将"不活跃的内存页"换出到 SWAP
SWAP 空间(磁盘)swappiness 参数(决定内核多积极使用 SWAP):
- 范围:0 ~ 100,默认通常为 60。
- 值越高:内核越积极将数据换出到 SWAP(对数据库有害,频繁磁盘 IO)。
- 值越低:内核尽量用物理内存,SWAP 作为最后手段。
- 达梦/Oracle 等数据库推荐设置为 10。
bash
# 查看当前值
[root@localhost ~]# cat /proc/sys/vm/swappiness
60
# 临时修改
[root@localhost ~]# sysctl vm.swappiness=10
# 永久修改(写入配置文件)
[root@localhost ~]# echo "vm.swappiness = 10" >> /etc/sysctl.conf
[root@localhost ~]# sysctl -p # 使配置生效6.2 SWAP 的两种形式
是什么? SWAP 空间可以用两种方式提供:独立的 SWAP 分区,或者现有文件系统中的一个普通文件。两者对操作系统的功能完全等价。
为什么有两种形式? SWAP 分区需要提前规划磁盘空间,灵活性差;SWAP 文件可以在任何时候、在现有磁盘剩余空间里临时创建,更灵活。
| 形式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| SWAP 分区 | 直接操作裸设备,I/O 路径短,性能略好 | 必须提前规划,事后扩容需停服 | 系统安装时提前规划好的情况 |
| SWAP 文件 | 随时创建/删除/扩大,无需重新分区 | 多一层文件系统 I/O 开销,性能略低(现代系统差距可忽略) | 系统运行中发现 SWAP 不足,临时扩充 |
怎么做 SWAP 分区(供参考):
bash
# 前提:已用 fdisk 在 /dev/sdb 上建了分区 /dev/sdb2
# 在 fdisk 内用 t 命令将分区类型设为 82(Linux swap)
# 格式化为 SWAP
[root@localhost ~]# mkswap /dev/sdb2
# 激活
[root@localhost ~]# swapon /dev/sdb2
# 验证
[root@localhost ~]# free -m
[root@localhost ~]# swapon --show
# 永久生效
[root@localhost ~]# echo "/dev/sdb2 swap swap defaults 0 0" >> /etc/fstab6.3 查看 SWAP 状态
bash
# 方法一:free -m(查看内存+SWAP 概况)
[root@localhost ~]# free -m
total used free shared buff/cache available
Mem: 7821 1203 5012 108 1605 6262
Swap: 3999 0 3999
# Swap used=0 表示当前未使用 SWAP,内存充裕
# 方法二:swapon --show(查看已激活的 SWAP 条目)
[root@localhost ~]# swapon --show
NAME TYPE SIZE USED PRIO
/dev/klas/klas-swap partition 4G 0B -2
# NAME:SWAP 来源(分区或文件路径)
# TYPE:partition(分区)或 file(文件)
# SIZE:总大小
# USED:当前占用
# PRIO:优先级,数字越大越优先使用6.4 创建 SWAP 文件(推荐方式,灵活)
bash
# 第一步:创建一个 2GB 的空文件
[root@localhost ~]# dd if=/dev/zero of=/swapfile bs=1M count=2048
# dd:磁盘拷贝工具(disk dump)
# if=/dev/zero:输入源为 /dev/zero(无限输出零字节的虚拟设备)
# of=/swapfile:输出文件路径(即要创建的 SWAP 文件)
# bs=1M:每次读写的块大小为 1MB
# count=2048:一共读写 2048 个块 = 2048MB = 2GB
# 第二步:设置权限(安全要求:只有 root 能读写)
[root@localhost ~]# chmod 600 /swapfile
# 600 = rw------- 只有所有者可读写,其他人无任何权限
# 第三步:将文件格式化为 SWAP 格式
[root@localhost ~]# mkswap /swapfile
# mkswap:创建交换空间(注意:不是 mkfs.swap)
# 第四步:激活 SWAP 文件
[root@localhost ~]# swapon /swapfile
# swapon:启用指定的交换空间
# 第五步:验证
[root@localhost ~]# free -m
Swap: 5999 0 5999 # SWAP 总量增加了 2GB
# 第六步:永久生效(写入 fstab)
[root@localhost ~]# echo "/swapfile swap swap defaults 0 0" >> /etc/fstab
# 【可选】临时关闭 SWAP 文件(若要删除此文件必须先执行)
[root@localhost ~]# swapoff /swapfile6.5 在 LVM 逻辑卷上扩展 SWAP(高级,需先阅读第七章)
前置知识 :LVM(逻辑卷管理器)是第七章的核心内容。简单理解:LVM 是在普通分区之上再套一层"虚拟磁盘",可以灵活调整大小。本文实验环境中的
klas-swap就是一个建立在 LVM 之上的 SWAP,路径/dev/klas/klas-swap中的klas是卷组名,klas-swap是逻辑卷名。如果还不了解 LVM,建议先阅读第七章,再回来看本节。
应用场景 :当 SWAP 是以 LVM 逻辑卷形式存在时(如本文环境中的 klas-swap),可以直接扩展逻辑卷然后重新格式化,比用文件方式更规范。
bash
# 第一步:先关闭 SWAP(运行中的 SWAP 不可直接操作)
[root@localhost ~]# swapoff /dev/klas/klas-swap
# 第二步:扩展逻辑卷大小(LVM 命令,详见第七章 7.5 节)
[root@localhost ~]# lvextend -L +5G /dev/klas/klas-swap
# -L +5G:在原有大小基础上增加 5GB
# 第三步:重新将逻辑卷格式化为 SWAP 格式
[root@localhost ~]# mkswap /dev/klas/klas-swap
# 第四步:重新激活
[root@localhost ~]# swapon /dev/klas/klas-swap
# 第五步:验证(Swap total 应该增加了 5GB)
[root@localhost ~]# free -m第七章 LVM 逻辑卷管理:在线扩容的核心技术
LVM(Logical Volume Manager,逻辑卷管理器) 是 Linux 中最重要的高级磁盘管理技术之一。它在物理磁盘和文件系统之间增加了一个虚拟抽象层,使磁盘空间的分配和扩容变得极为灵活------其最核心的价值是:在不停机、不迁移数据的情况下动态扩容磁盘空间。
7.1 为什么必须用 LVM?
| 场景 | 普通分区 | LVM 逻辑卷 |
|---|---|---|
| 空间用满了想扩容 | 需要停机,重新分区,迁移数据,风险极高 | 在线扩容,不停机,数据不丢失 |
| 多块磁盘合并使用 | 无法合并 | 可以将多块磁盘合并成一个大池子 |
| 创建快照备份 | 不支持 | 支持 LVM 快照,极速备份 |
7.2 LVM 三层架构
物理层: [/dev/sdb] [/dev/sdc] ← 物理磁盘或分区
↓ pvcreate
PV 层: [PV: /dev/sdb] [PV: /dev/sdc] ← 物理卷 (Physical Volume)
↓ vgcreate
VG 层: [ VG: datavg (合并的大池子) ] ← 卷组 (Volume Group)
↓ lvcreate
LV 层: [LV: lv_data 50G] [LV: lv_arch 30G] ← 逻辑卷 (Logical Volume)
↓ mkfs + mount
目录层: /dmdata /dmarch ← 用户看到的目录| 概念 | 全称 | 类比 | 说明 |
|---|---|---|---|
| PV | Physical Volume,物理卷 | 一块砖 | 物理磁盘/分区经过 pvcreate 初始化后成为 PV |
| VG | Volume Group,卷组 | 砖堆/资源池 | 一个或多个 PV 合并成 VG,是空间的总池子 |
| LV | Logical Volume,逻辑卷 | 从砖堆建造的房间 | 从 VG 中划出的虚拟磁盘,格式化后可挂载 |
7.3 LVM 创建完整流程
bash
# ============ 第一步:初始化物理卷 (PV) ============
[root@localhost ~]# pvcreate /dev/sdb
# pvcreate:将磁盘/分区初始化为 LVM 物理卷
# /dev/sdb:可以是整盘,也可以是分区(如 /dev/sdb1)
# 注意:整盘做 PV 更方便,不需要提前分区
Physical volume "/dev/sdb" successfully created.
# ============ 第二步:创建卷组 (VG) ============
[root@localhost ~]# vgcreate workvg /dev/sdb
# vgcreate:创建卷组
# workvg:卷组名称(自定义,建议见名知意)
# /dev/sdb:将该 PV 加入此卷组(可以同时写多个 PV)
Volume group "workvg" successfully created
# ============ 第三步:创建逻辑卷 (LV) ============
[root@localhost ~]# lvcreate -L 5G -n lv_dmdata workvg
# lvcreate:创建逻辑卷
# -L 5G:指定大小为 5GB(-L 指定绝对大小,-l 指定 PE 数量或百分比)
# -n lv_dmdata:逻辑卷名称(自定义)
# workvg:从哪个卷组里划空间
Logical volume "lv_dmdata" created.
# ============ 第四步:格式化逻辑卷 ============
[root@localhost ~]# mkfs.xfs /dev/workvg/lv_dmdata
# 逻辑卷路径格式:/dev/<卷组名>/<逻辑卷名>
# 也等价于:/dev/mapper/workvg-lv_dmdata
# ============ 第五步:挂载 ============
[root@localhost ~]# mkdir -p /dmdata
[root@localhost ~]# mount /dev/workvg/lv_dmdata /dmdata
# ============ 验证 ============
[root@localhost ~]# df -h | grep dmdata
/dev/mapper/workvg-lv_dmdata 5.0G 33M 5.0G 1% /dmdata7.4 查看 LVM 状态的命令
bash
# 查看所有物理卷 (PV)
[root@localhost ~]# pvs
PV VG Fmt Attr PSize PFree
/dev/sda2 klas lvm2 a-- 49.00g 0
/dev/sdb workvg lvm2 a-- 10.00g 5.00g
# PSize:该PV总容量;PFree:该PV剩余未分配空间
# 查看所有卷组 (VG)
[root@localhost ~]# vgs
VG #PV #LV #SN Attr VSize VFree
klas 1 2 0 wz--n- 49.00g 0
workvg 1 1 0 wz--n- 10.00g 5.00g
# VFree:卷组中还能划出多少空间给新的 LV
# 查看所有逻辑卷 (LV)
[root@localhost ~]# lvs
LV VG Attr LSize
klas-root klas -wi-ao---- 45.10g
klas-swap klas -wi-ao---- 3.90g
lv_dmdata workvg -wi-ao---- 5.00g
# LSize:逻辑卷大小(用户可见的"磁盘"大小)7.5 在线扩容(最核心操作,数据零损失)
场景:/dmdata 空间不足,需要扩容 3GB
bash
# 第一步:确认卷组还有剩余空间
[root@localhost ~]# vgs workvg
VG VFree
workvg 5.00g # 还剩 5GB 可用,够用
# 第二步:扩展逻辑卷
[root@localhost ~]# lvextend -L +3G /dev/workvg/lv_dmdata
# lvextend:扩展逻辑卷
# -L +3G:在现有基础上增加 3GB(注意:+号表示增加量,不带+号表示最终大小)
# 等价写法:-L +3G 也可以写成 -l +768(768个PE,每PE 4MB)
# 第三步:同步文件系统(关键步骤!否则目录看不到新空间)
[root@localhost ~]# xfs_growfs /dmdata
# xfs_growfs:XFS 文件系统在线扩展工具(参数是挂载点,不是设备路径)
# EXT4 文件系统对应命令:resize2fs /dev/workvg/lv_dmdata
# 验证
[root@localhost ~]# df -h | grep dmdata
/dev/mapper/workvg-lv_dmdata 8.0G 33M 8.0G 1% /dmdata
# 容量从 5G 变成 8G,数据完好无损7.6 向卷组添加新磁盘(VG 扩容)
是什么? vgextend 命令将新的物理卷(PV)追加到已有卷组(VG)中,相当于给资源池注入新的"原材料"。
为什么需要? 当 LV 想继续扩容但 VG 的 VFree(剩余空间)已为 0 时,无法直接扩 LV,必须先通过 vgextend 给 VG 添加新磁盘,才能继续切割出新的 LV 空间。这是两层操作:先扩 VG,再扩 LV。
怎么做?
bash
# 前提:已在 VMware 中添加了新磁盘,识别为 /dev/sdc
# 第一步:初始化新磁盘为 PV
[root@localhost ~]# pvcreate /dev/sdc
# 第二步:将新 PV 追加到现有卷组(VG 容量立即增大)
[root@localhost ~]# vgextend workvg /dev/sdc
# vgextend:extend volume group
# 第三步:验证(VFree 应该增加了新盘的容量)
[root@localhost ~]# vgs workvg
# 后续:可继续用 lvextend 扩展具体逻辑卷(见 7.5 节)第八章 磁盘 I/O 调度算法
8.1 I/O 调度算法是什么?为什么需要它?
是什么? I/O 调度算法是 Linux 内核中的一个组件,负责对应用程序发出的磁盘读写请求进行排队、合并和重新排序,然后再交给磁盘驱动执行。
为什么需要? 应用程序并发产生的磁盘请求是无序的。如果直接按到达顺序执行,机械盘的磁头需要在磁盘上来回跳动(类似电梯在每层楼随机停靠),效率极低。调度算法把"邻近位置的请求"合并和排序,让磁头尽量单向移动,大幅提升吞吐量。
怎么理解?
应用程序请求 → [I/O 调度队列(排序/合并)] → 磁盘驱动 → 物理磁盘
↑
调度算法在这里优化执行顺序8.2 常见调度算法对比
| 算法 | 全称 | 原理 | 适用场景 |
|---|---|---|---|
| CFQ | Completely Fair Queuing | 给每个进程分配均等的 I/O 带宽,公平但低效 | 桌面系统(默认)不适合数据库 |
| Deadline | Deadline Scheduling | 每个请求有截止时间,超时必须处理,避免饿死 | 机械盘数据库首选,延迟可控 |
| mq-deadline | Multi-Queue Deadline | Deadline 的多队列版本,适配多核 CPU | 新内核机械盘推荐 |
| NOOP / none | No Operation | 先来先服务,不做额外排序 | 固态盘(SSD/NVMe)首选,SSD 无需排序 |
| BFQ | Budget Fair Queuing | 按 I/O 预算调度,交互友好 | 桌面和低延迟场景 |
关键原则:
- SSD/NVMe:用
none(无调度),因为 SSD 任意地址访问速度一样快,排序反而浪费 CPU。 - HDD 机械盘:用
mq-deadline,因为机械盘寻道昂贵,需要调度算法合并相邻请求,减少磁头移动。
8.3 查看与修改调度算法
查看当前算法:
bash
# 查看 sda 盘的调度算法,中括号 [] 内的是当前生效的
[root@localhost ~]# cat /sys/block/sda/queue/scheduler
[mq-deadline] kyber bfq none
# 当前使用 mq-deadline,其他可用算法还有 kyber、bfq、none临时修改(立即生效,重启后失效):
bash
[root@localhost ~]# echo mq-deadline > /sys/block/sda/queue/scheduler
# echo:输出字符串
# >:重定向,将输出写入文件(覆盖写)
# /sys/block/sda/queue/scheduler:内核暴露的调度接口文件,写入即生效
# 验证
[root@localhost ~]# cat /sys/block/sda/queue/scheduler
[mq-deadline] kyber bfq none永久修改(重启后依然生效):
方法一:内核启动参数(GRUB)
bash
# 编辑 /etc/default/grub,在 GRUB_CMDLINE_LINUX 中添加
# elevator=deadline(老内核)或对应参数
[root@localhost ~]# vi /etc/default/grub
# 找到 GRUB_CMDLINE_LINUX 这行,在引号内末尾添加:
# elevator=mq-deadline
# 重新生成 GRUB 配置
[root@localhost ~]# grub2-mkconfig -o /boot/grub2/grub.cfg方法二:udev 规则(推荐,更精准)
是什么? udev 是 Linux 的设备管理守护进程。每当内核检测到硬件变化(插入新盘、系统启动等),udev 会读取规则文件并自动执行对应操作。
为什么推荐 udev 而不是 GRUB 方法? GRUB 方法给所有磁盘 统一设置同一种算法,而 udev 可以根据每块磁盘的旋转属性(ROTA)自动判断并分别设置------机械盘用 deadline,SSD 用 none,更精准灵活。
怎么做?
bash
# 创建 udev 规则文件(60 代表执行优先级顺序)
[root@localhost ~]# cat > /etc/udev/rules.d/60-scheduler.rules << 'EOF'
# 匹配机械盘(rotational=1),设置为 mq-deadline
ACTION=="add|change", KERNEL=="sd[a-z]", ATTR{queue/rotational}=="1", ATTR{queue/scheduler}="mq-deadline"
# 匹配 SSD(rotational=0),设置为 none
ACTION=="add|change", KERNEL=="sd[a-z]", ATTR{queue/rotational}=="0", ATTR{queue/scheduler}="none"
EOF
# 重新加载 udev 规则(无需重启,立即生效)
[root@localhost ~]# udevadm control --reload-rules
# 触发一次设备事件,让规则立刻作用于现有磁盘
[root@localhost ~]# udevadm trigger验证是否重启后依然生效:
bash
# 重启后执行
[root@localhost ~]# cat /sys/block/sda/queue/scheduler第九章 综合实战:Linux 磁盘管理全流程演练
本章通过一个连贯的端到端实验,将前八章的所有知识点串联起来实际操作一遍:分区、格式化、挂载、LVM 构建、在线扩容、SWAP 补充、I/O 调度验证。所有操作均在新增的实验盘 /dev/sdb 上完成,不涉及任何系统盘(sda)操作。
安全性说明 :本实验所有写操作仅针对新增虚拟磁盘
sdb。sdb上不存在任何已有数据,格式化/分区操作无法影响系统运行分区sda,可放心执行。SWAP 文件方式新增,不删除或修改现有 SWAP,无任何风险。
准备:在 VMware 中添加实验磁盘
在开始前,需要在虚拟机中添加一块额外磁盘供实验使用:
- 打开 VMware 虚拟机设置 → 添加 → 硬盘 → SCSI → 新建虚拟磁盘
- 分配容量 10 GB,完成后启动虚拟机
验证新盘已被系统识别:
bash
lsblk
lsblk -d -o name,rota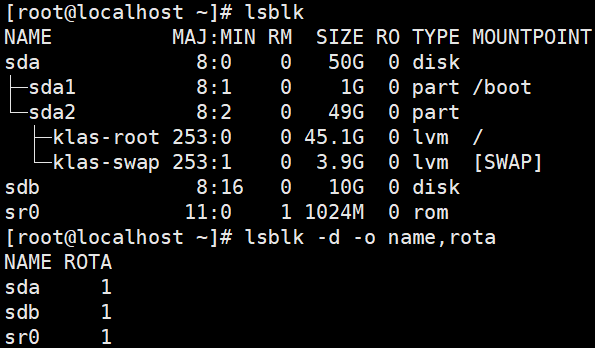
第一阶段:基础路径 --- 分区 → 格式化 → 挂载
目标 :体验不使用 LVM 的基础磁盘使用流程,在
sdb上划出 3GB 分区并挂载。
bash
# ─── 步骤 1:对 sdb 创建第一个分区(3GB)───
[root@localhost ~]# fdisk /dev/sdb
# 进入交互界面后依次输入:
# n → 新建分区
# p → 主分区
# 1 → 分区编号 1
# 回车(默认起始扇区)
# +3G(指定结束位置,划 3GB)
# w → 保存写入并退出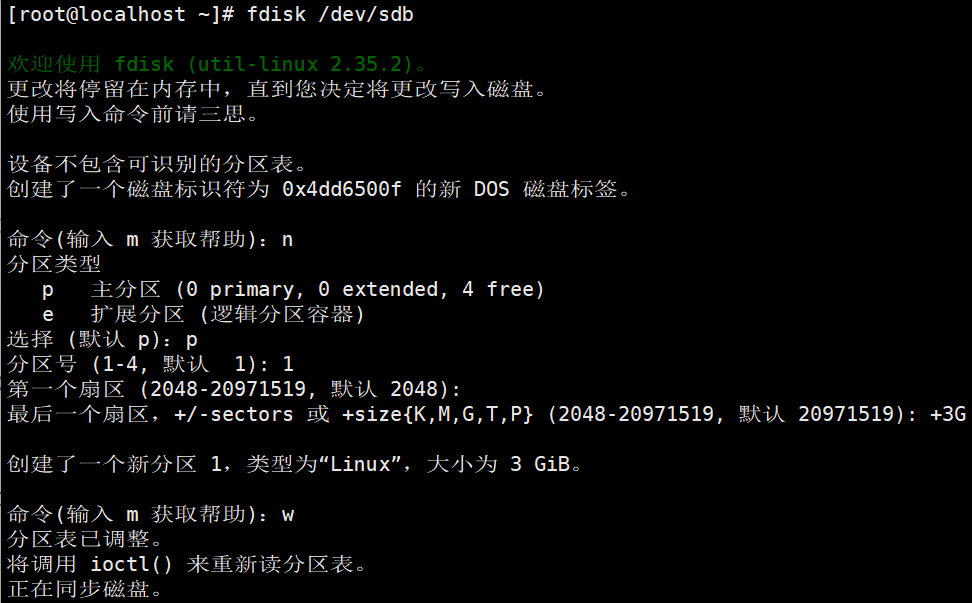
bash
# 确认分区已创建
[root@localhost ~]# lsblk /dev/sdb
# ─── 步骤 2:格式化为 XFS ───
[root@localhost ~]# mkfs.xfs /dev/sdb1
# ─── 步骤 3:创建挂载点并挂载 ───
[root@localhost ~]# mkdir /data_test
[root@localhost ~]# mount /dev/sdb1 /data_test
# ─── 步骤 4:验证挂载 ───
[root@localhost ~]# df -h | grep data_test
# ─── 步骤 5:写入测试文件,验证可读写 ───
[root@localhost ~]# echo "partition mount test" > /data_test/test1.txt
[root@localhost ~]# cat /data_test/test1.txt
# ─── 步骤 6:卸载(保留分区,仅解除挂载,便于后续继续实验)───
[root@localhost ~]# umount /data_test
[root@localhost ~]# df -h | grep data_test
# 无输出 → 已卸载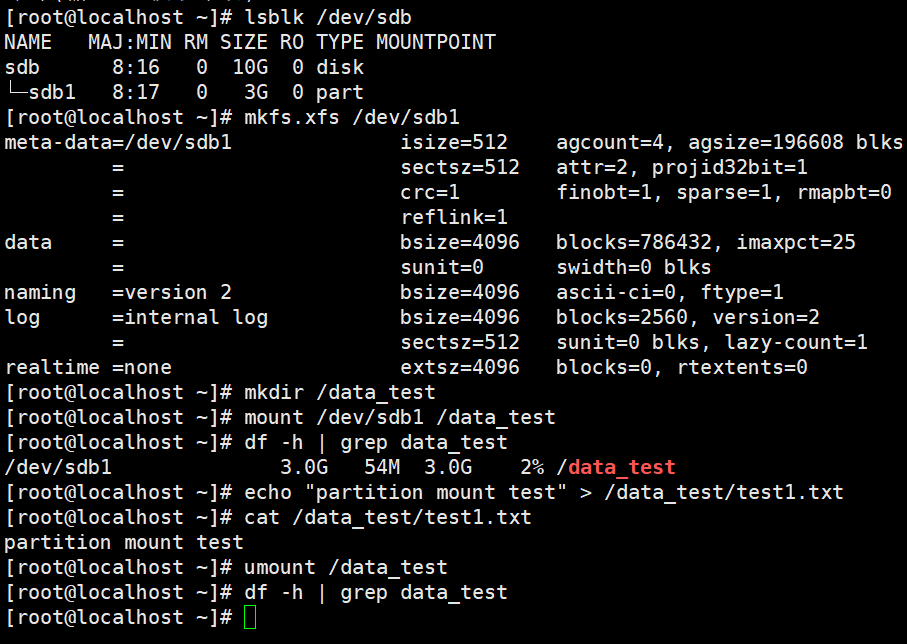
第二阶段:LVM 路径 --- PV → VG → LV → 格式化 → 永久挂载
目标 :用
sdb剩余约 7GB 空间,按生产规范搭建 LVM 结构,并配置开机自动挂载。
bash
# ─── 步骤 1:在 sdb 上再建一个分区(使用全部剩余空间)───
[root@localhost ~]# fdisk /dev/sdb
# n → p → 2 → 回车 → 回车(剩余全部)→ w
[root@localhost ~]# lsblk /dev/sdb
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdb 8:16 0 10G 0 disk
├─sdb1 8:17 0 3G 0 part # 第一阶段使用
└─sdb2 8:18 0 7G 0 part # ← 新分区,准备做 LVM
# ─── 步骤 2:初始化 PV(物理卷)───
[root@localhost ~]# pvcreate /dev/sdb2
Physical volume "/dev/sdb2" successfully created.
[root@localhost ~]# pvs
PV VG PSize PFree
/dev/sdb2 6.99g 6.99g # VG 列为空表示尚未加入卷组
# ─── 步骤 3:创建 VG(卷组)───
[root@localhost ~]# vgcreate datavg /dev/sdb2
Volume group "datavg" successfully created
[root@localhost ~]# vgs
VG #PV #LV #SN Attr VSize VFree
datavg 1 0 0 wz--n- 6.99g 6.99g
# ─── 步骤 4:创建 LV(逻辑卷)─── 划出 5GB
[root@localhost ~]# lvcreate -L 5G -n lv_data datavg
Logical volume "lv_data" created.
[root@localhost ~]# lvs
LV VG Attr LSize
lv_data datavg -wi-a----- 5.00g # ✓
# ─── 步骤 5:格式化逻辑卷 ───
[root@localhost ~]# mkfs.xfs /dev/datavg/lv_data
# 逻辑卷路径格式:/dev/<卷组名>/<逻辑卷名>
# ─── 步骤 6:挂载并配置永久挂载 ───
[root@localhost ~]# mkdir /mydata
[root@localhost ~]# mount /dev/datavg/lv_data /mydata
# 获取 UUID(永久挂载推荐使用 UUID,避免设备名变化导致挂载失败)
[root@localhost ~]# blkid /dev/datavg/lv_data
/dev/mapper/datavg-lv_data: UUID="92cd99dc-2ffd-458b-ba33-234103aa3c64" BLOCK_SIZE="512" TYPE="xfs"
# 写入 fstab(将 UUID 替换为上面查到的实际值)
[root@localhost ~]# echo "UUID=92cd99dc-2ffd-458b-ba33-234103aa3c64 /mydata xfs defaults 0 0" >> /etc/fstab
# 验证 fstab 无误
[root@localhost ~]# mount -a # 无报错即正确
# ─── 步骤 7:全面验证 ───
[root@localhost ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 50G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 49G 0 part
├─klas-root 253:0 0 45.1G 0 lvm /
└─klas-swap 253:1 0 3.9G 0 lvm [SWAP]
sdb 8:16 0 10G 0 disk
├─sdb1 8:17 0 3G 0 part # 第一阶段,已卸载
└─sdb2 8:18 0 7G 0 part
└─datavg-lv_data 253:2 0 5G 0 lvm /mydata # ✓ LVM 逻辑卷已挂载
sr0 11:0 1 1024M 0 rom
[root@localhost ~]# df -h | grep mydata
/dev/mapper/datavg-lv_data 5.0G 68M 5.0G 2% /mydata
[root@localhost ~]# pvs && vgs && lvs # 查看 LVM 三层状态
PV VG Fmt Attr PSize PFree
/dev/sda2 klas lvm2 a-- <49.00g 0
/dev/sdb2 datavg lvm2 a-- <7.00g <2.00g
VG #PV #LV #SN Attr VSize VFree
datavg 1 1 0 wz--n- <7.00g <2.00g
klas 1 2 0 wz--n- <49.00g 0
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
lv_data datavg -wi-ao---- 5.00g
root klas -wi-ao---- <45.06g
swap klas -wi-ao---- <3.94g 第三阶段:在线扩容 --- 验证 LVM 无损扩容能力
目标 :将
/mydata从 5GB 扩容至 6GB,验证数据在扩容过程中完好无损。
bash
# ─── 步骤 1:先写入测试数据,扩容后验证其完整性 ───
[root@localhost ~]# echo "lvm online resize test - data must survive" > /mydata/safety_check.txt
# ─── 步骤 2:确认 VG 还有剩余空间 ───
[root@localhost ~]# vgs datavg
VG #PV #LV #SN Attr VSize VFree
datavg 1 1 0 wz--n- <7.00g <2.00g # 还有约 2GB 可用
# ─── 步骤 3:扩展逻辑卷(+1GB)───
[root@localhost ~]# lvextend -L +1G /dev/datavg/lv_data
Size of logical volume datavg/lv_data changed from 5.00 GiB (1280 extents) to 6.00 GiB (1536 extents).
Logical volume datavg/lv_data successfully resized.
# ─── 步骤 4:同步文件系统(关键!否则 df 看不到新空间)───
[root@localhost ~]# xfs_growfs /mydata
meta-data=/dev/mapper/datavg-lv_data isize=512 agcount=4, agsize=327680 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1
data = bsize=4096 blocks=1310720, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
data blocks changed from 1310720 to 1572864 # ✓ 文件系统已扩展
# ─── 步骤 5:验证 ───
[root@localhost ~]# df -h | grep mydata
/dev/mapper/datavg-lv_data 6.0G 76M 6.0G 2% /mydata # ✓ 已扩至 6GB
[root@localhost ~]# cat /mydata/safety_check.txt
lvm online resize test - data must survive # ✓ 数据完好无损第四阶段:补充 SWAP --- 文件方式动态扩充交换空间
目标:在不修改现有 SWAP 分区的前提下,以文件方式额外新增 1GB SWAP。
bash
# ─── 步骤 1:查看当前 SWAP 状态 ───
[root@localhost ~]# free -m
total used free shared buff/cache available
Mem: 2879 2660 99 3 119 43
Swap: 4031 1050 2981
[root@localhost ~]# swapon --show
NAME TYPE SIZE USED PRIO
/dev/dm-1 partition 3.9G 1G -2 # 对应前文的 klas-swap,现有 SWAP,不动它
# ─── 步骤 2:创建 1GB SWAP 文件 ───
[root@localhost ~]# dd if=/dev/zero of=/swap_extra bs=1M count=1024
记录了1024+0 的读入
记录了1024+0 的写出
1073741824字节(1.1 GB,1.0 GiB)已复制,1.59706 s,672 MB/s # ✓
[root@localhost ~]# chmod 600 /swap_extra # 安全要求:仅 root 可读写
[root@localhost ~]# mkswap /swap_extra # 格式化为 SWAP 格式
正在设置交换空间版本 1,大小 = 1024 MiB (1073737728 个字节)
无标签,UUID=d6703ac5-22ff-4046-bb87-e110cad9697d
[root@localhost ~]# swapon /swap_extra # 激活
# ─── 步骤 3:验证 ───
[root@localhost ~]# free -m
total used free shared buff/cache available
Mem: 2879 2490 100 3 288 170
Swap: 5055 1220 3835 # ✓ 总量增加了约 1024MB
[root@localhost ~]# swapon --show
NAME TYPE SIZE USED PRIO
/dev/dm-1 partition 3.9G 1.2G -2
/swap_extra file 1024M 0B -3 # ✓ 新增文件型 SWAP
# ─── 步骤 4:永久生效 ───
[root@localhost ~]# echo "/swap_extra swap swap defaults 0 0" >> /etc/fstab第五阶段:I/O 调度 --- 查看与修改验证
目标:确认磁盘类型,查看当前调度算法,并练习切换操作。
bash
# ─── 步骤 1:确认磁盘类型 ───
[root@localhost ~]# lsblk -d -o name,rota
NAME ROTA
sda 1 # ROTA=1 → 机械盘
sdb 1 # ROTA=1 → 机械盘(VMware 虚拟盘均模拟为机械盘类型)
sr0 1
# ─── 步骤 2:查看当前调度算法([] 内为生效值)───
[root@localhost ~]# cat /sys/block/sda/queue/scheduler
[mq-deadline] kyber bfq none # 机械盘使用 mq-deadline,符合规范
[root@localhost ~]# cat /sys/block/sdb/queue/scheduler
[mq-deadline] kyber bfq none
# ─── 步骤 3:临时切换算法(练习,重启自动恢复)───
[root@localhost ~]# echo bfq > /sys/block/sdb/queue/scheduler
[root@localhost ~]# cat /sys/block/sdb/queue/scheduler
mq-deadline kyber [bfq] none # ✓ 已切换到 bfq
# ─── 步骤 4:改回推荐值 ───
[root@localhost ~]# echo mq-deadline > /sys/block/sdb/queue/scheduler
[root@localhost ~]# cat /sys/block/sdb/queue/scheduler
[mq-deadline] kyber bfq none # ✓ 已恢复第十章 Linux 磁盘管理操作核对清单
完成磁盘配置后,可按以下清单逐项核查关键指标:
| 序号 | 检查项 | 命令 | 期望结果 |
|---|---|---|---|
| 1 | 磁盘类型识别 | lsblk -d -o name,rota |
确认 ROTA 值,决定对应的调度策略 |
| 2 | I/O 调度算法 | cat /sys/block/<盘>/queue/scheduler |
HDD → [mq-deadline],SSD → [none] |
| 3 | 数据目录是否使用 LVM | lsblk 查看 TYPE 列 |
数据目录对应设备的 TYPE 应为 lvm |
| 4 | 文件系统类型 | df -T |
数据目录的 Filesystem 类型列应为 xfs |
| 5 | fstab 挂载方式 | cat /etc/fstab |
使用 UUID 挂载,而非设备路径 |
| 6 | SWAP 总量 | free -m 查看 Swap total |
建议为物理内存的 1~1.5 倍 |
| 7 | swappiness 值 | cat /proc/sys/vm/swappiness |
内存敏感型业务建议设为 10 |
| 8 | 挂载点空间余量 | df -h |
数据目录使用率 < 70% 为健康水位 |
| 9 | 重启后自动挂载 | 重启后执行 df -h |
数据目录仍在挂载点列表中 |
本文从物理磁盘识别出发,系统覆盖了分区、文件系统、挂载、SWAP、LVM 扩容与 I/O 调度优化等 Linux 磁盘管理的核心知识体系。理论结合实验是最高效的学习路径,建议在虚拟机中完整走一遍本文第九章的所有阶段,真正做到动手验证每一个知识点。