Tkinter的优点与局限
Tkinter作为Python 标准库中内置的 GUI(图形用户界面)工具包,具有以下优点:
优点
-
- 无需额外安装,开箱即用
Tkinter 是 Python 标准库的一部分(除极少数精简版 Python 外)。
用户运行你的程序时不需要安装任何第三方依赖,极大降低部署门槛。
- 无需额外安装,开箱即用
-
- 轻量、启动快
相比 PyQt、wxPython 等重型框架,Tkinter 内存占用小、启动速度快。
对于简单工具(如文件处理、配置窗口),响应几乎瞬时。
- 轻量、启动快
-
- 跨平台支持良好
支持 Windows、macOS、Linux,且在各平台上表现一致。
虽然原生外观略显"过时",但功能行为稳定。
- 跨平台支持良好
-
- 学习曲线平缓
API 简洁直观,概念少(widget + 布局 + 事件)。
初学者可在几小时内写出可用界面。
官方文档和社区教程丰富。
- 学习曲线平缓
-
- 与 Python 深度集成
作为标准库,与 Python 解释器无缝协作。
异常处理、线程交互(需注意主线程限制)等更自然。
- 与 Python 深度集成
-
- 足够应对中小型桌面应用
虽不擅长复杂 UI(如绘图、动画、多窗口协同),但对于:
配置面板
数据输入表单
文件/目录选择工具
自动化脚本前端
教学演示程序
完全够用且高效。
- 足够应对中小型桌面应用
-
- 可扩展性(通过 Ttk 和第三方美化)
内置 ttk(Themed Tk)模块提供现代化控件(如 Combobox、Notebook)。
第三方库如 CustomTkinter 等可让界面焕然一新(支持暗色主题、圆角、现代字体等),大幅提升视觉体验。
- 可扩展性(通过 Ttk 和第三方美化)
-
- 调试方便
因为是纯 Python 接口(底层 C 实现但上层封装干净),出错信息清晰。
不像某些绑定库(如 PyQt)可能出现"C++ 层崩溃"导致 Python 解释器直接退出。
- 调试方便
局限
| 局限 | 说明 |
|---|---|
| 默认外观老旧 | 但可通过 ttk 或 CustomTkinter 改善 |
| 不适合作复杂程序的 UI系统 | 如 CAD、视频编辑等高性能图形应用 |
| 多线程需谨慎 | GUI 必须在主线程操作 |
| 布局系统较原始 | 无 Flexbox、Constraint 等现代布局 |
不过,其中最主要的问题是Tkinter在构建UI时存在以下问题:
- 控件使用操作系统原生样式(Windows 经典按钮、macOS 老式控件等),在不同平台风格割裂。
- 无法实现现代 UI 所需的圆角、阴影、平滑过渡、暗色/亮色主题。
因此,不少第三方包针对Kinter的问题进行了改进,CustomTkinter就是一个代表性的第三方库。
CustomTkinter的改进
1、改进不同平台下外观不统一的问题
❌ tkinter 问题:
控件使用操作系统原生样式(Windows 经典按钮、macOS 老式控件等),在不同平台风格割裂。
无法实现现代 UI 所需的圆角、阴影、平滑过渡、暗色/亮色主题。
✅ CustomTkinter 改进:
完全自绘控件(基于 Canvas + 字体/颜色配置),实现跨平台一致的现代外观。
内置 浅色 / 深色双主题,支持一键切换:
控件具有圆角、高对比度、清晰字体、悬停/点击反馈动画。
2、改进控件现代化设计
❌ tkinter 问题:
Button、Entry 等控件样式简陋,无法满足现代审美。
ttk(Themed Tk)虽有改进,但主题有限,且自定义困难。
✅ CustomTkinter 改进:
提供重新设计的控件:
CTkButton:圆角、图标支持、悬停变色
CTkEntry:带边框聚焦效果、占位符(placeholder)
CTkCheckBox / CTkRadioButton:圆形/方形现代样式
CTkSlider、CTkProgressBar:平滑渐变
CTkTextbox:支持代码高亮风格
所有控件自动适配主题色(主色、强调色可配置)。
3、改进缩放与高分屏支持
❌ tkinter 问题:
在 Windows 高 DPI 屏幕上常出现模糊、错位、布局崩坏。
需手动处理缩放逻辑,复杂且易出错。
✅ CustomTkinter 改进:
内置高 DPI 自动缩放支持(基于系统 DPI 设置)。
所有尺寸(字体、边距、控件大小)自动按比例缩放,确保在 4K 屏或缩放 150% 时依然清晰。
禁止直接传入font=("Microsoft YaHei", 12)这种固定样式(防止缩放冲突),强制使用逻辑尺寸。
4、改进主题和样式的统一管理
❌ tkinter 问题:
每个控件需单独设置 bg、fg、font,维护成本高。
切换主题需遍历所有控件重设属性。
✅ CustomTkinter 改进:
全局主题系统:通过 ctk.set_default_color_theme("blue") 一键切换配色(蓝/绿/深紫等)。
所有控件自动继承主题色,无需逐个设置。
支持自定义 JSON 主题文件。
5、增加常用高级组件
❌ tkinter 问题:
无内置的 Spinner、Segmented Button、Scrollable Frame 等现代组件。
开发者需自行封装,重复造轮子。
✅ CustomTkinter 改进:
提供实用扩展组件:
CTkScrollableFrame:带滚动条的容器(无需手动绑定 Canvas)
CTkOptionMenu:下拉选择(比 ttk.Combobox 更美观)
CTkTabview:选项卡界面
CTkInputDialog:模态输入对话框
尽管CustomTkinter针对Tkinter进行了一些改进,但它并未改变Tkinter的底层架构,它的核心概念仍然是widget + 布局 + 事件 。widget 是程序的建筑材料,事件 是程序用户交互的核心,布局 则是UI界面构建的核心。下面对CustomTkinter的布局管理器进行一个简单归纳。
CustomTkinter的布局管理器
一、pack() 布局
- 1、适用场景:
简单线性排列(水平或垂直)
按顺序堆叠组件(如工具栏、按钮组、表单) - 2、基本语法:
python
widget.pack(side="top", fill="none", expand=False, padx=0, pady=0, anchor="center")- 3、核心参数:
| 参数 | 可选值 | 说明 |
|---|---|---|
| side | "top"(默认)、"bottom"、"left"、"right" | 组件贴靠哪一侧 |
| fill | "none"(默认)、"x"、"y"、"both" | 是否填充父容器(横向/纵向/全填) |
| expand | True / False(默认) | 是否随父容器扩大而分配额外空间 |
| padx, pady | 数字或 (left, right) 元组 | 外边距(像素) |
| anchor | "n", "s", "e", "w", "center" 等 | 在分配的空间内对齐方式 |
💡 示例:
python
水平居中两个按钮
frame = ctk.CTkFrame(root)
frame.pack(fill="x", padx=20, pady=10)
放入子 frame 并居中
center_frame = ctk.CTkFrame(frame, fg_color="transparent")
center_frame.pack(expand=True) # 关键:expand=True 实现居中
btn1 = ctk.CTkButton(center_frame , text="A")
btn2 = ctk.CTkButton(center_frame , text="B")
btn1.pack(side="left", padx=5)
btn2.pack(side="left", padx=5)⚠️ 注意:不能在同一个父容器中混用 pack 和 grid !
二、grid() 布局
- 1、 适用场景:
表格状布局(如表单、网格控件)
需要精确对齐的复杂界面 - 2、 基本语法:
python
widget.grid(row=0, column=0, sticky="", padx=0, pady=0, columnspan=1, rowspan=1)- 3、核心参数:
| 参数 | 说明 |
|---|---|
| row, column | 所在行/列(从 0 开始) |
| sticky | 对齐方式:"n", "s", "e", "w" 或组合如 "ew"(类似 anchor) |
| padx, pady | 外边距 |
| columnspan, rowspan | 跨多列或多行 |
| ipadx, ipady | 内边距(增大 widget 自身尺寸) |
| weight | 当窗口被拉大时,多余的空间的分配比例(实现自适应) |
python
# 第一列占总宽度的1/3,第二列占总宽的2/3
parent.grid_columnconfigure(0, weight=1)
parent.grid_rowconfigure(1, weight=2) weight=0(默认):当窗口被拉大时,控件不拉伸,仍然保持原来的尺寸
weight>0:按比例(本控件的weight/容器中所有控件的weight和)分配额外空间
💡 示例:居中两个按钮
python
frame = ctk.CTkFrame(root)
frame.pack(fill="x", padx=20, pady=10)
# 配置列权重:左右留空,中间放按钮
frame.grid_columnconfigure(0, weight=1) # 左侧空白
frame.grid_columnconfigure(1, weight=0) # 按钮A
frame.grid_columnconfigure(2, weight=0) # 按钮B
frame.grid_columnconfigure(3, weight=1) # 右侧空白
btn1 = ctk.CTkButton(frame, text="A", width=100)
btn2 = ctk.CTkButton(frame, text="B", width=100)
btn1.grid(row=0, column=1, padx=5)
btn2.grid(row=0, column=2, padx=5)三、place()布局
- place布局是绝对或相对定位布局,直接指定 widget 的精确位置和大小。有两种模式:
- 绝对定位:用像素指定 x, y, width, height
- 相对定位:用比例(0.0~1.0)指定 relx, rely, relwidth, relheight
- place布局 常用参数:
python
widget.place(
x=50, y=100, # 距离父容器左上角的绝对像素
width=200, height=30,
# 或使用相对坐标(推荐用于响应式)
relx=0.5, rely=0.5, # 相对于父容器宽高的比例(0.5=中心)
relwidth=0.8, relheight=0.1,
anchor="center" # 锚点:以 widget 哪个点对齐 (x,y) 或 (relx,rely)
)四、最佳实践建议
-
- 简单布局用 pack,如顶部菜单、底部按钮栏、垂直表单项。
-
- 复杂对齐用 grid,如登录表单(标签+输入框对齐)、仪表盘。
-
- 特殊场合用place,如固定位置元素(如 overlay、弹窗)等。
-
- 永远不要在同一个父 widget 中混用不同布局管理器,否则会卡死(tkinter 无限重排)。
-
- 响应式设计:
- 使用 grid_columnconfigure(..., weight=1) 让内容随窗口缩放
- 避免硬编码宽高,多用 fill 和 sticky
使用CustomTkinter创建GUI程序
以下使用CustomTkinter将上一篇博客中的命令行PDF去水印程序包装为GUI程序,从中可以看出CustomTkinter的基本操作其实跟Tkinter十分相似,但是控件外观以及调整外观的灵活性远远胜过TKinter。
python
import os
import hashlib
import tempfile
import shutil
from collections import defaultdict
import tkinter as tk
from tkinter import filedialog
import threading
import time
import pymupdf
import customtkinter as ctk
from PIL import Image
ctk.set_appearance_mode("dark")
ctk.set_default_color_theme("blue")
class PDFWatermarkRemoverGUI:
def __init__(self):
self.root = ctk.CTk()
self.root.title("PDF 水印删除工具")
self.root.geometry("1400x900")
# 临时文件夹
self.temp_dir = os.path.join(tempfile.gettempdir(), "pdf_watermark_remover_temp")
os.makedirs(self.temp_dir, exist_ok=True)
self.cleanup_temp_dir() # 启动时清理
self.pdf_path = None
self.doc = None
self.original_doc = None # 用于预览
self.watermark_images = {}
self.watermark_texts = {}
self.image_hashes = defaultdict(list)
self.text_hashes = defaultdict(list)
self.watermark_threshold = 2
self.threshold_var = ctk.StringVar(value=str(self.watermark_threshold))
self.selected_watermarks = set() # 存储选中的 hash
self.current_preview_path = None
self.setup_ui()
self.root.protocol("WM_DELETE_WINDOW", self.on_closing)
def cleanup_temp_dir(self):
try:
if os.path.exists(self.temp_dir):
for f in os.listdir(self.temp_dir):
try:
os.remove(os.path.join(self.temp_dir, f))
except:
pass
except:
pass
def setup_ui(self):
# 主框架 - 左右两列
self.main_frame = ctk.CTkFrame(self.root)
self.main_frame.pack(fill="both", expand=True, padx=10, pady=10)
# 左列
self.left_frame = ctk.CTkFrame(self.main_frame, width=700)
self.left_frame.pack(side="left", fill="both", expand=True, padx=(0, 5))
self.left_frame.pack_propagate(False)
# 右列
self.right_frame = ctk.CTkFrame(self.main_frame, width=700)
self.right_frame.pack(side="right", fill="both", expand=True, padx=(5, 0))
self.right_frame.pack_propagate(False)
self.setup_left_column()
self.setup_right_column()
self.setup_status_bar()
def setup_left_column(self):
# ==================== 第一组:文件 ====================
file_group = ctk.CTkFrame(self.left_frame)
file_group.pack(fill="x", pady=(0, 10))
# 缩略图
self.left_thumb_frame = ctk.CTkFrame(file_group, height=280)
self.left_thumb_frame.pack(fill="x", padx=10, pady=5)
self.left_thumb_label = ctk.CTkLabel(self.left_thumb_frame, text="PDF 预览缩略图", height=280)
self.left_thumb_label.pack(fill="both", expand=True)
# 阈值设置
threshold_frame = ctk.CTkFrame(file_group)
threshold_frame.pack(fill="x", padx=10, pady=5)
ctk.CTkLabel(threshold_frame, text="水印判定重复页数阈值:").pack(side="left", padx=5)
# 注册验证函数
va_cmd = (self.root.register(self.validate_int), '%P')
self.threshold_entry = ctk.CTkEntry(threshold_frame, textvariable=self.threshold_var,
width=80, validate='key', # 在每次按键时验证
validatecommand=va_cmd) # 验证回调
self.threshold_entry.pack(side="left")
# 增减按钮
self.plus_btn = ctk.CTkButton(threshold_frame, text="🔼", width=10, fg_color="transparent",
command=self.increase_threshold).pack(side="left")
self.minus_btn = ctk.CTkButton(threshold_frame, text="🔽", width=10, fg_color="transparent",
command=self.decrease_threshold).pack(side="left")
# 文件选择 + 水印分析
file_btn_frame = ctk.CTkFrame(file_group)
file_btn_frame.pack(fill="x", padx=10, pady=5)
# 居中方式一:加入expand=True的pack布局子CTkFrame中
center_frame = ctk.CTkFrame(file_btn_frame, fg_color="transparent")
center_frame.pack(expand=True) # 关键:expand=True 实现居中
self.select_btn = ctk.CTkButton(center_frame, text="选择文件",
command=self.select_pdf, width=100)
self.select_btn.pack(side="left", padx=20)
self.analyze_btn = ctk.CTkButton(center_frame, text="水印分析",
command=self.start_analysis, width=100,
state="disabled")
self.analyze_btn.pack(side="left", padx=20)
# 进度条
self.progress = ctk.CTkProgressBar(file_group)
self.progress.pack(fill="x", padx=10, pady=5)
self.progress.set(0)
self.progress_label = ctk.CTkLabel(file_group, text="")
self.progress_label.pack(pady=2)
# ==================== 第二组:疑似水印列表 ====================
list_group = ctk.CTkFrame(self.left_frame)
list_group.pack(fill="both", expand=True, pady=10)
(ctk.CTkLabel(list_group, text="疑似水印列表", font=ctk.CTkFont(size=16, weight="bold"))
.pack(anchor="w", padx=10, pady=5))
# 表格 Header
header_frame = ctk.CTkFrame(list_group)
header_frame.pack(fill="x", padx=10, pady=(0, 5))
ctk.CTkLabel(header_frame, text="选择", width=50).pack(side="left", padx=5)
ctk.CTkLabel(header_frame, text="类型", width=80).pack(side="left", padx=5)
ctk.CTkLabel(header_frame, text="详情", width=180).pack(side="left", padx=5)
ctk.CTkLabel(header_frame, text="次数", width=60).pack(side="left", padx=5)
ctk.CTkLabel(header_frame, text="页面", width=220).pack(side="left", padx=5)
# 可滚动表格
self.list_scroll = ctk.CTkScrollableFrame(list_group, height=260)
self.list_scroll.pack(fill="both", expand=True, padx=10, pady=5)
# 按钮区
btn_frame = ctk.CTkFrame(list_group)
btn_frame.pack(fill="x", padx=10, pady=5)
self.select_all_btn = ctk.CTkButton(btn_frame, text="全部选择", width=100,
command=self.select_all, state="disabled")
self.select_all_btn.pack(side="left", padx=5)
self.deselect_all_btn = ctk.CTkButton(btn_frame, text="取消选择", width=100,
command=self.deselect_all, state="disabled")
self.deselect_all_btn.pack(side="left", padx=5)
self.delete_selected_btn = ctk.CTkButton(btn_frame, text="删除选中", width=120,
fg_color="red", command=self.delete_selected, state="disabled")
self.delete_selected_btn.pack(side="right", padx=5)
def increase_threshold(self):
if self.doc:
self.threshold_var.set(str(self.get_threshold_safe() + 1))
def decrease_threshold(self):
if self.doc:
self.threshold_var.set(str(self.get_threshold_safe() - 1))
def setup_right_column(self):
# 右列缩略图
self.right_thumb_frame = ctk.CTkFrame(self.right_frame, height=700)
self.right_thumb_frame.pack(fill="x", padx=10, pady=10)
self.right_thumb_label = ctk.CTkLabel(self.right_thumb_frame, text="处理后预览", height=560)
self.right_thumb_label.pack(fill="both", expand=True)
# 居中方式二:利用grid_columnconfigure配置可伸缩的空列实现居中
op_frame = ctk.CTkFrame(self.right_frame, fg_color="transparent")
op_frame.pack(fill="x", padx=10, pady=10)
op_frame.grid_columnconfigure(0, weight=1)
op_frame.grid_columnconfigure(1, weight=0)
op_frame.grid_columnconfigure(2, weight=0)
op_frame.grid_columnconfigure(3, weight=1)
self.preview_btn = ctk.CTkButton(op_frame, text="预览当前结果", width=120,
command=self.preview_current, state="disabled")
self.preview_btn.grid(row=0, column=1, padx=20)
self.save_btn = ctk.CTkButton(op_frame, text="保存当前结果", fg_color="green",
width=120, command=self.save_file, state="disabled")
self.save_btn.grid(row=0, column=2, padx=20)
(ctk.CTkLabel(self.right_frame, text="说明", text_color="red",
font=ctk.CTkFont(size=16, weight="bold")).pack(anchor="center", padx=10, pady=5))
# 再创建正文文本框(正常大小)
textbox = ctk.CTkTextbox(
self.right_frame,
wrap="word",
font=("Microsoft YaHei", 12),
fg_color="transparent",
height=150
)
textbox.pack(fill="x", padx=10)
textbox.tag_config(
"body",
foreground="white",
spacing1=8, # 段前间距
spacing2=5, # 段内行间距
spacing3=8, # 段后行间距
lmargin1=46, # 首行缩进2字符
lmargin2=20
)
body = (
"1、如果PDF文件页面为扫描图片,不能使用本工具删除水印;\n"
f"2、限于PyMuPDF库的功能,如果文件中的文本水印与正文文本有部分重叠,删除文本水印将导致重叠的正文文本也被删除,"
f"因此,删除水印前请先检查是否存在文本水印与正文文本有部分重叠的情况;\n"
"3、请注意备份原始文件,以免使用本工具过程中发生问题造成损失。"
)
textbox.insert("end", body, "body")
textbox.configure(state="disabled")
def validate_int(self, value_if_allowed):
"""只允许数字(可为空)"""
if value_if_allowed == "":
return True # 允许清空
return value_if_allowed.isdigit() # 只允许正整数(无负号/小数)
def get_threshold_safe(self):
"""安全获取阈值,空时返回默认值"""
val = self.threshold_var.get()
if val == "":
return 2 # 默认值
try:
return int(val)
except ValueError:
return 2 # 理论上不会触发,因 validate 已过滤
def setup_status_bar(self):
self.status_bar = ctk.CTkFrame(self.root, height=30)
self.status_bar.pack(fill="x", side="bottom", padx=10, pady=5)
self.status_label = ctk.CTkLabel(self.status_bar, text="就绪", anchor="w",
font=ctk.CTkFont(size=14, weight="bold"), text_color="green")
self.status_label.pack(side="left", fill="x", expand=True, padx=10)
def update_status(self, text):
self.status_label.configure(text=text)
self.root.update_idletasks()
def select_pdf(self):
file_path = filedialog.askopenfilename(
title="选择 PDF 文件",
filetypes=[("PDF files", "*.pdf")]
)
if file_path:
self.analyze_btn.configure(state="normal")
self.select_all_btn.configure(state="disabled")
self.deselect_all_btn.configure(state="disabled")
self.delete_selected_btn.configure(state="disabled")
self.pdf_path = file_path
self.load_pdf_thumbnail(file_path, self.left_thumb_label)
self.update_status(f"已加载: {os.path.basename(file_path)}")
def load_pdf_thumbnail(self, pdf_path, target_label):
try:
self.doc = pymupdf.open(pdf_path)
page = self.doc[0]
# 获取 label 尺寸,若无效则用默认值
label_w = target_label.winfo_width() or 600
label_h = target_label.winfo_height() or 480
# 获取页面原始尺寸
page_w = page.rect.width
page_h = page.rect.height
# 等比缩放(完整显示)
scale = min(label_w / page_w, label_h / page_h)
matrix = pymupdf.Matrix(scale, scale)
pix = page.get_pixmap(matrix=matrix)
img_data = pix.tobytes("ppm")
img = Image.frombytes("RGB", (pix.width, pix.height), img_data)
# 调整大小
img.thumbnail((600, 480))
ctk_image = ctk.CTkImage(light_image=img, dark_image=img, size=img.size)
target_label.configure(image=ctk_image, text="")
target_label.image = ctk_image # 保持引用
except Exception as e:
target_label.configure(text=f"缩略图加载失败: {str(e)[:50]}")
def start_analysis(self):
if not self.pdf_path:
self.update_status("错误: 请先选择 PDF 文件")
return
self.watermark_threshold = min(self.get_threshold_safe(), len(self.doc))
self.update_status("正在分析水印...")
self.analyze_btn.configure(state="disabled")
self.select_all_btn.configure(state="disabled")
self.deselect_all_btn.configure(state="disabled")
self.delete_selected_btn.configure(state="disabled")
self.progress_label.configure(text="")
self.progress.set(0)
thread = threading.Thread(target=self.analyze_worker, daemon=True)
thread.start()
def analyze_worker(self):
try:
if not self.doc:
self.doc = pymupdf.open(self.pdf_path)
self.original_doc = pymupdf.open(self.pdf_path) # 备份
self.image_hashes.clear()
self.text_hashes.clear()
total_pages = len(self.doc)
for page_num, page in enumerate(self.doc):
# 图像处理
image_list = page.get_images(full=True)
image_xref_map = {}
for image in image_list:
xref = image[0]
try:
image_info = self.doc.extract_image(xref)
if image_info:
img_data = image_info["image"]
img_hash = hashlib.md5(img_data).hexdigest()
image_xref_map[xref] = {
"hash": img_hash,
"width": image_info["width"],
"height": image_info["height"],
}
except:
continue
# 文本+图像
text_dict = page.get_text("dict", flags=pymupdf.TEXT_PRESERVE_IMAGES | pymupdf.TEXTFLAGS_TEXT)
for block in text_dict.get("blocks", []):
if block.get("type") == 1: # 图像
img_data = block.get("image")
if img_data:
img_hash = hashlib.md5(img_data).hexdigest()
matched_xref = None
width, height = 0, 0
for xref, info in image_xref_map.items():
if info["hash"] == img_hash:
matched_xref = xref
width = info["width"]
height = info["height"]
break
self.image_hashes[img_hash].append({
"page": page_num + 1,
"block": block,
"bbox": block.get("bbox"),
"xref": matched_xref,
"width": width,
"height": height
})
elif block.get("type") == 0: # 文本
block_text = self.extract_text_from_block(block)
if block_text.strip():
text_hash = hashlib.md5(block_text.encode('utf-8')).hexdigest()
self.text_hashes[text_hash].append({
"page": page_num + 1,
"block": block,
"bbox": block.get("bbox"),
"text": block_text
})
# 更新进度
progress = (page_num + 1, total_pages)
self.root.after(0, self.update_progress, progress)
self.identify_watermarks()
self.root.after(0, self.populate_watermark_list)
except Exception as e:
self.root.after(0, lambda: self.update_status(f"分析失败: {str(e)}"))
finally:
self.root.after(0, lambda: self.analyze_btn.configure(state="normal"))
def update_progress(self, value):
self.progress.set(value[0] / value[1])
self.progress_label.configure(text=f"进度: {value[0]}/{value[1]}")
def extract_text_from_block(self, block):
text_lines = []
for line in block.get("lines", []):
line_text = "".join(span.get("text", "") for span in line.get("spans", []))
text_lines.append(line_text)
return "\n".join(text_lines)
def identify_watermarks(self):
self.watermark_images = {}
self.watermark_texts = {}
for img_hash, instances in self.image_hashes.items():
page_set = set(inst["page"] for inst in instances)
if len(page_set) >= self.watermark_threshold:
self.watermark_images[img_hash] = {
"count": len(instances),
"pages": sorted(list(page_set)),
"instances": instances,
"type": "image"
}
for text_hash, instances in self.text_hashes.items():
page_set = set(inst["page"] for inst in instances)
if len(page_set) >= self.watermark_threshold:
self.watermark_texts[text_hash] = {
"count": len(instances),
"pages": sorted(list(page_set)),
"instances": instances,
"type": "text"
}
self.update_status(f"发现 {len(self.watermark_images)} 个图像水印,{len(self.watermark_texts)} 个文本水印")
def populate_watermark_list(self):
# 清空现有
for widget in self.list_scroll.winfo_children():
widget.destroy()
self.watermark_widgets = {}
row = 0
# 图像水印
for h, info in self.watermark_images.items():
self.create_watermark_row(h, info, row)
row += 1
# 文本水印
for h, info in self.watermark_texts.items():
self.create_watermark_row(h, info, row)
row += 1
self.select_all_btn.configure(state="normal")
self.deselect_all_btn.configure(state="normal")
def create_watermark_row(self, hash_key, info, row_idx):
frame = ctk.CTkFrame(self.list_scroll, fg_color=("gray90", "gray20"))
frame.pack(fill="x", pady=1, padx=2)
var = tk.BooleanVar(value=False)
# 选择框
chk = ctk.CTkCheckBox(frame, text="", variable=var, width=50)
chk.pack(side="left", padx=5)
chk.configure(command=lambda h=hash_key, v=var: self.on_checkbox_toggle(h, v))
# 类型
typ = "图像" if info["type"] == "image" else "文本"
ctk.CTkLabel(frame, text=typ, width=80).pack(side="left", padx=5)
# 详情
if info["type"] == "image":
inst = info["instances"][0]
detail = f"{inst['width']}×{inst['height']} @ ({int(inst['bbox'][0])},{int(inst['bbox'][1])})"
else:
txt = info["instances"][0]["text"][:10] + "..." if len(info["instances"][0]["text"]) > 10 else \
info["instances"][0]["text"]
detail = txt.replace("\n", " ")
ctk.CTkLabel(frame, text=detail, width=180, anchor="w").pack(side="left", padx=5)
# 次数
ctk.CTkLabel(frame, text=str(info["count"]), width=60).pack(side="left", padx=5)
# 页面
pages_str = ",".join(map(str, info["pages"][:6])) + ("..." if len(info["pages"]) > 6 else "")
ctk.CTkLabel(frame, text=pages_str, width=220).pack(side="left", padx=5)
self.watermark_widgets[hash_key] = {
"var": var,
"frame": frame,
"info": info
}
def on_checkbox_toggle(self, hash_key, var):
if var.get():
self.selected_watermarks.add(hash_key)
else:
self.selected_watermarks.discard(hash_key)
if len(self.selected_watermarks) == 0:
self.delete_selected_btn.configure(state="disabled")
else:
self.delete_selected_btn.configure(state="normal")
def select_all(self):
for h, w in self.watermark_widgets.items():
w["var"].set(True)
self.selected_watermarks.add(h)
self.delete_selected_btn.configure(state="normal")
def deselect_all(self):
for h, w in self.watermark_widgets.items():
w["var"].set(False)
self.selected_watermarks.clear()
self.delete_selected_btn.configure(state="disabled")
def delete_selected(self):
if not self.selected_watermarks:
self.update_status("没有选中任何水印")
return
if not self.doc:
return
self.delete_selected_btn.configure(state="disabled")
self.update_status(f"正在删除 {len(self.selected_watermarks)} 个水印...")
thread = threading.Thread(target=self.delete_worker, daemon=True)
thread.start()
def delete_worker(self):
try:
to_delete = list(self.selected_watermarks)
for h in to_delete:
if h in self.watermark_images:
self.remove_single_image_watermark(self.watermark_images[h])
del self.watermark_images[h]
elif h in self.watermark_texts:
self.remove_single_text_watermark(self.watermark_texts[h])
del self.watermark_texts[h]
self.selected_watermarks.discard(h)
# 保存临时文件用于预览
temp_preview = os.path.join(self.temp_dir, f"preview_{int(time.time())}.pdf")
self.doc.save(temp_preview, garbage=4, deflate=True, clean=True)
self.current_preview_path = temp_preview
self.root.after(0, self.refresh_ui_after_delete)
except Exception as e:
self.root.after(0, lambda: self.update_status(f"删除失败: {str(e)}"))
def refresh_ui_after_delete(self):
self.populate_watermark_list()
self.load_pdf_thumbnail(self.current_preview_path, self.right_thumb_label)
self.preview_btn.configure(state="normal")
self.save_btn.configure(state="normal")
self.update_status("水印删除完成,可预览或保存")
def remove_single_image_watermark(self, info):
xrefs_to_remove = {inst.get("xref") for inst in info["instances"] if inst.get("xref")}
for xref in xrefs_to_remove:
try:
self.doc.update_object(xref, "<< /Type /XObject /Subtype /Form /BBox [0 0 0 0] >>")
except:
pass
def remove_single_text_watermark(self, info):
text_bboxes = defaultdict(list)
for instance in info["instances"]:
page_num = instance["page"] - 1
bbox = instance["bbox"]
text_bboxes[page_num].append(bbox)
for page_num, bboxes in text_bboxes.items():
if page_num < len(self.doc):
page = self.doc[page_num]
for bbox in bboxes:
try:
rect = pymupdf.Rect(bbox)
page.add_redact_annot(rect)
except:
pass
page.apply_redactions(images=0, graphics=0)
def preview_current(self):
if self.current_preview_path and os.path.exists(self.current_preview_path):
try:
os.startfile(self.current_preview_path)
except Exception as e:
self.update_status(f"预览失败: {e}")
def save_file(self):
if not self.current_preview_path:
return
output_file = filedialog.asksaveasfilename(
title="保存处理后的 PDF",
initialfile="output_clean.pdf",
defaultextension=".pdf",
filetypes=[("PDF files", "*.pdf")]
)
if output_file:
try:
shutil.copy2(self.current_preview_path, output_file)
self.update_status(f"已保存: {os.path.basename(output_file)}")
try:
os.startfile(output_file)
except:
pass
except Exception as e:
self.update_status(f"保存失败: {e}")
def on_closing(self):
self.cleanup_temp_dir()
if self.doc:
try:
self.doc.close()
except:
pass
if self.original_doc:
try:
self.original_doc.close()
except:
pass
self.root.destroy()
def run(self):
self.root.mainloop()
if __name__ == "__main__":
app = PDFWatermarkRemoverGUI()
app.run()程序运行界面如下:
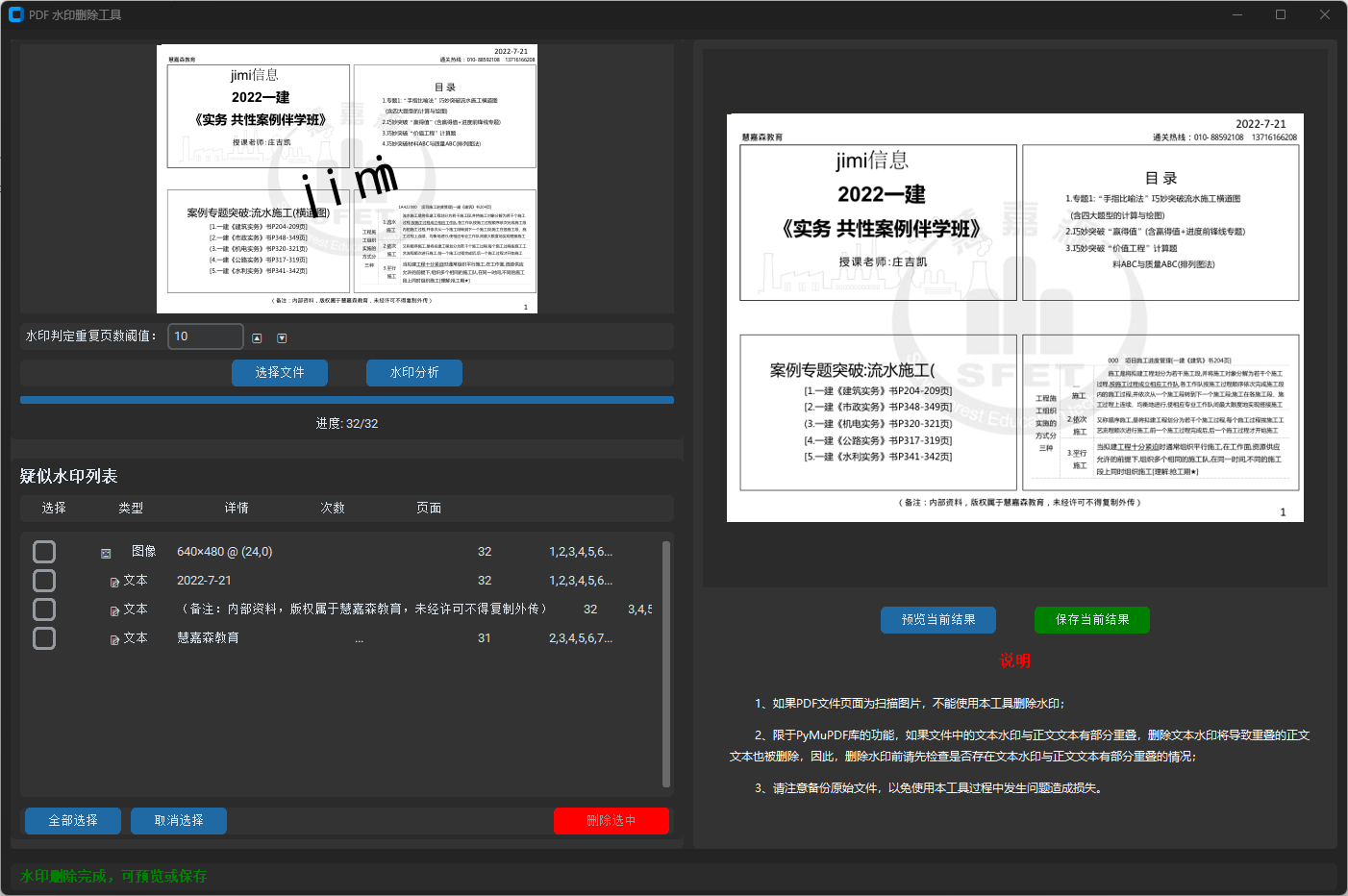
顺便制作了一个cx_Freeze的打包脚本,将其包装为exe文件:
python
import sys
from cx_Freeze import setup, Executable
# 打包配置
build_exe_options = {
"packages": [
"os",
"hashlib",
"tempfile",
"shutil",
"collections",
"tkinter",
"threading",
"time",
"pymupdf",
"customtkinter",
"PIL"
],
"excludes": [
"unittest",
"email",
"http",
"xml"
],
"include_files": [],
"optimize": 2,
"include_msvcr": True
}
# 程序基础信息
base = None
if sys.platform == "win32":
# Windows 系统:不显示命令行黑窗口(GUI 程序专用)
base = "GUI"
# 执行打包
setup(
name="PDF watermark remover",
version="1.0",
description="基于PyMuPDF的PDF文本水印删除工具",
author="你的名称",
options={"build_exe": build_exe_options},
executables=[
Executable(
script="wmk_remover_gui.py", # 你的主程序文件名
base=base,
icon="app.ico", # 如需图标,替换为 icon="app.ico"
target_name="PDF水印去除工具.exe"
)
]
)上面的截图就是执行python cx_freeze_setup.py build后生成的PDF水印去除工具.exe运行的的结果。