前言
在前面的实验中,我们已经通过Shell命令和Web界面与YARN进行过交互,也利用YARN提交和监控过MapReduce作业。但YARN作为Hadoop生态的资源调度大脑 ,其底层架构和工作机制远比表面看到的复杂。本文将从YARN基础架构 、作业提交流程 、三大调度器对比 和生产环境核心参数调优四个维度,结合架构图与源码逻辑,带你彻底掌握YARN的设计精髓。
一、YARN的定位与核心价值
YARN(Yet Another Resource Negotiator)是Hadoop 2.x引入的分布式资源调度平台,解决了Hadoop 1.x中JobTracker单点瓶颈和资源管理僵化的问题。
YARN的两大核心使命:
| 使命 | 说明 |
|---|---|
| 集群资源统一管理 | 将多台服务器的CPU、内存、磁盘、网络资源池化,统一调度 |
| 任务合理分配 | 根据应用需求,将任务分配到最合适的节点执行,实现数据局部性 |
可以把YARN理解为分布式操作系统:MapReduce、Spark、Flink等计算框架都是运行在其上的"应用程序"。
二、YARN基础架构详解
2.1 四大核心组件
YARN由ResourceManager、NodeManager、ApplicationMaster和Container四大组件构成,各司其职,协同工作。
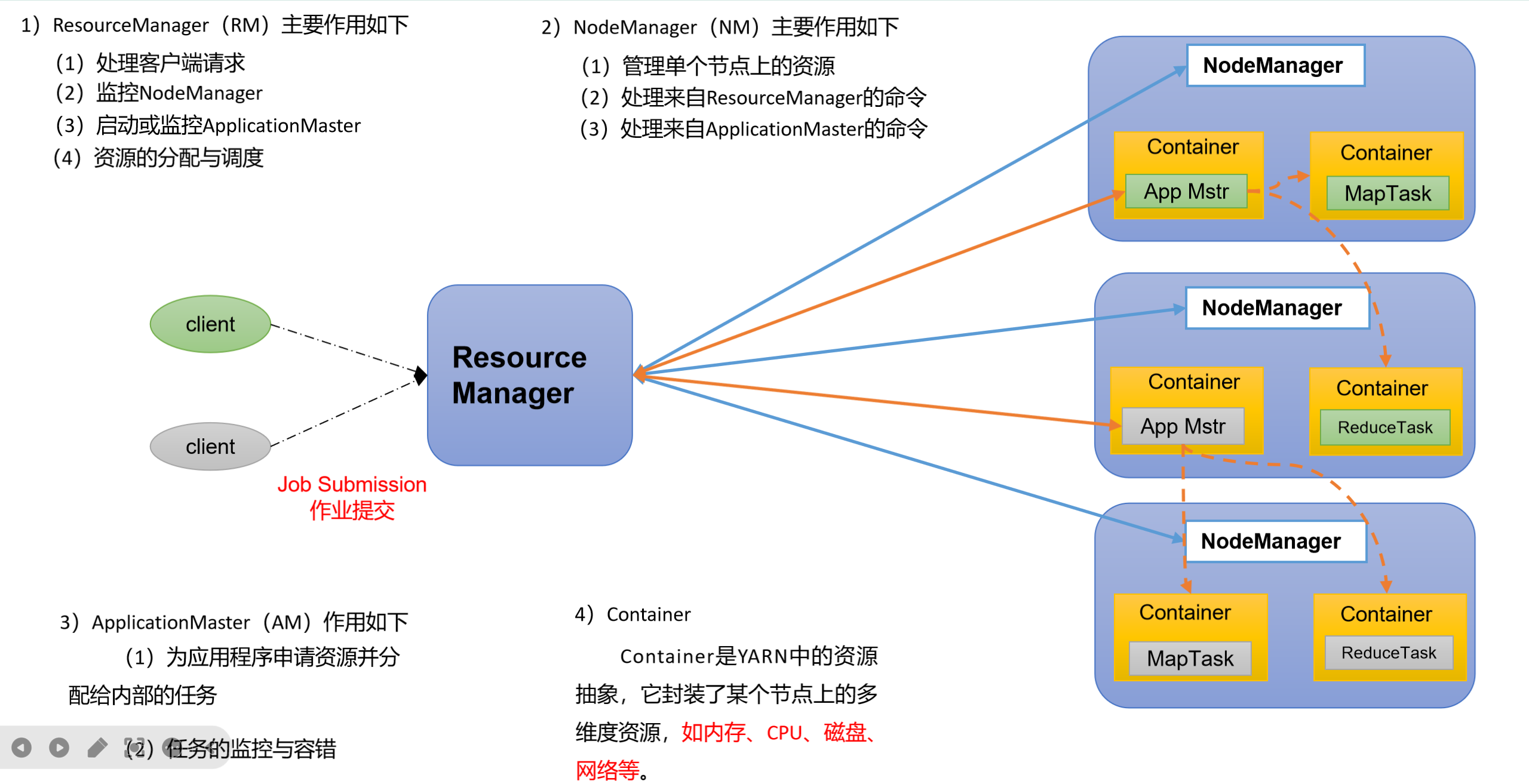
2.2 组件职责深度解析
① ResourceManager(RM)------ 集群资源老大
RM是整个集群资源的全局管理者,负责:
| 职责 | 详细说明 |
|---|---|
| 处理客户端请求 | 接收作业提交、查询、终止等请求 |
| 监控NodeManager | 通过心跳机制掌握各节点资源使用情况 |
| 启动/监控ApplicationMaster | 为每个应用启动AM,并监控其存活状态 |
| 资源分配与调度 | 根据调度策略,将Container分配给各应用 |
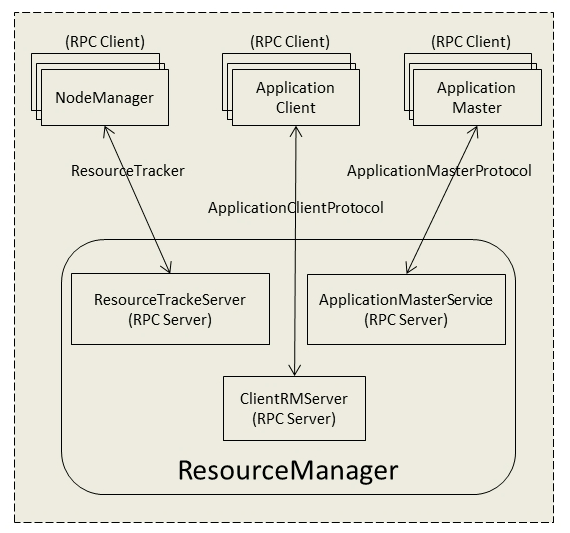
RM内部架构:
- ResourceTrackerServer:接收NodeManager的心跳汇报
- ApplicationMasterService:处理AM的资源申请和状态汇报
- ClientRMServer:处理客户端的请求
② NodeManager(NM)------ 单节点资源老大
NM是单个节点的资源管理者,负责:
| 职责 | 详细说明 |
|---|---|
| 管理单节点资源 | 监控本机CPU、内存、磁盘使用情况 |
| 执行RM命令 | 创建/销毁Container,启动AM和任务 |
| 处理AM命令 | 接收AM的任务启动、停止指令 |
| 定时向RM汇报 | 心跳机制汇报节点状态和Container运行情况 |
③ ApplicationMaster(AM)------ 任务老大
AM是单个应用的协调者,每个应用独占一个AM:
| 职责 | 详细说明 |
|---|---|
| 向RM申请资源 | 根据任务需求申请Container |
| 任务监控与容错 | 监控MapTask/ReduceTask运行状态,失败时重新申请资源 |
| 任务调度 | 决定任务在哪个Container上运行 |
关键设计:AM与任务同节点运行,若AM挂了,RM会检测到并重新分配资源启动新的AM。
④ Container------ 资源抽象单元
Container是YARN的资源抽象,封装了某个节点上的多维度资源:
| 资源维度 | 说明 |
|---|---|
| 内存 | 默认最小1G,最大8G |
| CPU虚拟核数 | 默认最小1核,最大4核 |
| 磁盘 | 本地磁盘空间 |
| 网络 | 网络带宽 |
Container不是物理容器(如Docker),而是逻辑资源隔离单元,由NM通过Cgroup等机制实现资源限制。
三、YARN工作机制与作业提交流程
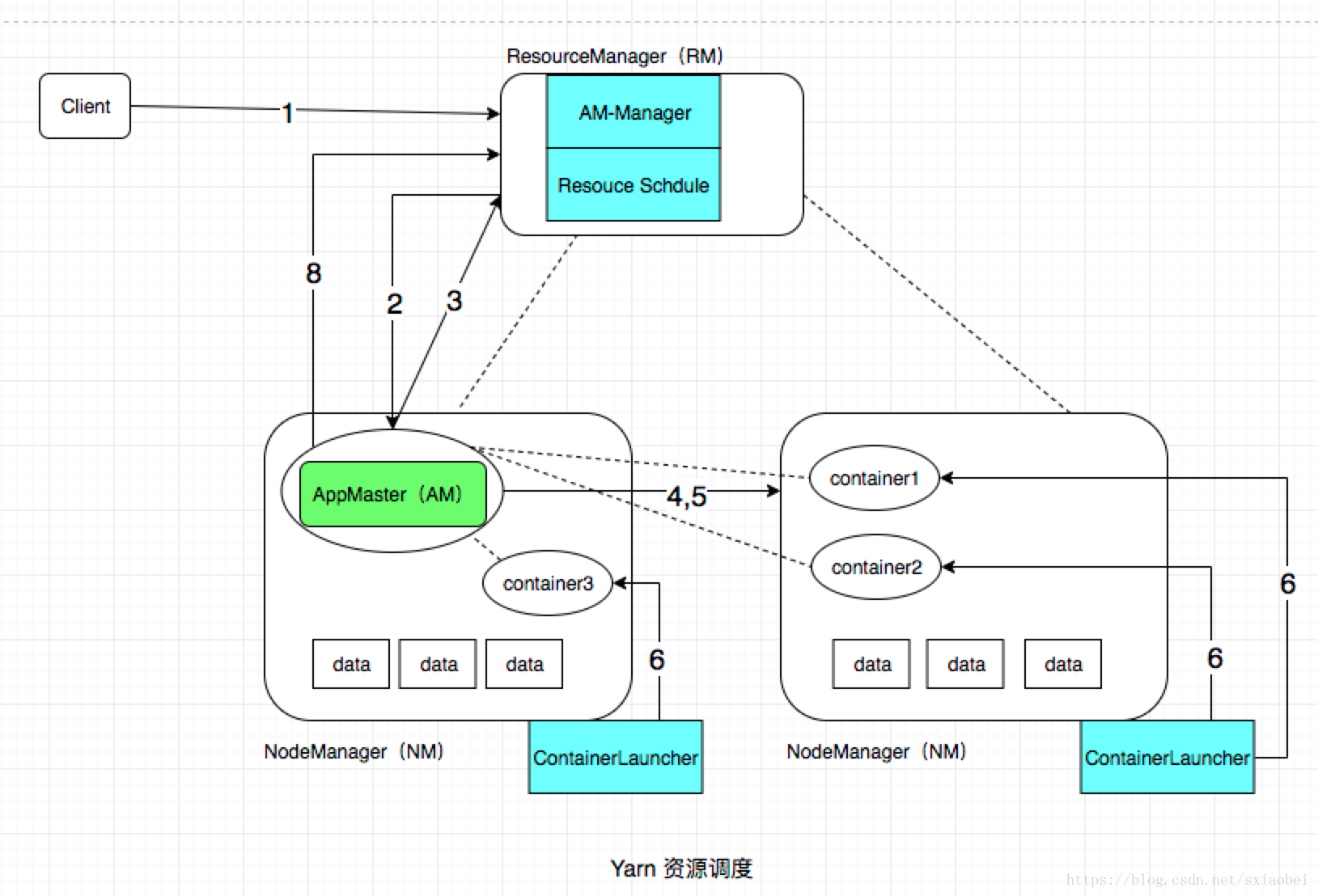
3.1 完整流程图解
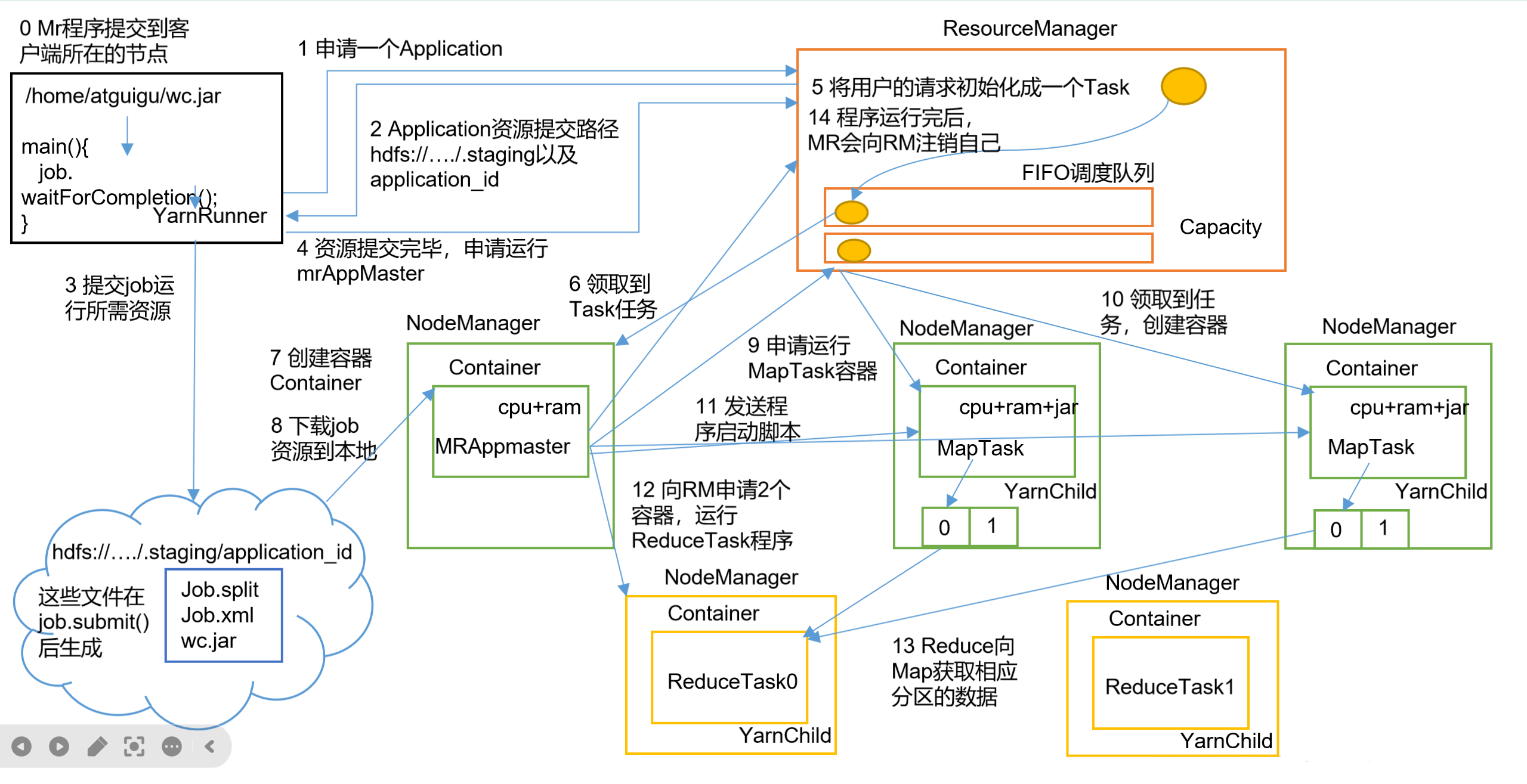
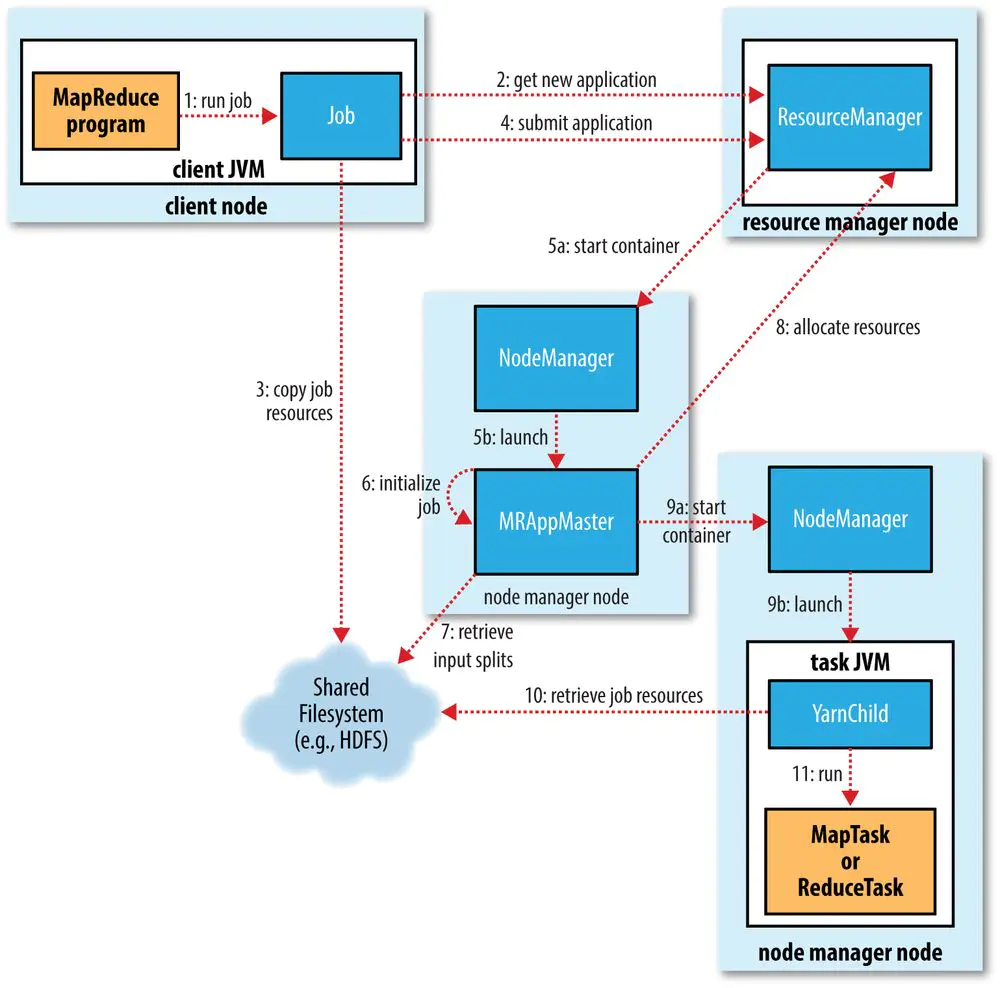
3.2 十五步详细解析
第一阶段:作业提交(第1-5步)
| 步骤 | 操作 | 说明 |
|---|---|---|
| ① | MR程序提交到客户端节点 | 客户端调用job.waitForCompletion() |
| ② | 向RM申请Application | YarnRunner向RM请求新的应用ID |
| ③ | RM返回资源提交路径和作业ID | 路径如hdfs://.../.staging/application_xxx |
| ④ | 提交资源到HDFS | 上传jar包、切片信息、job.xml配置文件 |
| ⑤ | 申请运行MRAppMaster | 资源提交完毕后,向RM申请启动AM |
第二阶段:作业初始化(第6-9步)
| 步骤 | 操作 | 说明 |
|---|---|---|
| ⑥ | RM将Job加入调度器 | 根据调度策略放入对应队列 |
| ⑦ | 空闲NM领取Task | 某个NM通过心跳获取到任务 |
| ⑧ | NM创建Container并启动AM | AM在Container中运行 |
| ⑨ | AM下载资源到本地 | 从HDFS下载jar包和配置 |
第三阶段:任务分配(第10-11步)
| 步骤 | 操作 | 说明 |
|---|---|---|
| ⑩ | AM向RM申请MapTask资源 | 根据切片数量申请对应Container |
| ⑪ | RM分配Container给NM | 选择资源充足的节点分配任务 |
第四阶段:任务运行(第12-15步)
| 步骤 | 操作 | 说明 |
|---|---|---|
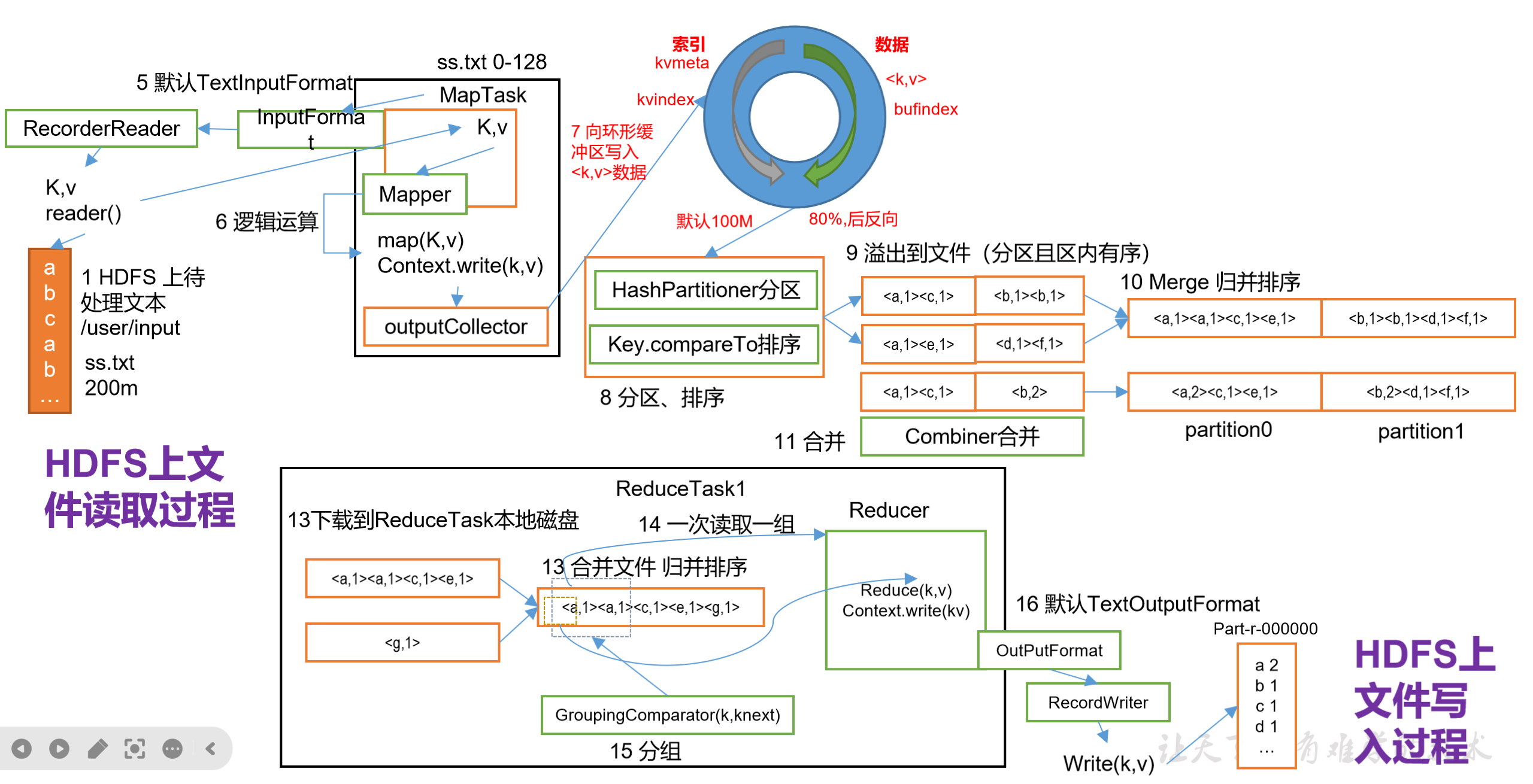
| ⑫ | AM发送启动脚本,NM启动MapTask | MapTask对数据分区排序 |
| ⑬ | MapTask完成后,AM申请ReduceTask资源 | 等待所有MapTask结束 |
| ⑭ | ReduceTask向MapTask拉取数据 | 按分区获取中间结果 |
| ⑮ | 程序结束,AM向RM申请注销 | 释放所有资源 |
3.3 进度与状态更新机制
| 机制 | 频率 | 说明 |
|---|---|---|
| 任务进度汇报 | 实时 | 任务将进度和Counter返回给AM |
| 客户端轮询 | 每秒1次 | 客户端向AM请求进度更新,展示给用户 |
| 作业完成检查 | 每5秒 | 客户端调用waitForCompletion()检查 |
| 资源清理 | 作业完成后 | AM和Container清理工作状态 |
四、YARN三大调度器对比
YARN支持三种调度器:FIFO、Capacity Scheduler和Fair Scheduler。
4.1 FIFO调度器(先进先出)
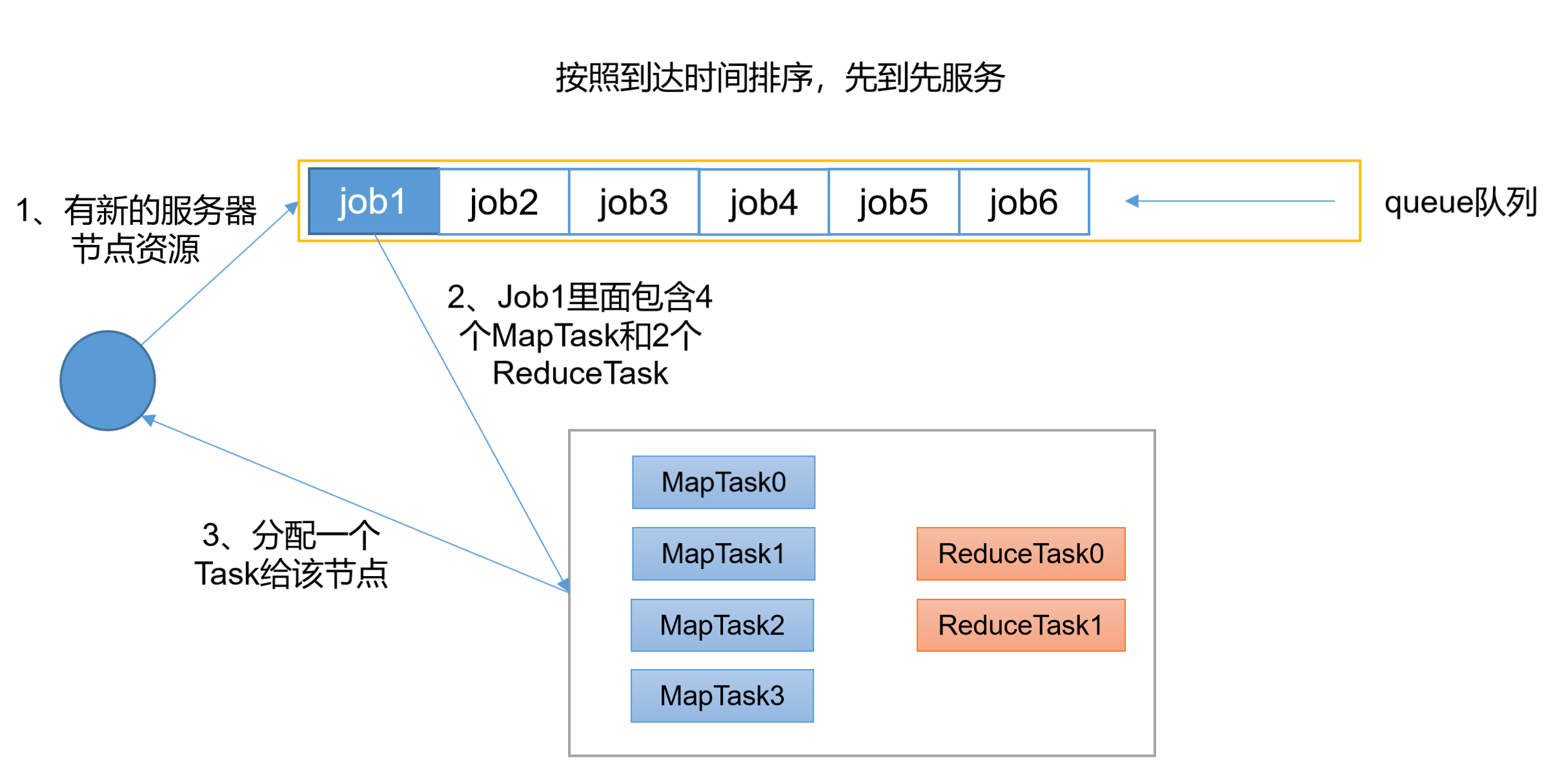
特点:
- 单队列,按提交顺序先来先服务
- 简单易懂,但不支持多用户共享
- 生产环境几乎不用
4.2 容量调度器(Capacity Scheduler)
Apache Hadoop 3.1.3默认调度器,Yahoo开发。
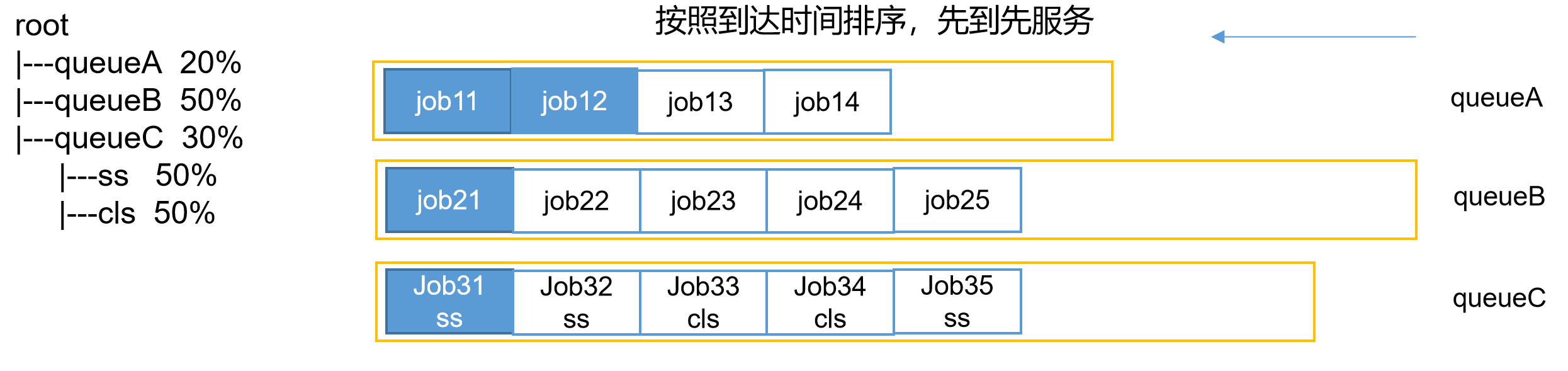
核心特性:
| 特性 | 说明 |
|---|---|
| 多队列支持 | 默认只有default队列,可配置多个 |
| 容量保证 | 每个队列配置资源容量百分比,保证最低资源 |
| 弹性分配 | 空闲资源可分配给其他队列,提高利用率 |
| ACL权限控制 | 控制用户/组对队列的提交和管理权限 |
| 优先级支持 | 资源紧张时,高优先级任务优先获取资源 |
配置示例:
xml
<!-- capacity-scheduler.xml -->
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,hive</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>40</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.hive.capacity</name>
<value>60</value>
</property>生产环境多队列设计思路:
| 设计维度 | 示例 |
|---|---|
| 按框架分 | hive队列、spark队列、flink队列 |
| 按业务部门分 | 登录注册队列、购物车队列、下单队列、支付队列 |
| 按优先级分 | 高优先级队列(双十一核心交易)、低优先级队列(离线报表) |
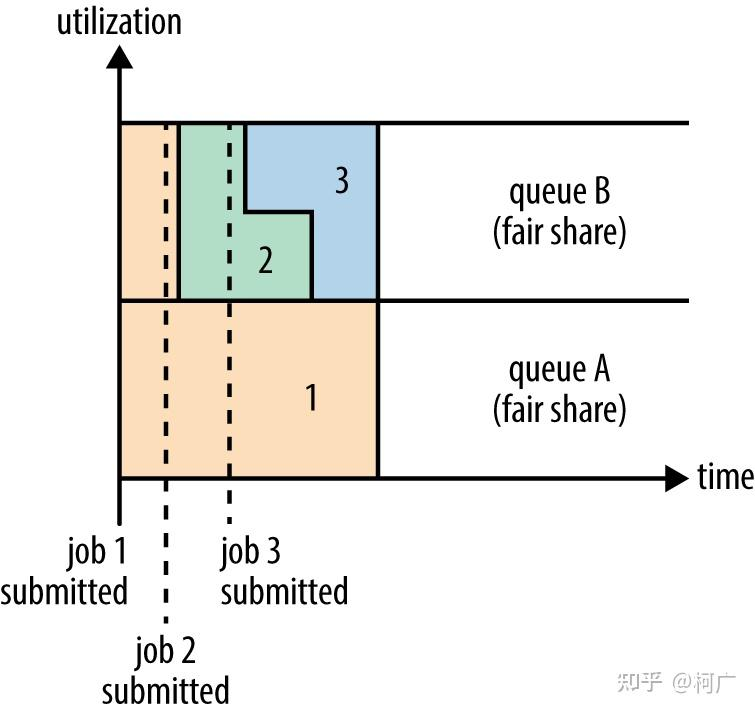
4.3 公平调度器(Fair Scheduler)
CDH框架默认调度器,Facebook开发。
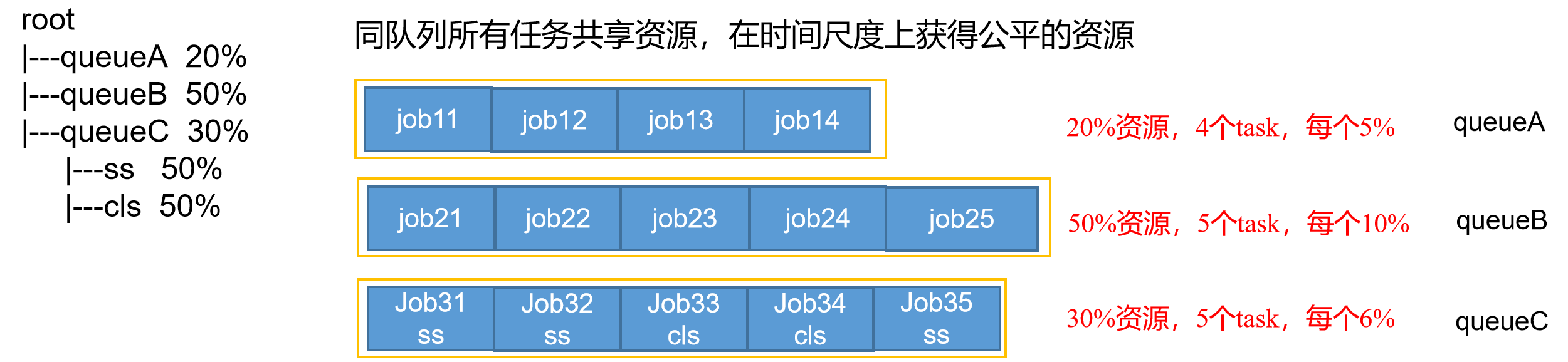
核心特性:
| 特性 | 说明 |
|---|---|
| 公平共享 | 所有应用平均分配资源,缺额大的优先获取 |
| 支持抢占 | 允许从超额队列回收资源(默认关闭) |
| 队列放置规则 | 支持按用户、组、指定队列等多层规则自动分配 |
| 最小资源保证 | 每个队列可配置最小资源,防止饿死 |
公平调度器配置:
xml
<!-- yarn-site.xml -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/fair-scheduler.xml</value>
</property>队列放置规则示例:
xml
<!-- fair-scheduler.xml -->
<queuePlacementPolicy>
<!-- 先匹配指定队列 -->
<rule name="specified" create="false"/>
<!-- 再按用户所属组匹配 -->
<rule name="nestedUserQueue" create="true">
<rule name="primaryGroup" create="false"/>
</rule>
<!-- 最后拒绝或放入default -->
<rule name="reject"/>
</queuePlacementPolicy>4.4 三大调度器对比总结
| 维度 | FIFO | Capacity Scheduler | Fair Scheduler |
|---|---|---|---|
| 默认场景 | 无 | Apache Hadoop | CDH |
| 队列支持 | 单队列 | 多队列 | 多队列 |
| 资源分配 | 先来先服务 | 容量百分比 | 公平共享 |
| 弹性扩展 | 无 | 空闲资源可借用 | 支持抢占 |
| 适用场景 | 测试环境 | 多用户共享、资源隔离 | 多用户公平共享 |
五、YARN生产环境核心参数调优
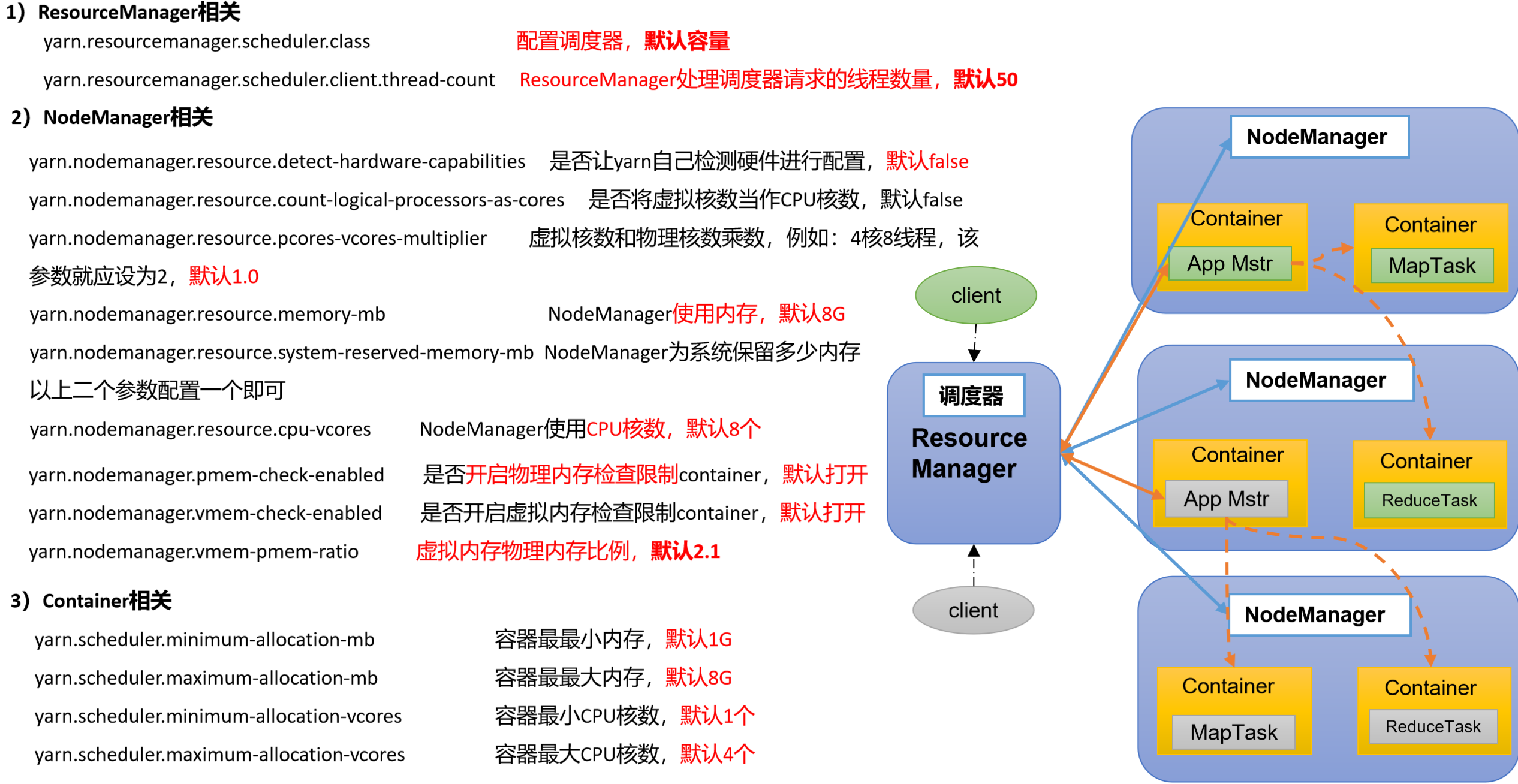
5.1 参数配置案例
场景:3台服务器,每台4G内存、4核CPU、4线程,处理1G数据。
计算分析:
- 1G数据 / 128M切片 = 8个MapTask
- 1个ReduceTask + 1个MRAppMaster
- 共10个任务 / 3台 ≈ 每台3-4个任务
5.2 核心参数详解
ResourceManager参数
xml
<!-- 调度器选择,默认容量调度器 -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
<!-- RM处理调度器请求的线程数,默认50 -->
<property>
<name>yarn.resourcemanager.scheduler.client.thread-count</name>
<value>8</value>
</property>NodeManager参数
xml
<!-- NM使用内存,默认8G,根据实际调整 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- NM使用CPU虚拟核数,默认8 -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value>
</property>
<!-- 是否自动检测硬件,生产环境建议手动配置 -->
<property>
<name>yarn.nodemanager.resource.detect-hardware-capabilities</name>
<value>false</value>
</property>Container资源限制参数
xml
<!-- 容器最小内存,默认1G -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<!-- 容器最大内存,默认8G -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<!-- 容器最小CPU核数,默认1 -->
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
<!-- 容器最大CPU核数,默认4 -->
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>2</value>
</property>虚拟内存参数
xml
<!-- 虚拟内存检查,默认打开,建议关闭避免误杀 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 虚拟内存与物理内存比例,默认2.1 -->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>5.3 参数调优黄金法则
| 原则 | 说明 |
|---|---|
| 内存配置 | Container最大内存 ≤ NM总内存 / 同时运行Container数 |
| CPU配置 | Container最大vcores ≤ NM总vcores / 同时运行Container数 |
| 虚拟内存 | 若任务频繁被kill,尝试关闭vmem-check或调大ratio |
| 异构集群 | 硬件不一致时,每台NM单独配置 |
| 预留资源 | 为系统进程和AM预留20%-30%资源 |
六、YARN常用命令与实战
6.1 应用管理命令
bash
# 列出所有Application
yarn application -list
# 按状态过滤
yarn application -list -appStates FINISHED
# 查看应用详情
yarn application -status application_xxx
# 终止应用
yarn application -kill application_xxx6.2 日志查看命令
bash
# 查看应用日志
yarn logs -applicationId application_xxx
# 查看指定Container日志
yarn logs -applicationId application_xxx -containerId container_xxx6.3 节点与队列管理
bash
# 查看所有节点状态
yarn node -list -all
# 刷新队列配置(无需重启YARN)
yarn rmadmin -refreshQueues
# 查看队列信息
yarn queue -status default6.4 任务优先级实战
bash
# 提交时指定优先级(需先开启优先级支持)
hadoop jar wordcount.jar -D mapreduce.job.priority=5 /input /output
# 动态修改运行中任务的优先级
yarn application -appID application_xxx -updatePriority 5七、YARN Tool接口与动态传参
7.1 问题背景
直接运行hadoop jar wc.jar WordCountDriver -Dmapreduce.job.queuename=root.test /input /output会报错,因为-D参数被误认为是输入路径。
7.2 Tool接口解决方案
实现Tool接口,通过ToolRunner解析参数:
java
public class WordCount implements Tool {
private Configuration conf;
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(conf);
// ... 作业配置
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
@Override
public void setConf(Configuration conf) { this.conf = conf; }
@Override
public Configuration getConf() { return conf; }
}
// Driver
public class WordCountDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Tool tool = new WordCount();
// ToolRunner自动解析-D参数
int run = ToolRunner.run(conf, tool, args);
System.exit(run);
}
}提交命令:
bash
yarn jar YarnDemo.jar com.atguigu.yarn.WordCountDriver \
wordcount -Dmapreduce.job.queuename=root.test /input /output八、核心知识点总结
| 主题 | 核心要点 |
|---|---|
| YARN架构 | RM全局管理、NM单节点管理、AM任务协调、Container资源单元 |
| 作业提交流程 | 客户端提交→RM分配→NM启动AM→AM申请资源→启动任务→完成注销 |
| 调度器选择 | FIFO简单但不实用;Capacity多队列容量隔离;Fair公平共享 |
| 生产调优 | 根据硬件配置NM资源、合理设置Container上下限、关闭虚拟内存检查 |
| 动态传参 | 实现Tool接口,通过ToolRunner解析-D参数 |
九、面试高频考点
Q1:YARN相比Hadoop 1.x的JobTracker有什么优势?
A:解耦资源管理和作业调度,RM只负责资源分配,AM负责作业协调,支持多计算框架(MR/Spark/Flink)共享集群资源。
Q2:ApplicationMaster挂了怎么办?
A:RM通过心跳监控AM存活状态,若AM挂了,RM会重新分配资源启动新的AM,新AM从HDFS恢复作业状态继续执行。
Q3:ReduceTask数量如何影响YARN资源分配?
A:ReduceTask数决定申请的Container数量,过多会导致资源争抢,过少则Reduce端压力大。一般设置为节点数的0.95或1.75倍。
Q4:容量调度器和公平调度器的核心区别?
A:容量调度器以队列容量百分比分配资源,强调资源隔离;公平调度器以缺额大小分配资源,强调公平共享,支持抢占。