文章目录
一、斐波那契数
斐波那契数 (通常用 F(n) 表示)形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是:
F(0) = 0,F(1) = 1
F(n) = F(n - 1) + F(n - 2),其中 n > 1
给定 n ,请计算 F(n) 。
解题思路
方法一(递归):
- 递归的思路很简单,重点是对它的分析
代码实现:
java
//(1):递归解法
class Solution {
public int fib(int n) {
return dfs(n);
}
int dfs(int n){
if(n<=1){
return n;
}
return dfs(n-1)+dfs(n-2);
}
}当n=5时,递归展开图:
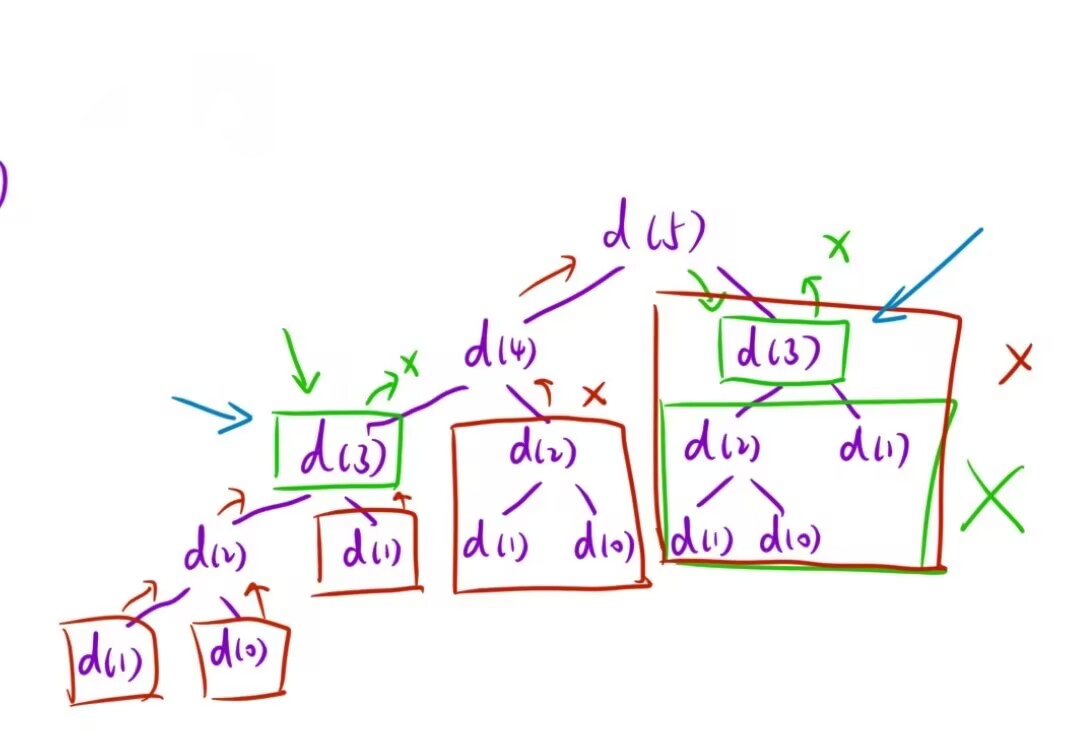
- 我们发现该递归算法的时间复杂度是O(2n)
- 在展开图中可以看出来当中有许多重复的计算,如:d(3)、d(2)、d(1)... ,而接下来的记忆化搜索就是对这个问题进行优化
方法二(记忆化搜索):
- 为了解决上面普通递归算法中出现的递归树中重复性计算问题,我们可以在递归回溯之前中将该层递归的结果保存起来,下次遇到相同的递归情况时直接拿来用,不用再次将相同的递归展开来计算了,这就叫记忆化搜,一句话总结什么是记忆化搜索:
对有些递归中会出现的重复性计算问题优化而得来的带备忘录的递归
如何实现记忆化搜索?
1.添加一个备忘录,记录:<可变参数,返回值>这样的键值对,那么跟以前一样,可以使用Map,也可以直接使用一个数组就解决了(当参数可以用数组下标表示时)
2.递归每次返回的时候,先将结果放到备忘录里面
3.在每次进入递归的时候,先往备忘录里面瞅一瞅是不是已经有这个结果了
代码实现:
java
//(2):记忆化搜索
class Solution {
int[] memory=new int[31];//本题说了0 <= n <= 30,所以备忘录的大小31就刚好够了
public int fib(int n) {
Arrays.fill(memory,-1);//先将memory的值初始化为-1,这样可以来判断memory中的值是不是有效的
return dfs(n);
}
int dfs(int n){
if(memory[n]!=-1){//查找备忘录中是否已经有该结果
return memory[n];
}
//备忘录中没有就先正常使用递归求解:
if(n<=1){
memory[n]=n;//先把结果记录在备忘录中
return n;
}
memory[n]=dfs(n-1)+dfs(n-2);//先把结果记录在备忘录中
return memory[n];
}
}所有的递归(暴搜、深搜),都能改成记忆化搜索吗?
- 不是的,只有在递归的过程中,出现了大量完全相同的问题时,才能用记忆化搜索的方式优化,不然盲目去使用个备忘录也没用,反而浪费了大量空间
方法三(动态规划):
代码实现:
java
//(3):动态规划
class Solution {
int[] dp=new int[31];//dp表
//dp表的状态表示:dp[i]表示第i个斐波那契数
public int fib(int n) {
dp[0]=0; dp[1]=1;//dp表的初始化
//填表:
for(int i=2;i<=n;i++){
dp[i]=dp[i-1]+dp[i-2];//使用递推公式填表
}
return dp[n];//使用dp表
}
}动态规划与记忆化搜索的联系:
- 由方法三可以看出动态规划与记忆化搜索代码实现中每一步的关系:

- 也可以从这些解题步骤中看出dp算法的关键就是dp表,整个dp算法就是围绕着dp表的设计、初始化、构建与使用来实现的
动态规划和记忆化搜索的本质(也是其共同点):
- 暴力解法(暴搜)--->对暴搜进行优化:
把已经计算过的值存起来
(可以这样理解,但不意味着做dp的题目时就是要先搞出来暴搜解法再优化,因为有些题目的暴搜解法相当复杂,而直接使用dp解法就很简单,所以解题直接使用dp即可)
二、不同路径
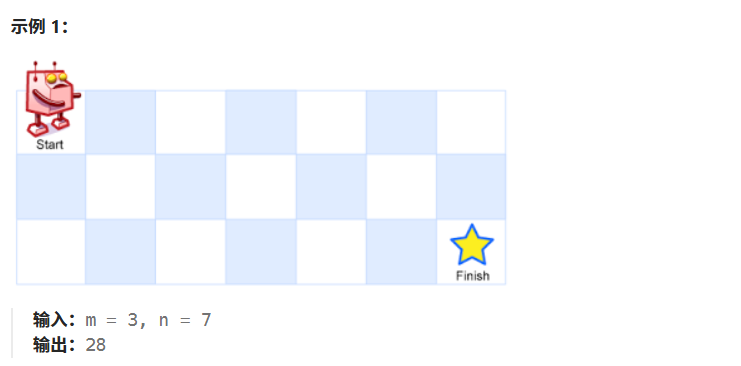
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 "Start" )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 "Finish" )。
问总共有多少条不同的路径?
解题思路
- 本题的思路也算是帮我们再次"激活"了一下递归的思想了,使用dfs做了一些深搜的题目之后基本上就会"一步一步往前走"这样的基础解题方法了,但是在本题会超时。
- 而观察到其实:
递归思路(1):从(i,j)位置走到终点的路径数=从(i,j+1)位置到终点的路径数+从(i+1,j)位置到终点的路径数,这样一来就可以改为递归算法来解题(递归思路(2):当然也可以看到:从唯一起点走到(x,y)位置有多少路径等于到(i-1,j)位置的路径数+到(i,j-1)位置的路径数,这两种思路都可以)。而且可以发现这个递推与上题斐波那契数的递推公式思路相似,只不过这个是二维的,其实数组、矩阵题目的递归解法,它们的递推公式一般都是依靠分析相邻位置作为参数时所得结果之间的关系而来的 - 改为递归解法依然会超时,但是这个时候我们已经可以对它进行记忆化搜索的优化了,因为按照第一个递归思路来的话,就会有大量的起点重复,就可以使用备忘录进行这些起点作为参数时的结果。但是直接使用dfs深搜的那种方法就没有办法进行记忆化搜索的优化,它甚至都没有返回值,而是依靠ret++来计数的。
代码实现
记忆化搜索:
java
//(1)记忆化搜索:
class Solution {
int m;
int n;
int[][] memory;//备忘录
public int uniquePaths(int _m, int _n) {
m=_m; n=_n;
memory=new int[m][n];
return dfs(0,0);//表示计算从(0,0)位置到终点的路径有多少条
}
int dfs(int i,int j){
if(i==m||j==n) return 0;//不要什么都往备忘录里面填,这个是非法坐标情况,是不予记录的
if(memory[i][j]!=0) return memory[i][j];//备忘录里记录的有,就直接用,不要再展开了
if(i==m-1&&j==n-1){//到终点了,终点--->终点的路径只有1个
memory[i][j]=1;
return memory[i][j];
}
memory[i][j]=dfs(i,j+1)+dfs(i+1,j);//先记录在备忘录里
return memory[i][j];
}
}还可以顺势改为dp解法:
- 为了使用从前往后的的dp填表顺序进行演示,我们使用递归思路(2)来解题(思路1要使用从后往前的填表顺序):
java
//(2)dp解法:
class Solution {
int m; int n;
int[][] dp;//dp表
//1.dp表状态表示:从start:(0,0)到dp[i][j]的路径数
public int uniquePaths(int _m, int _n) {
m=_m; n=_n;
dp=new int[m+1][n+1];//将dp表扩大一圈,可以免去那些麻烦的边界情况的处理,在之前前缀和章节中也是经常用到的技巧
dp[1][1]=1;//3.dp表的初始化
for(int i=1;i<m+1;i++){//4.填表顺序
for(int j=1;j<n+1;j++){
if(i==1&&j==1) continue;//该位置在初始化部分完成
dp[i][j]=dp[i][j-1]+dp[i-1][j];//2.状态转移方程
//dp表扩大一圈之后就不用担心坐标越界的问题了
}
}
return dp[m][n];//使用dp表:返回start到终点(m,n)的路径数
}
}总结
复习这两种方法的解题思路和代码注释思路优化的过程:先想到最基础的一步一步地去深搜来找到结果计数(超时)--->寻找不同坐标作为参数时所得结果之间的关系,然后由此得出递归解法(超时)--->普通递归解法改为记忆化搜索(AC)--->还可以进行dp的尝试(因为这种简单dp解法和记忆化搜索可以说是非常相似的)
三、最长递增子序列
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。
子序列 是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,3,6,2,7 是数组 0,3,1,6,2,2,7 的子序列。
示例 1:
输入:nums = 10,9,2,5,3,7,101,18
输出:4
解释:最长递增子序列是 2,3,7,101,因此长度为 4 。
解题思路
-
该题是动态规划算法中非常经典的一道题,也是本专题中最后一道:记忆化搜索改为dp的题目了
-
使用dfs解题,遍历数组,尝试寻找以不同元素为起点的最长递增子序列,然后得出这些子序列中最长的那个长度,而单独一个问题:如,找出以start为起点的最长递增子序列长度--->去start后面寻找出一个新的起点(大于start位置的元素)找出以其为起点的最长递增子序列长度(可以找到多个,取最大值),再+1(算上start位置),这就是本题的递归解法思路
-
"
以....为头/起点....然后递归剩下的部分":这是寻找递归思路常用的方法 -
而如果这样纯暴力搜索的话就又超时了,但是很明显本题的众多"起点"肯定会有重复,所以使用记忆化搜索来优化即可(后面也可以按一样的思路改为dp算法)
代码实现及解析
记忆化搜索:
java
//(1)记忆化搜索
class Solution {
int ret;
int[] memory;//备忘录
public int lengthOfLIS(int[] nums) {
memory=new int[nums.length];
for(int i=0;i<nums.length;i++){//以不同位置为起点,统计可找出的最长递增子序列
ret=Math.max(ret,dfs(nums,i));
}
return ret;
}
int dfs(int[] nums,int start){
if(memory[start]!=0) return memory[start];
int count=0;
for(int i=start+1;i<nums.length;i++){//循环将start后面的位置中最长的递增序列情况找出来
if(nums[i]>nums[start]){//当发现有个比nums[start]大的元素时就以它为起点统计其最长的递增序列
count=Math.max(count,dfs(nums,i));//找到最长的那个
}
}
memory[start]=count+1;//先将结果记录在备忘录里
return count+1;//最后再加上start本身这个位置就行了
//这个+1不要放在for循环里面,当start为最后一个元素或者start后面没有比它大的元素了,循环都不会有实际执行
}
}改为动态规划:
java
//(2)动态规划
class Solution {
int ret;
int[] dp;//dp表
//dp表状态表示:dp[i]表示以nums[i]为起点的最长的递增子序列
public int lengthOfLIS(int[] nums) {
int n=nums.length;
dp=new int[n];
Arrays.fill(dp,1);//dp表的初始化:因为dp表中的值至少为1,而下面的内层for循环不一定进得去,所以提前填上
for(int i=n-1;i>=0;i--){
for(int j=i+1;j<n;j++){//去i位置后面找dp[j]的最大值(也就是后面的最长递增序列)
if(nums[j]>nums[i]){
dp[i]=Math.max(dp[i],dp[j]+1);//按状态转移方程填表
}
}
ret=Math.max(ret,dp[i]);//每填完一个位置就尝试更新最长的子序列
}
return ret;
}
}总结
复习这两个方法的解题思路和代码注释
四、猜数字大小 II
我们正在玩一个猜数游戏,游戏规则如下:
我从 1 到 n 之间选择一个数字。
你来猜我选了哪个数字。
如果你猜到正确的数字,就会 赢得游戏 。
如果你猜错了,那么我会告诉你,我选的数字比你的 更大或者更小 ,并且你需要继续猜数。
每当你猜了数字 x 并且猜错了的时候,你需要支付金额为 x 的现金。如果你花光了钱,就会 输掉游戏 。
给你一个特定的数字 n ,返回能够 确保你获胜 的最小现金数,不管我选择那个数字 。
1 <= n <= 200
解题思路
- 我们很熟悉的猜数字游戏,之前是用该问题来讲解二分算法,但本题并不是使用二分解题,因为二分策略可以保证最小次数找到数字,但我们要按本题要求是要使用最小现金(猜了一次数字后如果不对,要给出对应钱数)找到数字
- 那其实就是我们多次猜数字,每次在对应范围内任意选择一个数,,每次选错都要给钱,这样一轮下来选了n次,要给出 X 块钱,这样的话我们就有很多种策略,最后把每种策略都尝试过后要找出花钱最少的那个(那这样的话花钱最少的策略就不一定是二分算法)
- 当然这个算法还是暴搜,要进行大量的查找,肯定超时,所以用记忆化搜索优化一下
代码实现及解析
java
class Solution {
int[][] memory;//备忘录
public int getMoneyAmount(int n) {
memory=new int[n+1][n+1];
return dfs(1,n);
}
int dfs(int left,int right){//返回猜数字范围在left~right之间时所需的最小现金数
if(left>=right) return 0;//猜数字范围到临界状态,这时不用花钱
if(memory[left][right]!=0) return memory[left][right];//先在备忘录查找
int ret=Integer.MAX_VALUE;
for(int i=left;i<=right;i++){//在该范围内选择不同的数字(代表不同的猜数字策略),看看在不同策略下分别至少需要多少钱
int x=dfs(left,i-1);//i左边范围内的最小现金数
int y=dfs(i+1,right);//i右边范围内的最小现金数
ret=Math.min(Math.max(x,y)+i,ret);//Math.max(x,y)代表左、右子树所需最小现金的较大值(因为只有这样才能保证游戏在该策略下获胜)
//而ret要取不同策略下的最小值,所以在每次for循环执行后都要更新
}
memory[left][right]=ret;
return ret;
}
}总结
复习解题思路和代码实现及解析主要是本题"左、右子树选较大值","不同策略选最小值"这样的细节不同的处理还有本题dfs的设计就是采用了"找子问题"的方法,要重视一下这样的设计思想