3. 多头注意力(MHA)有哪些局限?MQA、GQA、Flash Attention 怎么解决?
我理解 MHA 有三个核心痛点。
第一是「显存爆炸」。推理时每个 head 都要为序列里所有 token 保存自己的 K 和 V 矩阵,这就是 KV Cache。头数越多、序列越长,显存占用越夸张。一个 7B 模型跑 32K 上下文,光 KV Cache 就能吃掉十几 GB。
第二是「访存慢」。Attention 计算里 softmax 那步要把整个 N×N 的注意力矩阵搬来搬去,频繁读写 GPU 显存,瓶颈不在算力而在「内存带宽」。
第三是「N² 复杂度」。注意力分数矩阵是 N×N 的,序列翻倍计算量翻 4 倍,长上下文极其昂贵。
工业界对应了三类优化。MQA 让所有 head 共享一份 K/V,显存压到 1/H,但表达力损失明显。GQA 是折中方案:把 H 个 head 分成 G 组,每组共享一份 K/V,效果接近 MHA 但显存接近 MQA,Llama 2 70B、Llama 3、Qwen 2/3 的不少主力模型都用这个思路。Flash Attention 是另一条思路,不改变 MHA 的结构,而是从计算实现层面把 N×N 的注意力矩阵切成小块、用 GPU 片上缓存做在线 softmax,避免反复读写大矩阵,显存从 O(N²) 降到 O(N),速度还更快。
最关键的认知是:MQA/GQA 是「结构层」的优化,Flash Attention 是「实现层」的优化,两者是叠加关系不冲突,现在的主流模型基本上都是 GQA + Flash Attention 一起用。
回到开头那段对话,被怼三次后再回答这个问题,最重要的是先把 MHA 的三个痛点讲清楚,因为这是整道题的地基。
讲三个痛点的时候可以这样组织:显存上 KV Cache 随头数和序列线性增长,长上下文场景一下就吃光显存;访存上 Attention 计算反复读写 HBM 大矩阵,瓶颈不在算力在带宽;复杂度上注意力矩阵是 N×N,序列翻倍计算量翻 4 倍。这三个痛点是连在一起的,长上下文场景下尤其明显,也是后面所有优化的出发点。
讲完痛点之后,把三类优化方案各自的位置讲清。MQA 是暴力共享 K/V,显存压到 1/H 但表达力有损失;GQA 是分组折中(Llama 2 70B、Llama 3、Qwen 2/3 的不少主力模型都用),显存接近 MQA 但效果接近 MHA,是甜蜜点;Flash Attention 走另一条赛道,不改 Attention 结构,从计算实现层面用「分块 + 在线 softmax」把显存从 O(N²) 降到 O(N),速度还快 2-4 倍。
最关键的一句话是:这三类优化是叠加不是替代。结构层(GQA)和实现层(Flash Attention)攻击的痛点不同,主流大模型都是 GQA + Flash Attention 同时用。能说出这句话,面试官就知道你不是在背单点,而是真的理解了这套优化体系的层次结构。
如果还想再加分,可以提一句 MLA(DeepSeek 用的低秩潜在注意力)作为更前沿的方向,让面试官知道你跟得上技术节奏。
5. 什么是大模型项目的分词器?原理是什么?
我觉得面试被问到 Tokenizer,最重要的是先说清楚「为什么需要它」,模型只能处理整数,不认识字符串,Tokenizer 就是把文字转成数字 ID 序列的桥梁。至于原理,主流路线都是子词分词,常见实现有 BPE、SentencePiece / Unigram、WordPiece 等。BPE 的直觉是从小单元出发,反复把出现频率最高的相邻片段合并成新 token,最终形成一个几万到十几万规模的词汇表,既能控制大小又能处理新词。实际开发里要注意的是:API 按 token 计费而不是按字数,1000 个汉字大概对应 1000-1500 个 token,但具体比例和模型 tokenizer 强相关,估算成本和上下文窗口用量都要用真实 tokenizer 来算。
回到开头那段对话,问到 Tokenizer,最重要的是先讲清楚「为什么需要它」。模型只能处理整数,不认识字符串,Tokenizer 就是连接人类文字和模型整数世界的桥梁。这一句铺垫先讲到,面试官就知道你抓到了本质。
接下来讲清三种分词粒度的取舍。字符级太碎(序列太长、语义信息少),词级太散(OOV 严重、词汇表爆炸),BPE 取了中间的子词级折中,既控制词汇表又能处理新词。这是子词分词的核心动机。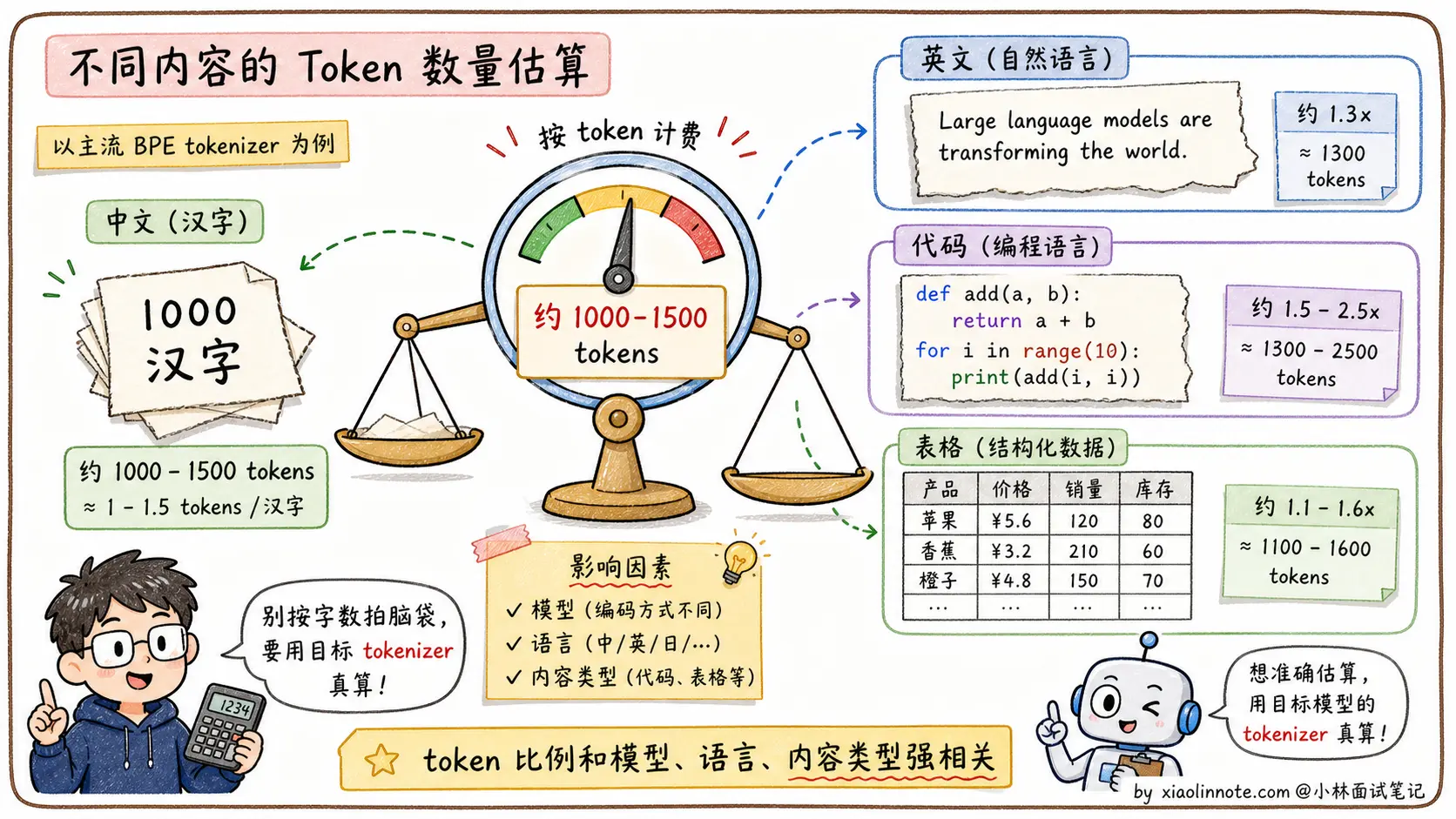
讲 BPE 原理时,把「初始化基础词汇表 → 反复合并最高频 pair → 直到词汇表达到预设大小」这个三步流程讲清楚就行。同时补一句:BPE 只是子词分词的一种,SentencePiece / Unigram、WordPiece 也很常见。能举一个「lowest123 被切成 low + est + 1 + 2 + 3,没有 OOV」的例子,比纯讲算法生动得多。
最关键的是带出实际工程影响:API 按 token 计费、1000 汉字 ≈ 1000-1500 tokens、上下文窗口管理、避免截断。这些都是面试官最爱听的「真的做过项目」的工程细节。
如果还想再加分,可以提一句特殊 token 的作用(BOS、EOS、PAD、SEP,以及 ChatML 格式里的 <|im_start|>),让面试官知道你不只懂分词算法,还懂模型对话格式背后的工程细节。能讲到这一层,这道题就答得很完整了。