
一、DFlash 是什么?
DFlash 是一种推测解码(Speculative Decoding)加速框架 ,由 Z Lab 在 2026 年 2 月提出。它的核心创新是:用块扩散模型(Block Diffusion Model)替代传统的自回归草稿模型。
一句话概括
DFlash = 目标大模型(自回归,负责验证)+ 块扩散草稿模型(并行,负责快速生成草稿)
二、为什么要做 DFlash?
现有方法的问题
推测解码的核心思路是:用小模型快速生成候选 token,大模型并行验证。但现有方法(包括 SOTA 的 EAGLE-3)都有一个共同瓶颈:草稿模型本身也是自回归的。
EAGLE-3 生成 8 个草稿 token:
Step 1: 输入 → 生成 "help"
Step 2: 输入 + "help" → 生成 "you"
Step 3: 输入 + "help" + "you" → 生成 "?"
...
Step 8: 生成第 8 个 token
→ 需要 8 次前向传播
→ 草稿延迟随 token 数线性增长这导致两个后果:
-
草稿模型必须很浅(通常 1 层),否则延迟太高
-
加速比天花板低(通常 2-3x),因为草稿生成本身就成了瓶颈
DFlash 的解决思路
扩散模型(Diffusion Model)擅长并行生成。DFlash 的想法是:如果草稿模型能一次性并行生成整个 token 块,就能打破串行瓶颈。
三、DFlash 的核心架构
DFlash 系统由两大部分组成:
3.1 目标模型(Target LLM)
-
原始大模型(如 Qwen3-8B、LLaMA-3.1-8B)
-
推理时完全冻结,只负责验证
-
同时提供多层隐藏状态给草稿模型作为上下文
3.2 块扩散草稿模型(Block Diffusion Draft)
-
5 层 Transformer(比 EAGLE-3 更深)
-
单次前向传播并行生成 16 个 token
-
使用双向注意力(块内 token 互相可见)
-
通过KV 注入机制接收目标模型的特征
四、关键技术详解
4.1 块扩散生成(核心创新)
自回归 vs 块扩散
| 维度 | 自回归(EAGLE-3) | 块扩散(DFlash) |
|---|---|---|
| 生成方式 | 逐个 token 串行生成 | 整个块一次性并行生成 |
| 前向传播次数 | K 次(K = 块大小) | 1 次 |
| 注意力 | 因果注意力(只能看前面) | 双向注意力(块内互相看) |
| 延迟与块大小关系 | 线性增长 | 基本无关 |
块扩散具体怎么做?
输入: [mask, mask, mask, ..., mask] (16 个 mask token)
↓
块扩散模型(5 层 Transformer)
第 1 层: 双向注意力处理所有 mask
第 2 层: 继续去噪
...
第 5 层: 输出预测
↓
输出: [t1, t2, t3, ..., t16] (16 个草稿 token,一次产出)关键 :块内所有位置是同时预测的,不需要等前面 token 生成完。
为什么双向注意力能实现并行预测?
因为所有 mask 位置同时计算,互相参考,不需要等前面 mask 的结果。
块扩散模型的注意力掩码(关键!):
g_how g_can g_I anchor m1 m2 m3 ... m16
g_how [ 1 1 1 1 1 1 1 ... 1 ]
g_can [ 1 1 1 1 1 1 1 ... 1 ]
g_I [ 1 1 1 1 1 1 1 ... 1 ]
anchor [ 1 1 1 1 1 1 1 ... 1 ]
m1 [ 1 1 1 1 1 1 1 ... 1 ] ← 双向!
m2 [ 1 1 1 1 1 1 1 ... 1 ]
... ...
m16 [ 1 1 1 1 1 1 1 ... 1 ]
规则:
• 前缀部分(g_t + anchor):标准因果注意力
• mask 块内部:双向注意力(所有 mask 互相可见)
• mask 块之间:禁止跨块注意力去噪过程(DFlash 简化为单步)
标准扩散模型需要多步去噪,但 DFlash 为了速度极度简化:
标准扩散: mask → 噪声 → 去噪步1 → 去噪步2 → ... → 最终token
DFlash: mask → 直接预测(单步去噪)
→ 牺牲一点质量,换取极致速度
→ 因为后面还有目标模型验证,所以可以接受4.2 KV 注入机制(第二个关键创新)
为什么需要这个?
扩散模型单独使用时,生成质量通常不如自回归模型。DFlash 的解决方法是:让草稿模型"读取"目标模型的内部特征。
EAGLE-3 的做法(对比)
EAGLE-3 把目标模型特征和 token embedding 拼接,只在第一层输入:
EAGLE-3:
Layer 1: 输入 [g_t + e_t] ← 有目标特征
Layer 2: 来自 Layer 1 的输出 ← 特征开始稀释
Layer 3: 进一步稀释...
→ 增加层数反而效果变差DFlash 的做法(改进)
DFlash 将融合特征 注入每一层的 KV Cache:
DFlash:
Layer 1: KV Cache 里有 g_t
Layer 2: KV Cache 里有 g_t
Layer 3: KV Cache 里有 g_t
Layer 4: KV Cache 里有 g_t
Layer 5: KV Cache 里有 g_t
→ 每层都能"看到"目标模型的思考过程
→ 增加层数 → 表达力增强 → 草稿质量提升具体注入方式:
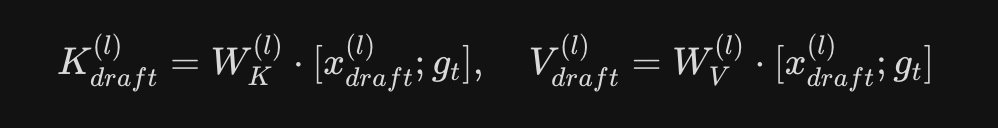
4.3 多层特征融合
与 EAGLE-3 类似,DFlash 也从目标模型提取多层隐藏状态:
从目标模型 32 层中提取 5 层:
Layer 2, Layer 8, Layer 16, Layer 24, Layer 29
拼接后降维:
[h_2 ⊕ h_8 ⊕ h_16 ⊕ h_24 ⊕ h_29] → FC → g_t (4096维)DFlash 提取 5 层(EAGLE-3 只提取 3 层),信息更丰富。
五、训练过程详解
5.1 训练数据
-
约 800K 样本(对话 + 代码数据)
-
关键:用目标模型生成回复作为标签(而非原始数据)
5.2 训练关键设计
1. 随机锚点采样
标准块扩散:均匀分块,随机 mask
DFlash:随机选锚点 token 作为块起点,mask 后面位置
→ 匹配推理时的真实情况(草稿基于目标模型的 bonus token 生成)2. 损失加权
块内位置越靠前,权重越高(因为前面错了后面全错):
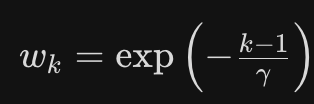
3. 共享组件
-
复用目标模型的 Embedding 层(冻结)
-
复用目标模型的 LM Head(冻结)
-
只训练块扩散的 Transformer 层
六、推理流程详解
Step 1: 目标模型生成第一个 token
└── 同时提取多层特征 → 融合为 g_t
Step 2: 块扩散草稿生成
└── 输入: g_t + [mask, mask, ..., mask] (16个)
└── 单次前向传播
└── 输出: [t1, t2, ..., t16] (16个草稿token)
Step 3: 目标模型并行验证
└── 一次前向传播验证 16 个 token
└── 逐个接受/拒绝
└── 拒绝处重采样
Step 4: 循环
└── 回到 Step 2,基于新验证序列继续七、关键答疑点
Q1: DFlash 的草稿模型如何一次性输出多个 token?
答 :通过在输入中插入 mask token ,使用双向注意力让所有 mask 位置同时计算、互相参考,经过 5 层 Transformer 后一次性并行输出整个 token 块。
输入: [g, g, g, anchor, mask, mask, ..., mask]
↓
双向注意力(块内所有 mask 互相可见)
↓
输出: [g, g, g, anchor, t1, t2, ..., t16]Q2: 训练时块大小是固定的吗?
答 :是的,训练时块大小(如 16)是超参数,训练前固定。模型只学习预测固定数量的 mask token。
训练时:
块大小 = 16(固定)
输入: [g, g, g, anchor, mask×16]
标签: [t1, t2, ..., t16](16个token)但推理时可以灵活调整:
| 推理块大小 | 效果 |
|---|---|
| 16 | 最佳匹配,质量最高 |
| 8 | 可以工作,质量稍降(相当于"提前停止") |
| 4 | 可以工作,质量进一步下降 |
| 32 | 效果不好(训练时没见过这么大的块) |
关键发现:训练时用大 block(16),推理时可以根据负载灵活调小,效果仍然很好。
Q3: 为什么 5 层模型比 EAGLE-3 的 1 层还快?
答:因为并行度更高:
EAGLE-3 (1层, 16个token):
16 次前向传播 × 小批量 = GPU 利用率低
DFlash (5层, 16个token):
1 次前向传播 × 大批量(16个位置并行) = GPU 利用率高
→ 虽然层数多,但并行度更高,总延迟更低Q4: mask token 是什么?
答 :mask token 是一个特殊的占位符,类似于 BERT 的 [MASK]:
mask token 的 embedding = 可学习的特殊向量
初始时代表"未知"
经过扩散模型的去噪后,变成具体的 token 预测Q5: 模型怎么知道每个 mask 该输出什么?
答:通过上下文学习。模型看到:
-
前缀上下文(g_t)
-
锚点 token(anchor)
-
其他 mask 位置的中间表示
然后通过多层 Transformer 的交互,每个位置"协商"出自己该是什么 token。
八、性能表现
| 模型 | 任务 | DFlash 加速比 | EAGLE-3 加速比 | 提升 |
|---|---|---|---|---|
| Qwen3-8B | GSM8K | 5.15x | 2.23x | 2.3x |
| Qwen3-8B | MATH-500 | 6.08x | 2.05x | 3.0x |
| Qwen3-8B | HumanEval | 5.14x | 2.17x | 2.4x |
| Qwen3-8B | MT-Bench | 2.75x | 1.63x | 1.7x |
核心优势:
-
比 EAGLE-3 快 2.5x
-
单次生成 16 个 token 的延迟比 EAGLE-3 生成 8 个还低
-
接受率高达 89%+
九、深度对比:DFlash vs EAGLE-3 vs MTP
| 维度 | DFlash | EAGLE-3 | MTP |
|---|---|---|---|
| 本质定位 | 推测解码框架(块扩散草稿) | 推测解码框架(自回归草稿) | 训练目标/辅助任务(多token预测头) |
| 核心目标 | 推理加速(无损) | 推理加速(无损) | 提升模型质量 + 辅助加速 |
| 训练阶段 | 后训练(Post-hoc) 目标模型冻结 | 后训练(Post-hoc) 目标模型冻结 | 联合训练(Co-training) 与主模型同时训练 |
| 草稿模型 | 独立块扩散模型 5层Transformer | 独立自回归模型 1-4层Transformer | 无独立草稿模型 主模型+多个预测头 |
| 生成方式 | 单次前向传播 并行生成整个块 | K次串行前向传播 逐个生成token | 单次前向传播 并行输出多个头 |
| 特征注入 | KV注入每层 接受率随深度提升 | 第一层输入 深度增加特征稀释 | 仅顶层隐藏状态 无深度注入 |
| 注意力 | 双向注意力 (块内互相可见) | 因果注意力 (只能看前面) | 因果注意力 (主模型标准结构) |
| 训练数据 | 需额外数据 (~800K样本) | 需额外数据 (ShareGPT等) | 无需额外数据 使用预训练数据 |
| 是否影响主模型 | 不影响 (主模型完全冻结) | 不影响 (主模型完全冻结) | 影响 (联合优化主模型) |
| 接受率 | ~89%+ | ~75-85% | ~60-75% |
| 加速比 | 3x-6.5x | 3x-5.5x | 1.5-2x |
| 适用场景 | 已有模型加速 追求极致加速 | 已有模型加速 高质量推理 | 从头训练新模型 资源受限部署 |
核心差异总结
DFlash = 独立块扩散草稿 + KV深度注入 + 并行生成
→ 草稿生成最快,加速比最高
EAGLE-3 = 独立自回归草稿 + 浅层特征输入 + 串行生成
→ 草稿质量高,但受限于串行瓶颈
MTP = 内置预测头 + 联合训练 + 有限加速
→ 训练一体化,但加速效果有限十、总结
DFlash 代表了推测解码领域的范式转变:
-
从自回归到块扩散:用并行生成打破串行瓶颈
-
从浅层到深层:KV 注入使接受率随模型深度持续提升
-
从特征约束到自由表达:扩散模型的双向注意力释放表达能力
它将扩散模型的并行生成优势与自回归模型的高质量验证完美结合,实现了 6x+ 无损加速,且已集成到 vLLM、SGLang、MLX 等主流推理框架中,具备生产部署能力。