集成学习与 AdaBoost 学习笔记
初学集成学习常会卡在 AdaBoost 权重更新、强弱分类器融合等难点,翻阅吕欣老师《数据挖掘》后豁然开朗。书本立足学习者认知规律,先铺垫集成学习基础思想,再循序渐进详解 AdaBoost 推导逻辑,难点分步拆解、辅以通俗说明,避开繁杂冗余内容,无论是课程配套学习,还是自主钻研集成算法,都是可读性很强的工具书。
在线学习开源代码:https://github.com/XL-lab-bigdata/DataMining
一、为什么需要集成学习
在实际机器学习任务中,单一模型往往存在如下问题:
- 对训练数据过拟合或欠拟合
- 对噪声较敏感
- 泛化能力有限
即使是性能较好的模型,在复杂数据场景下也难以长期保持稳定效果。
因此,一个自然的想法是:
能否将多个模型组合起来,使整体性能优于任何一个单独模型?
集成学习正是基于这一思想发展而来,其目标是通过多个模型之间的协同工作,提升预测精度与稳定性。
二、集成学习的基本框架
从整体思路上看,集成学习通常包含三个核心要素:
- 基学习器:若干个性能尚可的模型
- 差异性来源:保证模型之间存在差别
- 融合策略:将多个模型结果进行组合
1. 基学习器
基学习器可以是:
- 决策树
- 线性模型
- 支持向量机
- 神经网络
在多数集成算法中,决策树由于结构简单、训练速度快,常被作为默认基模型。
2. 模型多样性的来源
多样性主要通过以下方式获得:
- 数据层面的随机性(不同训练子集)
- 特征层面的随机性(随机选特征)
- 参数层面的随机性
多样性越高,集成模型往往越有效。
3. 集成学习的两条主线
从训练方式上,集成学习可以分为两大类:
(1)Bagging(并行式集成)
- 各基模型相互独立训练
- 重点在于降低方差
- 典型算法:随机森林
(2)Boosting(串行式集成)
- 模型按顺序训练
- 后续模型重点关注前序模型的错误
- 典型算法:AdaBoost、GBDT、XGBoost
三、Bagging代表:随机森林的直观理解
随机森林通过:
- Bootstrap 抽样生成多个数据子集
- 在每棵树中随机选择部分特征
- 对多棵树的预测结果进行投票或平均
实现"多棵树共同决策"。
其核心优势在于:
- 降低过拟合风险
- 提升泛化能力
- 对异常值相对鲁棒
随机森林的成功也进一步说明:
多个弱模型的组合,可以胜过单一强模型。
这一思想为理解 Boosting 奠定基础。
四、从 Bagging 到 Boosting 的转变
Bagging 主要解决的是"模型不稳定"问题,而 Boosting 更关注:
如何逐步减少模型的偏差
Boosting 不再让模型彼此独立,而是:
- 每一轮模型都建立在前一轮基础之上
- 重点处理之前分类错误的样本
具体而言:
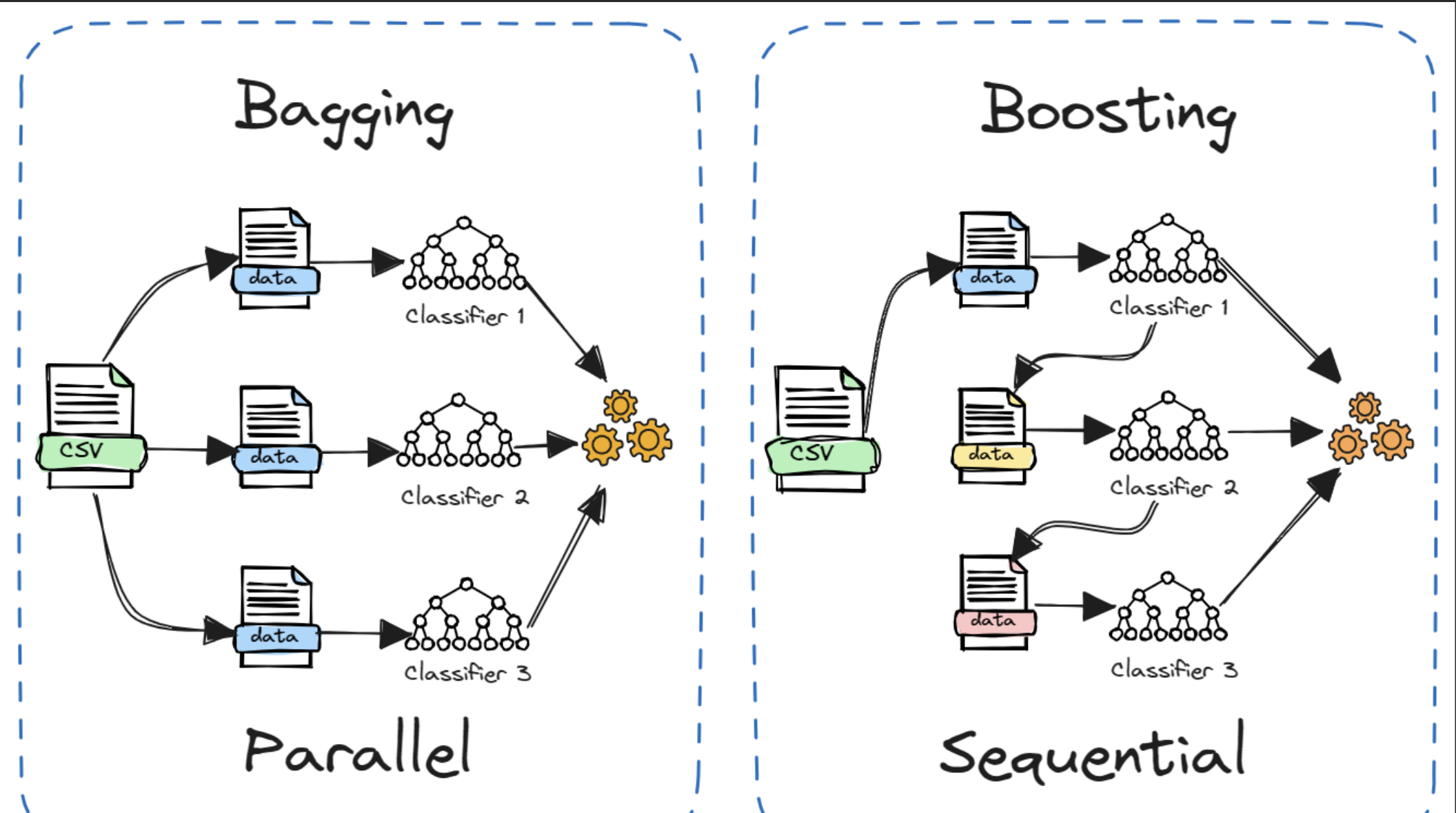
这张图通过可视化形式,清晰区分了集成学习中两类经典算法的核心逻辑:
左侧:Bagging(以随机森林为代表)
- 训练模式 :并行(Parallel)
从原始数据集(绿色CSV文件)中,通过抽样生成多个独立的子数据集,每个子集对应训练一个分类器(如决策树),所有分类器同步训练、互不影响。 - 核心特点 :
各分类器"独立平等",最终结果由所有分类器的输出(投票/均值)决定,目标是降低单模型的方差(减少过拟合,提升泛化能力)。
右侧:Boosting(以AdaBoost为代表)
- 训练模式 :串行(Sequential)
从原始数据集出发,先训练第1个分类器;根据其错误结果调整样本权重(错误样本权重升高),生成新的数据集后训练第2个分类器;依此迭代,后续分类器会"针对性学习"前序模型的错误。 - 核心特点 :
分类器之间存在"依赖关系",最终结果由各分类器的输出加权融合 (错误率低的分类器权重更高),目标是降低单模型的偏差(提升模型的拟合能力)。
两类算法核心差异对比
| 维度 | Bagging | Boosting |
|---|---|---|
| 训练方式 | 并行(各模型独立) | 串行(依赖前序结果) |
| 样本处理 | 随机抽样生成独立子集 | 动态调整样本权重 |
| 集成策略 | 平权投票/平均 | 加权融合(优模型权重高) |
| 核心目标 | 降低方差(抗过拟合) | 降低偏差(提准确率) |
| 代表算法 | 随机森林 | AdaBoost、GBDT |
AdaBoost 是 Boosting 思想中最经典的实现之一。
五、AdaBoost 的核心思想
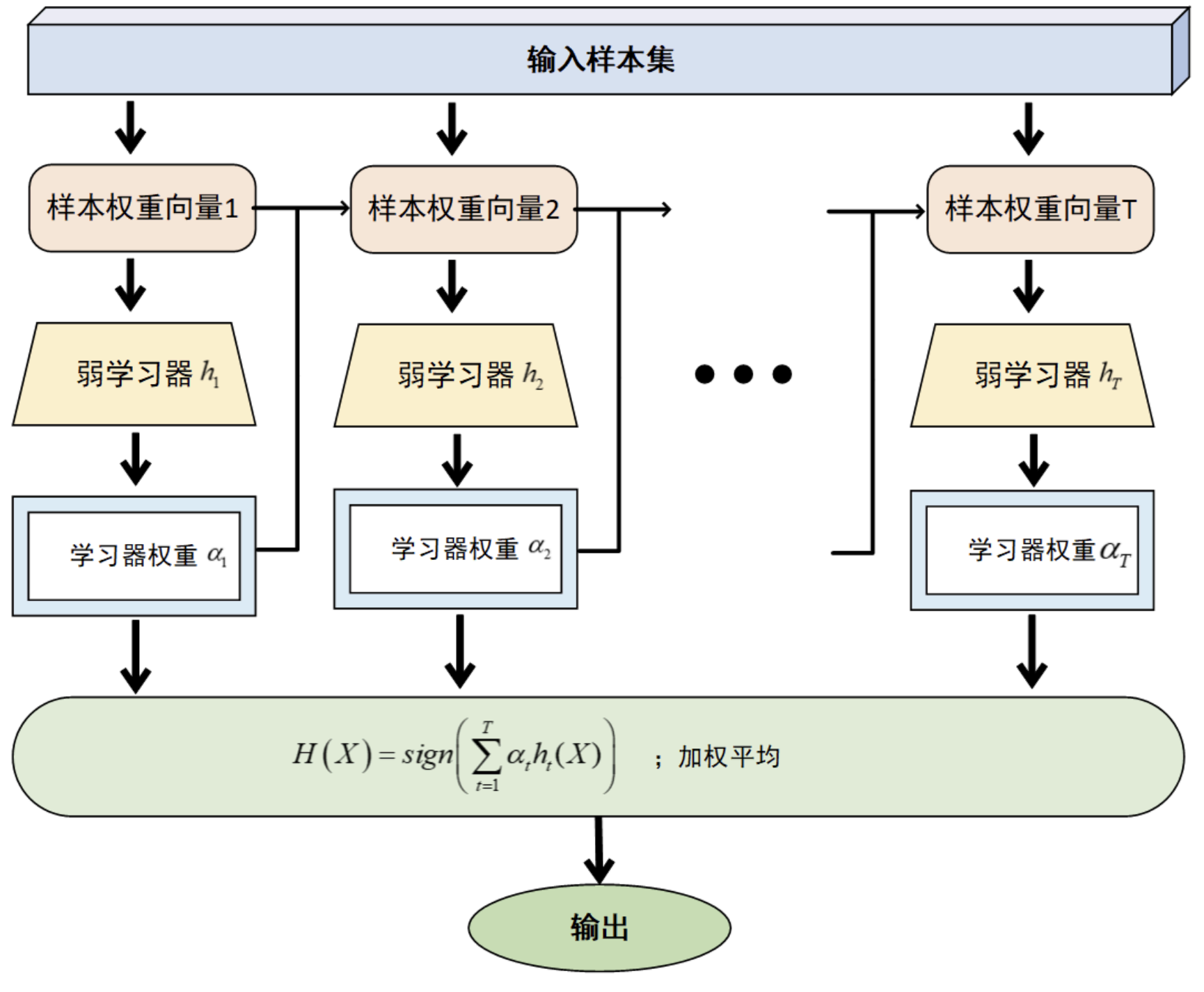
1、流程总览
输入样本集后,AdaBoost通过**"样本加权→训练弱学习器→计算学习器权重"的循环,迭代训练TTT个弱学习器,最终通过加权融合(所有弱学习器×对应权重后求和)**得到最终模型。
2、核心逻辑1:样本加权(图中"样本权重向量"部分)
- 初始状态:所有样本的权重相同(比如都为1N\frac{1}{N}N1,NNN是样本数);
- 每轮训练后:
- 被当前弱学习器分类错误的样本 ,权重会升高;
- 被分类正确的样本,权重会降低;
- 作用:让后续的弱学习器更"聚焦"于前一轮难以分类的样本(权重高的样本)。
3、核心逻辑2:模型加权(图中"学习器权重α\alphaα"部分)
这里的"学习器权重α\alphaα"就是你说的"模型权重",二者完全等价:
- 每个弱学习器(图中的h1、h2...hTh_1、h_2...h_Th1、h2...hT)训练完成后,会根据自身的错误率 计算对应的权重α\alphaα;
- 规则:错误率越低的弱学习器,α\alphaα(模型权重)越大;错误率越高,α\alphaα越小;
- 作用:让"表现更好"的弱学习器在最终模型中拥有更高的话语权。
4、最终输出
所有弱学习器的预测结果,会按照各自的权重α\alphaα进行加权求和,再通过sigmoid函数(图中signsignsign)得到最终分类结果,公式对应图底部的:
H(X)=sign(∑t=1Tαtht(X))H(X) = sign\left(\sum_{t=1}^{T}\alpha_t h_t(X)\right)H(X)=sign(t=1∑Tαtht(X))
六、AdaBoost 的训练流程
- 初始化样本权重
- 训练一个弱分类器
- 计算该分类器的错误率
- 根据错误率计算模型权重
- 更新样本权重分布
- 重复以上步骤
- 将所有弱分类器进行加权融合
可以理解为: 不断纠错、不断修正的过程。
七、AdaBoost 的数学表达
-
错误率:
em=∑i=1Nwiyi≠gm(xi)e_m = \sum_{i=1}^{N} w_i y_i \\neq g_m(x_i)em=i=1∑Nwiyi=gm(xi)
-
分类器权重:
αm=12ln(1−emem)\alpha_m = \frac{1}{2} \ln\left(\frac{1-e_m}{e_m}\right)αm=21ln(em1−em)
-
最终模型:
G(x)=sign(∑m=1Mαmgm(x))G(x) = \text{sign}\left(\sum_{m=1}^{M} \alpha_m g_m(x)\right)G(x)=sign(m=1∑Mαmgm(x))
这些公式体现了:
错误率越低 → 权重越大。
八、AdaBoost 的优势与不足
优势
- 能显著提升弱分类器性能
- 适用于高维数据
- 对小样本任务友好
- 参数相对较少
不足
- 对噪声和异常值敏感
- 训练时间随迭代次数增加
- 可解释性较弱
九、AdaBoost 的参数理解
1. n_estimators
- 弱分类器数量
- 过小:欠拟合
- 过大:计算成本高,可能过拟合
2. learning_rate
- 控制每个弱分类器的影响程度
- 学习率小 → 需要更多弱分类器
- 学习率大 → 易出现波动
实际应用中通常需要联合调节。
十、AdaBoost 的应用示例
场景:基于 AdaBoost 的医疗辅助诊断(疾病风险预测)
以「糖尿病风险预测」为例(公开数据集:Pima Indians Diabetes Dataset),通过患者的生理指标(如血糖、BMI、胰岛素水平等)预测是否患糖尿病,对比单决策树与 AdaBoost 的效果差异。
1. 实战代码
python
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import accuracy_score, recall_score, confusion_matrix
import warnings
warnings.filterwarnings('ignore')
# 1. 加载数据集(UCI公开糖尿病数据集)
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"
columns = ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness',
'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome']
df = pd.read_csv(url, names=columns)
# 2. 数据预处理(处理缺失值、标准化)
# 替换0值(生理指标不可能为0)为列均值
df[['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI']] = df[['Glucose', 'BloodPressure',
'SkinThickness', 'Insulin', 'BMI']].replace(0, np.nan)
df.fillna(df.mean(), inplace=True)
# 划分特征与标签、训练集与测试集
X = df.drop('Outcome', axis=1)
y = df['Outcome']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
# 标准化特征
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 3. 训练单决策树模型(弱分类器基准)
dt_model = DecisionTreeClassifier(max_depth=1, random_state=42) # 限制深度为1,模拟弱分类器
dt_model.fit(X_train_scaled, y_train)
dt_pred = dt_model.predict(X_test_scaled)
# 4. 训练AdaBoost模型(兼容scikit-learn新旧版本)
# 先检测scikit-learn版本,自动适配参数名
import sklearn
sklearn_version = sklearn.__version__
print(f"当前scikit-learn版本: {sklearn_version}")
if float(sklearn_version.split('.')[1]) >= 2: # 1.2及以上版本用estimator
ada_model = AdaBoostClassifier(
estimator=DecisionTreeClassifier(max_depth=1), # 替换base_estimator为estimator
n_estimators=50,
learning_rate=0.1,
random_state=42
)
else: # 1.2以下版本用base_estimator
ada_model = AdaBoostClassifier(
base_estimator=DecisionTreeClassifier(max_depth=1),
n_estimators=50,
learning_rate=0.1,
random_state=42
)
ada_model.fit(X_train_scaled, y_train)
ada_pred = ada_model.predict(X_test_scaled)
# 5. 模型评估(对比准确率、召回率)
def evaluate_model(y_true, y_pred, model_name):
acc = accuracy_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
cm = confusion_matrix(y_true, y_pred)
print(f"===== {model_name} 评估结果 =====")
print(f"准确率: {acc:.4f}")
print(f"召回率(糖尿病识别率): {recall:.4f}")
print(f"混淆矩阵:\n{cm}\n")
# 输出评估结果
evaluate_model(y_test, dt_pred, "单决策树(弱分类器)")
evaluate_model(y_test, ada_pred, "AdaBoost集成模型")2. 输出结果
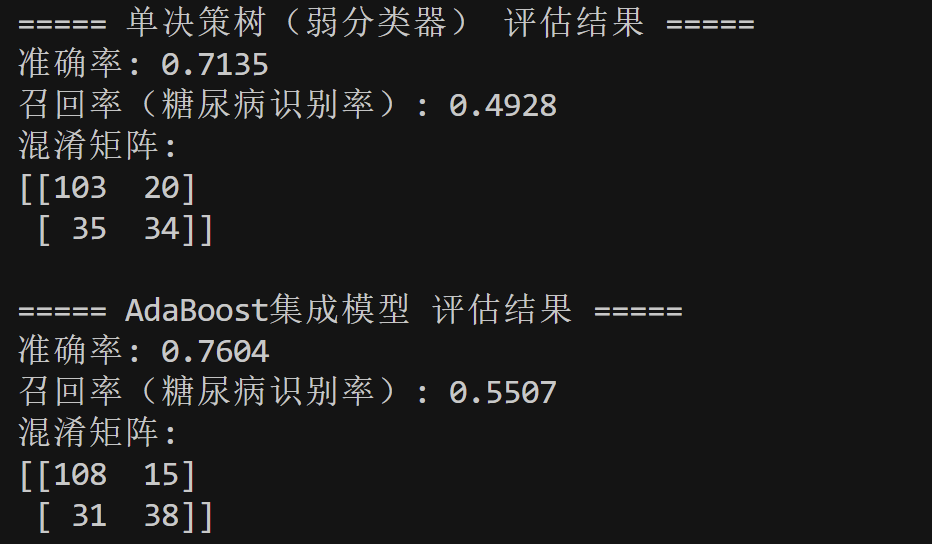
结果解读
- 单决策树(弱分类器):准确率71.35%,糖尿病识别召回率49.28%(漏诊较多);
- AdaBoost集成模型:准确率提升至76.04%,召回率升至55.07%(漏诊减少);
- 核心结论:AdaBoost集成后,模型准确率与疾病识别能力均有明显提升。
十一、与其他 Boosting 方法的关系
- GBDT:基于残差拟合
- XGBoost:在 GBDT 基础上加入正则化与二阶信息
- AdaBoost:基于样本权重调整
它们本质上都遵循:
逐步优化模型的思想
十二、学习总结
通过学习集成学习与 AdaBoost,可以得到以下体会:
- 提升模型性能不一定依赖复杂结构
- 合理组合多个简单模型同样有效
- Boosting 的核心在于"关注错误并修正错误"
AdaBoost 作为 Boosting 家族的基础算法,为后续理解 GBDT、XGBoost 等方法提供了重要理论起点。
笔记来源:冯同学
均有明显提升。
十一、与其他 Boosting 方法的关系
- GBDT:基于残差拟合
- XGBoost:在 GBDT 基础上加入正则化与二阶信息
- AdaBoost:基于样本权重调整
它们本质上都遵循:
逐步优化模型的思想
十二、学习总结
通过学习集成学习与 AdaBoost,可以得到以下体会:
- 提升模型性能不一定依赖复杂结构
- 合理组合多个简单模型同样有效
- Boosting 的核心在于"关注错误并修正错误"
AdaBoost 作为 Boosting 家族的基础算法,为后续理解 GBDT、XGBoost 等方法提供了重要理论起点。
笔记来源:冯同学