【RISC-V】RVV选摘
文章目录
- 【RISC-V】RVV选摘
-
- 1、SIMD
- 2、RVV参数
- 3、RVV寄存器
- [4、intrinsic 编程](#4、intrinsic 编程)
- 5、RVV指令------load&store
-
- [1、RVV load & store加载存储指令](#1、RVV load & store加载存储指令)
-
- 1.1**单位步长的load&store**
- 1.2**跨步长的load&store**
- [1.3**按索引的load & store**](#1.3按索引的load & store)
- [2、RVV segment load & store(自动拆包/打包的加载和存储)](#2、RVV segment load & store(自动拆包/打包的加载和存储))
-
- [2.1单位步长的Sgement load&store](#2.1单位步长的Sgement load&store)
-
- [2.2跨步长的Sgement load&store](#2.2跨步长的Sgement load&store)
- [2.3按索引的Sgement load & store](#2.3按索引的Sgement load & store)
- [3、RVV Load/Store Whole Register搬运整个寄存器](#3、RVV Load/Store Whole Register搬运整个寄存器)
- 4、首次(遇到)异常**(就停止)**的加载指令
- 6、RVV指令------整数算术指令
-
- [6.1 向量整数加减](#6.1 向量整数加减)
- [6.2 向量整数扩宽/缩减](#6.2 向量整数扩宽/缩减)
- [6.3 向量整数逻辑操作](#6.3 向量整数逻辑操作)
- [6.4 向量整数移位](#6.4 向量整数移位)
- [6.5 向量整数比较](#6.5 向量整数比较)
- [6.6 向量逐元素比较并选取极值指令](#6.6 向量逐元素比较并选取极值指令)
- [6.7 向量整数乘除法指令](#6.7 向量整数乘除法指令)
- [6.8 向量 整数合并](#6.8 向量 整数合并)
- [7 定点数算术指令](#7 定点数算术指令)
-
- [7.2 单宽度向量平均加减](#7.2 单宽度向量平均加减)
- [7.3 单宽度向量饱和乘法](#7.3 单宽度向量饱和乘法)
- [7.4 单宽度向量缩放移位指令](#7.4 单宽度向量缩放移位指令)
- [7.5 **窄化裁剪移位指令**](#7.5 窄化裁剪移位指令)
- 8、浮点数指令
-
- [8.1 浮点数加减](#8.1 浮点数加减)
- [8.2 浮点数乘除](#8.2 浮点数乘除)
- [8.3 浮点数乘加](#8.3 浮点数乘加)
- 8.4向量浮点平方根、浮点倒数平方根、浮点倒数
- [8.5 向量浮点最小最大](#8.5 向量浮点最小最大)
- [8.6 向量浮点符号注入指令](#8.6 向量浮点符号注入指令)
- [8.7 浮点数比较](#8.7 浮点数比较)
- [8.8 向量浮点分类](#8.8 向量浮点分类)
- 8.9向量浮点合并
- 8.10单宽度浮点和整数类型相互转换
- [9、归约指令(**Reduction 指令**)](#9、归约指令(Reduction 指令))
- 10、掩码指令
-
- 10.1逻辑操作
- [10.2 统计掩码寄存器中处于活跃状态数据元素的数量指令](#10.2 统计掩码寄存器中处于活跃状态数据元素的数量指令)
- [10.3 **查找掩码中第一个活跃元素位置的指令**](#10.3 查找掩码中第一个活跃元素位置的指令)
- [10.4 将寄存器中第一个1(之前)(的所有)bit置1,后面置0指令](#10.4 将寄存器中第一个1(之前)(的所有)bit置1,后面置0指令)
- [10.5 计算源操作数所存储的bit的前缀和](#10.5 计算源操作数所存储的bit的前缀和)
- [10.6 索引写入寄存器](#10.6 索引写入寄存器)
- 11、排列指令
1、SIMD
比如一个向量有4个元素{a, b, c, d}, 另一个向量也有4个元素{e, f, d, h},它们做向量加法,普通标量(SISD)的做法如做下图所示,需要4次add指令,而SIMD 的做法如右图所示,一次加法指令便完成了4个元素的加法,所以理论上SIMD比SISD要快。
SISD的做法:
c
for (int i = 0; i < N; i++) {
C[i] = A[i] + B[i];
}SIMD的做法:
c
for (int i = 0; i < N; i+=4) {
vec4 A_tmp = load4(A + i); // Loads 4 integers into a SIMD register A_tmp
vec4 B_tmp = load4(B + i);
vec4 C_tmp = add4(A_tmp, B_tmp); // Adds together vectors of four integers
store4(C_tmp, C + i); // Stores four integers
}2、RVV参数
VLEN:向量寄存器文件(Vector Register File)的单寄存器位宽 。 RISC-V 向量扩展通常有 32 个向量寄存器(v0-v31)。VLEN 定义了其中每一个寄存器有多少个比特位。它是硬件设计时就固定的物理属性(如 128、256、512 bits)。可以通过读取 vlenb 寄存器(VLEN/8)来获取这个硬件参数。
ELEN: 向量执行单元(Vector Execution Units)支持的最大数据通路位宽 。,它代表了硬件内部运算逻辑(如加法器、乘法器、加载存储单元)能够处理或传输的单个数据元素的最大比特数。(我这里理解的就是假如ALU支持8位、16位、32位运算,那么它的 ELEN 就是 32)
SEW: SEW 定义了向量处理单元(VPU)在执行后续大多数向量指令时,所默认使用的标准元素宽度。它就像一个全局的模式
EEW: EEW 是某一条特定向量指令在执行时,其操作数实际使用的元素宽度。它的作用范围是局部的,仅针对单条指令。
LMUL: LMUL 定义了向量处理单元(VPU)在执行后续大多数向量指令时,所默认使用的标准寄存器分组大小。
EMUL:EMUL 是某一条特定向量指令在执行时,其操作数实际使用的寄存器分组系数。它的作用范围是局部的,仅针对单条指令。
举例:
以 A + B = C 向量扩宽加法举例:
A B 输入数据类型为int32,
C的数据类型为Int64
假设VLEN=128bits,那么一个向量寄存器可以放{a0~a3} 共4个元素,如果LMUL=2 时,意味着使用两个向量寄存器,一共可以装{a0~a7}共8个元素,此时EEW=SEW 且 EMUL=LMUL,向量B也是类似
对于输出C向量,数据类型为Int64,VLEN=128bits,那么一个向量寄存器可以放{c0~c1} 共2个元素,很明显2个寄存器存放不了8个int64 元素,所以LMUL也要扩宽,也即EEW=2 * SEW 且 EMUL= 2 * LMUL
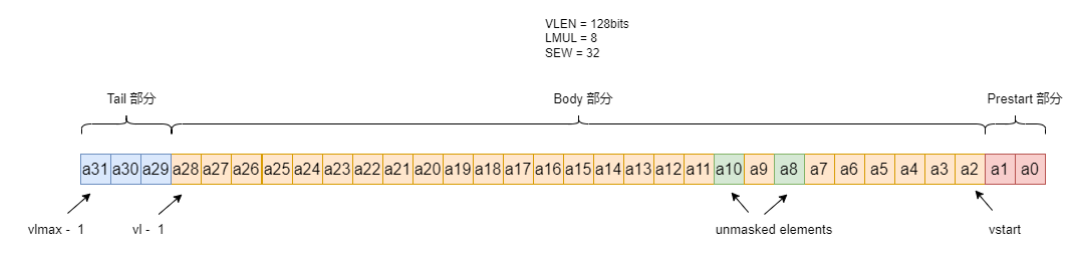
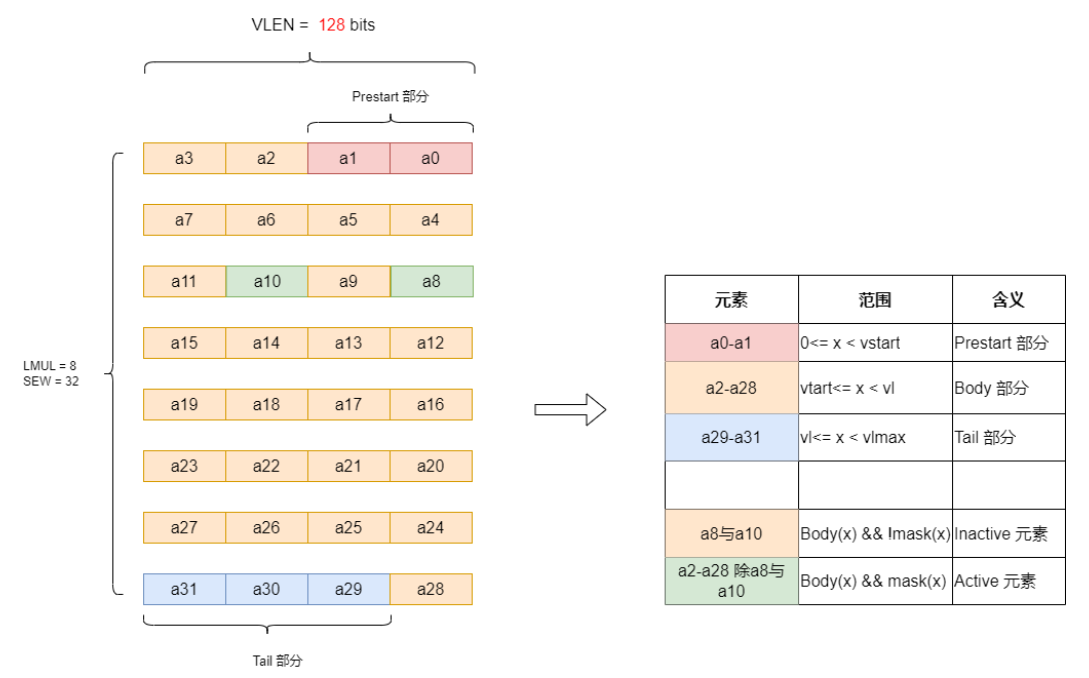
Prestart部分,Body部分,Tail 部分,Active 元素, Inactive元素:
假设我们设置
VLEN = 128 bits
SEW = 32
LMUL = 8
vstart = 2
所以:
Prestart部分[a0,a1]
Body部分 [a2,a28]
Tail部分 [a29, a31]
其中Body部分,可以设置一部分参与运算,一部分不参与运算
Inactive 元素,a8与a10, 不参与运算
Active 元素,a2-a28除a8与a10, 参与运算
3、RVV寄存器
数据寄存器
RVV 有32个vector寄存器,编号v0-v31,每个寄存器的宽度是固定的,宽度为VLEN bits。
CSR寄存器
RVV 的 7个CSRs 寄存器
vstart:vstart 存储的是一个索引值 ,它指定了当前正在执行的向量指令应该从第几个数据元素开始处理。所有vector指令都是从vstart中给定的元素索引开始执行,并在执行结束时将vstart CSR重置为零。一般情况下,vstart寄存器只能由硬件执行向量指令时写入,软件不需要管。举例:当硬件执行向量指令时遇到中断或异常,硬件可以将已经处理的元素索引写入vstart寄存器,等中断或异常处理完成后,将从vstart开始恢复处理
vxsat:向量定点数饱和标志。在向量运算中,尤其是定点数(整数)运算,结果很容易超出目标寄存器所能表示的范围,导致溢出。vxsat 就是用来标记这种事件的。等于1表示至少有一次向量运算的结果因为溢出而被饱和处理了。
vxrm:向量定点数舍入模式,定义了在定点数运算中,当结果精度高于目标格式时,如何进行舍入处理.
rnu:就近舍入,中间值向上,类似于我们常说的"四舍五入"。当结果恰好在两个可表示值的正中间时,向绝对值更大的方向(向上)舍入。rne:就近舍入,中间值向偶数。当结果恰好在两个可表示值的正中间时,向最低有效位(LSB)为 0 的那个值(即偶数)舍入。
举例:将一个二进制数舍入到小数点后一位
10.10 (十进制 2.5):它恰好在 10.0 (2.0) 和 11.0 (3.0) 的正中间。因为 10.0 的最低有效位是 0(偶数),所以选择 10.0。
11.10 (十进制 3.5):它恰好在 11.0 (3.0) 和 100.0 (4.0) 的正中间。因为 100.0 的最低有效位是 0(偶数),所以选择 100.0。
rdn:向下舍入。直接截断多余的低位,相当于向负无穷方向舍入。rod:向奇数舍入。当需要舍入时,如果结果不是精确值,则将最低有效位(LSB)设置为 1(即变为奇数)。
举例:将一个二进制数舍入到小数点后一位
10.01 (十进制 2.25):这个值无法精确表示。它介于 10.0 (2.0) 和 10.1 (2.5) 之间。根据 rod 规则,我们需要将结果的最低有效位设为 1,所以结果是 10.1。
10.11 (十进制 2.75):这个值也无法精确表示。它介于 10.1 (2.5) 和 11.0 (3.0) 之间。根据 rod 规则,我们需要将结果的最低有效位设为 1,所以结果是 10.1。
vcsr:向量控制与状态寄存器将两个独立的控制寄存器------vxrm(舍入模式)和 vxsat(饱和标志)------聚合在一起,方便软件通过一条指令同时读取或修改这两个状态。它的低 3 位分别映射了 vxsat 和 vxrm 的内容

vl:决定当前向量指令实际要处理多少个数据元素 。对于索引大于等于 vl 的元素(即第 6 个及以后的元素),硬件通常会保持其原值不变(undisturbed)或将其视为无效,具体行为取决于配置。当一条向量指令执行时,硬件会读取 vl 的值。假设 vl = 5,那么这条指令只会处理向量寄存器中的前 5 个元素。
注:vl 是一个只读寄存器 ,软件不能直接通过 csrw 指令修改它。它的值是由硬件根据软件请求和硬件能力自动计算得出的。
设置 vl 的唯一途径是执行 vsetvl 或 vsetvli 指令。这个过程涉及三个关键参数:
- AVL (Application Vector Length):软件告诉硬件"我想处理多少个元素"(例如循环剩余的元素个数)。
- VLMAX (Maximum Vector Length) :硬件根据当前的
SEW(元素宽度)和LMUL(寄存器分组)计算出的"我一次最多能处理多少个元素"。 - vl (Vector Length):硬件最终决定的"这次实际处理多少个元素"。
vlenb:向量寄存器字节长度,是只读控制与状态寄存器(CSR),用于告诉软件硬件向量寄存器的物理宽度是多少字节 。(vlenb 的值等于 VLEN / 8,VLEN是bits,vlenb是byte)
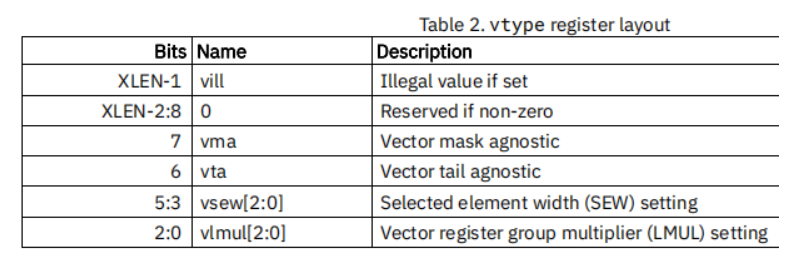
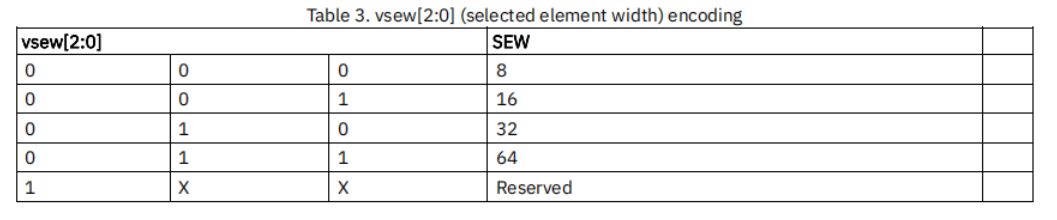
vtype:定义向量数据的组织形式,定义SEW,LMUL,向量指令执行时的"边界行为"等。告诉硬件如何解释向量寄存器中的二进制位。
字段解释:
vlmul字段0:2(低3位),是lmul,lmul值最高为8(因为只有3位),记得满足
ELEN * EMUL >= SEWvsew字段5:3(3位)用来动态设置数据元素的位宽。目前支持{8, 16, 32, 64}几种位宽。
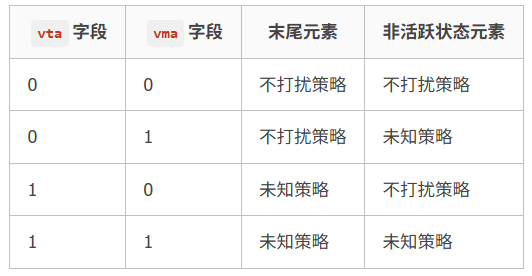
vma和vta字段(第7位和第8位)
vta(vector tail agnostic) 表示目标向量寄存器中末尾数据元素的处理策略,vma(vector mask agnostic)表示非活跃状态的数据元素处理策略。
分为两种策略:
- 不打扰策略(undisturbed): 目标向量寄存器中相应的数据元素保持原值不变
- 未知策略(agnostic):目标向量寄存器中相应的数据元素可以保持原值不变,也可以写入1
它们的区别是:
未知策略可能效率较高(适应某些处理器内部的向量寄存器重命名特性),如果一些数据元素后续计算中用不到的话,可以选择未知策略。
其中0为不打扰1为未知策略
vill字段(高1为):非法标志位,是一个只读位,用于指示上一次通过 vsetvl 或 vsetvli 指令对 vtype 寄存器的配置是否为当前硬件所不支持。vill 位是 vsetvl和vsetvli 指令执行的结果 ,如果合法,就写入新的配置。如果不合法,就将 vill 置 1,并将其他位清零。

4、intrinsic 编程
API查询入口:Intrinsics viewer
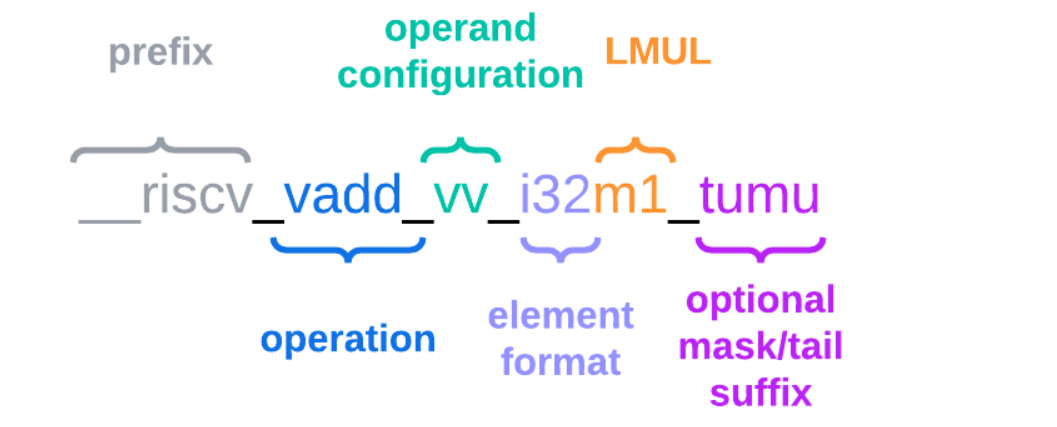
__riscv ------ 前缀
这是所有 RISC-V 内在函数的标准前缀。
- 作用:告诉编译器这是一个特定于 RISC-V 架构的内置函数,而不是普通的 C 函数。
vadd ------ 操作
vv ------ 操作数配置
这部分描述了操作数的来源类型。
vv:代表第一个v是源向量,第二个v也是源向量。即:向量 + 向量。vx:代表向量 + 标量。vi:代表向量 + 立即数。
i32m1 ------ 元素格式
这部分定义了数据的类型和寄存器分组大小。
i32:表示元素的数据类型是 32位整数。i= 整数f= 浮点数u= 无符号整数
m1:表示 LMUL=1。- 这意味着每个向量元素占用 1 个向量寄存器的空间。
- 如果是
m2,则表示 LMUL=2(两个寄存器组成一组);如果是mf2,则表示 LMUL=1/2。
tumu ------ 可选的掩码/尾部后缀
这是最复杂的部分,它由四个字母组成,定义了掩码 和尾部的行为。这四个字母的顺序是固定的,分别对应不同的策略:
t(Mask Type - 掩码类型) :- 这里省略了,通常如果是
v(如vvm) 表示使用向量掩码。
- 这里省略了,通常如果是
u(Mask Policy - 掩码策略) :u= Undisturbed。- 含义:对于被掩码禁用的元素,目标寄存器中的旧值保持不变(不被破坏)。
- 如果是
m,则表示 Mask-Agnostic(不管旧值,可能置为1)。
m(Tail Policy - 尾部策略) :m= Mask-Agnostic。- 含义 :对于
vl之后的"尾部"元素,硬件可以随意处理(通常置为全1),软件不关心其值。 - 如果是
u,则表示 Tail-Undisturbed(尾部元素保持旧值不变)。
u(Merge Logic - 合并逻辑) :u= Undisturbed。- 含义:这通常与掩码策略结合,表示这是一个"合并"操作。
向量掩码:目前 RVV 标准规定,只有 v0 寄存器被用作掩码寄存器。
-
Bit = 1:允许运算(Active)。
-
Bit = 0:禁止运算(Inactive/Masked off)。
-
开启掩码:在指令后面加上 , v0.t
- 例如:
vadd.vv v1, v2, v3, v0.t - 含义:只有当
v0对应位为 true (1) 时,才执行v1 = v2 + v3。
- 例如:
-
关闭掩码:不写 , v0.t
- 例如:
vadd.vv v1, v2, v3 - 含义:所有元素都执行加法。
- 例如:
当一个元素被掩码屏蔽(即 v0 对应位为 0)时,目标寄存器里的对应位置会发生什么变化?这由 vtype 寄存器里的 vma 位控制:
vma = 0(Mask Undisturbed):- 保留原值 。如果该元素不参与运算,目标寄存器里的那个位置保持原来的值不变。这就像 C 语言里的
if语句,不满足条件就不赋值。
- 保留原值 。如果该元素不参与运算,目标寄存器里的那个位置保持原来的值不变。这就像 C 语言里的
vma = 1(Mask Agnostic):- 任意值(破坏原值)。硬件被允许把那个位置写成任意值(通常是全 1)。
- 为什么这么做? 为了性能。允许硬件"偷懒"不去保留旧值,通常能跑得更快。在编程时,如果你不关心被屏蔽位置的数据,建议开启这个选项。
5、RVV指令------load&store
根据操作对象的不同RVV操作分为标量(scalar)操作与向量(vector)操作,其中向量操作受LMUL参数控制,而标量操作不受LMUL参数影响。
设置指令
RVV支持动态向量长度(VL)特性,即:应用程序特性将要处理的元素总数(应用程序向量长度或AVL)作为输入,通过vsetvl指令计算,然后将计算得到的结果写入vl寄存器,每次处理vl个元素,迭代继续,直到所有元素都被处理完毕。
-
AVL (Application Vector Length):代表你的程序总共还有多少数据没处理。
-
vl (Vector Length):代表当前硬件在一次指令执行中实际能处理多少个元素。
-
vl = min(AVL, VLMAX(当前硬件能处理的最大元素数))
如果AVL <= VLMAX 则 vl = AVL
如果AVL > VLMAX 则vl = VLMAX
设置vl :RVV并不是能设置vl寄存器的,而是将AVL参数传递给vsetvl指令来设置正确的vl值。AVL 即应用程序向量长度,指的是应用程序希望处理的数据元素总数。
vsetvli rd, rs1, vtypei # rd = new vl, rs1 = AVL, vtypei = new vtype setting
vsetvli rd, uimm, vtypei # rd = new vl, uimm = AVL, vtypei = new vtype setting
vsetvl rd, rs1, rs2 # rd = new vl, rs1 = AVL, rs2 = new vtype value注:当rs1≠x0是正常设置vl,rs1=x0表示把vl设置到最大值(VLMAX),rs1=x0且rd=0表示保持当前vl不变,这通常用来只修改 vtype
设置vtype(设置SEW和LMUL)寄存器:
vsetvli t0, a0, e8 # SEW= 8, LMUL=1
vsetvli t0, a0, e8, m2 # SEW= 8, LMUL=2
vsetvli t0, a0, e32, mf2 # SEW=32, LMUL=1/2
vsetvli t0, a0, e16, m4, ta, ma # SEW=16, LMUL=4, unmasked, tail-agnostic1、RVV load & store加载存储指令
RVV load & store 指令支持三种寻址模式,分别为:
- Unit-Stride load & store, 即单位步长的load&store
- Strided load & store, 即跨步长的load&store
- Indexed load & store,即按索引的load & store,也称聚合加载/离散存储模式(gather-load/scatter-store)
1.1单位步长的load&store
#v:代表这是一条向量指令
le:代表Load Element(加载元素)。
8:代表元素宽度是 8位(即 1 字节)。
.v:代表寻址模式。这里的 .v 特指单位步长模式,也就是数据在内存里是紧紧挨着的。
vd (目标向量寄存器):这是目的寄存器。CPU 把数据从内存读出来后,存放在这里的向量寄存器组里(比如 v0 - v31)。
(rs1) (基地址):rs1 是一个通用寄存器(如 a0),里面存着内存的起始地址。括号 () 表示"取这个地址里的内容"。
vm (掩码寄存器):决定了哪些位置"允许被写入"。
v0.t或其他掩码:表示受控加载:只有掩码对应位为 1 的元素才会被加载,为 0 的位置保持原值不变。
v0 或空:,表示非受控加载(全开模式):所有元素都会被加载。
# vd 表示目的向量寄存器,rs1表示内存基地址, vm 表示掩码操作数 (v0.t or 空)
vle8.v vd, (rs1), vm # 加载8位宽的数据元素
# vs3 表示向量寄存器元素, rs1表示内存基地址, vm 表示掩码操作数 (v0.t or 空)
vse8.v vs3, (rs1), vm # 存储8位宽的数据元素1.2跨步长的load&store
rs2:通用寄存器,存储的步长
vlse8.v vd, (rs1), rs2, vm # 8位宽的数据跨步长的load
vsse8.v vs3, (rs1), rs2, vm # 8位宽的数据跨步长的store上次地址 + 步长
c
如元素类型为int32:
int32_t vec1[DATALEN] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, };
若步长为4字节,则每隔32bits取一个元素,即单位存取:vec1[0 + 1],vec1[1 + 1]
ptrdiff_t bstride = 4;
pDes[16] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16};
若步长为8字节,则每隔64bits取一个元素,vec1[0 + 2],vec1[2 + 2],可以实现分奇偶取数的目的。
ptrdiff_t bstride = 8;
pDes[16] = {1, 3, 5, 7, 9, 11, 13, 15...}
若步长为0字节,则vec1[0 + 0],vec1[0 + 0]...
ptrdiff_t bstride = 0;
pDes[16] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
若步长为-4字节,并从数组尾部作为基地址(修改部分如下),则会实现倒序效果,
ptrdiff_t bstride = -4;
vx = __riscv_vlse32_v_i32m4(pSrc + 15, bstride, vl);#pSrc 是 int* 类型,pSrc + 15 指向数组的最后一个元素(下标 15)。
pDes[16] = {16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1}**注:**步长bstride 需设置为 SEW (以字节为单位)的整数倍,否则结果可能不符合预期。
c
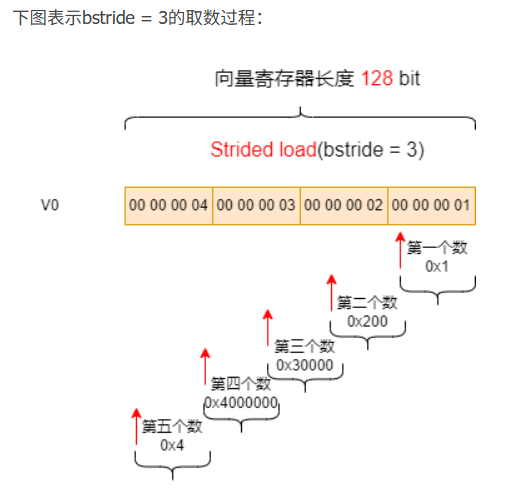
若步长不是`SEW`的整数倍,例如设置 bstride = 3
ptrdiff_t bstride = 3;
res[16] = {1, 512, 196608, 67108864, 4, 1280, 393216, 117440512, 7, 2048, 589824, 167772160, 10, 2816, 786432, 218103808}
将其以16进制显示:
res[16] = {0x1, 0x200, 0x30000, 0x4000000, 0x4, 0x500, 0x60000, 0x7000000, 0x7, 0x800, 0x90000, 0xa000000, 0xa, 0xb00, 0xc0000, 0xd000000}
1.3按索引的load & store
按索引的load & store 支持以下两种形式:
- 有序索引(indexed-ordered):访问内存时按照索引的顺序有序地访问
- 无序索引(indexed-unordered):访问内存时不能保证数据元素的访问顺序
注意:顺序和乱序只是针对硬件(线程之间)拿取和存储数据的动作是否要按照顺序执行,但是数据最终在寄存器/内存里的存放位置必须严格对应索引表的顺序。
rs1基址,vd目的寄存器,vs2偏移量
# 向量无序load & store:硬件可以自由优化访问顺序,不保证按索引大小顺序访问内存。
vluxei8.v vd, (rs1), vs2, vm # unordered 8-bit indexed load of SEW data
vsuxei8.v vs3, (rs1), vs2, vm # unordered 8-bit indexed store of SEW data
# 向量有序load & store:有序。硬件必须严格按照索引向量中元素的顺序(从小到大)访问内存。
vloxei8.v vd, (rs1), vs2, vm # ordered 8-bit indexed load of SEW data
vsoxei8.v vs3, (rs1), vs2, vm # ordered 8-bit indexed store of SEW data
int vec1[DATALEN] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16};
// 注意index单位为byte
uint32_t index_table[4] = {7 * 4, 3 * 4, 10 * 4, 8 * 4};
size_t vl = __riscv_vsetvl_e32m4(avl);
bindex = __riscv_vle32_v_u32m4(index_table, vl);
vx = __riscv_vloxei32_v_i32m4(vec1, bindex, vl);
__riscv_vse32_v_i32m4 (res, vx, vl);2、RVV segment load & store(自动拆包/打包的加载和存储)
2.1单位步长的Sgement load&store
假设你在处理一张图片,内存里存的数据是 RGB RGB RGB... 这样交错排列的(或结构体数组 AoS):你想修改 R 通道。但在内存里,R 和 G、B 混在一起。此时可以使用RVV segment指令
-
Load :把混在一起的
RGBRGB拆成RRR、GGG、BBB并加载。 -
Store :把分开的
RRR、GGG、BBB合回RGBRGB并存储vlseg3e8.v vd, (rs1), vm # 内存里一个元素是8bits,每3个数据是一组,把它们拆开并分别加载进rd,rd+1,rd+2寄存器
vsseg3e32.v vs3, (rs1), vm # 以一个元素32bits的大小从vs3,vs3+1,vs3+2寄存器打包并存储至rs1存储的地址中
举例
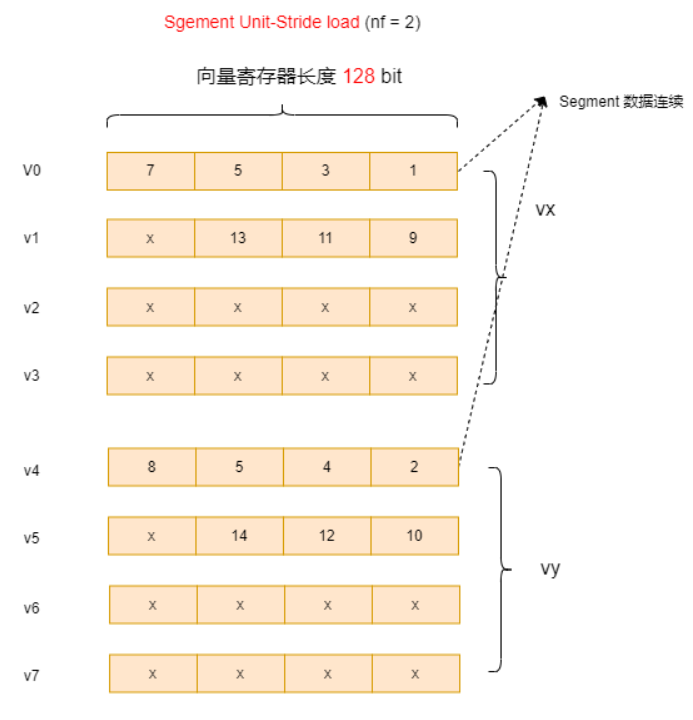
int vec1[DATALEN] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16};
每次从内存读 2 个数据(seg2),每个数据 32 位(e32)。读回来后,把它们拆分成两组,每组都是 32 位整数(i32),每组占用 4 个寄存器宽度(m4),最终返回这 2 个向量(x2)。
vint32m4x2_t vtuple = __riscv_vlseg2e32_v_i32m4x2 (vec1, vl);
vint32m4_t vx = __riscv_vget_v_i32m4x2_i32m4 (vtuple, 0);
vint32m4_t vy = __riscv_vget_v_i32m4x2_i32m4 (vtuple, 1);结果
# 结果如下,可以实现一次segment load 分奇偶的目的
vx[16] = {1, 3, 5, 7, 9, 11, 13, x}
vy[16] = {2, 4, 6, 8, 10, 12, 14, x}下面是上述nf=2时的图示

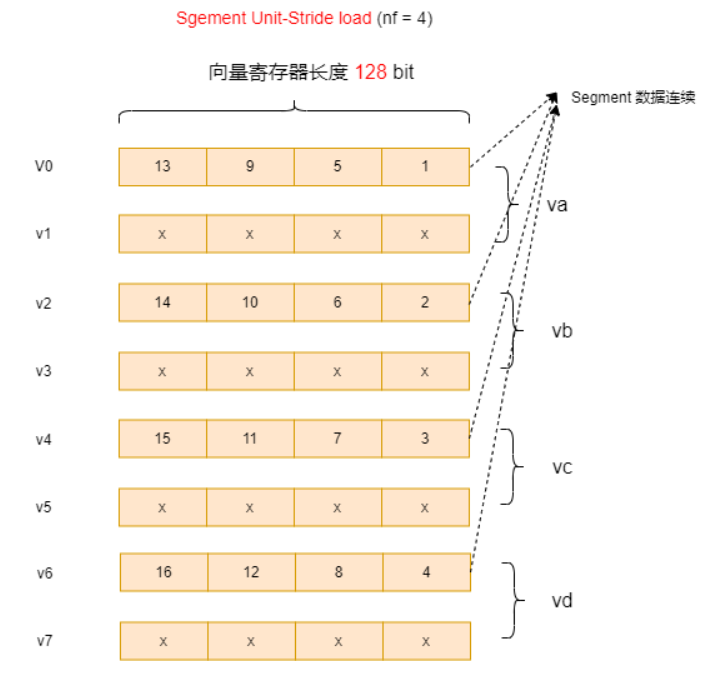
我觉得要注意的点是m4这一块,因为nf * lmul <= 8 (因为单条指令能调用的最大连续寄存器数量被限制为 8 个)
例如
vint32m2x4_t vtuple = __riscv_vlseg4e32_v_i32m2x4 (vec1, vl);
vint32m2_t va = __riscv_vget_v_i32m2x4_i32m2 (vtuple, 0);
vint32m2_t vb = __riscv_vget_v_i32m2x4_i32m2 (vtuple, 1);
vint32m2_t vc = __riscv_vget_v_i32m2x4_i32m2 (vtuple, 2);
vint32m2_t vd = __riscv_vget_v_i32m2x4_i32m2 (vtuple, 3);
2.2跨步长的Sgement load&store
先读取再拆包
vlsseg3e8.v v4, (x5), x6 # Load bytes at addresses x5+i*x6 into v4[i],
vssseg2e32.v v2, (x5), x6 # Store words from v2[i] to address x5+i*x6举例
int vec1[DATALEN] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16};
size_t avl = 10;
size_t vl = __riscv_vsetvl_e32m4(avl);
ptrdiff_t bstride = 4; // 一个int32元素步长
vint32m4x2_t vtuple = __riscv_vlsseg2e32_v_i32m4x2 (vec1, bstride, vl);
#(1,2)(2,3)(3,4)...
vint32m4_t vx = __riscv_vget_v_i32m4x2_i32m4 (vtuple, 0);
vint32m4_t vy = __riscv_vget_v_i32m4x2_i32m4 (vtuple, 1);结果
vx[16] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
vy[16] = {2, 3, 4, 5, 6, 7, 8, 9, 10, 11}2.3按索引的Sgement load & store
先读取再拆包
硬件拿到索引表后,发现要去 4 个不同的地方取数据。为了快,它可能会乱序 去取(谁先到谁先处理),虽然搬运是乱的,但填表(写寄存器)必须按顺序来。
#乱序读取 + 自动拆包
vluxseg3ei32.v v4, (x5), v3 # Load bytes at addresses x5+v3[i] into v4[i]
#乱序读取 + 自动打包
vsuxseg2ei32.v v2, (x5), v5 # Store words from v2[i] to address x5+v5[i]
int vec1[DATALEN] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16};
size_t avl = 16;
uint32_t index_table[4] = {7 * 4, 3 * 4, 10 * 4, 8 * 4}; // 注意index单位为byte
vint32m4x2_t vtuple = __riscv_vloxseg2ei32_v_i32m4x2 (vec1, bindex, vl);
#(8,9)(4,5)(11,12)(9,10)
vint32m4_t vx = __riscv_vget_v_i32m4x2_i32m4 (vtuple, 0);
vint32m4_t vy = __riscv_vget_v_i32m4x2_i32m4 (vtuple, 1);结果
vx[16] = {8, 4, 11, 9}
vy[16] = {9, 5, 12, 10}指令名.目标类型.源类型
| 指令助记符 | 含义 | 数据流向 | 典型用途 |
|---|---|---|---|
vmv.v.v |
向量 -> 向量 | vd[i] = vs1[i] |
寄存器拷贝 |
vmv.v.x |
标量 -> 向量 | vd[i] = x[rs1] |
广播(把同一个数填满向量) |
vmv.v.i |
立即数 -> 向量 | vd[i] = imm |
初始化(如全填0或全填1) |
vmv.x.s |
向量 -> 标量 | x[rd] = vs2[0] |
提取结果(把计算结果取出来) |
vmv.s.x |
标量 -> 向量(0) | vd[0] = x[rs1] |
设置初值(只改第0个元素) |
3、RVV Load/Store Whole Register搬运整个寄存器
RVV提供了一种加载全部向量数据的指令。加载全部向量数据的指令常常用于保存和恢复向量寄存器的值(如操作系统上下文切换)。
-
vl: Vector Load (向量加载)。 -
1r,2r,4r,8r: 表示一次性加载 1、2、4 或 8 个连续的物理向量寄存器。 -
.v: 表示操作对象是向量寄存器。 -
(a0): 内存的基地址,存放在通用寄存器a0中。vl1r.v v3, (a0) # 从内存地址 a0 开始,读取 1 个向量寄存器宽度(VLEN) 的数据,直接填入向量寄存器 v3。
vl2r.v v2, (a0)
vl4r.v v4, (a0)
vl8r.v v8, (a0)vs1r.v v3, (a1) # 把寄存器 v3 里的所有比特(VLEN 位),原样写入a1里写的那个内存地址处。
vs2r.v v2, (a1) # Store v2-v3 to address in a1
vs4r.v v4, (a1) # Store v4-v7 to address in a1
vs8r.v v8, (a1) # Store v8-v15 to address in a1
4、首次(遇到)异常**(就停止)**的加载指令
有些场景我们无法确定要处理的数据长度、不知道数据元素的边界与临界值在哪,而在向量加载指令中,如果加载了字符串结束后的数据,那么会造成非法访问,导致程序出错。
RVV引入了首次异常加载指令。首次异常加载指令常常用于待处理数据元素长度不确定的场合。

ff (Fault-Only-First)
vle8ff.v vd, (rs1), vm # 以字节(8位)为单位,从 rs1 指向的内存地址开始加载数据。
vle16ff.v vd, (rs1), vm # 16-bit unit-stride fault-only-first load
vle32ff.v vd, (rs1), vm # 32-bit unit-stride fault-only-first load
vle64ff.v vd, (rs1), vm # 64-bit unit-stride fault-only-firstdd load注意:首次异常(Fault-Only-First, ff)"机制仅存在于单位步长(Unit-Stride)加载指令中
6、RVV指令------整数算术指令
6.1 向量整数加减
RISC-V RVV第11讲之RVV 整数算术指令 - sureZ_ok - 博客园
# 整数加法
vadd.vv vd, vs2, vs1, vm # 向量-向量运算:vd[i] = vs2[i] + vs1[i]
vadd.vx vd, vs2, rs1, vm # 向量-标量运算:vd[i] = vs2[i] + x[rs1]
vadd.vi vd, vs2, imm, vm # 向量-立即数运算:vd[i] = vs2[i] + imm
# 整数减法
vsub.vv vd, vs2, vs1, vm # Vector-vector:vd[i] = vs2[i] - vs1[i]
vsub.vx vd, vs2, rs1, vm # vector-scalar:vd[i] = vs2[i] - x[rs1]
# 整数反减(vector-scalar格式)
# 向量操作数可以使用x0的反减指令来得到其相反数,类似如:vneg.v vd,vs = vrsub.vx vd, vs, x0
vrsub.vx vd, vs2, rs1, vm # vd[i] = x[rs1] - vs2[i]
vrsub.vi vd, vs2, imm, vm # vd[i] = imm - vs2[i]向量扩宽加减:两个int16 类型数据相加,如果结果也是int16类型,可能发生溢出,所以提供扩宽的加减法(包括有符号数与无符号数)。
# 扩宽的无符号数加减法 2*SEW = SEW +/- SEW
vwaddu.vv vd, vs2, vs1, vm # vector-vector
vwaddu.vx vd, vs2, rs1, vm # vector-scalar
vwsubu.vv vd, vs2, vs1, vm # vector-vector
vwsubu.vx vd, vs2, rs1, vm # vector-scalar
# 扩宽的有符号数加减法 2*SEW = SEW +/- SEW
vwadd.vv vd, vs2, vs1, vm # vector-vector
vwadd.vx vd, vs2, rs1, vm # vector-scalar
vwsub.vv vd, vs2, vs1, vm # vector-vector
vwsub.vx vd, vs2, rs1, vm # vector-scalar
# 扩宽的无符号数加减法 2*SEW = 2*SEW +/- 2*SEW
vwaddu.wv vd, vs2, vs1, vm # vector-vector
vwaddu.wx vd, vs2, rs1, vm # vector-scalar
vwsubu.wv vd, vs2, vs1, vm # vector-vector
vwsubu.wx vd, vs2, rs1, vm # vector-scalar
# 扩宽的有符号数加减法 2*SEW = 2*SEW +/- 2*SEW
vwadd.wv vd, vs2, vs1, vm # vector-vector
vwadd.wx vd, vs2, rs1, vm # vector-scalar
vwsub.wv vd, vs2, vs1, vm # vector-vector
vwsub.wx vd, vs2, rs1, vm # vector-scalar向量整数进位与借位加减:
进位加
# Produce sum with carry.产生结果的加法 :vd存储加法的和
# vd[i] = vs2[i] + vs1[i] + v0.mask[i]
vadc.vvm vd, vs2, vs1, v0 # Vector-vector
# vd[i] = vs2[i] + x[rs1] + v0.mask[i]
vadc.vxm vd, vs2, rs1, v0 # Vector-scalar
# vd[i] = vs2[i] + imm + v0.mask[i]
vadc.vim vd, vs2, imm, v0 # Vector-immediate
# Produce carry out in mask register format产生进位的加法 :vd不保存和,而是将是否产生新的进位(0 或 1)写入
# vd.mask[i] = carry_out(vs2[i] + vs1[i] + v0.mask[i])
vmadc.vvm vd, vs2, vs1, v0 # Vector-vector
# vd.mask[i] = carry_out(vs2[i] + x[rs1] + v0.mask[i])
vmadc.vxm vd, vs2, rs1, v0 # Vector-scalar
# vd.mask[i] = carry_out(vs2[i] + imm + v0.mask[i])
vmadc.vim vd, vs2, imm, v0 # Vector-immediate
# vd.mask[i] = carry_out(vs2[i] + vs1[i])
vmadc.vv vd, vs2, vs1 # Vector-vector, no carry-in
# vd.mask[i] = carry_out(vs2[i] + x[rs1])
vmadc.vx vd, vs2, rs1 # Vector-scalar, no carry-in
# vd.mask[i] = carry_out(vs2[i] + imm)
vmadc.vi vd, vs2, imm # Vector-immediate, no carry-in借位减
# Produce difference with borrow.
# vd[i] = vs2[i] - vs1[i] - v0.mask[i]
vsbc.vvm vd, vs2, vs1, v0 # Vector-vector
# vd[i] = vs2[i] - x[rs1] - v0.mask[i]
vsbc.vxm vd, vs2, rs1, v0 # Vector-scalar
# Produce borrow out in mask register format
# vd.mask[i] = borrow_out(vs2[i] - vs1[i] - v0.mask[i])
vmsbc.vvm vd, vs2, vs1, v0 # Vector-vector
# vd.mask[i] = borrow_out(vs2[i] - x[rs1] - v0.mask[i])
vmsbc.vxm vd, vs2, rs1, v0 # Vector-scalar
# vd.mask[i] = borrow_out(vs2[i] - vs1[i])
vmsbc.vv vd, vs2, vs1 # Vector-vector, no borrow-in
# vd.mask[i] = borrow_out(vs2[i] - x[rs1])
vmsbc.vx vd, vs2, rs1 # Vector-scalar, no borrow-in6.2 向量整数扩宽/缩减
将较窄的整数向量转换为较宽的整数向量,同时保持向量中的元素个数不变。
-
vzext (Vector Zero Extend): 高位补 0。适用于无符号数,确保数值大小不变。
-
vsext (Vector Sign Extend): 高位补符号位(最高位的值)。适用于有符号数,确保正负性不变。
vzext.vf2 vd, vs2, vm # 2倍零扩宽(源操作数:EEW = SEW/2, EMUL = (EEW/SEW) * LMUL,目的操作数:SEW,LMUL)
vsext.vf2 vd, vs2, vm # 2倍有符号扩宽 (源操作数:EEW = SEW/2, EMUL = (EEW/SEW) * LMUL,目的操作数:SEW,LMUL)
vzext.vf4 vd, vs2, vm # 4倍零扩宽(源操作数:EEW = SEW/4, EMUL = (EEW/SEW) * LMUL,目的操作数:SEW,LMUL)
vsext.vf4 vd, vs2, vm # 4倍有符号扩宽(源操作数:EEW = SEW/4, EMUL = (EEW/SEW) * LMUL,目的操作数:SEW,LMUL)
vzext.vf8 vd, vs2, vm # 8倍零扩宽(源操作数:EEW = SEW/8, EMUL = (EEW/SEW) * LMUL,目的操作数:SEW,LMUL)
vsext.vf8 vd, vs2, vm # 8倍有符号扩宽(源操作数:EEW = SEW/8, EMUL = (EEW/SEW) * LMUL,目的操作数:SEW,LMUL)
另外,也有缩减指令,只能2倍缩减
vncvt(Vector Narrowing Convert):向量窄化转换
# vint16m2_t 缩减为 vint8m1_t (2倍缩减):将一个包含 16 位有符号整数的向量,"砍掉"高 8 位,只保留低 8 位,转换成一个包含 8 位有符号整数的向量。
vint8m1_t __riscv_vncvt_x_x_w_i8m1 (vint16m2_t src, size_t vl);6.3 向量整数逻辑操作
# 按位操作指令
# 与
vand.vv vd, vs2, vs1, vm # Vector-vector
vand.vx vd, vs2, rs1, vm # vector-scalar
vand.vi vd, vs2, imm, vm # vector-immediate
# 或
vor.vv vd, vs2, vs1, vm # Vector-vector
vor.vx vd, vs2, rs1, vm # vector-scalar
vor.vi vd, vs2, imm, vm # vector-immediate
# 异或
vxor.vv vd, vs2, vs1, vm # Vector-vector
vxor.vx vd, vs2, rs1, vm # vector-scalar
vxor.vi vd, vs2, imm, vm # vector-immediate6.4 向量整数移位
逻辑左移(sll),逻辑右移(srl),算术右移(sra)(高位补符号位),算术左移与逻辑左移一样的操作。
# 逻辑左移与算术左移
vsll.vv vd, vs2, vs1, vm # Vector-vector
vsll.vx vd, vs2, rs1, vm # vector-scalar
vsll.vi vd, vs2, uimm, vm # vector-immediate
# 逻辑右移(无符号数)
vsrl.vv vd, vs2, vs1, vm # Vector-vector
vsrl.vx vd, vs2, rs1, vm # vector-scalar
vsrl.vi vd, vs2, uimm, vm # vector-immediate
# 算术右移(有符号数)
vsra.vv vd, vs2, vs1, vm # Vector-vector
vsra.vx vd, vs2, rs1, vm # vector-scalar
vsra.vi vd, vs2, uimm, vm # vector-immediate缩减整数右移指令:
先把宽数据向右移动,然后丢弃高位,只保留低位结果。
# 缩减逻辑右移, SEW = (2*SEW) >> SEW:源操作数的有效位宽(EEW)是目的操作数(SEW)的 2倍。
vnsrl.wv vd, vs2, vs1, vm # vector-vector
vnsrl.wx vd, vs2, rs1, vm # vector-scalar
vnsrl.wi vd, vs2, uimm, vm # vector-immediate
# 缩减算术右移, SEW = (2*SEW) >> SEW
vnsra.wv vd, vs2, vs1, vm # vector-vector
vnsra.wx vd, vs2, rs1, vm # vector-scalar
vnsra.wi vd, vs2, uimm, vm # vector-immediate6.5 向量整数比较
向量整数比较指令用来获取掩码。掩码是放在一个矢量寄存器中,其每一bit表示向量比较的结果(true为1,false为0)
# Mask Set Equal =:相等则掩码位为 1,否则为 0。
vmseq.vv vd, vs2, vs1, vm # Vector-vector
vmseq.vx vd, vs2, rs1, vm # vector-scalar
vmseq.vi vd, vs2, imm, vm # vector-immediate
# Mask Set Not Equal !=:不相等则掩码位为 1,否则为 0。
vmsne.vv vd, vs2, vs1, vm # Vector-vector
vmsne.vx vd, vs2, rs1, vm # vector-scalar
vmsne.vi vd, vs2, imm, vm # vector-immediate
# Mask Set Less Than Unsigned <, unsigned:无符号比较 vs2[i] < vs1[i],成立为则为1,否则为 0
vmsltu.vv vd, vs2, vs1, vm # Vector-vector
vmsltu.vx vd, vs2, rs1, vm # Vector-scalar
# Mask Set Less Than <, signed:有符号比较 vs2[i] < vs1[i]
vmslt.vv vd, vs2, vs1, vm # Vector-vector
vmslt.vx vd, vs2, rs1, vm # vector-scalar
# Mask Set Less or Equal Unsigned<=, unsigned
vmsleu.vv vd, vs2, vs1, vm # Vector-vector
vmsleu.vx vd, vs2, rs1, vm # vector-scalar
vmsleu.vi vd, vs2, imm, vm # Vector-immediate
# <=, signed
vmsle.vv vd, vs2, vs1, vm # Vector-vector
vmsle.vx vd, vs2, rs1, vm # vector-scalar
vmsle.vi vd, vs2, imm, vm # vector-immediate
# >, unsigned
vmsgtu.vx vd, vs2, rs1, vm # Vector-scalar
vmsgtu.vi vd, vs2, imm, vm # Vector-immediate
# >, signed
vmsgt.vx vd, vs2, rs1, vm # Vector-scalar
vmsgt.vi vd, vs2, imm, vm # Vector-immediate注:不存在>=的指令
6.6 向量逐元素比较并选取极值指令
功能非常直观:对比两个操作数,将更大 或更小 的那个值写入目标寄存器。这相当于在硬件层面实现了 C 语言中的三元运算符(例如 c = (a > b) ? a : b)。
# 最小值, Unsigned
vminu.vv vd, vs2, vs1, vm # Vector-vector
vminu.vx vd, vs2, rs1, vm # vector-scalar
# 最小值,Signed
vmin.vv vd, vs2, vs1, vm # Vector-vector
vmin.vx vd, vs2, rs1, vm # vector-scalar
# 最大值,Unsigned
vmaxu.vv vd, vs2, vs1, vm # Vector-vector
vmaxu.vx vd, vs2, rs1, vm # vector-scalar
# 最大值,Signed
vmax.vv vd, vs2, vs1, vm # Vector-vector
vmax.vx vd, vs2, rs1, vm # vector-scalar6.7 向量整数乘除法指令
单宽整数乘法指令
两个 N 位数相乘,结果可能是 2N 位,硬件需要明确指示是保留"低位结果"还是"高位结果"
# 有符号单宽乘法,返回低字节数据,只保留结果的低 N 位(与输入位宽相同的N位)
vmul.vv vd, vs2, vs1, vm # Vector-vector
vmul.vx vd, vs2, rs1, vm # vector-scalar
# 有符号单宽乘法,返回高字节数据,保留结果的高 N 位(与输入位宽相同的N位)
vmulh.vv vd, vs2, vs1, vm # Vector-vector
vmulh.vx vd, vs2, rs1, vm # vector-scalar
# 无符号单宽乘法,返回高字节数据
vmulhu.vv vd, vs2, vs1, vm # Vector-vector
vmulhu.vx vd, vs2, rs1, vm # vector-scalar
# 有符号-无符号单宽乘法,返回高字节数据
vmulhsu.vv vd, vs2, vs1, vm # Vector-vector
vmulhsu.vx vd, vs2, rs1, vm # vector-scalar单宽整数除法/取余指令
# 无符号除法
vdivu.vv vd, vs2, vs1, vm # Vector-vector
vdivu.vx vd, vs2, rs1, vm # vector-scalar
# 有符号除法
vdiv.vv vd, vs2, vs1, vm # Vector-vector
vdiv.vx vd, vs2, rs1, vm # vector-scalar
# 无符号求余
vremu.vv vd, vs2, vs1, vm # Vector-vector
vremu.vx vd, vs2, rs1, vm # vector-scalar
# 有符号求余
vrem.vv vd, vs2, vs1, vm # Vector-vector
vrem.vx vd, vs2, rs1, vm # vector-scalar加宽向量整数乘法指令
加宽乘法 (vwmul):完整保留 2N 位的结果。目的寄存器 (vd) 的元素宽度必须是源寄存器 (vs2, vs1) 的两倍。
# Widening signed-integer multiply将两个有符号的 N 位整数相乘,生成一个 2N 位的有符号结果。
vwmul.vv vd, vs2, vs1, vm # vector-vector
vwmul.vx vd, vs2, rs1, vm # vector-scalar
# Widening unsigned-integer multiply将两个无符号的 N 位整数相乘,生成一个 2N 位的无符号结果。
vwmulu.vv vd, vs2, vs1, vm # vector-vector
vwmulu.vx vd, vs2, rs1, vm # vector-scalar
# Widening signed(vs2)-unsigned integer multiply将第一个操作数 (vs2) 视为有符号数,第二个操作数 (vs1) 视为无符号数,相乘后生成一个 2N 位的有符号结果。
vwmulsu.vv vd, vs2, vs1, vm # vector-vector
vwmulsu.vx vd, vs2, rs1, vm # vector-scalar单宽向量整数乘加指令
C += A * B
# Integer multiply-add, overwrite addend。Multiply-Accumulate(向量乘后累加)
vmacc.vv vd, vs1, vs2, vm # vd[i] = +(vs1[i] * vs2[i]) + vd[i]
vmacc.vx vd, rs1, vs2, vm # vd[i] = +(x[rs1] * vs2[i]) + vd[i]
# Integer multiply-sub, overwrite minuend。Negative Multiply-Accumulate(向量负乘后累加)
vnmsac.vv vd, vs1, vs2, vm # vd[i] = -(vs1[i] * vs2[i]) + vd[i]
vnmsac.vx vd, rs1, vs2, vm # vd[i] = -(x[rs1] * vs2[i]) + vd[i]
# Integer multiply-add, overwrite multiplicand。Multiply-Add(向量乘后加)
vmadd.vv vd, vs1, vs2, vm # vd[i] = (vs1[i] * vd[i]) + vs2[i]
vmadd.vx vd, rs1, vs2, vm # vd[i] = (x[rs1] * vd[i]) + vs2[i]
# Integer multiply-sub, overwrite multiplicand。Negative Multiply-Subtract(向量负乘后减)
vnmsub.vv vd, vs1, vs2, vm # vd[i] = -(vs1[i] * vd[i]) + vs2[i]
vnmsub.vx vd, rs1, vs2, vm # vd[i] = -(x[rs1] * vd[i]) + vs2[i]扩宽向量整数乘加指令
# Widening unsigned-integer multiply-add, overwrite addend
vwmaccu.vv vd, vs1, vs2, vm # vd[i] = +(vs1[i] * vs2[i]) + vd[i]
vwmaccu.vx vd, rs1, vs2, vm # vd[i] = +(x[rs1] * vs2[i]) + vd[i]
# Widening signed-integer multiply-add, overwrite addend
vwmacc.vv vd, vs1, vs2, vm # vd[i] = +(vs1[i] * vs2[i]) + vd[i]
vwmacc.vx vd, rs1, vs2, vm # vd[i] = +(x[rs1] * vs2[i]) + vd[i]
# Widening signed-unsigned-integer multiply-add, overwrite addend
vwmaccsu.vv vd, vs1, vs2, vm # vd[i] = +(signed(vs1[i]) * unsigned(vs2[i])) + vd[i]
vwmaccsu.vx vd, rs1, vs2, vm # vd[i] = +(signed(x[rs1]) * unsigned(vs2[i])) + vd[i]
# Widening unsigned-signed-integer multiply-add, overwrite addend
vwmaccus.vx vd, rs1, vs2, vm # vd[i] = +(unsigned(x[rs1]) * signed(vs2[i])) + vd[i]6.8 向量 整数合并
vmerge.vvm vd, vs2, vs1, v0 # vd[i] = v0.mask[i] ? vs1[i] : vs2[i]
vmerge.vxm vd, vs2, rs1, v0 # vd[i] = v0.mask[i] ? x[rs1] : vs2[i]
vmerge.vim vd, vs2, imm, v0 # vd[i] = v0.mask[i] ? imm : vs2[i]掩码为真1则取新值,掩码为假0则保留旧值
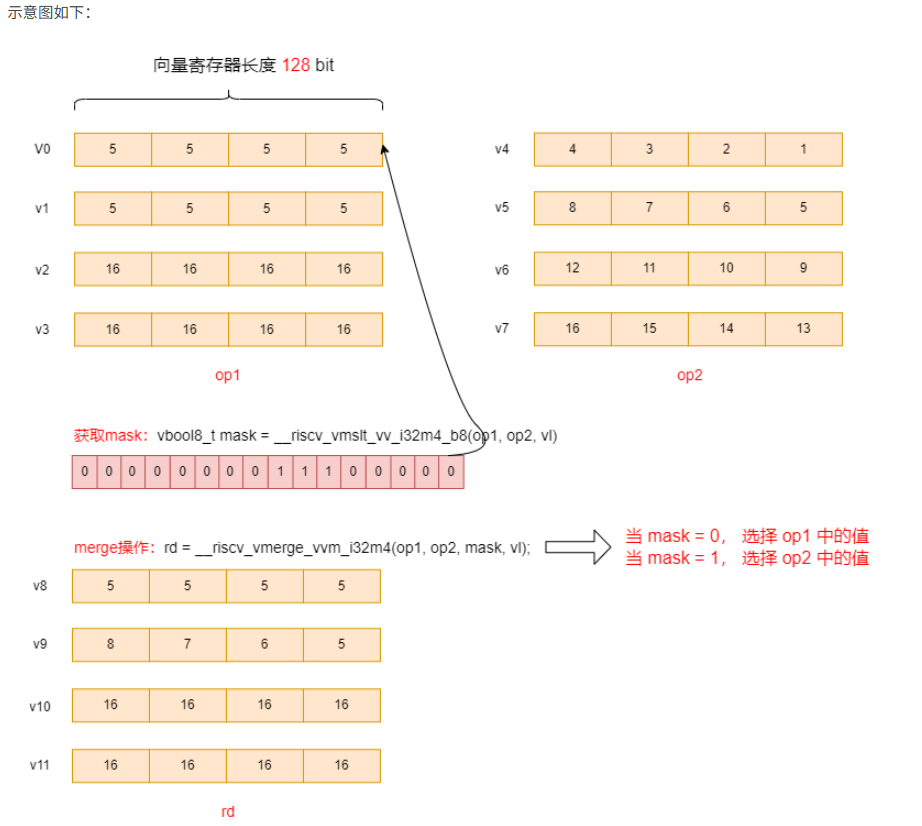
const int32_t vec1[DATALEN] = {5, 5, 5, 5, 5, 5, 5, 5, 16, 16, 16, 16, 16, 16, 16, 16};
const int32_t vec2[DATALEN] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16};
vbool8_t mask = __riscv_vmslt_vv_i32m4_b8(op1, op2, vl);
// merge,要注意当mask = 0,时取op1的值,当mask=1时,取op2的值
rd = __riscv_vmerge_vvm_i32m4(op1, op2, mask, vl);
结果:
res[16] = {5, 5, 5, 5, 5, 6, 7, 8, 16, 16, 16, 16, 16, 16, 16, 16,}
7 定点数算术指令
7.1单宽度向量饱和加减
当运算结果超出目标数据类型所能表示的范围时,不会发生"回绕"(wrap-around),而是会被"钳位"到该范围的最大值或最小值。(例如对于8位有符号数是-128到127,当结果超出有符号数的表示范围时,结果会被钳位到上界或下界。)
# 无符号定点数饱和加
vsaddu.vv vd, vs2, vs1, vm # Vector-vector
vsaddu.vx vd, vs2, rs1, vm # vector-scalar
vsaddu.vi vd, vs2, imm, vm # vector-immediate
# 有符号定点数饱和加 Vector Saturated(饱和) Add
vsadd.vv vd, vs2, vs1, vm # Vector-vector
vsadd.vx vd, vs2, rs1, vm # vector-scalar
vsadd.vi vd, vs2, imm, vm # vector-immediate
# 无符号定点数饱和减:用于无符号定点数的减法。当结果小于0时,结果会被设置为0。
vssubu.vv vd, vs2, vs1, vm # Vector-vector
vssubu.vx vd, vs2, rs1, vm # vector-scalar
# 有符号定点数饱和减
vssub.vv vd, vs2, vs1, vm # Vector-vector
vssub.vx vd, vs2, rs1, vm # vector-scalar7.2 单宽度向量平均加减
核心功能是先对两个操作数执行加法或减法,然后将中间结果(未溢出,因为计算时会用更宽的寄存器保存中间结果)右移一位(相当于除以2),并根据配置的舍入模式进行舍入。
# Averaging add
# Averaging adds of unsigned integers.
vaaddu.vv vd, vs2, vs1, vm # roundoff_unsigned(vs2[i] + vs1[i], 1)
vaaddu.vx vd, vs2, rs1, vm # roundoff_unsigned(vs2[i] + x[rs1], 1)
# Averaging adds of signed integers.
vaadd.vv vd, vs2, vs1, vm # roundoff_signed(vs2[i] + vs1[i], 1)
vaadd.vx vd, vs2, rs1, vm # roundoff_signed(vs2[i] + x[rs1], 1)
# Averaging subtract
# Averaging subtract of unsigned integers.
vasubu.vv vd, vs2, vs1, vm # roundoff_unsigned(vs2[i] - vs1[i], 1)
vasubu.vx vd, vs2, rs1, vm # roundoff_unsigned(vs2[i] - x[rs1], 1)
# Averaging subtract of signed integers.
vasub.vv vd, vs2, vs1, vm # roundoff_signed(vs2[i] - vs1[i], 1)
vasub.vx vd, vs2, rs1, vm # roundoff_signed(vs2[i] - x[rs1], 1)7.3 单宽度向量饱和乘法
__riscv_vsmul_vv_i16m1 的计算规则为:
-
计算两个 16 位有符号操作数的全乘积,得到一个 32 位有符号中间结果;
-
将中间结果算术右移 15 位(相当于除以 32768 并向负无穷取整);
-
如果移位后的结果超出 16 位有符号整数范围
[-32768, 32767],则饱和到边界值。Signed saturating and rounding fractional multiply
See vxrm description for rounding calculation
vsmul.vv vd, vs2, vs1, vm # vd[i] = clip(roundoff_signed(vs2[i]*vs1[i], SEW-1))
vsmul.vx vd, vs2, rs1, vm # vd[i] = clip(roundoff_signed(vs2[i]*x[rs1], SEW-1))const int16_t vec1[DATALEN] = { 32767, 32767, 32767, 32767, -32767, -32767, -32767, -32767, };
const int16_t vec2[DATALEN] = { 1862, 1862, 1862, 1862, 32767, 32767, 32767, 32767, };
rd = __riscv_vsmul_vv_i16m1(op1, op2, vl);
结果

7.4 单宽度向量缩放移位指令
核心作用是对向量数据进行右移操作,但与普通的移位指令不同,它们支持**舍入(Rounding)**功能,通常用于定点数运算(如 Q 格式定点数)中,以保持计算精度。
普通的逻辑/算术右移(如 srl, sra)在丢弃低位时,通常是直接截断(相当于向下取整)。这会带来精度损失。vssrl / vssra 会根据 RISC-V 的 vxrm(向量舍入模式寄存器) 的设置,对移出的低位进行舍入处理。
# Scaling shift right logical(逻辑右移)
vssrl.vv vd, vs2, vs1, vm # vd[i] = roundoff_unsigned(vs2[i], vs1[i])无符号缩放逻辑右移
vssrl.vx vd, vs2, rs1, vm # vd[i] = roundoff_unsigned(vs2[i], x[rs1])
vssrl.vi vd, vs2, uimm, vm # vd[i] = roundoff_unsigned(vs2[i], uimm)
# Scaling shift right arithmetic(算术右移)
vssra.vv vd, vs2, vs1, vm # vd[i] = roundoff_signed(vs2[i],vs1[i])有符号缩放算术右移
vssra.vx vd, vs2, rs1, vm # vd[i] = roundoff_signed(vs2[i], x[rs1])
vssra.vi vd, vs2, uimm, vm # vd[i] = roundoff_signed(vs2[i], uimm)注:在 RISC-V 向量扩展(RVV 1.0)中,没有直接与 vssrl/vssra 对称的"缩放左移"指令(即没有 vssll/vssla) ,但拥有标准左移指令 vsll。
7.5 窄化裁剪移位指令
将宽位宽的向量数据(如16位)转换为窄位宽(如8位),同时进行右移舍入和饱和截断。
# Narrowing unsigned clip
# SEW 2*SEW SEW
vnclipu.wv vd, vs2, vs1, vm # vd[i] = clip(roundoff_unsigned(vs2[i], vs1[i]))
vnclipu.wx vd, vs2, rs1, vm # vd[i] = clip(roundoff_unsigned(vs2[i], x[rs1]))
vnclipu.wi vd, vs2, uimm, vm # vd[i] = clip(roundoff_unsigned(vs2[i], uimm))
# Narrowing signed clip
vnclip.wv vd, vs2, vs1, vm # vd[i] = clip(roundoff_signed(vs2[i], vs1[i]))
vnclip.wx vd, vs2, rs1, vm # vd[i] = clip(roundoff_signed(vs2[i], x[rs1]))
vnclip.wi vd, vs2, uimm, vm # vd[i] = clip(roundoff_signed(vs2[i], uimm))8、浮点数指令
8.1 浮点数加减
单宽度向量浮点加减法指令
# Floating-point add
vfadd.vv vd, vs2, vs1, vm # Vector-vector
vfadd.vf vd, vs2, rs1, vm # vector-scalar
# Floating-point subtract
vfsub.vv vd, vs2, vs1, vm # Vector-vector
vfsub.vf vd, vs2, rs1, vm # Vector-scalar vd[i] = vs2[i] - f[rs1]
vfrsub.vf vd, vs2, rs1, vm # Scalar-vector vd[i] = f[rs1] - vs2[i]浮点数反减
const float32_t vec1[DATALEN] = { 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0, 11.0, 12.0, 13.0, 14.0, 15.0, 16.0 };
const float32_t vec2[DATALEN] = { 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0 };
rd = __riscv_vfadd_vv_f32m4(op1, op2, vl);结果:
res[16] = {2.000000, 3.000000, 4.000000, 5.000000, 6.000000, 7.000000, 8.000000, 9.000000, 10.000000, 11.000000, 12.000000, 13.000000, 14.000000, 15.000000, 16.000000, 17.000000,}扩宽向量浮点加减指令
# Widening FP add/subtract, 2*SEW = SEW +/- SEW
# 将两个单精度(窄)的操作数相加/相减,并将结果存储为双精度(宽)
vfwadd.vv vd, vs2, vs1, vm # vector-vector
vfwadd.vf vd, vs2, rs1, vm # vector-scalar
vfwsub.vv vd, vs2, vs1, vm # vector-vector
vfwsub.vf vd, vs2, rs1, vm # vector-scalar
# Widening FP add/subtract, 2*SEW = 2*SEW +/- SEW
# 将一个双精度(宽)的操作数和一个单精度(窄)的操作数相加/相减,结果保持双精度(宽)
vfwadd.wv vd, vs2, vs1, vm # vector-vector
vfwadd.wf vd, vs2, rs1, vm # vector-scalar
vfwsub.wv vd, vs2, vs1, vm # vector-vector
vfwsub.wf vd, vs2, rs1, vm # vector-scalar8.2 浮点数乘除
单宽度浮点乘除
# Floating-point multiply
vfmul.vv vd, vs2, vs1, vm # Vector-vector
vfmul.vf vd, vs2, rs1, vm # vector-scalar
# Floating-point divide
vfdiv.vv vd, vs2, vs1, vm # Vector-vector
vfdiv.vf vd, vs2, rs1, vm # vector-scalar
# Reverse floating-point divide vector = scalar / vector
vfrdiv.vf vd, vs2, rs1, vm # scalar-vector, vd[i] = f[rs1]/vs2[i]加宽浮点乘法
# Widening floating-point multiply
vfwmul.vv vd, vs2, vs1, vm # vector-vector
vfwmul.vf vd, vs2, rs1, vm # vector-scalar注:目前官方的RVV(RISC-V向量扩展)规范中,没有定义加宽浮点除法指令。
8.3 浮点数乘加
单宽度向量浮点乘加
# FP multiply-accumulate, overwrites addend乘后加,覆盖加数
vfmacc.vv vd, vs1, vs2, vm # vd[i] = +(vs1[i] * vs2[i]) + vd[i]
vfmacc.vf vd, rs1, vs2, vm # vd[i] = +(f[rs1] * vs2[i]) + vd[i]
# FP negate-(multiply-accumulate), overwrites subtrahend负乘后减,覆盖减数
vfnmacc.vv vd, vs1, vs2, vm # vd[i] = -(vs1[i] * vs2[i]) - vd[i]
vfnmacc.vf vd, rs1, vs2, vm # vd[i] = -(f[rs1] * vs2[i]) - vd[i]
# FP multiply-subtract-accumulator, overwrites subtrahend乘减累加,覆盖减数
vfmsac.vv vd, vs1, vs2, vm # vd[i] = +(vs1[i] * vs2[i]) - vd[i]
vfmsac.vf vd, rs1, vs2, vm # vd[i] = +(f[rs1] * vs2[i]) - vd[i]
# FP negate-(multiply-subtract-accumulator), overwrites minuend
vfnmsac.vv vd, vs1, vs2, vm # vd[i] = -(vs1[i] * vs2[i]) + vd[i]
vfnmsac.vf vd, rs1, vs2, vm # vd[i] = -(f[rs1] * vs2[i]) + vd[i]
# FP multiply-add, overwrites multiplicand
vfmadd.vv vd, vs1, vs2, vm # vd[i] = +(vs1[i] * vd[i]) + vs2[i]
vfmadd.vf vd, rs1, vs2, vm # vd[i] = +(f[rs1] * vd[i]) + vs2[i]
# FP negate-(multiply-add), overwrites multiplicand
vfnmadd.vv vd, vs1, vs2, vm # vd[i] = -(vs1[i] * vd[i]) - vs2[i]
vfnmadd.vf vd, rs1, vs2, vm # vd[i] = -(f[rs1] * vd[i]) - vs2[i]
# FP multiply-sub, overwrites multiplicand
vfmsub.vv vd, vs1, vs2, vm # vd[i] = +(vs1[i] * vd[i]) - vs2[i]
vfmsub.vf vd, rs1, vs2, vm # vd[i] = +(f[rs1] * vd[i]) - vs2[i]
# FP negate-(multiply-sub), overwrites multiplicand
vfnmsub.vv vd, vs1, vs2, vm # vd[i] = -(vs1[i] * vd[i]) + vs2[i]
vfnmsub.vf vd, rs1, vs2, vm # vd[i] = -(f[rs1] * vd[i]) + vs2[i]扩宽浮点乘加
# FP widening multiply-accumulate, overwrites addend
vfwmacc.vv vd, vs1, vs2, vm # vd[i] = +(vs1[i] * vs2[i]) + vd[i]
vfwmacc.vf vd, rs1, vs2, vm # vd[i] = +(f[rs1] * vs2[i]) + vd[i]
# FP widening negate-(multiply-accumulate), overwrites addend
vfwnmacc.vv vd, vs1, vs2, vm # vd[i] = -(vs1[i] * vs2[i]) - vd[i]
vfwnmacc.vf vd, rs1, vs2, vm # vd[i] = -(f[rs1] * vs2[i]) - vd[i]
# FP widening multiply-subtract-accumulator, overwrites addend
vfwmsac.vv vd, vs1, vs2, vm # vd[i] = +(vs1[i] * vs2[i]) - vd[i]
vfwmsac.vf vd, rs1, vs2, vm # vd[i] = +(f[rs1] * vs2[i]) - vd[i]
# FP widening negate-(multiply-subtract-accumulator), overwrites addend
vfwnmsac.vv vd, vs1, vs2, vm # vd[i] = -(vs1[i] * vs2[i]) + vd[i]
vfwnmsac.vf vd, rs1, vs2, vm # vd[i] = -(f[rs1] * vs2[i]) + vd[i]8.4向量浮点平方根、浮点倒数平方根、浮点倒数
浮点平方根
# Floating-point square root sqrt(x)
vfsqrt.v vd, vs2, vm # Vector-vector square root向量浮点倒数平方根估计指令
用于快速估算 倒数平方根的专用指令。主要用于对性能要求极高、但对精度要求稍低的场景。
# Floating-point reciprocal square-root estimate to 7 bits. estimate of 1/sqrt(x) accurate to 7 bits
vfrsqrt7.v vd, vs2, vm浮点倒数估计指令
计算的是 1/x,核心设计理念也是**"用精度换速度"**,主要用于高性能计算中的除法优化。
# Floating-point reciprocal (1/x) estimate to 7 bits.
vfrec7.v vd, vs2, vm举例:
const float32_t vec1[DATALEN] = { 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0, 11.0, 12.0, 13.0, 14.0, 15.0, 16.0 };
vfsqrt_rd = __riscv_vfsqrt_v_f32m4(op1, vl);开方
vfrsqrt7_rd = __riscv_vfrsqrt7_v_f32m4(op1, vl);倒数平方根
vfrec7_rd = __riscv_vfrec7_v_f32m4(op1, vl);倒数结果:
fsqrt result[16] = {1.000000, 1.414214, 1.732051, 2.000000, 2.236068, 2.449490, 2.645751, 2.828427, 3.000000, 3.162278, 3.316625, 3.464102, 3.605551, 3.741657, 3.872983, 4.000000}
vfrsqrt7 result[16] = {0.996094, 0.703125, 0.574219, 0.498047, 0.445312, 0.406250, 0.376953, 0.351562, 0.332031, 0.314453, 0.300781, 0.287109, 0.277344, 0.267578, 0.257812, 0.249023}
vfrec7 result[16] = {0.996094, 0.498047, 0.332031, 0.249023, 0.199219, 0.166016, 0.142578, 0.124512, 0.110840, 0.099609, 0.090820, 0.083008, 0.076660, 0.071289, 0.066406, 0.062256}8.5 向量浮点最小最大
# Floating-point minimum
vfmin.vv vd, vs2, vs1, vm # Vector-vector
vfmin.vf vd, vs2, rs1, vm # vector-scalar
# Floating-point maximum
vfmax.vv vd, vs2, vs1, vm # Vector-vector
vfmax.vf vd, vs2, rs1, vm # vector-scalar8.6 向量浮点符号注入指令
结果由操作数 A 的数值部分(绝对值)加上操作数 B 的符号位组合而成。
这组指令常用于实现取绝对值、取反、或者根据条件翻转符号等逻辑,且比传统的分支跳转指令效率更高。
# Floating-Point Sign-Injection直接注入符号。
# 结果的符号 = vs1 的符号;结果的数值 = vs2 的数值。
vfsgnj.vv vd, vs2, vs1, vm
vfsgnj.vf vd, vs2, rs1, vm # vector-scalar
# Floating-Point Sign-Injection Negative注入相反的符号。
# 结果的符号 = vs1 符号的反码;结果的数值 = vs2 的数值。
vfsgnjn.vv vd, vs2, vs1, vm
vfsgnjn.vf vd, vs2, rs1, vm # vector-scalar
# Floating-Point Sign-Injection XOR符号位进行异或(XOR)运算。
# 结果的符号 = vs1 符号 XOR vs2 符号;结果的数值 = vs2 的数值。
vfsgnjx.vv vd, vs2, vs1, vm # Vector-vector
vfsgnjx.vf vd, vs2, rs1, vm # vector-scalar两条很常用的伪指令
vfneg.v vd,vs = vfsgnjn.vv vd,vs,vs#求相反数
vfabs.v vd,vs = vfsgnjx.vv vd,vs,vs#求绝对值8.7 浮点数比较
与整数相同
# Compare equal
vmfeq.vv vd, vs2, vs1, vm # Vector-vector
vmfeq.vf vd, vs2, rs1, vm # vector-scalar
# Compare not equal
vmfne.vv vd, vs2, vs1, vm # Vector-vector
vmfne.vf vd, vs2, rs1, vm # vector-scalar
# Compare less than
vmflt.vv vd, vs2, vs1, vm # Vector-vector
vmflt.vf vd, vs2, rs1, vm # vector-scalar
# Compare less than or equal
vmfle.vv vd, vs2, vs1, vm # Vector-vector
vmfle.vf vd, vs2, rs1, vm # vector-scalar
# Compare greater than
vmfgt.vf vd, vs2, rs1, vm # vector-scalar
# Compare greater than or equal
vmfge.vf vd, vs2, rs1, vm # vector-scalar8.8 向量浮点分类
vfclass.v vd, vs2, vm # Vector-vector
if (vl > vlmax(e32, mf2)) vl = __riscv_vsetvl_e32mf2(vl);
vuint32mf2_t res;
for (size_t i = 0; i < vl; i++) {
uint32_t t = 0;
float32_t a = op1[i];
bool sub = is_subnormal(op1[i]); // false for ±0
if (a == -∞) t |= 1<<0; //负无穷 == 1 == 0x001
if (a<0 && !sub) t |= 1<<1; //负正规数 == 2 == 0x002; false for ±0.0
if (a<0 && sub) t |= 1<<2; //负非正规数(指数) == 4 == 0x004; false for ±0.0
if (a === -0.0) t |= 1<<3; //负零 == 8 == 0x008
if (a === +0.0) t |= 1<<4; //正零 == 16 == 0x010
if (a>0 && sub) t |= 1<<5; //正非正规数 == 32 == 0x020
if (a>0 && !sub) t |= 1<<6; //正正规数 == 64 == 0x040
if (a == +∞) t |= 1<<7; //正无穷 == 128 == 0x080
if (isSNaN(a)) t |= 1<<8; //信号 == 256 == 0x100
if (isQNaN(a)) t |= 1<<9; //静默 == 512 == 0x200
res[i] = t;
}
for (size_t i = vl; i < vlmax; i++) res[i] = anything();
return res;8.9向量浮点合并
基于掩码(Mask)进行数据选择 :根据掩码寄存器 v0 的状态,决定是将一个标量浮点数值写入目标向量,还是保留源向量中的原始数据。
vd[i] = v0.mask[i] ? f[rs1] : vs2[i]这意味着对于向量中的每一个元素 i:
-
当掩码为 1 时 :目标向量
vd的第i个元素会被覆盖 为标量寄存器f[rs1]的值。 -
当掩码为 0 时 :目标向量
vd的第i个元素会保留 源向量vs2的第i个元素的值vfmerge.vfm vd, vs2, rs1, v0 # vd[i] = v0.mask[i] ? f[rs1] : vs2[i]
// merge 其中op1是原向量,op2是要并入向量
rd = __riscv_vmerge_vvm_f32m4(op1, op2, mask, vl);
8.10单宽度浮点和整数类型相互转换
标志cv
vfcvt.xu.f.v vd, vs2, vm # 将浮点数转换为无符号整数.
vfcvt.x.f.v vd, vs2, vm # 将浮点数转换为有符号整数.
vfcvt.rtz.xu.f.v vd, vs2, vm # 将浮点数转换为无符号整数, 归零截断.
vfcvt.rtz.x.f.v vd, vs2, vm # 将浮点数转换为有符号整数,归零截断
vfcvt.f.xu.v vd, vs2, vm # 将无符号数转换为浮点数
vfcvt.f.x.v vd, vs2, vm # 将有符号数转换为浮点数有几种舍入类型可以选择,以下是枚举可选的参数
enum __RISCV_FRM {
__RISCV_FRM_RNE = 0, // 最近偶数舍入,默认
__RISCV_FRM_RTZ = 1, // 向0舍入, 与truncf()函数等价
__RISCV_FRM_RDN = 2, // 向下(负无穷)舍入,与floorf()函数等价
__RISCV_FRM_RUP = 3, // 向上(正无穷)舍入,与ceilf()函数等价
__RISCV_FRM_RMM = 4, // 向最大尾数舍入,与roundf()函数等价
}; 默认以RNE方式(就近舍入,中间值向偶数。当结果恰好在两个可表示值的正中间时,向最低有效位(LSB)为 0 的那个值(即偶数)舍入。)
const float32_t vec1[DATALEN] = { 16.0, 16.40, 16.5000, 16.5001, 16.9, -16.1000, -16.5000, -16.8 };
rd = __riscv_vfcvt_x_f_v_i32m2(op1, vl);//浮点转整型
结果:
res[8] = {16, 16, 16, 17, 17, -16, -16, -17}RTZ(Round Towards Zero):归零截断,与C语言的truncf()函数等价
// 归零截断,下面三种写法等价
rd = __riscv_vfcvt_rtz_x_f_v_i32m2(op1, vl);
rd = __riscv_vfcvt_x_f_v_i32m2_rm(op1, __RISCV_FRM_RTZ, vl);
truncf(vec1[i])
const float32_t vec1[DATALEN] = { 16.0, 16.40, 16.5000, 16.5001, 16.9, -16.1000, -16.5000, -16.9 };
16.000000, 16.000000, 16.000000, 16.000000, 16.000000, -16.000000, -16.000000, -16.000000,RDN(Round Down):向下取整,与floorf()函数等价
rd = __riscv_vfcvt_x_f_v_i32m2_rm(op1, __RISCV_FRM_RDN, vl);
floorf(vec1[i])
const float32_t vec1[DATALEN] = { 16.0, 16.40, 16.5000, 16.5001, 16.9, -16.1000, -16.5000, -16.9 };
res[8] = {16, 16, 16, 16, 16, -17, -17, -17}
16.000000, 16.000000, 16.000000, 16.000000, 16.000000, -17.000000, -17.000000, -17.000000,RUP(Round Up):向上取整,与ceilf()函数等价
rd = __riscv_vfcvt_x_f_v_i32m2_rm(op1, __RISCV_FRM_RUP, vl);
ceilf(vec1[i])
const float32_t vec1[DATALEN] = { 16.0, 16.40, 16.5000, 16.5001, 16.9, -16.1000, -16.5000, -16.9 };
res[8] = {16, 17, 17, 17, 17, -16, -16, -16,}
16.000000, 17.000000, 17.000000, 17.000000, 17.000000, -16.000000, -16.000000, -16.000000,RMM(Round to Nearest, ties to Max Magnitude):四舍五入,与roundf()函数等价
rd = __riscv_vfcvt_x_f_v_i32m2_rm(op1, __RISCV_FRM_RMM, vl);
roundf(vec1[i])
const float32_t vec1[DATALEN] = { 16.0, 16.40, 16.5000, 16.5001, 16.9, -16.1000, -16.5000, -16.9 };
res[8] = {16, 16, 17, 17, 17, -16, -17, -17}
16.000000, 16.000000, 17.000000, 17.000000, 17.000000, -16.000000, -17.000000, -17.000000,扩宽/缩减浮点与整数类型转换
vfwcvt.xu.f.v vd, vs2, vm # Convert float to double-width unsigned integer.
vfwcvt.x.f.v vd, vs2, vm # Convert float to double-width signed integer.
vfwcvt.rtz.xu.f.v vd, vs2, vm # Convert float to double-width unsigned integer, truncating.
vfwcvt.rtz.x.f.v vd, vs2, vm # Convert float to double-width signed integer, truncating.
vfwcvt.f.xu.v vd, vs2, vm # Convert unsigned integer to double-width float.
vfwcvt.f.x.v vd, vs2, vm # Convert signed integer to double-width float.
vfwcvt.f.f.v vd, vs2, vm # Convert single-width float to double-width float.
vfncvt.xu.f.w vd, vs2, vm # Convert double-width float to unsigned integer.
vfncvt.x.f.w vd, vs2, vm # Convert double-width float to signed integer.
vfncvt.rtz.xu.f.w vd, vs2, vm # Convert double-width float to unsigned integer, truncating.
vfncvt.rtz.x.f.w vd, vs2, vm # Convert double-width float to signed integer, truncating.
vfncvt.f.xu.w vd, vs2, vm # Convert double-width unsigned integer to float.
vfncvt.f.x.w vd, vs2, vm # Convert double-width signed integer to float.
vfncvt.f.f.w vd, vs2, vm # Convert double-width float to single-width float.
vfncvt.rod.f.f.w vd, vs2, vm # Convert double-width float to single-width float,
# rounding towards odd.9、归约指令(Reduction 指令)
规约:将一个向量寄存器中的所有"活跃"元素,通过特定的运算(如求和、求最大值、逻辑与等),缩减为一个单一的数值,并将结果存入目标向量寄存器的第0个元素中。
vd: 目标向量寄存器。运算结果会存放在vd的第0个元素中 (vd)。vs2: 源向量寄存器。这是包含多个元素、需要进行规约运算的向量。vs2[*]代表其中所有活跃的元素。vs1: 源向量寄存器。它的第0个元素 (vs1) 会作为运算的初始值或操作数之一。vm: 掩码寄存器,用于控制哪些元素参与运算。
9.1单宽度整数规约指令
操作数与结果具有相同的SEW宽度,vredsum 算术和运算可能存在溢出。
# Simple reductions, where [*] denotes all active elements:
简单归约,其中 [*] 表示所有活跃元素:
#向量求和
vredsum.vs vd, vs2, vs1, vm # vd[0] = sum( vs1[0] , vs2[*] )
#取向量最大值
vredmaxu.vs vd, vs2, vs1, vm # vd[0] = maxu( vs1[0] , vs2[*] )
vredmax.vs vd, vs2, vs1, vm # vd[0] = max( vs1[0] , vs2[*] )
#取向量最小值
vredminu.vs vd, vs2, vs1, vm # vd[0] = minu( vs1[0] , vs2[*] )
vredmin.vs vd, vs2, vs1, vm # vd[0] = min( vs1[0] , vs2[*] )
#对向量中所有元素进行按位逻辑操作
vredand.vs vd, vs2, vs1, vm # vd[0] = and( vs1[0] , vs2[*] )
vredor.vs vd, vs2, vs1, vm # vd[0] = or( vs1[0] , vs2[*] )
vredxor.vs vd, vs2, vs1, vm # vd[0] = xor( vs1[0] , vs2[*] )9.2扩宽整数规约
在求和之前,先扩宽为2SEW宽度,这样避免溢出。
# Unsigned sum reduction into double-width accumulator
vwredsumu.vs vd, vs2, vs1, vm # 2*SEW = 2*SEW + sum(zero-extend(SEW))
# Signed sum reduction into double-width accumulator
vwredsum.vs vd, vs2, vs1, vm # 2*SEW = 2*SEW + sum(sign-extend(SEW))9.3单宽度浮点数规约
# Simple reductions.
vfredosum.vs vd, vs2, vs1, vm # Ordered sum
vfredusum.vs vd, vs2, vs1, vm # Unordered sum
vfredmax.vs vd, vs2, vs1, vm # Maximum value
vfredmin.vs vd, vs2, vs1, vm # Minimum value**vfredosum与vfredusum的区别:**vfredosum是顺序的,性能较差,vfredosum指令必须按元素顺序对浮点值求和,从vs10中的标量开始,即它执行计算:vd0 = (((vs1[0] + vs2[0]) + vs2[1]) + ...) + vs2[vl-1],而vfredusum是乱序的,性能比vfredosum好,但其结果可能与标量运算结果有些小的差别,这是因为浮点运算的计算顺序可能会影响结果。
9.4扩宽浮点数规约
# Simple reductions.
vfwredosum.vs vd, vs2, vs1, vm # Ordered sum
vfwredusum.vs vd, vs2, vs1, vm # Unordered sum10、掩码指令
maski=1代表i元素参与运算,=0为不参与运算
10.1逻辑操作
后缀 .mm 表示操作数都是掩码寄存器
# 与
vmand.mm vd, vs2, vs1 # vd.mask[i] = vs2.mask[i] && vs1.mask[i]
# 与非:先做 AND 运算,然后取反。
vmnand.mm vd, vs2, vs1 # vd.mask[i] = !(vs2.mask[i] && vs1.mask[i])
# 与非:第一个源为 1 且 第二个源为 0 时,结果为 1。
vmandn.mm vd, vs2, vs1 # vd.mask[i] = vs2.mask[i] && !vs1.mask[i]
# 异或:相异即为真(1)
vmxor.mm vd, vs2, vs1 # vd.mask[i] = vs2.mask[i] ^^ vs1.mask[i]
# 或
vmor.mm vd, vs2, vs1 # vd.mask[i] = vs2.mask[i] || vs1.mask[i]
# 或非:先做 OR 运算,然后取反
vmnor.mm vd, vs2, vs1 # vd.mask[i] = !(vs2.mask[i] || vs1.mask[i])
# 或非:第一个源为 1 或 第二个源为 0 时,结果为 1。
vmorn.mm vd, vs2, vs1 # vd.mask[i] = vs2.mask[i] || !vs1.mask[i]
# 同或:相同即为真
vmxnor.mm vd, vs2, vs1 # vd.mask[i] = !(vs2.mask[i] ^^ vs1.mask[i])
void main(void)
{
uint8_t src1[2] = {0x0F, 0x73};
uint8_t src2[2] = {0xF3, 0x31};
uint8_t res[2] = {0};
size_t vl;
vl = __riscv_vsetvlmax_e16m2();
vbool8_t mask1 = __riscv_vlm_v_b8(src1, vl); // vbool的load操作
vbool8_t mask2 = __riscv_vlm_v_b8(src2, vl);
vbool8_t mask = __riscv_vmand_mm_b8(mask1, mask2, vl);
__riscv_vsm_v_b8 (res, mask, vl); // vbool的store操作
for (int i = 0; i < 2; i++) {
printf("0x%02x \r\n", res[i]);
}
}
结果:
res[2] = {0x03, 0x31} 即 0x3103 = 0x31F3 & 0x730F10.2 统计掩码寄存器中处于活跃状态数据元素的数量指令
vcpop.m rd, vs2, vmvcpop.m (Vector Count Population Mask)指令用来统计掩码寄存器中处于活跃状态数据元素的数量即掩码中bit=1的数量。
void main(void)
{
uint8_t src1[2] = {0x04, 0x73};
size_t vl;
vl = __riscv_vsetvlmax_e16m2();
vbool8_t mask1 = __riscv_vlm_v_b8(src1, vl); // vbool的load操作
unsigned long count = __riscv_vcpop_m_b8 (mask1, vl);
printf("count = %ld\r\n", count);
}
结果:
count = 6, 即 0x7304 = 0b0111 0011 0000 0100 中bit为1的个数为6。10.3 查找掩码中第一个活跃元素位置的指令
vfirst.m rd, vs2, vmvfirst.m rd, vs2, vm(Vector Find First-set Mask bit)指令从低位到高位扫描掩码寄存器,找到第一个值为 1 的 bit,并返回它的索引(下标)。
void main(void)
{
uint8_t src1[2] = {0x04, 0x73};
size_t vl;
vl = __riscv_vsetvlmax_e16m2();
vbool8_t mask1 = __riscv_vlm_v_b8(src1, vl); // vbool的load操作
unsigned long index = __riscv_vfirst_m_b8 (mask1, vl);
printf("index = %ld\r\n", index);
}
结果:
index = 2, 即0x7304 = 0b0111 0011 0000 0100 中第一个不为零元素的索引为2(0100)。说明一点:在 RISC-V 向量扩展(RVV)中,内存数据加载到寄存器时遵循 小端序(Little-Endian)规则。数组的第一个字节 src1 (值为 0x04) 会被放置在掩码寄存器的低8位 ,而第二个字节 src1 (值为 0x73) 会被放置在高8位。
索引 (Index): 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
|---- src1 ----| |---- src1 ----|
比特值 (Bit): 0 1 1 1 0 0 1 1 0 0 0 0 0 1 0 0
(0x73) (0x04)10.4 将寄存器中第一个1(之前)(的所有)bit置1,后面置0指令
vmsbf.m( Vector Mask Set-Before-First) :找到源掩码中第一个为 1 的位,将该位"之前"的所有低位都置为 1 ,而该位及其之后 的所有高位都置为 0。
vmsbf.m vd, vs2, vm
void main(void)
{
uint8_t src1[2] = {0xE0, 0x73};
size_t vl;
uint8_t res[2] = {0};
vl = __riscv_vsetvlmax_e16m2();
vbool8_t mask1 = __riscv_vlm_v_b8(src1, vl); // vbool的load操作
vbool8_t mask = __riscv_vmsbf_m_b8 (mask1, vl);
__riscv_vsm_v_b8 (res, mask, vl); // vbool的store操作
for (int i = 0; i < 2; i++) {
printf("0x%02x \r\n", res[i]);
}
}
结果:
res[2] = {0x1f, 0x00}, 即0x73E0 = 0b0111 0011 1110 0000
经过vmsbf指令后,变成 0x001F = 0b0000 0000 0001 1111vmsif.m( set-including-first mask bit):将寄存器中第一个1之前,包括这一位在内的所有bit置为1,后面置0,写入rd中。
vmsif.m vd, vs2, vm
一样的例子
结果:
res[2] = {0x3f, 0x00}, 即0x73E0 = 0b0111 0011 1110 0000
经过vmsbf指令后,变成 0x003F = 0b0000 0000 0011 1111vmsof.m (set-only-first mask bit):将寄存器中第一个1对应bit置为1,其它位为0,写入rd中
vmsof.m vd, vs2, vm
一样的例子
结果:
res[2] = {0x3f, 0x00}, 即0x73E0 = 0b0111 0011 1110 0000
经过vmsbf指令后,变成 0x003F = 0b0000 0000 0010 000010.5 计算源操作数所存储的bit的前缀和
viota.m vd, vs2, vm对源向量 vs2 的每个元素,只看它的最低有效位(LSB,即二进制第0位),统计从第0个元素开始到当前元素(该位)之前 ,这些最低位为1的次数,将统计结果写入目标向量 vd。
void main(void)
{
uint8_t src1[2] = {0x0F, 0x73};
size_t vl;
uint16_t res[16] = {0};
vl = __riscv_vsetvlmax_e16m2();
vbool8_t mask1 = __riscv_vlm_v_b8(src1, vl); // vbool的load操作
vuint16m2_t valm2 = __riscv_viota_m_u16m2 (mask1, vl);
__riscv_vse16_v_u16m2(res, valm2, vl);
for (int i = 0; i < 16; i++) {
printf("0x%02x, ", res[i]);
}
printf("\r\n");
}
结果:
res[16] = {0x00, 0x01, 0x02, 0x03, 0x04, 0x04, 0x04, 0x04, 0x04, 0x05, 0x06, 0x06, 0x06, 0x07, 0x08, 0x09},
0x730F = 0b0111 0011 0000 1111
= 9876 6654 4444 3210 10.6 索引写入寄存器
vid.v指令将每个元素的索引写入目标向量寄存器组,从0到vl-1。
vid.v vd, vm # Write element ID to destination.
void main(void)
{
size_t vl;
uint16_t res[16] = {0};
vl = __riscv_vsetvlmax_e16m2();
vuint16m2_t valm2 = __riscv_vid_v_u16m2 (vl);
__riscv_vse16_v_u16m2(res, valm2, vl);
for (int i = 0; i < 16; i++) {
printf("0x%02x, ", res[i]);
}
printf("\r\n");
}
结果:
res[16] = {0x00, 0x01, 0x02, 0x03, 0x04, 0x05, 0x06, 0x07, 0x08, 0x09, 0x0a, 0x0b, 0x0c, 0x0d, 0x0e, 0x0f},11、排列指令
11.1 向量移动至标量/标量移动至向量
整数移动
vmv.x.s:向量移动至标量
指令含义: 将向量寄存器 vs2 的第 0 号元素取出,存入标量寄存器 x[rd]。
vmv.s.x:标量移动至向量
指令含义: 将标量寄存器 x[rs1] 的值,写入到向量寄存器 vd 的第 0 号元素位置。
vmv.x.s rd, vs2 # x[rd] = vs2[0] (vs1=0) # 向量move到标量,注意:即使vstart>=vl或者vl=0,这条指令都会执行操作。
vmv.s.x vd, rs1 # vd[0] = x[rs1] (vs2=0) # 标量move到向量,注意:当vl=0时,无论vstart如何,目标向量寄存器组中都不会更新任何元素。浮点移动
vfmv.f.s:向量浮点至标量浮点寄存器
指令含义: 将向量寄存器 vs2 的第 0 号元素(浮点数),取出并存入标量浮点寄存器 f[rd]。
vfmv.s.f:标量浮点移动至向量寄存器
指令含义: 将标量浮点寄存器 f[rs1] 的值,写入到向量寄存器 vd 的第 0 号元素位置。
vfmv.f.s rd, vs2 # f[rd] = vs2[0] (rs1=0)
vfmv.s.f vd, rs1 # vd[0] = f[rs1] (vs2=0)后缀含义
| 缩写/后缀 | 全称 | 含义 | 对应硬件资源 |
|---|---|---|---|
| v | Vector | 向量指令前缀 | 向量寄存器组 (v0-v31) |
| x | x-register | 整数标量 | 通用寄存器 (x0-x31) |
| f | f-register | 浮点标量 | 浮点寄存器 (f0-f31) |
| s | Scalar | 标量元素 | 向量寄存器的第 0 号元素 (vi0) |
| i | Immediate | 立即数 | 指令中直接包含的常数 (如 vmv.v.i) |
相关内联函数
其中倒数第一个字母代表数据的src,倒数第二个字母代表dst
# 整数类型
vint32m4_t __riscv_vmv_v_v_i32m4 (vint32m4_t src, size_t vl);#向量到向量复制
#标量扩展(广播)到整个向量。把标量整数 src 的值写入目标向量的前 vl 个元素。
vint32m4_t __riscv_vmv_v_x_i32m4 (int32_t src, size_t vl);
#提取向量的第 0 个元素到标量寄存器。
int32_t __riscv_vmv_x_s_i32m4_i32 (vint32m4_t src);
#只修改向量的第 0 个元素(其他元素保持不变)。把目标向量的第 0 个元素设为标量 src,索引 ≥ 1 的元素保留之前的值不变。
vint32m4_t __riscv_vmv_s_x_i32m4 (int32_t src, size_t vl);
#浮点类型
vfloat32m4_t __riscv_vmv_v_v_f32m4 (vfloat32m4_t src, size_t vl);#向量到向量复制
vfloat32m4_t __riscv_vfmv_v_f_f32m4 (float32_t src, size_t vl);#浮点标量广播到整条向量。
float32_t __riscv_vfmv_f_s_f32m4_f32 (vfloat32m4_t src);#提取浮点向量的第 0 个元素到标量浮点寄存器。
vfloat32m4_t __riscv_vfmv_s_f_f32m4 (float32_t src, size_t vl);#只修改浮点向量的第 0 个元素,其余保留。示例
int32_t vec1[DATALEN] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16 };
int32_t res[DATALEN] = {0};
vint32m4_t vx, vy, vz, vs;
vl = __riscv_vsetvl_e32m4(DATALEN);
// vmv.v.v
vx = __riscv_vle32_v_i32m4(vec1, vl);
// vmv.v.v
vy = __riscv_vmv_v_v_i32m4 (vx, vl);
// vmv.v.x
vz = __riscv_vmv_v_x_i32m4 (100, vl);
// vmv.s.x
vs = __riscv_vmv_s_x_i32m4 (200, vl);
结果:
// vmv.v.v
vy[16] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,}
// vmv.v.x
vz[16] = {100, 100, 100, 100, 100, 100, 100, 100, 100, 100, 100, 100, 100, 100, 100, 100,}
// vmv.x.s
s0 = 1
// vmv.s.x
vs[16] = {200, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,}11.2 向量拷贝
指令的通用形式为 vmv<nr>r.v vd, vs2:
-
vmv: 代表 Vector Move(向量移动)。 -
<nr>: 代表 Number of Registers(寄存器数量)。它告诉硬件需要拷贝多少个连续的寄存器。 -
r: 表示操作对象是寄存器(register)。 -
vd: 目的寄存器组的首地址(Destination)。 -
vs2: 源寄存器组的首地址(Source)。Copy v1=v2:将源寄存器 v2 的内容拷贝到目的寄存器 v1。
vmv1r.v v1, v2
Copy v10=v12; v11=v13:将源寄存器组 (v12, v13) 的内容分别拷贝到目的寄存器组 (v10, v11)。即:v10=v12, v11=v13
vmv2r.v v10, v12
Copy v4=v8; v5=v9; v6=v10; v7=v11:将源寄存器组 (v8, v9, v10, v11) 的内容拷贝到目的寄存器组 (v4, v5, v6, v7)。即:v4=v8, v5=v9, v6=v10, v7=v11。
vmv4r.v v4, v8
Copy v0=v8; v1=v9; ...; v7=v15:将源寄存器组 (v8...v15) 的内容拷贝到目的寄存器组 (v0...v7)。即:v0=v8, v1=v9, ..., v7=v15。
vmv8r.v v0, v8
11.3 向量滑动指令
向量向高索引移动
vslideup :把源向量 vs2 中的每个元素向右(高索引方向)移动 固定的偏移量,然后写入目标向量 vd。
vslideup.vx vd, vs2, rs1, vm # vd[i+rs1] = vs2[i]
vslideup.vi vd, vs2, uimm, vm # vd[i+uimm] = vs2[i]
#define DATALEN 16
int main(void)
{
int32_t vec1[DATALEN] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16};
int32_t res[DATALEN] = {0};
size_t vl;
vint32m4_t vx;
vl = __riscv_vsetvl_e32m4(DATALEN);
vx = __riscv_vle32_v_i32m4(vec1, vl);
vx = __riscv_vslideup_vx_i32m4 (vx, vx, 3, vl);
__riscv_vse32_v_i32m4(res, vx, vl);
for (int i = 0; i < DATALEN; i++) {
printf("%d, ", res[i]);
}
printf("\r\n");
}
结果:
res[16] = {1, 2, 3, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13}; // 向上移动了3个元素,低位的3个元素保持不变
// 调整 vl = 3
vx = __riscv_vslideup_vx_i32m4 (vx, vx, 3, 3);
// 打印结果为:
res[16] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16}; // 向上移动了3个元素
// 调整 vl = 4
vx = __riscv_vslideup_vx_i32m4 (vx, vx, 3, 4);
// 打印结果为:
res[16] = {1, 2, 3, 1, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16}; // 向上移动了3个元素
// 调整 vl = 8
vx = __riscv_vslideup_vx_i32m4 (vx, vx, 3, 8);
// 打印结果为:
res[16] = {1, 2, 3, 1, 2, 3, 4, 5, 9, 10, 11, 12, 13, 14, 15, 16}; // 向上移动了3个元素
// 调整 vl = 16
vx = __riscv_vslideup_vx_i32m4 (vx, vx, 3, 16);
// 打印结果为:
res[16] = {1, 2, 3, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13}; // 向上移动了3个元素vslide1up:slide1up是vslideup指令的特殊情况,只向上(右)移动一个元素,但是允许在空出的元素位置(一次数据操作的第一位)插入一个标量元素。
vslide1up.vx vd, vs2, rs1, vm # vd[0]=x[rs1], vd[i+1] = vs2[i]
vfslide1up.vf vd, vs2, rs1, vm # vd[0]=f[rs1], vd[i+1] = vs2[i]
int32_t vec1[DATALEN] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16};
vx = __riscv_vslide1up_vx_i32m4 (vx, 99, vl);
结果:
res[16] = { 99, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15}; // 可见低位补充了元素99
// 调整 vl = 4
vx = __riscv_vslide1up_vx_i32m4 (vx, 99, 4);
// 打印结果为:
res[16] = {99, 1, 2, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,}向量向低索引移动
vslidedown :把源向量 vs2 中的元素向左(低索引方向)移动 固定的偏移量,写入目标向量 vd。
vslidedown.vx vd, vs2, rs1, vm # vd[i] = vs2[i+rs1]
vslidedown.vi vd, vs2, uimm, vm # vd[i] = vs2[i+uimm]举例
int32_t vec1[DATALEN] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16};
vx = __riscv_vslidedown_vx_i32m4 (vx, 3, vl);
res[16] = {4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 0, 0, 0};
// 调整 vl = 3
vx = __riscv_vslidedown_vx_i32m4 (vx, vx, 3, 3);
// 打印结果为:
res[16] = {4, 5, 6, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16}; // 向下移动了3个元素
// 调整 vl = 4
vx = __riscv_vslidedown_vx_i32m4 (vx, vx, 3, 4);
// 打印结果为:
res[16] = {4, 5, 6, 7, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,}; // 向下移动了3个元素
// 调整 vl = 8
vx = __riscv_vslidedown_vx_i32m4 (vx, vx, 3, 8);
// 打印结果为:
res[16] = {4, 5, 6, 7, 8, 9, 10, 11, 9, 10, 11, 12, 13, 14, 15, 16,}; // 向下移动了3个元素
// 调整 vl = 16
vx = __riscv_vslidedown_vx_i32m4 (vx, vx, 3, 16);
// 打印结果为:
res[16] = {4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 0, 0, 0,}; // 向下移动了3个元素slide1down:slide1down是slide1down指令的特殊情况,只向下(左)移动一个元素,但是允许在空出的元素位置(一次数据操作的最后一位)插入一个标量元素。
vslide1up.vx vd, vs2, rs1, vm # vd[0]=x[rs1], vd[i+1] = vs2[i]
vfslide1up.vf vd, vs2, rs1, vm # vd[0]=f[rs1], vd[i+1] = vs2[i]
int32_t vec1[DATALEN] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16};
vx = __riscv_vslide1down_vx_i32m4 (vx, 99, vl);
结果:
res[16] = { 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 99}; // 可见高位补充了元素99
// 调整 vl = 4
vx = __riscv_vslide1down_vx_i32m4 (vx, 99, 4);
// 打印结果为:
res[16] = {2, 3, 4, 99, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,}11.4 向量收集指令
vrgather指令按照索引向量 vs1 提供的下标,从数据向量 vs2 中挑出元素,写入目标 vd。如果某个下标越界,对应位置填 0。
vrgather.vv vd, vs2, vs1, vm # vd[i] = (vs1[i] >= VLMAX) ? 0 : vs2[vs1[i]];
vrgatherei16.vv vd, vs2, vs1, vm # vd[i] = (vs1[i] >= VLMAX) ? 0 : vs2[vs1[i]];示例
#define DATALEN 16
void main(void)
{
int32_t vec1[DATALEN] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16 };
// 与 index load&store不同
uint32_t index[DATALEN] = { 5, 5, 5, 5, 5, 5, 5, 5, 11, 11, 11, 11, 15, 15, 15, 15 };
int32_t res[DATALEN] = {0};
size_t vl;
vint32m4_t vx;
vuint32m4_t vy;
vl = __riscv_vsetvl_e32m4(DATALEN);
vx = __riscv_vle32_v_i32m4(vec1, vl);
vy = __riscv_vle32_v_u32m4(index, vl);
vx = __riscv_vrgather_vv_i32m4 (vx, vy, vl);
__riscv_vse32_v_i32m4(res, vx, vl);
for (int i = 0; i < DATALEN; i++) {
printf("%d, ", res[i]);
}
printf("\r\n");
}
结果:
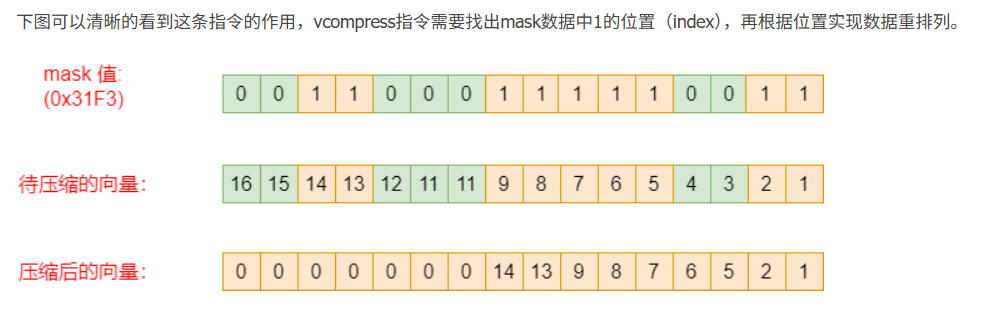
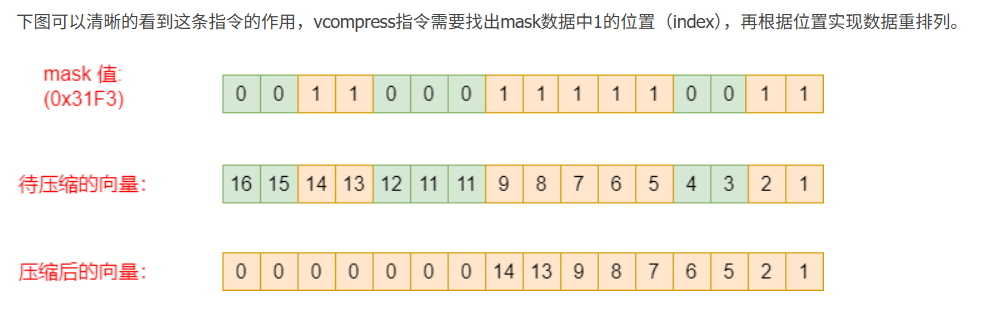
res[16] = { 6, 6, 6, 6, 6, 6, 6, 6, 12, 12, 12, 12, 16, 16, 16, 16,}; // 相当于在向量寄存器里索引11.5 向量压缩指令
vcompress向量压缩指令允许从源向量寄存器(vs2)中挑选出由向量掩码寄存器(vs1)标记的元素打包到目标向量寄存器(vd)开始处,简单来说:compress指令用于将数据中某些数据"剔除",实现数据压缩。
vcompress.vm vd, vs2, vs1 # Compress into vd elements of vs2 where vs1 is enabled
#define DATALEN 16
void main(void)
{
int32_t vec1[DATALEN] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16 };
uint8_t compress_t[2] = {0xF3, 0x31};
int32_t res[DATALEN] = {0};
size_t vl;
vint32m4_t vx;
vbool8_t mask;
vl = __riscv_vsetvl_e32m4(DATALEN);
mask = __riscv_vlm_v_b8(compress_t, vl);
vx = __riscv_vle32_v_i32m4(vec1, vl);
vx = __riscv_vcompress_vm_i32m4 (vx, mask, vl);
__riscv_vse32_v_i32m4(res, vx, vl);
for (int i = 0; i < DATALEN; i++) {
printf("%d, ", res[i]);
}
printf("\r\n");
}
结果:
res[16] = { 1, 2, 5, 6, 7, 8, 9, 13, 14, 0, 0, 0, 0, 0, 0, 0,};