监督学习核心算法:单变量线性回归
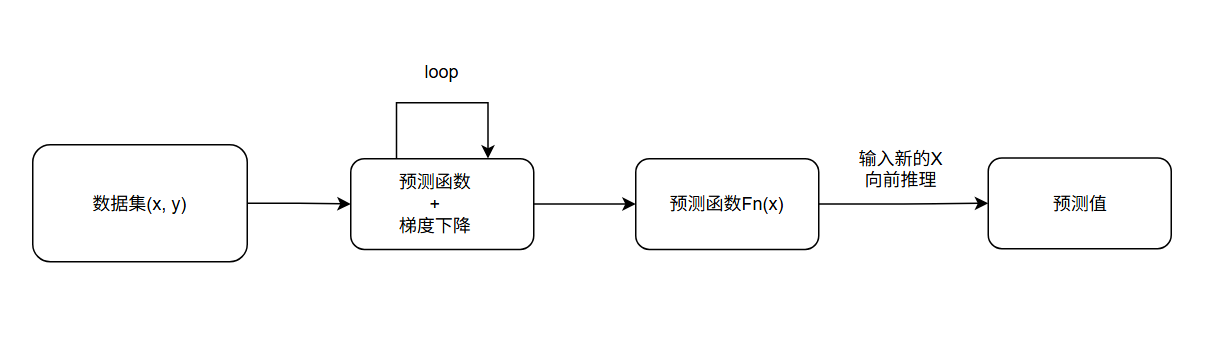
前言
在文章监督学习与无监督学习中我们讲述了什么是监督学习与无监督学习,监督学习的本质就是找到所谓的 X->Y 的映射函数,而线性回归算法是监督学习的一种核心算法,也可以称为是一个最小的算法单元,是整个机器学习的地基。
这里是整个线性模型回归的流程,下面将会围绕流程来讲解!
一、线性回归是什么?
1.1核心定义
将线性回归拆解成两个词分别是线性 与回归,将这两个词分开解释如下:
线性: 我们常说过,X与Y是呈线性关系,我们可以用一条直线或者曲线来拟合这两者的关系,从而得到一个强联系的XY函数。
回归: 回归是在线性的基础上进行的,使用线性得到的函数,对已知的X预测出Y,这就是回归,将得到的用回来。
1.2 模型公式 fn = θ1 + θ2X
单变量线性回归的核心方程为:fn = θ2 + θ1X ,这里的参数在下面解释,我们可以将这个公式看为更为熟悉的一元一次方程:h(x) = wx + b = y。
| 符号 | 课程对应名称 | 通俗意义 | 物理含义 |
|---|---|---|---|
| x | 特征(Feature) | 题目 | 输入的已知数据,比如房屋面积 |
| y | 标签(Label) | 标准答案 | 真实的结果,比如房屋的真实房价 |
| fn、h(x) | 假设函数(Hypothesis) | 模型的预测答案 | 模型根据 x 输出的预测值,也就是 AI 的前向推理结果 |
| w(θ1) | 权重(Weight) | 直线的斜率 | x 每变化 1 个单位,y 的变化幅度 |
| b(θ2) | 偏置(Bias) | 直线的截距 | 当 x=0 时,y 的基础值 |
注意:所谓的线性方程,并不是只能拟合直线,同样可以拟合曲线,但是必须是保存一元一次的θ1、θ2,举个例子:h(x) = w·x² + b 依然是线性回归,因为 w 和 b 是一次的;但 h(x) = w²·x + b 就不是线性回归,因为参数 w 是二次的。
二、如何评判模型的好坏?
上面我们说了有公式 h ( x ) = w x + b h(x)=wx+b h(x)=wx+b,来拟合我们的数据,在平时做题的过程中,我们可以想象这个函数大概在哪一个斜率上可以高度拟合,但是对于计算机来说,计算机并不会跟人一样想象,所以计算机需要去找到最合适的 w w w与 b b b。这就需要一个「量化评分标准」,来告诉我们当前的 w 和 b,让模型预测的误差有多大 ------ 这个标准,就是代价函数(Cost Function)。
2.1 均方误差公式
均方误差公式 是线性规划模型里面常用且经典的代价函数,其形式如下并解释其含义:
J ( w , b ) = 1 2 m ∑ i = 1 m ( h ( x ( i ) ) − y ( i ) ) 2 J(w, b) = \frac{1}{2m}\sum_{i=1}^{m}{(h(x^{(i)}) - y^{(i)})}^2 J(w,b)=2m1∑i=1m(h(x(i))−y(i))2
| J ( w , b ) J(w, b) J(w,b) | 代价函数(Cost Function) |
|---|---|
| m m m | 样本数据中的样本个数 |
| i i i | 第i个样本数据 |
| h ( x ( i ) ) − y ( i ) h(x^{(i)}) - y^{(i)} h(x(i))−y(i) | 第 i 个样本的「预测值 - 真实值」,也就是单条数据的预测误差 |
| 1 m ∑ i = 1 m ( h ( x ( i ) ) − y ( i ) ) 2 \frac{1}{m}\sum_{i=1}^{m}{(h(x^{(i)}) - y^{(i)})}^2 m1∑i=1m(h(x(i))−y(i))2 | 所有的误差的平均值,平方的意义在于去除负数 |
| 1 2 \frac{1}{2} 21 | 1 2 \frac{1}{2} 21 用于后面的求导方便 |
2.2 公式的直观理解
如图,基于以下数据( x x x:房屋面积, y y y:房屋价格),构建了图标,并找到最合适的也就是最拟合的函数 f ( x ) = w x + b f(x) =wx+b f(x)=wx+b的 w w w与 b b b值。
x = [1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0]
y = [0.52, 0.98, 1.53, 2.01, 2.47, 3.05, 3.49, 4.02, 4.48, 5.03]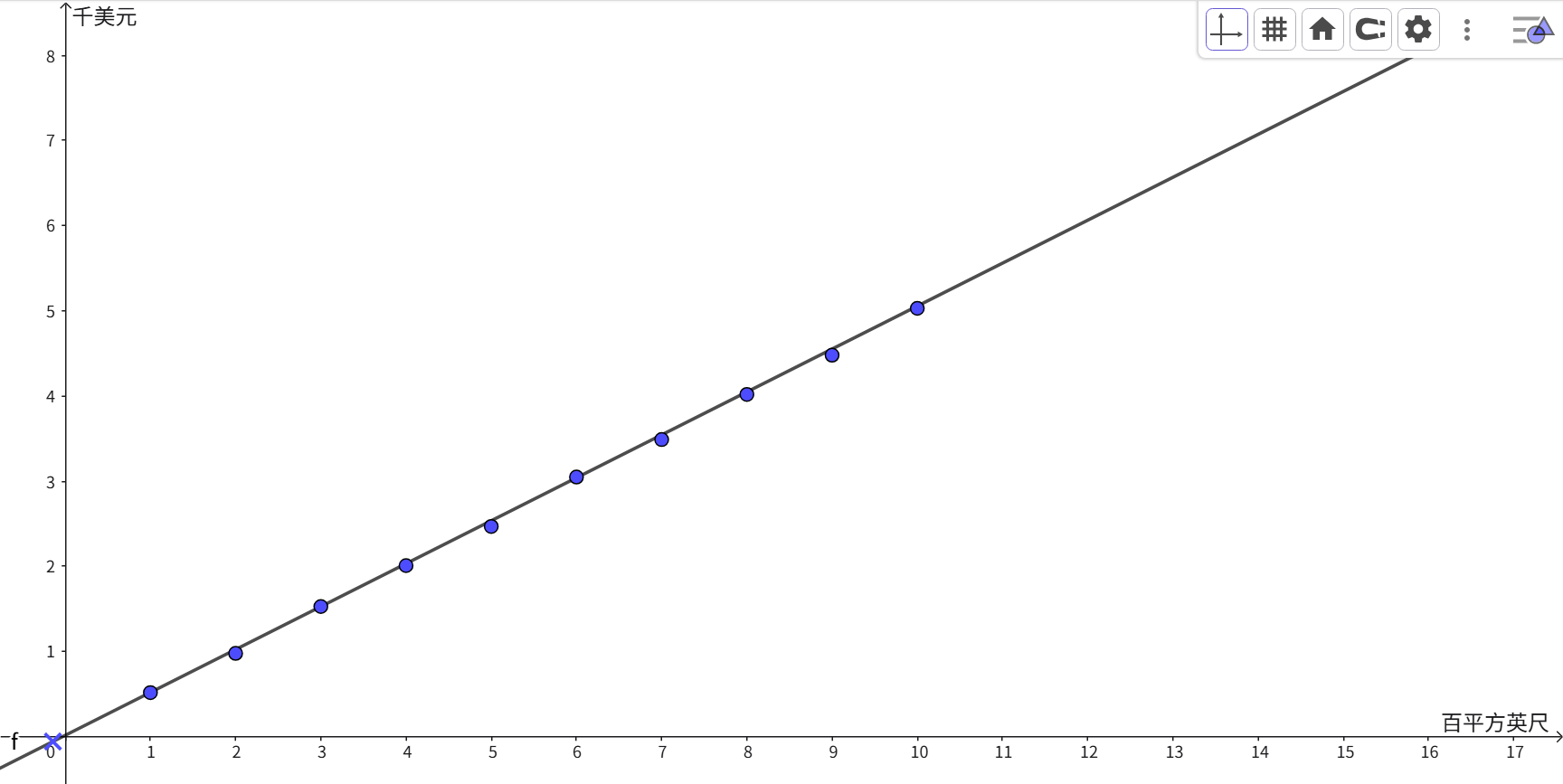
当我们不断的调整线段的 w w w与 b b b的值,寻找到最小的 J ( w , b ) J(w, b) J(w,b),此时拟合程度最好!
三、怎么让模型自动找到最优参数?
有了代价函数,我们的目标就非常明确了:找到一组 w 和 b,让 J(w,b) 的值最小。
而实现这个目标的核心算法,就是梯度下降(Gradient Descent)------ 它是几乎所有机器学习、深度学习模型训练的核心逻辑,必须彻底吃透。
3.1 基础数学知识
梯度:
梯度是多元可微函数在某一点处,描述函数值增长最快的方向、以及对应最大增长速率的向量,是一元函数导数在多元场景下的核心推广,本质是一个有方向、有大小的向量,而非单个数值。
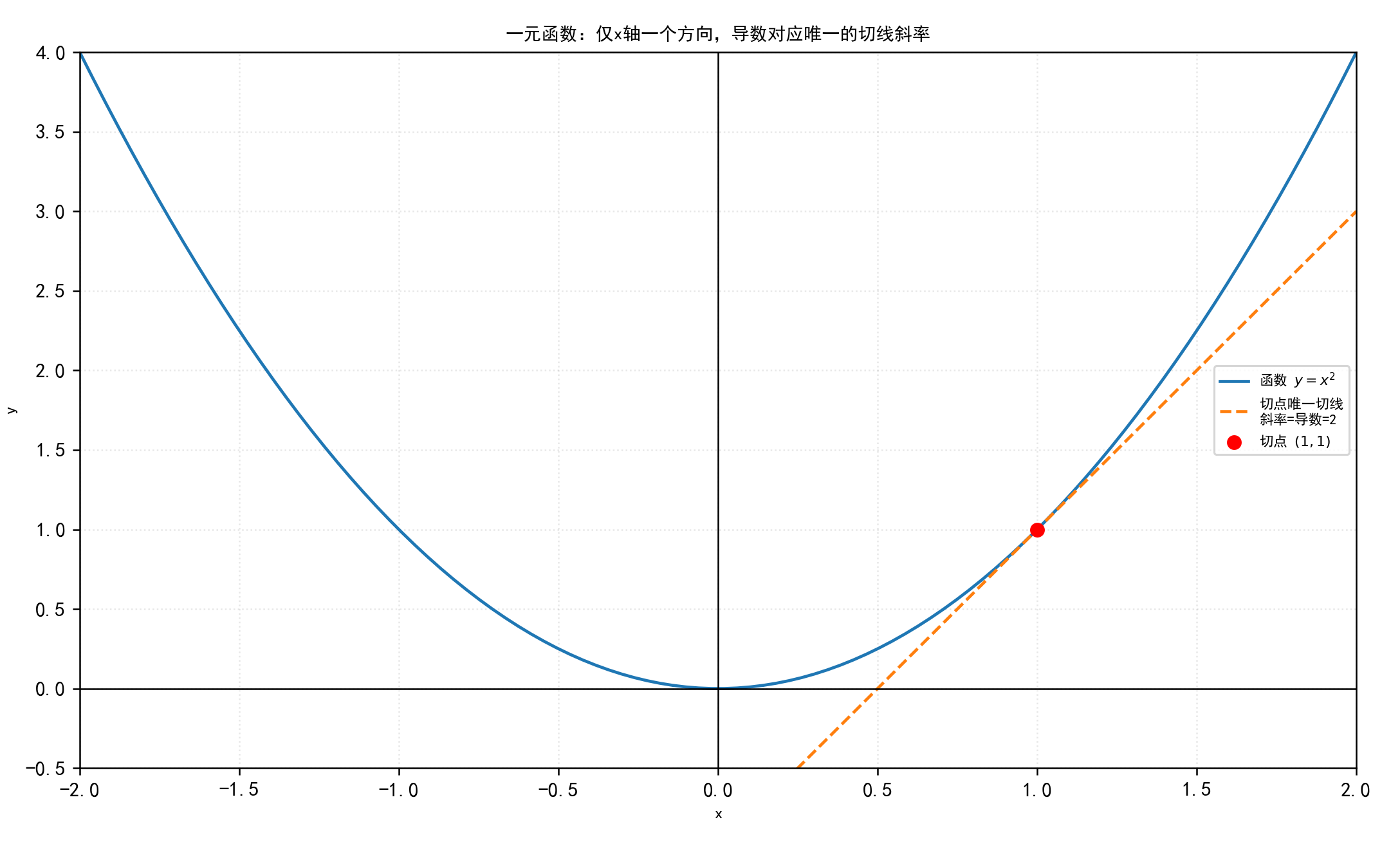
一元函数 y = f ( x ) y=f(x) y=f(x)中,导数 f ' ( x ) f'(x) f'(x)是函数在该点的瞬时变化率,因为只有 x x x 轴这一个方向,所以是个标量。
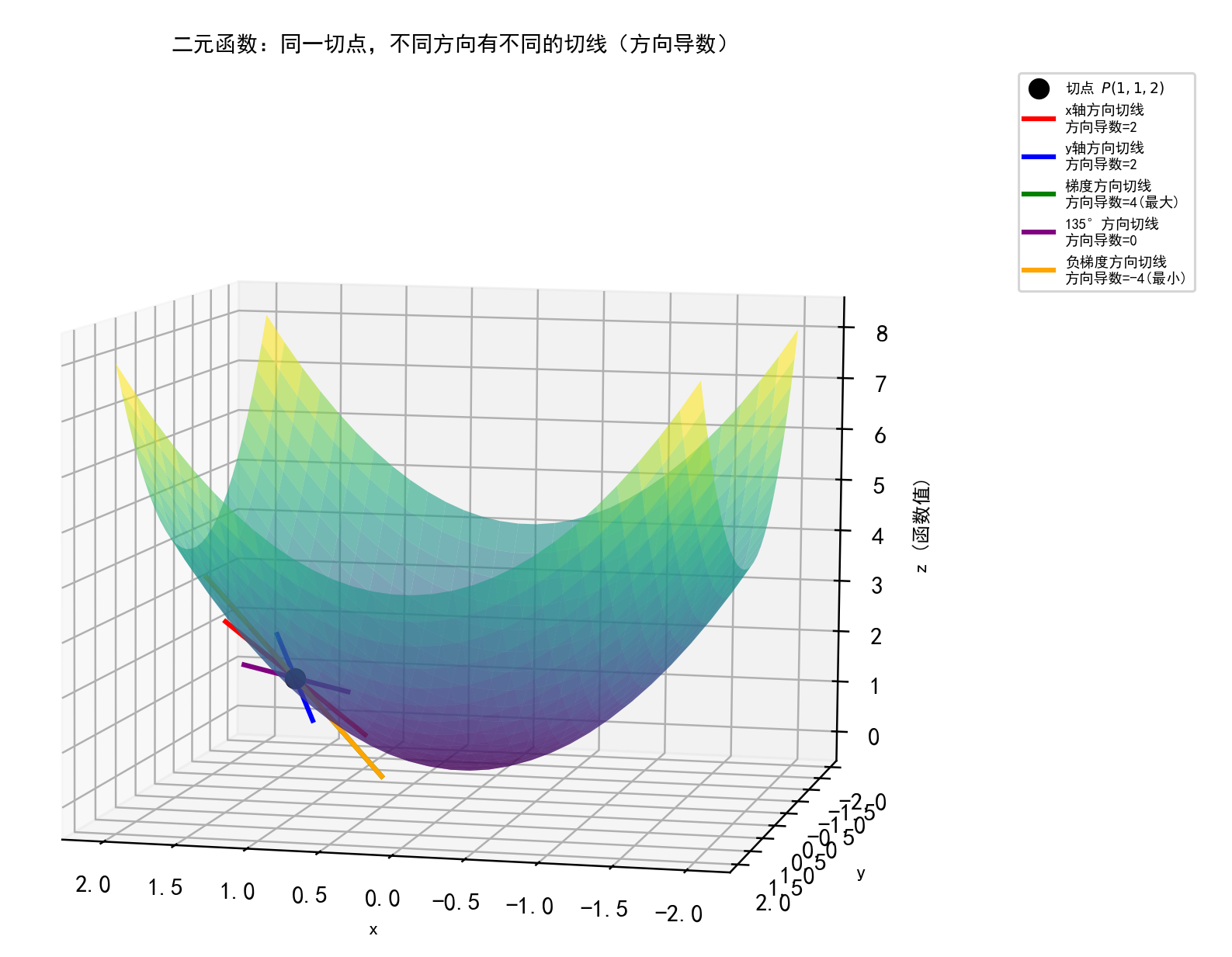
但多元函数(比如二元函数 z = f ( x , y ) z=f(x,y) z=f(x,y),对应空间中的一个曲面),在一个点上有无数个方向,每个方向都有对应的变化率(方向导数)。梯度就是从这无数个方向里,挑出函数值增长最快的那个方向 ,并把这个方向和对应的最大变化率打包成的向量。如图,绿色切线则上升最快,橙色切线下降最快!
3.2 J ( w , b ) J(w, b) J(w,b)的梯度下降
所谓的梯度下降,我们用来找到最合适的 w w w与 b b b,我们可以使用下山来比喻:
你现在站在一座山的任意一个位置,想要最快走到山的最低点(山谷),你会怎么做?
答案是:每一步都朝着当前位置最陡的下坡方向走,走一步停一下,重新找最陡的方向,再走一步,直到走到山谷。
对应到线性回归里:
- 山的高度 = 代价函数
J(w,b)的值 - 你的位置 = 当前的 w w w 和 b b b 的值
- 最陡的下坡方向 = 代价函数对 w w w 和 b b b 的 梯度(导数) 的反方向
- 每一步走多远 = 学习率(Learning Rate)α
3.2 核心公式:参数更新规则
找到最合适的 w w w与 b b b,我们需要偏导函数,也就是说分别对 w w w与 b b b在 J ( w , b ) J(w, b) J(w,b)函数中进行倒数,然后慢慢的下降,公式分别如下:
w w w梯度下降函数 : w = w − α ⋅ ∂ j ( w , b ) ∂ w w=w−α⋅\frac{\partial j(w,b)}{\partial w} w=w−α⋅∂w∂j(w,b)
b b b梯度下降函数: w = w − α ⋅ ∂ j ( w , b ) ∂ b w=w−α⋅\frac{\partial j(w,b)}{\partial b} w=w−α⋅∂b∂j(w,b)
这里我们分别对 w w w b b b做偏导,让这两个变量在不同的方向找到最佳的下降方向,其过程如图所示:
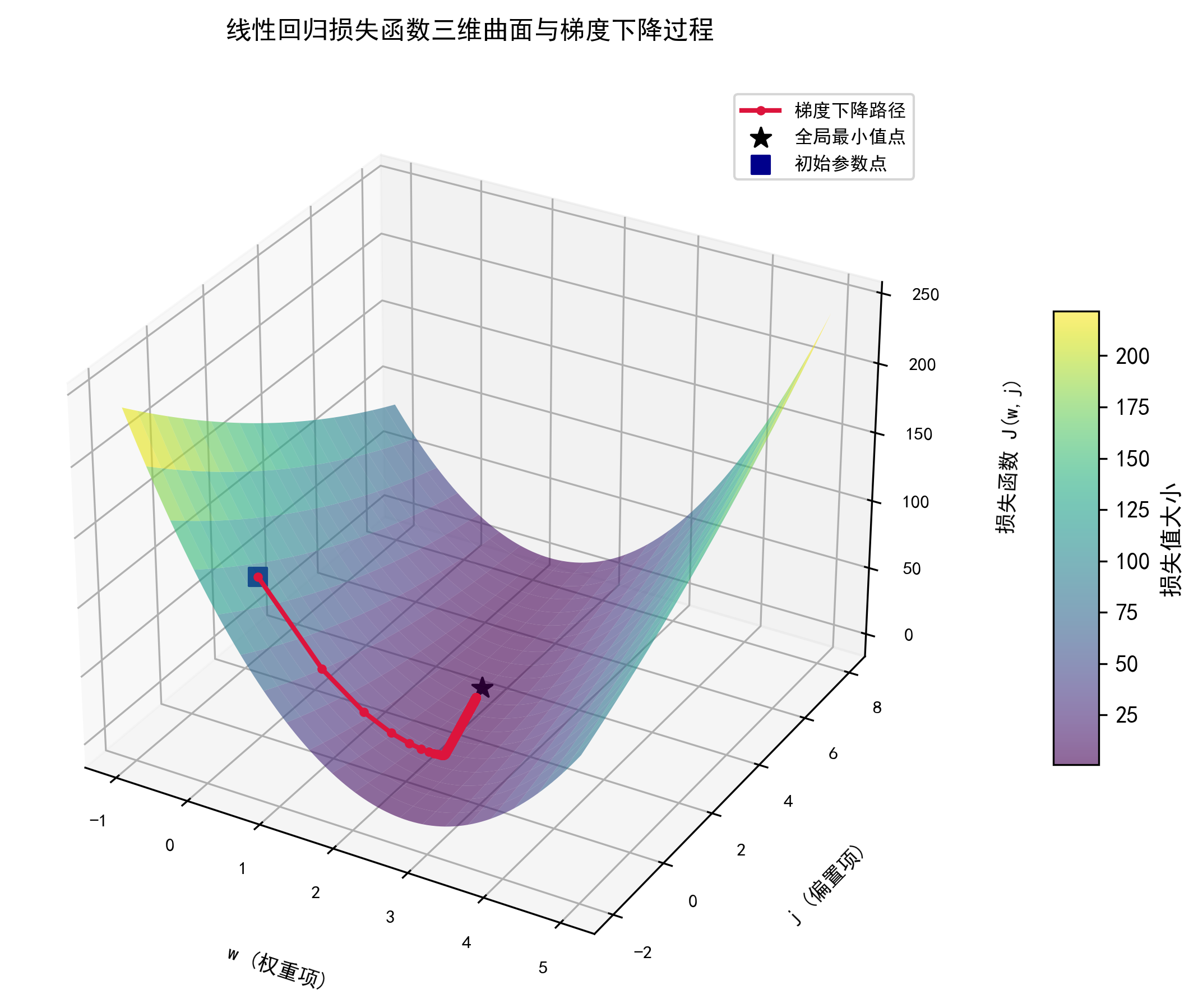
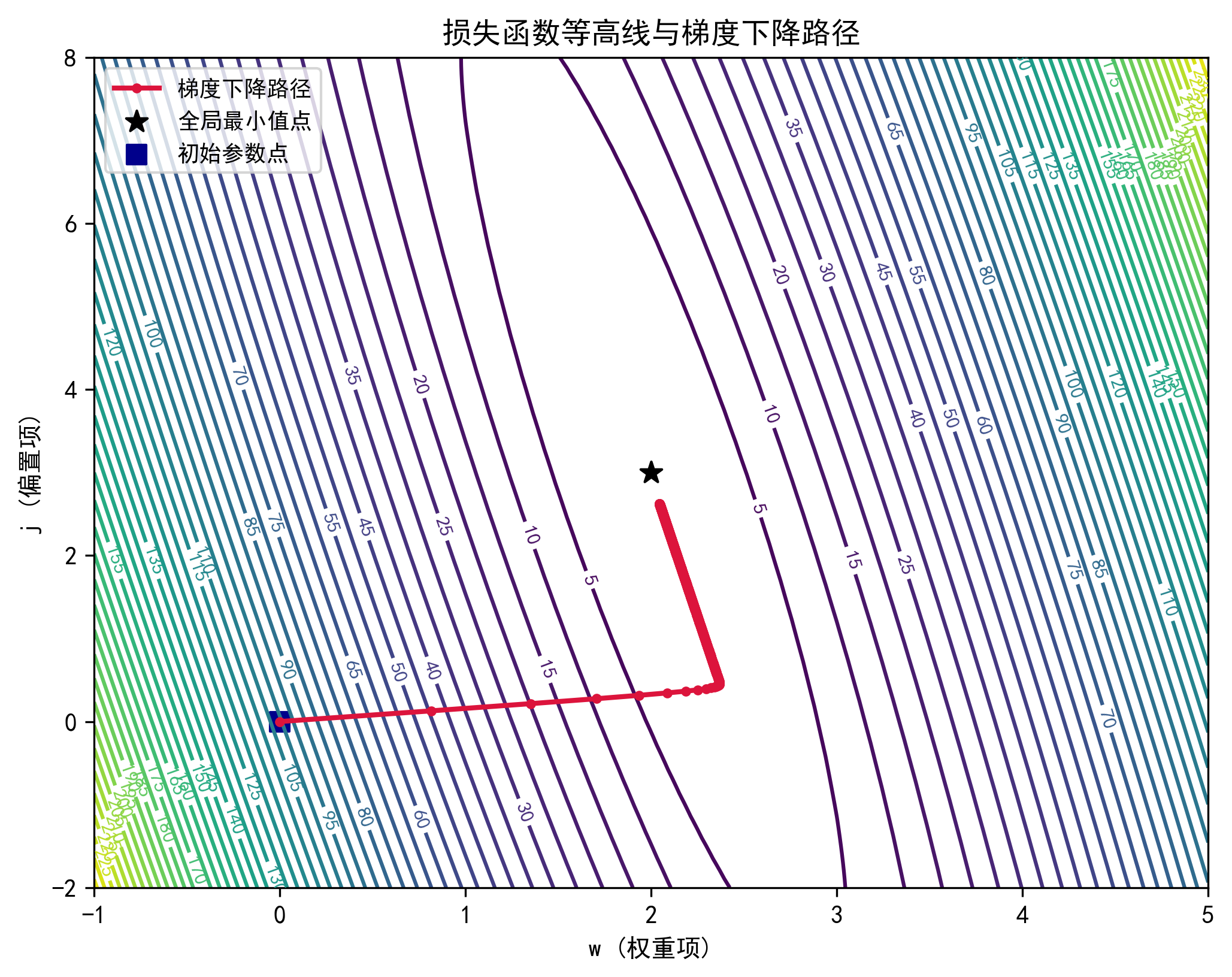
根据等高图,我们更可以解释梯度下降就是找到一个最低的点,此时我们的 j ( w , b ) j(w,b) j(w,b)函数达到最小值!
3.3 梯度下降的几种方式
3.4 两个核心参数的避坑指南
(1)学习率 α
学习率决定了梯度下降每一步走多远,是梯度下降能否收敛的核心:
- α 太小:每一步走的距离太短,收敛速度极慢,要迭代成千上万次才能走到最低点
- α 太大:一步跨出去直接越过了最低点,甚至会越走越高,导致代价函数不降反升,最终无法收敛
吴恩达课程里给了最佳实践:先尝试 0.001、0.01、0.1、1 这几个数量级的学习率,观察每一轮迭代的代价值,只要代价持续下降,就是合适的学习率。
(2)参数同步更新(重点!我踩过的坑)
这里是新手最容易写错的地方,也是梯度下降数学正确性的核心:必须先算完 w 和 b 的完整梯度,再同步更新两个参数。
✅ 正确逻辑:
- 用当前的旧 w w w 和旧 b b b,计算出所有样本的误差,算出 d w dw dw 和 d b db db 的完整值
- 用 d w dw dw 更新新 w w w,用 d b db db 更新新 b b b
- 整个过程中,计算梯度用的始终是同一组旧参数, w w w 的更新不会影响 b b b 的梯度计算,反之亦然
❌ 错误逻辑:
先更新 w w w,再用更新后的新 w w w 去计算 b b b 的梯度,再更新 b b b------ 这会导致 b b b 的梯度被新 w w w 污染,不符合梯度下降的数学定义,模型大概率无法正确收敛。
四、Python简单实现
python
def forward(x, w, b):
return w*x + b
def cost_function(xSet, ySet, w, b):
m = len(xSet)
total_cost = 0.0
for i in range(m):
tmp = forward(xSet[i], w, b) - ySet[i]
total_cost += tmp * tmp
return total_cost / (2 * m)
def gradient_descent(xSet, ySet, w, b, learning_rate):
m = len(xSet)
dw = 0.0
db = 0.0
for i in range(m):
tmp = forward(xSet[i], w, b) - ySet[i]
dw += tmp * xSet[i]
db += tmp
dw /= m
db /= m
w -= learning_rate * dw
b -= learning_rate * db
return w, b
if __name__ == "__main__":
# 1. 准备测试数据集(y = 2x)
x = [1.0, 2.0, 3.0, 4.0, 5.0]
y = [2.0, 4.0, 6.0, 8.0, 10.0]
# 2. 初始化参数
w = 0.0
b = 0.0
learning_rate = 0.05
epochs = 2000
# 3. 开始训练
print("===== 开始训练 =====")
for i in range(epochs):
w, b = gradient_descent(x, y, w, b, learning_rate)
# 每50轮打印一次
if i % 50 == 0:
cost = cost_function(x, y, w, b)
print(f"迭代:{i:4d} | 损失:{cost:.6f} | w:{w:.4f} | b:{b:.4f}")
# 4. 训练完成,预测
print("\n===== 训练完成 =====")
print(f"最终模型:y = {w:.4f} * x + {b:.4f}")
test_x = 6.0
pred_y = forward(test_x, w, b)
print(f"输入 x={test_x:.1f},预测 y={pred_y:.4f}")五、C++简单实现
cpp
#include <iostream>
#include <vector>
#include <cmath>
// 向前传递函数
float Forward(const float x_i, const float w, const float b) {
return w * x_i + b;
}
// 代价函数(均方误差函数)
float ComputeCost(const std::vector<float>& xSet, const std::vector<float>& ySet, const float w, const float b) {
int m = static_cast<int>(xSet.size());
float total = 0.0f;
for (int i = 0; i < m; i++) {
float tmp = Forward(xSet[i], w, b) - ySet[i];
total += tmp * tmp;
}
return total / (2 * m);
}
//梯度下降函数(批量梯度下降)
std::pair<float, float> GradientDescentStep(const std::vector<float>& xSet, const std::vector<float>& ySet
, float w, float b, const float learning_rate) {
int m = static_cast<int>(xSet.size());
float dw = 0.0f, db = 0.0f;
for (int i = 0; i < m; i++) {
float forwordResult = Forward(xSet[i], w, b) - ySet[i];
dw += forwordResult * xSet[i];
db += forwordResult;
}
// 计算平均值
dw /= m;
db /= m;
// 梯度下降
w -= dw * learning_rate;
b -= db * learning_rate;
return { w,b };
}
// 指定小数位判断相等
bool IsEqual(float a, float b, int site) {
float scale = 1.0f;
for (int i = 0; i < site; i++)
scale *= 10;
return std::trunc(a * scale) == std::trunc(b * scale);
}
// ===================== 测试主函数 =====================
int main() {
// 1. 准备测试数据集(简单线性关系:y = 2x)
std::vector<float> x = { 1.0, 2.0, 3.0, 4.0, 5.0 };
std::vector<float> y = { 2.0, 4.0, 6.0, 8.0, 10.0 };
// 2. 初始化参数
float w = 0.0f; // 初始权重
float b = 0.0f; // 初始偏置
float lr = 0.05f; // 学习率
int epochs = 5000; // 训练迭代次数
// 3. 开始梯度下降训练
std::cout << "===== 开始训练 =====" << std::endl;
for (int i = 0; i < epochs; i++) {
// 单步更新参数
auto [new_w, new_b] = GradientDescentStep(x, y, w, b, lr);
if (IsEqual(w, new_w, 7) && IsEqual(b, new_b, 8)) {
printf("%d次训练结束,w与b不再变化,w = %.4f,b = %.4f。\n", i, w, b);
break;
}
w = new_w;
b = new_b;
// 每50轮打印一次训练结果
if (i % 50 == 0) {
float cost = ComputeCost(x, y, w, b);
printf("迭代%4d次 | 损失: %.6f | w: %.4f | b: %.4f\n", i, cost, w, b);
}
}
// 4. 训练完成,用模型预测
std::cout << "\n===== 训练完成 =====" << std::endl;
printf("最终模型:y = %.4f * x + %.4f\n", w, b);
// 测试预测 x=6
float test_x = 6.0f;
float pred_y = Forward(test_x, w, b);
printf("输入x=%.1f,预测y=%.4f\n", test_x, pred_y);
return 0;
}六、线性回归对 AI 工程化的核心意义(AI)
很多人会问:线性回归这么简单,和我要学的 AI 部署有什么关系?
答案是:线性回归的核心逻辑,就是所有 AI 模型部署的底层逻辑,吃透它,你就搞懂了 AI 部署的本质:
- 前向推理是部署的唯一核心 :AI 部署的工作,就是把训练好的模型,用高性能的代码实现前向推理,给用户输出预测结果。而线性回归的
forward函数,就是所有 AI 模型前向推理的最小单元 ------ 哪怕是大模型、CNN、Transformer,本质都是无数个线性变换 + 激活函数的组合。 - 理解参数的意义,才能做好部署优化:只有搞懂 w 和 b 是怎么来的、有什么物理意义,后续做模型量化、算子优化、自定义算子开发的时候,才不会出现「只会调 API,不懂底层逻辑」的问题。
答案是:线性回归的核心逻辑,就是所有 AI 模型部署的底层逻辑,吃透它,你就搞懂了 AI 部署的本质:
- 前向推理是部署的唯一核心 :AI 部署的工作,就是把训练好的模型,用高性能的代码实现前向推理,给用户输出预测结果。而线性回归的
forward函数,就是所有 AI 模型前向推理的最小单元 ------ 哪怕是大模型、CNN、Transformer,本质都是无数个线性变换 + 激活函数的组合。 - 理解参数的意义,才能做好部署优化:只有搞懂 w 和 b 是怎么来的、有什么物理意义,后续做模型量化、算子优化、自定义算子开发的时候,才不会出现「只会调 API,不懂底层逻辑」的问题。
- C++ 实现的线性回归,就是最小的 AI 部署 demo:你写的 C++ 版本代码,已经实现了「训练固定参数→C++ 封装前向推理接口→输入新数据输出预测结果」的完整部署闭环,这和工业界用 C++ 部署大模型、视觉模型的流程,本质完全一致。