AI 编程提效的困局:为什么出码率上去了,效率却没来?
最近看到阿里高德团队发的一篇文章,把 AI 生成的代码在项目总代码中的占比 从 53% 拉到了 80%-90%。
数字很漂亮,但结果出乎意料,项目交付周期几乎没变,开发者的实际工作量也没见少。
出码率几乎翻倍了,但是效率却不见得有什么增长。

这事不只有他们碰到。用过 AI 写代码的人多少都有类似的困惑:AI 确实写得又多又快了,但项目整体并没有因此变快。今天就来聊聊,问题到底卡在哪。
AI 写代码的三个坑
在聊根本原因之前,先说说我观察到 AI 写代码本身的几个常见问题。
一是瞎写。 AI 不了解你的业务背景和团队约定,它写的代码往往是"功能上没毛病,但跟你现有的架构风格完全不搭"。让它写个登录模块,它可能给你整出三种方案,每一种都能跑,但每一种跟你代码库里的风格都格格不入。
二是越用越慢。 听起来离谱,但很多人有这个体验。给 AI 的指令不够精确的时候,你和 AI 之间的对话会变成反复拉锯,你让它改,它改了一版,你觉得不对,再让它改,又来一版......几轮下来你自己手写都完成了。
三是记性差。 任务一大,AI 就开始丢信息。你在对话开头强调的架构约束、编码规范,到了后面它就"忘"了。对话越长,AI 越像是只记得最后一句话。
这些问题去年就有不少团队注意到了。当时的应对方式大概分三类:用项目文档和规则约束 AI 的行为、优化提示词让指令更清晰、做上下文管理让 AI 不丢信息。
这些方法有用,但它们解决的只是表面问题。
出码率上去了,效率为什么没跟上?
真正的瓶颈不在 AI 写代码本身,而在更大的层面,我分析了下有这些原因。
开发不是只有写代码
一个需求从想法变成线上功能,中间要经历的环节非常多:产品经理写需求、团队评审、技术方案设计、开发、代码审查、测试、前后端联调、上线部署。

写代码只是其中一环。有些团队做过统计,纯编码的时间可能只占整个交付周期的 30% 左右。
这意味着就算你把编码效率提升了 50%,放到整个链路里看,整体提效可能只有 15%。而且 AI 生成的代码往往会带来更多的 review 时间,你得花更多精力确认 AI 写的东西是不是对的、会不会埋坑。
所以,只盯着编码环节使劲,效果天然有限。真正的提效得覆盖从需求到上线的完整链路。
"VibeCoding"迟早翻车
"氛围编程"说的就是那种随口给 AI 几句描述,让它直接生成一大堆代码的用法。
在个人小项目里这么搞可能没问题。但在公司里、在跑了多年的存量项目里,这就是在埋雷。存量代码有历史包袱、有隐式的调用关系、有大量业务知识藏在代码逻辑里。这些 AI 都不知道,它只管按照自己的理解生成代码。
有人就踩过坑:AI 生成的代码改了一个核心接口的参数顺序,单测全部通过,看起来没问题。结果一上线,三个依赖这个接口的下游服务全报错了。排查了一整天才定位到原因。
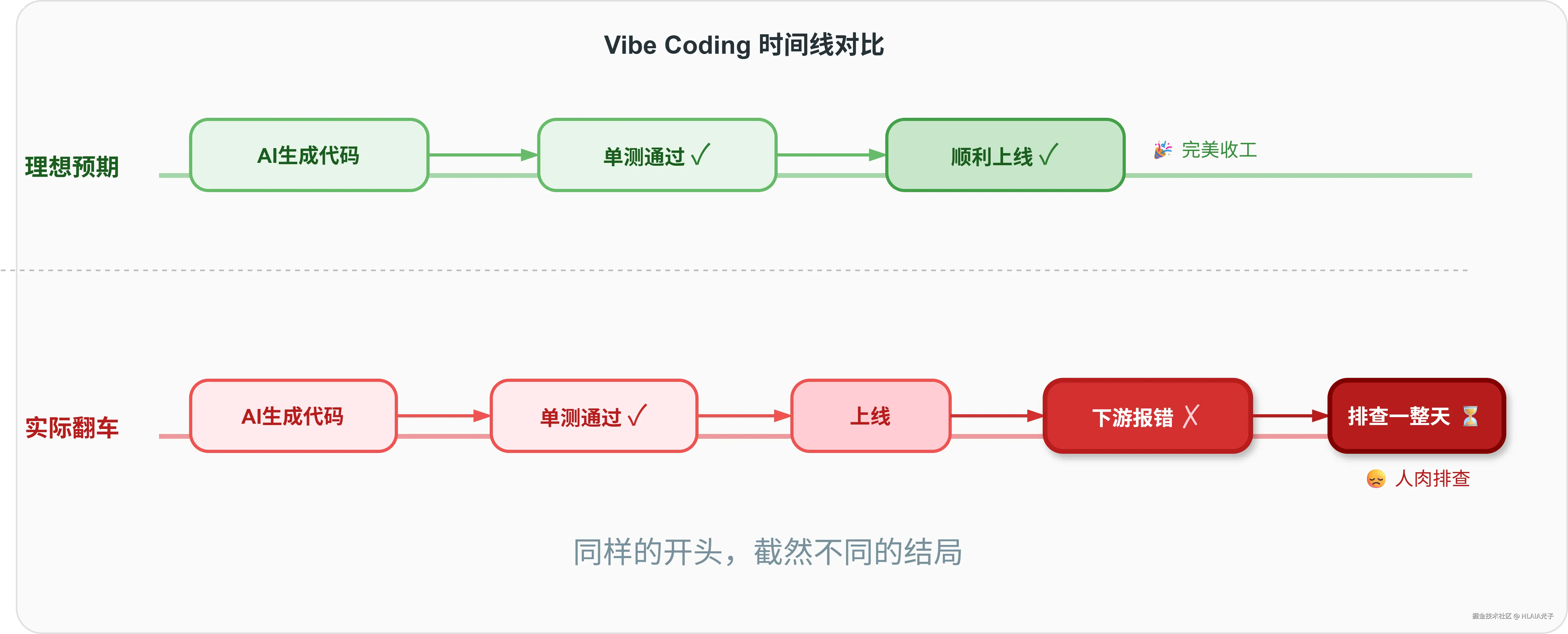
这就是存量项目里"氛围编程"的代价------问题不是在开发阶段暴露,而是在上线后才炸。
大任务 AI 处理不了
还有一个现实问题:当需求涉及十几个模块、前后端联动的时候,你不可能靠一次对话就搞定。AI 的注意力有限,上下文窗口也有限,任务越复杂,它越容易漏掉细节、顾此失彼。
这三个问题指向一个共同的结论:想让 AI 真正在团队研发中发挥作用,不能靠个人拿着 AI 工具单打独斗,得把它升级成一套有规范的工程体系。
如何破局
高德团队的答案是两个东西:SDD 和 Harness。一个管"做什么",一个管"怎么控"。
SDD 规范驱动开发
SDD 全称叫 Specification-Driven Development,规范驱动开发。
传统的开发流程里,需求文档和设计文档本质上只是"参考资料",真正说了算的是代码。文档和代码脱节是常态,文档过期也没人管。
SDD 把这个关系反过来了:规范变成唯一的依据。 不是先写代码再补文档,而是先把需求说清楚、说精确、说成 AI 能直接理解的结构化格式,然后让 AI 照着规范去写代码。需求改了?先改规范,再让 AI 根据新规范重新生成。
SDD工作流程分四个阶段:
- 把需求说清楚:人和 AI 来回讨论,把模糊的想法变成明确的规范,包括用户场景、验收标准、技术约束
- 拆成执行计划:AI 把规范翻译成具体的技术方案和任务清单
- 分任务执行:AI 按照任务清单逐个完成,生成代码
- 自动验证:根据规范自动生成测试用例跑一遍,确认代码和规范一致
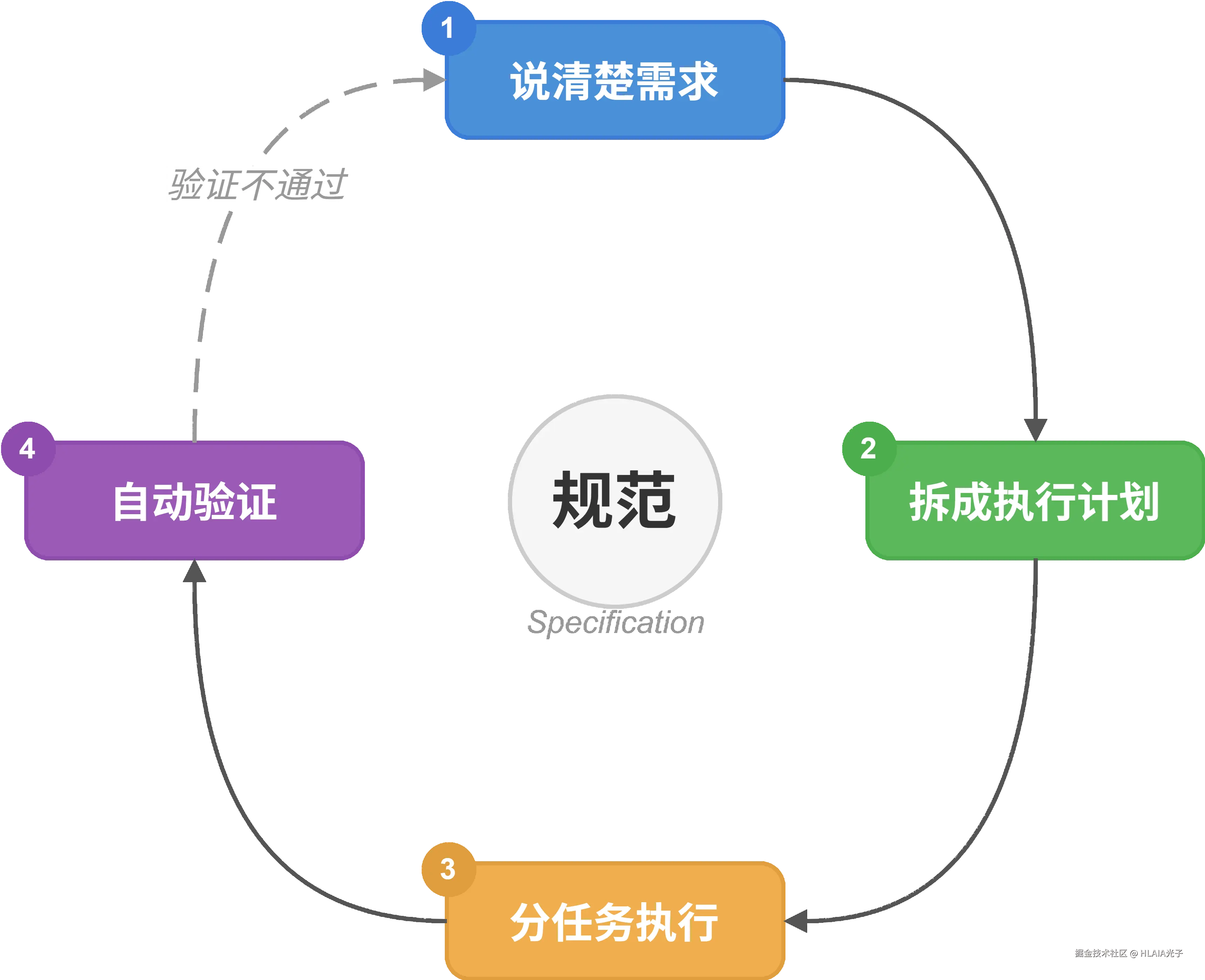
这里面最关键的是验收标准。好的验收标准必须是具体、可测试的。"登录成功后跳转到首页"这种描述太模糊了;"登录成功后 3 秒内跳转到首页,首页顶部显示用户昵称"才是一个合格的验收标准。
Harness Engineering 驾驭工程
Harness 解决的是另一个问题:就算你把规范写好了,AI 在执行过程中会不会跑偏?
想象你骑一匹力气很大但没有马具的马,你控制不住它。Harness 不是去改造这匹马(模型本身),而是给它装上缰绳、马鞍,让你能驾驭它。
Harness 包含四个方面的控制手段:
-
上下文信息。 不是简单地把文档丢给 AI 检索,而是有组织地投喂信息。维护一份"单一事实来源",让 AI 清楚地知道项目的结构、当前进展、哪些文档是最新的。AI 不该猜的信息,就不要让它猜。
-
架构约束。 这是最硬的一道防线。比如你的架构规定前端代码不能直接调数据库,那就通过代码检查工具把这条规则钉死------AI 生成的代码一旦违反这个分层,直接在提交前被拦截,连语法检查都过不了。不靠"建议",靠"强制"。
-
自我修正。 AI 一定会犯错,关键是犯错之后怎么办。做法是建一个自动化的闭环:AI 写完代码 → 跑测试 → 测试挂了 → AI 读错误日志 → 修改代码 → 再跑测试。更重要的,每次人类手动修复了一个问题,就把修复经验写成规则,让同样的错误不会再出现。系统从"越改越乱"变成"越改越稳"。
-
人工兜底。 人的角色从"写代码的执行者"变成"把关的审核者"。核心职责是定义 AI 搞不定的那部分模糊业务边界,审核 AI 的产出,以及持续优化整套控制体系本身。
从"跟 AI 说话"到"驾驭 AI"
把上面这些串起来,能看到一条清晰的路线:
- 最早大家研究的是提示词工程------怎么跟 AI 说话才能让它写出你想要的代码
- 后来进化到上下文工程------不是研究怎么说话,而是研究 AI 应该看到哪些信息
- 现在走向了 Harness Engineering------不光给信息,还要给约束,让 AI 在受控的环境里运行
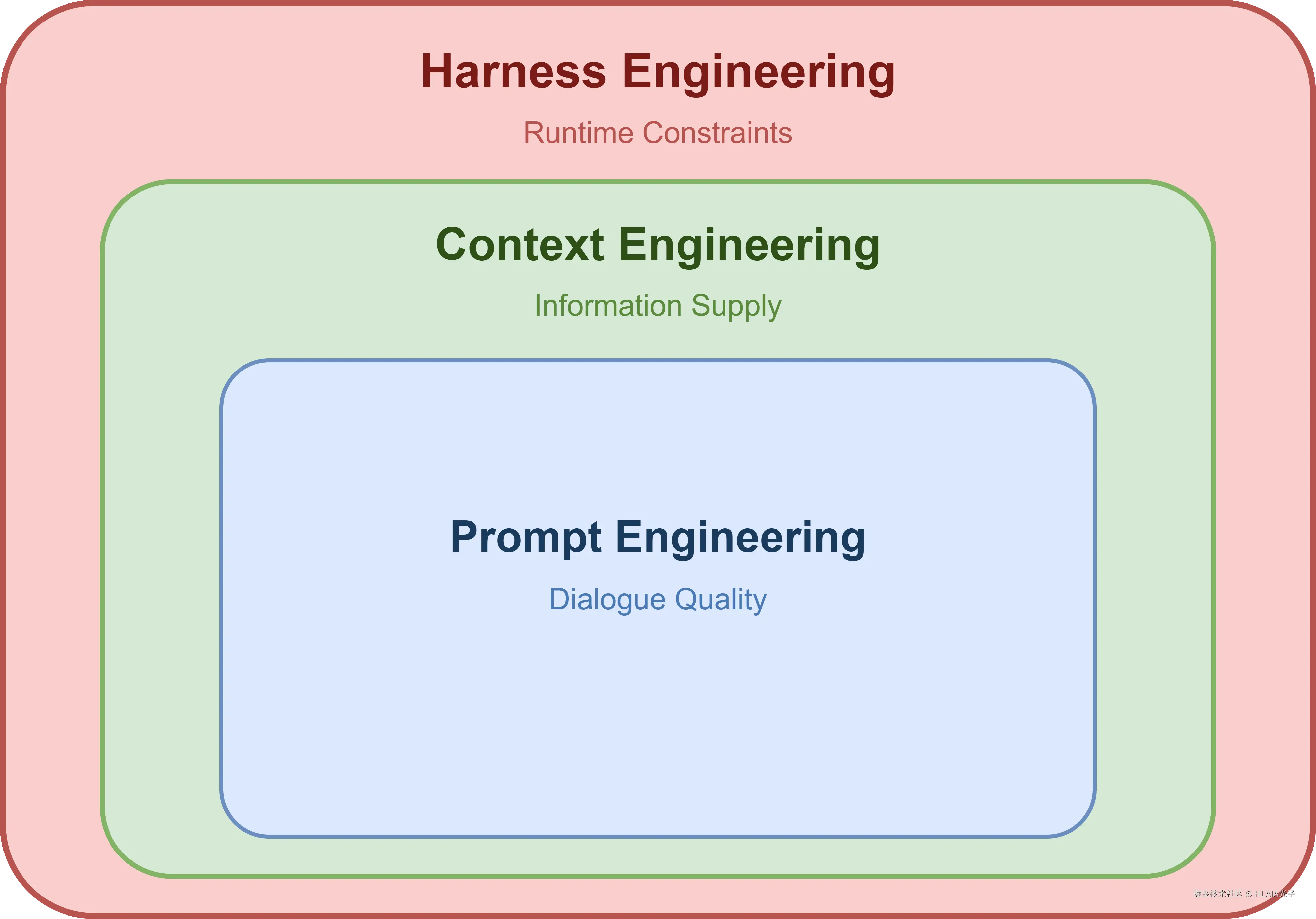
三者不是互相替代的关系,而是在不同维度上逐步叠加。对话质量、信息供给、运行约束,缺一不可。
写在最后
AI 编程走到今天,瓶颈已经不是"AI 能不能写代码"了,而是"AI 写的代码靠不靠谱、能不能真正减少人的工作量"。
出码率是一个容易让人产生错觉的指标。它衡量的是 AI 生成了多少代码,而不是你少花了多少时间。真正该关注的,是整个交付周期的缩短、返工率的降低、开发者的实际负担有没有变轻。
要实现这些,光靠让 AI 写更多代码是不够的。得建立一套完整的体系:需求先规范再动手,执行过程有约束有兜底,从需求到部署打通闭环。
下一篇,我会拆解这套体系在具体项目里怎么一步步落地------知识库怎么搭、需求怎么处理、任务怎么执行、部署怎么自动化。
如果你觉得这篇文章有帮助,点赞关注,点点赞~