Day 5:Agent Loop------整个系列里最关键的一天
《7天从零手搓 AI Agent》第5篇 · 今日成果:Agent 能反复推理、多次使用工具,自动完成复杂任务
大家好,欢迎来到小撒的私房菜,我是小撒。
今天是这个系列里技术含量最高的一天。
但它也是最值得搞清楚的一天。
因为所有你听说过的 Agent 系统------AutoGPT、BabyAGI、Devin、Manus------它们的核心,都是今天要讲的这个循环。
前4天的问题
前4天,Agent 的工作流程是这样的:
用户输入 → AI 决策(用哪个工具?) → 执行一次 → 输出结果最多执行一次动作,就结束了。
但真实任务往往需要多步:
帮我搜索最近 AI 领域的新闻,总结出3条最重要的,并分析一下趋势。
这个任务至少需要:
- 搜索新闻
- 看搜索结果,可能再补充搜索
- 整理和总结
- 分析趋势
一步做不完。需要循环。
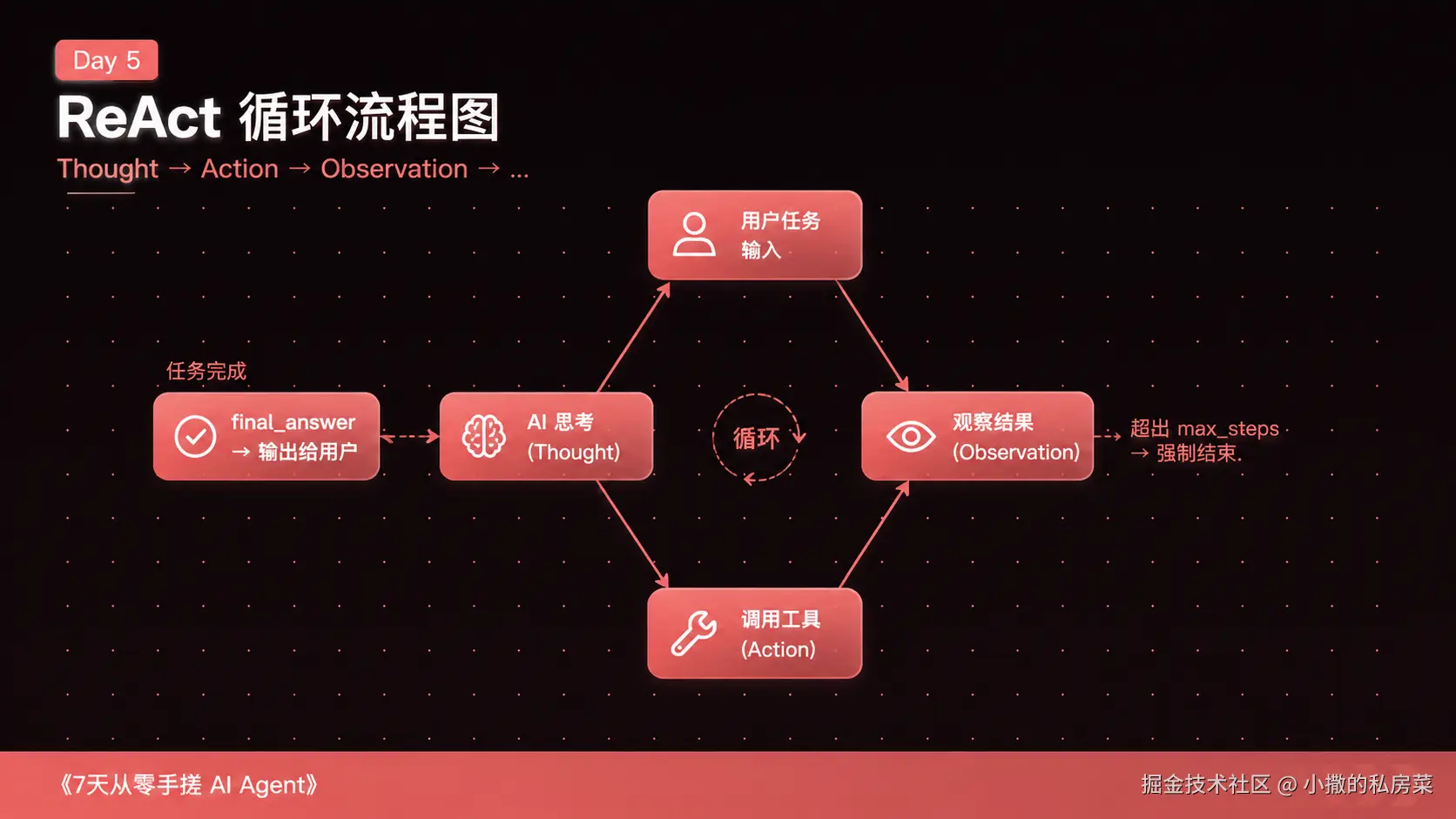
ReAct:思考、行动、观察,反复循环
2022 年,一篇论文叫 ReAct(发音像英文单词 react)。
它提出了一个思路:
erlang
Thought(思考)→ Action(行动)→ Observation(观察结果)→ Thought → ...让 AI 反复执行这个三步循环,直到任务完成。
这个思路很直觉:人做复杂任务的时候也是这样的。
"我先搜一下(行动),哦有了一些信息(观察),但还不够,再搜一个关键词(行动),好了信息足够了,现在我来总结(最终行动)。"
Agent Loop 就是把这个人类的思考过程,写成代码。
实现 ReAct Loop
新建 agent_loop.py:
python
# agent_loop.py
import json
import re
from llm import chat
from tool_registry import get_tools_description, execute_tool
from memory.short_term import ShortTermMemory
REACT_SYSTEM_PROMPT = """你是一个能完成复杂任务的智能助手,可以反复使用工具直到任务完成。
{tools_description}
每次回复必须是 JSON,三种格式之一:
1. 需要使用工具(可以多次使用):
{{"type": "tool_call", "tool": "工具名", "params": {{"参数名": "参数值"}}, "thought": "我为什么用这个工具"}}
2. 任务已完成:
{{"type": "final_answer", "content": "最终答案内容"}}
3. 需要向用户提问:
{{"type": "ask_user", "question": "你的问题"}}
规则:
- 最多使用工具 {max_steps} 次
- 收集到足够信息后,必须给出 final_answer
- 不要用相同参数重复调用同一个工具
- 只返回 JSON"""
def safe_parse_json(text: str) -> dict:
try:
return json.loads(text)
except json.JSONDecodeError:
pass
match = re.search(r'\{.*\}', text, re.DOTALL)
if match:
try:
return json.loads(match.group())
except json.JSONDecodeError:
pass
return {"type": "final_answer", "content": text}
class ReactAgent:
def __init__(self, max_steps: int = 5) -> None:
self.max_steps = max_steps
def run(self, user_task: str) -> str:
"""运行 ReAct 循环完成任务,返回最终答案。"""
# 每次任务新建一个记忆实例(不跨任务保留中间步骤)
memory = ShortTermMemory(max_messages=40)
memory.add("system", REACT_SYSTEM_PROMPT.format(
tools_description=get_tools_description(),
max_steps=self.max_steps,
))
memory.add("user", f"请帮我完成这个任务:{user_task}")
for step in range(1, self.max_steps + 1):
print(f"\n{'─'*40}")
print(f"[步骤 {step}/{self.max_steps}]")
ai_response = chat(memory.to_api_format())
print(f"[AI 思考]: {ai_response}")
memory.add("assistant", ai_response)
decision = safe_parse_json(ai_response)
resp_type = decision.get("type")
# 任务完成
if resp_type == "final_answer":
print(f"[任务完成,共 {step} 步]")
return decision.get("content", "(无内容)")
# 使用工具
if resp_type == "tool_call":
tool_name = decision.get("tool", "")
params = decision.get("params", {})
thought = decision.get("thought", "")
print(f"[调用工具]: {tool_name}")
if thought:
print(f"[理由]: {thought}")
result = execute_tool(tool_name, params)
# 只打印前300字,避免终端被刷屏
preview = result[:300] + "..." if len(result) > 300 else result
print(f"[工具结果]: {preview}")
# 把工具结果作为"观察"加入记忆
memory.add("user", f"工具 {tool_name} 返回结果:\n{result}")
continue
# 向用户提问
if resp_type == "ask_user":
question = decision.get("question", "")
user_answer = input(f"\nAgent 问你:{question}\n你:")
memory.add("user", user_answer)
continue
# 未知类型,结束
return str(decision)
# 达到步骤上限,强制要求给出答案
print(f"\n[已达步骤上限 {self.max_steps},要求给出最终答案]")
memory.add("user", "你已用完所有步骤,请立即基于已有信息给出最终答案。")
final_response = chat(memory.to_api_format())
final = safe_parse_json(final_response)
return final.get("content", final_response)核心逻辑只有这几行
整个 ReAct 的精髓,其实就是一个 while 循环里的三个分支:
python
if resp_type == "final_answer":
return ... # 任务完成,退出循环
if resp_type == "tool_call":
result = 执行工具
memory.add(result) # 把结果加入记忆,下一步 AI 能看到
continue # 继续循环
if resp_type == "ask_user":
answer = input(...)
memory.add(answer)
continue每一步,AI 都能看到之前所有步骤的结果(因为都存在 memory 里),所以它能做出更好的决策。
运行效果
css
你:帮我搜索最近 AI 领域的重要新闻,总结3条最重要的
────────────────────────────────────────
[步骤 1/5]
[AI 思考]: {"type": "tool_call", "tool": "web_search", "params": {"query": "AI 人工智能最新新闻 2024"}, "thought": "需要先搜索最新 AI 新闻"}
[调用工具]: web_search
[理由]: 需要先搜索最新 AI 新闻
[工具结果]: 摘要:人工智能领域...
────────────────────────────────────────
[步骤 2/5]
[AI 思考]: {"type": "final_answer", "content": "根据搜索结果,以下是3条最重要的 AI 新闻:\n\n1. ..."}
[任务完成,共 2 步]
Agent:根据搜索结果,以下是3条最重要的 AI 新闻:
1. ...
2. ...
3. ...max_steps 有多重要
假设没有步骤上限,会发生什么?
有时候 AI 会陷入一种状态:觉得自己信息不够,一直在搜索,搜索,再搜索......永远不输出答案。
这叫死循环。
max_steps=5 是一道保险:最多执行5步,然后强制要求给出答案。即使 AI 觉得信息不够,也要用现有的信息给一个答案。
一般任务用5步够了。
复杂的研究任务可以设8-10步。记住,每步都要调用 API,步骤越多,费用越高。
thought 字段有什么用
注意 tool_call 类型的 JSON 里有一个 thought 字段:
json
{"type": "tool_call", "tool": "web_search", "params": {...}, "thought": "我为什么要用这个工具"}这是让 AI 说出自己的思考过程。
好处:
- 调试方便:你能看到 AI 为什么做这个决定,更容易发现问题
- 决策更准确:先说出理由再行动,AI 的准确率会提高(这是 Chain-of-Thought 的效果)
如果 Agent 做了奇怪的决定,先看 thought,通常能找到原因。
今天的项目结构
bash
my_agent/
├── .env
├── llm.py
├── agent_loop.py # 新增:ReAct 循环(今天最重要的文件)
├── tool_registry.py
├── memory/
│ └── short_term.py
├── tools/
│ ├── search.py
│ ├── weather.py
│ ├── calculator.py
│ └── datetime_tool.py
└── main.py小结
今天的 ReAct 循环,是整个系列里最值得理解透的部分。
核心只有一句话:
把工具结果存入记忆,让 AI 在下一步能看到,然后继续决策------直到任务完成或达到步骤上限。
这个模式,你在 LangChain 里看到的 AgentExecutor,在 OpenAI 的 Assistants API 里看到的 Run Loop,都是它的变体。
明天,Day 6:《先想清楚再动手------给 Agent 加上规划能力》
ReAct 是"边做边想",明天我们学"先想好再做"(Plan-and-Execute)。
两种模式各有优势,适合不同场景。
代码在 GitHub,文末有链接。
如果本教程对你有所帮助,留下一个免费的三连吧,这是对我最大的鼓励♥️!