1. 为什么"评估指标"是大模型面试里的高频题?
1.1 面试官真正想听的,不只是定义
很多人一看到"评估指标"就开始背 Accuracy、Precision、Recall、F1、BLEU、ROUGE,但如果只是把名词丢出来,回答往往会显得很散。面试官真正想听的是:你知不知道不同任务该看什么指标,以及这些指标分别在衡量什么。
所以,这道题最好的答法不是平铺罗列,而是先按任务分类,再重点展开 BLEU 和 ROUGE。这样逻辑会非常清楚。
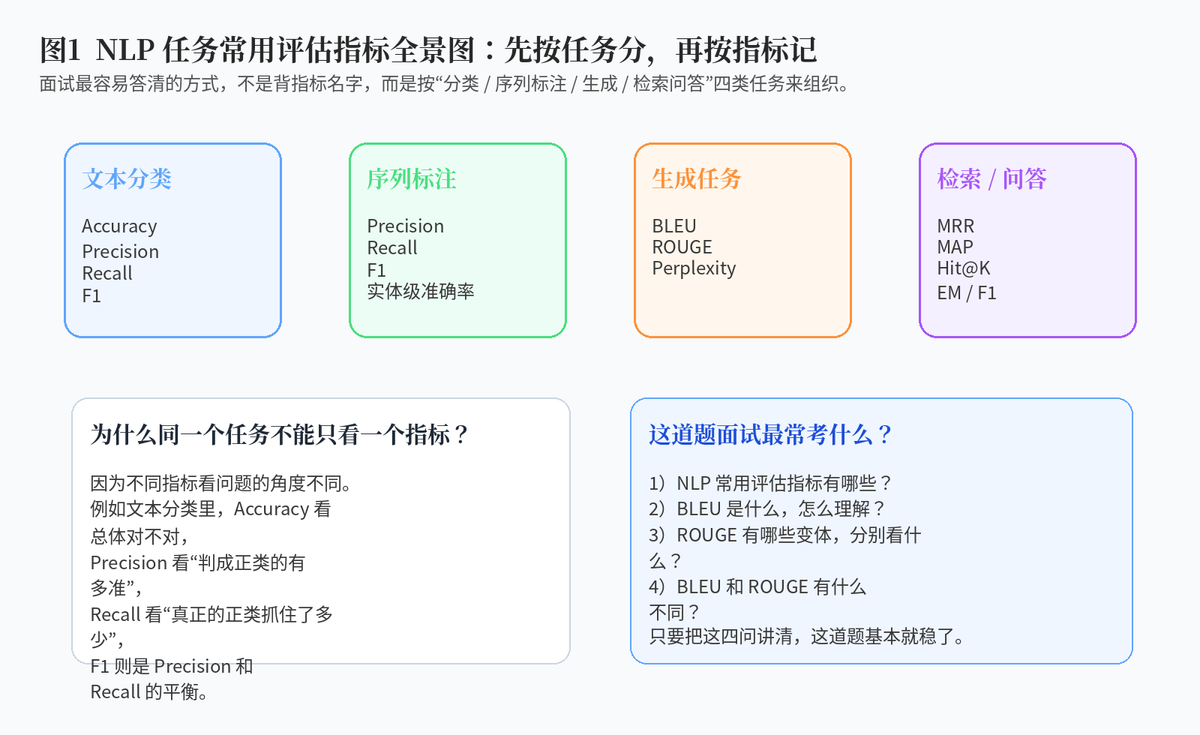
2. NLP 任务中常用的评估指标有哪些?
2.1 文本分类最常见:Accuracy、Precision、Recall、F1
文本分类是最基础的一类 NLP 任务,比如情感分类、主题分类、垃圾短信识别等。这里最常见的指标就是 Accuracy、Precision、Recall 和 F1。
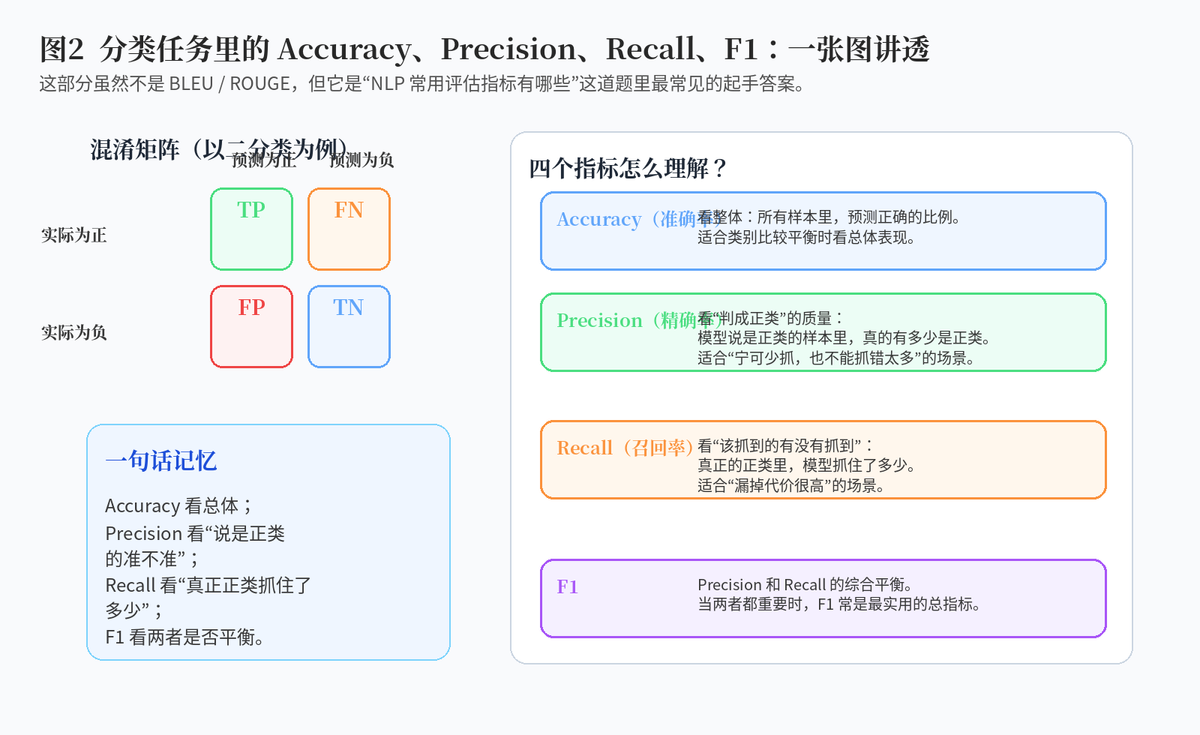
Accuracy 看的是整体预测正确的比例;Precision 强调"模型说是正类的有多准";Recall 强调"真正的正类抓住了多少";F1 则是 Precision 和 Recall 的平衡。
2.2 序列标注常见:Precision、Recall、F1
像命名实体识别、分词、槽位抽取这类序列标注任务,通常也看 Precision、Recall 和 F1。不过要注意,很多时候看的是"实体级"指标,而不是单个字或单个 token 的逐点准确率。
2.3 生成任务常见:BLEU、ROUGE、Perplexity
像机器翻译、文本摘要、对话生成、文本改写等任务,分类指标就不够用了,因为答案不一定只有一个。这时更常见的是 BLEU、ROUGE 这类基于参考答案重合度的自动指标,另外语言模型还会常看 Perplexity。
2.4 问答和检索任务常见:EM、F1、MRR、MAP、Hit@K
问答任务常看 Exact Match 和 F1,检索任务常看 MRR、MAP、Hit@K、Recall@K,这些指标关注的是"正确答案是否找到了"和"是否排得足够靠前"。
3. BLEU 指标是什么?
3.1 BLEU 的出发点
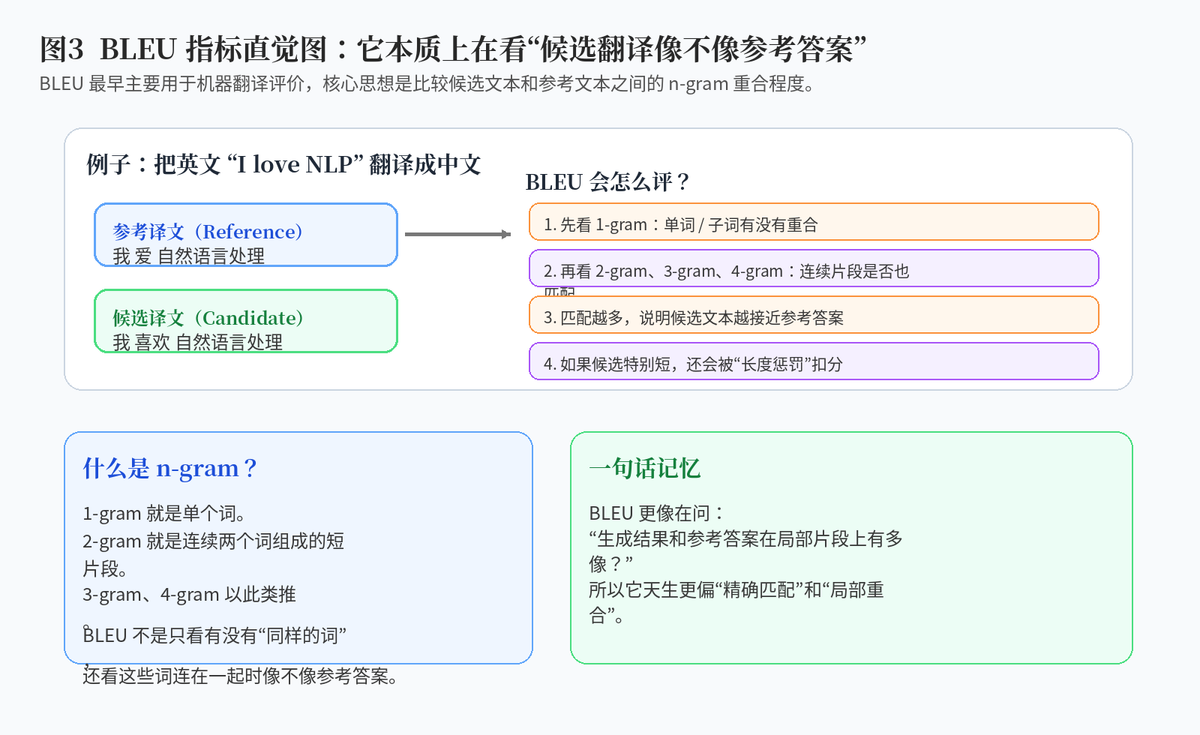
BLEU 最早主要用于机器翻译自动评价。它的基本思路非常直观:如果一个候选译文和人工参考译文在很多局部片段上都很相似,那么它大概率翻译得还不错。
3.2 BLEU 到底在看什么?
BLEU 会比较候选文本和参考文本在 1-gram、2-gram、3-gram、4-gram 这些层面上的重合。简单理解,1-gram 看单词有没有重合,2-gram 看连续两个词组成的片段有没有重合,更高阶的 n-gram 则看更长的局部结构是否相似。
3.3 为什么大家总说 BLEU 更偏 Precision?
因为 BLEU 更像在问:你写出来的这些内容里,有多少和参考答案对得上。也就是说,它更关注"候选结果的局部内容准不准",而不是"参考答案的重要内容有没有全部覆盖到"。
3.4 BLEU 为什么还要加长度惩罚?
如果不惩罚长度,模型完全可以投机:只生成几个特别稳妥、和参考答案肯定重合的短词,依然可能拿到还不错的重合分。为避免这种"偷懒写太短"的情况,BLEU 会加入长度惩罚。
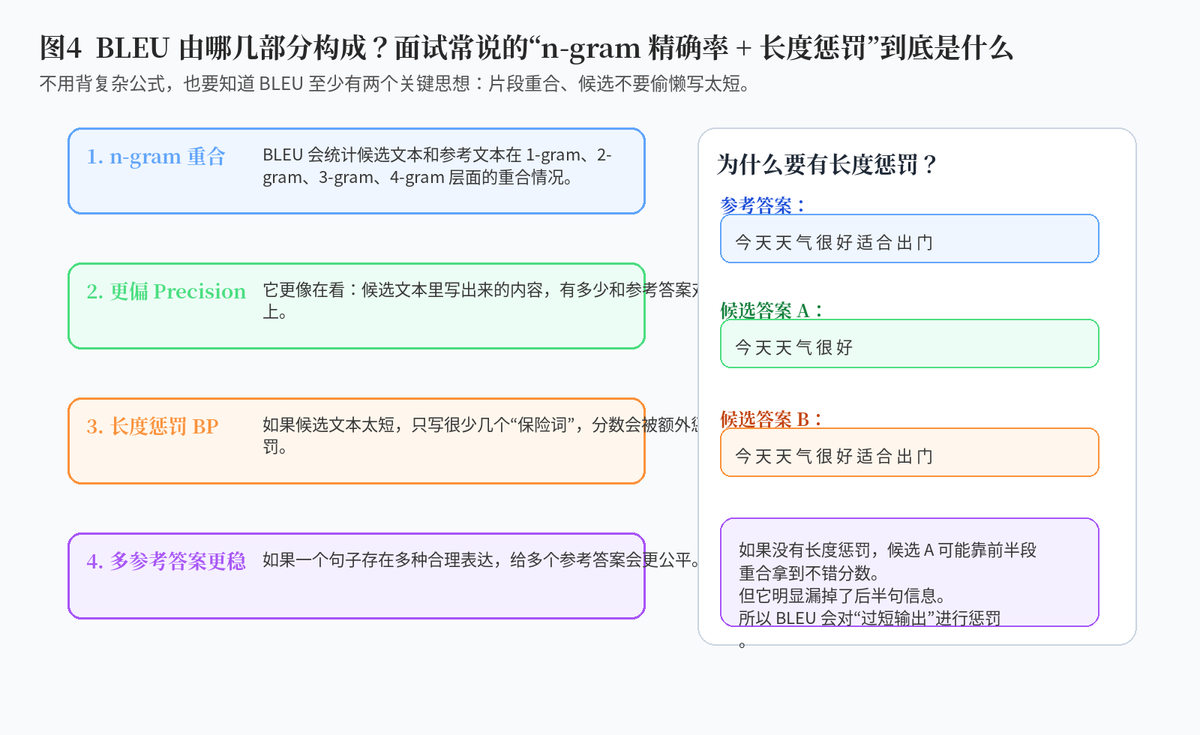
3.5 BLEU 的优点和局限
BLEU 的优点是自动化、便宜、速度快,非常适合批量评测。它的局限是:如果模型输出和参考答案语义相同,但换了一种不同表达方式,BLEU 分数不一定高,因为它本质上仍然比较依赖表面片段重合。
4. ROUGE 指标是什么?
4.1 ROUGE 的出发点
ROUGE 最早主要用于自动摘要评价。它的核心问题是:系统生成的摘要,到底覆盖了多少参考摘要中的重要内容?
因此,ROUGE 虽然和 BLEU 一样也会看重合度,但它在理解上更偏向"覆盖率"。
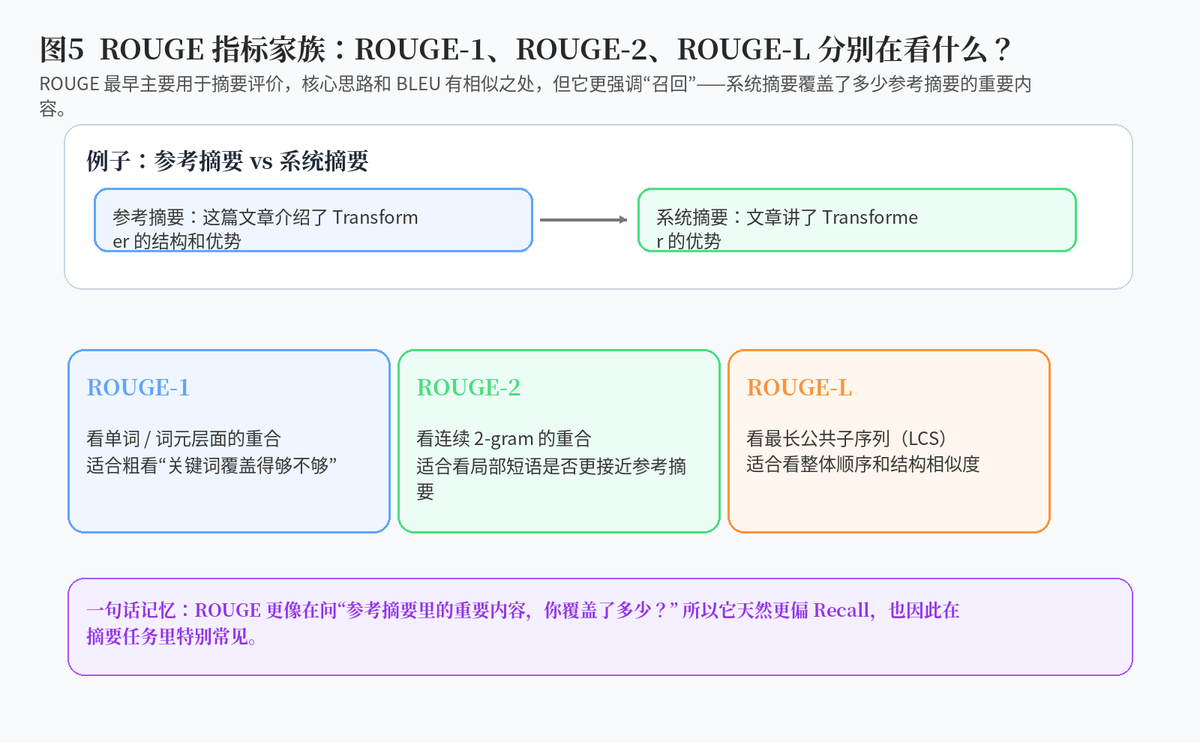
4.2 常见 ROUGE 变体有哪些?
最常见的是 ROUGE-1、ROUGE-2、ROUGE-L。ROUGE-1 看单词层面的重合,ROUGE-2 看连续两个词片段的重合,ROUGE-L 则看最长公共子序列,更强调整体顺序和结构相似性。
4.3 为什么说 ROUGE 更偏 Recall?
因为它更像在问:参考摘要里的关键信息,你到底覆盖了多少。如果生成摘要覆盖得更全,ROUGE 往往会更高。这和 BLEU 更关心"你写出来的内容准不准"是不同的。
4.4 ROUGE 的优点和局限
ROUGE 非常适合做摘要任务的自动评测,也是论文里非常常见的指标。但它和 BLEU 一样,也受表面词重合限制,无法完整替代人工对可读性、事实性和信息价值的判断。
5. BLEU 和 ROUGE 有什么不同?
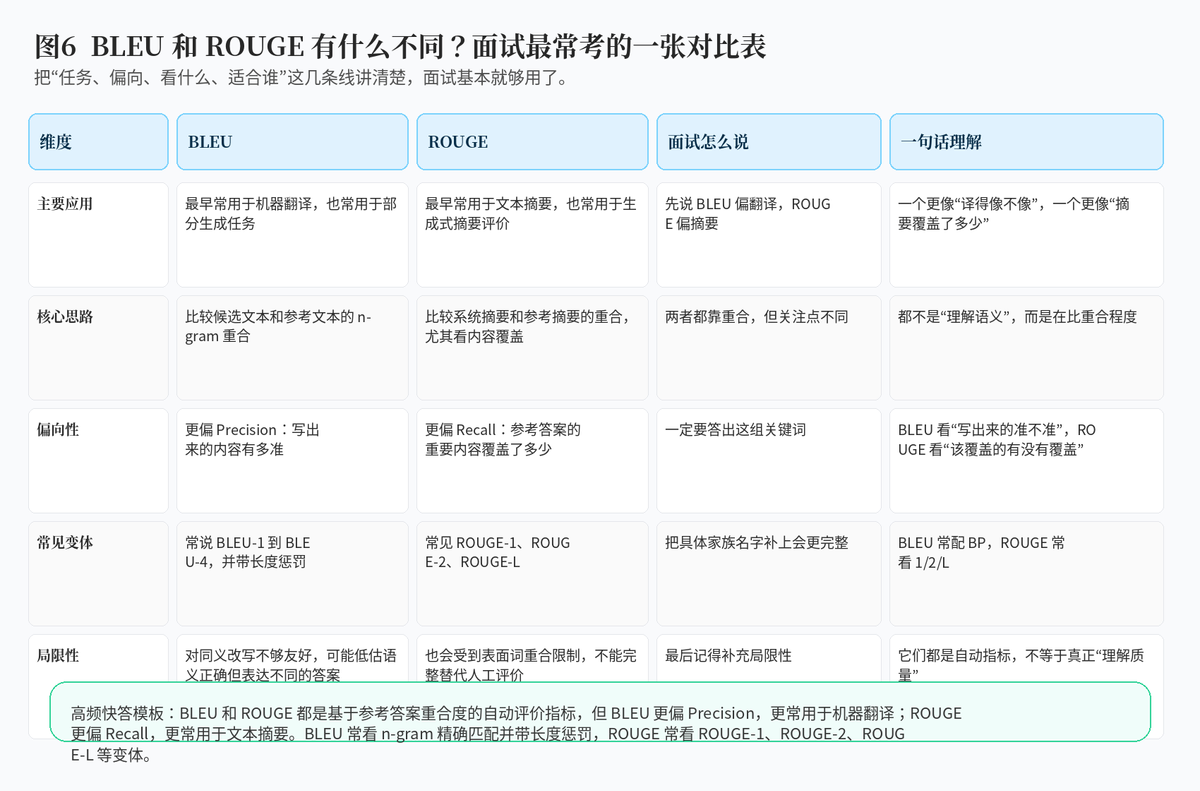
5.1 场景不同
BLEU 最早更常用于机器翻译,ROUGE 最早更常用于自动摘要。虽然现在两者都可能出现在更广泛的生成任务里,但各自的"老本行"不同。
5.2 关注重点不同
BLEU 更偏 Precision,关注候选文本写出来的内容有多像参考答案;ROUGE 更偏 Recall,关注参考答案的重要内容覆盖了多少。
5.3 变体和使用习惯不同
BLEU 常按 BLEU-1 到 BLEU-4 来看,并常带长度惩罚;ROUGE 常看 ROUGE-1、ROUGE-2、ROUGE-L。
5.4 真正高质量的回答应该怎么说?
最好的答法是:先说两者都属于基于参考答案重合度的自动评测指标;再说 BLEU 偏翻译、偏 Precision,ROUGE 偏摘要、偏 Recall;最后补一句它们都不能完全替代人工评价。这样既全面又有层次。
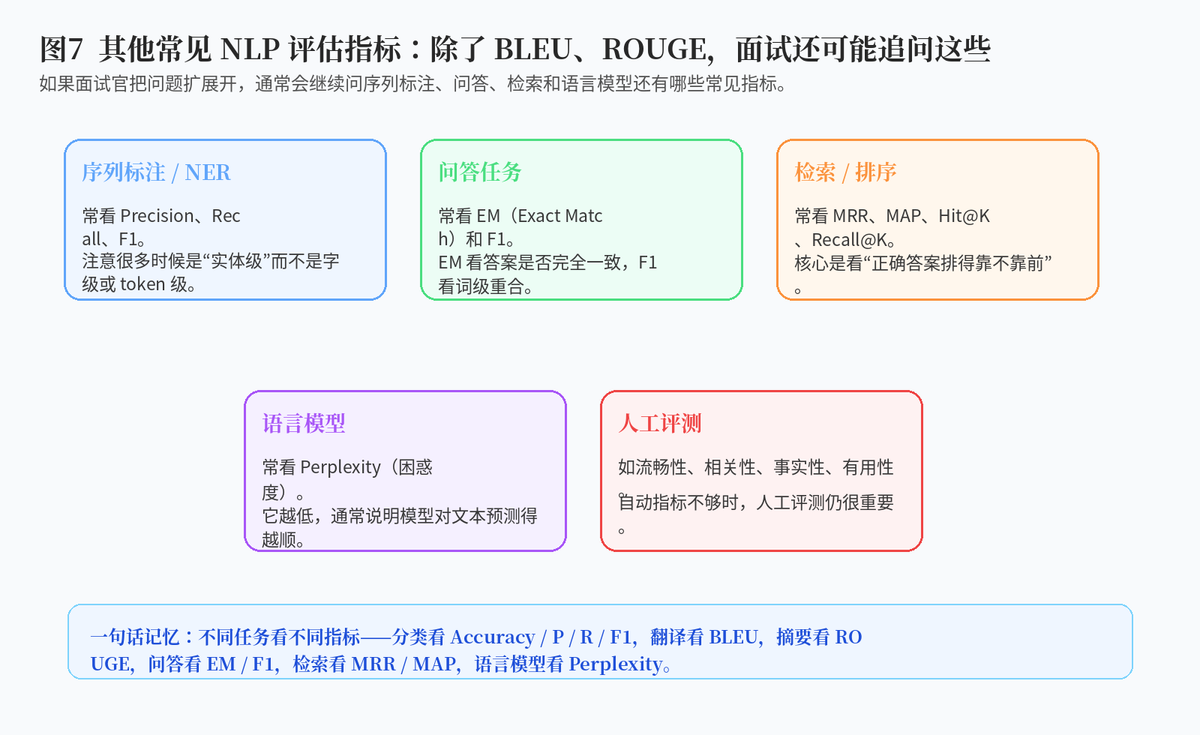
6. 除了 BLEU、ROUGE,还有哪些 NLP 指标也值得知道?
如果面试官进一步追问,你还可以补充:NER 等序列标注常看实体级 F1;问答常看 EM 和 F1;检索排序常看 MRR、MAP、Hit@K;语言模型常看 Perplexity。
7. 面试高频追问,建议这样回答
7.1 NLP 任务中常用的评估指标有哪些?
答:要按任务来看。文本分类常看 Accuracy、Precision、Recall、F1;序列标注常看实体级 Precision、Recall、F1;机器翻译常看 BLEU;文本摘要常看 ROUGE;问答常看 EM 和 F1;检索任务常看 MRR、MAP、Hit@K 等。
7.2 介绍一下 BLEU 指标
答:BLEU 是一种常用于机器翻译的自动评测指标,核心是比较候选文本和参考文本在不同阶 n-gram 上的重合程度。它更偏 Precision,并带有长度惩罚,用来避免模型只输出过短结果。
7.3 ROUGE 指标之间的区别是什么?
答:ROUGE-1 看单词重合,ROUGE-2 看连续 2-gram 重合,ROUGE-L 看最长公共子序列,更强调整体顺序和结构。
7.4 BLEU 和 ROUGE 有什么不同?
答:两者都基于参考答案重合度,但 BLEU 更偏 Precision,更常用于机器翻译;ROUGE 更偏 Recall,更常用于文本摘要。BLEU 常带长度惩罚,ROUGE 常看 1、2、L 三种变体。
8. 总结:讲清"任务---指标---含义---区别",这道题就不难
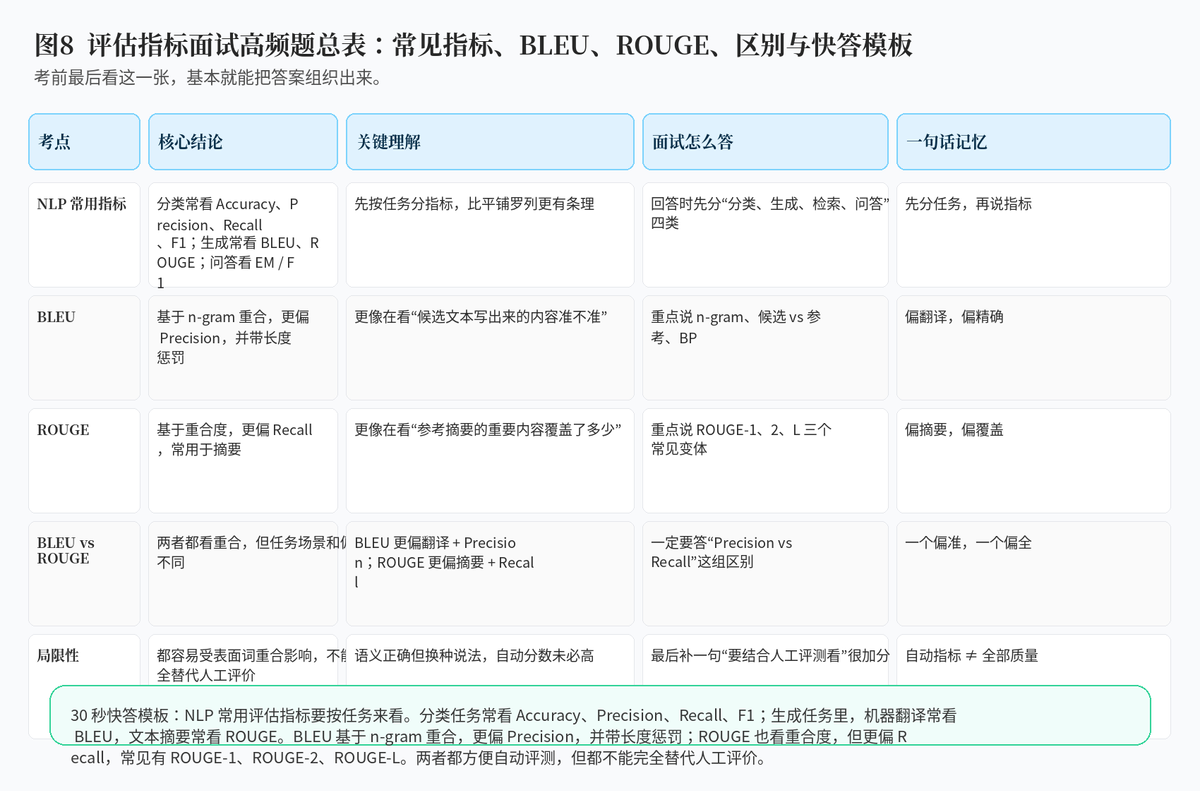
如果把这道题浓缩成一句话,那就是:评估指标要按任务来看,分类任务看 Accuracy、Precision、Recall、F1,机器翻译常看 BLEU,文本摘要常看 ROUGE;BLEU 更偏 Precision,ROUGE 更偏 Recall。
真正高质量的回答,不是把名词背一串,而是能讲清每个指标在衡量什么、适合什么任务、和相近指标有什么区别,再补一句它们都不能完全替代人工评价。这样逻辑就会非常完整。
附:30 秒面试快答模板
"NLP 常用评估指标要按任务来看。分类任务常看 Accuracy、Precision、Recall、F1;序列标注常看实体级 F1;生成任务里,机器翻译常看 BLEU,文本摘要常看 ROUGE;问答常看 EM 和 F1,检索任务常看 MRR、MAP。BLEU 和 ROUGE 都基于参考答案重合度,但 BLEU 更偏 Precision,更常用于翻译,还带长度惩罚;ROUGE 更偏 Recall,更常用于摘要,常见有 ROUGE-1、ROUGE-2、ROUGE-L。"