文章目录
- 概述
- zpool结构
-
- [一、从从结构视角看 ZPool](#一、从从结构视角看 ZPool)
- 二、从功能视角看ZPool
-
- [Dataset 的层次结构](#Dataset 的层次结构)
-
- [1. Filesystem Dataset](#1. Filesystem Dataset)
- [2. Volume Dataset(zvol)](#2. Volume Dataset(zvol))
- [3. Snapshot Dataset](#3. Snapshot Dataset)
- [4. Bookmark Dataset](#4. Bookmark Dataset)
- 总结
概述
在使用 ZFS 时,最常提出的问题往往是"我的 zpool 应该如何配置"。有些人希望在已有硬盘的基础上获得最佳配置方案,而另一些人则想知道应该购买多少、以及什么类型的硬盘。无论属于哪种情况,要回答这个问题都必须先理解 ZFS 存储池的基本构成。一个 pool 并不是直接由磁盘组成,而是由多个 vdev 组成,每个 vdev 再由若干磁盘构成。因此,在规划 ZFS 存储架构时,更合理的思考方式是从上往下:先理解 pool 的结构,再到 vdev 的冗余方式,最后才是具体使用多少块磁盘。只有掌握这种层级关系,才能做出合理的存储设计。
zpool结构
一、从从结构视角看 ZPool
zpool 是 vdev 的集合,大致可以分为:
- Support vdevs,包含:
- Cache(L2ARC,不是main ARC)
- Log
- Special
- Storage vdevs
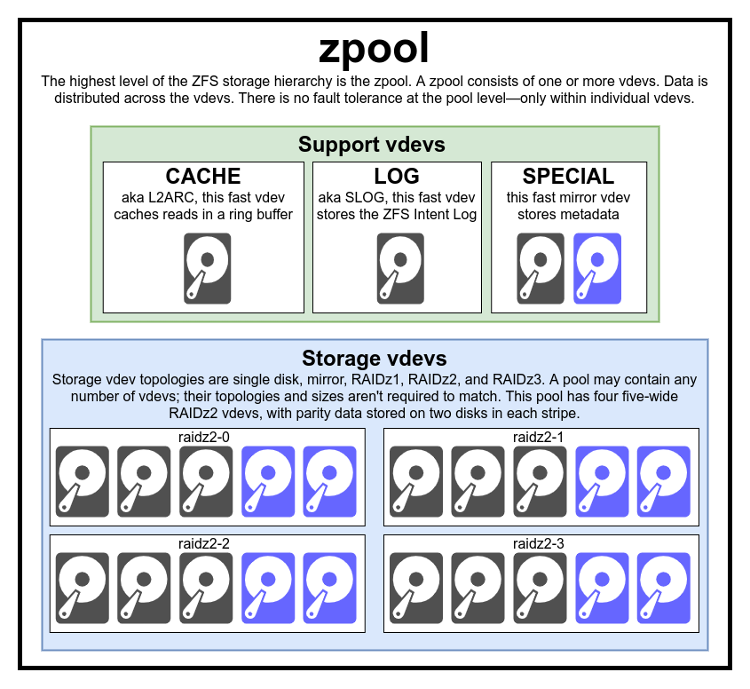
一个 zpool 由 四个 RAIDz2 storage vdev 组成,并且包含每一种受支持的 support vdev 类型各一个------LOG、CACHE 和 SPECIAL。
data 会在这些 vdev 之间进行分布,而 容错性是在 每个 vdev 内部提供的,而不是在 vdev 之间提供的。
上图展示了一个 pool,它使用了 四个 RAIDz2 vdev,并且包含当前所有受支持的 support vdev 类型各一个。
从最顶层开始,zpool 是 ZFS 的顶层结构。
从结构上来说,zpool 是由 一个或多个 storage vdev 以及 零个或多个 support vdev 组成的集合。
需要注意的是,zpool 并不会直接包含实际的 disks(或其他 block/character devices,例如 sparse files)。这正是下一层对象 vdev 的职责。vdev 是 virtual device 的缩写,每个 vdev------无论是 support vdev 还是 storage vdev------都是由多个 block 或 character devices(在大多数情况下是 disks 或 SSDs)按照特定 topology 组织而成的集合。
1. Storage vdevs
storage vdev 可以使用这几种 topology。 :
- single
- mirror
- RAIDz1/2/3
- 或 DRAID
其中前三种 topology 相对比较简单,而 DRAID 则是一个比较特殊的机制,我们会在后面的独立章节中单独介绍。
Single
最简单的一种 vdev 类型,只包含 一个 disk。这里几乎没有 容错性(fault tolerance)(虽然 metadata blocks 会以副本形式存储,但这并不能在 drive 完全故障时保护数据)。在相同 disk 数量 的情况下,这是速度最快的 vdev 类型,但前提是你必须把 backups 做好。
Mirror
Mirror:这种简单的 vdev 类型是速度最快的容错类型(fault-tolerant type)。Mirror 最常见的是 双盘(two-wide) 配置,不过也支持由更多磁盘组成的配置。
在 mirror vdev 中,所有成员设备(member devices)都保存该 vdev 上写入数据的完整副本(full copies)。
读取(reads)的速度最高可以达到单个磁盘的 n 倍,其中 n 是 vdev 中的磁盘数量;但 writes 的性能会受到限制,无论 vdev 中有多少磁盘,其速度都只会略低于单个磁盘,主要原因如下:
- Mirror write 需要等待所有磁盘完成
在 OpenZFS 的 mirror vdev 中,一次写入会同时发送到所有 mirror 成员盘:
bash
write
├─ disk1
└─ disk2IO 只有在 所有磁盘都完成 时才算完成,因此:
bash
write latency = max(latency of each disk)这意味着:
- 不会比最快盘快
- 取决于最慢盘
- ZFS 软件层的额外开销
相比单盘直写,ZFS 需要做额外工作:
- mirror IO split
- vdev IO queue 调度
- checksum 计算
- completion 聚合
流程类似:
bash
ZFS
↓
mirror vdev
↓
split IO → disk1
→ disk2
↓
wait all completion这些软件层操作带来少量延迟。
- IO completion 需要同步聚合
bash
write → completemirror IO:
bash
write
↓
disk1 complete
disk2 complete
↓
wait both
↓
returnRAIDz1
这种条带化的校验虚拟设备(striped parity vdev) 类似于经典的 RAID5。数据会在 vdev 中的所有磁盘之间进行条带化(striped),并且每一行中会保留 一个磁盘用于 parity。
在经典 RAID5 中,parity 会进行 "staggered(交错)"分布,因此不会总是落在同一块磁盘上,这样在 阵列降级(degraded ,比如一个硬盘故障)状态 或 rebuild 过程中可以提高性能。
举一个简单的例子,假设有 4 块磁盘:D0、D1、D2、D3。RAID5 会把数据按 stripe 写入,并让 parity 在不同磁盘之间轮流移动:
bash
Stripe 0: D0: Data0 D1: Data1 D2: Data2 D3: Parity
Stripe 1: D0: Data3 D1: Data4 D2: Parity D3: Data5
Stripe 2: D0: Data6 D1: Parity D2: Data7 D3: Data8
Stripe 3: D0: Parity D1: Data9 D2: Data10 D3: Data11可以看到:
- 每一行必须写完整条带(stripe)
- stripe 宽度固定
- 每一行(stripe)都会有一个 parity 块,但它的位置在磁盘之间不断轮换。
这种"交错"布局意味着: - 所有磁盘都既存储数据又存储 parity
- 没有单独的 parity 磁盘成为瓶颈
如果你只写 4KB 数据,而 stripe 需要 12KB data(因为它的每个条带是固定宽度),RAID5 就必须:
bash
read old data
read old parity
recalculate parity
write data
write parity这就是著名的 RAID5写惩罚(write penalty)
而 RAIDz1 则依赖其 dynamic stripe width(动态条带宽度) 来实现类似效果:与经典 RAID5 不同,RAIDz1 可以用较窄的 条带(stripe) 写入少量数据。
因此,一个 metadata block(一个metadata block 的大小可能小到只占用一个 sector)会被存储为:
- 一个 data block
- 一个 parity block
即使是在一个更大磁盘宽度的 RAIDz1 vdev 上也是如此。
在 RAIDz1 中,条带(stripe) 不是固定宽度
为了更进一步澄清动态条带宽度的概念,这里同样假设你有 4 块盘 RAIDz1:
最大 stripe 可能是:
bash
3 data + 1 parity但如果写入数据很小,只是写入一个metadata block:
RAIDz1 可以写成:
bash
1 data + 1 parity只用 两块盘。
bash
disk1 data
disk2 parity
disk3 -
disk4 -下一次写入可能变成:
bash
disk3 data
disk4 parity所以 parity 自然会分布到所有盘。
这种方式不仅 节省空间并提升性能,还可以将 parity 有效地分布到 vdev 中的所有磁盘上,而不是像某些 stripe 写入那样,总是把 parity 写到同一块磁盘上。
RAIDz2
这是 ZFS 三种 striped parity vdev 拓扑中的第二种(也是最常用的一种)。它的工作方式与 RAIDz1 基本相同,但使用的是 dual parity(双重 parity),而不是 single parity(单重 parity)。
在这种情况下,一个 metadata block 会被写入 三块磁盘,而不是两块:
- 一块磁盘存储原始 data
- 另外两块磁盘存储 parity blocks
对于 RAIDz1 vdev 来说,如果丢失 一块磁盘,系统仍然可以正常工作而不会发生灾难性故障;而 RAIDz2 vdev 则可以在丢失 两块磁盘 的情况下仍然保持正常运行。
RAIDz3
这是最后一种 条带校验拓扑(striped parity topology),它使用 三重校验(triple parity)。这意味着在 三块磁盘故障的情况下,系统仍然不会发生 灾难性故障
同时,这也意味着 元数据(metadata) 和其他 小块(small blocks) 在写入时会被写入 四块磁盘(four drives):
一块磁盘存储 数据(data)
三块磁盘存储 校验块(parity blocks)。
Support vdevs
前面我们已经了解了 存储 vdev 拓扑(storage vdev topologies),接下来再来讨论 vdev 类别(vdev classes)。
需要说明的是,"vdev 类别(vdev class)" 和 "支持 vdev(support vdev)" 并不是 OpenZFS 的官方术语,但它们提供了一种有用的方式,可以帮助我们对 ZFS 如何管理存储进行分类和理解。
目前已经实现的 支持 vdev 类型(support vdev types) 包括:
- 日志(LOG)
- 缓存(CACHE)
- 特殊设备(SPECIAL)
- 备用设备(SPARE)
Log
我们先从日志设备(LOG vdev)说起,并先澄清一个常见的误解:LOG vdev 并不是写缓存(write cache)或缓冲区(buffer)。
在正常运行情况下,OpenZFS 会将 同步写入(sync writes) 保存到磁盘 两次:
- 第一次是 立即(immediately) 写入 ZFS 意图日志(ZFS Intent Log,ZIL)
- 第二次是在稍后的某个时间点写入主存储(main storage)
如果没有 日志设备(LOG vdev),那么这两次写入都会发生在 主存储 vdev(main storage vdevs) 上。
当为存储池配置了 独立日志设备(separate log device,SLOG)时,ZIL 就会被写入这个 LOG vdev。换句话说,SLOG 实际上就是用于存放 ZIL 的专用 LOG vdev,其作用只是为 ZIL 提供一个独立且更快的存储位置。
与直觉相反,这种双重写入(double writes) 实际上可以提高同步写入吞吐量(sync write throughput)。其主要原因是通过使用预分配的 ZIL 块(pre-allocated ZIL blocks) 来降低延迟(latency):这样可以避免在写入时花时间去寻找存放数据的位置,同时还能减少 碎片,从而降低寻道延迟(seek latency)。
日志设备(LOG vdev) 只是一个用于存放 ZFS 意图日志(ZFS Intent Log,ZIL) 的地方,而且这个地方 不是主存储(main storage)------仅此而已,没有其他额外功能。因此,通常所说的 SLOG,本质上只是一个 专门用于存放 ZIL 的独立 LOG vdev。
通常情况下,LOG vdev(SLOG) 会使用 低延迟设备,例如 SSD 或 NVMe SSD,因此将数据 同步到它上的速度会明显快于写入 主存储(main storage)。这正是 LOG vdev 类别(LOG vdev class) 存在的原因。
写入 日志设备(LOG vdev) 的数据在正常情况下 不会再次被读取,除非发生 系统崩溃或 内核崩溃。在系统恢复时,ZFS 会读取 ZIL 来重新执行尚未完成的操作。因此,LOG 或 SLOG 都不应该被理解为"写缓冲区(write buffer)"。
虽然一个 高速日志设备(fast LOG vdev / SLOG) 可以极大地加速 同步写入密集型工作负载,但对于 几乎没有同步写入(sync writes)的工作负载来说,它 完全不会产生任何影响。事实上,大多数工作负载------即使是 服务器工作负载------通常也 很少包含同步写入。
同步写入密集型工作负载的典型场景包括:
- NFS 导出(NFS exports)
- 数据库(databases)
- 虚拟机镜像(VM images)
在 早期版本的 ZFS中,如果 日志设备(LOG vdev)丢失,就意味着 整个存储池也会丢失。
而在现代 ZFS 中,LOG vdev的丢失不会危及 存储池或其中的数据。
如果 LOG 发生故障,唯一可能丢失的只是其中的 脏数据(dirty data)------尚未提交到磁盘的数据。
日志设备(LOG vdev可)以使用 单盘拓扑 或 镜像拓扑;但不能使用 RAIDz 拓扑或分布式 RAID 拓扑(DRAID拓扑)。
如果同步写入(sync writes) 数量非常多,希望将负载分散到多个 日志设备(LOG) 上,那么你可以配置 任意数量的 LOG vdev。
CACHE
需要澄清的是,这里的缓存设备(CACHE vdev)并不是指main ARC,而是 二级自适应替换缓存(L2ARC,Level 2 Adaptive Replacement Cache)。
从实现上看,它只是 ARC 的扩展读缓存层,用于在内存 ARC 不足时缓存部分热点数据块。L2ARC 通常部署在 SSD 或 NVMe SSD 等高速设备上。
与 ARC(内存缓存)不同,L2ARC 只是 二级缓存层,其数据始终是主存储中数据块的副本。
实际上它并不是一个真正的 自适应替换缓存(ARC,Adaptive Replacement Cache)。L2ARC 本质上是一个简单的后进后出环形缓冲区(LILO ring buffer,Last-In-Last-Out)。它并不是由那些已经从 ARC 中淘汰的数据块来填充,而是由那些可能很快就会从 ARC 中被淘汰 的数据块提前写入。
CACHE vdev 上对写入有一个相当严格的限速(write throttle),目的是防止它迅速把 SSD 的写入寿命耗尽。这也意味着,你之前读取过的某个数据块仍然存在于 CACHE vdev 中、并再次命中的概率,比想象的要低。再加上主 ARC 本身的命中率已经非常高,因此在大多数工作负载下,CACHE vdev 实际上很少被命中。CACHE vdev 本身也不可能拥有很高的命中率,因为一旦发生命中,该数据块就会被重新移动回主 ARC 中。
CACHE vdev 里的数据一定来自主存储(main pool)
它不是唯一副本的原因是:
- CACHE 只缓存已经安全写入主存储的 clean block。L2ARC / CACHE 只是把 已经存在于主存储的数据块复制一份作为缓存。
- 只有 clean block(即未受污染的干净的数据块) 才会进入 CACHE
- 还没写入主存储的 dirty block 不会被放进 L2ARC。
因此 CACHE 永远不会保存唯一副本,如果 CACHE 丢失:
bash
缓存没了
↓
重新从主存储读取SPECIAL
SPECIAL vdev 是最新引入的一种支持类设备。 它的出现主要是为了弥补 DRAID vdev 的一些劣势。当你在一个存储池中添加 SPECIAL vdev 后,该池之后产生的所有元数据写入 都会落在 SPECIAL 上,而不是写入主存储设备。
值得提到的是,RAIDZ 也有这个问题,但 dRAID 的随机 I/O 更严重,因此 SPECIAL vdev 对 dRAID 的提升更明显,主要理由如下:
- DRAID 的数据分布更分散
在 dRAID 中,数据和校验块会被均匀分布到整个磁盘集合中,并且还预留了 distributed spare。
结果是:
- 一个小的元数据读取
- 可能需要访问很多不同的磁盘位置
- 元数据访问非常频繁
例如目录遍历、打开文件等操作都会大量读取 metadata,如果这些都在 HDD 上,会产生很多随机读。
例如:
bash
ls -l
遍历目录
打开文件
snapshot
dataset 操作这些都会读取medata:
bash
dnode
indirect block
block pointer
object set metadata如果这些 metadata 在 HDD dRAID vdev 上,就会产生大量随机 I/O。
- 另一个原因与dRAID 的典型使用场景有关,即DRAID通常用于非常大的 HDD 阵列,几十到几百块盘
在这种规模下:
- metadata 随机 I/O 成本更高
- SSD metadata tier 的收益更大
此外,SPECIAL vdev 还可以选择用于存储小数据块。
例如,当设置 special_small_blocks=4K 时,大小为 4 KiB 或更小的文件将会完全存储在 SPECIAL 上;当设置 special_small_blocks=64K 时,大小为 64 KiB 或更小的文件也会完全存储在 SPECIAL 上。
special_small_blocks 是一个可调参数,可以在每个 dataset 级别单独设置。
但对于 元数据(metadata块,则无法选择不存储到 SPECIAL 上:只要存储池中存在一个或多个 SPECIAL vdev,所有元数据写入都会被写入到这些 SPECIAL 设备上,没有例外
丢失任何一个 SPECIAL vdev,就像丢失任何一个storage vdev 一样,会导致整个存储池失效。 因此,SPECIAL 必须采用具备容错能力的拓扑结构,而且其容错能力需要与存储 vdev 保持一致。
例如,如果一个存储池使用 RAIDz3 作为存储 vdev,那么 SPECIAL vdev 就需要使用四盘镜像(quadruple mirror)------因为 RAIDz3 的存储 vdev 可以承受三块磁盘故障,所以 SPECIAL 也必须能够承受三块磁盘故障。
与 LOG vdev 类似,如果需要将负载分散到更多磁盘上,你可以添加任意数量的 SPECIAL vdev。不过,与 LOG 不同的是,一旦丢失任何一个 SPECIAL vdev,整个存储池也会随之不可恢复地丢失。
SPARE
SPARE vdev 在正常运行时不会执行任何操作,但会处于待命状态,一旦某个 vdev 中的磁盘发生故障,它就会被自动加入并进行数据重建。显然,要想自动替换故障磁盘,SPARE 的容量至少必须与故障磁盘一样大。
如果你的存储池只有 一个存储 vdev,那么其实不需要 SPARE。SPARE 的作用在于:当池中的某个 vdev 进入 降级(degraded)状态 时,它可以被用来替换其中发生故障的磁盘。
而在只有单个 vdev 的存储池中,与其配置 SPARE,不如直接提高冗余级别更合理。比如,在一个 12 盘位的系统中,使用 11 盘宽的 RAIDz3 vdev,其性能会明显优于 10 盘宽的 RAIDz2 vdev 再加一个 SPARE。
是否需要 SPARE vdev 的主要指标是 存储 vdev 的数量,而不是 存储磁盘的数量。如果存储池中有 六个或更多 vdev,几乎可以肯定应该配置一个或多个SPARE。
而且这六个 vdev 是 两个磁盘镜像(总共十二块盘),还是 十个磁盘宽度的 RAIDz2(总共六十块盘),其实差别不大;无论是哪种情况,当某个 vdev 进入 降级(degraded)状态 时,你都会非常希望通过 SPARE 来缩短系统处于脆弱状态的时间窗口。
| vdev 类型 | vdev 数 | 每个 vdev 盘数 | 总盘数 |
|---|---|---|---|
| two-disk mirror | 6 | 2 | 12 |
| 10-wide RAIDZ2 | 6 | 10(8data+2parity) | 60 |
DRAID
前面已经多次提到过 DRAID,如果不了解它之前的设计(比如传统 vdev、SPARE 等)就很难理解 DRAID------因此,在我们已经介绍了标准的 vdev 拓扑结构以及支持类 vdev 类型(尤其是 SPARE)之后,现在来讨论 DRAID。
这种拓扑是为拥有 60 个或更多硬盘的系统设计的,它用一个单一的、极其巨大的 vdev,取代了传统的由多个Sotrage vdev 和 SPARE vdev 组成的架构。
这个庞大的 vdev 同时集成了 RAIDz 和 SPARE 的功能。
假设你正好有 60 块磁盘,并且想用它们来构建一个 DRAID。第一步是决定你的条带于宽度(stripe width) 和 校验冗余级别(parity level),与 RAIDz 不同,这两者并不严格受制可用驱动器数量的限制。
在 DRAID 出现之前,你可能会决定把这 60 块磁盘划分为:9 个由 6 盘组成的 RAIDz2 vdev,再加上 6 个 SPARE vdev。一旦确定了每个 vdev 的宽度(vdev width)和校验级别(parity level),vdev 的数量也就随之固定:本质上,在总共 60 块磁盘上,你不可能创建超过 10 个6盘宽"的 vdev。
DRAID 提供了更高的灵活性:你可以选择 DRAID2:4:4(每个 stripe 包含 2 个校验块和 4 个数据块,而整个 DRAID 在所有磁盘上分布式地预留了相当于 4 块磁盘容量的备用空间),但你同样也可以选择 DRAID3:4:4。显然,每个 stripe 中 3 个校验块加 4 个数据块(共 7 个 block)并不能整除你总共的 60 块磁盘......但不用担心,因为 DRAID 会在需要时对 stripe 进行"环绕(wrap)"分布,使其跨越磁盘矩阵进行放置,从而适配你现有的磁盘布局。
- 场景:DRAID2:4:4(60 块盘)
| 项目 | 数值 | 说明 |
|---|---|---|
| 数据块(data) | 4 | 用户数据 |
| 校验块(parity) | 2 | 可容忍最多 3 盘故障 |
| 每条 stripe 总块数 | 6 | = 4 + 2 |
| 分布方式 | 跨 6 块盘 | 每个 block 落在不同磁盘 |
| spare | 相当于4块硬盘的容量 | 从60块硬盘中预留相当于4块硬盘的容量作为spare空间(而不是像RAIDZ中固定硬盘作为spare设备),60 块盘 × 每盘预留一小部分≈ 总共等效 4 块盘容量 |
DRAID2:4:4 条带范例:
bash
Stripe #1:
D1 D2 D3 D4 P1 P2条带分布示列:
| Disk | 内容 |
|---|---|
| Disk8 | D1 |
| Disk15 | D2 |
| Disk22 | D3 |
| Disk30 | D4 |
| Disk41 | P1 |
| Disk6- | P2 |
Stripe #2:
会换另外 6 块盘(轮转分布),不是固定哪 6 块盘,而是在 60 块盘里不断"游走"
因为DRAID2:4:4的条带长度是6,能被60整除,所以不存在wrap(回绕)的情形
我们再来看场景2
2.场景:DRAID3:4:4(60 块盘)
| 项目 | 数值 | 说明 |
|---|---|---|
| 数据块(data) | 4 | 用户数据 |
| 校验块(parity) | 3 | 可容忍最多 3 盘故障 |
| 每条 stripe 总块数 | 7 | = 4 + 3 |
| 分布方式 | 跨7块盘 | 每个 block 落在不同磁盘 |
| spare | 相当于4块硬盘的容量 | 从60块硬盘中预留相当于4块硬盘的容量作为spare空间(而不是像RAIDZ中固定硬盘作为spare设备),60 块盘 × 每盘预留一小部分≈ 总共等效 4 块盘容量 |
DRAID3:4:4 条带范例:
bash
Stripe #1:
D1 D2 D3 D4 P1 P2 P3条带分布示例:
| Disk | 内容 |
|---|---|
| Disk8 | D1 |
| Disk15 | D2 |
| Disk22 | D3 |
| Disk30 | D4 |
| Disk41 | P1 |
| Disk52 | P2 |
| Disk60 | P3 |
3.wrap(环绕)
| 顺序 | Disk | 内容 |
|---|---|---|
| 1 | Disk58 | D1 |
| 2 | Disk59 | D2 |
| 3 | Disk60 | D3 |
| 4 | Disk1 | D4 |
| 5 | Disk2 | P1 |
| 6 | Disk3 | P2 |
| 7 | Disk4 | P3 |
stripe 从 60 走到头,然后从 1 继续,如果理解成环形将会更直观:
bash
(环形)
[1] [2] [3]
[60] [4]
[59] [5]
[58] [6]
[57] [56] ...
Stripe 跨过去:
57 → 58 → 59 → 60 → 1 → 2 → 3到这里,我们应该理解了"环绕",就是:stripe 写到磁盘末尾时,不停下来,而是从开头继续写
不过,这里还是有个小代价:如果 dRAID 的条带宽度不能被硬盘总数整除(例如 7 除不尽 60),系统就需要对条带进行"环绕(wrap)"处理,导致数据在硬盘上的分布无法做到最优对齐。这可能会带来一定的性能损失,尤其是在处理小文件或随机 I/O 时,读写效率会稍微降低一些。
但在拥有 60 块甚至更多硬盘的超大规模系统中,这个问题通常可以忽略不计。因为此时整个存储系统的瓶颈,已经不再是单个硬盘的性能,而是硬盘控制器(HBA 卡、PCIe 通道等)的整体吞吐能力。单个硬盘或条带排列带来的那点轻微损失,在海量并行 I/O 面前就显得微不足道了。
在 DRAID 配置中,并不是像传统 RAIDZ 那样,把某一块磁盘固定对应到某一个特定条带(stripe)。相反,dRAID vdev 的每一个成员数据都会分布到 vdev 中的全部 60 块磁盘上。
因此,当某一块磁盘发生故障时,并不是丢失某一个完整的条带,而是等价于从这 60 个成员中的每一个都损失了 1/60 的数据。
下图描述了RAIDz 与 DRAID 的重建(Resilvering)行为
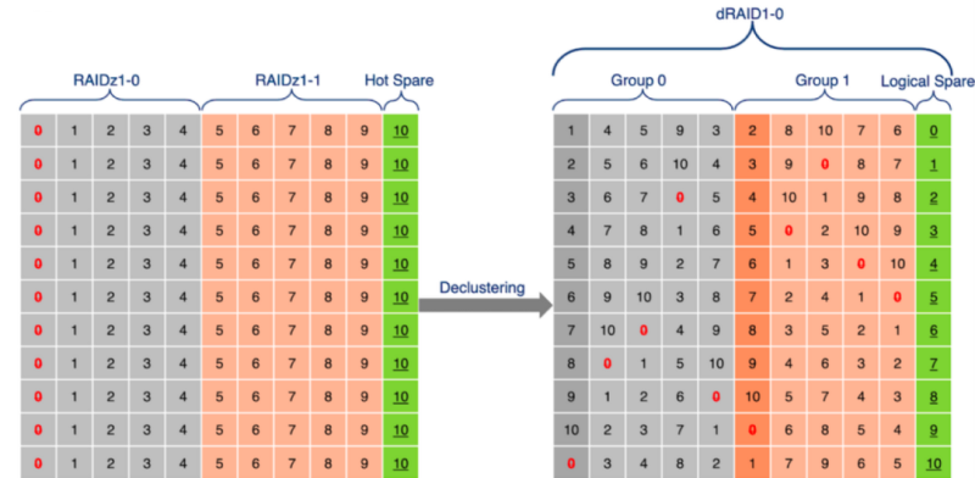
上图结构说明:
- 基本配置:
两边用的是完全相同的11块盘(编号0~10),只是组织方式不同。 - 左边:传统 RAIDz
| 区域 | 盘 | 说明 |
|---|---|---|
| RAIDz1-0 | 盘 0~4 | 独立的一组,5块盘 |
| RAIDz1-1 | 盘 5~9 | 独立的一组,5块盘 |
| Hot Spare | 盘 10 | 热备盘,平时完全闲置 |
- 红色的 0 代表 parity 块,集中固定在盘0这一列
- RAIDz1-1 实际上也有自己的 parity,图中未标红,属于示意图简化
- 两个 RAIDz 组互相独立,parity 不跨组共享
- 绿色的盘10是热备盘,平时完全空闲浪费
- 右边:DRAID(Declustering 后)
| 区域 | 说明 |
|---|---|
| Group 0 | 打散重组后的第一组 |
| Group 1 | 打散重组后的第二组 |
| Logical Spare | 逻辑备用,分散在所有盘上 |
- 红色的 0 依然代表 parity 块 ,但不再固定在某一列,而是打散分布到所有盘的各个位置
- 绿色的备用容量也不再是单独一列,而是每块盘都贡献一部分(Logical Spare)
- 这正是 Declustering(去集中化) 的核心------parity 和备用容量均匀散布在所有盘上
这张图展示的是:同样11块盘,左边 RAIDz 的 parity 块集中固定在某一列,热备盘整块闲置;右边 DRAID 通过 Declustering 把 parity 块和备用容量全部打散到所有盘上,既消灭了热备盘的浪费,又让 resilver 可以所有盘并行加速。
如果我们的 DRAID vdev 中有一块硬盘发生故障,原本属于该故障硬盘的数据块会通过校验信息重建,并重新写入到 DRAID 内部"分布式备用(SPARE)空间"中。这种重建(resilver)过程比传统将数据重建到一个独立 SPARE vdev 上要快得多。
举个对比的例子:假设之前有一个由 6 组、每组 9 盘宽的 RAIDZ2(并配有 6 块备用盘)。当一块硬盘故障时,系统会从剩余的 8 块盘读取数据,并写入到 1 块备用盘中。
为何需要读取剩余的8块盘?
因为这里一个条带跨9盘分布
在坏的是数据块的情况下,需要读取剩余的8块盘,用"剩下的所有数据块 + 校验块"来反推
如果坏的是校验块,因为校验块是由所有数据计算出来的,因此仍然要读取所有其他块(7 数据 + 1 校验)
而在 DRAID 中,由于传统重建的主要瓶颈------"写入速度"------现在被分散到其余的 59 块硬盘上,而不是集中在一块盘上,因此性能大大提升。也就是说,DRAID 会同时从 59 块盘读取,并向 59 块盘写入,这显然比传统 RAIDZ 的"8 读 + 1 写"要快得多。
但是,为了回收那些已被占用的分布式备用容量,DRAID vdev 的运维人员仍然必须对一块新磁盘执行传统的 resilver(重建),而且这次 resilver 的速度会和任何传统 resilver 一样慢。
而且,第一次 resilver 存在一个脆弱窗口期(以上图只配备一个parity为例,此时 DRAID 已经少了一个奇偶校验级别,这时如果再有磁盘故障,数据就会丢失),而第二次则不存在脆弱窗口期(因为缺失的奇偶校验级别已经通过分布式备用容量的利用而得到了恢复)。
不过,DRAID vdev 也有其缺点------最大的缺点是它失去了传统 RAIDz vdev 的动态条带宽度存储能力。如果你配置的是 DRAID2:4:4,每个条带必须固定是6块盘宽(4个数据块 + 2个奇偶校验块),即使该条带只存储一个 4KiB 的元数据块也是如此。
这也正是 SPECIAL vdev 发挥作用的地方------虽然 SPECIAL 对传统存储池来说只是锦上添花,但对于拥有宽条带 DRAID vdev 的存储池来说,它几乎是必不可少的。将元数据(以及可选的其他非常小的数据块)存放在 SPECIAL vdev 上,意味着不必再把它们浪费性地存储在全宽条带中,从而避免了大量磁盘空间和性能的浪费!
二、从功能视角看ZPool
- 从功能上来说,zpool 是一个 storage object,可以进一步划分为 :
- datasets(看起来像文件夹)
- zvols(看起来像简单的 block/character devices,例如 raw disks)。
在 OpenZFS 中,dataset 是一个非常核心但也容易让初学者混淆的概念。
很多存储系统会区分:
- 文件系统(filesystem)
- 逻辑卷(logical volume)
- 快照(snapshot)
但在 ZFS 的设计里,这些对象都统一抽象为:dataset
Dataset 的层次结构
也就是说:
dataset 并不只是"数据集",
而是 ZFS 中"可被管理的数据对象"的统称。
Dataset 的层次结构
从逻辑结构来看:
bash
Physical Disks
↓
vdev
↓
zpool
↓
datasets
↓
filesystem / zvol / snapshot / bookmark其中dataset是位于这个逻辑结构的最底层,有分为4个类型:
bash
dataset
├── filesystem
├── volume(zvol)
├── snapshot
└── bookmark1. Filesystem Dataset
这是最常见的 dataset 类型。
例如:
bash
zfs create /ZFS100G/data创建完成后,它会像一般 Linux 文件系统一样,可直接进行文件读写操作:
bash
root@idpcipve01:~# ls -alh /ZFS100G/ | grep -v '\.$'
total 5.0K
drwxr-xr-x 2 root root 2 May 10 10:11 data同时,也可以通过 zfs 命令查看该 dataset 的相关信息:
bash
zfs list -t filesystem
NAME USED AVAIL REFER MOUNTPOINT
ZFS100G 672K 9.20G 96K /ZFS100G
ZFS100G/data 96K 9.20G 96K /ZFS100G/data2. Volume Dataset(zvol)
volume dataset 通常简称:zvol
它不是文件系统,而是:
它并不是传统意义上的文件系统,而是由 ZFS 提供的虚拟块设备(block device)。可供 iSCSI、数据库或虚拟机磁盘等场景使用。
例如:
bash
zfs create -V 1G ZFS100G/vm01创建完成后,系统会在 /dev/zvol/ 下生成对应的设备文件:
bash
ls -alh /dev/zvol/ZFS100G/vm01
lrwxrwxrwx 1 root root 9 May 10 10:56 /dev/zvol/ZFS100G/vm01 -> ../../zd0其中:
- /dev/zvol/ZFS100G/vm01 为 ZFS 提供的逻辑块设备
- zd0 为 Linux 内核识别到的实际 block device
系统会将其视为一块虚拟磁盘,因此可以进一步: - 格式化文件系统(ext4、xfs 等)
- 挂载使用
- 提供给虚拟机作为磁盘
- 用于 iSCSI、数据库等需要 block storage 的场景
也可以通过 zfs 命令查看该 volume:
bash
zfs list -t volume
NAME USED AVAIL REFER MOUNTPOINT
ZFS100G/vm01 1.02G 9.20G 56K filesystem 与 zvol 的区别
两者最本质的差异是:
| 类型 | 面向对象 |
|---|---|
| filesystem dataset | 文件 |
| zvol(volume dataset) | block device |
3. Snapshot Dataset
snapshot某个 dataset 在特定时间点的只读状态。
它的概念与 VMware 虚拟机 snapshot 类似,可用于:
- 数据回滚
- 误删恢复
- 备份
- 快速复制
- 历史版本保留
不过 ZFS snapshot 是基于 Copy-on-Write(COW)机制实现,因此建立速度非常快,且初始几乎不占额外空间。
需要注意的是:
当原始数据发生修改时,ZFS 会将新数据写入新的 block,而旧 block 会因 snapshot 仍在引用而被保留。
因此,snapshot 本身初始占用空间通常很小,但随着数据持续变更以及 snapshot 数量增加,被保留的历史数据块也会逐渐占用更多存储空间。
创建snapshot:
bash
zfs snapshot ZFS100G/data@snap01如下命令可查看已经创建的snapshot:
bash
zfs list -t snapshot
NAME USED AVAIL REFER MOUNTPOINT
ZFS100G/data@snap01 0B - 96K -
ZFS100G/vm01@snap01 0B - 56K -4. Bookmark Dataset
Bookmark 是 ZFS 中一种轻量级的快照参考点,可以理解为「快照的书签」。
为了说明bookmark的作用,我们先跟随下面的步骤
- 建立 Bookmark
首先查看现有的 snapshot:
bash
zfs list -t snapshot
NAME USED AVAIL REFER MOUNTPOINT
ZFS100G/data@snap01 56K - 96K -
ZFS100G/vm01@snap01 0B - 56K -- 建立 bookmark(
從 snapshot 建立 bookmark(注意:snapshot 用 @,bookmark 用 #):
bash
zfs bookmark ZFS100G/data@snap01 ZFS100G/data#bm01- 查看建立的 bookmark:
bash
zfs list -t bookmark
NAME USED AVAIL REFER MOUNTPOINT
ZFS100G/data#bm01 - - 96K 可以看到 USED 字段為 -,代表 bookmark 几乎不占用用任何磁盘空间。
Bookmark 的本质:只保存 createtxg
- 查看 snapshot 的 createtxg:
bash
zfs get createtxg ZFS100G/data@snap01
NAME PROPERTY VALUE SOURCE
ZFS100G/data@snap01 createtxg 1401685 - 查看 bookmark 的 createtxg:
bash
zfs get createtxg ZFS100G/data#bm01
NAME PROPERTY VALUE SOURCE
ZFS100G/data#bm01 createtxg 1401685 -两者的 createtxg 完全相同。这说明 bookmark 的核心就是保存了这个 TXG ID(Transaction Group ID)。
TXG 是 ZFS 的写入提交序号,每个资料区块都带有「由哪个 TXG 写入」的标记。有了这个序号,ZFS 在做增量传输(zfs send)时就能精确找出「哪些数据区块是在此之后发生变更的」。
核心使用场景:节省来源端空间的增量备份
Bookmark 最典型的用途是在备份完成后,让来源端可以删除 snapshot 释放空间,同时仍保留继续做增量备份的能力:
不同 snapshot 钉住不同版本的 block,就是为了保留每个时间点的完整状态,让你能还原到任意一个过去的时间点。代价就是这些旧版本 block 无法释放,snapshot 保留越多,占用空间越大。
我们来看看大致的过程:
bash
# 1. 建立 snapshot
zfs snapshot ZFS100G/data@snap01
# 2. 全量传输到备份端
zfs send ZFS100G/data@snap01 | zfs receive backup/data
# 3. 建立 bookmark,记录传输基准点
zfs bookmark ZFS100G/data@snap01 ZFS100G/data#bm01
# 4. 删除来源端 snapshot,释放空间
zfs destroy ZFS100G/data@snap01
# 5. 下次备份时,以 bookmark 为起点做增量传输
zfs snapshot ZFS100G/data@snap02
zfs send -i ZFS100G/data#bm01 ZFS100G/data@snap02 | zfs receive backup/data整个流程中,来源端通过 bookmark 记录「上次传输到哪个 TXG」,下次只需传输该 TXG 之后发生变更的数据块,无需保留占用空间的旧 snapshot。
需要注意的是:
bookmark 除了记录 TXG 外,会保留 snapshot lineage metadata等其他信息,用于确认 source 与 target 曾经共享同一个 snapshot ancestor。
否则:
增量 replication 的 block delta 将无法正确套用到目标端。
总结
本文完整拆解了 ZFS 存储池(zpool)的核心架构与各类 vdev 的设计逻辑、适用场景与选型原则。zpool 本质是storage vdev 与 support vdev 的集合,数据分布与容错能力均以 vdev 为基本单元,合理规划 vdev 拓扑直接决定存储系统的冗余能力、性能表现与空间利用率。
在存储 vdev 方面,Mirror 提供最佳读写性能与简单可靠的冗余,适合高性能、低延迟场景;RAIDz1/RAIDz2/RAIDz3 以校验方式实现不同等级容错,空间利用率更高,是大容量存储的主流选择,其中 RAIDz2 兼顾安全性与成本,通用性最强;DRAID 面向超大规模磁盘阵列,通过分布式重构与分布式热备大幅缩短重建窗口,提升集群整体可靠性,但需配合 SPECIAL vdev 弥补随机 I/O 短板。
Support vdev 作为性能增强组件,LOG(SLOG) 加速同步写入,适配数据库、NFS、虚拟化等关键业务;CACHE(L2ARC) 扩展内存读缓存,提升热点数据访问效率;SPECIAL vdev 专门承载元数据与小数据块,显著优化大规模阵列(尤其 DRAID)的随机性能;SPARE 则缩短降级运行时间,提升多 vdev 环境的可靠性。
从功能管理视角,ZFS 以 dataset 统一抽象文件系统、卷、快照与书签,实现灵活的资源分配、高效快照与轻量增量备份,简化运维并降低数据保护成本。
综上,ZFS 存储池配置无绝对最优方案,需围绕数据重要性、性能需求、磁盘规模与运维成本综合选型:追求性能优先选 Mirror;容量与平衡优先选 RAIDz2;大规模集群优先用 DRAID 并搭配 SPECIAL、LOG 等辅助 vdev;同时善用快照与书签建立可靠备份体系,最终构建出高性能、高可靠、易维护的企业级存储架构。