本文档整合了团队成员开发法律文书智能摘要系统时,在系统集成开发、功能模块实现、基础能力建设及问题治理等方面的工作。
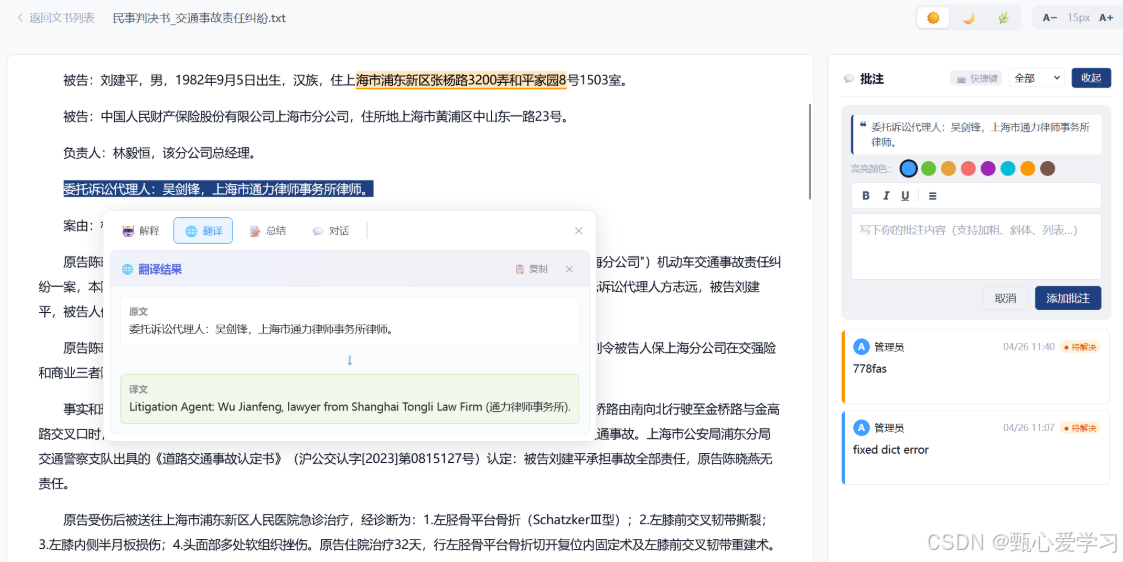
一、系统概述
legal-doc-analyzer 是一个法律文书智能分析平台,采用前后端分离架构:
- 前端:Vue 3 + Element Plus
- 后端:FastAPI + SQLite + ChromaDB
系统核心能力覆盖文书解析与结构化抽取、摘要生成与溯源、类案智能推荐、法律术语翻译、文档主题发现等多个维度,同时集成了悬浮AI助手与智能体交互能力,为用户提供一站式的法律文档分析体验。
二、核心功能模块
F0 --- 规则化信息抽取(基础模块)
规则化信息抽取是系统的核心基础模块,负责从非结构化的法律文书文本中提取结构化的关键信息,为后续的摘要生成、类案推荐等功能提供结构化输入。
核心特性:
- 正则+关键词组合规则引擎
- 字段标准化输出(统一字段名、数据类型)
- 来源切片ID追踪(便于溯源)
- 规则库热加载支持
关键技术实现:
- 案号抽取 :正则中融入
\s*处理PDF提取时产生的多余空格,兼容中文括号与英文括号混用情况 - 当事人识别:支持"原告/上诉人/申请人/公诉机关"等多称谓覆盖,使用非贪婪匹配配合明确终止符避免过度匹配
- 法院名称:优先搜索文书前500字符,因法院名称通常出现在文书开头
- 日期抽取:取全文最后一个日期匹配项,因判决日期通常在文书末尾
- 案件类型检测:采用关键词投票机制,统计民事、刑事、行政三类案件特征关键词的出现次数,取最高分者为判定结果
关键文件 :extractor.py
前端展示 (FieldsDisplay.vue):
- 字段分组管理(基本信息、当事人信息、案件信息、判决信息),默认展开"基本信息"和"当事人信息"两组
- 实时统计字段识别率,帮助用户快速评估抽取质量
- 支持多种展示类型:普通文本、标签徽章、标签列表
F1 --- 溯源元数据管理(基础设施)
溯源元数据管理是为上层溯源功能提供精确位置定位能力的基础设施,实现了文档级 → 页面级 → 切片级的三级元数据管理体系。
核心数据模型 (schemas.py):
| 层级 | 核心字段 | 作用 |
|---|---|---|
| 文档级 | doc_id, filename, doc_type, upload_time, case_type | 文档整体标识与分类 |
| 页面级 | page_num, page_size | 页面维度定位 |
| 切片级 | chunk_id, bbox_list, block_indices, confidence | 精确坐标与溯源路径 |
设计亮点:
bbox_list保存切片包含的所有文本块边界框[x0, y0, x1, y1],支持前端精确定位高亮block_indices记录切片与原始文本块的映射关系,实现双向溯源page_start/page_end快速定位切片所在页面范围
切片生成策略 (chunker.py):
- 语义边界感知 :以标题块(
block_type == "title")作为自然分割点 - 重叠机制:保留上一个切片末尾部分(默认重叠64字符),确保切片边界处的上下文不丢失
- 滤除页眉页脚 :自动跳过
header/footer类型的文本块
数据库持久化 (database.py):
- 使用 JSON 格式存储
bbox_list和block_indices复杂结构 - 支持外键级联删除(
ON DELETE CASCADE)
溯源查询 API (documents.py):
GET /{doc_id}/chunks:获取文档所有切片,含chunk_id、content、page_start/end、bbox_list、block_indices- 通过
block_indices可反向查询原始文本块,实现切片到原文的溯源定位
F2 --- 摘要溯源
在 LLM 生成文书摘要的基础上,将每条关键要素与原文段落对应起来,前端点击摘要要点可跳转到原文并高亮。
实现方式:
- 通道1(硬约束) :在 Prompt 中要求 LLM 在要点后面标注
[来源: X, Y] - 通道2(语义匹配) :使用
text-embedding-3-small计算要点和原文块的余弦相似度 - 通道3(文本重叠):ROUGE-L 计算文本重叠度
- NLI过滤:LLM 做 NLI 三分类,过滤矛盾来源
- 最终融合:三通道加权融合 + MMR 多样性选择
关键文件 :summarizer.py、source_fusion.py、rouge.py、nli_verifier.py、mmr.py、SummaryPanel.vue
F3 --- 类案推荐
给定一篇文书,从已有文档库中找出最相似的案例。
三级检索架构:
| 阶段 | 方法 | 说明 |
|---|---|---|
| Stage 1a | ChromaDB 向量检索(Dense) | 稠密向量语义匹配 |
| Stage 1b | BM25 关键词检索(Sparse) | 稀疏关键词匹配 |
| Stage 1c | CaseGNN 图增强相似度(Graph) | 基于文档关系图的图检索 |
| Stage 2 | RRF 三路融合 + 四维结构化要素重排序 | 案件类型0.15 + 案由Jaccard0.30 + 争议焦点0.25 + 法条引用0.30 |
| Stage 3 | Cross-Encoder 精排 | LLM 二次打分 |
最终五信号融合输出推荐结果。
关键文件 :enhance.py、bm25.py、case_graph.py、fusion.py、reranker.py、vector_store.py
F4 --- 三轮自检翻译
对法律文书摘要进行中英翻译,采用三轮迭代机制 + 多维度质量评估。
三轮流程:
- Round 1:初始翻译,注入45条法律术语词典 + TF-IDF发现的词汇表外术语
- Round 2:术语校验,输出修正记录
- Round 3:完整性验证,检测遗漏/幻觉/偏差三类问题
后验评估指标:
- BLEU 收敛检测
- Levenshtein 编辑距离
- 回译一致性
- ROUGE-L
- 术语一致性检查
综合评分公式:
LLM 自评 × 0.25 + 回译 BLEU × 0.25 + ROUGE-L × 0.20 + 术语一致性 × 0.15 + 术语覆盖率 × 0.15
关键文件 :translator.py、bleu.py、levenshtein.py、back_translator.py、consistency_checker.py、terminology.py、rouge.py
F5 --- 主题建模
对整个文档库做无监督主题发现,前端用散点图可视化展示文档聚类结果。
技术链路:
OpenAI Embedding → UMAP 降维 → HDBSCAN 聚类 → c-TF-IDF 主题词提取 → LLM 语义标签生成
特色实现:
- UMAP 和 HDBSCAN 全部用纯 NumPy 从零实现(~360行 + ~443行),不依赖
bertopic/umap-learn/hdbscan库 - 法律文本专用清洗:去除人名、地名、法院名、案号、金额、法条引用等干扰信息
- 扩展停用词表覆盖法律程序套话
- LLM 为每个主题生成语义标签
关键文件 :topic_modeler.py、umap_impl.py、hdbscan_impl.py
三、模块间依赖关系
┌─ text-embedding-3-small ─┐
│ │
F2 溯源 ──────┤ ├── F5 主题建模
(cosine sim) │ OpenAI Embedding API │ (UMAP 输入)
│ │
F3 类案 ──────┤ │
(ChromaDB) └───────────────────────────┘
F2 溯源 ────── rouge.py ────── F4 翻译
(ROUGE通道) (回译ROUGE-L)
F3 类案 ────── bm25.py / fusion.py / case_graph.py / reranker.py共用模块:
rouge.py被 F2(ROUGE-L 通道)和 F4(回译忠实度评估)共用- OpenAI Embedding API 被 F2(要点-块匹配)、F3(ChromaDB 入库/检索)、F5(文档向量化)共用
mmr.py的_cosine_similarity被 F2 的溯源管线和融合模块使用
四、系统集成联调测试
4.1 测试环境
- Windows 10,Python 3.11,Node.js 18
- 后端:
uvicorn app.main:app --reload - 前端:
npm run dev(Vite) - 数据库:SQLite(
legal_docs.db)+ ChromaDB(chroma_data/)
4.2 测试用例与结果
用例1:全流程走通
上传一份民事判决书 PDF → 系统自动解析、分块、入库 ChromaDB → 生成摘要(F2)→ 查看类案推荐(F3)→ 翻译摘要(F4)→ 查看主题建模散点图(F5)。
结果:全流程走通。
发现问题:
- 文档少于2篇时主题建模接口返回空结果(已加提示文案)
- 类案推荐在只有1篇文档时也无结果(逻辑正确,前端待加空状态提示)
用例2:溯源准确性抽查
选取3篇不同类型的文书(民事合同纠纷、刑事故意伤害、行政处罚),手动检查溯源标签指向的原文块正确性:
| 文书 | 要点数 | 有溯源标签 | 抽查正确 |
|---|---|---|---|
| 合同纠纷判决 | 5 | 4 | 3/4 |
| 故意伤害判决 | 6 | 5 | 5/5 |
| 行政处罚裁定 | 4 | 3 | 2/3 |
分析:错误的2个要点均为"间接引用"类型(概括性表述),余弦相似度阈值0.45需根据文书类型进一步调优。
用例3:翻译质量检查
用一份约300字的裁定书摘要进行翻译测试:
| 指标 | 结果 |
|---|---|
| 综合分 | 88.3 |
| 三轮是否收敛 | 是(R2→R3 BLEU > 0.95) |
| 术语修正 | 1处 |
| 回译 ROUGE-L | 0.81 |
关键发现:Round 2 曾将一个正确术语改错,但 Round 3 通过完整性验证纠正了回来,说明三轮机制有效。
用例4:主题建模散点图
上传8篇文书(3篇合同纠纷、3篇故意伤害、2篇交通肇事)。HDBSCAN 分出3个主题,三组文档在散点图上明显分开,c-TF-IDF 提取的主题词合理(合同组有"合同/违约/赔偿",刑事组有"故意/伤害/鉴定"等)。
发现问题:一篇短篇幅刑事文书(仅2个块)因清洗后文本太少导致 Embedding 质量差,被标为噪声。
4.3 性能观察
| 操作 | 平均耗时 | 瓶颈 |
|---|---|---|
| 摘要生成(含溯源) | 8-15s | LLM 生成 + NLI 验证 |
| 类案推荐 | 3-6s | Cross-Encoder 精排 |
| 三轮翻译 | 15-25s | 三轮 LLM + 一次回译(至少4次API调用) |
| 主题建模 | 5-12s | Embedding API(取决于文档数) |
本地计算部分(余弦相似度、ROUGE-L DP、UMAP SGD、HDBSCAN MST)均在1秒以内,所有瓶颈在 OpenAI API 调用。
五、新增功能
5.1 悬浮AI工具
在文档阅读区域集成类似飞书的悬浮 AI 工具栏,支持文本选区自动弹出、多轮对话等功能。
使用流程:
- 在文档阅读区域按住鼠标左键拖动选择一段文字
- 松开鼠标左键
- 选区正上方自动弹出 AI 工具栏
- 点击任意功能按钮(解释/翻译/总结/对话)
后端 API (backend/app/api/ai_tools.py):
POST /api/ai/explain--- 解释选中的法律术语或概念POST /api/ai/translate--- 翻译选中文本(支持 zh2en/en2zh/auto)POST /api/ai/summarize--- 摘要选中文本POST /api/ai/chat--- 多轮对话(支持流式输出)
前端组件:
AiFloatingToolbar.vue--- 悬浮工具栏(毛玻璃效果、淡入动画、自动位置自适应)AiResultCard.vue--- 结果展示卡片(Markdown渲染、复制、重试)AiChatPopover.vue--- 聊天弹窗(多轮对话历史、流式打字机效果、可拖拽调整大小)
集成说明:阅读模式与编辑模式均支持该工具,详情页面中的结构化信息、类案推荐、关键词分析等模块与 AI 工具共存。
5.2 智能体交互(法智助手)
新增独立的 AI 交互页面(AssistantView.vue),支持文档检索、增强问答与文书对比分析三大功能。
后端 API (assistant.py):
| 端点 | 功能 | 说明 |
|---|---|---|
POST /api/assistant/chat |
智能问答 | 通用 AI 对话,支持多轮历史 |
POST /api/assistant/rag-chat |
文档增强问答 | 基于 ChromaDB 向量检索的 RAG 问答,返回参考文书来源 |
POST /api/assistant/search-docs |
文档检索 | 支持混合/精确/语义三种检索模式 |
GET /api/assistant/doc-list |
文档列表 | 获取所有文书供对比选择 |
POST /api/assistant/compare |
文书对比 | AI 生成结构化对比分析报告(2-5份文书) |
前端实现 (AssistantView.vue):
- 智能问答:聊天式界面,支持文档增强(RAG)与通用问答两种模式,快捷问题推荐,参考文书来源标签可点击跳转,Markdown 渲染,Enter 发送
- 文档检索:三种检索模式切换,搜索结果卡片展示文件名、案号、法院、匹配类型、相关度
- 文书对比:多选 2-5 份文书,支持关注重点输入,AI 生成结构化对比分析报告
路由与导航 :在 main.ts 中添加 /assistant 路由,在 App.vue 侧边栏新增"法智助手"导航项。
5.3 文档详情返回与历史定位
实现了从历史记录或示例入口返回文档列表时,能够自动定位并高亮到对应文档位置。
场景1 --- 从历史记录返回:
- 用户在首页/阅读页查看文档 → 系统自动记录到历史记录
- 用户点击历史记录条目 → 导航至
/documents?highlight=xxx - 文档列表自动加载 → 平滑滚动到目标文档行 → 高亮边框 + 脉冲动画(3秒)→ 清除 URL 参数
场景2 --- 首次访问/示例展示:
- 用户访问首页 → 展示统计数据横幅、上传区域、示例文书区域(民事/刑事/行政判决书)
- 点击示例文书 → 加载示例内容到数据库 → 跳转到阅读页面 → 显示完整 AI 分析界面
5.4 主题模式统一整合
问题:左侧栏只有深色/浅色切换,阅读页有亮色/暗色/护眼三种模式,两个入口使用不同的 UI 风格且状态可能不同步。
解决方案:
- 两个入口统一使用同一个
useThemeStore() - 都调用
themeStore.setTheme(t.key)变更主题 - 都读取
themeStore.theme判断当前状态 localStorage统一存储
六、开发问题与反思
6.1 组件导入缺失的隐蔽性
问题 :Vue 模板中使用的组件若未在脚本中正确导入,框架不会给出明确错误提示,而是静默失败。例如 DocumentView.vue 中使用了 <KeywordCloud> 组件但未导入,导致关键词分析 Tab 显示空白。
解决方案:
- 建立模板组件的使用检查清单
- 优先采用
<script setup>配合 TypeScript 的写法,借助编译器进行更早的静态检查
6.2 SQLite 使用中的易忽略限制
常见问题:
ALTER TABLE操作能力有限- 外键约束在删除记录时顺序敏感(
annotation_history表有级联引用,需先清理关联数据再删除) - 不支持原生 Python 类型(需要手动 JSON 序列化)
- 相对路径在多环境下可能解析失败
解决方案:
- 优先使用 SQLAlchemy ORM 封装底层差异
- 制定数据库迁移操作检查清单
- 使用基于
BACKEND_DIR的绝对路径,避免相对路径
6.3 状态管理的一致性问题
问题:主题模式、用户登录状态等全局信息若由多个入口独立管理,容易出现状态不同步的异常。
解决方案:
- 尽早引入统一的状态管理方案(Pinia)
- 确保每一个状态只有一个可信来源
- 所有状态修改都通过统一的 API 进行变更
6.4 相对路径的不可靠性
问题 :config.py 中 data_dir 使用相对路径 data,uvicorn 在不同工作目录下会连接到不同数据库文件。
解决方案:
- 避免在任何代码中直接使用相对路径
- 使用
Path(__file__).resolve()计算绝对路径 - 通过环境变量进行配置
6.5 DELETE HTTP 方法路由异常
问题 :uvicorn --reload 对 DELETE 方法的路由存在缓存问题,同样的代码在 GET 中正常但在 DELETE 中返回 404。
解决方案 :改用 POST /delete 端点,这是业界常见模式。
6.6 用户流程测试的重要性
问题:单元测试仅能保证单个组件或函数的正确性,但多个功能组合后的用户流程可能存在断点。例如从首页进入示例文书详情页,再返回列表并高亮对应文档的完整链路。
解决方案:编写覆盖完整"用户故事"的流程测试,重点验证导航闭环是否通畅。
6.7 错误信息的友好化设计
问题 :直接将底层异常(如 sqlite3.OperationalError)抛给用户既不安全也不友好。
解决方案:建立三层异常处理链:
- 底层捕获原始异常
- 中间层转换为业务可理解的错误类型
- 最上层向用户展示友好的提示信息(如"文档不存在""服务错误""加载中...")
七、遗留问题与优化方向
7.1 已知问题
| 问题 | 描述 | 后续方案 |
|---|---|---|
| 溯源间接引用问题 | 概括性要点与原文不是逐字对应时,余弦相似度区分度不够 | 加入 Cross-Encoder 对溯源候选做精排 |
| 翻译 JSON 解析脆弱 | LLM 输出有时非标准 JSON,虽有三层兜底策略但仍有失败 | 进一步优化解析鲁棒性 |
| 主题建模小文档问题 | 篇幅太短的文书(<100字)清洗后 Embedding 质量差,易被标为噪声 | 对短文档不做清洗或降低清洗力度 |
| CaseGNN 图信号弱 | 结构化字段提取不完整时(如案由为空),图信号很弱 | 增强字段提取完整性或降低该路检索权重 |
7.2 优化方向
- 翻译模块:改成流式输出(SSE),用户可看到每轮的中间结果
- 主题建模:做持久化缓存,避免每次都重新计算
- 类案推荐 :Cross-Encoder 用更便宜的模型(如
gpt-4o-mini)降低成本 - 前端体验:对各功能的空状态和错误状态做更好的提示
- 规则化抽取:完善争议焦点和 OCR 分块功能,引入规则库热加载和测试界面
八、关键文件清单
| 模块 | 后端关键文件 | 前端关键文件 |
|---|---|---|
| 信息抽取 | extractor.py |
FieldsDisplay.vue |
| 溯源元数据 | schemas.py, chunker.py, database.py |
--- |
| F2 摘要溯源 | summarizer.py, source_fusion.py, rouge.py, nli_verifier.py, mmr.py |
SummaryPanel.vue, DocumentView.vue |
| F3 类案推荐 | enhance.py, bm25.py, case_graph.py, fusion.py, reranker.py, vector_store.py |
DocumentView.vue(类案 tab) |
| F4 三轮翻译 | translator.py, bleu.py, levenshtein.py, back_translator.py, consistency_checker.py, terminology.py |
SummaryPanel.vue(翻译入口) |
| F5 主题建模 | topic_modeler.py, umap_impl.py, hdbscan_impl.py |
StatisticsView.vue |
| 悬浮 AI 工具 | ai_tools.py |
AiFloatingToolbar.vue, AiResultCard.vue, AiChatPopover.vue |
| 智能体交互 | assistant.py |
AssistantView.vue |
| 公共 | config.py, vector_store.py |
api/documents.ts, api/enhance.ts |
本次开发涵盖了从基础数据结构、规则化信息抽取、多路融合检索,到上层智能交互的完整技术栈。通过系统集成测试与迭代优化,系统已具备法律文书智能分析的核心能力。后续将在上述优化方向上持续推进,不断提升系统的鲁棒性与用户体验。