目录
- 一、引言
- [二、基础知识点CountVectorizer 与词频统计](#二、基础知识点CountVectorizer 与词频统计)
- 三、实战项目:评论情感分析
- 四、进阶:用大模型搭建交互网页
一、引言
在自然语言处理(NLP)入门中,文本分类是一个非常经典的任务。今天,我将带你从最基础的词频统计开始,一步步构建一个能够自动判断评论是"好评"还是"差评"的情感分析模型。
本文会用到 scikit-learn 的 CountVectorizer 做文本向量化,用 jieba 做中文分词,最后用朴素贝叶斯分类器完成训练和预测。整个过程会包含完整的代码和详细的注释。
二、基础知识点CountVectorizer 与词频统计
在开始实战之前,我们先了解一下 CountVectorizer 的核心用法。它能把自然语言文本转换成机器学习模型能处理的数字矩阵,属于"基于统计的文本特征提取"方法。
python
from sklearn.feature_extraction.text import CountVectorizer
texts = ["dog cat fish", "dog cat cat", "fish bird", "bird"]
cv = CountVectorizer(max_features=6, ngram_range=(1, 3))
cv_fit = cv.fit_transform(texts)
print(cv_fit)
print(cv.get_feature_names_out())
print(cv_fit.toarray())1、主要知识点
这段代码演示了 CountVectorizer 最核心的用法,下面逐行拆解:
from sklearn.feature_extraction.text import CountVectorizer:从 scikit-learn 的特征提取模块中导入词频向量化工具。这是文本分类中最常用的特征提取器之一。
texts = ["dog cat fish", "dog cat cat", "fish bird", "bird"]:定义了一个包含 4 条英文文本的列表,每条文本由空格分隔的单词组成。
cv_fit = cv.fit_transform(texts):这是两步合一的操作。fit 阶段根据输入的所有文本,统计出所有符合 ngram_range 的词/词组,并按频率排序筛选出前 6 个,生成词库。transform 把每一条文本转换成对应词库的词频向量,输出一个稀疏矩阵。
print(cv_fit):打印稀疏矩阵,只存储非零元素的位置和数值,节省内存。输出格式为 (行索引, 列索引) 数值。
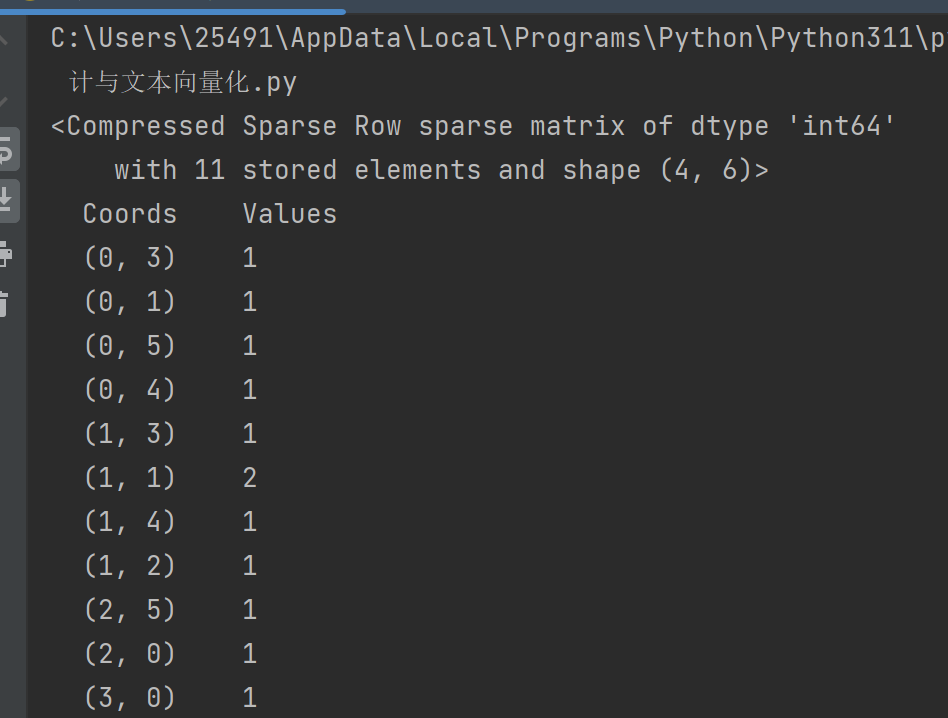
print(cv.get_feature_names_out()):输出词库中的词列表,即筛选出来的前 6 个词/词组。

print(cv_fit.toarray()):将稀疏矩阵转换成普通的二维数组,每一行对应一条文本,每一列对应词库中的一个词,数值是该词在文本中出现的次数。
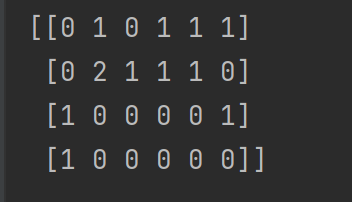
2、参数讲解
cv = CountVectorizer(max_features=6, ngram_range=(1, 3)):初始化向量化器,这里有两个关键参数需要重点理解:
ngram_range=(1, 3) :控制词/词组的组合长度范围。(1, 3) 表示同时提取单个词(1-gram)、两个词的组合(2-gram)和三个词的组合(3-gram)。例如文本 "dog cat fish" 会提取出:dog、cat、fish、dog cat、cat fish、dog cat fish。这个参数越大,能捕捉的语义信息越丰富,但特征维度也会急剧膨胀。
max_features=6:限制最终保留的特征数量(即词/词组的总数),只保留出现频率最高的前 6 个。这是一个重要的降维手段,可以防止特征过多导致维度灾难和过拟合。在实际项目中,这个值通常设为 1000~10000 之间。
三、实战项目:评论情感分析
1、项目目标
我们手头有两份从苏宁易购网站爬取的关于商品评价的文本文件:差评.txt 和 好评.txt。目标是训练一个模型,能够自动判断任意一条新评论的情感倾向(好评或差评)。
2、数据读取与分词
首先,用 pandas 读取数据,并用 jieba 进行中文分词。
python
import pandas as pd
import jieba
cp_content = pd.read_table(r".\差评.txt", encoding='utf-8', header=None)
yzpj_content = pd.read_table(r".\好评.txt", encoding='utf-8', header=None)
# 差评分词
cp_segments = []
contents = cp_content[0].values.tolist()
for content in contents:
results = jieba.lcut(content)
if len(results) > 1:
cp_segments.append(results)
# 好评分词
yzpj_segments = []
contents = yzpj_content[0].values.tolist()
for content in contents:
results = jieba.lcut(content)
if len(results) > 1:
yzpj_segments.append(results)
# 分词结果保存
cp_fc_results = pd.DataFrame({'content': cp_segments})
cp_fc_results.to_excel('cp_fc_results.xlsx', index=False)
yzpj_fc_results = pd.DataFrame({'content': yzpj_segments})
yzpj_fc_results.to_excel('yzpj_fc_results.xlsx', index=False)jieba.lcut() 返回的是分词列表,if len(results) > 1 用于过滤掉分词后只有一个词(通常是标点或单字)的无效行,避免后续处理出错。pd.read_table() 的 header=None 参数不能漏,否则第一行数据会被误当作列名。
3、去除停用词
停用词(如"的"、"了"、"是"等)对分类任务贡献不大,反而会增加噪声,因此需要去除。
python
stopwords = pd.read_csv(r".\StopwordsCN.txt", encoding='utf8', engine='python', index_col=False)
def drop_stopwords(contents, stopwords):
segments_clean = []
for content in contents:
line_clean = []
for word in content:
if word in stopwords:
continue
line_clean.append(word)
segments_clean.append(line_clean)
return segments_clean
contents = cp_fc_results.content.values.tolist()
stopwords_list = stopwords.stopword.values.tolist()
cp_fc_contents_clean_s = drop_stopwords(contents, stopwords_list)
contents = yzpj_fc_results.content.values.tolist()
yzpj_fc_contents_clean_s = drop_stopwords(contents, stopwords_list)stopwords.stopword.values.tolist() 中的 stopword 是停用词文件中的列名,如果列名不一致(比如叫 word 或 stopword),需要根据实际文件内容修改,建议先用 print(stopwords.columns) 确认列名。
4、构建分类数据集
将清洗后的文本打上标签:差评为 1,好评为 0,并合并成一个完整的数据集。
python
cp_train = pd.DataFrame({'segments_clean': cp_fc_contents_clean_s, 'label': 1})
yzpj_train = pd.DataFrame({'segments_clean': yzpj_fc_contents_clean_s, 'label': 0})
pj_train = pd.concat([cp_train, yzpj_train])
pj_train.to_excel('pj_train.xlsx', index=False)将预处理(分词、去停用词、打标签)后的中间结果持久化到磁盘,后续可以直接读取该 Excel 文件进行模型训练,避免每次运行程序都重新做分词和清洗(尤其当数据量较大时,能节省大量时间);同时方便人工查看数据是否正确。
5、特征提取与模型训练
这是核心环节。我们将分词后的文本列表拼接成空格分隔的字符串,然后用 CountVectorizer 将其转换为词频向量,最后用朴素贝叶斯分类器进行训练。
python
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
x_train, x_test, y_train, y_test = train_test_split(
pj_train['segments_clean'].values, pj_train['label'].values, random_state=0
)
words = []
for line_index in range(len(x_train)):
words.append(' '.join(x_train[line_index]))
vec = CountVectorizer(max_features=4000, lowercase=False, ngram_range=(1, 3))
vec.fit(words)
x_train_vec = vec.transform(words)
classifier = MultinomialNB(alpha=0.1)
classifier.fit(x_train_vec, y_train)
train_pr = classifier.predict(x_train_vec)
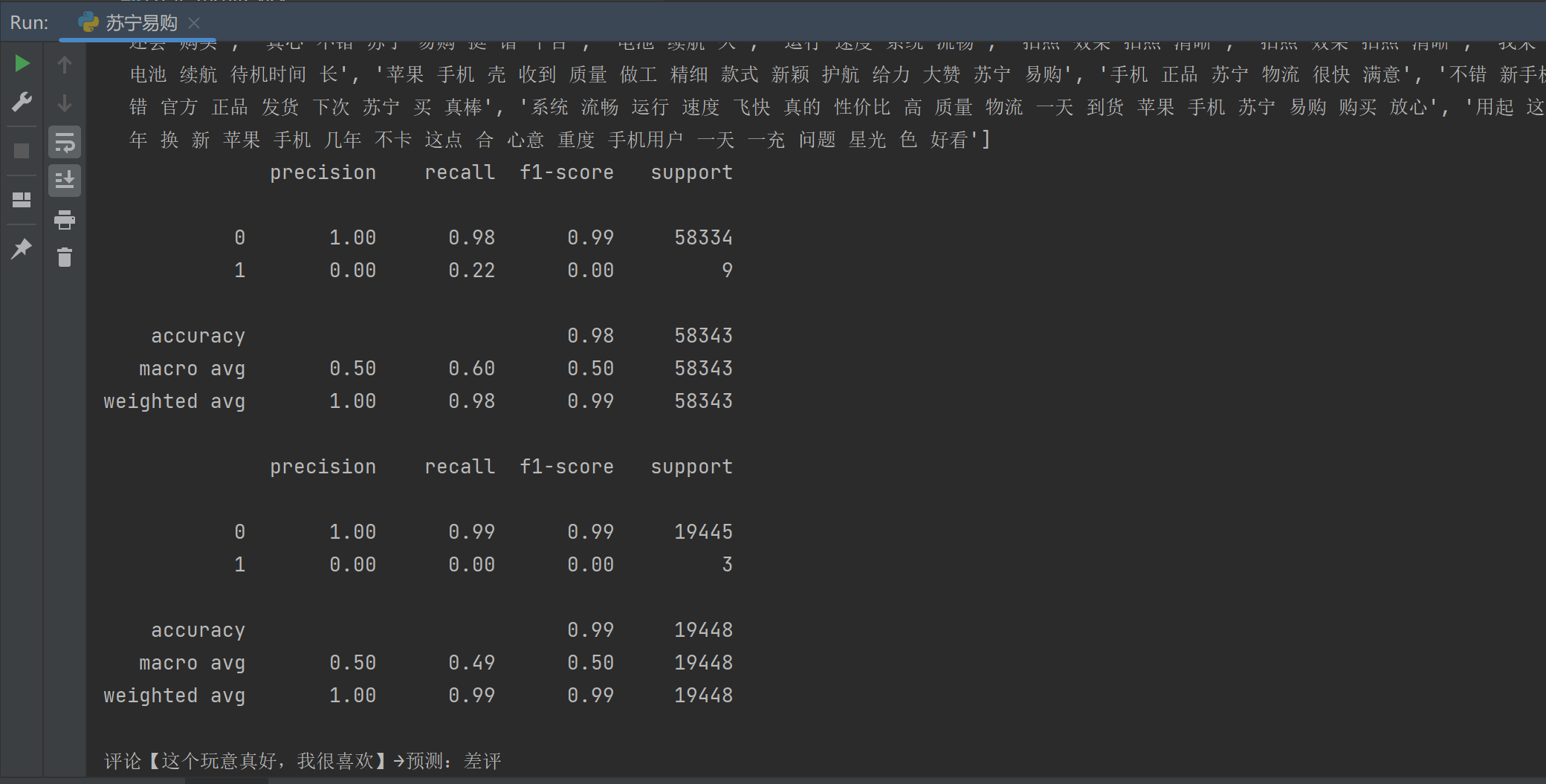
print("训练集评估结果:")
print(metrics.classification_report(y_train, train_pr))max_features=4000:限制特征数量为 4000,避免维度灾难,数据量大时可适当增大。
ngram_range=(1, 3):同时考虑单个词、双词组合和三词组合,捕捉更多语义信息。对于中文评论,2-gram 和 3-gram 能有效捕捉"不好"、"非常差"等短语级情感。
alpha=0.1:拉普拉斯平滑系数,防止零概率问题。当某个词在训练集中未出现时,平滑系数可以避免概率为 0 导致整个预测失败。值越小,对原始频率的依赖越大;值越大,平滑效果越强。
和vec.transform(words)必须分开调用,且fit只能在训练集上执行一次。如果误写成vec.fit_transform(words),虽然语法上没错,但后续测试集和新数据就无法正确向量化了。另外,words列表中的每个元素必须是空格分隔的字符串,不能是原始的分词列表,否则CountVectorizer` 会把整个列表当成一个字符串处理。
6、测试集评估
用同样的方式处理测试集,并评估模型在未见过的数据上的表现。
python
test_words = []
for line_index in range(len(x_test)):
test_words.append(' '.join(x_test[line_index]))
test_pr = classifier.predict(vec.transform(test_words))
print("测试集评估结果:")
print(metrics.classification_report(y_test, test_pr))测试集向量化时只能用 vec.transform(),绝对不能再次调用 vec.fit() 或 vec.fit_transform()。fit 只能调用一次,否则测试集的词库会和训练集不一致,导致预测结果完全错误。
7、模型预测与保存
训练好的模型可以用来预测任意新评论。同时,我们将模型和向量化器保存到磁盘,方便以后直接使用。
python
s = '这个玩意真好,我很喜欢'
cut_list = jieba.lcut(s)
cut_str = ' '.join(cut_list)
s_vec = vec.transform([cut_str])
result = classifier.predict(s_vec)
if result[0] == 1:
print(f"评论【{s}】→预测:好评")
else:
print(f"评论【{s}】→预测:差评")
import joblib
joblib.dump(classifier, 'nb_model.pkl')
joblib.dump(vec, 'count_vectorizer.pkl')
joblib.dump(stopwords, 'stopwords.pkl')在预测新评论时,一定要使用训练好的 vec.transform() 进行向量化,而不是 vec.fit_transform()。fit 只能在训练集上调用一次,测试集和新数据只能调用 transform,否则会导致词库不一致,预测结果完全错误。vec.transform([cut_str]) 中传入的参数必须是列表形式(即使只有一条评论),因为 CountVectorizer 要求输入是文本列表。joblib.dump 保存的三个 .pkl 文件后续可以直接加载使用,无需重新训练。
代码运行展示
四、进阶:用大模型搭建交互网页
模型训练好了,但每次预测都要跑 Python 代码,不够方便。我们可以借助大模型(如 ChatGPT、Claude 等)帮我们生成一个 HTML 网页,让用户直接在浏览器中输入评论,点击按钮就能得到预测结果。
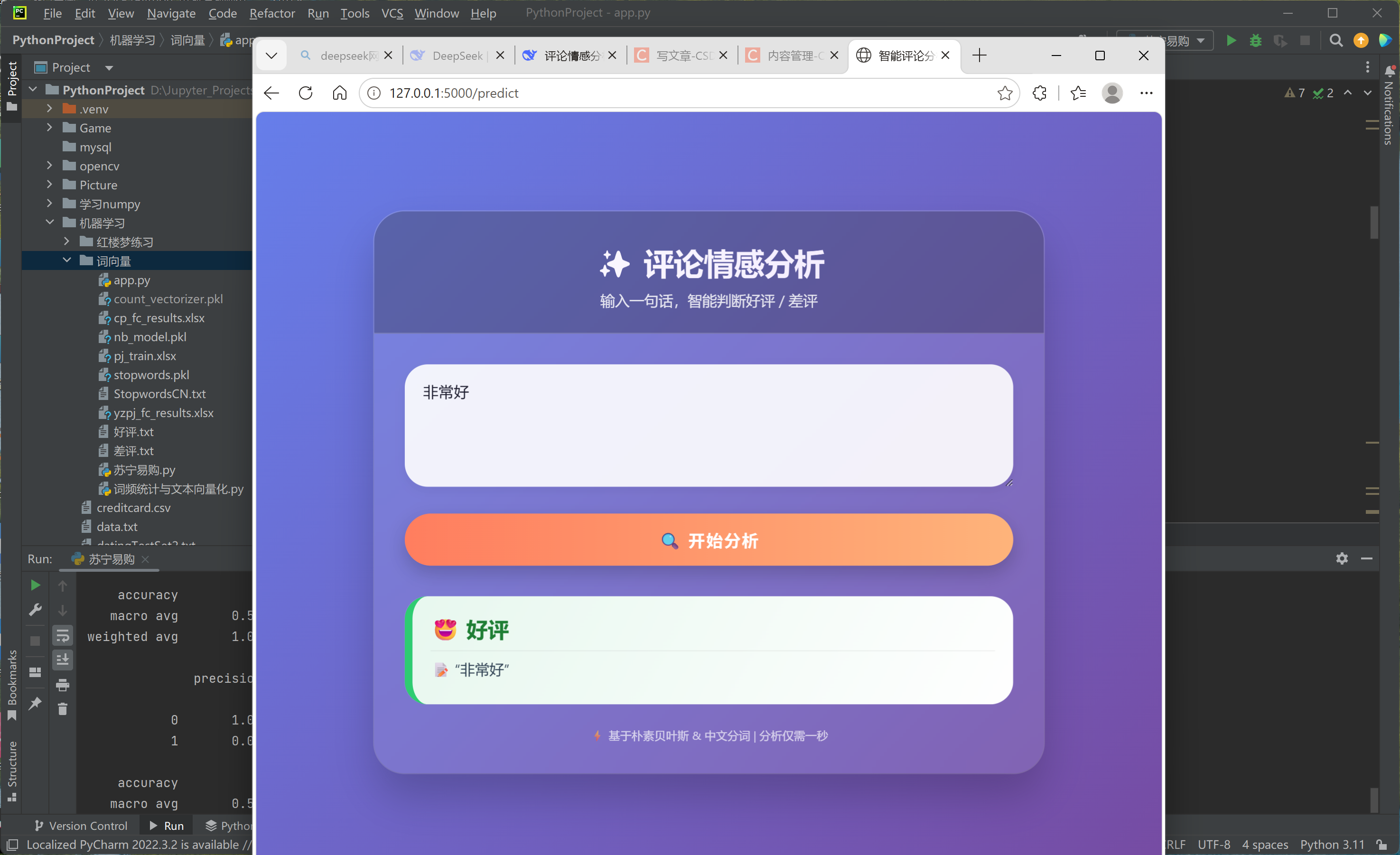
我们已经有三个关键文件:nb_model.pkl(训练好的朴素贝叶斯模型)、count_vectorizer.pkl(词向量转换器)、stopwords.pkl(停用词表)。大模型可以帮我们生成一个 Flask 后端 + HTML 前端的简易 Web 应用,后端加载模型并暴露 API,前端提供输入框和结果显示区域。确保已安装 Flask:pip install flask,运行 python app.py,在浏览器中访问 http://127.0.0.1:5000,输入评论点击"判断情感"即可看到预测结果。
成果展示