文章目录
bitsandbytes:大语言模型低内存运行的核心工具
GitHub上的bitsandbytes项目,目前已有8183个Star,专门为PyTorch提供k-bit量化能力,核心作用是大幅降低大语言模型推理和训练的内存消耗。
它的核心功能主要有三个。第一个是8位优化器,采用块级量化方案,能在仅占用少量内存的情况下,保持32位精度的运行效果。第二个是LLM.int8() 8位量化技术,仅需要原来一半的内存就能完成大语言模型推理,同时不会带来任何性能下降。该方法基于向量级量化,将大部分特征量化为8位,对异常值单独采用16位矩阵乘法处理。第三个是QLoRA 4位量化技术,结合多种内存节省方案,可在不损失性能的前提下完成大语言模型训练。该方法将模型量化为4位,同时插入少量可训练的低秩适配权重,实现训练效果。库内还包含8位和4位运算的量化原语,通过bitsandbytes.nn.Linear8bitLt、bitsandbytes.nn.Linear4bit模块提供量化线性层,通过bitsandbytes.optim模块提供8位优化器。
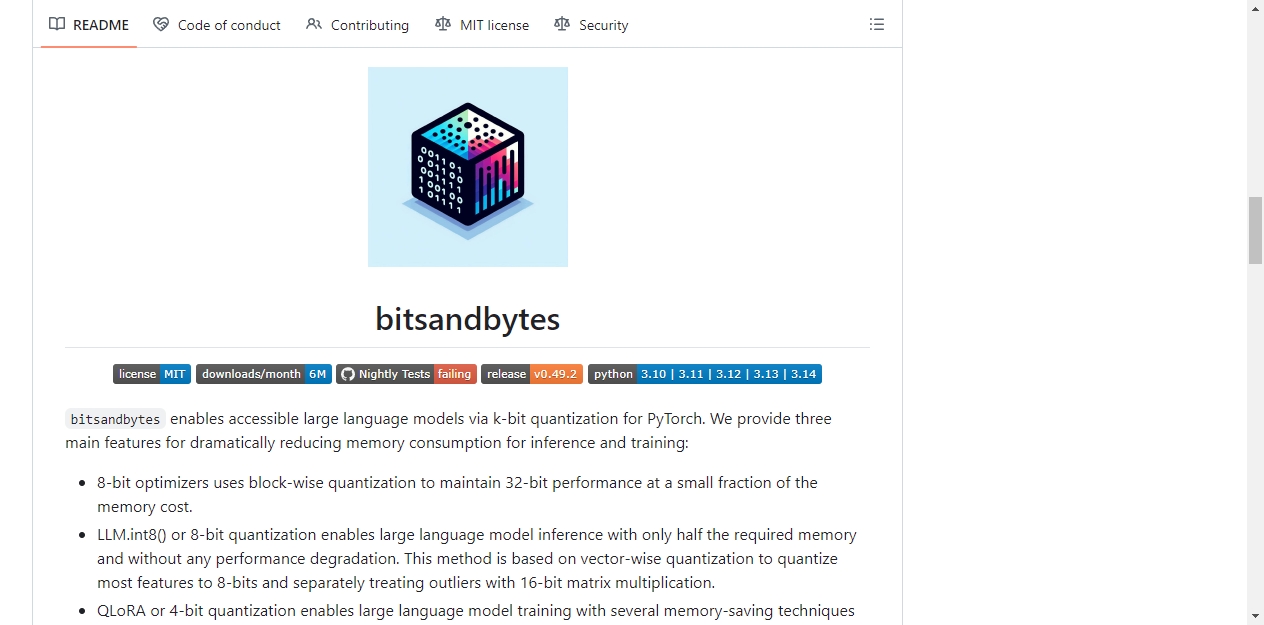
运行bitsandbytes的最低要求为Python 3.10及以上版本,PyTorch 2.3及以上版本。官方推荐使用最新版PyTorch以获得更好的使用体验。硬件支持覆盖多个平台。Linux系统下支持x86-64和aarch64架构,CPU要求最低支持AVX2指令集,同时支持NVIDIA、AMD、Intel的主流GPU,以及Intel Gaudi加速卡。Windows系统下支持x86-64架构的CPU和NVIDIA、AMD、Intel的主流GPU。macOS系统下支持Apple M1及以上芯片的CPU和Metal加速。不同硬件对各项功能的支持程度存在差异,具体可参考官方文档的支持矩阵。
对于需要运行大语言模型的开发者来说,bitsandbytes是常用工具。在推理场景下,使用8位量化可以让显存占用减半,在消费级显卡上也能运行更大参数的模型。在训练场景下,QLoRA技术可以让用户在普通消费级显卡上完成7B甚至13B参数模型的微调,不需要昂贵的专业计算卡。目前该库已被Hugging Face的Transformers、Diffusers、PEFT等主流库集成,用户可以直接在这些库的量化功能中调用bitsandbytes的能力,不需要额外做复杂配置。
bitsandbytes采用MIT协议开源,代码完全公开。项目的持续维护得到了Hugging Face、Intel等企业的赞助,更新节奏稳定。如果你的工作涉及大语言模型的推理或微调,可以尝试使用这个工具来降低硬件需求。
试使用这个工具来降低硬件需求。