1、概述
MinerU 专注于高效解析和提取复杂的 PDF 文档、网页和电子书,并将其转换为易于分析的 Markdown 或
JSON 格式。由 上海人工智能实验室OpenDataLab 团队 开发。
主要功能包括:
• PDF 转 Markdown
支持多模态 PDF(含图片、表格、公式等)的结构化转换。
自动去除页眉、页脚、脚注等干扰信息,保留标题、段落、列表等结构。
公式识别并转换为 LaTeX 格式,表格转换为 HTML 或 Markdown。
• 网页内容提取:从网页中剔除广告等干扰信息,精准提取正文、评论、视频文字等内容。
• 电子书转换:支持 epub、mobi、docx、pptx、chm、azw 等格式批量转 Markdown。
• 多语言 OCR:自动检测扫描版 PDF 和乱码,支持 84 种语言 的 OCR 识别
2、使用
• 在线使用
https://mineru.net/OpenSourceTools/Extractor
• 客户端
• API
• 本地化部署
2.1、在线使用
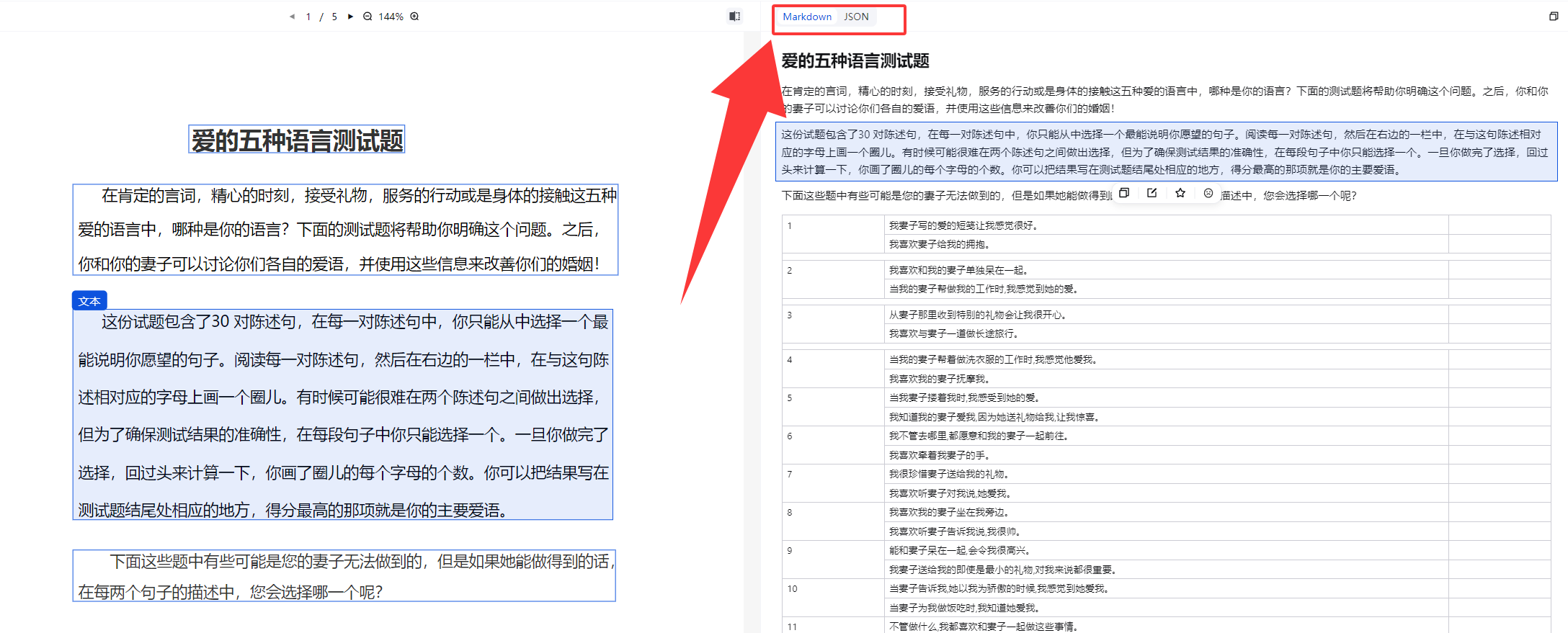
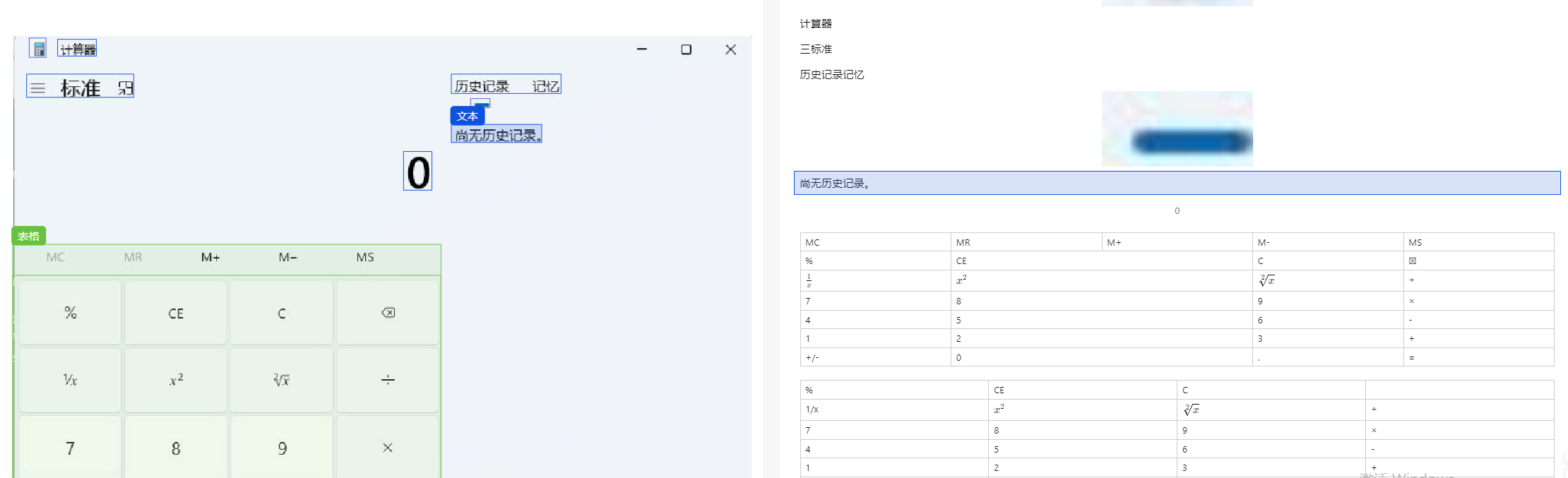
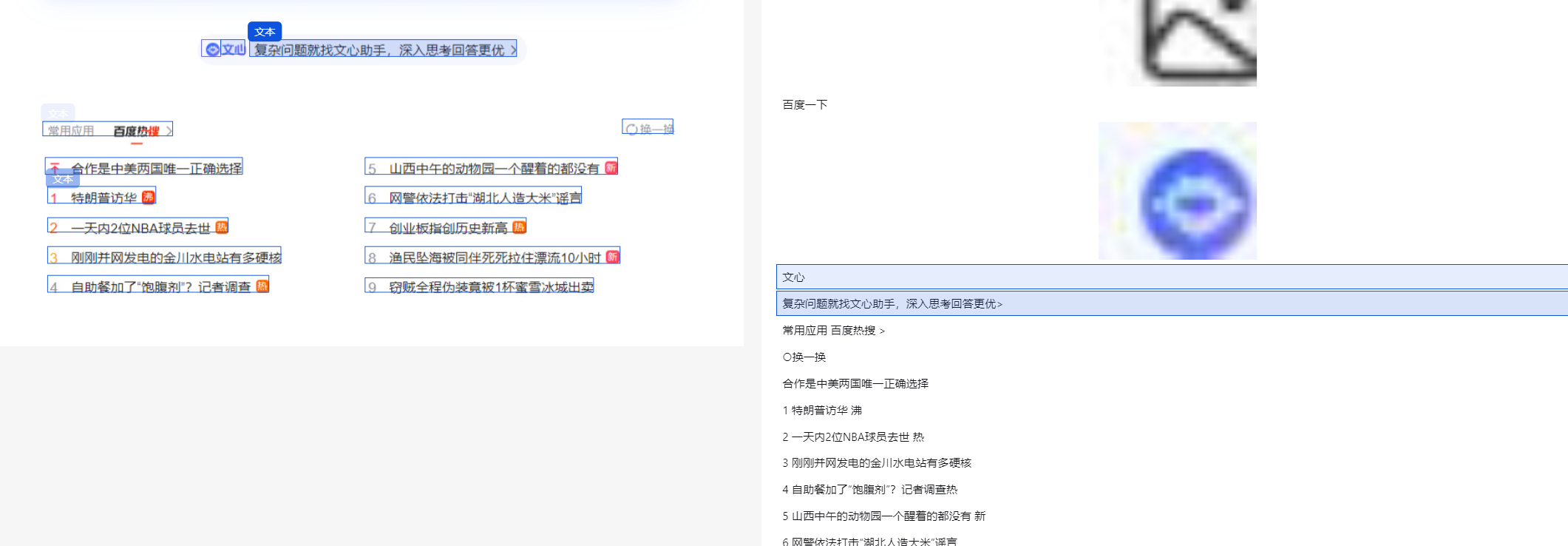
MinerU会把文档解析成markdown、json格式,如果文档中包含图片,默认用ocr解析文本
2.2、本地部署使用
mineru 1.0 minerU3.0变化很大,这里我弄了很长时间,一开始安装的1.3.x,手动下载模型,最后处理pdf时,总是报缺少模型,后来使用的3.x(当前最新)。具体区别如下(豆包查的):
|--------|---------------------------|--------------------------------|
| 对比维度 | MinerU 1.0 | MinerU 3.0 |
| 包名与命令行 | 包名:magic-pdf;命令:magic-pdf | 包名:mineru;命令:mineru,与1.0不兼容 |
| 架构模式 | 单一进程,单机小工具,无多卡/异步支持 | 三层微服务,支持分布式、多GPU负载均衡、异步任务 |
| 解析能力 | 仅支持PDF解析(文字、表格、公式) | 原生支持DOCX/PPTX/XLSX全格式,增强复杂版面解析 |
| 安装与依赖 | 依赖复杂,模型需手动下载 | 无闭源依赖,模型一键下载,pip一键安装 |
| 核心定位 | PDF解析小工具 | 企业级全格式文档解析引擎 |
1、安装minerU
pip install -U "mineruall" -i https://mirrors.aliyun.com/pypi/simple
2、下载需要的模型(pipeline可以理解为cpu可以跑的模型)
mineru-models-download -s modelscope -m pipeline
3、设置环境变量(默认走的huggingface),设置如下,会走国内镜像源
set MINERU_MODEL_SOURCE=modelscope
4、处理pdf(这个过程要几分钟时间)
mineru -p "三国演义.pdf" -o ouput -b pipeline
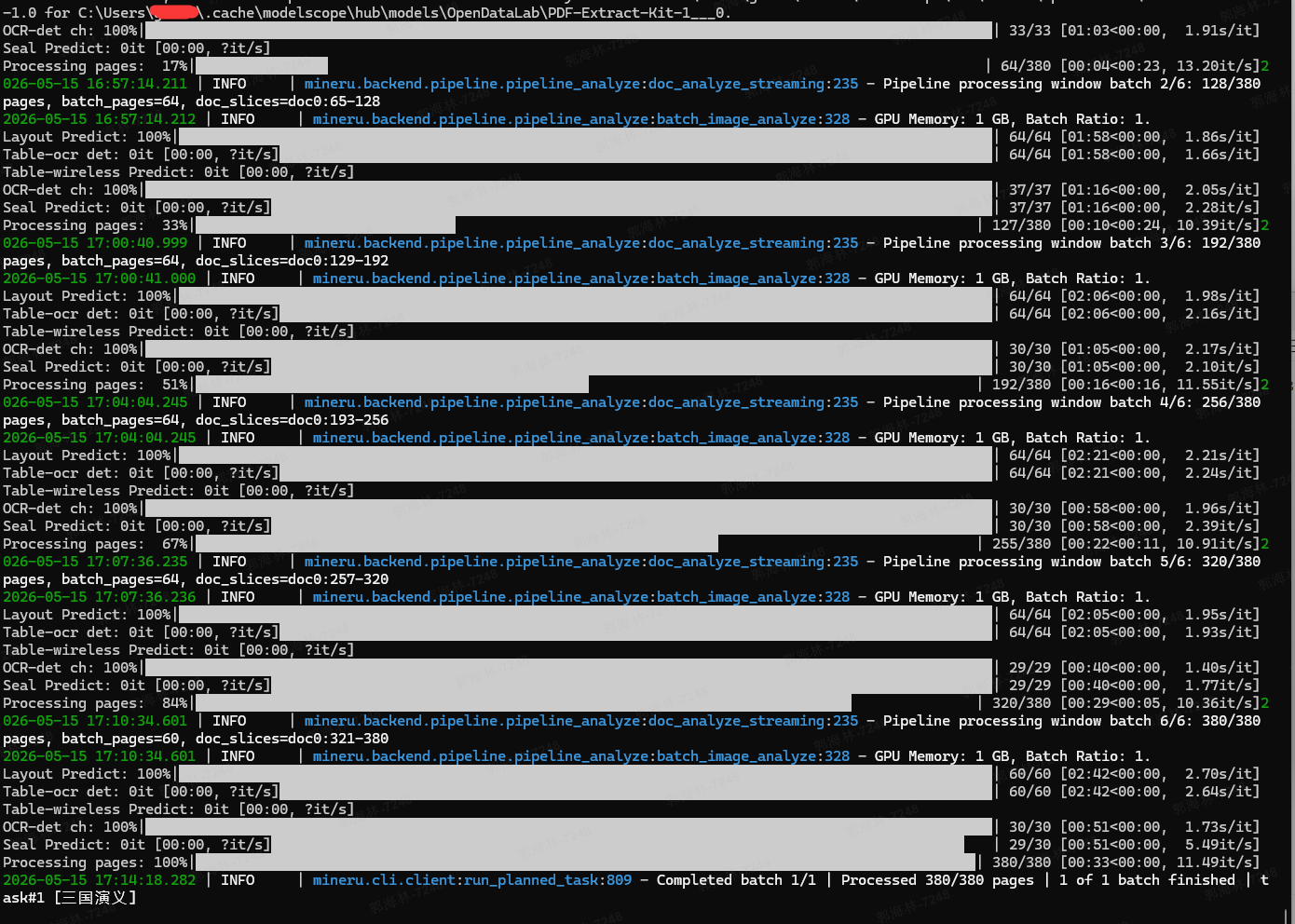
5、处理完成,minerU会生成对应的json、md文件
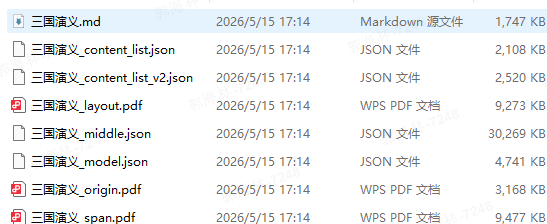
| 文件名 | 核心作用 | 适用场景 |
|---|---|---|
三国演义.md |
最终结构化输出,Markdown 格式,包含文本、标题层级、表格 / 图片引用 | 直接阅读、后续 NLP / 大模型训练的文本素材 |
三国演义_content_list.json |
按阅读顺序平铺的结构化内容列表,含类型(文本 / 表格 / 图片等)、页码、文本层级、位置信息 | 快速提取文本内容、做结构化二次开发 |
三国演义_content_list_v2.json |
content_list.json 的升级版本,补充了更完善的坐标与类型字段 |
新版 API 兼容、需要更精准位置信息的场景 |
三国演义_layout.pdf |
布局分析可视化文件,用方框标注了识别到的内容块 | 检查布局识别是否准确、调试解析效果 |
三国演义_span.pdf |
文本 Span 级别的可视化文件,标注了每个文本片段的识别结果 | 排查文本漏识别、字符级 OCR 问题 |
三国演义_middle.json |
完整中间数据文件,包含所有模型推理结果、布局、坐标、文本等全部信息 | 深度二次开发、自定义后处理流程 |
三国演义_model.json |
模型推理的原始结果,记录了每个内容块的模型识别信息 | 调试模型、分析识别错误、做质量评估 |
三国演义_origin.pdf |
原始输入文件的副本 | 对比解析前后差异、溯源原始内容 |
三国演义_span.pdf |
同上面的 Span 可视化文件(已说明) | 文本级调试 |
如果担心把本地环境弄坏了,可以用conda搭建一个隔离环境,测试验证!!!!