文章目录
-
- 前言
- 一、核心定义
- 二、标准体系结构图
- 三、场景推演
- 四、实战案例
-
- [4.1 需求分析](#4.1 需求分析)
-
- [4.1.1 数据结构设计](#4.1.1 数据结构设计)
- [4.1.2 相关算法设计](#4.1.2 相关算法设计)
- [4.2 架构图](#4.2 架构图)
-
- [4.2.1 面条代码架构图](#4.2.1 面条代码架构图)
- [4.2.2 组合模式架构图](#4.2.2 组合模式架构图)
- [4.3 时序图](#4.3 时序图)
-
- [4.3.1 面条代码时序图](#4.3.1 面条代码时序图)
- [4.3.2 组合模式时序图](#4.3.2 组合模式时序图)
- [4.4 代码分析](#4.4 代码分析)
-
- [4.4.1 面条代码(if-else / 硬编码)](#4.4.1 面条代码(if-else / 硬编码))
- [4.4.2 组合模式代码](#4.4.2 组合模式代码)
- 总结
前言
随着业务线的发展,系统中的判断逻辑变得越来越错综复杂。
今天产品要求"按性别发不同的优惠券",明天要求"加上年龄段限制",后天又追加了"新老用户身份"。
如果用传统的编程思维,这段代码很快就成为一座由无限嵌套 if-else 构成的"屎山"。
面对这种易变的规则嵌套,有没有一种优雅的设计能够打破僵局?
组合模式(Composite Pattern) 给出了完美的答案。
它通过将独立的业务逻辑抽象为原子节点,并像搭积木一样组合成一棵"决策树",最精妙的是,它让外部调用方可以无差别地处理单个节点和复杂的树形结构。
组合模式在实际业务中的经典场景:不同类型的决策节点(身份证校验、银行卡校验、手机号校验)可以自由组合成一棵服务树,不同调用方使用不同的树结构,而无需修改任何节点代码。
本文代码链接:https://github.com/likerhood/CodeDesignWork/tree/main/codedesign7.0-0 和7.0-1
一、核心定义
组合模式(Composite Pattern)是一种用来组织"树形业务结构"的设计模式。
它的核心思想是:把一个个独立的业务节点,按照树的方式组合起来,并且让外部调用方用同一种方式调用单个节点和整棵树。
放到你的业务场景里,可以这样理解:
身份证校验、银行卡校验、手机号校验,都是一个个独立的"原子节点"。它们各自只负责一件事:
- 身份证校验节点:判断身份证是否有效
- 银行卡校验节点:判断银行卡是否可用
- 手机号校验节点:判断手机号是否符合要求
但是不同调用方需要的校验流程不一样。
比如:
- 实名认证场景: 身份证校验 -> 银行卡校验 -> 手机号校验 ;
- 快捷注册场景: 手机号校验 -> 身份证校验 ;
- 绑卡场景: 身份证校验 -> 银行卡校验。
如果不用组合模式,代码里很容易写成大量 if else:
如果是实名认证,执行 A、B、C 如果是快捷注册,执行 C、A 如果是绑卡,执行 A、B
调用方越多,组合越多,代码就越乱。
组合模式要解决的就是这个问题:
节点本身保持稳定,业务变化通过"组合节点"来完成。
也就是说,身份证校验节点不用关心自己被谁调用,也不用关心自己前面或后面是谁。它只负责身份证校验。至于它和银行卡校验、手机号校验怎么组合,由外部的服务树决定。
组合模式最重要的地方不是"把对象放进集合",而是:
叶子节点和组合节点都实现同一个接口,所以调用方不需要区分当前拿到的是一个单独节点,还是一整棵服务树。
调用方只需要:执行根节点。
至于根节点下面挂了多少层、有哪些校验、按什么顺序执行,调用方都不用关心。
所以,组合模式特别适合这种场景:
业务节点相对稳定,但节点之间的组合方式经常变化。
因此常见案例中,身份证校验、银行卡校验、手机号校验这些节点本身是稳定的;真正经常变化的是不同调用方需要不同的校验链路。
组合模式就是把这些节点搭成不同的树,让业务通过"换树结构"来变化,而不是通过"改节点代码"来变化。
- 图片引用网址:组合设计模式
二、标准体系结构图
实现(叶节点)
实现(容器节点)
组合持有子节点
<<interface>>
Component
+operation() : void
Leaf
+operation() : void
Composite
-children: List<Component>
+add(c: Component) : void
+remove(c: Component) : void
+operation() : void
| 角色 | 本案例对应 | 说明 |
|---|---|---|
| Component(组件接口) | LogicFilter |
定义统一操作接口,叶节点和容器节点都实现它 |
| Leaf(叶节点) | UserAgeFilter / UserGenderFilter |
具体决策逻辑,树的末端可执行节点 |
| Composite(容器节点) | TreeNode(nodeType=1)+ EngineBase |
持有子节点引用,递归向下执行 |
| Client(客户端) | TreeEngineHandle + 测试类 |
只操作根节点,不关心树内部结构 |
三、场景推演
根据前面提到的身份校验的案例,简单展示代码。
身份证校验、银行卡校验、手机号校验,都是一个个独立的"原子节点"。它们各自只负责一件事:
- 身份证校验节点:判断身份证是否有效
- 银行卡校验节点:判断银行卡是否可用
- 手机号校验节点:判断手机号是否符合要求
不同调用方需要的校验流程:
- 实名认证场景: 身份证校验 -> 银行卡校验 -> 手机号校验 ;
- 快捷注册场景: 手机号校验 -> 身份证校验 ;
- 绑卡场景: 身份证校验 -> 银行卡校验。
接下来是代码案例:
- 定义统一的"接口"(树枝和树叶的共同标准)
不管是单独的"身份证校验",还是包含一堆校验的"整棵服务树",对外必须长得一样。
Java
// 统一的组件接口(Component)
public interface ValidationNode {
// 所有的节点都必须提供一个统一的校验方法
boolean validate(String userId);
}- 编写原子节点(叶子节点 / Leaf)
这些就是你说的"稳定的业务节点",它们只管干好自己的事,完全不知道自己会被放在哪里。
Java
// 1. 身份证校验节点
public class IdCardValidationNode implements ValidationNode {
@Override
public boolean validate(String userId) {
System.out.println("-> 正在执行:身份证有效性校验...");
// 模拟调用公安接口等逻辑
return true;
}
}
// 2. 银行卡校验节点
public class BankCardValidationNode implements ValidationNode {
@Override
public boolean validate(String userId) {
System.out.println("-> 正在执行:银行卡状态校验...");
// 模拟调用银联接口等逻辑
return true;
}
}
// 3. 手机号校验节点
public class PhoneValidationNode implements ValidationNode {
@Override
public boolean validate(String userId) {
System.out.println("-> 正在执行:手机号风控校验...");
// 模拟调用运营商接口等逻辑
return true;
}
}3. 编写组合节点(树枝节点 / Composite)
这是组合模式的灵魂! 这个类既是 ValidationNode(实现了接口),内部又包含了一个 List<ValidationNode>。它负责把叶子节点串起来。
Java
import java.util.ArrayList;
import java.util.List;
// 校验流程树(组合节点)
public class ValidationFlow implements ValidationNode {
// 内部持有一组节点,这些节点可以是叶子,也可以是另一棵子树!
private List<ValidationNode> nodes = new ArrayList<>();
// 提供添加节点的方法(搭积木)
public void addNode(ValidationNode node) {
nodes.add(node);
}
// 重写 validate 方法:它的逻辑就是按顺序执行内部所有的节点
@Override
public boolean validate(String userId) {
for (ValidationNode node : nodes) {
// 如果某个节点校验失败,直接返回 false,阻断流程
if (!node.validate(userId)) {
System.out.println("X 校验不通过,流程终止!");
return false;
}
}
return true;
}
}- 外部调用方
Java
public class Client {
public static void main(String[] args) {
String userId = "USER_10086";
System.out.println("====== 场景一:实名认证 (身份证 -> 银行卡 -> 手机号) ======");
ValidationFlow realNameFlow = new ValidationFlow();
realNameFlow.addNode(new IdCardValidationNode());
realNameFlow.addNode(new BankCardValidationNode());
realNameFlow.addNode(new PhoneValidationNode());
// 调用方根本不在乎里面有几个步骤,直接调 validate
realNameFlow.validate(userId);
System.out.println("\n====== 场景二:快捷注册 (手机号 -> 身份证) ======");
ValidationFlow quickRegFlow = new ValidationFlow();
quickRegFlow.addNode(new PhoneValidationNode());
quickRegFlow.addNode(new IdCardValidationNode());
// 同样,直接调 validate
quickRegFlow.validate(userId);
System.out.println("\n====== 场景三:极致套娃 (实名认证树 + 人脸识别) ======");
// 假设出了个新场景,要求在之前的"实名认证"基础上,再加一个人脸识别。
// 因为 ValidationFlow 本身也是一个 ValidationNode,我们可以把"树"挂在"树"上!
ValidationFlow superSafeFlow = new ValidationFlow();
// 把整棵场景一的树塞进去
superSafeFlow.addNode(realNameFlow);
// 假设我们有个新节点叫 FaceRecognitionNode
// superSafeFlow.addNode(new FaceRecognitionNode());
superSafeFlow.validate(userId);
}
}组合模式是的优势:
- 解耦 :
IdCardValidationNode里的代码永远不需要修改,即使业务上多出 100 种排列组合。 - 多态 :在
ValidationFlow的for (ValidationNode node : nodes)循环里,引擎根本不知道正在执行的是具体的手机号校验,还是另一个嵌套的子流程,它只知道"这是一个可以validate()的东西"。 - 彻底消灭
if-else:原本需要写在代码里的流程判断(if 场景==实名...),现在变成了单纯的"组装对象"。在真实的框架中,这种对象的组装通常可以通过读取数据库配置或 XML/YAML 文件来动态完成,从而实现真正的"不发版改逻辑"。
四、实战案例
4.1 需求分析
营销系统需要根据用户属性(性别、年龄)进行差异化发券:
- 男性 + 年龄 < 25 → 果实A(年轻男性优惠券)
- 男性 + 年龄 ≥ 25 → 果实B(成熟男性优惠券)
- 女性 + 年龄 < 25 → 果实C(年轻女性优惠券)
- 女性 + 年龄 ≥ 25 → 果实D(成熟女性优惠券)
业务会持续迭代:今天按性别,明天加年龄段,后天加婚育状况......每次迭代就往同一个方法里追加 if-else,最终演变成无法维护的"千行大法"。
组合模式将每个判断条件抽象为独立的决策节点 ,通过配置树结构来描述业务规则,新增判断维度只需新增节点类并挂载到树上,原有代码无需改动。
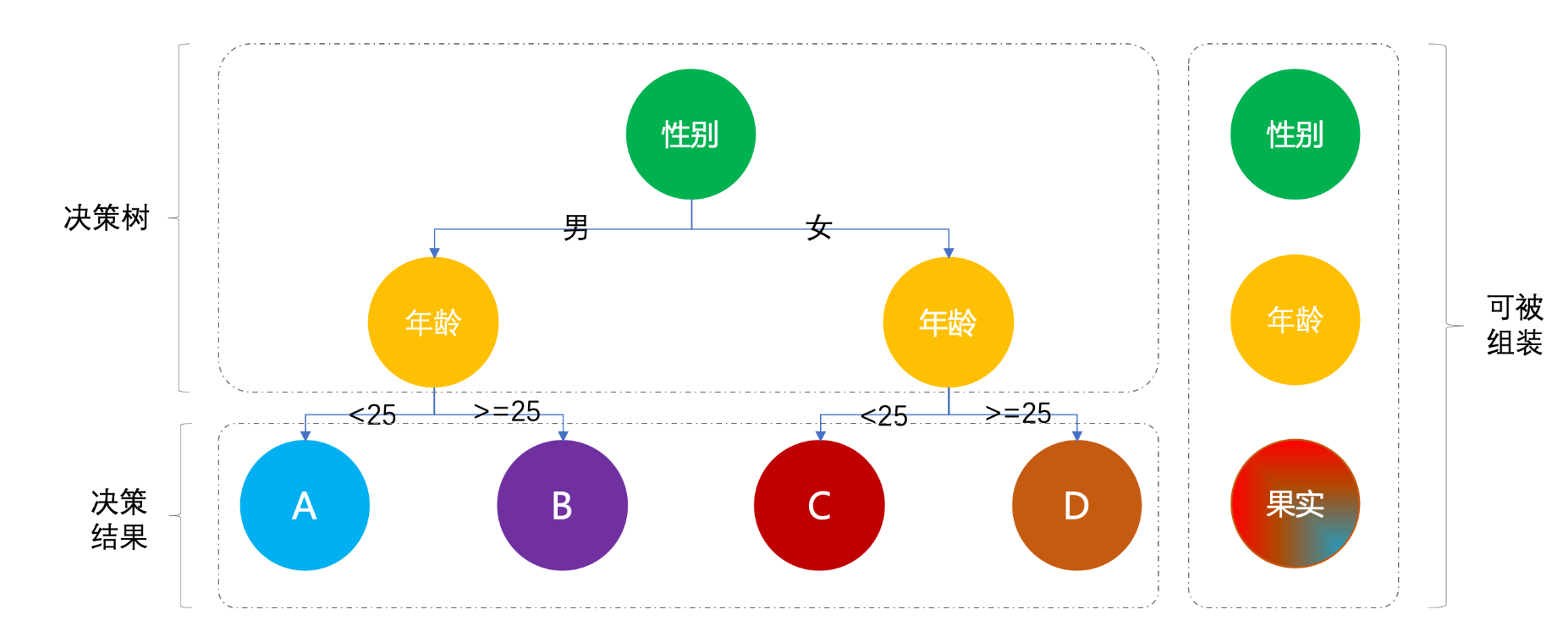
- 图片引用来自:重学 Java 设计模式:实战组合模式「营销差异化人群发券,决策树引擎搭建场景」 \| 小傅哥 bugstack 虫洞栈(https://bugstack.cn/md/develop/design-pattern/2020-06-08-重学 Java 设计模式《实战组合模式》.html)
4.1.1 数据结构设计
树的形状与整体架构(视觉直观图)
TreeRoot
treeId = 10001
treeRootNodeId = 1 ← 入口
┌─────────────────────────┐
│ 节点 1 │
│ ruleKey = "userGender" │
│ nodeType = 1 (叶子) │
└────────────┬────────────┘
│
┌──────────────────┴──────────────────┐
== "man" == "woman"
(Link: 1→11) (Link: 1→12)
│ │
┌───────────▼───────────┐ ┌───────────────▼───────────┐
│ 节点 11 │ │ 节点 12 │
│ ruleKey = "userAge" │ │ ruleKey = "userAge" │
│ nodeType = 1 (叶子) │ │ nodeType = 1 (叶子) │
└───────────┬───────────┘ └───────────────┬───────────┘
│ │
┌──────┴──────┐ ┌──────┴──────┐
< 25 >= 25 < 25 >= 25
(Link:11→111) (Link:11→112) (Link:12→121) (Link:12→122)
│ │ │ │
┌────▼────┐ ┌────▼────┐ ┌────▼────┐ ┌────▼────┐
│ 节点111 │ │ 节点112 │ │ 节点121 │ │ 节点122 │
│ 果实A │ │ 果实B │ │ 果实C │ │ 果实D │
│type=2 │ │type=2 │ │type=2 │ │type=2 │
└─────────┘ └─────────┘ └─────────┘ └─────────┘树并不是像链表一样用对象指针连起来的,而是用一个 Map 拍平存放,节点之间的父子关系靠 TreeNodeLink 的 ID 引用来表达:
treeNodeMap (HashMap)
├── key=1 → TreeNode { ruleKey="userGender", treeNodeLinkList=[Link(1→11), Link(1→12)] }
├── key=11 → TreeNode { ruleKey="userAge", treeNodeLinkList=[Link(11→111), Link(11→112)] }
├── key=12 → TreeNode { ruleKey="userAge", treeNodeLinkList=[Link(12→121), Link(12→122)] }
├── key=111 → TreeNode { nodeType=2, nodeValue="果实A", treeNodeLinkList=null }
├── key=112 → TreeNode { nodeType=2, nodeValue="果实B", treeNodeLinkList=null }
├── key=121 → TreeNode { nodeType=2, nodeValue="果实C", treeNodeLinkList=null }
└── key=122 → TreeNode { nodeType=2, nodeValue="果实D", treeNodeLinkList=null }引擎遍历时,上述两部分通过 TreeRich(整棵树) 对象组合在一起,缺一不可(没有 TreeRoot 就不知道从哪个节点起步;没有 Map 知道下一个ID也找不到对象):
TreeRich(整棵树)
│
├── TreeRoot(树的身份 + 入口)
│ treeId = 10001
│ treeRootNodeId = 1 ← 指向下面 Map 中 key=1 的节点
│ treeName = "规则决策树"
│
└── Map<Long, TreeNode>(所有节点的查找表)
│
├── key=1 → TreeNode(判断节点)
│ nodeType = 1
│ ruleKey = "userGender"
│ treeNodeLinkList:
│ ├── TreeNodeLink { 1→11, type=1, value="man" }
│ └── TreeNodeLink { 1→12, type=1, value="woman" }
│
├── key=11 → TreeNode(判断节点)
│ nodeType = 1
│ ruleKey = "userAge"
│ treeNodeLinkList:
│ ├── TreeNodeLink { 11→111, type=3, value="25" } (< 25)
│ └── TreeNodeLink { 11→112, type=5, value="25" } (>= 25)
│
├── key=12 → TreeNode(判断节点)
│ nodeType = 1
│ ruleKey = "userAge"
│ treeNodeLinkList:
│ ├── TreeNodeLink { 12→121, type=3, value="25" } (< 25)
│ └── TreeNodeLink { 12→122, type=5, value="25" } (>= 25)
│
├── key=111 → TreeNode(结果节点)
│ nodeType = 2
│ nodeValue = "果实A"
│
├── key=112 → TreeNode(结果节点)
│ nodeType = 2
│ nodeValue = "果实B"
│
├── key=121 → TreeNode(结果节点)
│ nodeType = 2
│ nodeValue = "果实C"
│
└── key=122 → TreeNode(结果节点)
nodeType = 2
nodeValue = "果实D"TreeRoot --- 树的入口
Java
public class TreeRoot {
private Long treeId; // 这棵树的ID
private Long treeRootNodeId; // 入口节点的ID
private String treeName; // 树的名字
}它解决一个核心问题:引擎从哪里开始走?
Map 里面存了所有的节点,如果没有 TreeRoot 指定 treeRootNodeId = 1,引擎就不知道哪个是根节点。同时 treeId 和 treeName 是这棵树的"身份证",用于日志记录和业务标识。
TreeNode --- 节点内部结构
Plaintext
TreeNode 的所有字段:
┌─────────────────────────────────────────────────────┐
│ treeId = 10001 ← 属于哪棵树 │
│ treeNodeId = 11 ← 自己的编号 │
│ nodeType = 1 ← 类型:1=判断节点 │
│ 2=结果节点 │
│ ruleKey = "userAge" ← 判断什么(只有type=1有)│
│ ruleDesc = "用户年龄" ← 描述(给人看的) │
│ nodeValue = null ← 结果值(只有type=2有) │
│ treeNodeLinkList = [...] ← 出口列表(只有type=1有)│
└─────────────────────────────────────────────────────┘一个叶子节点(判断节点)内部的结构实例:
Plaintext
TreeNode (节点11)
├── treeNodeId = 11
├── nodeType = 1 ← "我是中间节点,还有子节点"
├── ruleKey = "userAge" ← "引擎通过这个key找到 UserAgeFilter"
└── treeNodeLinkList
├── TreeNodeLink
│ ├── nodeIdFrom = 11
│ ├── nodeIdTo = 111
│ ├── ruleLimitType = 3 ← "<"
│ └── ruleLimitValue = "25"
└── TreeNodeLink
├── nodeIdFrom = 11
├── nodeIdTo = 112
├── ruleLimitType = 5 ← ">="
└── ruleLimitValue = "25"关键规律:nodeType 决定哪些字段有意义
nodeType = 1 (判断节点) nodeType = 2 (结果节点)
───────────────────────── ─────────────────────────
ruleKey ✓ 有值 ruleKey ✗ 无意义
nodeValue ✗ null nodeValue ✓ "果实A"
treeNodeLinkList ✓ 有子链路 treeNodeLinkList ✗ null / 空两种节点对比:
节点11(判断节点) 节点111(结果节点)
treeNodeId = 11 treeNodeId = 111
nodeType = 1 nodeType = 2
ruleKey = "userAge" ← 有 ruleKey = null ← 无
nodeValue = null ← 无 nodeValue = "果实A" ← 有
links = [两条链路] ← 有 links = [] ← 无TreeNodeLink --- 节点之间的连线
一条 TreeNodeLink 就是树上的一根箭头,它本质上是把一个 if 条件拆成了三个字段来存,回答三个问题:
TreeNodeLink {
nodeIdFrom = 11 ← 从哪出发
nodeIdTo = 111 ← 到哪去
ruleLimitType = 3 ← 什么条件下走这条路?(用数字表示运算符)
ruleLimitValue = "25" ← 条件的比较值
}ruleLimitType 对照表:
1 → == 等于 matterValue == "25"
2 → > 大于 matterValue > 25
3 → < 小于 matterValue < 25
4 → <= 小于等于 matterValue <= 25
5 → >= 大于等于 matterValue >= 25逻辑映射与举例:
if ( age < 25 )
↑ ↑ ↑
matterValue ruleLimitType ruleLimitValue节点11(判断年龄)的两条出路对应 if-else:
Link A: nodeIdFrom=11, nodeIdTo=111, ruleLimitType=3, ruleLimitValue="25"
含义:age < 25 → 走向节点111(果实A)
Link B: nodeIdFrom=11, nodeIdTo=112, ruleLimitType=5, ruleLimitValue="25"
含义:age >= 25 → 走向节点112(果实B)翻译成 Java 代码逻辑即:
Java
if (age < 25) → 节点111
if (age >= 25) → 节点1124.1.2 相关算法设计
logicFilterMap
<<interface>>
IEngine
+process(treeId, userId, treeRich, decisionMatter) : EngineResult
<<interface>>
LogicFilter
+filter(matterValue, treeNodeLinkList) : Long
+matterValue(treeId, userId, decisionMatter) : String
EngineConfig
+Map<String,LogicFilter> logicFilterMap
<<abstract>>
EngineBase
+process(treeId, userId, treeRich, decisionMatter) : EngineResult
#engineDecisionMaker(treeRich, treeId, userId, decisionMatter) : TreeNode
<<abstract>>
BaseLogic
+filter(matterValue, treeNodeLinkList) : Long
-decisionLogic(matterValue, nodeLink) : boolean
+matterValue(treeId, userId, decisionMatter) : String
TreeEngineHandler
+process(treeId, userId, treeRich, decisionMatter) : EngineResult
UserGenderFilter
+matterValue(treeId, userId, decisionMatter) : String
UserAgeFilter
+matterValue(treeId, userId, decisionMatter) : String
核心思路:把 if-else 翻译成数据
原始代码里的每一个 if-else 分支,在这里都被拆成了三个对象
原来的 if-else:
if (gender == "man") {
if (age < 25) {
return "果实A"; 这3层判断
} else { 被翻译成
return "果实B"; ↓
} 3种数据对象
}
翻译之后:
TreeNode(节点) → 代表"在这里做一个判断"
TreeNodeLink(连线) → 代表"满足什么条件,走哪条路"
TreeRoot(树根) → 代表"从哪里开始判断"为什么要翻译成数据?
if-else 的问题: 数据化之后:
───────────────────────────── ──────────────────────────────
逻辑写死在代码里 逻辑存在数据里(可以存数据库)
改规则 = 改代码 + 重新部署 改规则 = 改一条数据库记录
加新判断层 = 改代码 加新判断层 = 插入新节点数据
不同业务不同规则 = 复制代码 不同业务 = 传不同的 TreeRich数据结构的精妙之处:用 Map 拍平存储
不用对象引用连接(链表思维):
节点1 → { 子节点引用: [节点11对象, 节点12对象] }
↑ 对象直接持有对象,无法持久化到数据库
用 Map + ID 引用(数据库思维):
Map {
1 → 节点1对象 { links: [1→11, 1→12] } ← 存 ID,不存对象
11 → 节点11对象 { links: [11→111, 11→112] }
111 → 节点111对象 { nodeValue: "果实A" }
}
↑ 完美对应数据库表结构,加载进来直接能用四个类的职责一句话总结:
TreeNode → 节点本身(我是谁,我判断什么,我有哪些出口)
TreeNodeLink → 一条带条件的出口(满足什么条件,去哪个节点)
TreeRoot → 树的身份证(整棵树叫什么,从哪个节点进入)
TreeRich → 打包盒(把 TreeRoot 和所有节点装在一起传递)组合模式引擎设计与核心思路:把"变化的部分"和"不变的部分"分离
不变的部分(所有引擎都一样): 变化的部分(每种规则不同):
──────────────────────────────── ────────────────────────────────
遍历树的 while 循环算法 取哪个字段(gender? age? level?)
按 ruleKey 查找 Filter
按 nodeType 判断是否到终点 继承体系如何实现这个分离:
IEngine(接口)
│
│ "我保证对外提供 process() 能力"
│
EngineBase(抽象类)
├── extends EngineConfig → 获得 logicFilterMap 注册表
├── process() abstract → 强制子类实现结果包装
└── engineDecisionMaker() → 遍历算法,所有子类共用
│
│ extends
│
TreeEngineHandler(具体类)
└── process() → 调用遍历算法 + 包装 EngineResultLogicFilter 体系如何实现"取值"的扩展:
LogicFilter(接口)
├── filter() → "我能比较"
└── matterValue() → "我能取值"
│
BaseLogic(抽象类)
├── filter() ✅ 实现 → 比较逻辑对所有节点通用,写一次
└── matterValue() ❌ → 每种节点取不同字段,留给子类
│
┌───────┴────────┐
UserGenderFilter UserAgeFilter
matterValue()✅ matterValue()✅
取 "gender" 取 "age"组合模式的价值体现在扩展时:
现在(2个判断维度): 将来(加第3个维度,比如城市):
──────────────────────── ────────────────────────────────
UserGenderFilter UserGenderFilter ← 不动
UserAgeFilter UserAgeFilter ← 不动
UserCityFilter ← 新增1个文件
EngineConfig 加1行 ← 只改1行
所有已有代码:零修改树的遍历检索算法本质:带条件跳转的 while 循环
这里没有用递归,而是用 while 循环,原因是规则树是单向的(只会从根走向叶子,不会回头),用循环比递归更直观、更安全(不会有栈溢出风险)。
算法流程:
START
│
▼
从 treeRootNodeId 取得入口节点
│
▼
┌─────────────────────────────┐
│ nodeType == 1 ? (判断节点) │──── NO ──→ 返回当前节点(果实)→ END
└──────────┬──────────────────┘
│ YES
▼
ruleKey → logicFilterMap → 找到 Filter
│
▼
Filter.matterValue() → 取出用户属性值(如 "man")
│
▼
Filter.filter() → 遍历所有 Link,找满足条件的那条
│
▼
treeNodeMap.get(nextNodeId) → 跳到下一节点
│
└──────────────────────→ 回到循环顶部算法中最关键的一行:
Java
LogicFilter logicFilter = logicFilterMap.get(ruleKey);这一行完成了从"数据"到"行为"的桥接:
树节点上存的是字符串 "userAge"
↓
logicFilterMap.get("userAge")
↓
拿到 UserAgeFilter 对象
↓
调用它的 matterValue() 和 filter()没有任何 if-else 判断是哪种节点,Map 查找直接解决了分支问题。
filter() 内部的匹配算法:
遍历当前节点的所有出口链路:
Link1: (< 25) ──→ decisionLogic("29", Link1) → 29 < 25 → false → 跳过
Link2: (>= 25) ──→ decisionLogic("29", Link2) → 29 >= 25 → true → 立刻返回 Link2.nodeIdTo
找到第一条满足条件的就返回,后面的不再检查
(因为所有条件是互斥的,找到一条就够了)EngineConfig 配置设计核心思路:集中注册,统一查找
Java
static Map<String, LogicFilter> logicFilterMap;
static {
logicFilterMap = new ConcurrentHashMap<>();
logicFilterMap.put("userAge", new UserAgeFilter());
logicFilterMap.put("userGender", new UserGenderFilter());
}三个技术细节:
static 字段:
属于类本身,不属于任何一个对象实例
所有继承 EngineConfig 的子类共享同一份 Map
整个程序只有这一份注册表 ✓
static 代码块:
JVM 加载这个类时执行一次,且只执行一次
Filter 对象只被 new 一次,不会重复创建 ✓
ConcurrentHashMap:
线程安全,多个请求同时进来不会出问题
生产环境必须考虑并发,普通 HashMap 会出 bug ✓配置类的位置为什么在 EngineBase 和具体 Filter 之间:
Filter 层(知道怎么取值、比较)
↑ 被注册进去
EngineConfig(注册中心,Map 存放所有 Filter)
↑ 被继承
EngineBase(遍历算法,直接用 logicFilterMap)
↑ 被继承
TreeEngineHandler(具体引擎,包装结果)这个顺序保证了:引擎能直接用注册表,注册表知道所有 Filter,但引擎不需要直接依赖每一个具体 Filter 类。
三个设计的整体关系
数据结构设计 引擎设计 算法设计
────────────── ────────────── ──────────────
TreeRich 装载 IEngine 对外暴露 while 循环遍历
规则树数据 → process() 接口 → 按 ruleKey 查 Filter
按 Link 条件跳转
TreeNode 描述 EngineBase 实现
节点和出口 → 遍历算法 → matterValue 取值
filter 比较跳转
TreeNodeLink 描述 LogicFilter 体系
条件和目标 → 取值 + 比较 → 找到果实节点返回
三者缺一不可:
没有数据结构 → 无法描述规则
没有引擎设计 → 无法扩展新规则
没有遍历算法 → 无法执行判断核心组件理解确认
IEngine --- 所有规则树引擎都要实现这个接口,不管是用户信息树、学历树还是其他什么树,对外都暴露同一个 process() 方法,调用方不需要关心内部是什么树。
EngineConfig --- 基本正确,但不是严格的单例模式。它用 static 保证 logicFilterMap 只有一份,让所有继承它的子类共用同一个注册表。严格单例是控制对象实例只有一个,这里控制的是 Map 数据只有一份,思路相同但写法略有区别。
EngineBase --- 完全正确。抽象类可以继承普通类,也可以实现接口,同时把接口方法继续声明为 abstract 强制子类实现。自己写的 engineDecisionMaker 是所有子类共用的遍历算法,子类直接调用,不重复写。
新加一棵规则树的扩展方式
假设现在要加一棵学历规则树,判断逻辑是:
节点1:判断学历 (ruleKey = "userEducation")
├── == "bachelor" → 节点11
└── == "master" → 节点12
节点11:判断工作年限 (ruleKey = "userWorkYear")
├── < 3 → 果实X(初级岗)
└── >= 3 → 果实Y(中级岗)
节点12:直接是果实Z(高级岗)只需要做两件事:
新增 Filter 类
Java
// 新增:UserEducationFilter.java
public class UserEducationFilter extends BaseLogic {
@Override
public String matterValue(Long treeId, String userId, Map<String, String> decisionMatter) {
return decisionMatter.get("education"); // 只加这一个文件
}
}
// 新增:UserWorkYearFilter.java
public class UserWorkYearFilter extends BaseLogic {
@Override
public String matterValue(Long treeId, String userId, Map<String, String> decisionMatter) {
return decisionMatter.get("workYear");
}
}在 EngineConfig 注册
Java
static {
logicFilterMap = new ConcurrentHashMap<>();
logicFilterMap.put("userAge", new UserAgeFilter());
logicFilterMap.put("userGender", new UserGenderFilter());
logicFilterMap.put("userEducation", new UserEducationFilter()); // ← 加这一行
logicFilterMap.put("userWorkYear", new UserWorkYearFilter()); // ← 加这一行
}其他所有代码零修改 。引擎遍历时遇到 ruleKey="userEducation" 自动就能找到对应的 Filter。
在原有规则树上新增判断维度的扩展方式
原始 if-else 设计
────────────────────────────────────────────────────
加新判断维度: 进 EngineController 改代码 ✗
加新规则树: 复制粘贴一个新的 Controller ✗
多人协作: 改同一个文件,代码冲突 ✗
单元测试: 整个方法耦合在一起,难以测试 ✗
现在的设计
────────────────────────────────────────────────────
加新判断维度: 新增一个 Filter 文件 + 注册一行 ✓
加新规则树: 新增一个 EngineHandler 文件 ✓
多人协作: 每人负责自己的 Filter 文件,互不干扰 ✓
单元测试: 每个 Filter 独立测试,引擎独立测试 ✓核心原则是"开闭原则":
对扩展开放 → 可以随时加新的 Filter、新的 Engine
对修改关闭 → 加新东西不需要改已有代码4.2 架构图
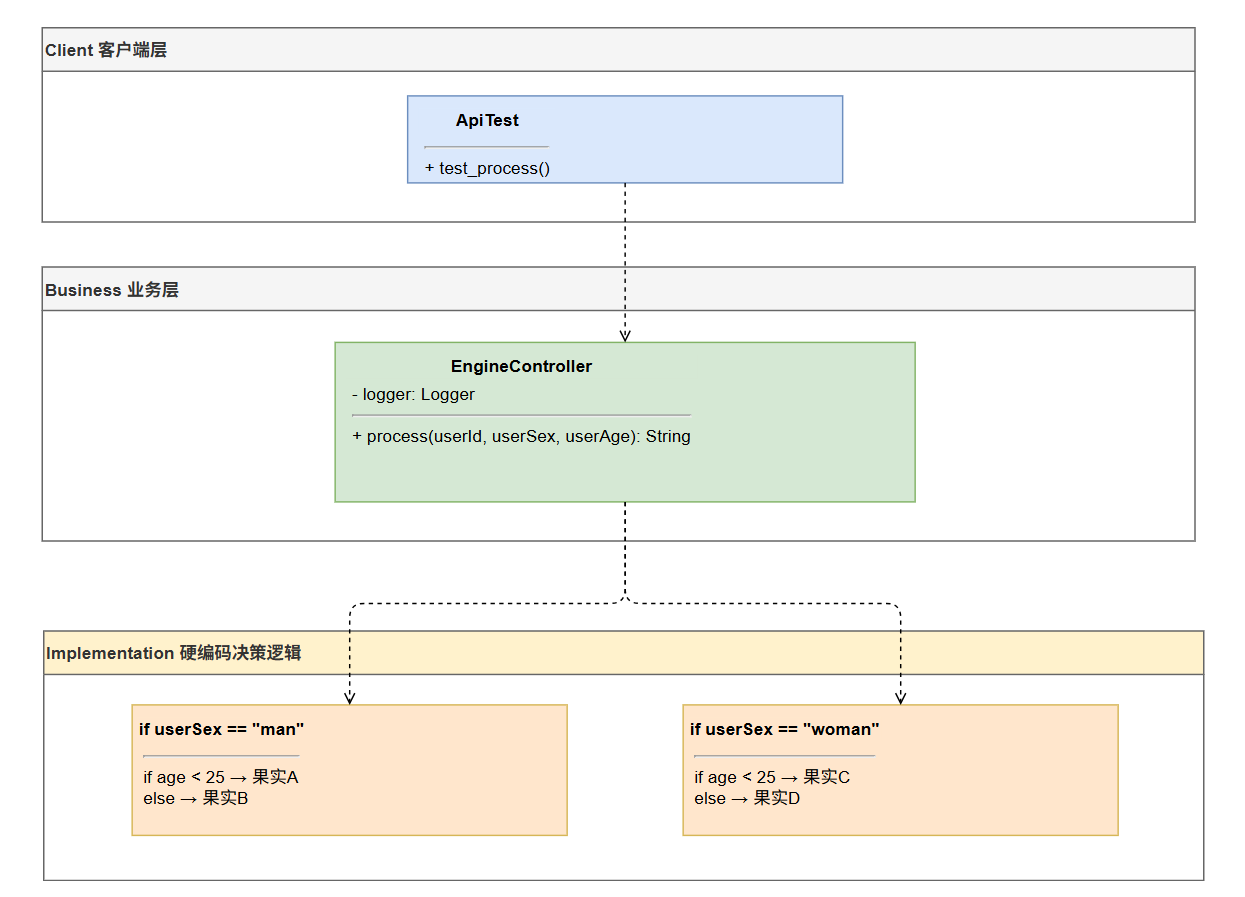
4.2.1 面条代码架构图
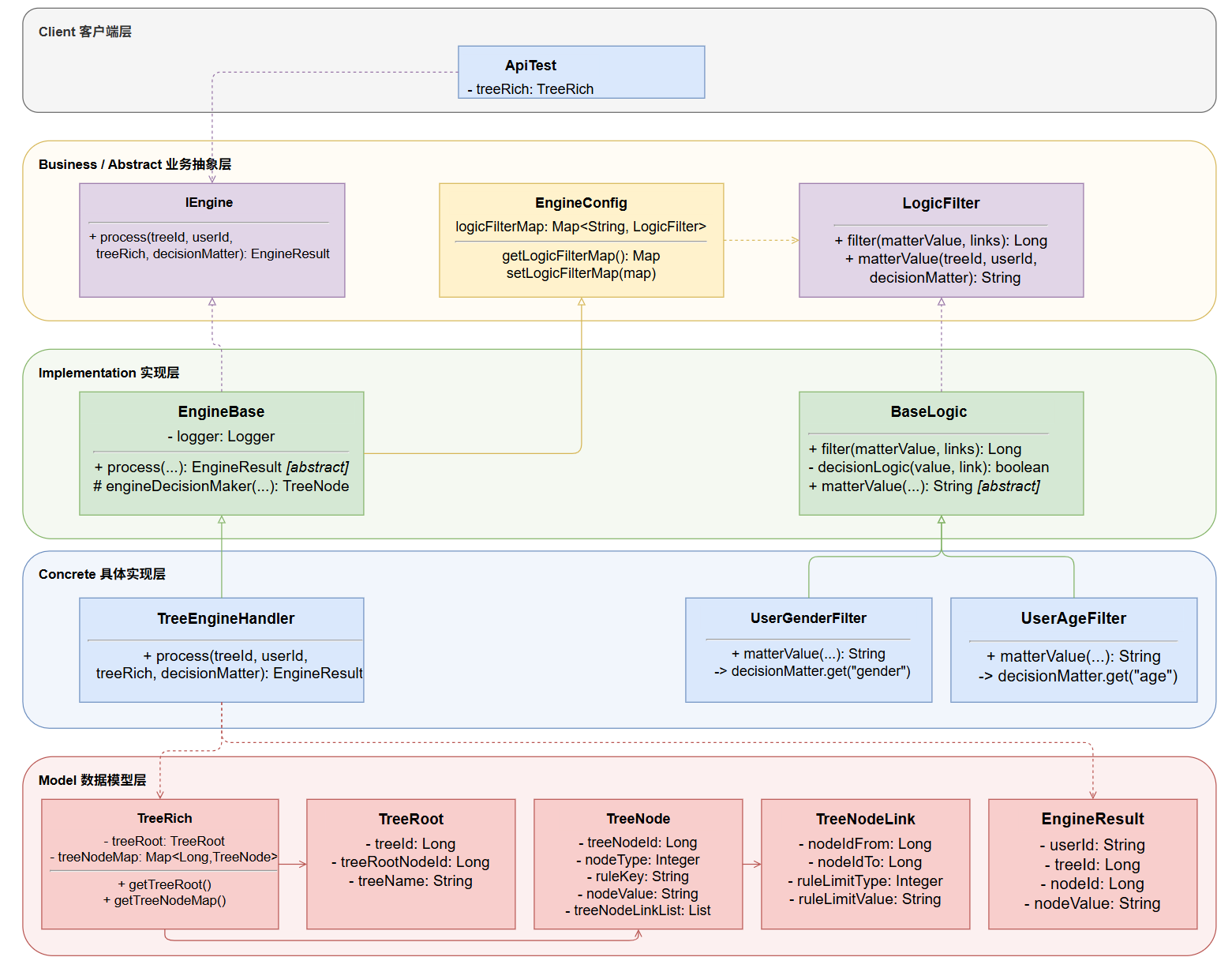
4.2.2 组合模式架构图
4.3 时序图
4.3.1 面条代码时序图
EngineController 客户端 EngineController 客户端 if ("man".equals(userSex)) if (userAge >= 25) → return "果实B" 规则逻辑全部内联,调用方需传入具体字段值 修改规则 = 修改 process 方法本身 process("Oli09pLkdjh", "man", 29) "果实B"
4.3.2 组合模式时序图
TreeRich/TreeNode UserAgeFilter UserGenderFilter EngineBase TreeEngineHandle 客户端 TreeRich/TreeNode UserAgeFilter UserGenderFilter EngineBase TreeEngineHandle 客户端 从根节点1开始,nodeType=1(子叶),进入循环 "man".equals("man") → true,返回 nodeIdTo=11 nodeType=1,继续循环 29 >= 25 → case5 成立,返回 nodeIdTo=112 process(10001L, "Oli09pLkdjh", treeRich, {gender:man, age:29}) engineDecisionMaker(treeRich, treeId, userId, decisionMatter) 取节点1,ruleKey="userGender" matterValue(10001, "Oli09pLkdjh", {gender:man, age:29}) "man" filter("man", links→11(man), →12(woman)) 11L 取节点11,ruleKey="userAge" matterValue(10001, "Oli09pLkdjh", {gender:man, age:29}) "29" filter("29", links→111(\<25), →112(\>=25)) 112L 取节点112,nodeType=2(果实),退出循环 TreeNode(nodeId=112, nodeValue="果实B") EngineResult(userId, treeId=10001, nodeId=112, nodeValue="果实B")
4.4 代码分析
4.4.1 面条代码(if-else / 硬编码)
java
// tutorials-11.0-1 EngineController.java
public String process(final String userId, final String userSex, final int userAge) {
logger.info("ifelse实现方式判断用户结果。userId:{} userSex:{} userAge:{}", userId, userSex, userAge);
if ("man".equals(userSex)) {
if (userAge < 25) {
return "果实A"; // 硬编码:性别man AND 年龄<25
}
if (userAge >= 25) {
return "果实B"; // 硬编码:性别man AND 年龄>=25
}
}
if ("woman".equals(userSex)) {
if (userAge < 25) {
return "果实C"; // 硬编码:性别woman AND 年龄<25
}
if (userAge >= 25) {
return "果实D"; // 硬编码:性别woman AND 年龄>=25
}
}
return null;
}问题清单(真实业务演进过程):
| 迭代 | 产品需求 | 代码影响 |
|---|---|---|
| 第1次 | 按性别发不同优惠券 | 加2个 if 分支 |
| 第2次 | 再按年龄细分 | 嵌套 if,分支数×2 |
| 第3次 | 加婚育状况 | 继续嵌套,分支数再×3 |
| 第4次 | 调整年龄阈值 | 全文搜索魔法数字,极易改错 |
| 第5次 | 值粘错位置 | 线上 bug,客诉 |
4.4.2 组合模式代码
(1)数据模型层:树的数据结构
java
// TreeNode.java - 节点有两种类型
// nodeType=1: 子叶节点(带判断逻辑,有子链路)
// nodeType=2: 果实节点(无子链路,有果实值)
TreeNode {
Long treeNodeId;
Integer nodeType; // 1=子叶, 2=果实
String nodeValue; // 仅果实节点有值
String ruleKey; // 对应 EngineConfig 中的 key(如 "userGender")
List<TreeNodeLink> treeNodeLinkList; // 出边列表
}
// TreeNodeLink.java - 连接两个节点的有向边
TreeNodeLink {
Long nodeIdFrom; // 起始节点
Long nodeIdTo; // 目标节点
Integer ruleLimitType; // 比较类型:1=等于, 2=>,3=<, 4=<=, 5=>=
String ruleLimitValue; // 比较阈值
}(2)决策节点接口 LogicFilter(组合模式的 Component)
java
public interface LogicFilter {
// 过滤器:传入"当前节点的决策值" + "所有出边",返回"命中的下一节点ID"
Long filter(String matterValue, List<TreeNodeLink> treeNodeLineInfoList);
// 取值器:从决策物料中提取当前节点需要的值(如 age、gender)
String matterValue(Long treeId, String userId, Map<String, String> decisionMatter);
}(3)抽象类 BaseLogic:实现通用比较逻辑(模板方法)
java
public abstract class BaseLogic implements LogicFilter {
@Override
public Long filter(String matterValue, List<TreeNodeLink> treeNodeLinkList) {
// 遍历所有出边,找到第一个满足条件的,返回其目标节点ID
for (TreeNodeLink nodeLine : treeNodeLinkList) {
if (decisionLogic(matterValue, nodeLine)) return nodeLine.getNodeIdTo();
}
return 0L; // 未命中
}
// 子类只需实现"如何取值",无需关心比较逻辑
@Override
public abstract String matterValue(Long treeId, String userId, Map<String, String> decisionMatter);
// 通用比较逻辑(equals / > / < / <= / >=)
private boolean decisionLogic(String matterValue, TreeNodeLink nodeLink) {
switch (nodeLink.getRuleLimitType()) {
case 1: return matterValue.equals(nodeLink.getRuleLimitValue()); // 等于
case 2: return Double.parseDouble(matterValue) > Double.parseDouble(nodeLink.getRuleLimitValue()); // >
case 3: return Double.parseDouble(matterValue) < Double.parseDouble(nodeLink.getRuleLimitValue()); // <
case 4: return Double.parseDouble(matterValue) <= Double.parseDouble(nodeLink.getRuleLimitValue()); // <=
case 5: return Double.parseDouble(matterValue) >= Double.parseDouble(nodeLink.getRuleLimitValue()); // >=
default: return false;
}
}
}(4)具体节点实现(Leaf,只覆盖取值逻辑)
java
// 年龄节点:从物料Map中取 "age"
public class UserAgeFilter extends BaseLogic {
@Override
public String matterValue(Long treeId, String userId, Map<String, String> decisionMatter) {
return decisionMatter.get("age");
}
}
// 性别节点:从物料Map中取 "gender"
public class UserGenderFilter extends BaseLogic {
@Override
public String matterValue(Long treeId, String userId, Map<String, String> decisionMatter) {
return decisionMatter.get("gender");
}
}新增一种判断维度(如"婚育状态")只需新建一个
UserMaritalFilter extends BaseLogic,在 EngineConfig 中注册,然后在树结构数据中挂载新节点。原有任何代码无需修改。
(5)节点注册配置 EngineConfig
java
public class EngineConfig {
static Map<String, LogicFilter> logicFilterMap;
static {
logicFilterMap = new ConcurrentHashMap<>();
logicFilterMap.put("userAge", new UserAgeFilter()); // ruleKey → 节点实例
logicFilterMap.put("userGender", new UserGenderFilter()); // 可从数据库/配置中心加载
}
}(6)引擎核心:树遍历算法 EngineBase.engineDecisionMaker()
java
protected TreeNode engineDecisionMaker(TreeRich treeRich, Long treeId, String userId,
Map<String, String> decisionMatter) {
TreeRoot treeRoot = treeRich.getTreeRoot();
Map<Long, TreeNode> treeNodeMap = treeRich.getTreeNodeMap();
Long rootNodeId = treeRoot.getTreeRootNodeId();
TreeNode treeNodeInfo = treeNodeMap.get(rootNodeId); // 从根节点开始
// 只要当前节点是"子叶节点"(有判断逻辑),就继续向下走
while (treeNodeInfo.getNodeType().equals(1)) {
String ruleKey = treeNodeInfo.getRuleKey(); // 取节点的过滤器key
LogicFilter logicFilter = logicFilterMap.get(ruleKey); // 找到对应过滤器
String matterValue = logicFilter.matterValue(treeId, userId, decisionMatter); // 取值
Long nextNode = logicFilter.filter(matterValue, treeNodeInfo.getTreeNodeLinkList()); // 过滤,找下一节点
treeNodeInfo = treeNodeMap.get(nextNode); // 移动到下一节点
}
return treeNodeInfo; // 返回果实节点(nodeType=2)
}(7)引擎实现与调用
java
// TreeEngineHandle:最终实现,只是薄薄的一层
public class TreeEngineHandle extends EngineBase {
@Override
public EngineResult process(Long treeId, String userId, TreeRich treeRich, Map<String, String> decisionMatter) {
TreeNode treeNode = engineDecisionMaker(treeRich, treeId, userId, decisionMatter);
return new EngineResult(userId, treeId, treeNode.getTreeNodeId(), treeNode.getNodeValue());
}
}
// 调用方
IEngine treeEngineHandle = new TreeEngineHandle();
Map<String, String> decisionMatter = new HashMap<>();
decisionMatter.put("gender", "man");
decisionMatter.put("age", "29");
EngineResult result = treeEngineHandle.process(10001L, "Oli09pLkdjh", treeRich, decisionMatter);
// result.getNodeValue() = "果实B"
// result.getNodeId() = 112总结
回顾整个重构路径:原始代码用 if-else 把所有判断逻辑硬编码在一个方法里,每次业务迭代都必须进入同一个方法修改,随着条件组合数指数级增长,代码迅速腐化。重构后的方案将每一个判断条件抽象为独立的 LogicFilter节点,将判断规则的结构数据化为 TreeNode + TreeNodeLink,通过 EngineBase 的 while 循环统一遍历,彻底消灭了业务逻辑里的 if-else。
组合模式在这里真正发挥价值的地方,不是经典教材里那句"把对象放进集合",而是:
- 同一个
TreeNode类既是判断节点(Composite)又是结果节点(Leaf),引擎统一处理,无需区分类型,树结构可以任意层数扩展而引擎代码不动; - 节点(Filter)只负责自己的取值逻辑,和其他节点完全解耦,新增维度只加文件不改存量;
- 业务规则的变化通过"换树结构"来承接,而不是"改节点代码",真正实现了对扩展开放、对修改关闭。
组合模式最适合的场景可以用一句话来判断:业务节点相对稳定,但节点之间的组合方式经常变化。 只要你的业务满足这个特征,组合模式就值得引入。