零、前言
进入 2026 年,大街小巷都在聊着与 AI 有关的话题,AI 在不断地颠覆着我们的日常生活和各行各业的工作习惯。相信很多同学都已经开始用着 AI 相关的产品,例如豆包、元宝、ChatGPT、Gemini、Claude Code 等,会在这些 AI 产品的聊天框内输入一段文字然后发送,等待一定的时间后,会看到 AI 给出对应的回复内容。
或许你有着和我一样的疑惑:
- 从按下回车,聊天内容被发出去之后,到底发生些什么呢?
- AI 是怎么记住我们的聊天内容呢?有时为什么又好像忘了?
基于这些问题,便分享了这篇文章,最后会结合代码,亲自感受一次聊天背后的流程。
一、发出的内容不只是聊天内容
当我们在聊天框里输入 "帮我写一个排序算法",然后敲击回车键,这句话就被打包发送给大模型了,但打包出去的并不只是输入的这句话。
客户端(包括网页、App、CLI、IDE 插件)会在背后悄悄地做一件事:把刚才这句话、之前的聊天记录、还有一段 "系统指令",全部拼成一个完整的内容块,一起发给大模型。这个被打包好、最终送进大模型的完整内容,就叫 提示词(Prompt)。
所以我们输入的那句话只是 Prompt 的一小部分,Prompt 才是大模型真正 "看到" 的全部内容。
Prompt 长什么样?
实际打包出去的内容长这样:
json
{
"messages": [
{
"role": "system",
"content": "你是 ChatGPT,一个由 OpenAI 开发的 AI 助手,必须提供准确的回答。"
},
{
"role": "user",
"content": "你好,请问 Python 怎么排序?"
},
{
"role": "assistant",
"content": "你可以使用 sorted() 函数或者 list.sort() 方法..."
},
{
"role": "user",
"content": "帮我写一个排序算法"
}
]
}这里使用的是 ChatGPT 格式,其他模型的 Prompt 格式和 ChatGPT 会有一些差异,但整体上一致。因为这套格式一开始就是 ChatGPT 提出的,随着 ChatGPT 的流行也就成为了行业的标准。
ChatGPT Prompt 格式的官方文档:platform.openai.com/docs/api-re...
完整的 Prompt 包含三部分:
- 系统提示词(System Prompt):限制 AI 的行为,告诉它当前扮演的角色,在接下来的对话中应该如何表现;
- 对话历史:之前所有的问答记录;
- 当前消息:刚输入的那句话,例如这里的 "帮我写一个排序算法";
这三部分拼在一起就是大模型真正 "看到" 的全部内容。
三种角色:System、User、Assistant
随着模型的发展,角色会不断扩充或删除,这篇文章并不是 ChatGPT 的 API 使用讲解,所以就提取这三个比较有代表性的角色进行分享。
在 ChatGPT o1 后续模型中,官方规定使用 Developer 代替 System 角色,但在旧的模型就还是继续使用 System 角色。
系统(System)
System 消息是给 AI 设定的 "工作指南"。它不是对话的一部分,而是 AI 开发者设置的一个全局性的指令。比如:
- "你是一个资深的 Python 开发工程师,用简洁的中文回答"
- "你的回答不能超过 100 字"
- "当用户问到政治话题时,礼貌地拒绝回答"
在 ChatGPT 里并不会直接看到 System Prompt,但它一直会存在,ChatGPT 会自动加上一段默认的 System Prompt。Claude、Cursor 也同样会有自家的 System Prompt,在发送给模型时一同携带。
System Prompt 就像 AI 入职第一天收到的《员工手册》,它不会出现在 AI 跟我们的日常对话里,但始终影响着 AI 的回答方式。
用户(User)
User 消息就是我们在聊天框发送的内容。
助手(Assistant)
Assistant 消息是 AI 的回复。之所以出现在 Prompt 里,是因为每次对话都需要带上历史记录,否则模型会不知道之前我们聊了什么(很意外吧,文章后面会展开分享)。
System Prompt 的威力
System Prompt 的设计是一门学问。同一个问题,不同的 System Prompt 会让 AI 给出完全不同的回答。
比如你问:"JavaScript 好还是 Python 好?"
| System Prompt | AI 可能的回答风格 |
|---|---|
| "你是一个客观的技术顾问" | 列出两种语言各自的优劣,让用户自己决定 |
| "你是一个狂热的 Python 爱好者" | 疯狂吹捧 Python |
| "你是一个五岁小孩" | "Python 像小蛇,好可爱!" |
这也是为什么不同的 AI 产品,即使用的是同一个底层模型,给出的答案却完全不同,这很大程度上是因为 System Prompt 不同。
谁在组装 Prompt
组装 Prompt 的并不是大模型,而是客户端应用,例如:
- 在 ChatGPT 里,是 OpenAI 的网页或 App 把 System Prompt、历史、我们的消息拼在一起;
- 在 Cursor 里,是 Cursor 的 IDE 把代码文件内容、我们的指令、System Prompt 组装好;
- 当我们用 API 调用大模型时,那便是我们负责使用代码进行组装;
因为大模型本身并不知道什么是 "一次对话"。它每次收到的都是打包好的内容,然后理解和回答,至于这块内容是怎么拼出来的,它并不关心。所有的 "对话体验" 都是客户端在大模型之上构建的。
Prompt 的成本
System Prompt 是有长度的,而且它的长度也需要花钱。
像 ChatGPT、Claude、Cursor 这类产品,每一次对话都会携带一段 System Prompt。这段内容对于使用者是看不到的,但它却悄悄地消耗着容量和费用。
而且 System Prompt 在每一轮对话中都会被发送一遍。如果聊了 20 轮,System Prompt 则被发送了 20 次。这也是为什么 AI 产品会尽量精简 System Prompt,因为每多一个字,每次对话都会多一些开销。
二、大模型的文字------Token
大模型不识字,只识数
在上一小节完成了 Prompt 的组装,但是大模型根本不认识文字,它只认识数字。
这就像一个老外看到 "你好" 这两个字,对他来说只是两个奇怪的图案,就跟我们看到阿拉伯文是一样的。但如果把 "你好" 转为 "Hello",老外就知道什么意思了。所以对于大模型,如果把 "你好" 转为它能识别的编号 "12345",大模型也就知道什么意思了,才能进行后续的处理。
所以这里需要一位 "翻译官",把文字转为大模型能认识的编码。这个过程分为两个步骤:
- 切分(Tokenize) :先把文字切成一个个小块,每一小块就叫 Token;
- 映射(Encode):再把每个 Token 查表换成大模型能读懂的 Token ID;
反过来也一样,大模型输出 Token ID 后,翻译官再查表把它们还原回文字,这个翻译官就是 分词器(Tokenizer)。
什么是 Token?
Token 是大模型处理文本的最小单位。 它就是大模型世界里的 "文字",但不一定对应我们认知中的一个字,就像中文和英文也不是一一对应的。
一个 Token 可能是:
- 一个常见的英文单词,比如
hello - 一个英文单词的一部分,比如
programming可能被拆成program+ming - 一个中文汉字,比如
你 - 两个常见汉字的组合,比如
你好 - 一个标点符号,比如
。 - 一个空格
而把文字拆成 Token 的工具叫做 分词器(Tokenizer)。每个大模型都有自己的 Tokenizer,拆分规则不一样,所以 Tokenizer 和模型强绑定,同一家公司的不同模型的 Tokenizer 也可能不相同。
为什么不直接按字处理?
你可能有着和我一样的疑惑:为什么不直接一个个字符地处理?需要多一个步骤,将文本转为 Token 再进行处理?
其实 Token 是在 "太细粒度" 和 "太粗粒度" 之间找一个平衡点。
- 太细粒度(每个字符一个单位):序列太长,模型处理效率低,而且单个字符本身没什么语义,例如把 "cat" 的每个字母 "c" 、 "a" 、 "t" 单独拿出来没意义。
- 太粗粒度(每个完整词一个单位):词表会很庞大,英文单词有几十万个,加上各种变形、组合词、人名、新造词,词表根本装不下。更致命的是,一旦遇到词表里没有的词,模型就完全不认识了。
因此 Token 的做法便有了以下三个好处:
1. 效率更高
常见的字符组合被合并成一个 Token,例如:the、ing、编程,序列长度大幅缩短。就像我们背单词时把 cat 当作一个整体进行记忆,比 c-a-t 三个字母分别记忆要更方便更快。
2. 能处理 "没见过的词"
如果词表只存完整单词,遇到训练时没见过的词就不知道如何处理了,这就是 OOV(Out-Of-Vocabulary,词表外)问题,例如遇到新造词、拼写错误、生僻专有名词,而子词级的 Token 可以把陌生词拆成熟悉的小块。
比如 tokenization 即使没进词表,也能被拆成 token + ization,模型依然能处理,这样词表就能覆盖几乎任何输入。
3. 保留有意义的结构
像 un-、-ing、pre- 这些词缀本身就有语义。把它们作为独立的 Token,模型学到 "un + 形容词 = 否定" 之后,哪怕看到一个从没见过的新造词,也能猜出大概意思。
其实这和我们学习英语时的思路是大致相同的,也会对长句进行拆分、对单词进行拆分、词根分析,最终的目的都是让我们更好地记住、理解这一句子的意思。
词表是怎么来的?
到此你可能会冒出另一个疑问,那本查询 Token 映射的 "Token 词表" 是怎么来的呢?
这本词表不是拍脑袋写出来的,而是事先用大量文本训练出来的 :算法会扫描海量语料,统计哪些字符组合经常一起出现,例如 the、ing、编程 这些经常组在一起,则把它们固化成一个 Token。最终得到的这本 "Token ↔ Token ID" 映射表,就叫做词表(Vocabulary)。
所以 "Token 词表" 的大小是模型设计时就定好的,GPT-4 的词表大约有 10 万个 Token。
Tokenizer 是怎么工作的?
至此,我们知道了 "Token"、"Token 词表" 的由来,再回头看 Tokenizer 这个 "翻译官" 是怎么干活的。它工作分两步:先切分、再查询。
以下示例使用 GPT-4 / GPT-3.5 的分词器演示,不同模型的切分结果和 Token ID 会有差异。
假设输入是 "Hello, 你好":
arduino
第 1 步:切分(按词表里的 Token 规则把文本切成小块)
"Hello, 你好" → ["Hello", ",", " ", "你", "好"]
第 2 步:映射(查词表,把每个 Token 换成对应的数字 ID)
"Hello" → 9906
"," → 11
" " → 220
"你" → 57668
"好" → 53901
输出:[9906, 11, 220, 57668, 53901]模型最终拿到的就是 [9906, 11, 220, 57668, 53901] 这一串数字序列。模型使用这串数字序列进行分析处理,然后生成回复,它的回复也会是一串数字。
例如此次模型回复了 [57668, 53901, 6447] Tokenizer 翻译官需要把它们翻译成我们可以看懂的文字,这个过程刚好就是上面的反向操作。
css
第 1 步:映射(查词表,把数字 ID 换回 Token)
[57668, 53901, 6447] → ["你", "好", "!"]
第 2 步:拼接(把 Token 片段拼成完整文本)
["你", "好", "!"] → "你好!"每个大模型都有自己的 Tokenizer 和词表,拆分规则也不一样。这也是为什么同一句话用不同模型算出来的 Token 数会有差异。
OpenAI 提供了一个在线的 Tokenizer 工具 platform.openai.com/tokenizer,可以自行输入内容,更加直观地体验一下效果。
一些有趣的 Token 现象
理解了 Token 的原理后,一些看似奇怪的 AI 行为就说得通了:
-
AI 数不清字数:让 AI "写一个恰好 100 字的段落",它几乎不能精确地做到。因为它操作的是 Token,不是文字,它不知道自己已经输出了多少个 "字",它只知道自己输出了多少个 Token。就跟我们被要求写一篇一百个单词的作文,但我们一提笔用汉字写了一篇认为符合要求的作文,但从中文翻译为英文总会有些出入。
-
AI 算不了复杂的数学题 :
1234 × 5678对人类来说是一道算术题,但对大模型来说,这串数字会被拆成好几个 Token,它并没有 "计算" 的能力,只是在做 "看到这些 Token 后,下一个 Token 最可能是什么" 的预测。 -
AI 偶尔会拼错不常见的词:如果一个罕见的词在训练数据中出现得很少,它在词表中可能被拆成好几个小 Token,模型重新 "拼" 回来的时候就可能出错。
-
代码中的变量名影响 AI 的理解 :
handleClick会被拆成 2 个 Token(handle+Click),而缩写写法hndlClk会被拆成 4 个 Token(h+ndl+Cl+k),更碎片化的 Token 意味着模型更难理解它的含义,所以好的变量命名不仅能帮人,也帮 AI。
中英文 Token 的差异
同样的意思,中文和英文消耗的 Token 数量不一样,例如 "我是中国人" 和 "I am Chinese" 比较:
| 文本 | Token 数 | 拆分结果 |
|---|---|---|
| 我是中国人 | 4 | 我 / 是 / 中国 / 人 |
| I am Chinese | 3 | I / am / Chinese |
同样的意思,中文要比英文多消耗 Token。这意味着:
- API 费用更高:大模型的 API 按 Token 数量计费;
- 上下文空间更快被填满:更容易达到大模型 "记忆上限",文章后续章节会进行分享;
- 处理速度稍慢:更多的 Token 意味着更多的计算量;
Token 与费用
Token 是大模型的计费单位,以 2026 年主流模型的价格为例:
| 模型 | 输入价格(每百万 Token) | 输出价格(每百万 Token) |
|---|---|---|
| GPT-4o | $2.50 | $10.00 |
| Claude Sonnet 4.6 | $3.00 | $15.00 |
| Gemini 2.5 Flash | $0.30 | $2.50 |
值得注意:
- 输入和输出分开计费,而且输出通常比输入贵 3~5 倍,因为输出的生成文本比输入的理解文本需要更多的计算;
- 不同模型差价大,选对模型,成本可以节省几十倍。模型的能力差距大,需要选择合适自己执行场景的模型;
当你在 Cursor 里用 AI 辅助编程时,它每次把你的代码文件内容发给大模型,那些代码都是 Token,一个 500 行的文件可能就有几千个 Token,这也是为什么 Cursor 会有使用次数限制。
三、AI 的 "短期记忆" ------Context Window
跟 AI 聊了很长一段对话后,突然提及到前面说过的某件事,AI 像是 "失忆" 了,完全不记得你之前说了什么,这其实不是 Bug,而是 上下文窗口(Context Window) 限制导致的。
Context Window 是什么?
Context Window 是大模型一次能 "看到" 的信息总量上限,用 Token 数量来衡量。
可以把 Context Window 想象成一张桌子,大模型处理信息的时候,需要把所有相关内容都摊在这张桌子上,System Prompt 会占一些空间,对话历史会占一些空间,你的新消息会占一些空间,模型的回复也会占空间。如果桌子放不下了,最早放上去的东西就会被移走。
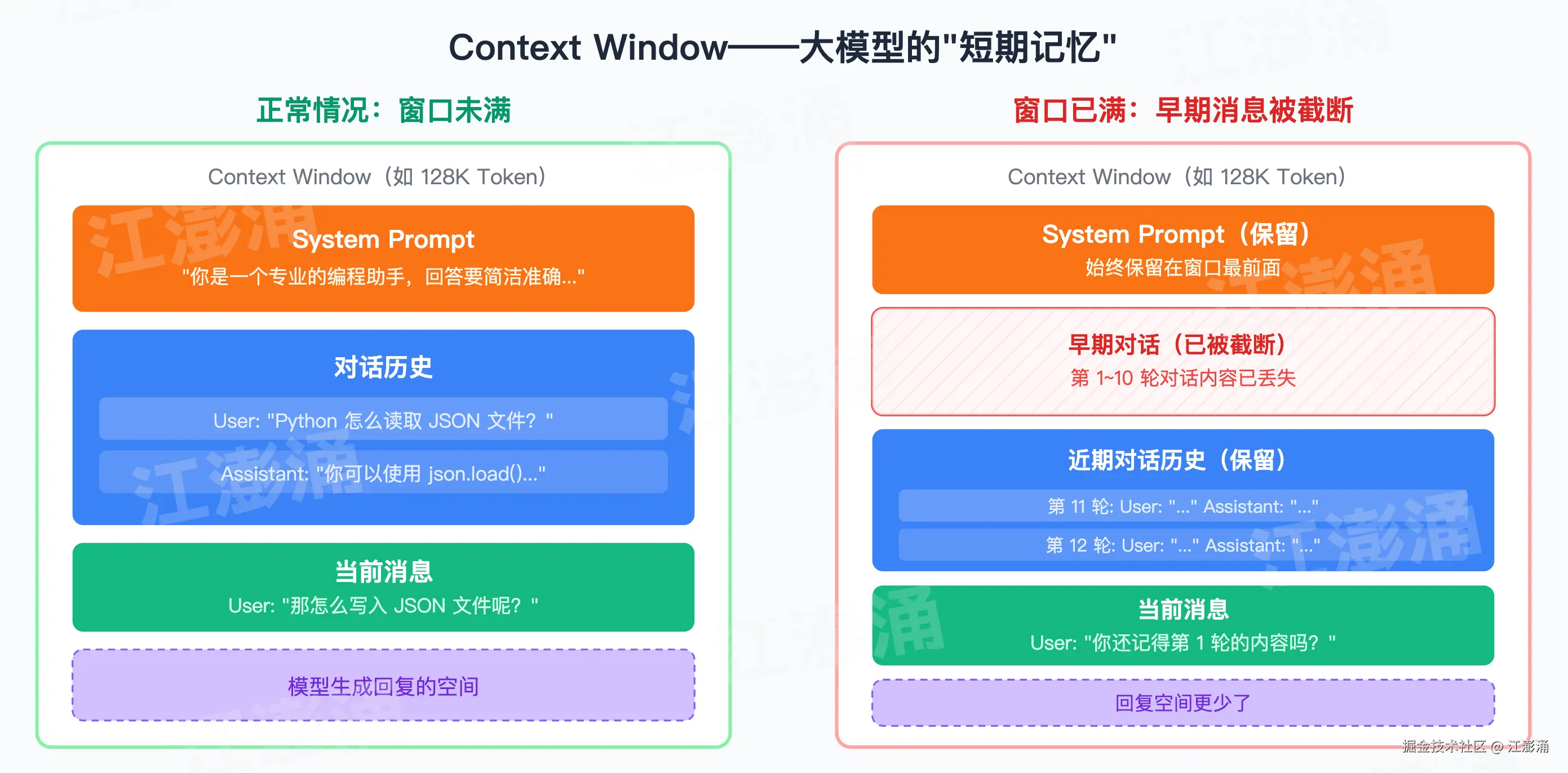
从图中可以知道:Context Window ≥ System Prompt + 对话历史 + 当前消息 + 模型回复
不同模型的 Context Window 大小差异很大:
| 模型 | Context Window |
|---|---|
| GPT-4o | 128K Token(约 10 万字) |
| Claude Sonnet 4.6 | 1M Token(约 75 万字) |
| Gemini 2.5 Pro | 1M Token(约 70 万字) |
1M Token 能装下多少内容?我们一起来算算:
- System Prompt:大约 500 Token
- 每轮对话(一问一答):大约 500 Token
- 1M 的窗口,扣掉系统提示和回复空间,理论上能放近 2000 轮对话
但实际场景远没这么多,代码文件、工具调用说明、检索到的参考资料等都会占用 Token,真正留给对话的空间比想象的少。
后续的文章会进行分享 Skill、MCP 等机制,它们让 AI 能调用外部工具,但每一项都需要在 Context Window 中占用 Token 来描述自己的用法,也就是上面的 "工具调用说明"。
AI 没有 "记忆"
AI 没有 "记忆",所以每一次对话,它都是从头看起的。 当你跟 ChatGPT 聊了 10 轮之后发第 11 条消息,ChatGPT 的客户端会做这样一件事:
- 把 System Prompt 放在最前面
- 把前 10 轮的完整对话记录全部附上
- 把第 11 条消息放在最后
- 把这全部内容一起发给大模型
大模型看到这些内容后,才知道我们之前聊了什么内容,然后才生成回复。每一轮都是如此,每次都从头看完整段历史。
这就解释了几个现象:
- 为什么对话越长越慢? 因为每次都要重新处理所有历史消息,Token 数量越来越多;
- 为什么对话越长越贵? 因为每次输入的 Token 数量在累积增长;
- 为什么 AI 会 "忘记" 前面的话? 因为历史太长了,超过了 Context Window,早期的消息会被截断丢弃;
Context Window 管理策略
Context Window 有长度限制,所以实际的 AI 产品会用一些策略来管理它:
- 截断早期历史:最简单的方式,把最早的对话丢掉,只保留最近的;
- 摘要压缩:把前面的对话用 AI 生成一个摘要,替代原始内容,节省 Token。例如 Claude Code 的 compact 功能,就是在上下文快满时自动将历史对话压缩成摘要,既释放了空间又保留了关键信息;
- RAG(检索增强生成):不把所有信息放在 Context 里,而是建一个数据库,需要时检索相关内容再塞进去;
后续文章会继续深入分享这些问题,敬请期待吧。
多轮对话的 Token 累积
假设你在做一个编程问答,每轮对话平均 400 Token(你的问题 100 Token + AI 回复 300 Token),System Prompt 500 Token:
| 对话轮数 | 本轮发送的总 Token 数 | 累计消耗的 Token 数 |
|---|---|---|
| 第 1 轮 | 500 + 100 = 600 | 600 |
| 第 2 轮 | 500 + 400 + 100 = 1000 | 1600 |
| 第 5 轮 | 500 + 1600 + 100 = 2200 | 7000 |
| 第 10 轮 | 500 + 3600 + 100 = 4200 | 24000 |
| 第 20 轮 | 500 + 7600 + 100 = 8200 | 88000 |
从表格可以看到第 20 轮时,仅仅是输入就已经消耗了 88000 个 Token,如果用 GPT-4o 的价格(约 2.50/百万输入 Token),20 轮对话的输入成本大约是 0.22,这样看起来不多,但几百轮就是一笔不小的开销了。而且 Token 会不断逼近 Context Window 的上限,一旦超出,AI 就会开始 "失忆" 了。
所以使用 AI 辅助工作时,新的任务应该开启新的对话,而不是在一个对话里一直聊下去。因为没有历史记录占用,剩余可用的空间更多,可以容纳更多新内容,也降低使用成本。
四、控制 AI 的行为:Temperature、Top-k、Top-p 和 Max Tokens
至此,客户端把 Prompt 组装好,Tokenizer 把文本切成数字序列,这些数字序列被放入 Context Window 送给大模型。但模型是怎么生成回复,以及我们怎么控制它的行为?
创造力旋钮------Temperature
Temperature 的作用是控制 AI 回答的随机性和创造力,想象在一家餐厅点菜:
- Temperature = 0:相当于跟服务员说 "照往常的来",服务员每次都给你上同一道菜;
- Temperature = 1:相当于跟服务员说 "今天推荐点不一样的",服务员可能推荐一道我们没吃过的创意菜;
- Temperature = 2:服务员开始胡来,端上来一盘完全看不懂的东西;
大模型生成每一个 Token 时,其实是在做一次 "投票",它会给词表中的所有 Token 打分(计算概率),然后从中选一个,至于选不选概率最高的那个,取决于 Temperature。
Temperature 的取值范围通常是 0~2(不同 API 略有差异,OpenAI、Gemini 上限是 2,有些开源模型上限是 1;不过大多数推理类模型不支持调节 Temperature,例如 OpenAI 的 o1 / o3 / GPT-5 系列、Claude 开启 extended thinking 后)。数值越大,随机性越强:
- Temperature 低 (0.0~0.3):模型几乎总是选概率最高的那个 Token,输出非常确定、稳定、可预测,适合代码生成、数据分析、事实性问答;
- Temperature 中等 (0.5~0.8):在高概率 Token 中引入一些随机性,适合日常对话、文案写作;
- Temperature 高 (0.9~1.5):低概率的 Token 也有较大机会被选中,输出更有创意,但也可能更离谱,适合头脑风暴、创意写作。
举个例子:假设下一个 Token 的候选概率:"猫" = 0.6,"狗" = 0.3,"龙" = 0.08,"椅子" = 0.02
- 当 Temperature = 0: 永远选 "猫",因为概率最高
- 当 Temperature = 0.7: 大概率选 "猫",偶尔选 "狗"
- 当 Temperature = 1.5: "猫"、"狗"、"龙" 都有可能,甚至 "椅子" 也有一点机会
可以运行 demo_temperature 的代码,对同一问题使用不同的 Temperature 数值,直观地感受 Temperature 对大模型回答的影响,运行效果如下:

Temperature 怎么影响概率?
模型在预测下一个 Token 时,会给每个候选 Token 算一个 "原始分数"(叫做 logit),然后通过 Softmax 函数把分数转成概率。

上图左边是纯粹的 Softmax 函数,增加了 Temperature 参数则为右边的函数,通过控制 Temperature 大小达到缩放 e 的指数部分,从而放大或缩小 Token 之间的概率差距。
举个例子:现在班里 10 个同学投票选班长(每人 1 票),四位候选人 A、B、C、D 的得票:
- A 同学得 4 票;
- B 同学得 3 票;
- C 同学得 2 票;
- D 同学得 1 票;
这些得票数就是 "原始分数"(logit),代入具有 Temperature 的 Softmax 公式:
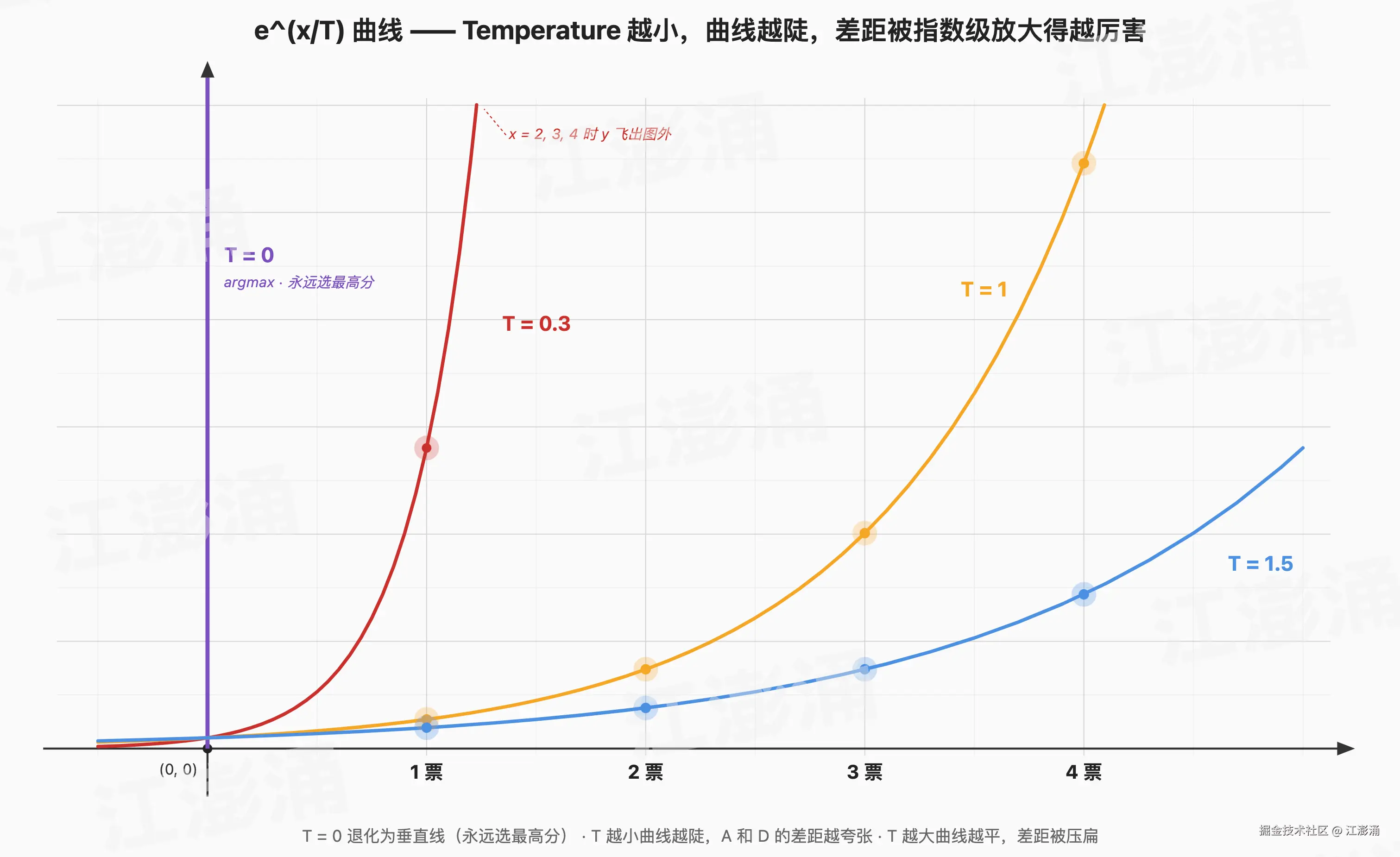
- Temperature = 0(紫色线):不抽签,直接选 A 同学,因为他的票最多;
- Temperature = 0.3(红色线):所有票都被指数级放大,A 被放大倍数最大,几乎独占(约 96.4%),其他几乎没机会;
- Temperature = 1(黄色线):按指数比例抽签,约 64.4% / 23.7% / 8.7% / 3.2%,A 仍领先,但 B、C 也有不小的机会;
- Temperature = 1.5(蓝色线):差距被压扁,A 的概率被缩小得最多,和 D 的差距明显变小,D 也有机会爆冷胜出;
当 Temperature = 0 时,并不会真的代入公式,而是直接进行贪婪采样;
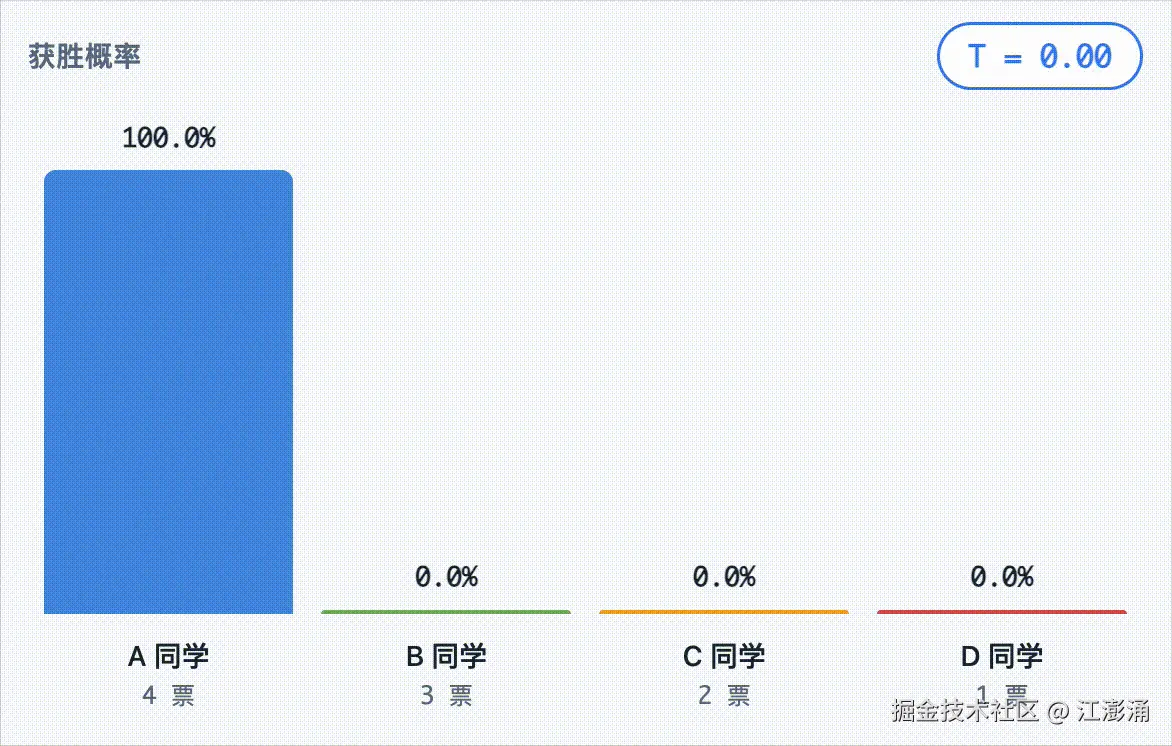
这张动图则连贯地展示了 Temperature 从 0~2 的变化过程对每位同学胜出概率的影响:
- 当 Temperature 缩小时 ,即小于 1 时,高分 Token 和低分 Token 的概率差距被指数级放大,会让高分的 Token 更有可能胜出;
- 当 Temperature 放大时 ,即大于 1 时,差距被指数级压扁,会让更多的 Token 被选择;
实际应用场景
知道了 Temperature 是如何影响结果的,那么我们在现实场景中如何进行设置这个值呢?
| 场景 | Temperature | 为什么? |
|---|---|---|
| JSON 结构数据输出 | 0.0 | 必须严格符合格式 |
| 代码生成 | 0.0~0.2 | 代码需要精确,不能有 "创意性" 的语法错误 |
| 客服机器人 | 0.3~0.5 | 需要稳定但不要太死板 |
| 日常聊天 | 0.7~0.9 | 自然、有变化 |
| 头脑风暴 | 1.0~1.5 | 需要多样性和意外惊喜 |
候选范围------Top-k、Top-p
Top-k 和 Top-p 是另一类控制随机性的方式。它们不像 Temperature 那样改变概率分布的 "形状",而是直接截断候选 Token 的范围,把不太可能的 Token 排除在外,只在剩下的 Token 里采样。
Top-k:按数量截断
只保留概率最高的 k 个 Token,从这 k 个里按概率采样。
- Top-k = 1:永远选概率最高的那个 Token,此时和 Temperature = 0 效果一样;
- Top-k = 50:从概率前 50 的 Token 里采样;
Top-p(Nucleus Sampling):按累积概率截断
把候选 Token 按概率从高到低排序,依次累加,累加到刚刚达到或越过 p 的位置就停,最后将入围的 Token 重新归一化再采样。
举个例子,假设当前候选 Token 的概率已经按从高到低排好:
yaml
A: 50% B: 25% C: 15% D: 7% E: 3%不同 Top-p 下的候选范围如下:
| Top-p | 候选范围 | 累计概率 |
|---|---|---|
| 0.4 | A | 50%(首个就越过 p,保留 A) |
| 0.6 | A, B | 75%(累到 B 时越过 0.6) |
| 0.9 | A, B, C | 90%(累到 C 时刚好达到 0.9) |
| 1.0 | A, B, C, D, E | 100%(全部入围) |
Top-k、Top-p 两者的区别
Top-k 永远取 k 个候选,不管分布是否平均;
Top-p 的候选数则会随分布动态变化,分布不平均时(模型很确定)可能只剩 1~2 个候选,分布很平均时(模型不确定)可能有几十个。这使 Top-p 比 Top-k 更 "聪明",因此现代 LLM 中 Top-p 比 Top-k 更常用。
Temperature、Top-k、Top-p 的关系
| 参数 | 控制方式 |
|---|---|
| Temperature | 调整概率分布的 "锐利度" |
| Top-k | 限制候选数,固定 k 个 |
| Top-p | 限制候选数,按累积概率 |
所以三个参数可以同时使用,并按固定顺序依次作用:
- Temperature 先缩放 logit,即
logit / T,决定分布的整体陡峭度; - Top-k 把排名 k 以外的候选直接砍掉;
- Top-p 在剩下的候选里再按累积概率收窄;
- 最后 Softmax 归一化,从剩下的候选里按概率采样;
但在真实场景,一般建议固定其他参数只调一个。OpenAI 在 API 文档里对 Temperature 和 top_p 都写了同一句话:"We generally recommend altering this or top_p but not both" (建议调 Temperature 或 top_p 中的一个,但不要两个都调)。Temperature 和 top_p 的默认值都是 1,所以只调你顺手的那一个、另一个保持默认,是最稳的做法。
字数上限------Max Tokens
Max Tokens 规定了模型最多能输出多少个 Token。就像考试时老师说 "答案不超过 200 字",你可能写到 150 字就自然收尾了,也可能写到 200 字时被强制停笔。
为什么 AI 有时候回答到一半就断了?
如果你让 AI "详细解释量子计算",但 Max Tokens 只设了 100,它可能说到一半就戛然而止,因为达到了输出上限。
有两种场景会让回答突然中断:
- API 调用时设了太小的 max_tokens,这是开发者的问题,将导致很多场景无法较好地输出结果;
- 模型本身有默认的输出上限,比如某些模型默认最多输出 4096 个 Token,即使你没有显式设置,也会中断输出;
在 ChatGPT 里,如果 AI 的回答突然在一个句子中间断了,你可以点 "继续生成" 按钮,本质上是重新发一次请求,把那段没写完的回复作为最后一条 assistant 消息,模型看到 messages 以 assistant 结尾,就把它当作 "未完成的草稿" 从断点继续生成而不是从头再答一遍。
这里每点一次 "继续生成",前面所有对话历史 + 已生成的不完整内容都会被作为输入重新发一次并重新计费,这也是另一个角度回应了 "多轮对话越长越贵" 的问题。
可以运行 demo_max_tokens 代码,感受 Max Tokens 的作用,运行的效果如下:

Max Tokens 和 Context Window 的区别
Max Tokens 和 Context Window 是不同的东西:
| 概念 | 含义 |
|---|---|
| Context Window | 模型一次能看到的总 Token 数(输入 + 输出) |
| Max Tokens | 调用一次 API 或发送一次请求,模型最多能输出的 Token 数 |
Max Tokens 必须小于 Context Window 减去输入的 Token 数。如果你的输入已经占了 120K Token,而 Context Window 是 128K,那模型最多只能输出 8K Token 的回复,不管你 Max Tokens 设多大。
五、为什么 AI 是一个字一个字蹦出来的------Streaming
当我们在 ChatGPT 或 Claude 里提问时,AI 的回答不是 "砰" 的一下全部出现的,而是一个字一个字地 "打" 出来,就像有人在实时打字一样。这不是为了好看而增加的动画效果,而是技术本质决定的。
大模型的生成方式:逐 Token 生成
大模型不是一次性算出整段回答的,它的工作方式是:
- 看完所有输入(即我们前面组装好的 Prompt);
- 然后预测第 1 个输出 Token;
- 把第 1 个 Token 加到已有内容后面,再预测第 2 个 Token;
- 把第 1、2 个 Token 都加上,预测第 3 个 Token;
- ......如此循环,直到生成一个 "结束" Token,或者达到 Max Tokens;
"结束" Token(也叫 EOS,end-of-sequence)是词表里的一个特殊 Token,模型在训练时学过 "一段话讲完了就该输出它",所以模型知道什么时候该停下来。
这个过程叫做 Autoregressive Generation(自回归生成),每一步都依赖前面所有步的结果。
不用 Streaming 会怎样?
如果不用 Streaming,客户端需要等大模型生成完所有 Token 后,才能拿到回复。
一个 500 Token 的回复,假设每个 Token 需要 30 毫秒,总共需要 15 秒。用户要盯着空白屏幕等 15 秒,体验极差。
Streaming 的做法
Streaming(流式输出)的做法很简单:模型每生成一个或几个 Token,就立刻通过网络发送给客户端,客户端实时显示。
这样用户在第 30 毫秒就能看到第一个字,而不是 15 秒后才看到全文。虽然总时间没变,但感知等待时间从 15 秒降到了几十毫秒,用户体验会好很多。
从技术实现上说,Streaming 通常使用 SSE(Server-Sent Events) 协议,一种服务器向客户端持续推送数据的 HTTP 技术。每次推送一小块数据(chunk),里面包含新生成的 Token。
可以运行 demo_streaming 感受这一过程,效果如下图:
每个红色的 ▌ 表示一个数据块
Streaming vs 非 Streaming 的对比
| 维度 | 非 Streaming | Streaming |
|---|---|---|
| 用户感知 | 等很久,然后整段文字一次出现 | 第一个字很快出现,持续流入 |
| 首 Token 延迟 | 等于完整生成时间,可能 10~30 秒 | 约几十毫秒到 2 秒 |
| 总完成时间 | 相同 | 相同 |
| 实现复杂度 | 简单,一次 HTTP 请求响应 | 稍复杂,需要处理 SSE 流 |
| 可以中途取消 | 不行,要么等完要么放弃 | 可以,关闭连接即可停止生成 |
| 错误处理 | 简单,要么成功要么失败 | 更复杂,流中间可能断开 |
对于面向用户的产品,Streaming 几乎是必选项,这是一个更好的体验。用户肯定不愿盯着一个加载动画等 20 秒,而是可以更快地看到结果,即使是一部分。但在后端场景中,比如批量处理、自动化流水线,非 Streaming 反而更方便,因为你不需要流式处理,只需要最终结果。
首 Token 延迟------TTFT
在 AI 领域,首 Token 延迟(TTFT,Time To First Token) 是一个关键的性能指标。它衡量的是:从你发送请求到收到第一个 Token 之间的时间。
TTFT 越短,用户感觉 AI "反应越快"。影响 TTFT 的因素包括:
- 模型大小:越大的模型,处理输入的时间越长
- 输入长度:Prompt 越长,意味着 Token 越多,模型读完输入的时间越长
- 服务器负载:高峰期排队时间更长
- 网络延迟:用户跟服务器的物理距离
有时候感觉 AI "反应慢了",可能不是模型变笨了,而是 TTFT 变长了。Claude 的 1M Context 如果塞满了,TTFT 可能需要好几秒。
六、实战一下吧
本篇所有运行的代码,可以在 01_拆解与 AI 的一次对话 进行查看,包含了以下 demo:
github 地址:github.com/zincPower/L...
Temperature 的作用
Max Tokens 的限制
Streaming 效果
多轮对话

Token 的计算

纸上得来终觉浅,分享得再多不如自己运行一次,调一调参数感受这中间的不同,至于如何运行,可以查看 README.md。
七、写在最后
如果本篇文章让你对大模型有些不一样的认识或是有所收获,请给我一个赞并关注我吧,码字不易,请多多支持。
如果文章有笔误或是有疑惑,请在评论区留言讨论或是联系我,让我们一起进步,一起拥抱 AI,让它成为我们手中的一把利剑。
个人博客
掘金:江澎涌
CSDN:江澎涌
公众号:微信搜索 "江澎涌"