Transformer架构的变体
Encoder-only
架构图
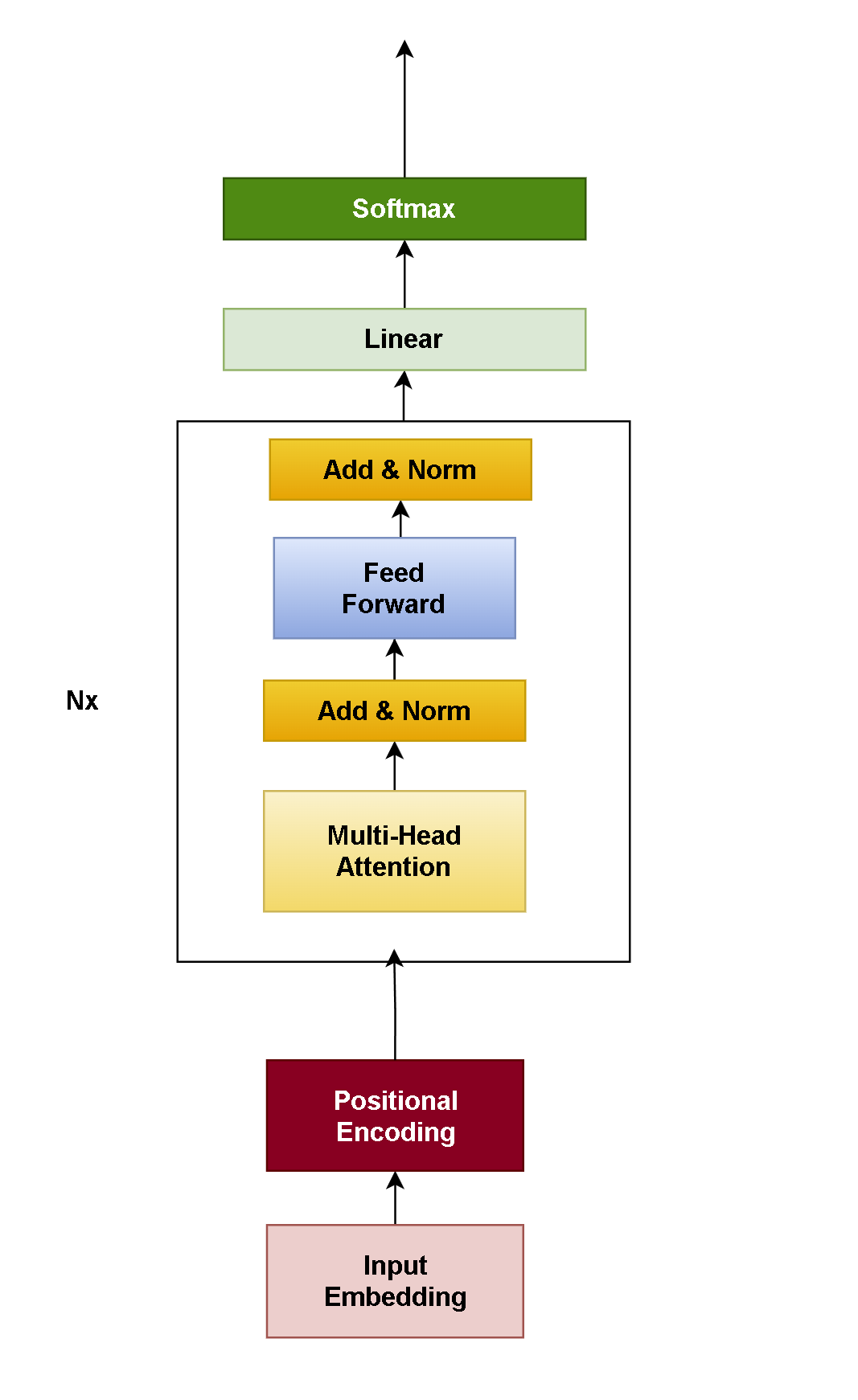
核心能力:文本理解(分类、NER等)
代表模型: BERT、RoBERTa、ALBER
当前地位: 逐渐被替代(仅用于纯理解任务)
Transformer
核心能力:序列转换(翻译、摘要等)
代表模型: T5、BART
当前地位: 特定场景使用(如翻译、摘要)
Decoder-only
架构图与 Encoder-only结构差不多,差别在掩码
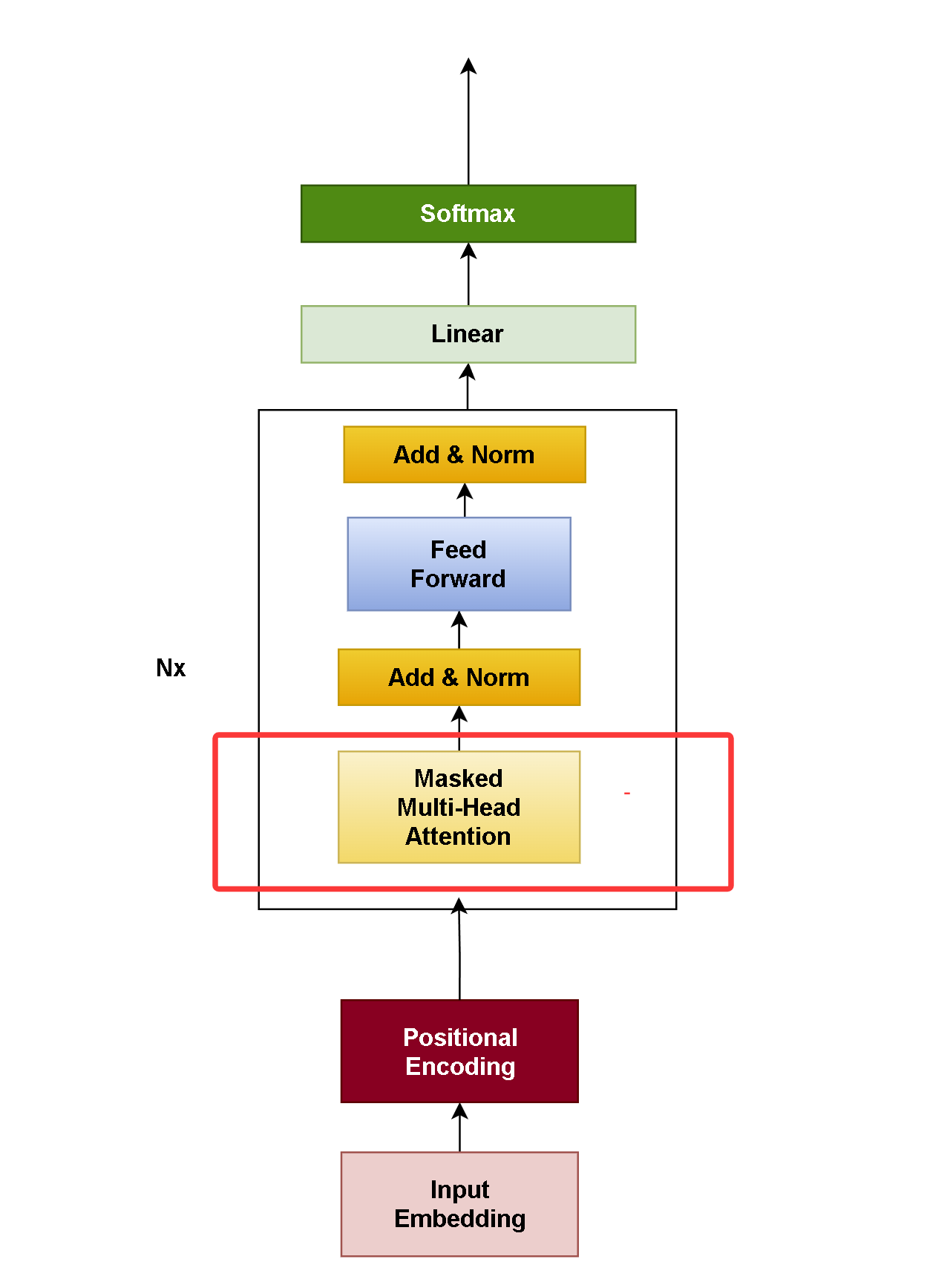
核心能力:序列生成(对话、写作等)
代表模型: GPT、Llama、Claude、deepseek
当前地位: 主流选择(通用大模型首选)
其优势在于强大的自回归生成能力、优秀的扩展性和任务通用性,能满足通用生成需求,模型复杂度低,易于训练,无监督文本数据训练,这是Decoder-only架构的优势。
手写Decoder-only架构代码
手写过Transformer架构代码,decoder-only架构相对简单点
1. 代码优化:
位置编码和词嵌入合成一个类
cpp
class EmbeddingWithPositionImpl : public torch::nn::Module
{
public:
EmbeddingWithPositionImpl(int64_t d_model, int64_t vocab_size, int64_t max_len)
{
m_iDmodel = d_model;
m_iMaxlen = max_len;
m_posEncode = torch::zeros({ m_iMaxlen, m_iDmodel }, torch::kFloat32);
Encoding();
emb_dropout = register_module("emb_dropout1", torch::nn::Dropout(dropoutp));
m_embPosition = register_module("m_embPosition", torch::nn::Embedding(torch::nn::EmbeddingOptions(max_len, m_iDmodel)));
m_emb = register_module("m_emb", torch::nn::Embedding(torch::nn::EmbeddingOptions(vocab_size, m_iDmodel)));
register_buffer("posEncode", m_posEncode);
}
torch::Tensor& forward(torch::Tensor& x)
{
// x [bath, seq]
//cout << x.sizes()<<endl;
//cout <<m_emb << endl;
x = m_emb->forward(x) * std::sqrt(m_iDmodel);
// cout << x.sizes() << endl;
// x [bath, seq, dim]
auto seq = x.size(1);
auto B = x.size(0);
// cout << "x " << x.sizes() << endl;
//cout << "m_posEncode " << m_posEncode.sizes() << endl;
//cout << "m_posEncode.slice " << m_posEncode.slice(1, 0, dim).sizes() << endl;
auto pos = torch::arange(seq, x.device()).unsqueeze(0).expand({ B, seq });
x = x + m_posEncode.slice(1, 0, seq);
//x = x + m_embPosition->forward(pos);
x = emb_dropout->forward(x);
return x ;
}
private:
void Encoding()
{
auto pos = torch::arange(0, m_iMaxlen, torch::kFloat32).reshape({ m_iMaxlen, 1 });
auto den_indices = torch::arange(0, m_iDmodel, 2, torch::kFloat32);
auto den = torch::exp(-den_indices * std::log(10000.0f) / m_iDmodel);
m_posEncode.index_put_({ torch::indexing::Slice(), torch::indexing::Slice(0, m_iDmodel, 2) }, torch::sin(pos * den));
m_posEncode.index_put_({ torch::indexing::Slice(), torch::indexing::Slice(1, m_iDmodel, 2) }, torch::cos(pos * den));
m_posEncode.unsqueeze_(0);
// [bath,seq,dim]
}
torch::nn::Dropout emb_dropout{ nullptr };
torch::nn::Embedding m_emb{ nullptr };
torch::nn::Embedding m_embPosition{ nullptr };
torch::Tensor m_posEncode;
int64_t m_iDmodel = 0;
int64_t m_iMaxlen = 0;
};
TORCH_MODULE(EmbeddingWithPosition);2. 代码优化:
- 前馈神经网络合并到解码器
cpp
class DeOnlyLayerImpl : public torch::nn::Module
{
public:
DeOnlyLayerImpl(int64_t dmodel, int64_t nheads,int64_t feedforward)
{
m_fFeedForward = register_module("feedForward", torch::nn::Sequential(torch::nn::Linear(dmodel, feedforward),
torch::nn::GELU(), torch::nn::Linear(feedforward, dmodel)));
}
//torch::nn::MultiheadAttention m_attention{ nullptr };
XMultiHeadAttention m_attention{ nullptr };
torch::nn::Sequential m_fFeedForward{ nullptr };
};
TORCH_MODULE(DeOnlyLayer);- decoder-only实现代码
cpp
class DecodersOnlyImpl : public torch::nn::Module
{
public:
DecodersOnlyImpl(const DeOnlyOptions& inOpt)
{
fc = register_module("fc", torch::nn::Linear(inOpt.dmodel, inOpt.vocab_size));
m_emb = register_module("m_emb", EmbeddingWithPosition(inOpt.dmodel, inOpt.vocab_size, inOpt.max_len));
moduleLayers = register_module("EncoderLayers", torch::nn::ModuleList());
m_option = inOpt;
for (int i = 0; i < inOpt.layers; i++)
{
torch::nn::TransformerEncoderLayerOptions opt(inOpt.dmodel, inOpt.head);
opt.dim_feedforward(inOpt.ffn);
//opt.dropout(0);
moduleLayers->push_back(DeOnlyLayer(inOpt.dmodel, inOpt.head, inOpt.ffn));
/// moduleLayers->push_back(torch::nn::TransformerEncoderLayer(opt));
}
}
auto forward(torch::Tensor x)
{
// x [bath, seq]
int64_t batch = x.size(0);
int64_t seq = x.size(1);
auto src_mask = generate_square_subsequent_mask(seq).to(x.device());
auto tgt_key_padding_mask = (x == gPad).to(torch::kBool).to(x.device());
x = m_emb->forward(x);
x = x.permute({ 1,0, 2 });
// cout <<x.sizes()<< endl;
for (auto& item : *moduleLayers)
{
x = item->as<DeOnlyLayer>()->forward(x, src_mask);
//x = item->as<torch::nn::TransformerEncoderLayer>()->forward(x, src_mask, tgt_key_padding_mask);
}
return fc->forward(x);
}
torch::Tensor generate_square_subsequent_mask(int64_t sz)
{
auto mask = torch::triu(torch::ones({ sz, sz }, torch::kFloat32), 1);
mask = mask.masked_fill(mask == 1, -std::numeric_limits<float>::infinity());
return mask;
}
public:
EmbeddingWithPosition m_emb{ nullptr };
torch::nn::ModuleList moduleLayers{ nullptr };
torch::nn::Linear fc{ nullptr };
DeOnlyOptions m_option;
};
TORCH_MODULE(DecodersOnly);- 多头注意力、训练代码、三角掩码和上一章相同
3. 推理预测:
举例说明诗集:"春眠不觉晓,处处闻啼鸟。 夜来风雨声,花落知多少。" ,当我们把"春眠不觉晓" 输入给模型后产生流程: 1. "<S>春眠不觉晓" -> "春眠不觉晓,"
-
"<S>春眠不觉晓," -> "春眠不觉晓,处"
-
"<S>春眠不觉晓,处" -> "春眠不觉晓,处处"
....
相应代码
cpp
string predict(string ch, translatDatasetOnly& dataTest)
{
std::vector<int64_t> tgtpad;
tgtpad.push_back(gBOS);
tgtpad.push_back(5);
tgtpad.push_back(6);
tgtpad.push_back(7);
int start = tgtpad.size() - 1;
std::vector<int64_t> outVector;
cout << "input: ";
for (auto xx : tgtpad)
{
cout << xx<< " , ";
}
cout << endl;
int i = 0;
while (i < 100)
{
torch::Tensor tgt = torch::tensor(tgtpad, torch::kLong).to(gDType);
auto out = forward(tgt.unsqueeze(0));
// out = out.squeeze();
//cout << out.sizes() << endl;
auto next_token = out.argmax(-1).cpu();
// cout << next_token << endl;
int64_t key = next_token[i+ start].item<int64_t>();
tgtpad.push_back(key);
if (key == gEOS)
{
break;
}
i++;
}
cout << "tgtpad ";
for (auto& key : tgtpad)
{
cout << key << " ";
}
cout << endl << endl<<endl;
return "__TestData__";踩过一个坑跟大家分享一下,本着最简单的原则 decoder-onl与Encoder-only结构差不多,最要区别在掩码, 用torch::nn::TransformerEncoderLayer作为解码器层再接上全连接层,写完用二条数据测试发现没问题正常,用300一首诗集数据训练实现诗集填写模型,无论怎样模型维度、解码器层数、学习率、批次大小、调整词表大小都无法收敛,为了验证模型架构的正确性,使用一组有规律数据作为数据集
4.测试数据集
有这样的数据组合 第一组 从1到50 有50个数字
第二组 从2到50 有49个数字
第三组 从3到50 有48个数字
.....
第四十组 从40到50 有10个数字
相应数据生成代码
cpp
vector<vector<int64_t>> MakeTestData(int count)
{
count = min(count, 50);
gVocabCount = 55;
gBOS = 51;
gEOS = 52;
gPad = 53;
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> dis(0, 49);
vector<vector<int64_t>> data;
for (size_t i = 0; i < count; i++)
{
vector<int64_t> item;
for (int j = 1; j < 50 - i; j++)
{
int randomNumber = i + j;//dis(gen);
item.push_back(randomNumber);
}
data.push_back(item);
}
return data;
}这些数据长度不一样,同一批次长度必须一样 ,要重写torch::data::samplers::next函数
cpp
struct BatchSampler : public torch::data::samplers::RandomSampler
{
BatchSampler(translatDatasetOnly* dataset) : RandomSampler(*dataset->size())
{
m_dataset = dataset;
}
std::optional<std::vector<size_t>> next(size_t batch_size) override
{
auto vlist = RandomSampler::next(batch_size);
if (vlist != std::nullopt)
{
m_dataset->UpdateBatchMax(*vlist);
}
return vlist;
}
translatDatasetOnly* m_dataset;
};得到同一批次的下标集合,找出本批次最大长度,
cpp
void UpdateBatchMax(std::vector<size_t>& vlist)
{
m_gMaxBatch = 0;
for (size_t i = 0; i < vlist.size(); i++)
{
m_gMaxBatch = max(m_gMaxBatch, m_vTestData.at(vlist.at(i)).size());
}
} 同一批次长度相同,目的是为了 节省点算力和内存
cpp
torch::data::Example<torch::Tensor, torch::Tensor> get(size_t index) override
{
auto item = m_vTestData.at(index);
int len = m_gMaxBatch - item.size();
item.insert(item.begin(), gBOS);
item.push_back(gEOS);
for (int i = 0; i < len; i++)
{
item.push_back(gPad);
}
auto inpput = torch::tensor(item, torch::kLong);
item.erase(item.begin());
item.push_back(gPad);
auto lable = torch::tensor(item, torch::kLong);
return { inpput, lable };
}加载数据代码
cpp
BatchSampler sampler(&dataTrain);
auto datasetTrain = dataTrain.map(torch::data::transforms::Stack<>());
auto train_data_loader = torch::data::make_data_loader(std::move(datasetTrain), std::move(sampler),torch::data::DataLoaderOptions().batch_size(batchsize));训练时数据:
输入: <s> 5,6,..50</s> <p><p>
标签:5,6,...50</s><p><p><p>
5.训练和推理
用40组数据来验证框架的正确性,运行效果
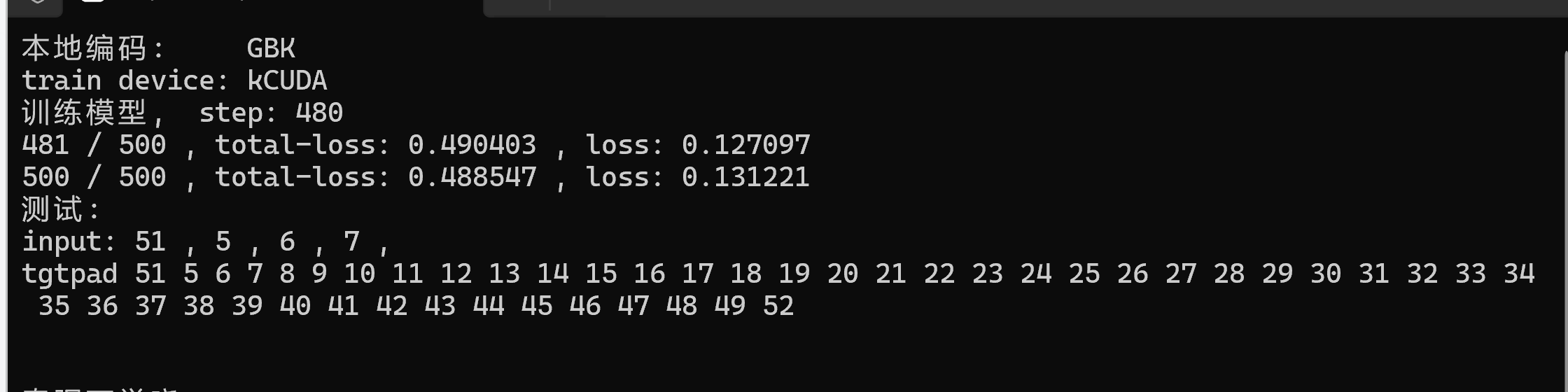
为了减少计算量 模型参数设置比较少,为提高计算速度要使用GPU来计算,用cpu数据量大时计算太慢了,使用GPU来提高计算速度,需要硬件支持和安装环境。
CUDA 配置和使用
1.硬件是否支持
CUDA 硬件是否支持,取决于所使用的 GPU 是否为 NVIDIA 生产且支持 CUDA 架构。
用命令行查看: nvidia-smi
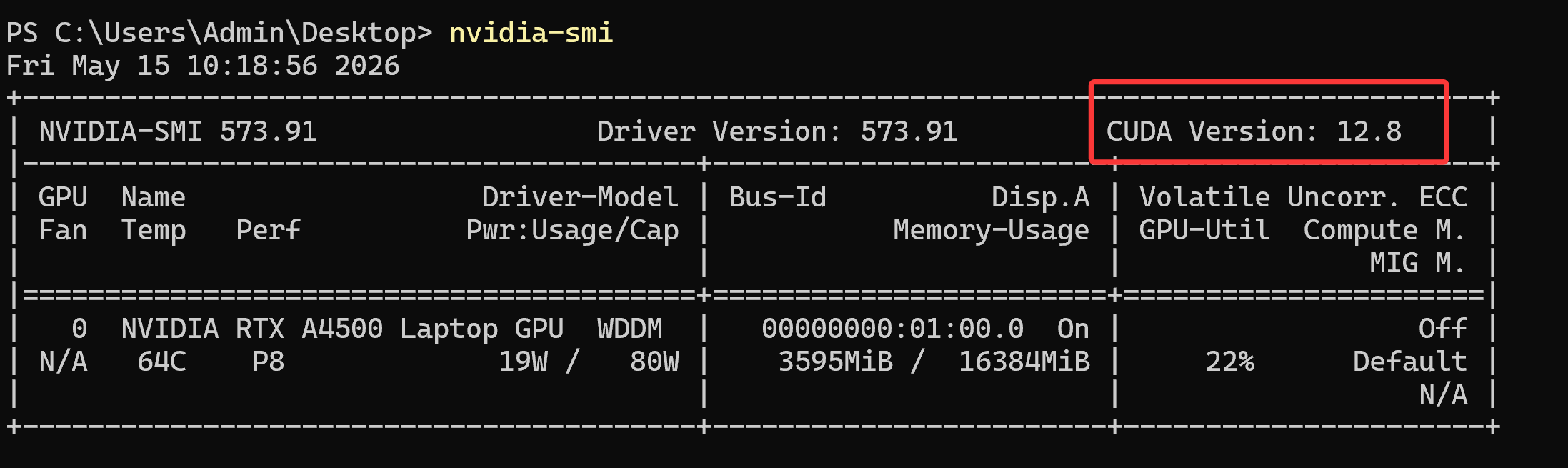
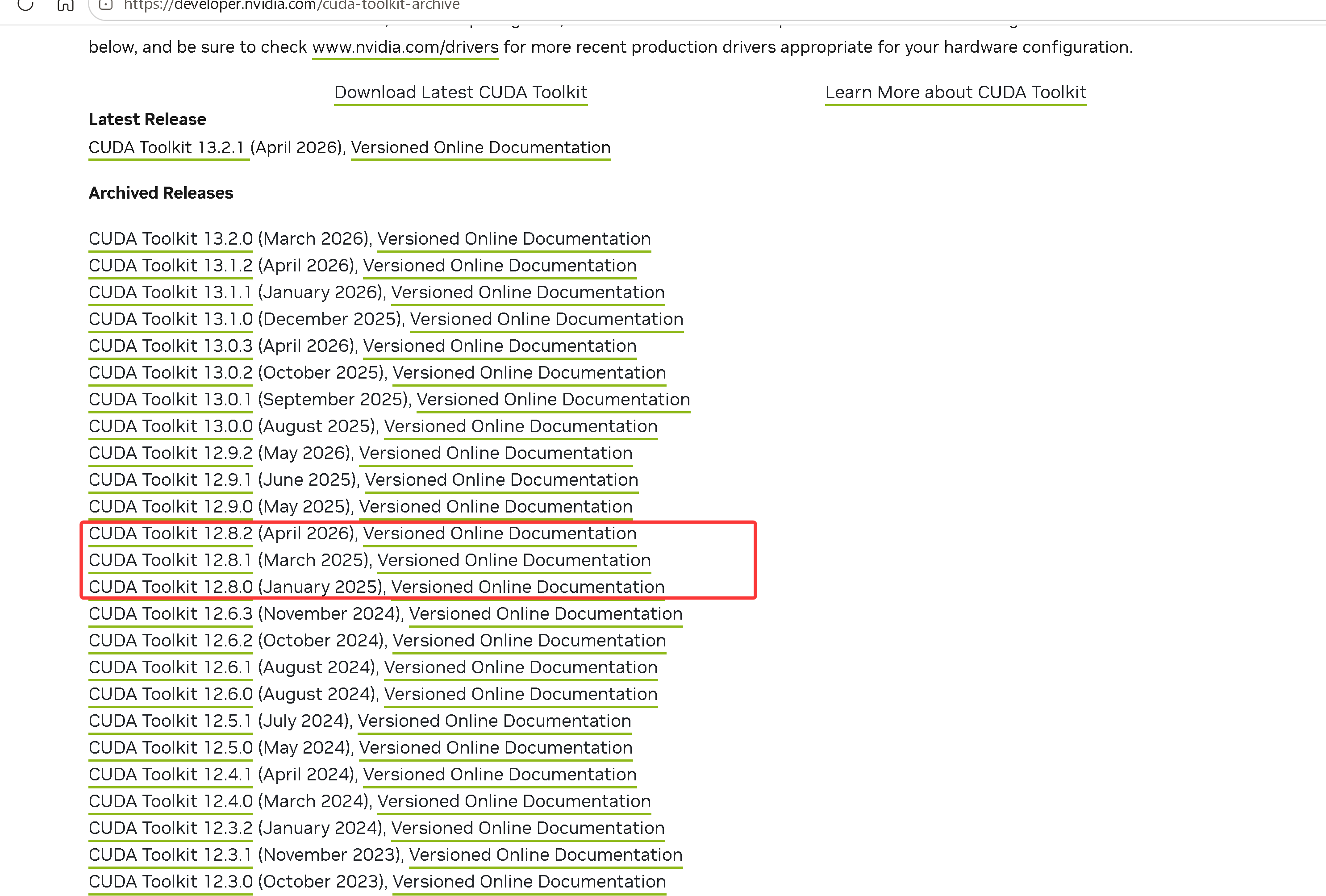
2.选择下载CUDA版本
根据nvidia-smi 命令查询选择下载对应版本,如上 选择 cuda12.8 下载安装 https://developer.nvidia.com/cuda-toolkit-archive

3. 选择下载libtorch-cuda版本
下载点 Get Started
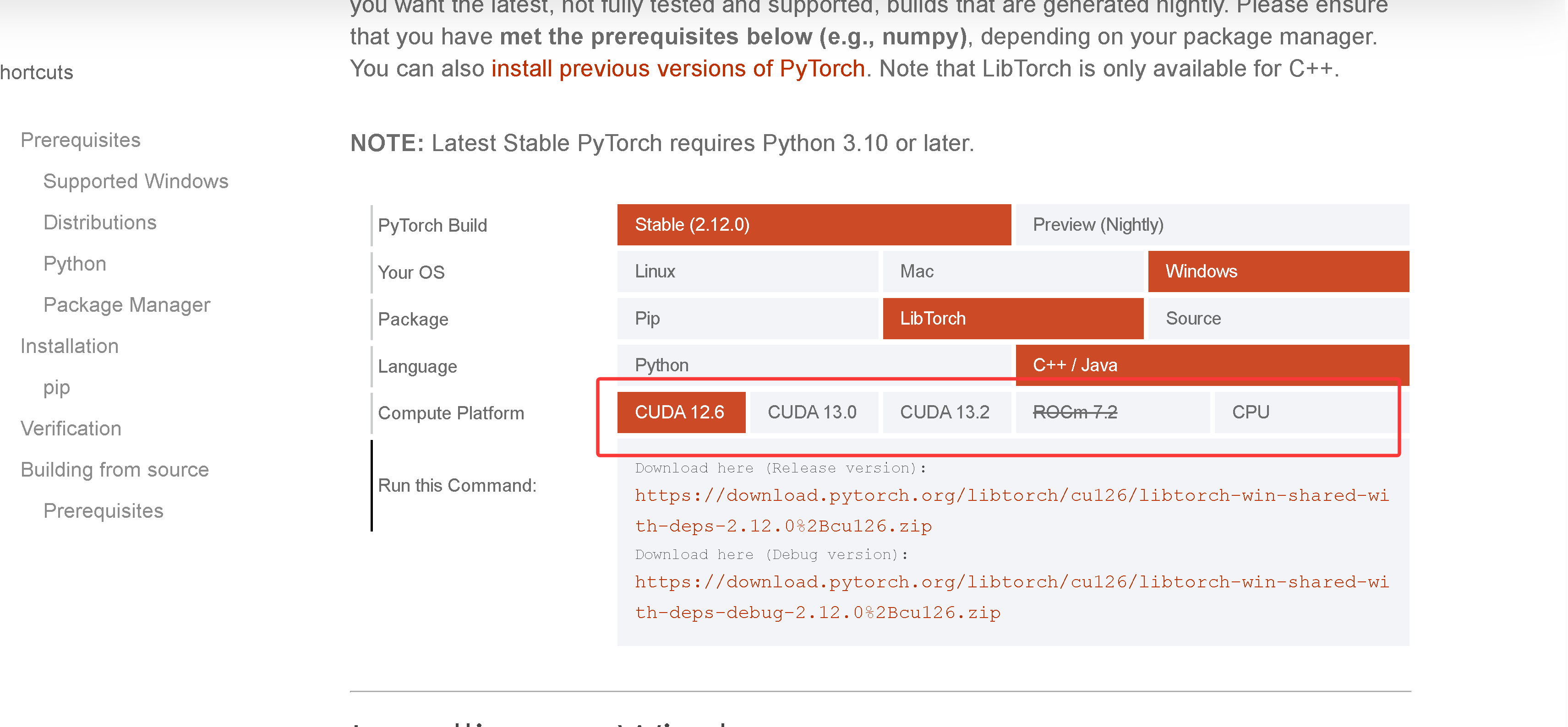
如上找不到CUDA 12.8版本, 是因为最新版本出来了隐藏了一些版本, URL 模板(自己拼任何版本)
cpp
cuda-debug:
https://download.pytorch.org/libtorch/cuXXX/libtorch-win-shared-with-deps-debug-VERSION%2BcuXXX.zip
cuXXX: cu126, cu128
VERSION: 2.10.0 2.11.0
下载 cu128 + 2.11.0
https://download.pytorch.org/libtorch/cu128/libtorch-win-shared-with-deps-debug-2.11.0%2Bcu128.zip4.工程项目
vs2022+cmake工程,CMakeLists.txt
cpp
# CMakeList.txt: GpuMakeProject 的 CMake 项目,在此处包括源代码并定义
# 项目特定的逻辑。
#
cmake_minimum_required (VERSION 3.8)
# 如果支持,请为 MSVC 编译器启用热重载。
if (POLICY CMP0141)
cmake_policy(SET CMP0141 NEW)
set(CMAKE_MSVC_DEBUG_INFORMATION_FORMAT "$<IF:$<AND:$<C_COMPILER_ID:MSVC>,$<CXX_COMPILER_ID:MSVC>>,$<$<CONFIG:Debug,RelWithDebInfo>:EditAndContinue>,$<$<CONFIG:Debug,RelWithDebInfo>:ProgramDatabase>>")
endif()
project ("GpuMakeProject")
set(targetExeName "MakeProject")
if(CMAKE_BUILD_TYPE STREQUAL "Debug")
set(torchpath "D:/libtorch_gpu2.11.0/debug")
else()
set(torchpath "D:/libtorch_gpu2.11.0/debug")
endif()
find_package(Torch REQUIRED PATHS "${torchpath}/share/cmake/Torch/")
include_directories(${TORCH_INCLUDE_DIRS})
if(CMAKE_BUILD_TYPE STREQUAL "Debug")
set(CMAKE_RUNTIME_OUTPUT_DIRECTORY_DEBUG ${CMAKE_SOURCE_DIR}../Debug/)
else()
set(CMAKE_RUNTIME_OUTPUT_DIRECTORY_RELEASE ${CMAKE_SOURCE_DIR}../bin2/)
endif()
file(GLOB SRC_FILES ${PROJECT_SOURCE_DIR}/*.cpp)
add_executable (${targetExeName} ${SRC_FILES})
target_link_libraries(${targetExeName} "${TORCH_LIBRARIES}")
file(GLOB TORCH_DLLS "${TORCH_INSTALL_PREFIX}/lib/*.dll"
)
add_custom_command(TARGET ${targetExeName}
POST_BUILD
COMMAND ${CMAKE_COMMAND} -E copy_if_different
${TORCH_DLLS}
$<TARGET_FILE_DIR:${targetExeName}>)
# 将源代码添加到此项目的可执行文件。
##add_executable (GpuMakeProject "GpuMakeProject.cpp" "GpuMakeProject.h")
if (CMAKE_VERSION VERSION_GREATER 3.12)
set_property(TARGET ${targetExeName} PROPERTY CXX_STANDARD 20)
endif()
# TODO: 如有需要,请添加测试并安装目标。
到这里decoder-only架构基本完成 下一章接着实现一个诗集填空示例。
感谢大家的支持。