线上服务告警频发:Pod CrashLoopBackOff、接口 P99 飙升、节点资源告警......你需要快速定位是哪个 Pod 出了问题、翻看分散的容器日志、还要判断是否需要扩容。一个人排查耗时耗力,能不能让多个 Agent 分工协作?
JiuwenSwarm 是基于 openJiuwen 框架构建的智能 AI Agent,提供 Team 模式(多智能体协作)、Skill 技能系统、Heartbeat 心跳巡检、Cron 定时任务等能力,可以帮助云原生开发者构建智能化的 K8s 集群管理 Agent 团队。

核心能力速览
动手之前,先了解 JiuwenSwarm 中与 K8s 管理场景相关的几个核心能力:
Team 模式(多智能体协作)
JiuwenSwarm 支持 Agent / Code / Team 三种运行模式。Team 模式支持配置 Leader + 多个 Agent 的协作团队,通过 /mode team 切换。在 config.yaml 中配置团队结构,Leader 的 persona 字段定义该角色的行为方式。
Skill 技能系统
Skill 是 JiuwenSwarm 的可安装能力模块,每个 Skill 是一个包含 SKILL.md 的文件夹:
my-skill/
├── SKILL.md # 技能定义(必须)
├── references/ # 参考文档(可选)
└── scripts/ # 辅助脚本(可选)技能来源包括:内置技能、SkillNet(基于 GitHub)、ClawHub(技能商店)、本地导入。
Heartbeat 心跳巡检
Heartbeat 机制可以按固定间隔触发 Agent 执行任务。在 HEARTBEAT.md 中定义巡检任务,Agent 会在每次心跳时读取并执行。配置位于 config.yaml:
heartbeat:
every: 3600 # 间隔秒数,3600 = 每小时
target: web # 结果推送到哪个渠道
active_hours: # 生效时间段(本地时间)
start: 08:00
end: 22:00Cron 定时任务
Cron 功能支持创建定时执行的 Agent 任务,在 Web UI 的 Cron / Scheduled tasks 面板中配置,支持标准 5 字段 cron 表达式,结果可推送到 web、飞书等渠道。
实操:搭建 K8s 集群管理 Agent 团队
一、安装与初始化
pip install jiuwenclaw
jiuwenclaw-init初始化完成后,工作空间位于 ~/.jiuwenclaw/,通过 jiuwenclaw-start 启动服务,浏览器访问 http://localhost:5173。
启动后进入"设置 → 配置信息 → 模型配置",填入大模型 API KEY(支持华为云 MaaS 等平台)。
二、配置 K8s 管理团队(Team 模式)
编辑 ~/.jiuwenclaw/config/config.yaml,在 modes 部分添加 Team 配置:
modes:
team:
k8s_ops_team:
team_name: k8s_ops_team
lifecycle: persistent
teammate_mode: build_mode
spawn_mode: inprocess
leader:
member_name: k8s_ops_leader
display_name: K8s运维值班长
persona: "资深K8s运维工程师,擅长Pod诊断、日志分析和资源扩缩容。
收到集群异常报告后,你需要:
1) 执行Pod诊断,定位异常Pod及其根因;
2) 聚合相关Pod日志,分析异常模式;
3) 综合资源利用率给出扩缩容建议。
所有分析结果以结构化格式输出。"
agents:
leader:
workspace:
stable_base: true
max_iterations: 200
completion_timeout: 600.0
workspace:
enabled: true
transport:
type: inprocess
storage:
type: sqlite
启动或重启服务后,在 Web 对话框中输入 /mode team 切换到团队模式。
三、创建 K8s 运维分析技能(Skill)
除了 Team 模式,也可以创建专用 Skill 来处理集群运维分析。
本地创建 Skill 文件:
cd ~/.jiuwenclaw/agent/jiuwenclaw_workspace/skills
mkdir k8s-ops-analysis创建 SKILL.md:
name: k8s-ops-analysis
version: 1.0.0
description: K8s集群运维分析技能,支持Pod诊断、日志聚合分析和扩缩容建议
tags: [k8s, pod, logs, scaling]
allowed_tools: [webSearch, readFile]
K8s 集群运维分析
当收到集群异常需要分析时,按以下流程处理:
步骤
Pod 诊断:对异常 Pod 执行诊断分析(检查状态、事件、资源限制),按严重程度分为 Critical(Pod 不可用)、Warning(频繁重启)、Info(资源预警)。关联同一 Deployment/StatefulSet 下的 Pod 进行分组去重。
日志聚合分析:对异常 Pod 组收集容器日志,使用模式匹配识别 ERROR/WARN 关键信息,按出现频率排序,输出 Top 异常模式和时间线。
扩缩容建议:基于当前资源利用率(CPU/内存)、Pod 异常模式、业务趋势,给出扩缩容建议(扩容/缩容/维持),附上目标副本数和理由。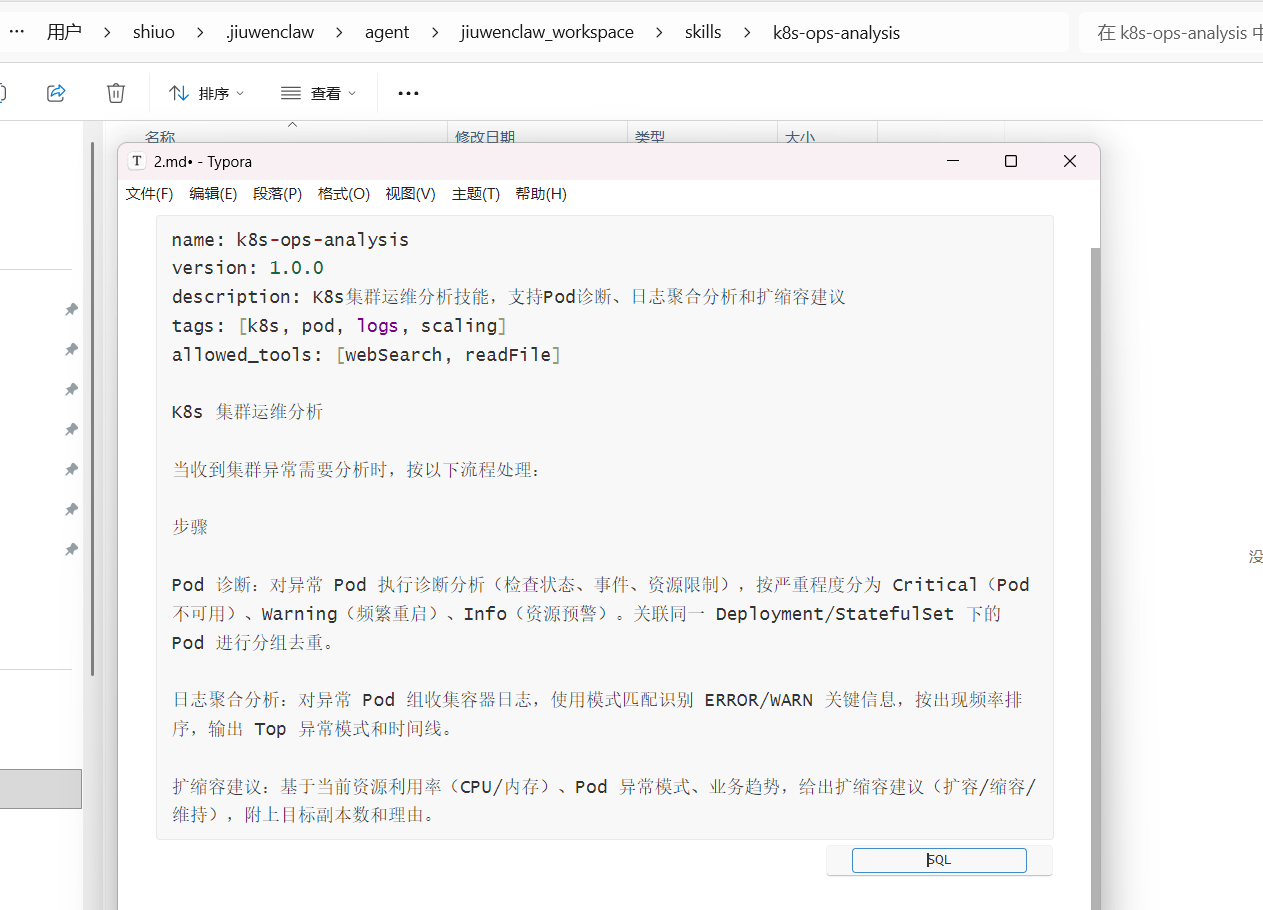
也可以通过 Web 界面左侧栏 → Skills → Local import → 选择上述技能文件夹安装。
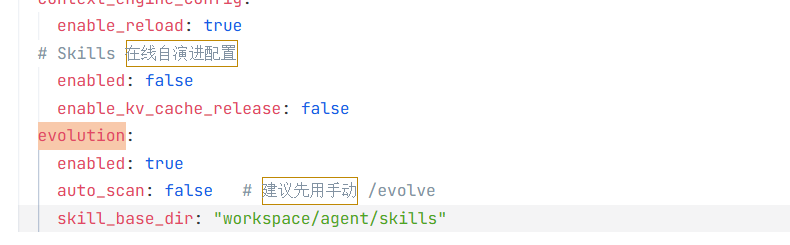
技能自演进: JiuwenSwarm 支持技能自演进(Skill Evolution),Agent 会根据使用反馈自动优化 SKILL.md 内容。在 config.yaml 中配置:
四、配置心跳巡检(Heartbeat)
编辑 ~/.jiuwenclaw/agent/jiuwenclaw_workspace/HEARTBEAT.md,添加 K8s 巡检任务:
心跳任务:
检查集群中是否有新增的 CrashLoopBackOff 或 ImagePullBackOff Pod
如有异常 Pod,按 k8s-ops-analysis 技能流程进行分析
汇总当前各命名空间的 Pod 健康状态统计
在 config.yaml 中调整心跳间隔:
heartbeat:
every: 300 # 每 5 分钟巡检一次
target: web
active_hours:
start: 00:00 # 24 小时覆盖
end: 23:59
五、配置定时集群巡检汇总(Cron)
在 Web UI 中打开 Cron / Scheduled tasks → 点击 New job:
- name :
daily_k8s_report - cron_expr :
0 9 * * *(每天上午 9 点) - timezone :
Asia/Shanghai - targets :
web - description:汇总过去 24 小时的集群状态,包括各命名空间 Pod 异常数、Top-5 频繁异常服务、资源利用率概览

也可以通过对话创建:"创建一个每天早上 9 点的定时任务,汇总过去 24 小时 K8s 集群状态,推送到 web。"
实际使用示例
场景:API 服务 Pod 异常引发连锁故障
在 JiuwenSwarm 的 Web 对话框中(使用 /mode team 切换到 Team 模式后)输入:
收到以下集群异常:
[prod-api] Deployment api-server Pod CrashLoopBackOff (3/5 replicas)
[prod-api] HTTP 500 rate spike to 25%
[prod-gateway] response time P99 > 5s
[prod-db] MySQL connection pool exhausted
[monitor] node-03 CPU usage > 95%
特性总结
|-----------|-------------------------------|
| 能力 | K8s 场景应用 |
| Team 模式 | Leader 统一协调 Pod 诊断、日志分析、扩缩容建议 |
| Skill 技能 | 可安装的 K8s 运维分析技能,支持自演进优化 |
| Heartbeat | 定时巡检集群 Pod 健康状态 |
| Cron 定时 | 每日自动生成集群巡检报告 |
| Channel | 飞书/小艺等渠道接入,告警直达 Agent |
相关资源
- openJiuwen 官方网站:https://www.openjiuwen.com
- openJiuwen 代码仓库:https://atomgit.com/openJiuwen