目录
[一、单 Agent 的能力边界](#一、单 Agent 的能力边界)
[1.1 V1 架构的核心组件](#1.1 V1 架构的核心组件)
[1.2 V1 的运行模式](#1.2 V1 的运行模式)
[1.3 运行环境](#1.3 运行环境)
[1.4 单 Agent 的天花板](#1.4 单 Agent 的天花板)
[2.1 决策树](#2.1 决策树)
[2.2 简化为三个维度判断](#2.2 简化为三个维度判断)
[三、V2 架构总览](#三、V2 架构总览)
[3.1 V2 架构图](#3.1 V2 架构图)
[3.2 TeamManager:团队生命周期管理](#3.2 TeamManager:团队生命周期管理)
[3.3 技能继承机制](#3.3 技能继承机制)
[3.4 V2 典型角色设计](#3.4 V2 典型角色设计)
[3.5 并发管理与 LLM 调用](#3.5 并发管理与 LLM 调用)
[3.6 实时事件监控](#3.6 实时事件监控)
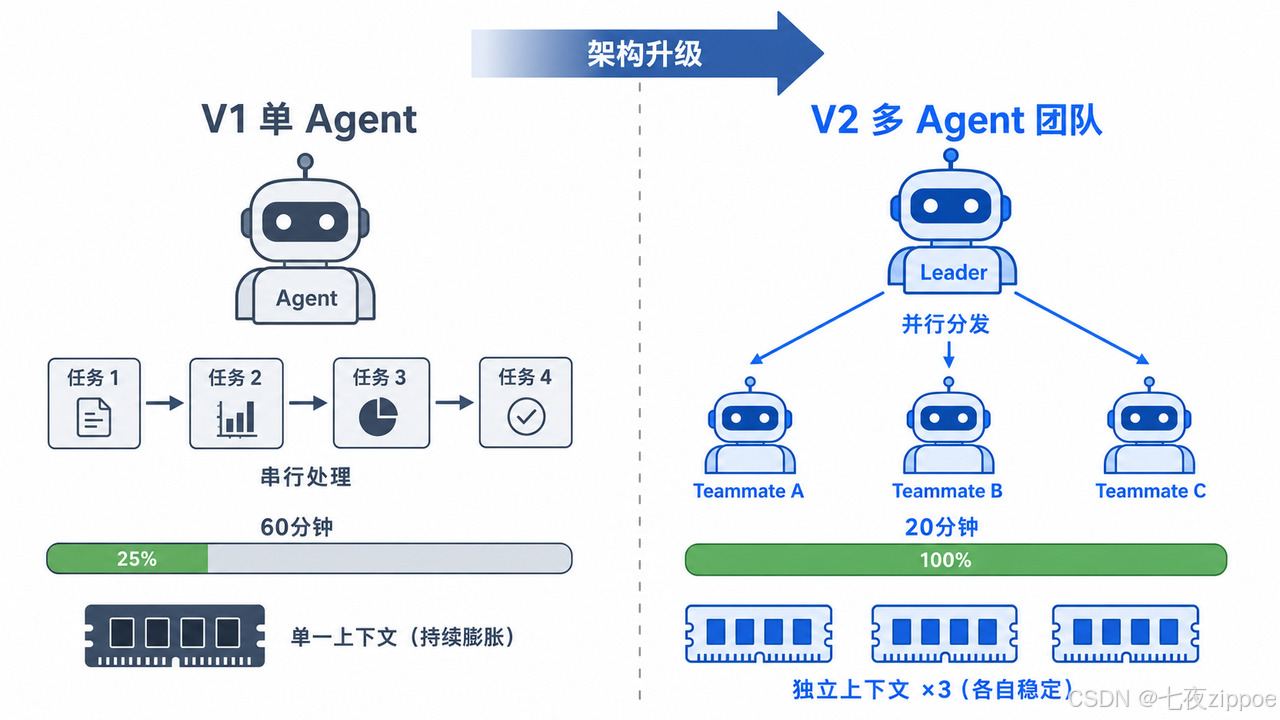
[3.7 架构演进图](#3.7 架构演进图)
[3.8 V1 vs V2 架构对比](#3.8 V1 vs V2 架构对比)
[4.1 前置条件](#4.1 前置条件)
[4.2 配置迁移步骤](#4.2 配置迁移步骤)
[4.3 模式切换确认](#4.3 模式切换确认)
[4.4 数据存储](#4.4 数据存储)
[4.5 迁移成本评估](#4.5 迁移成本评估)
[4.6 V1 → V2 迁移检查清单(20 项必查)](#4.6 V1 → V2 迁移检查清单(20 项必查))
[五、实操演示:V1 vs V2 效果对比](#五、实操演示:V1 vs V2 效果对比)
[5.1 场景说明](#5.1 场景说明)
[5.2 步骤一:启动服务](#5.2 步骤一:启动服务)
[5.2.1 下载exe安装包](#5.2.1 下载exe安装包)
[5.2.2 双击安装包exe文件进行安装](#5.2.2 双击安装包exe文件进行安装)
[5.2.3 双击图标启动客户端](#5.2.3 双击图标启动客户端)
[5.3 步骤二:V1 模式下的体验(对比基准)](#5.3 步骤二:V1 模式下的体验(对比基准))
[5.4 步骤三:切换到 V2 集群模式](#5.4 步骤三:切换到 V2 集群模式)
[5.5 步骤四:发送调研任务](#5.5 步骤四:发送调研任务)
[5.6 步骤五:观察团队运行](#5.6 步骤五:观察团队运行)
[5.7 步骤六:追加新方向](#5.7 步骤六:追加新方向)
[5.8 步骤七:查看结果](#5.8 步骤七:查看结果)
[5.9 效果对比](#5.9 效果对比)
当你用一个 Agent 完成日常对话和简单任务时,体验往往还不错。但任务复杂度一旦上来------多步骤串行、多领域交叉、实时协作------单 Agent 架构的天花板就会暴露得越来越明显。
本文基于 JiuwenSwarm 的真实架构,帮你建立一套清晰的升级决策框架:什么时候单 Agent 就够了,什么时候该切到多 Agent 团队模式,升级路径怎么走,以及怎么验证升级效果。全文提供决策树、架构对比、迁移检查清单和实操演示,不臆造。
一、单 Agent 的能力边界
先搞清楚一个问题:单 Agent 到底能扛到什么程度?
1.1 V1 架构的核心组件
JiuwenSwarm 基于 openJiuwen 框架构建,通过适配器模式(AgentAdapter)将底层能力统一封装。入口类是 JiuWenSwarm(位于 jiuwenswarm/server/runtime/agent_adapter/interface.py),它在首次请求时通过 _ensure_adapter() 懒初始化适配器实例,后续请求复用同一实例。
V1 是单 智能体 架构,所有任务由一个 Agent 串行处理。核心组件分工如下:
|----------------|------------------------|----------------------------------------------------------------------------------------------|
| 组件 | 职责 | 源码位置 |
| JiuwenSwarm | 主协调器,懒初始化适配器、分发请求 | server/runtime/agent_adapter/interface.py |
| AgentAdapter | 适配器层,封装底层 DeepAgent 能力 | server/runtime/agent_adapter/ |
| SkillManager | 技能生命周期管理(安装、卸载、市场) | server/runtime/agent_adapter/interface.py 内嵌 |
| SessionManager | 会话管理与并发控制 | server/runtime/agent_adapter/interface.py 内嵌 |
| MessageHandler | 消息路由,Channel 级别模式控制 | gateway/message_handler/message_handler.py |
来看看 JiuWenSwarm 的初始化逻辑,理解 V1 的运行时结构:
class JiuWenSwarm:
def __init__(self) -> None:
self._adapter: AgentAdapter | None = None
self._sdk_name: str | None = None
self._skill_manager = SkillManager(workspace_dir=str(get_agent_workspace_dir()))
self._session_manager = SessionManager()一个 _adapter 就是一个 Agent 适配器。它在首次请求时通过 _ensure_adapter() 懒初始化:
def _ensure_adapter(self, *, mode: str = "agent") -> AgentAdapter:
if self._adapter is None:
self._sdk_name = resolve_sdk_choice()
self._adapter = create_adapter(self._sdk_name, mode=mode)
if hasattr(self._adapter, "set_skill_manager"):
self._adapter.set_skill_manager(self._skill_manager)
return self._adapter所有会话共享这一个适配器实例,通过 SessionManager 做会话隔离。这就意味着,同一时刻只能处理一个请求链路。
1.2 V1 的运行模式
当前系统通过 Mode 枚举定义了多种运行模式,用户可以在聊天界面直接切换:
class Mode(Enum):
AGENT_PLAN = "agent.plan" # 规划模式:任务拆解 + 动态插入
AGENT_FAST = "agent.fast" # 智能执行:经典 ReAct,适合日常对话
CODE_PLAN = "code.plan" # 代码规划模式
CODE_NORMAL = "code.normal" # 代码普通模式
CODE_TEAM = "code.team" # 代码团队模式
TEAM = "team" # 集群模式:多 Agent 团队协作对于日常使用,最核心的两个模式是 agent.plan(规划模式)和 agent.fast(智能执行)。模式从用户到 Agent 的数据流很清晰:前端通过 WebSocket 传递 params.mode 字段,MessageHandler._apply_channel_state() 将当前 Channel 的模式状态注入消息参数:
def _apply_channel_state(self, msg: "Message") -> None:
"""将当前 Channel 的控制状态应用到消息上(session_id / mode)."""
channel_type = self._resolve_control_channel_type(msg)
if channel_type not in self._control_channel_types:
return
state = self._get_or_create_channel_state(msg)
# ... 会话 ID 解析 ...
if msg.params is None:
msg.params = {}
if isinstance(msg.params, dict):
msg.params.setdefault("mode", state.mode.value)对于非 Web Channel(飞书、小艺等),用户可以通过 /mode agent.plan、/mode agent.fast、/mode team 等命令切换模式。
1.3 运行环境
|----------|------------------------------------------------------------------|
| 项目 | 配置值 |
| 操作系统 | Windows 10 / macOS / Linux |
| Python | 3.11 / 3.12 / 3.13 |
| 模型服务 | 华为云 MaaS / OpenAI 兼容接口 / ModelScope 等 |
| 通信渠道 | Web / 飞书 / 钉钉 / 企业微信 / 小艺 / Telegram / Discord / WhatsApp / 个人微信 |
| Agent 框架 | openJiuwen(内置) |
1.4 单 Agent 的天花板
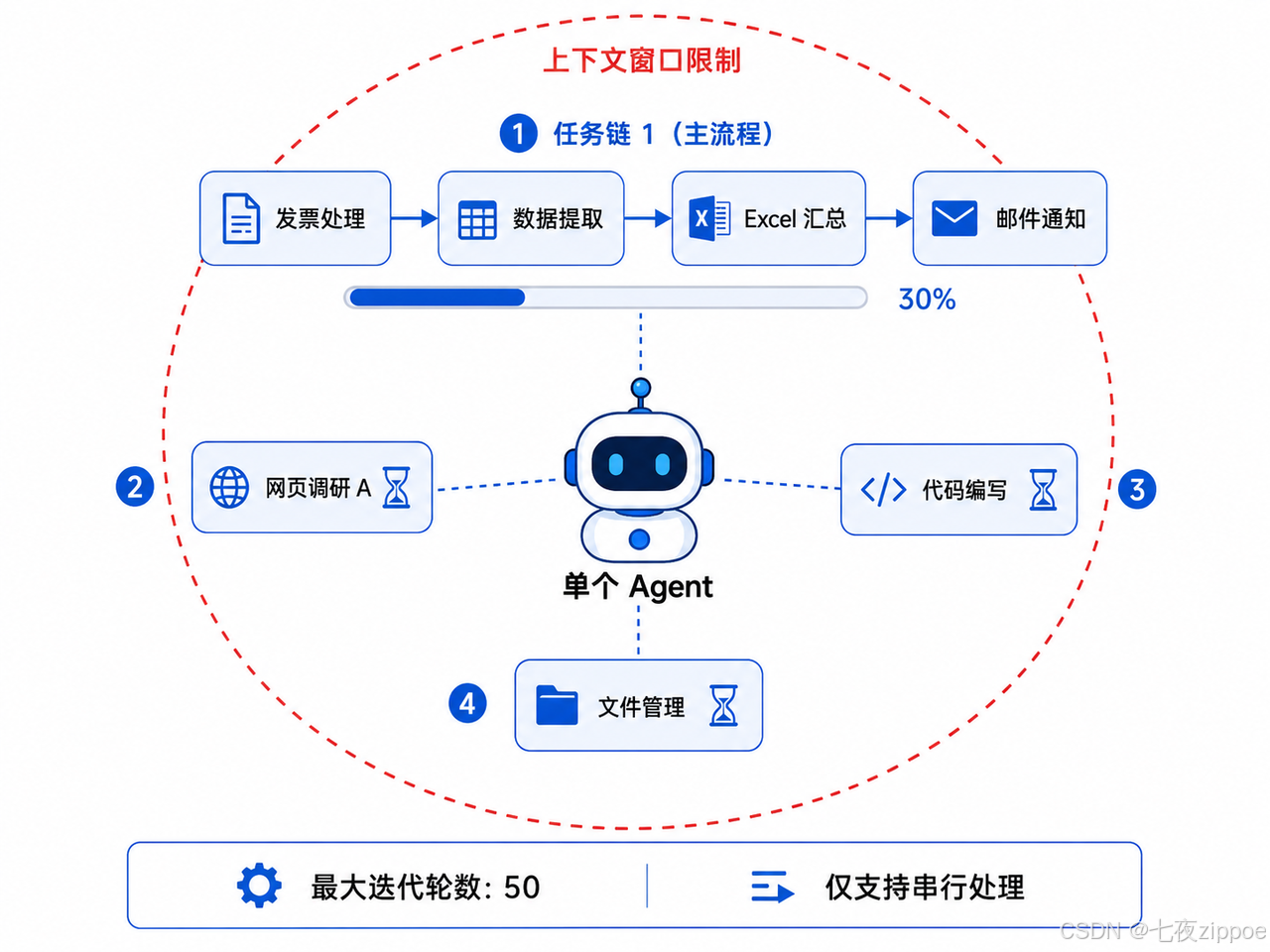
这套架构在日常问答、单领域工具调用、结构化的线性任务上表现良好。
但当任务出现以下特征时,瓶颈就会显现:
-
长链条串行任务 :比如"整理本月发票 → 提取关键信息 → 汇总 Excel → 发邮件通知"。中间任何一步出错,后续流程可能中断。最大迭代轮数(
react.max_iterations默认 50)也会限制超长任务的完成率。 -
多领域复合任务:一个 Agent 同时操作浏览器、编写代码、管理文件时,上下文膨胀和注意力分散几乎不可避免。
-
并发需求:三个独立的调研方向需要同时展开,单 Agent 只能排队处理。
-
上下文膨胀:随着信息累积,LLM 的有效注意力会被稀释,后期任务质量下降。
说白了,单个 Agent 的"注意力"、"专业度"、"并发能力"都有明确的天花板。到了这个点,就需要考虑架构升级了。
二、升级决策树
不是所有场景都需要多 Agent。以下决策树帮你判断。
2.1 决策树
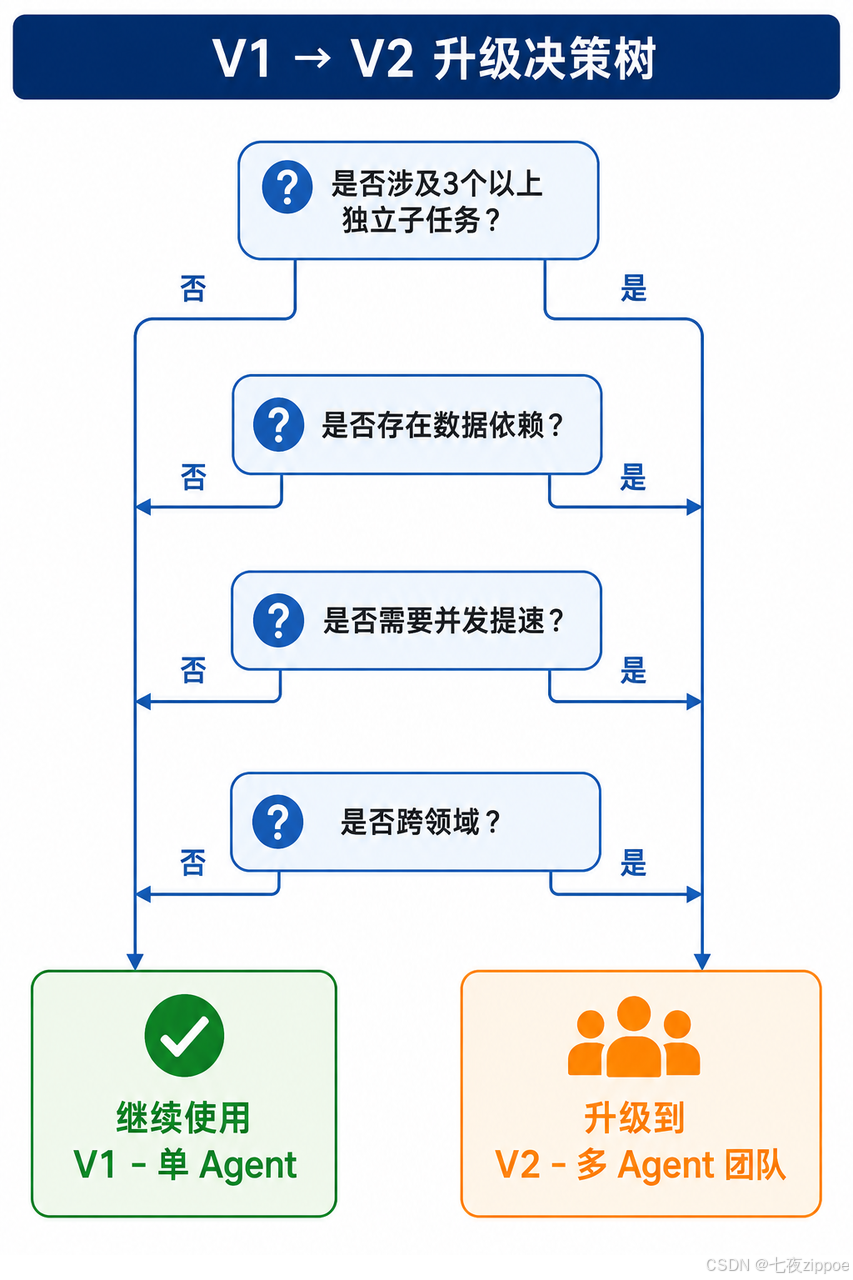
2.2 简化为三个维度判断
如果你不想走决策树,从任务复杂度、响应时间、用户满意度三个维度快速判断是否需要升级:
|-------|----------------------|--------------------|
| 维度 | 判断标准 | 升级信号 |
| 任务复杂度 | 涉及 3 个以上独立子任务、跨领域操作 | 单 Agent 串行处理效率急剧下降 |
| 响应时间 | 单任务串行耗时超过 30 分钟 | 并发可显著提速,用户等待体验差 |
| 用户满意度 | 上下文膨胀导致后期质量下降、无法追加需求 | 单一注意力被稀释,交互灵活性不足 |
三个维度中出现两个或以上亮红灯,就应该认真考虑升级了。
三、V2 架构总览
确定要升级后,先理解 V2 的架构设计。
JiuwenSwarm 的做法是让 Agent 组队。通过内置的 Swarm Agent 机制,一个 Leader Agent 可以动态创建多个 Teammate Agent,各司其职、协同完成复杂任务。这套机制与 JiuwenSwarm 已有的技能自演进、记忆系统、任务规划等能力是打通的,不是孤立的模块。
3.1 V2 架构图
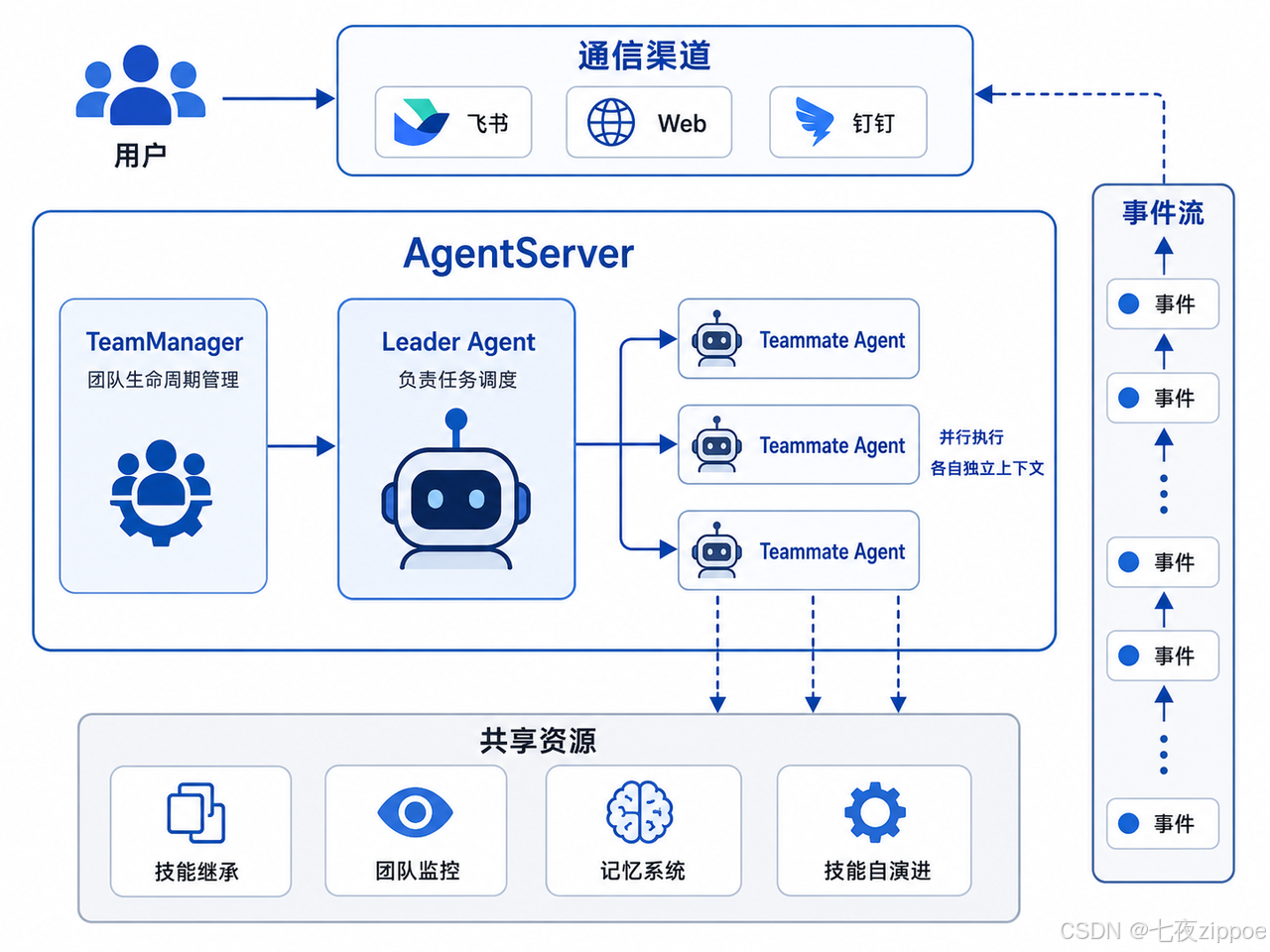
核心组件分工:
|------------------------|----------------------------|---------------------------------------------------------------------------------------------------------------------|
| 组件 | 职责 | 源码位置 |
| TeamManager | 团队生命周期管理(创建/销毁/会话隔离) | agents/harness/team/team_manager.py |
| ConfigLoader | 从 config.yaml 加载团队配置并构建规格 | agents/harness/team/config_loader.py |
| TeamAgentSpec | 团队规格定义(角色/技能/生命周期) | openjiuwen agent_teams.schema |
| TeamAgent | 运行时团队实例(Leader + Teammate) | openjiuwen agent_teams.agent |
| TeamMonitorHandler | 实时事件监控(成员/任务/消息) | agents/harness/team/monitor_handler.py |
| TeamRuntimeInheritance | 技能继承与能力卡复制 | agents/harness/team/team_runtime_inheritance.py |
| team_helpers | 流式协作(多请求并发/事件广播) | server/runtime/agent_adapter/team_helpers.py |
3.2 TeamManager:团队生命周期管理
TeamManager 是 V2 的核心调度器。它的数据结构以 session_id 为键,管理团队实例、监控器和后台流式任务,同时维护技能演进和会话状态:
class TeamManager:
def __init__(self):
self._team_agents: dict[str, TeamAgent] = {} # session_id → TeamAgent
self._team_monitors: dict[str, TeamMonitorHandler] = {} # session_id → monitor
self._stream_tasks: dict[str, asyncio.Task] = {} # session_id → asyncio.Task
self._lock = asyncio.Lock()
self._active_session_id: str | None = None
self._active_team_name: str | None = None
self._team_skill_rails: dict[str, Any] = {} # 技能演进 Rail
self._team_evolution_watchers: dict[str, asyncio.Task] = {} # 演进监控对外暴露的核心方法是 get_or_create_team(),实现了懒加载复用------已有 Team 就复用,没有就新建:
async def get_or_create_team(self, session_id, deep_agent, ...) -> TeamAgent:
async with self._lock:
team_agent = self._team_agents.get(session_id)
if team_agent is not None:
return team_agent
await self._destroy_other_sessions(session_id)
return await self.create_team(session_id, deep_agent, ...)值得注意的是,每个 Channel(飞书、Web、钉钉等)拥有独立的 TeamManager 实例,通过全局注册表获取:
_team_managers: dict[str, TeamManager] = {}
def get_team_manager(channel_id: str | None = None) -> TeamManager:
resolved_channel_id = str(channel_id or "default").strip() or "default"
manager = _team_managers.get(resolved_channel_id)
if manager is None:
manager = TeamManager()
_team_managers[resolved_channel_id] = manager
return manager这是 commit 1380032 中引入的改进,解决了多 Channel 同时使用 Team 模式时的冲突问题。
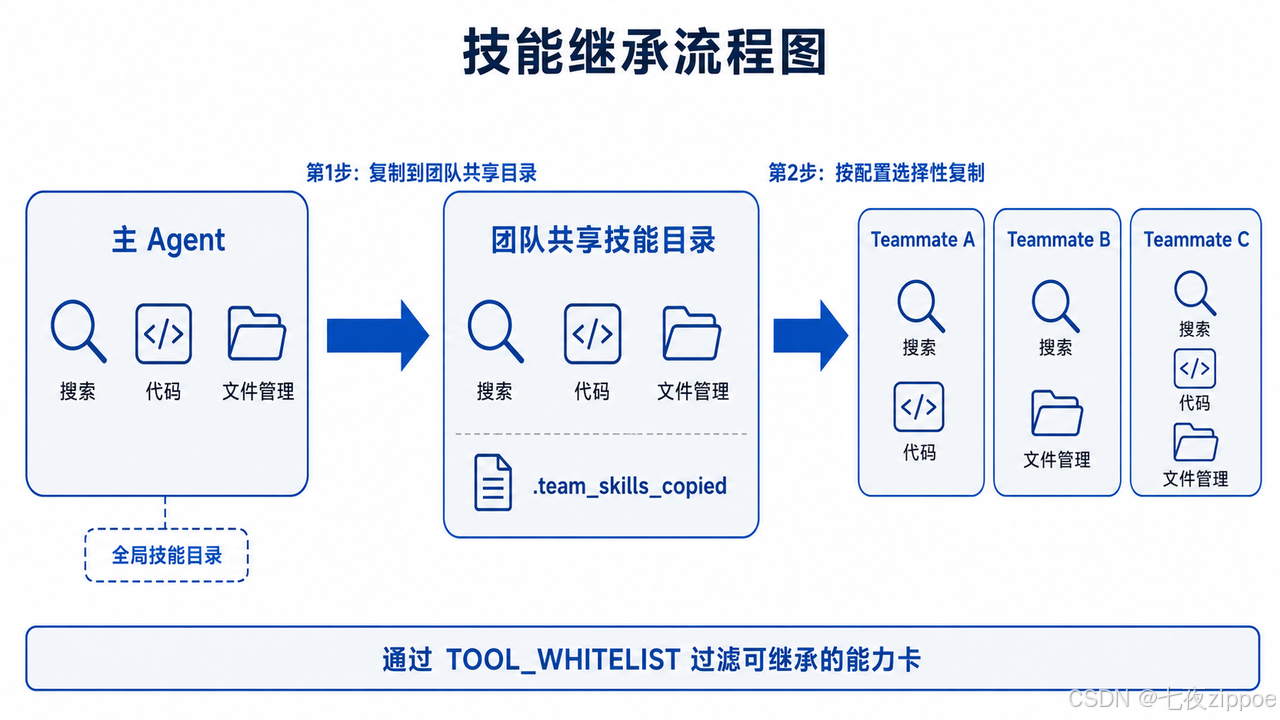
3.3 技能继承机制
这是 V2 设计中比较精巧的部分。新 Teammate 创建时不是从零开始,而是通过 TeamRuntimeInheritance 和 TeamManager.build_agent_customizer() 自动继承主 Agent 的技能和工具。
继承分两步走:先将全局技能复制到团队共享目录,再按成员配置选择性复制到个人目录。以下是 TeamManager.build_agent_customizer() 中的核心逻辑:
def copy_member_configured_skills(
member_skills_dir: Path,
selected_skills: list[str],
) -> None:
selected_skill_set = set(selected_skills)
member_skills_dir.mkdir(parents=True, exist_ok=True)
for skill_dir in global_skills_dir.iterdir():
if not skill_dir.is_dir() or not (skill_dir / "SKILL.md").is_file():
continue
if skill_dir.name not in selected_skill_set:
continue
dest = member_skills_dir / skill_dir.name
if not dest.exists():
shutil.copytree(skill_dir, dest)能力卡的继承也是自动的。主 Agent 的工具能力卡中标记为可继承的(通过白名单过滤),会被添加到新成员:
TOOL_WHITELIST = frozenset({
"free_search", "fetch_webpage", "paid_search", "vision",
"audio", "image_ocr", "visual_question_answering",
"generate_image", "audio_transcription",
"search_skill", "install_skill", "uninstall_skill",
"task_tool", "user_todos",
"create_note", "search_notes", "modify_note",
"search_file", "upload_file",
# ... 更多工具
})
def filter_inheritable_ability_cards(main_agent: Any) -> list[ToolCard]:
result = []
try:
abilities = main_agent.ability_manager.list()
for ability in abilities:
if isinstance(ability, ToolCard):
if ability.name in TOOL_WHITELIST:
result.append(ability)
except Exception as exc:
logger.warning("[TeamRuntime] Failed to filter inheritable abilities: %s", exc)
return result白名单从早期的 9 项扩展到了 30+ 项,覆盖搜索、视觉、音频、技能管理、笔记、文件等工具类别。实际效果是:给主 Agent 安装了"网页搜索""技能管理"等技能后,新创建的 Teammate 会自动拥有这些能力,不需要逐个配置。
3.4 V2 典型角色设计
以客服场景为例,V2 架构的典型角色分工:
|------------------|---------------------|----------------------|
| 角色 | 职责 | 说明 |
| Leader(编排) | 接收用户请求,任务拆解与分发,汇总结果 | 相当于项目经理,不做具体执行 |
| Teammate-A(查询) | 订单查询、物流追踪、账户信息检索 | 专注查询类任务,技能限定为搜索和数据访问 |
| Teammate-B(工单处理) | 退款、投诉、售后工单创建与流转 | 专注写入类任务,技能限定为工单系统操作 |
当用户提出"帮我查一下订单 12345 的物流,然后申请退款"时:Leader 将请求拆分为查询物流、处理退款两个子任务,Teammate-A 和 Teammate-B 分别并行执行,Leader 汇总结果返回给用户。
3.5 并发管理与 LLM 调用
多 Agent 同时调用 LLM API 时,并发控制由底层 openjiuwen 框架和模型服务提供商共同保障。TeamManager 通过 asyncio.Lock 管理团队创建/销毁的并发安全,确保同一 Channel 下不会出现两个 Team 同时创建的竞态条件:
async def get_or_create_team(self, session_id, deep_agent, ...) -> TeamAgent:
async with self._lock:
team_agent = self._team_agents.get(session_id)
if team_agent is not None:
return team_agent
await self._destroy_other_sessions(session_id)
return await self.create_team(session_id, deep_agent, ...)LLM API 层面的 429 限流处理由 openjiuwen SDK 内部机制管理。如果模型服务商有并发限制,建议在部署时根据配额合理控制 Teammate 数量。
3.6 实时事件监控
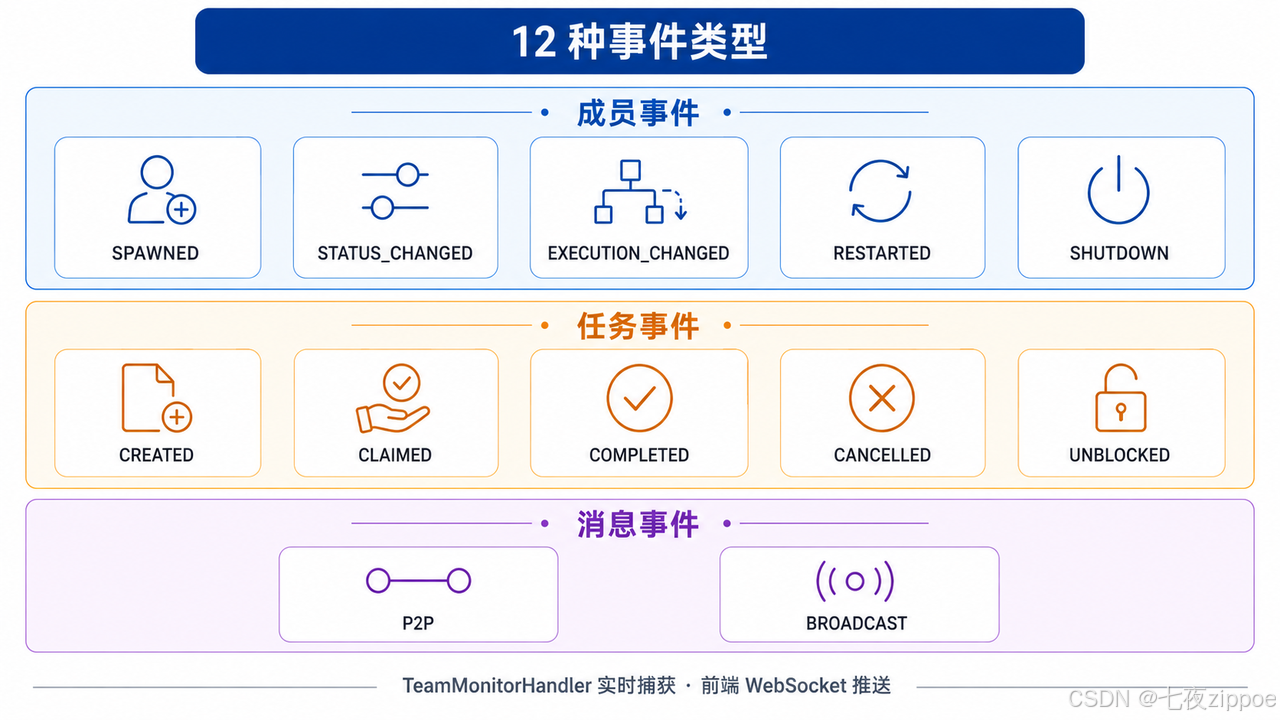
V2 通过 TeamMonitorHandler 实现了实时事件监控,定义了 12 种事件类型:
3.7 架构演进图
V1: [单Agent] ──→ V2: [Leader + 2个Teammate]
│ │
单线程 并行处理
单技能 专业分工
单模型 按需分配3.8 V1 vs V2 架构对比
|-------|------------------|---------------------------|
| 维度 | V1(单 Agent) | V2(多 Agent 团队) |
| 执行模式 | 串行 ReAct 循环 | Leader 调度 + Teammate 并行执行 |
| 上下文管理 | 单一上下文,随任务累积膨胀 | 每个 Teammate 独立上下文,质量稳定 |
| 工具注册 | 全量注册到单个 Agent | 按角色选择性继承或全量继承 |
| 任务监控 | TodoToolkit 状态追踪 | 12 种事件类型覆盖全生命周期 |
| 追加交互 | 排队等待当前任务完成 | 立即创建新 Teammate 处理 |
| 模型消耗 | 单路 LLM 调用 | 多路并发调用 |
| 配置复杂度 | react: 段即可 | 需额外 team: 段 |
四、迁移检查清单
确定要升级到 V2 后,按以下清单逐项操作。
4.1 前置条件
|----------------|------------------------------------------|-------------------------------------|
| 检查项 | 要求 | 验证方式 |
| Python 版本 | 3.11 / 3.12 / 3.13 | python --version |
| JiuwenSwarm 版本 | 确认已安装最新版本 | pip show jiuwenswarm |
| 模型 API 配额 | 多 Agent 并发会增大调用量,确认配额充足 | 查看 API 服务商控制台 |
| team 模块 | 确认 jiuwenswarm/agents/harness/team/ 目录存在 | ls jiuwenswarm/agents/harness/team/ |
4.2 配置迁移步骤
第一步:保留现有 V1 配置不动
V1 的 react: 配置段不需要任何修改,V2 是在其基础上新增配置。这是关键设计------V1 和 V2 共存,不是替代:
# V1 配置保持不变
react:
agent_name: main_agent
max_iterations: 50
model_name: ${MODEL_NAME:-glm-4.7}
model_client_config:
client_provider: OpenAI
api_base: ${MODEL_API_BASE:-https://open.bigmodel.cn/api/paas/v4}
api_key: ${MODEL_API_KEY}
verify_ssl: false第二步:添加 team 配置段
最小可用配置,只需 4 行:
team:
team_name: "my_team"
lifecycle: "persistent"
teammate_mode: "build_mode"
spawn_mode: "inprocess"进阶配置(含自定义 Leader、技能选择、预定义成员):
team:
team_name: "project_team"
lifecycle: "persistent"
teammate_mode: "build_mode"
spawn_mode: "inprocess"
leader:
member_name: "project_manager"
display_name: "项目经理"
persona: "擅长任务分解和项目管理的专家"
agents:
leader:
skills: ["openJiuwen-DeepSearch", "advanced-daily-report"]
teammate: {} # Teammate 继承全部技能
predefined_members:
- member_name: "data_analyst"
display_name: "数据分析师"
persona: "擅长数据清洗、统计分析和可视化"
- member_name: "doc_writer"
display_name: "文档编写员"
persona: "擅长技术文档、报告和公文撰写"关键配置项说明:
|------------------------|---------------|------------|--------------------------------------------|
| 配置项 | 说明 | 默认值 | 建议 |
| team.lifecycle | 团队生命周期模式 | persistent | 保持默认,团队实例跨会话复用 |
| team.teammate_mode | Teammate 构建模式 | build_mode | 任务不固定用 build_mode,固定流程用 predefined_members |
| team.spawn_mode | 进程模式 | inprocess | 初期用 inprocess,后期可切 pyzmq 做分布式 |
| agents.leader.skills | Leader 技能列表 | 继承全部 | 建议限定核心技能,减少上下文噪音 |
| agents.teammate.skills | Teammate 技能列表 | 继承全部 | 根据角色按需配置 |
第三步:验证配置生效
客户端启动后,AgentServer 会自动检测 team 配置段。存在则启用 Swarm Agent 模式,不存在则以 V1 模式运行。完全向后兼容。
4.3 模式切换确认
V2 启用后,前端模式按钮组会增加第三个选项:
|----------|---------------|------------|-----------------|
| 按钮 | 模式 | 标识 | 说明 |
| 📋(规划模式) | V1 - 任务规划 | agent.plan | 主动记忆 + 任务规划 |
| ⚙️(智能执行) | V1 - 经典 ReAct | agent.fast | 基础 Agent,适合日常对话 |
| 👥(集群模式) | V2 - 团队协作 | team | 多 Agent 团队协作 |
4.4 数据存储
团队运行时数据默认存储在 ~/.jiuwenswarm/agent/team.db(SQLite)。分布式模式下推荐 PostgreSQL:
team:
storage:
type: "postgresql"
params:
connection_string: "postgresql+asyncpg://user:pass@127.0.0.1:5432/team_db"4.5 迁移成本评估
|-------|---------------------------------------------------------------------|-------|
| 成本维度 | 具体内容 | 评估 |
| 代码改动量 | 零代码改动,纯配置升级。V1 配置完全保留,V2 通过新增 team: 配置段启用 | 低 |
| 配置复杂度 | 最小配置仅需 4 行 YAML(team_name / lifecycle / teammate_mode / spawn_mode) | 低 |
| 运维成本 | 需关注多 Agent 并发导致的 LLM API 调用量增长、团队运行时状态监控 | 中 |
| 学习成本 | 需理解 Leader/Teammate 角色分工、技能继承机制、12 种事件类型 | 中 |
| 资源消耗 | 多 Agent 并发占用更多内存和 API 配额,需根据实际配额合理控制 Teammate 数量 | 视规模而定 |
| 回退风险 | V1 和 V2 共存设计,删除 team: 配置段即可回退到 V1 | 无风险 |
结论: 迁移成本整体偏低,核心原因是配置驱动而非代码驱动。主要增量成本在于 API 调用量和运维监控。
4.6 V1 → V2 迁移检查清单(20 项必查)
环境与依赖(5 项):
|---|----------------|------------------------------------------|-------------------------------------|
| # | 检查项 | 要求 | 验证方式 |
| 1 | Python 版本 | 3.11 / 3.12 / 3.13 | python --version |
| 2 | JiuwenSwarm 版本 | 确认已安装最新版本 | pip show jiuwenswarm |
| 3 | team 模块 | 确认 jiuwenswarm/agents/harness/team/ 目录存在 | ls jiuwenswarm/agents/harness/team/ |
| 4 | 模型 API 配额 | 多 Agent 并发会增大调用量,确认配额充足 | 查看 API 服务商控制台 |
| 5 | 系统资源 | 系统资源满足多进程并发需求(内存、磁盘充足) | 系统监控工具 |
配置迁移(5 项):
|----|-------------|-------------------------------|-----------------------|
| # | 检查项 | 要求 | 验证方式 |
| 6 | V1 配置完整性 | react: 配置段正常工作 | 发送测试消息确认 V1 响应正常 |
| 7 | team 配置段添加 | 最小配置 4 行 YAML 已写入 config.yaml | 检查 config/config.yaml |
| 8 | 环境变量 | MODEL_API_KEY 等环境变量已配置 | echo $MODEL_API_KEY |
| 9 | Leader 角色定义 | persona 和 skills 已配置(可选) | 检查 team.leader 配置 |
| 10 | 数据存储配置 | SQLite 或 PostgreSQL 连接配置正确 | 启动后检查 team.db 是否创建 |
功能验证(5 项):
|----|-------------|--------------------------|-------------------------------------|
| # | 检查项 | 要求 | 验证方式 |
| 11 | 模式切换 | 前端三个模式按钮均可点击切换 | 依次切换 agent.plan / agent.fast / team |
| 12 | 团队创建 | Leader Agent 能正常创建并显示在面板 | 发送消息后检查团队成员面板 |
| 13 | Teammate 创建 | Leader 能动态创建 Teammate | 发送多子任务请求,观察成员列表更新 |
| 14 | 技能继承 | Teammate 自动继承主 Agent 的技能 | 检查 Teammate 是否能使用搜索等继承技能 |
| 15 | 事件监控 | 12 种事件类型能正常触发和显示 | 查看任务事件面板 |
稳定性与回退(5 项):
|----|------|----------------------------|------------------------|
| # | 检查项 | 要求 | 验证方式 |
| 16 | 追加交互 | 运行中能追加新需求而不中断已有任务 | 调研过程中追加新方向 |
| 17 | 会话隔离 | 不同 Channel 的团队实例互不干扰 | 多 Channel 同时使用 team 模式 |
| 18 | 错误恢复 | Teammate 出错不影响其他成员和 Leader | 模拟一个 Teammate 异常 |
| 19 | 资源释放 | 任务完成后 Teammate 正确关闭,资源释放 | 观察成员状态变为灰色已关闭 |
| 20 | 回退验证 | 删除 team: 配置段后能正常回退到 V1 | 删除配置,重启服务,确认 V1 正常 |
五、实操演示:V1 vs V2 效果对比
用一个实际场景走一遍完整流程,直观对比 V1 和 V2 的差异。
5.1 场景说明
用户要求对 AI Agent 的多个方向同时展开深度调研:
帮我全面调研一下 AI Agent 的最新进展,我需要了解三个方向:1)主流 Agent 框架的设计对比(LangGraph vs CrewAI vs AutoGen);2)Agent 通信协议的现状(MCP、A2A、ACP);3)Agent 在企业场景中的落地案例。每个方向生成一份独立的 Markdown 报告,保存到工作目录。
这个场景完美命中升级决策树的三个信号:3 个独立子任务、跨领域(技术对比 + 协议分析 + 案例调研)、需要并发提速。
5.2 步骤一:启动服务
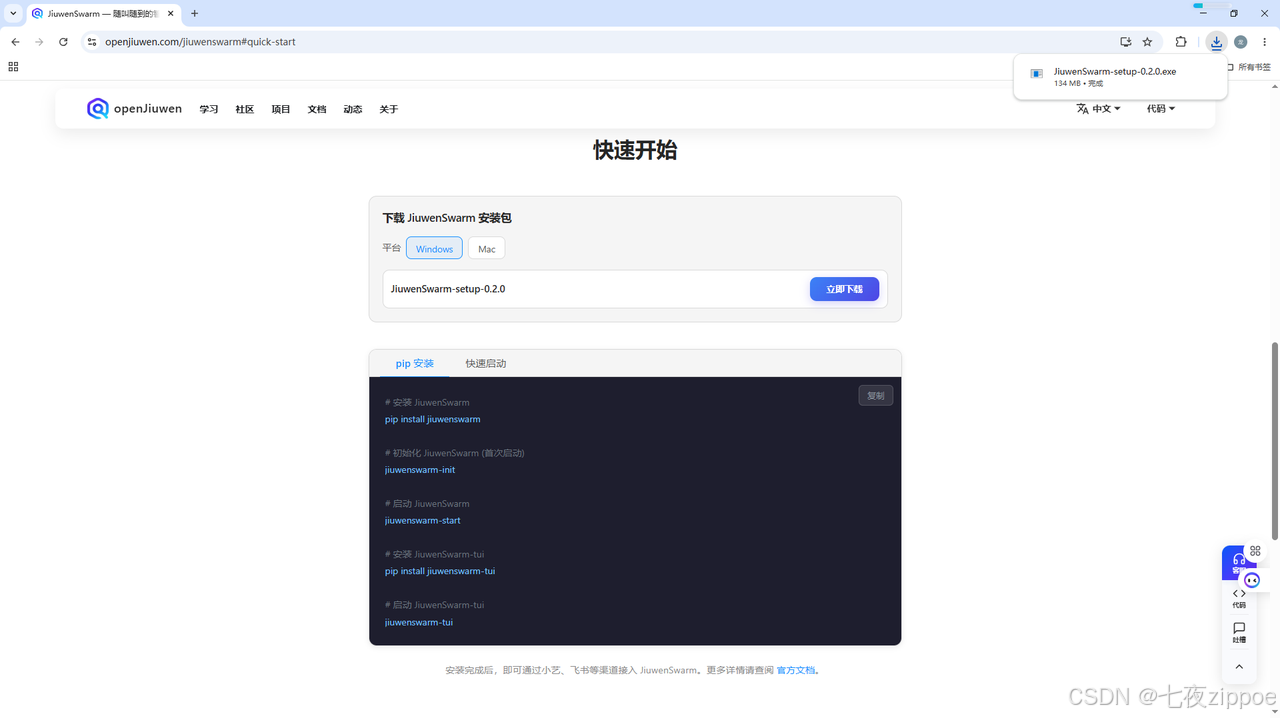
5.2.1 下载exe安装包
访问https://openjiuwen.com/jiuwenswarm#quick-start,根据电脑系统选择下载相应的安装包,我这里选择的是windows 。点击立即下载按钮,完成下载。
5.2.2 双击安装包exe文件进行安装
在安装弹框中选择要安装的文件路径,点击next按钮。
再次点击next按钮。
点击install按钮。
安装完成。
5.2.3 双击图标启动客户端
图示:启动JiuwenSwarm客户端
图示:JiuwenSwarm的客户端界面
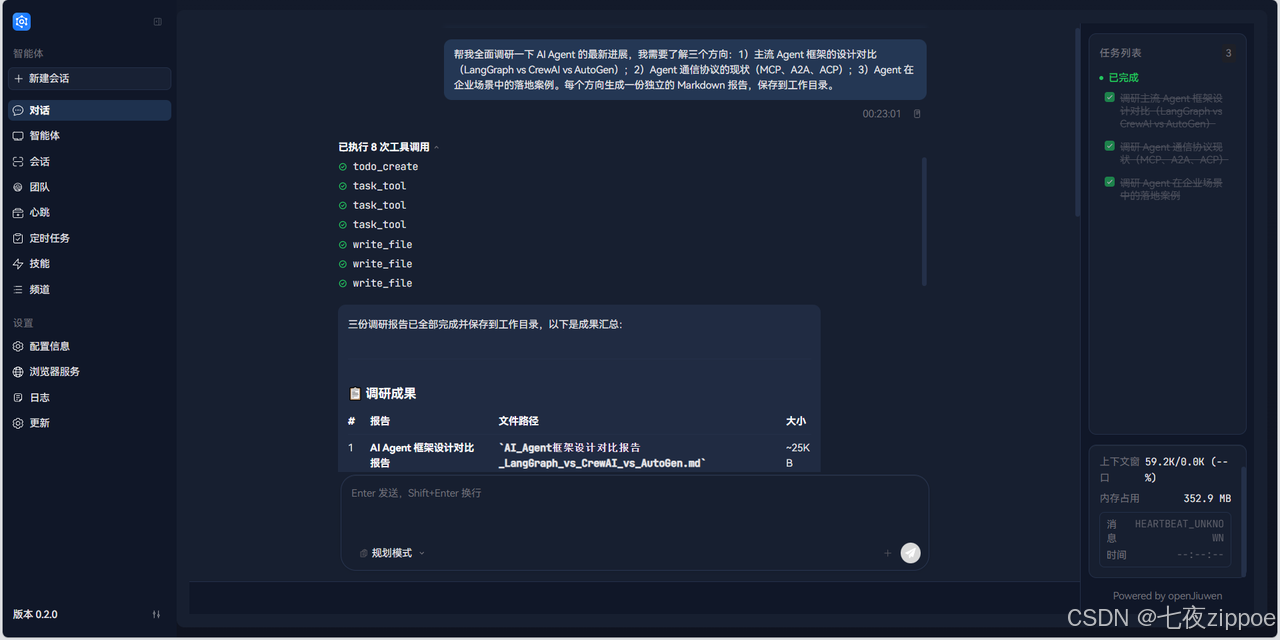
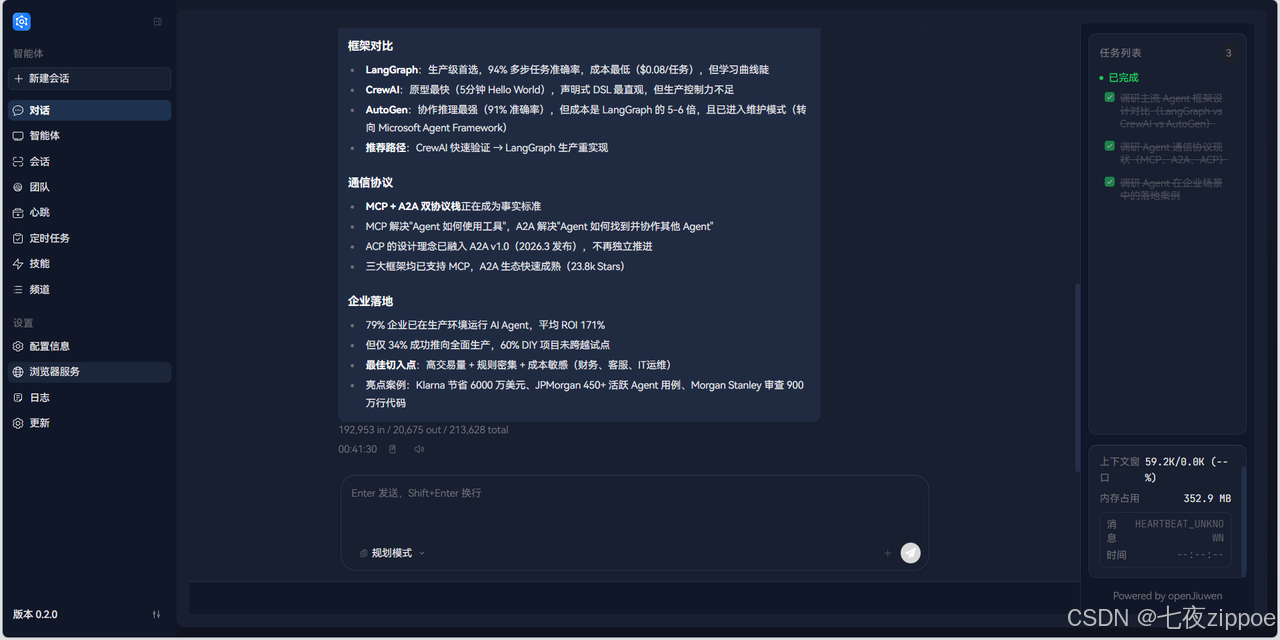
5.3 步骤二:V1 模式下的体验(对比基准)
先在规划模式(V1)下执行同样的任务。
帮我全面调研一下 AI Agent 的最新进展,我需要了解三个方向:
1)主流 Agent 框架的设计对比(LangGraph vs CrewAI vs AutoGen)
2)Agent 通信协议的现状(MCP、A2A、ACP)
3)Agent 在企业场景中的落地案例
每个方向生成一份独立的 Markdown 报告,保存到工作目录。-
Agent 先创建任务列表,依次标记为
running→completed -
第一个方向处理完后才开始第二个,总耗时约 45-60 分钟
-
随着信息累积,后期任务的质量可能因上下文膨胀而下降
-
如果中途追加新需求,需要排队等待当前任务完成
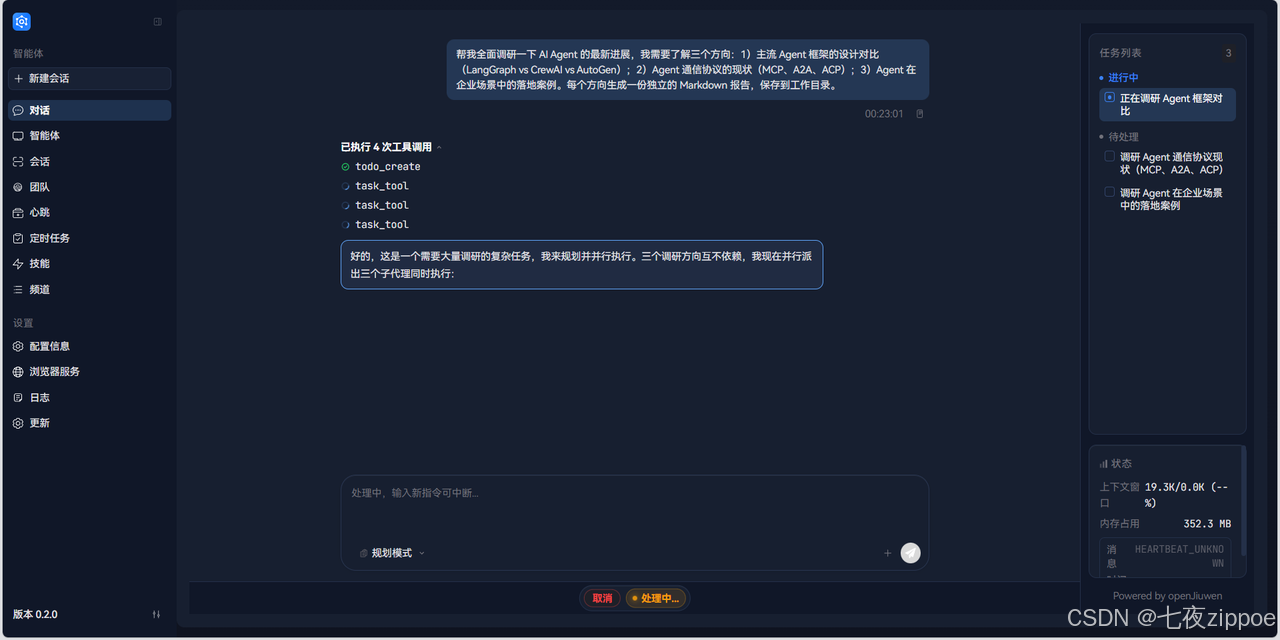
5.4 步骤三:切换到 V2 集群模式
在聊天输入框底部的工具栏中,找到左侧的模式切换按钮组(三个并排按钮),点击最右侧的"集群模式"按钮(👥 图标)。
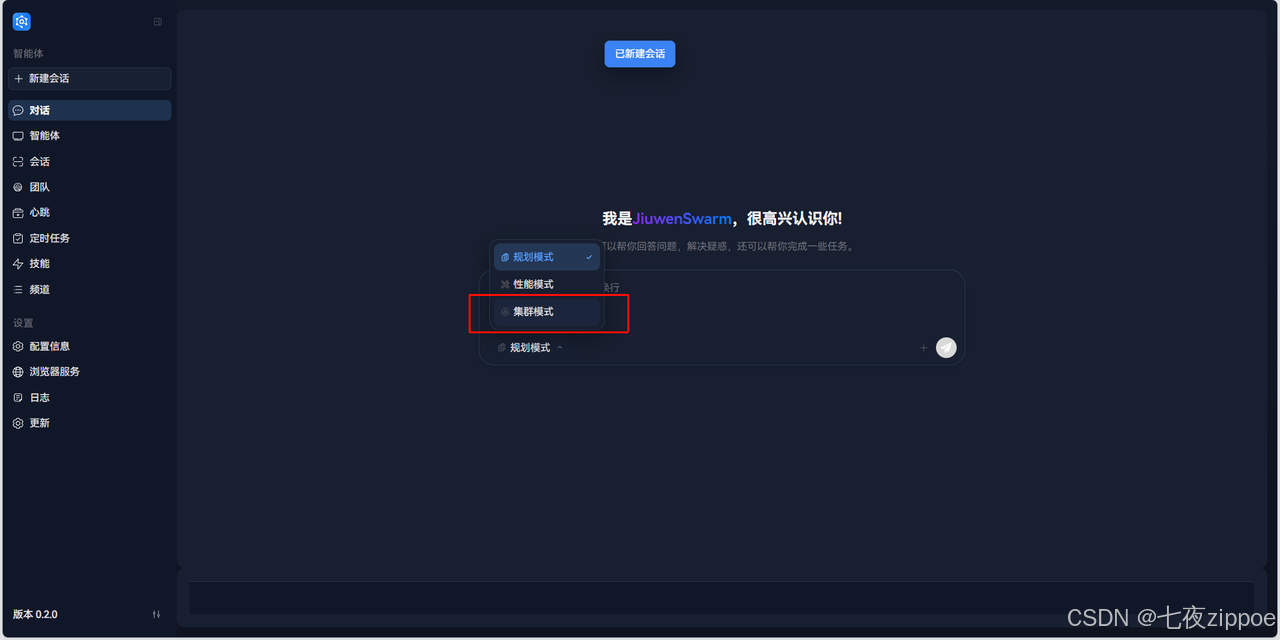
如果当前会话有历史消息,会弹出确认弹窗提示"切换模式将创建新会话",点击确认即可。
5.5 步骤四:发送调研任务
在集群模式下发送同样的调研指令:
帮我全面调研一下 AI Agent 的最新进展,我需要了解三个方向:
1)主流 Agent 框架的设计对比(LangGraph vs CrewAI vs AutoGen)
2)Agent 通信协议的现状(MCP、A2A、ACP)
3)Agent 在企业场景中的落地案例
每个方向生成一份独立的 Markdown 报告,保存到工作目录。消息发送后,系统进入 Swarm Agent 模式。代码层面,process_team_message_stream() 判断这是首次请求,自动创建团队并启动监控:
async def process_team_message_stream(
request: Any, inputs: dict[str, Any], deep_agent: DeepAgent,
) -> AsyncIterator[AgentResponseChunk]:
# 判断是否首次请求
is_first_request = not team_manager.has_stream_task(session_id)
if is_first_request:
# 构建团队规格并创建团队
team_spec = await team_manager.get_enriched_team_spec(...)
# 启动流式消费任务
stream_task = asyncio.create_task(
_consume_stream_with_query(channel_id, session_id, team_agent, query)
)
team_manager.register_stream_task(session_id, stream_task)
else:
# 追加交互:直接注入消息到运行中的团队
await team_manager.interact(session_id, query)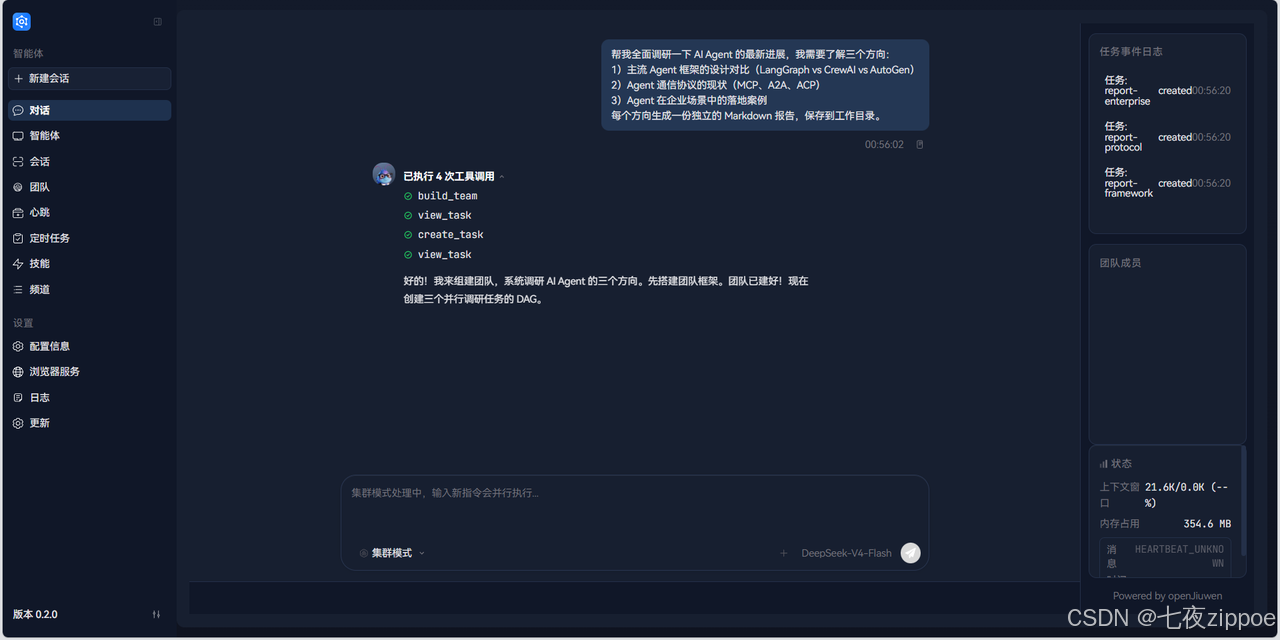
5.6 步骤五:观察团队运行
在聊天区域右侧会显示团队面板,包含两个区域:
团队成员面板显示所有成员及其状态:

-
🟢 绿色:就绪
-
🟡 黄色:忙碌
-
🔵 蓝色:重启中
-
🟠 橙色:关闭请求中
-
⚪ 灰色:已关闭
-
🔴 红色:错误
任务事件面板显示实时事件日志,可以看到任务被创建 → 被成员认领 → 完成的完整生命周期。
初始状态可以看到 Leader(team_leader)被创建。随后 Leader 分析任务,动态创建 3 个 Teammate,成员列表实时更新。Leader 会实时监控成员运行状态,给出提醒并汇报进度。
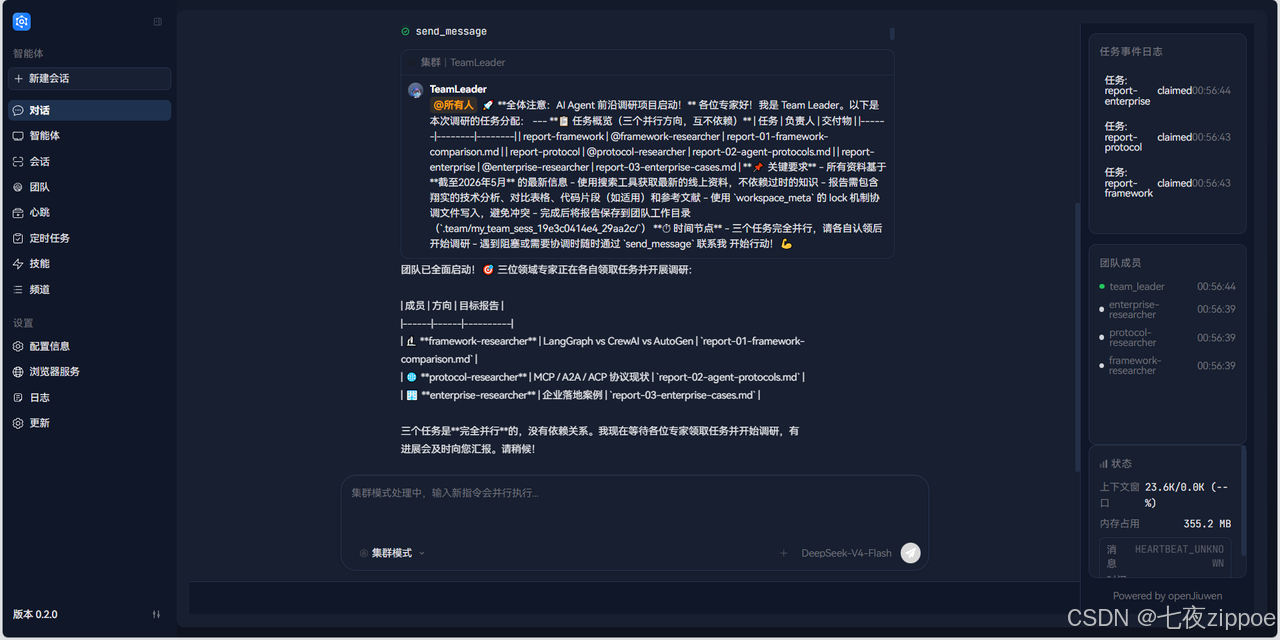
5.7 步骤六:追加新方向
调研进行到第 5 分钟左右,直接在输入框追加减指令:
再帮我加一个方向,Agent 的安全与对齐问题也调研一下。在集群模式下,消息会通过追加交互路径注入正在运行的 TeamAgent。代码层面的判断很直接------检查该 session 是否已有流式任务在跑,如果是,直接注入而不是新建团队:
# 不是首次请求
if query:
success = await team_manager.interact(session_id, query)Leader 收到后动态创建新的 Teammate 处理,不影响其他正在执行的成员。观察团队成员面板,可以看到第 4 个成员被创建并开始执行。
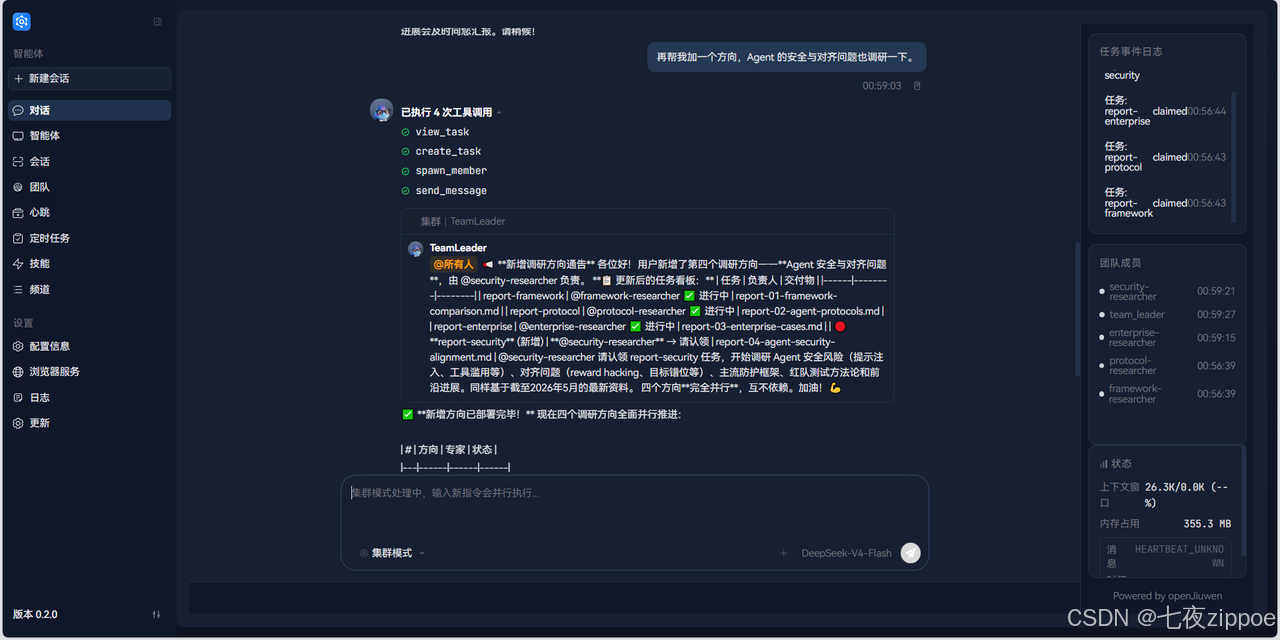
5.8 步骤七:查看结果
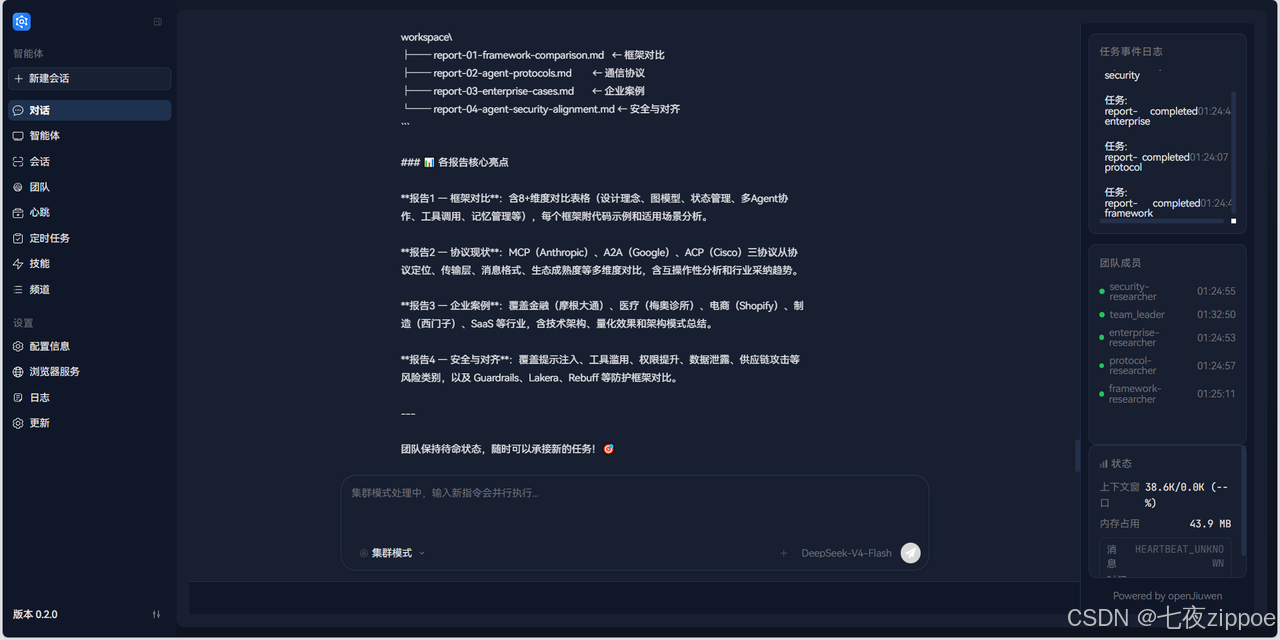
调研完成后:
-
聊天区域:Leader 汇总所有调研结果
-
团队成员面板:所有成员状态变为 🟢 就绪,随后变为 ⚪ 已关闭
-
工作目录:报告文件已保存
workspace/session/sess_research/
├── Agent框架对比分析.md # LangGraph vs CrewAI vs AutoGen
├── Agent通信协议技术对比.md # MCP / A2A / ACP
├── Agent企业落地案例.md # 企业应用实践
├── Agent安全与对齐.md # 追加的安全方向
└── todo.md # 任务进度记录




5.9 效果对比
|-------|-----------------|--------------------------|
| 维度 | V1(单 Agent) | V2(Swarm Agent) |
| 处理方式 | 串行处理 4 个方向 | 并行处理,3+1 个 Teammate 同时工作 |
| 耗时 | 约 60 分钟 | 约 20 分钟 |
| 上下文质量 | 信息累积导致膨胀,后期质量下降 | 每个 Teammate 上下文独立,质量稳定 |
| 追加需求 | 需排队等待当前任务完成 | 立即创建新 Teammate 处理 |
六、什么情况下不要升级
最后说一个重要的事:不是所有场景都需要升级到 V2。
|------------------------|---------------------|
| 场景 | 原因 |
| 任务始终是线性的(步骤 A → B → C) | 串行执行更自然,上下文共享是优势 |
| API 配额紧张 | 多 Agent 并发会显著增加调用量 |
| 任务简单,30 秒内完成 | 多 Agent 的调度开销反而拖慢速度 |
| 只需要单一领域操作 | 上下文不需要隔离 |
| 调试和开发阶段 | 单 Agent 的调试体验更直观 |
V1 和 V2 是共存关系,不是替代关系。日常对话用 V1 的智能执行模式,复杂任务切 V2 的集群模式。系统支持在不同会话间自由切换,互不影响。
七、写在最后
从 V1 到 V2 的升级,本质上是把"一个人扛"变成"一个团队协作"。但团队协作不是免费的------你需要配置团队结构、管理资源竞争、监控运行状态。JiuwenSwarm 的设计重心在于降低这个升级成本:
-
配置驱动而非代码驱动 :V1 配置完全保留,V2 通过新增
team:配置段启用,零侵入 -
能力 继承 而非重复配置:新 Teammate 自动继承主 Agent 的技能和能力卡,不需要逐个配置
-
动态 + 静态双模式 :
build_mode按需动态创建适合任务不固定的场景,predefined_members适合固定流程 -
全链路可观测:12 种事件类型覆盖团队运行的关键节点,前端实时展示
总的来说,这是一套实用导向的升级方案------重心放在如何让现有能力在多 Agent 场景下顺畅运转,而不是追求架构上的花哨。