unbutu安装clickhouse,并且远程连接
一. 安装
1. 先更新 & 装依赖
bash
sudo apt update
sudo apt install -y apt-transport-https ca-certificates curl gnupg
```.
## 2. 导入 ClickHouse 官方 GPG 密钥(Ubuntu 22.04 推荐做法)
```bash
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://packages.clickhouse.com/rpm/stable/repodata/repomd.xml.key \
| sudo gpg --dearmor -o /etc/apt/keyrings/clickhouse.gpg3. 添加 ClickHouse 官方 APT 源
bash
echo "deb [signed-by=/etc/apt/keyrings/clickhouse.gpg] https://packages.clickhouse.com/deb stable main" \
| sudo tee /etc/apt/sources.list.d/clickhouse.list4. 安装
bash
sudo apt update
sudo apt install -y clickhouse-server clickhouse-client5. 启动 & 开机自启
bash
sudo systemctl start clickhouse-server
sudo systemctl enable clickhouse-server
sudo systemctl status clickhouse-server6. 本地连接测试
bash
clickhouse-client7. 设置 default 密码(重要,默认空密码)
bash
sudo vim /etc/clickhouse-server/users.xml找到
bash
<password></password>改成(随便设一个)
bash
<password>123456</password>重启生效:
bash
sudo systemctl restart clickhouse-server8. 开放远程连接(默认只监听本机)
bash
sudo vim /etc/clickhouse-server/config.xml找到
bash
<!-- <listen_host>::</listen_host> -->改成
<listen_host>0.0.0.0</listen_host>保存退出,重启:
bash
sudo systemctl restart clickhouse-server二. dbserver 远程连接
1. 下载驱动
在项目pom 文件添加maven 依赖,然后在maven 仓库之中找到坐标
bash
<dependency>
<groupId>cc.blynk.clickhouse</groupId>
<artifactId>clickhouse4j</artifactId>
<version>1.4.4</version>
</dependency>下面这个jar包就是驱动
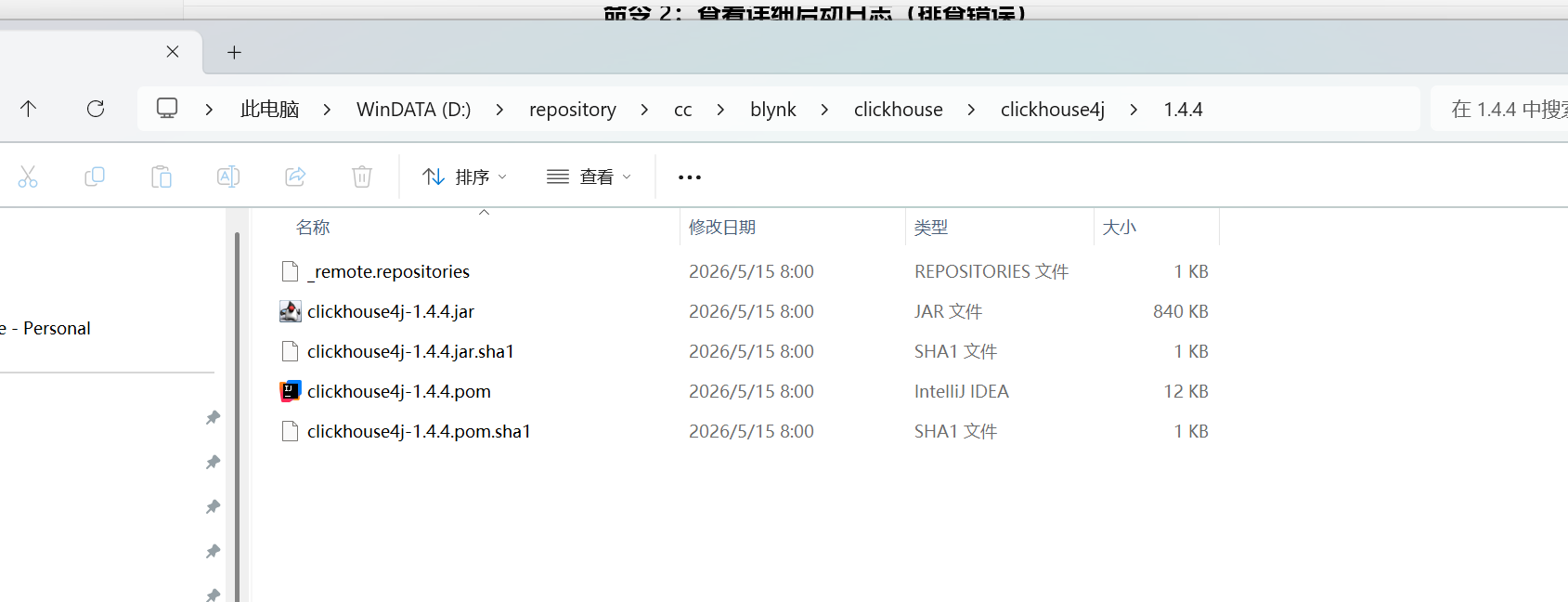
2. 配置dbserver
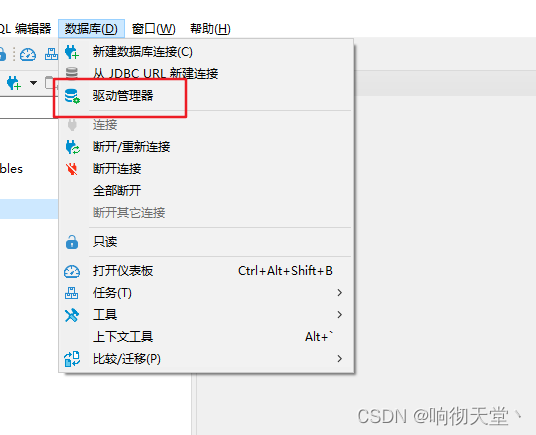
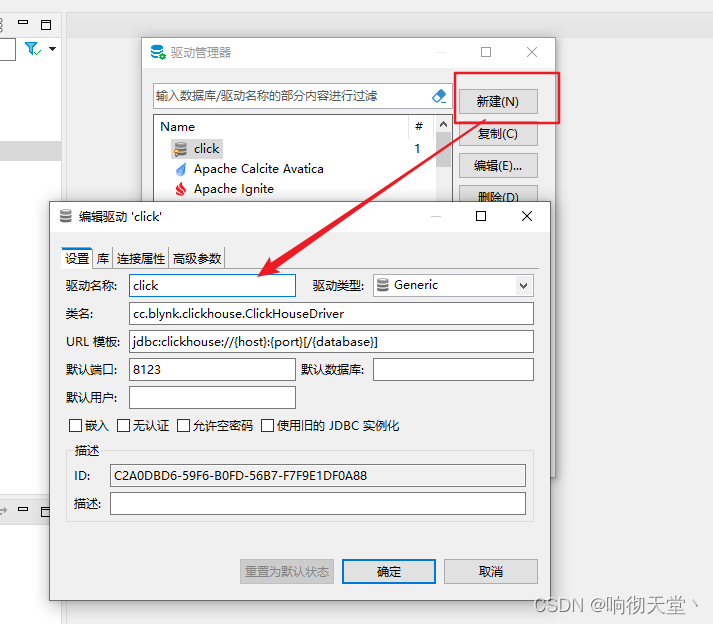
#配置
click
cc.blynk.clickhouse.ClickHouseDriver
jdbc:clickhouse://{host}:{port}/{database}
8123
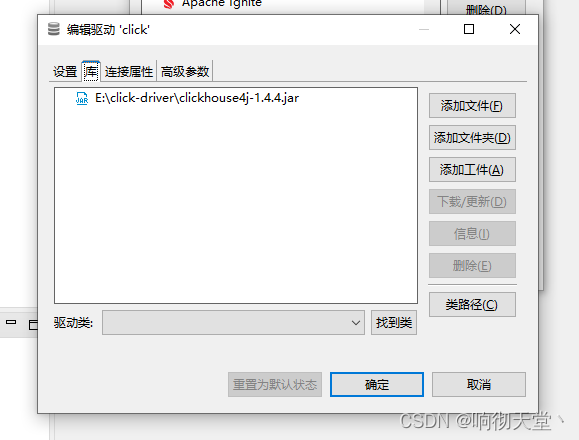
新建好后连接:
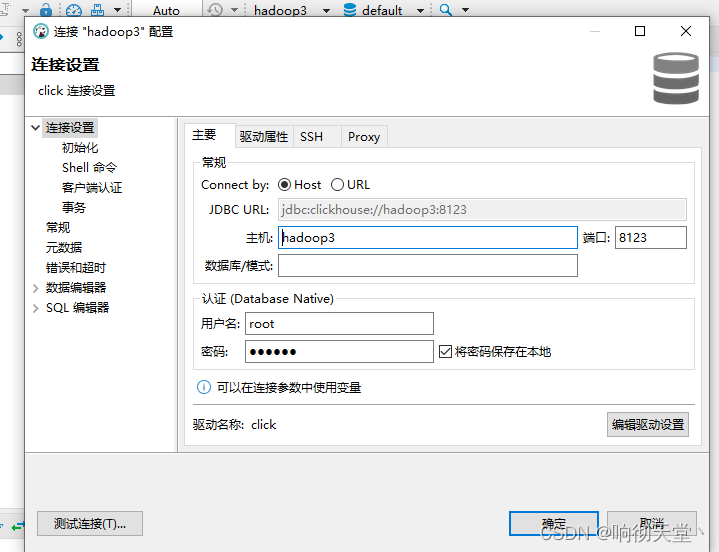
3. 使用
建表:
bash
CREATE TABLE IF NOT EXISTS device_data (
device_id FixedString(32),
time_stamp DateTime,
preasure Float64,
INDEX idx_device_id device_id TYPE minmax GRANULARITY 1
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(time_stamp)
ORDER BY (device_id, time_stamp)
SETTINGS index_granularity = 8192;测试插入
bash
INSERT INTO device_data (device_id, time_stamp, preasure)
VALUES ('dev001', '2025-05-14', 1.25), ('dev002', '2025-05-15', 2.33);测试查询
bash
SELECT * FROM device_data WHERE device_id = 'dev001';三: 调优
- 硬件配置建议
bash
• 确保服务器硬件足够强大,特别是磁盘 I/O、内存和 CPU。
• 使用 SSD 替代传统磁盘,以提高磁盘读写速度。
• 考虑使用 NVMe 存储,以更进一步提升 I/O 性能。- 查询优化:
• 使用合适的查询条件,避免全表扫描。
• 避免在大表上进行复杂的 JOIN 操作,可以通过分布式计算将查询分解为多个小查询。
• 合理利用 ClickHouse 的内置函数,以减少数据传输和处理的开销。 - 适当的集群规模:
• 考虑数据量和查询负载,适当调整集群规模。
• 在大规模集群中,使用 Distributed 引擎以实现分布式查询。
数据导入优化:
• 使用批量插入操作以提高数据导入速度。
• 考虑使用异步数据导入,避免实时要求。 - 系统参数调优:
• 调整 ClickHouse 的配置参数,例如缓存大小、线程数等,以适应不同的硬件和工作负载。 - 定期维护:
• 定期进行表的优化操作,如 OPTIMIZE TABLE,以减小存储空间并提高查询性能。
• 定期进行系统统计信息的收集,以帮助 ClickHouse 进行更好的查询计划优化。 - 监控和日志:
• 设置监控和日志,及时发现性能问题并进行调整。
• 根据日志进行故障排查和性能分析。 - 系统参数调优
bash
<!-- config.xml -->
<!-- 设置单个查询可以使用的最大线程数 -->
<max_threads>16</max_threads>
<!-- 设置单个查询可以使用的最大内存量 -->
<max_memory_usage>10000000000</max_memory_usage>
<!-- 在进行 GROUP BY 操作之前,最大的数据大小,超过这个大小将执行外部 GROUP BY -->
<max_bytes_before_external_group_by>10000000000</max_bytes_before_external_group_by>
<!-- 在进行 ORDER BY 操作之前,最大的数据大小,超过这个大小将执行外部排序 -->
<max_bytes_before_external_sort>10000000000</max_bytes_before_external_sort>
<!-- MergeTree 引擎执行合并操作的线程数 -->
<merge_tree>
<merge_threads>4</merge_threads>
</merge_tree>
<!-- MergeTree 引擎合并操作的块大小 -->
<merge_tree>
<merge_max_block_size>10000000</merge_max_block_size>
</merge_tree>
<!-- 查询日志的最大长度 -->
<query_log>
<max_length>1000000</max_length>
</query_log>
<!-- 记录查询执行过程中的日志级别 -->
<query_thread_log>
<log_level>2</log_level>
</query_thread_log>
<!-- 启用分布式聚合的内存优化 -->
<settings>
<distributed_aggregation_memory_efficient>1</distributed_aggregation_memory_efficient>
</settings>
<!-- 禁用压缩缓存 -->
<settings>
<use_uncompressed_cache>1</use_uncompressed_cache>
</settings>max_threads:指定单个查询可以使用的最大线程数。
• 调优建议:根据服务器的 CPU 核数和负载情况,适当设置 max_threads。在高负载情况下,可以适当降低。
max_memory_usage:指定单个查询可以使用的最大内存量。
• 调优建议:根据服务器的可用内存和工作负载,合理设置 max_memory_usage。避免设置得太大,以防止系统因为内存不足而变得缓慢。
max_bytes_before_external_group_by:指定在进行 GROUP BY 操作之前,最大的数据大小,超过这个大小将执行外部 GROUP BY。
• 调优建议:根据 GROUP BY 操作的频率和数据量,适当调整该参数。对于大数据量的 GROUP BY 操作,考虑增大该值。
max_bytes_before_external_sort:指定在进行 ORDER BY 操作之前,最大的数据大小,超过这个大小将执行外部排序。
• 调优建议:根据 ORDER BY 操作的频率和数据量,适当调整该参数。对于大数据量的 ORDER BY 操作,考虑增大该值。
merge_tree的merge_threads:指定 MergeTree 引擎执行合并操作的线程数。
• 调优建议:根据服务器的 CPU 核数和硬盘 I/O 的能力,适当调整 merge_threads。可以考虑增大该值以加速数据合并。
merge_tree的merge_max_block_size:指定 MergeTree 引擎合并操作的块大小。
• 调优建议:根据硬盘 I/O 和表分区的大小,适当调整 merge_max_block_size。通常情况下,增大该值有助于减小合并操作的开销。
query_log_max_length:指定查询日志的最大长度。
• 调优建议:根据日志记录需求,适当调整 query_log_max_length。对于需要详细查询日志的场景,可以增大该值。
query_thread_log_level:指定记录查询执行过程中的日志级别。
• 调优建议:在需要调试查询性能问题时,将 query_thread_log_level 设置为较低的日志级别,以获取更详细的查询执行信息。
distributed_aggregation_memory_efficient:启用分布式聚合的内存优化。
• 调优建议:对于涉及到分布式聚合操作的场景,启用该参数以优化内存使用。
use_uncompressed_cache:禁用压缩缓存。
• 调优建议:在硬盘 I/O 足够快的情况下,禁用压缩缓存可以提高查询性能。