**作者:洛水石** | **更新日期:2026-05-11** | **标签:ClickHouse | OLAP | 数据库优化 | 大数据**
前言
上个月,运营同学找我抱怨:每天凌晨的报表查询要等5分钟才能出来,数据量大的时候直接超时。作为DBA,我排查发现是MySQL在作祟------**8000万数据的聚合查询**,MySQL根本扛不住。
换用ClickHouse后,同样的查询从5分钟降到****3秒****。这不是偶然,ClickHouse专为OLAP场景设计,列式存储、向量化执行、并行处理,让它成为大数据分析的首选。
本文分享我在ClickHouse生产环境的优化经验,从表设计到查询优化,手把手教你榨干性能。
▲ ClickHouse查询优化流程图
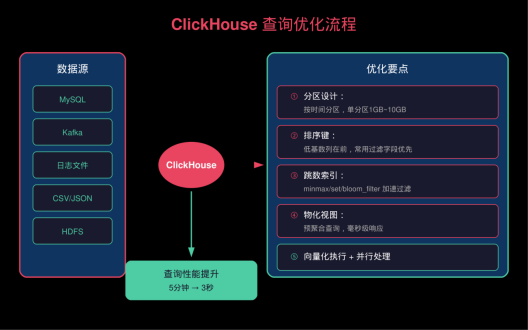
一、ClickHouse核心优势
1.1 为什么选择ClickHouse
|---------------|----------------|-----------|----------------|
| 特性 | ClickHouse | MySQL | PostgreSQL |
| **存储方式** | 列式存储 | 行式存储 | 行式存储 |
| **数据压缩** | 10~30倍 | 2~3倍 | 2~3倍 |
| **查询速度** | 毫秒级 | 秒~分钟级 | 秒~分钟级 |
| **写入性能** | 50MB/s+ | 1~5MB/s | 1~5MB/s |
| **支持数据量** | PB级 | TB级 | TB级 |
| **SQL支持** | 高 | 高 | 高 |
1.2 适用场景
- �� **用户行为分析**:埋点数据、点击流
- �� **实时报表**:大屏展示、Dashboard
- �� **日志分析**:访问日志、错误日志
- �� **商业智能**:经营分析、用户画像
- �� **监控数据**:时序数据、指标聚合
二、表设计最佳实践
2.1 表引擎选择
▲ 表引擎对比图 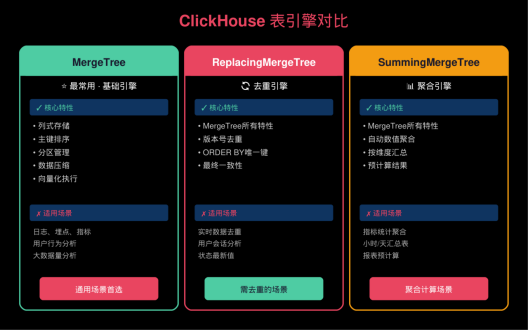
-- 合并树表引擎(MergeTree)- 最常用
CREATE TABLE events (
event_date Date,
event_time DateTime,
user_id UInt64,
event_type String,
event_data String
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(event_date)
ORDER BY (event_type, event_time, user_id)
TTL event_date + INTERVAL 3 MONTH
SETTINGS index_granularity = 8192;
-- ReplacingMergeTree - 去重表
CREATE TABLE user_sessions (
session_id String,
user_id UInt64,
start_time DateTime,
end_time DateTime,
version UInt32
) ENGINE = ReplacingMergeTree(version)
ORDER BY (user_id, session_id);
-- SummingMergeTree - 自动聚合
CREATE TABLE metrics_hourly (
metric_date Date,
metric_hour DateTime,
metric_name String,
tags String,
value Float64
) ENGINE = SummingMergeTree()
PARTITION BY toYYYYMM(metric_date)
ORDER BY (metric_name, tags, metric_hour);
2.2 分区策略
-- 按月分区 - 适合日志类数据
CREATE TABLE logs (
log_date Date,
log_time DateTime,
level String,
message String
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(log_date)
ORDER BY (level, log_time)
SETTINGS parts_to_throw_insert = 300; -- 控制单批次大小
**分区设计原则**:
- �� 分区粒度不要过细(避免小分区过多)
- �� 分区字段应与查询条件匹配
- �� 单分区数据量建议在1GB~10GB
2.3 排序键设计
-- 低基数列放前面 - 利用Skip Index
CREATE TABLE analytics (
event_date Date,
event_type LowCardinality(String), -- 低基数用LowCardinality
user_id UInt64,
session_id String,
properties String,
created_at DateTime
) ENGINE = MergeTree()
ORDER BY (event_type, event_date, user_id, created_at);
-- 跳数索引 - 加速过滤
CREATE TABLE products (
category_id UInt32,
product_id UInt64,
price Decimal(10,2),
name String,
description String
) ENGINE = MergeTree()
ORDER BY (category_id, product_id)
SETTINGS index_granularity = 8192;
▲ 索引优化示意图 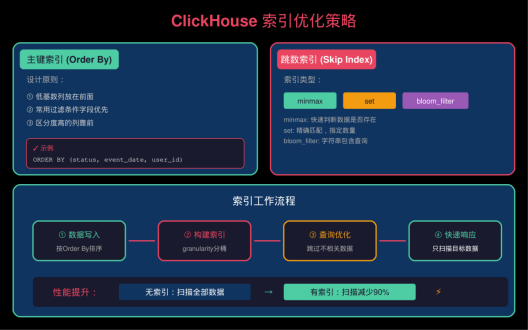
三、索引优化
3.1 主键索引(Order By Key)
-- 好的设计:过滤条件在前面
CREATE TABLE access_logs (
event_date Date,
status UInt16,
user_id UInt64,
path String,
response_time Float32,
created_at DateTime
) ENGINE = MergeTree()
ORDER BY (status, event_date, created_at); -- 常用过滤字段靠前
-- 查询示例
SELECT count(*), avg(response_time)
FROM access_logs
WHERE status = 404
AND event_date >= '2026-05-01';
3.2 跳数索引(Skip Index)
-- minmax 索引 - 快速判断数据是否存在
ALTER TABLE events ADD INDEX idx_event_type event_type TYPE minmax;
-- set 索引 - 精确匹配
ALTER TABLE events ADD INDEX idx_user_id user_id TYPE set(1000);
-- bloom_filter - 字符串包含查询
ALTER TABLE events ADD INDEX idx_event_data event_data TYPE bloom_filter(0.01, 3);
-- 生效查询
SELECT * FROM events WHERE event_data LIKE '%error%';
四、查询优化技巧
4.1 使用PREWHERE替代WHERE
-- 优化前
SELECT user_id, event_data
FROM events
WHERE event_type = 'click'
AND event_data != '';
-- 优化后 - ClickHouse自动优化
SELECT user_id, event_data
FROM events
PREWHERE event_type = 'click' -- 先过滤,减少数据读取
WHERE event_data != '';
4.2 物化视图加速聚合
-- 创建物化视图
CREATE MATERIALIZED VIEW stats_hourly
ENGINE = SummingMergeTree()
PARTITION BY toYYYYMM(hour)
ORDER BY (event_type, hour)
AS
SELECT
event_type,
toStartOfHour(event_time) AS hour,
count() AS cnt,
uniqExact(user_id) AS uv
FROM events
GROUP BY event_type, toStartOfHour(event_time);
-- 查询物化视图(毫秒级)
SELECT event_type, cnt, uv
FROM stats_hourly
WHERE hour >= now() - INTERVAL 1 DAY;
4.3 采样查询
-- 全表10%采样
SELECT event_type, count() / 0.1 AS total
FROM events SAMPLE 0.1
GROUP BY event_type;
-- 按指定样本数
SELECT event_type, count() * 10 AS estimated_total
FROM events SAMPLE 1000000
GROUP BY event_type;
4.4 常见慢查询优化
-- ❌ 慢查询:全表扫描
SELECT * FROM events WHERE event_date = '2026-05-10';
-- ✅ 优化:指定分区 + 限制返回
SELECT event_type, user_id, event_time
FROM events
WHERE event_date = '2026-05-10'
AND event_type = 'purchase'
LIMIT 1000;
-- ❌ 慢查询:大量小批次INSERT
INSERT INTO events VALUES ('2026-05-10', now(), 1, 'click', '');
-- ✅ 优化:批量INSERT
INSERT INTO events VALUES
('2026-05-10', now(), 1, 'click', ''),
('2026-05-10', now(), 2, 'view', ''),
('2026-05-10', now(), 3, 'click', '');
五、数据导入优化
5.1 批量导入配置
clickhouse-client 批量导入
clickhouse-client --query \
"INSERT INTO events FORMAT JSONEachRow" \
< data.json
优化参数
clickhouse-client \
--max_insert_block_size=100000 \ # 更大的块
--max_memory_usage=10G \ # 更大的内存
--max_threads=16 \ # 更多线程
--query "INSERT INTO events FORMAT JSONEachRow" \
< data.json
5.2 Kafka实时导入
-- 创建Kafka引擎表
CREATE TABLE events_queue (
event_date Date,
event_time DateTime,
user_id UInt64,
event_type String,
event_data String
) ENGINE = Kafka()
SETTINGS kafka_broker_list = 'kafka:9092',
kafka_topic_list = 'user-events',
kafka_group_name = 'clickhouse-consumer',
kafka_format = 'JSONEachRow';
-- 创建物化视图消费Kafka数据
CREATE MATERIALIZED VIEW events_mv TO events
AS SELECT * FROM events_queue;
六、生产环境配置
6.1 配置文件优化
<!-- /etc/clickhouse-server/config.xml -->
<clickhouse>
<!-- 监听地址 -->
<listen_host>::</listen_host>
<!-- 最大内存 -->
<max_memory_usage>16G</max_memory_usage>
<!-- 聚合内存限制 -->
<max_bytes_before_external_group_by>8G</max_bytes_before_external_group_by>
<max_bytes_before_external_sort>8G</max_bytes_before_external_sort>
<!-- 并行处理 -->
<max_threads>16</max_threads>
<max_distributed_connections>1024</max_distributed_connections>
<!-- 后台池 -->
<background_pool_size>16</background_pool_size>
<background_schedule_pool_size>16</background_schedule_pool_size>
<!-- 连接超时 -->
<connect_timeout_with_failover_ms>1000</connect_timeout_with_failover_ms>
<connect_timeout_with_failover_remote_server_ms>1000</connect_timeout_with_failover_remote_server_ms>
</clickhouse>
6.2 资源限制
-- 设置用户配额
CREATE USER analyst IDENTIFIED WITH plaintext_password BY 'password'
QUOTA my_quota;
CREATE QUOTA my_quota FOR INTERVAL 1 hour
READ rows 10000000,
WRITE bytes 10G,
EXECUTE time 300;
七、监控与运维
7.1 关键监控指标
-- 查询性能
SELECT
query,
queries,
result_rows,
result_bytes,
formatReadableQuantity(elapsed) AS time,
formatReadableQuantity(memory_usage) AS memory
FROM system.query_log
WHERE type = 'QueryFinish'
AND event_time >= now() - INTERVAL 1 hour
ORDER BY elapsed DESC
LIMIT 20;
-- 分区状态
SELECT
database,
table,
partition,
sum(rows) AS rows,
formatReadableSize(sum(bytes)) AS size,
max(modification_time) AS latest_modify
FROM system.parts
WHERE active = 1
GROUP BY database, table, partition
ORDER BY size DESC;
7.2 常用运维命令
查看表大小
SELECT table, formatReadableSize(sum(bytes)) AS size
FROM system.parts WHERE active GROUP BY table;
合并分区
OPTIMIZE TABLE events FINAL;
清理过期数据
ALTER TABLE events MODIFY TTL event_date + INTERVAL 3 MONTH;
查看后台任务
SELECT * FROM system.background_processes;
八、常见问题
Q1: 数据量大了查询变慢?
-- 检查是否使用了正确的分区和排序键
EXPLAIN indexes = 1
SELECT * FROM events WHERE event_date = '2026-05-10';
-- 重建表使用更好的排序键
ALTER TABLE events MODIFY ORDER BY (event_type, event_date, user_id);
Q2: 内存占用过高?
-- 启用外部排序
SET max_bytes_before_external_sort = 8G;
-- 使用LIMIT减少内存
SELECT * FROM events WHERE event_type = 'click' LIMIT 100000;
Q3: 写入失败?
-- 检查Parts数量
SELECT count() FROM system.parts WHERE table = 'events' AND active = 1;
-- 如果Parts过多,手动合并
OPTIMIZE TABLE events PARTITION '202605' FINAL;
总结
ClickHouse性能优化核心要点:
|--------------|-----------------------|-----------|
| 优化方向 | 关键措施 | 预期收益 |
| **表设计** | 选择合适引擎、合理分区、设计排序键 | 查询快5~50倍 |
| **索引优化** | 使用跳数索引、LowCardinality | 扫描数据减少90% |
| **查询优化** | 使用PREWHERE、物化视图、批量写入 | 延迟降低80% |
| **资源调优** | 合理配置内存和线程数 | 吞吐量提升3倍 |
**记住**:ClickHouse是为分析而生的,合理设计表结构是性能的基础。
*数据驱动决策,ClickHouse让分析成为可能。*
