引言
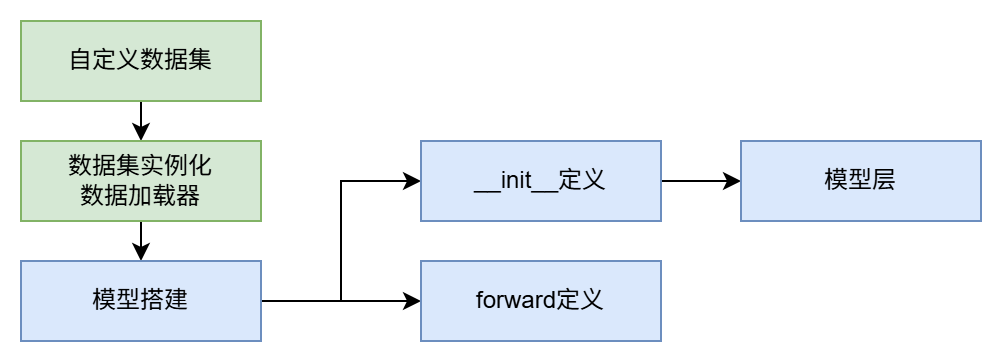
我们接着上一篇文章继续,上次我们创建了数据集,加载了数据集,那么接下来就是搭建模型了。
构建模型
这里推荐看一下Pytorch官方的描述,比较具体。简单来说,神经网络由对数据执行操作的层/模块组成。我们构建的神经网络类继承自torch.nn.Module。我们需要在__init__中初始化神经网络层,然后在forward方法中实现对输入数据的操作。
python
class SegmentationNet(nn.Module):
def __init__(self):
def forward(self,x):__init__定义
首先使用super().init()继承一下nn.Module的__init__部分。在自定义模型时,必须在__init__方法的第一行调用,它构建了一个神经网络所需要的容器。之后才可以编写自己的模型层。
python
def __init__(self,n_classes=1):
super().__init__()
# 编码器
self.encoder = nn.Sequential(
nn.Conv2d(3, 64, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(64, 128, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(128, 256, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),
)
# 解码器
self.decoder = nn.Sequential(
nn.ConvTranspose2d(256, 128, 2, stride=2),# 64->128
nn.Conv2d(128, 64, 3, padding=1), nn.ReLU(),# 平滑作用,不改变矩阵大小
nn.ConvTranspose2d(64, 64, 2, stride=2),# 128->256
nn.Conv2d(64,32, 3, stride = 1,padding = 1), nn.ReLU(), # 平滑作用,不改变矩阵大小
nn.ConvTranspose2d(32, 32, 2, stride=2), # 256->512
nn.Conv2d(32, n_classes,1), # 1*1卷积,降维到单通道
nn.Sigmoid() # 二分类概率
)这里我们定义了self.encoder和self.decoder两个模型层,但是仔细观察便能发现这两个是容器的类型,里面包含了一系列层。我们用nn.Sequential实现该结构。nn.Sequential 是一个有序的模块容器。数据按照定义的相同顺序通过所有模块。
forward定义
forward 方法实现了从输入到输出的完整计算逻辑,也就是定义了数据如何在网络中流动、变换,最终产生预测结果。定义好forward方法不要直接调用,要通过model(x)间接调用,直接调用会跳过__call__方法,使得其中的钩子逻辑失效,使得模型训练异常。

python
# 错误:跳过钩子
output = model.forward(x)
# 正确:调用 __call__,自动触发 hooks
output = model(x)进行forward方法定义:
python
def forward(self, x):
return self.decoder(self.encoder(x))内容逻辑很简单,先进行self.encoder然后进行self.decoder。
模型层
这里介绍一下本示例中用到的模型层,如卷积层,池化层,激活函数层
卷积层
卷积层
实现下采样(提取特征),通过调整卷积核参数进行学习。
输出尺寸 = (W - K + 2P) / S + 1
W:输入矩阵宽度,K:卷积核宽度,P:padding长度,S:stride长度
nn.Conv2d(1, 1, kernel_size=3, stride=1, padding=0)
这个卷积层输入通道数为1,输出通道数为1,卷积核宽度为3,步长为1,padding为0。假设输入矩阵为4*4,那么输出矩阵的尺寸为2*2。
转置卷积层
转置卷积层,实现上采样(恢复分辨率),通过调整卷积核参数进行学习。
输出尺寸 = (W - 1) × S - 2P + K + 输出填充
W:输入矩阵宽度,K:卷积核宽度,P:padding长度,S:stride长度
nn.ConvTranspose2d(1, 1, kernel_size=3, stride=1, padding=0)
这个卷积层输入通道数为1,输出通道数为1,卷积核宽度为3,步长为1,padding为0。假设输入矩阵为2*2,那么输出矩阵的尺寸为4*4。简单来说,就是输入矩阵的每一个数点乘卷积核,得到的矩阵放入对应的位置,最后将每个位置的数叠加后即得到输出矩阵。
不过转置卷积虽然能增加参数,提高分辨率,单容易产生棋盘效应,即因为重叠区域不均匀导致可能产生棋盘状伪影。解决方法是转置卷积+普通卷积,这里的普通卷积的作用是平滑矩阵中的伪影。
池化层
该层主要做的就是降参,降低分辨率。
示例所用的为最大池化层,即:
nn.MaxPool2d(2)
池化窗口宽度为2,将输入矩阵中固定位置的数换为池化窗口范围中最大的数。
激活函数层
非线性激活是模型输入和输出之间产生复杂映射的原因。它们在线性变换后应用,以引入非线性,帮助神经网络学习各种各样的现象。如果没有激活函数,那么多层卷积等价于单层卷积,即线性变换的复合仍是线性。引入非线性后,网络才能学习复杂模式。
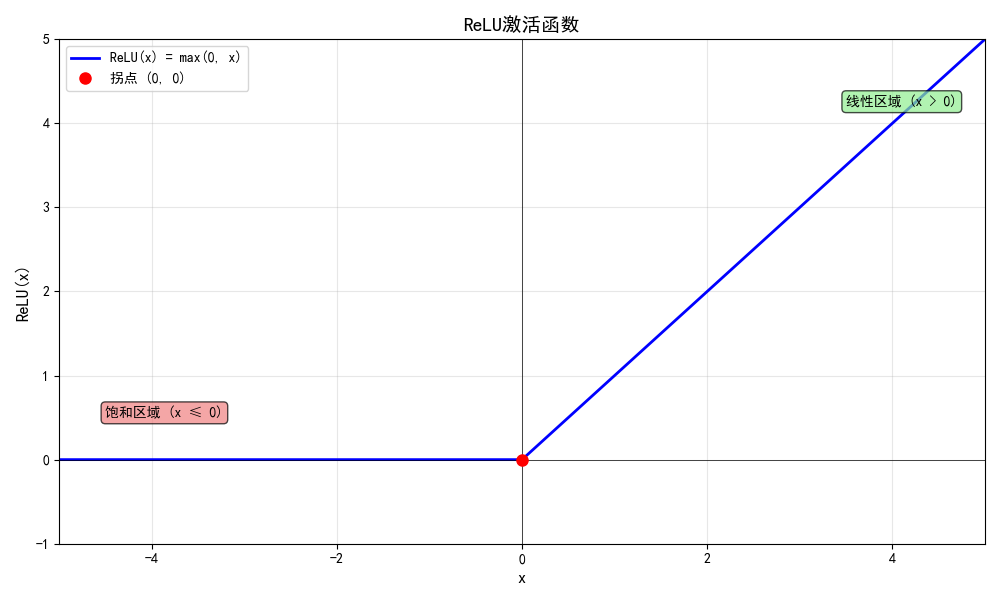
nn.ReLU即为一个非线性激活函数。
f(x) = max(0, x)
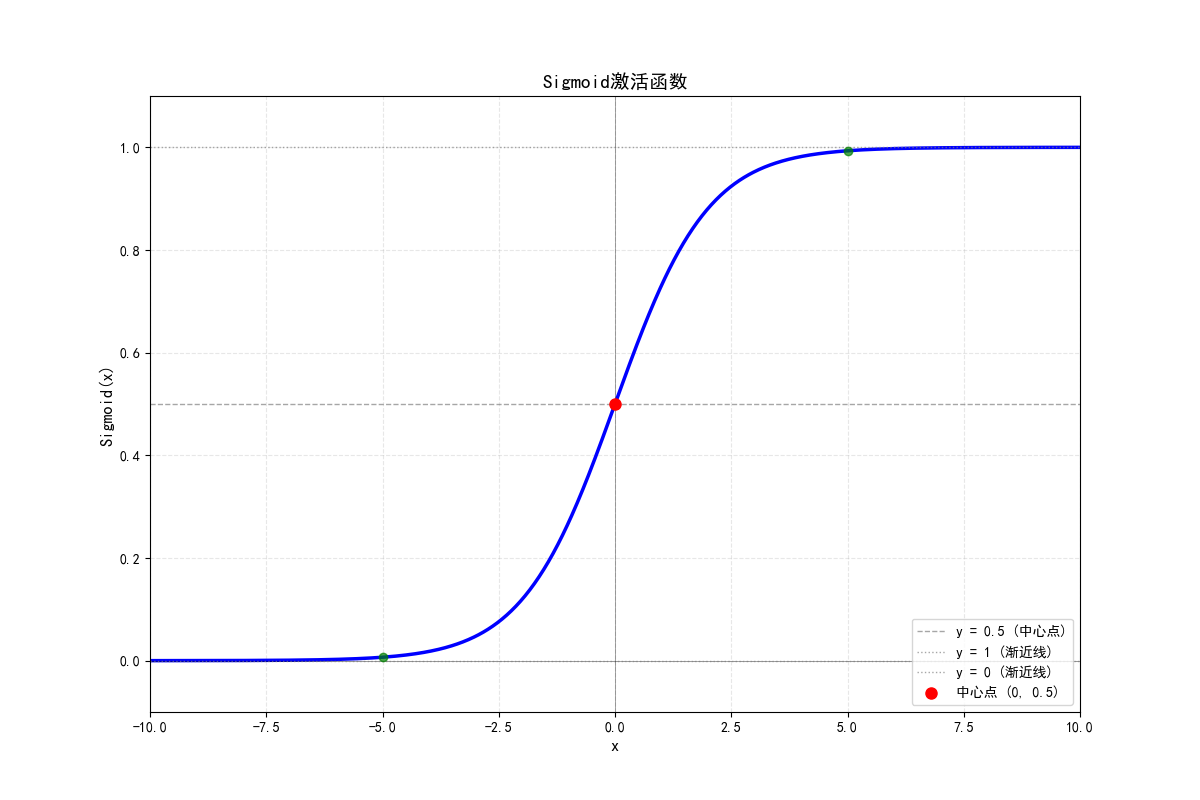
nn.sigmoid激活函数适合概率值的输出
f(x) = 1 / (1 + e^(-x))
模型参数
如官方文档所说,神经网络内部的许多层都是参数化的,即具有在训练期间优化的相关权重和偏置。继承 nn.Module 会自动跟踪模型对象内定义的所有字段,并使所有参数都可以通过模型的 parameters() 或 named_parameters() 方法访问。
python
model = SegmentationNet()
for i in model.named_parameters():
print(i[0],i[1].size())
python
encoder.0.weight torch.Size([64, 3, 3, 3])
encoder.0.bias torch.Size([64])
encoder.3.weight torch.Size([128, 64, 3, 3])
encoder.3.bias torch.Size([128])
encoder.6.weight torch.Size([256, 128, 3, 3])
encoder.6.bias torch.Size([256])
decoder.0.weight torch.Size([256, 128, 2, 2])
decoder.0.bias torch.Size([128])
decoder.1.weight torch.Size([64, 128, 3, 3])
decoder.1.bias torch.Size([64])
decoder.3.weight torch.Size([64, 64, 2, 2])
decoder.3.bias torch.Size([64])
decoder.4.weight torch.Size([32, 64, 3, 3])
decoder.4.bias torch.Size([32])
decoder.6.weight torch.Size([32, 32, 2, 2])
decoder.6.bias torch.Size([32])
decoder.7.weight torch.Size([1, 32, 1, 1])
decoder.7.bias torch.Size([1])我们也可以打印出该网络总参数量
python
total_params = sum(p.numel() for p in model.parameters())
trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"总参数量: {total_params:,}")
print(f"可训练参数量: {trainable_params:,}")
python
总参数量: 614,881
可训练参数量: 614,881当然,我们可以测试一下该模型的输出,应该和输入矩阵尺寸相同
python
model = SegmentationNet()
x = torch.randn(1, 3, 512, 512)
output = model(x)
print(f"输出尺寸: {output.shape}")
python
输出尺寸: torch.Size([1, 1, 512, 512])结尾及相关链接
很好,我们已经搭建了神经网络,接下来定义好评估函数和优化器就可以开始训练了呢。
下期见 ദ്ദി (⩌ᴗ⩌ )
相关链接如下:
示例所用数据集:
Pytorch链接: