在视频生成的扩散模型(Diffusion)或流匹配(Flow Matching)架构中,视频数据 (B,T,C,H,W)(B, T, C, H, W)(B,T,C,H,W) 的维度极其庞大。VAE 的核心使命是将高维的像素空间映射到低维的隐空间(Latent Space),从而大幅降低下游生成模型的计算复杂度。
一、 2D VAE:纯空间压缩(时间盲区)
1. 核心机制
2D VAE 将视频视为独立的图像集合。它将时间维度 TTT 折叠进 Batch 维度,即 (B×T,C,H,W)(B \times T, C, H, W)(B×T,C,H,W),然后使用标准的 2D 卷积进行特征提取和下采样。
- 维度变化 :(B,T,C,H,W)→Encoder(B,T,C′,H/8,W/8)(B, T, C, H, W) \xrightarrow{\text{Encoder}} (B, T, C', H/8, W/8)(B,T,C,H,W)Encoder (B,T,C′,H/8,W/8)
- 时间维度 TTT 不变,仅空间维度缩小。
2. 优势与局限
- 优势:可以直接复用成熟的图像 VAE(如 SD 1.5/XL 的 VAE),无需重新训练,显存占用极低。
- 局限(致命伤) :时序不连贯。由于编码和解码是逐帧独立进行的,任何微小的重建误差都会在相邻帧之间表现为"闪烁"或高频抖动。如果要生成一段连续的动作(例如手指弹奏钢琴的复杂动作),2D VAE 解码出的每一帧手指边缘可能会不断跳变,彻底破坏动作的物理连贯性。
二、 标准 3D VAE:时空联合压缩(全知视角)
1. 核心机制
为了解决闪烁问题,标准 3D VAE 引入了 3D 卷积核(例如 3×3×33 \times 3 \times 33×3×3)。它在高度、宽度和时间轴上同时滑动,捕捉连续多帧内的时空动态特征(Motion Dynamics)。
- 维度变化 :(B,T,C,H,W)→Encoder(B,T/4,C′,H/8,W/8)(B, T, C, H, W) \xrightarrow{\text{Encoder}} (B, T/4, C', H/8, W/8)(B,T,C,H,W)Encoder (B,T/4,C′,H/8,W/8)
- 时间维度 TTT 被压缩(通常下采样 4 倍)。
2. 优势与局限
- 优势:极大地平滑了视频帧,消除了闪烁。隐变量不再是一张静态图,而是一个包含物理运动轨迹的"时空块"。
- 局限(未来泄露) :标准的 3D 卷积是对称的。当它计算第 ttt 帧的特征时,它会同时"看向"第 t−1t-1t−1 帧(过去)和第 t+1t+1t+1 帧(未来)。这种"偷看未来"的机制在处理定长视频时没有问题,但它摧毁了模型流式生成长视频的能力。如果你想预测下一秒的画面,但你的解码器必须依赖未来的画面才能工作,这就陷入了死循环。
是的,你抓住了 VAE 数学推导与工程实现结合的最核心问题!
在 3D VAE 中,μ\muμ(均值)和 σ\sigmaσ(标准差/方差)绝对也是"3D"的(严格来说,加上批次和通道,它们是 5 维张量,但在物理意义上保留了完整的 3D 时空结构)。
为了让你看得最清楚,我们直接把张量(Tensor)在 PyTorch 中的维度变化拆解开来:
1. 具体的维度是多少?
假设我们输入一段视频,并且 VAE 的压缩策略是:时间维度压缩 4 倍,空间维度压缩 8 倍,隐变量通道数为 C′C'C′。
Step 1: 视频输入
输入的视频张量 XXX 的维度是:(B,Cin,T,H,W)(B, C_{in}, T, H, W)(B,Cin,T,H,W)
- BBB: Batch Size(批次大小)
- CinC_{in}Cin: RGB 通道(通常为 3)
- TTT: 输入帧数(例如 16)
- H,WH, WH,W: 空间分辨率(例如 512, 512)
Step 2: 经过 3D 编码器 (Encoder)
视频经过一系列 3D 卷积下采样后,网络会输出一个融合了时空特征的张量。关键来了,为了同时得到 μ\muμ 和 σ\sigmaσ,Encoder 最后一层的输出通道数通常会设定为目标隐通道数 C′C'C′ 的两倍。
- Encoder 输出维度:(B,2×C′,T/4,H/8,W/8)(B, 2 \times C', T/4, H/8, W/8)(B,2×C′,T/4,H/8,W/8)
- 代入数字:(B,2×C′,4,64,64)(B, 2 \times C', 4, 64, 64)(B,2×C′,4,64,64)
Step 3: 切分得到 μ\muμ 和 σ\sigmaσ
网络会把上面这个张量在通道维度(Channel)上直接对半切开(torch.chunk 或 torch.split):
- μ\muμ 的维度是:(B,C′,T/4,H/8,W/8)(B, C', T/4, H/8, W/8)(B,C′,T/4,H/8,W/8)
- σ\sigmaσ 的维度也是:(B,C′,T/4,H/8,W/8)(B, C', T/4, H/8, W/8)(B,C′,T/4,H/8,W/8)
2. 采样过程(重参数化技巧)
得到 μ\muμ 和 σ\sigmaσ 后,VAE 会从标准正态分布 N(0,I)\mathcal{N}(0, I)N(0,I) 中采样一个与它们维度完全相同 的噪声张量 ϵ\epsilonϵ:
- ϵ\epsilonϵ 的维度:(B,C′,T/4,H/8,W/8)(B, C', T/4, H/8, W/8)(B,C′,T/4,H/8,W/8)
然后进行重参数化(Reparameterization Trick)计算最终的隐变量 ZZZ:
Z=μ+σ⊙ϵ Z = \mu + \sigma \odot \epsilon Z=μ+σ⊙ϵ
- 最终隐变量 ZZZ 的维度:(B,C′,T/4,H/8,W/8)(B, C', T/4, H/8, W/8)(B,C′,T/4,H/8,W/8)
3. 这在物理上意味着什么?
为什么 μ\muμ 和 σ\sigmaσ 必须保持 3D 结构,而不能被压扁成一个一维向量(像早期的图像 VAE 那样压缩成例如一个长度为 256 的向量)?
- 局部时空管辖权 (Spatiotemporal Patch) :
在 μ\muμ 这个张量中,你可以取出一个具体的"像素点",比如 μ0,:,1,10,10\mu0, :, 1, 10, 10μ0,:,1,10,10。这一个点对应的并不是原视频中的某一个像素,而是原视频中一个 4帧×8像素×8像素4帧 \times 8像素 \times 8像素4帧×8像素×8像素 的"时空立方体块"。 - 分布的意义:
- μ\muμ 记录了这个时空块的"主要运动特征和外貌特征"。
- σ\sigmaσ 记录了这个时空块的"不确定性"或"容错空间"。
- 如果 σ\sigmaσ 很小,说明 VAE 认为这个时空块的动作非常确定(比如一面静止的白墙);如果 σ\sigmaσ 很大,说明这里的动态很复杂(比如水花飞溅),网络允许在这个位置生成时有更多的随机性。
三、 3D Causal VAE:因果建模(时间之矢)
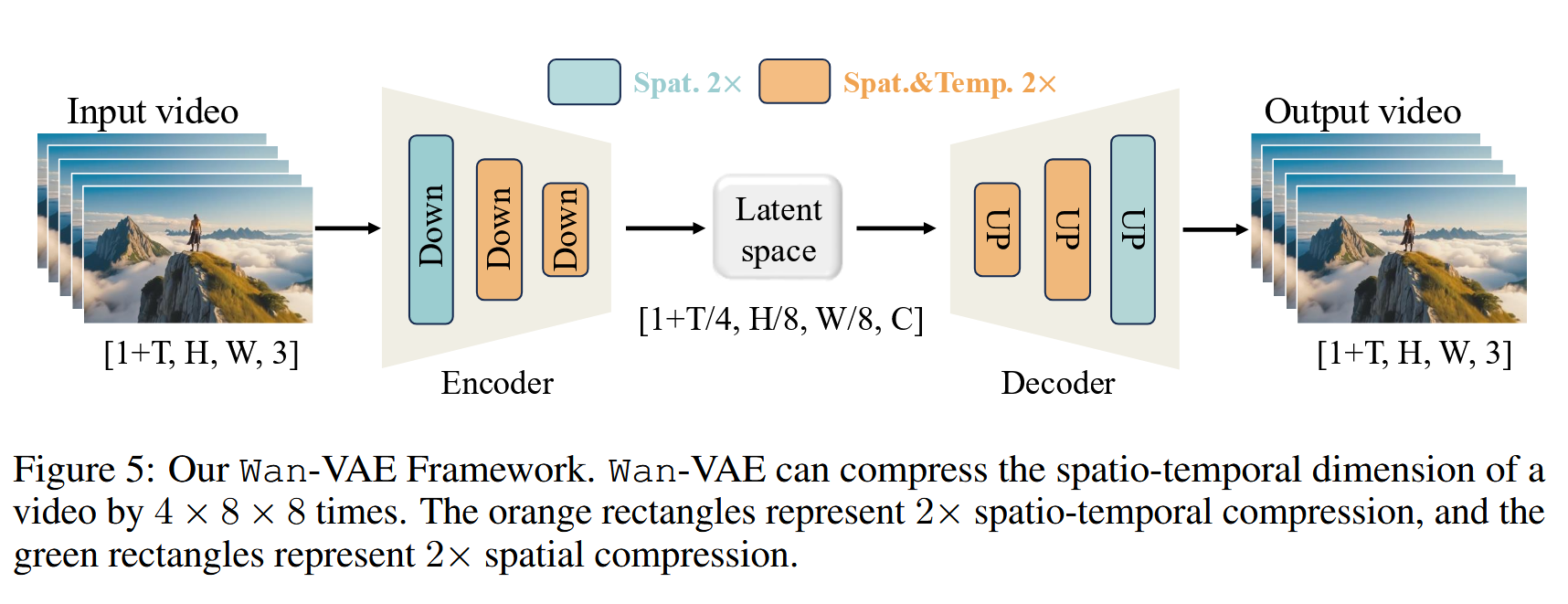
在视频生成大模型(如 Sora、Wan2.1 等)中,视频数据不再是简单的时间切片,而是一个完整的时空张量 X∈RB×(1+T)×C×H×WX \in \mathbb{R}^{B \times (1+T) \times C \times H \times W}X∈RB×(1+T)×C×H×W。
为了解决标准 3D VAE 无法支持自回归生成和会产生"未来泄露"的问题,3D Causal VAE 通过对时间维度进行严格的"因果切片与填充",成为了目前高质量视频生成架构的基础设施。
1. 什么是"因果 (Causal)"的维度映射?
在时间序列建模中,"因果"意味着信息在时间轴上只能单向流动。
映射到张量计算上,它的绝对原则是:在计算潜空间中第 tlatentt_{latent}tlatent 帧的特征时,网络在原始视频输入的时间维度 TTT 上,只能进行索引 ≤tinput\le t_{input}≤tinput 的局部张量切片操作,对 >tinput> t_{input}>tinput 的数据保持绝对的"零掩码(Zero Mask)"或不可见状态。
2. 核心技术实现:时间维度的非对称填充 (Asymmetric Padding in TTT-axis)
标准 3D 卷积之所以会看到未来,是因为它在处理张量的时间维度时,使用了对称填充(Symmetric Padding)。假设我们使用一个空间大小为 3×33 \times 33×3,时间步长为 333 的 3D 卷积核(形状为 3×3×33 \times 3 \times 33×3×3),为了保持时间维度的形状不变(在下采样前),标准的做法是在 TTT 维度的左右各补 1 帧零:Padding = (1, 1)。这使得计算目标帧时,强制引入了 t+1t+1t+1(未来)的切片。
Causal 3D VAE 通过修改 TTT 维度的 Padding 规则来实现物理上的因果性:
- 非对称填充 :它将时间维度的 Padding 修改为
(2, 0)(左侧补2,右侧补0)。 - 计算滑窗 :这意味着,当卷积核的中心对准输入张量的第 ttt 个切片时,它的感受野(滑窗)仅覆盖了第 t−2t-2t−2、第 t−1t-1t−1 和第 ttt 帧。在未来方向(t+1t+1t+1)上,由于 Padding 边界为 0,滑窗不会发生越界读取。这在矩阵运算层面彻底斩断了未来信息流入当前特征图的路径。
3. 破局"无源之水":[1+T] 维度的首帧特权
既然因果计算要求必须依赖"过去",那时间维度索引为 000 的第一帧怎么办?这就引出了极其优雅的 [1+T] 维度切分策略:
-
结构解耦 :Causal VAE 不再将输入视为均质的 T′T'T′ 帧,而是拆解为
[1 (锚点帧) + T (动态帧)]。 -
非对称降维 (Asymmetric Downsampling):
-
对
[1]的处理 :网络将时间轴索引为 0 的张量切片独立提取,这一帧完全跳过时间维度的压缩 (即在处理它时,3D 卷积自动退化为 2D 卷积或使用 Replication Padding)。它只在空间上被压缩(例如 H,WH,WH,W 变为 1/81/81/8)。 -
对
[T]的处理 :后续的 TTT 帧则严格按照上述的"非对称填充"和"因果 3D 卷积"进行时空联合下采样(例如时间维度 TTT 压缩 444 倍)。 -
维度收敛 :最终输出的潜空间张量维度变为 1+T/4,Clatent,H/8,W/81+T/4, C_{latent}, H/8, W/81+T/4,Clatent,H/8,W/8。首帧作为绝对清晰的"空间锚点"得以保全,而后续动作被压缩成了高密度的时空动力学块。
4. 为什么基于 [1+T] 的 Causal VAE 是工业界标配?
- 支持自回归/流式生成 (Streamable Generation) :由于严格的因果隔离,你可以先生成一个
[1+4]的潜空间张量(对应 1+161+161+16 帧原始视频)。在生成下一段时,直接将上一次的最后几帧作为新的历史输入(Context),继续生成下一个[T/4]张量。两段拼接时,由于底层的感受野边界完美对齐,生成的长视频不会出现帧间断层或闪烁突变。 - 极致的显存优化 (KV-Caching 机制) :在处理长视频推理时,张量的历史切片可以像 LLM 的 KV Cache 一样被保留在显存中。当新的一帧进入时,模型只需要对最新的张量切片执行前向传播,并与缓存的过去特征进行因果卷积,而无需把前面几百帧的数据重新进行 3D 卷积运算。这是 Sora 等模型能够一次性生成 60 秒(数千帧)极长视频的底层算力保障。
第一帧的具体处理方法
那么,像 Sora 或 Wan2.1 这样的模型,底层究竟是如何用同一套 3D VAE 权重,既能处理长视频,又能完美处理单张图像(不进行时间压缩)的呢?
这主要归功于两种极其巧妙的底层实现机制:条件步长(Conditional Stride) 和 卷积核退化(Kernel Squeezing)。
1. 物理形态的统一:图像就是 T=1T=1T=1 的视频
首先,在数据进入网络之前,单张图像会被升维。
标准的图像维度是 (B,C,H,W)(B, C, H, W)(B,C,H,W),在输入 3D VAE 时,它会被强行插入一个时间维度,变成 (B,C,1,H,W)(B, C, 1, H, W)(B,C,1,H,W) 。
这样在数据格式上,图像和视频统统变成了 5 维张量,满足了 3D 卷积的输入要求。
2. 核心难点与两种解决方案
将 (B,C,1,H,W)(B, C, 1, H, W)(B,C,1,H,W) 喂给 3D 卷积层时,会面临两个致命阻碍,工程师们是这样化解的:
方案 A:代码层面的"条件路由"(Conditional Execution)
这是最直观的工程解法。网络在执行前向传播(Forward)时,会动态检查当前输入的时间维度 TTT。
-
阻碍 1:感受野不够 。假设 3D 卷积核大小是 3×3×33 \times 3 \times 33×3×3(需要吃进 3 帧),但输入只有 1 帧。
-
化解:复制填充(Replication Padding) 。网络会自动把这一帧复制 3 份,变成 (B,C,3,H,W)(B, C, 3, H, W)(B,C,3,H,W)。这就相当于在一瞬间,这幅画面静止了 3 帧。这样 3×3×33 \times 3 \times 33×3×3 的卷积核就能正常滑动了。
-
阻碍 2:不能被下采样 。VAE 的某些层需要时间压缩(比如
stride=(2, 2, 2),即时间缩小一半,空间缩小一半)。 -
化解:动态步长 。代码里会写一个判断逻辑:如果发现这是一张图像(原本的 T=1T=1T=1),网络会强制将时间步长(Temporal Stride)修改为 1 ,即改为
stride=(1, 2, 2)。 -
结果:空间被压缩了,但时间维度完好无损地保留了下来。
方案 B:数学层面的"降维打击"(Kernel Squeezing)------ 更高级的 SOTA 做法
这是一种更加优雅、计算效率极高的方法,不需要在显存里去复制图像,而是直接去修改卷积核的权重。
假设我们有一个训练好的 3D 卷积核,权重张量为 W3D∈RCout×Cin×Kt×Kh×KwW_{3D} \in \mathbb{R}^{C_{out} \times C_{in} \times K_t \times K_h \times K_w}W3D∈RCout×Cin×Kt×Kh×Kw(例如时间维度 Kt=3K_t = 3Kt=3)。
当我们要用它处理单张图像时,我们可以在数学上把它"压扁"成一个纯粹的 2D 卷积核:
W2D=∑t=1KtW3D:,:,t,:,: W_{2D} = \sum_{t=1}^{K_t} W_{3D}:, :, t, :, : W2D=t=1∑KtW3D:,:,t,:,:
我们直接把这个 3D 卷积核在时间轴上的 3 个切片加权求和 ,得到一个新的权重 W2D∈RCout×Cin×Kh×KwW_{2D} \in \mathbb{R}^{C_{out} \times C_{in} \times K_h \times K_w}W2D∈RCout×Cin×Kh×Kw。
- 为什么这么做是合理的?
如果输入是一张静止的图像(相当于前后帧完全一样),那么 3D 卷积核在时间轴上分别乘以相同像素后的总和,数学上等价于把权重加起来再去乘那个唯一的像素。 - 执行流程 :
当输入 T=1T=1T=1 时,网络根本不调用慢吞吞的Conv3d算子。它直接把 3D 权重求和变成 2D 权重,然后调用极其优化的Conv2d算子,并且使用纯空间的步长stride=(2, 2)。 - 优势:速度极快,显存占用极小,完美绕过了 3D 下采样导致崩溃的 bug,同时依然享受了 3D 预训练模型带来的强大特征表达能力。
总结:统一架构的魅力
为什么非要这么大费周章地用 3D VAE 去处理 2D 图像呢?不能单独弄个 2D VAE 吗?
为了"同源同宗"。
在视频生成任务(尤其是图生视频 Image-to-Video)中,你的起始条件是一张图(第 0 帧),你后续要生成的是视频(第 1 到 T 帧)。
如果你用一个单独的 2D VAE 去编码第一张图,用 3D VAE 去编码后续的视频,这两个 VAE 映射出的"隐空间"(Latent Space)存在天然的特征鸿沟(Domain Gap)。
通过上述的"时间步长退化"或 "权重求和压缩"机制,迫使单帧图像通过 3D VAE 的网络权重。这确保了图像的隐变量和视频的隐变量身处绝对相同的数学空间。这样,下游的 Diffusion 模型在做自回归接力时,才能完美地将这张静态图像作为锚点,顺滑地推演出未来的每一帧。
四、 总结与深度对比
| 特性维度 | 2D VAE | 标准 3D VAE | 3D Causal VAE (当前 SOTA) |
|---|---|---|---|
| 空间压缩 | 是 (例如 8x) | 是 (例如 8x) | 是 (例如 8x) |
| 时间压缩 | 否 (维持原帧数) | 是 (例如 4x) | 是 (例如 4x) |
| 帧间特征融合 | 无,单帧独立 | 有,对称融合 | 有,严格向后(历史)融合 |
| 画面连贯性 (抗闪烁) | 极差,依赖下游对齐 | 极佳 | 极佳 |
| 是否产生"未来泄露" | 否 | 是 | 否 |
| 长视频 / 自回归生成 | 难以保持长期一致性 | 不支持,切块边缘会断裂 | 原生完美支持 |
| 训练与显存成本 | 低 | 极高 (序列长度受限) | 极高 (但支持增量推理/缓存) |
| 典型代表 / 场景 | SD1.5, 早期图片动效插件 | 离线视频压缩、动作识别 | Sora, CogVideoX, SVD |
一句话总结 :
如果把视频生成比作"演奏一段连贯的钢琴曲",2D VAE 只是给每个音符拍了一张清晰的照片;标准 3D VAE 听到了整段旋律,但它必须听完后面的小节才能写出现在的谱子;而 3D Causal VAE 则是一个真正的现场演奏家,它记住了过去所有的旋律,并在这一刻精准地按下当前的琴键,让音乐可以无限延续。
在针对 3D 视觉、视频生成算法工程师或 AI 研究员的面试中,3D VAE 是一个非常高频的考点。它不仅考查你对自编码器基础的理解,更考查你对时空特征建模、显存优化以及生成模型工程化的深度思考。
以下是针对 3D VAE 整理的 5 个面试高频问题及其深度解析:
面试问题
1. 为什么视频生成模型(如 Sora)不直接在像素空间训练,而是非要过一层 3D VAE?
回答要点:
- 计算复杂度减维: 视频数据的原始维度 (T,C,H,W)(T, C, H, W)(T,C,H,W) 极其巨大。通过 3D VAE,我们可以在保持语义信息的前提下,在空间(H,WH, WH,W)和时间(TTT)维度上进行下采样(例如 8×8×48 \times 8 \times 48×8×4),将计算量减少数百倍。
- 训练效率: 在隐空间(Latent Space)中进行扩散(Diffusion)比在像素空间训练要快得多,且能显著降低显存占用。
- 解耦: VAE 负责处理"如何画出清晰的像素",而下游的生成模型(如 DiT)可以专心学习"物理规律和时序逻辑",这种分工极大提升了系统的鲁棒性。
2. 请详细解释 CausalConv3d(因果 3D 卷积)的实现原理,以及它如何解决长视频生成的"接力"问题。
回答要点:
- 实现原理: 核心在于非对称填充(Asymmetric Padding) 。对于大小为 kkk 的卷积核,只在时间轴的左侧(过去)填充 k−1k-1k−1 个单位,右侧(未来)填充 0。
- 因果性保障: 这种设计确保了在计算第 ttt 帧特征时,感受野只覆盖 ≤t\le t≤t 的帧。
- 接力生成(Streamable Inference): 在生成长视频时,我们可以将视频分段处理。因为 VAE 不"偷看"未来,第一段生成的最后一帧隐变量可以作为第二段生成的历史背景(Context),从而保持前后段的无缝连接。如果没有因果性,分段生成的边缘会出现严重的视觉断层(Artifacts)。
3. 在训练 3D VAE 时,除了 MSE 损失,为什么通常还要引入 3D Perceptual Loss 和 GAN Loss?
回答要点:
- MSE 的局限性: MSE 倾向于让像素值趋向平均值,导致生成的视频虽然平滑但非常模糊,缺乏高频细节(如头发丝、纹理)。
- 3D Perceptual Loss (感官损失): 通常使用预训练的 3D 网络(如 I3D 或经过视频微调的 LPIPS)提取特征,强制重建视频在语义特征层面与原视频一致,这有助于保持物体形状和动态的连贯。
- GAN Loss (对抗损失): 通过引入判别器(Discriminator),强制解码器生成的画面必须符合"真实分布",能极大提升画面的清晰度和细节的生动感。
4. 3D VAE 的显存压力巨大,如何处理高分辨率(如 1080p)或长视频的编解码?
回答要点:
- 空间切片(Spatial Tiling): 将画面切割成多个 Patch 独立进入编码器,最后在隐空间拼接。为了消除拼接处的缝隙,通常在边缘设置一定的 Overlap(重叠区),并在解码时进行混合(Blending)。
- 时间切片(Temporal Tiling): 类似于空间切片,但针对时间维度。结合 Causal Conv,可以实现类似 LLM 的 KV-Cache 机制,逐段处理时间序列。
- 混合精度与量化: 使用 BF16 或 FP16 训练,并结合梯度检查点(Gradient Checkpointing)技术。
5. 在视频 VAE 中,时间轴的下采样(Temporal Downsampling)通常比空间下采样小(如空间 8x,时间 4x),这是为什么?
回答要点:
- 采样定率差异: 视频在空间维度的冗余度通常比时间维度更高。过强的时间压缩(如 8x 或 16x)会导致隐变量丢失关键的动作细节,产生"拖影"或"丢帧"感。
- 因果性与质量的权衡: 时间下采样越大,解码器在还原当前帧时需要依赖的历史上下文就越复杂,模型训练难度会呈指数级上升。目前的 SOTA 模型(如 CogVideoX)通常选择 4x 压缩作为质量与效率的平衡点。