作为干了10年运维总监的人,我最怕的不是深夜告警,而是告警来了------人到了,系统却"失联"了。
一次大规模中断,足以让一家企业的全年利润归零。根据New Relic发布的《2025可观测性预测报告》(调查覆盖23个国家、11个行业的1700余名IT管理者),重大IT中断每小时造成中位数损失达200万美元(约合每分钟3.3万美元) ,年度中位数损失高达7600万美元。同时,恒州诚思调研显示,2024年全球数据备份和灾难恢复收入规模约1058.6亿元,预计到2031年将接近1795.3亿元,年复合增长率7.7%------这个市场的爆发式增长,说明企业正在用真金白银投票,回应一个共同的问题。

这篇文章就帮你回答三个最核心的问题:灾难恢复为什么不能再走老路?工单系统凭什么成为灾备的核心基础设施?如何用最小成本构建真正的业务韧性?
问题一:2026年了,灾难恢复为什么不能再"跑脚本、等恢复"?
结论先行:因为业务等不起,客户不会等,监管也不允许你等。
先看两组数据,它们指向同一个方向------
RPO/RTO标准正在被重新定义。 据金仓数据库2026白皮书指出,传统RPO>0、RTO>5分钟的标准已逐渐失效,金融、政务等关键基础设施领域正全面向RPO=0和RTO<30秒的"双零"高标准演进。核心业务系统每中断一分钟,大型金融机构不仅面临直接经济损失,还要承受不可逆的品牌声誉损伤。
灾难恢复服务市场在加速增长。 据全球市场研究机构预测,灾难恢复服务市场2025年规模约199.1亿美元,到2032年将增长至397.6亿美元,年复合增长率达10.38%。这背后是勒索软件激增、混合云架构复杂化、监管合规趋严三重压力叠加的结果。

更残酷的是,2025年10月AWS全球宕机事件持续超过15小时,波及60多个国家、3500家以上企业,全球经济损失估计上亿美元,而这个灾难的起因仅仅是一次自动化脚本的逻辑判定失误。问题出在哪里?不是没有灾备方案,而是灾备方案的执行仍然靠人------人用聊天工具通知、人靠经验判断切换、人凭记忆跑预案。这种"半自动灾备"在分钟级恢复的要求面前,已经撑不住了。
问题二:工单系统为什么是灾难恢复的"中枢神经系统"?
结论先行:因为灾难恢复的本质不是"有备份",而是"能指挥"------谁做什么、按什么顺序做、出了问题谁顶上,这些都需要一个系统来管。
很多人以为灾难恢复是"存储+网络+备份"的技术活。我干了10年运维,最深的体会是:灾难恢复本质上是一场跨团队协同作战,最难的不是技术切换,而是人和流程的调度。
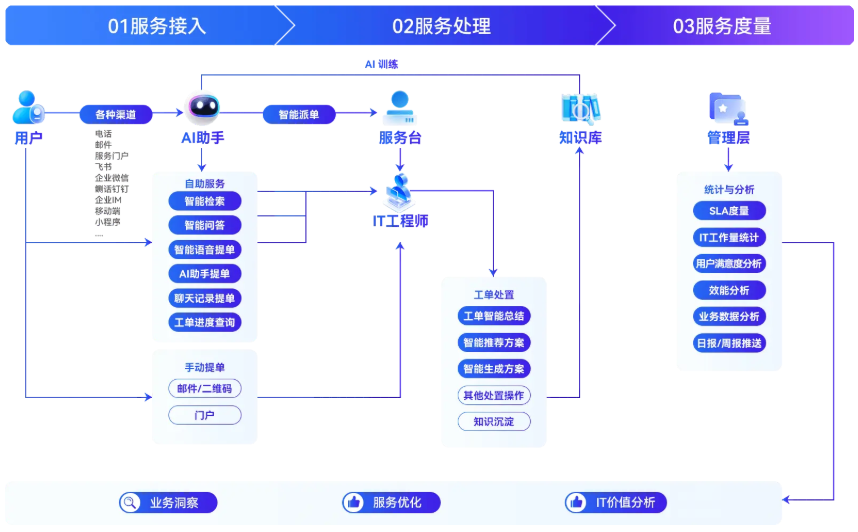
一个优秀的工单系统,在灾难恢复场景中至少解决四个核心问题:
-
事件驱动自动化,而非被动等通知: 当监控系统探测到异常,工单系统应立即自动生成灾备工单,按预设规则精准分派到对应责任人,告警触发到工单生成的时间从分钟级压缩到秒级。在灾备场景下,工单系统还能协调多部门协作,确保故障处理、数据恢复、业务迁移有序进行,根据工单状态和优先级自动调度资源。
-
应急预案即时调用,而非翻文件夹: 真正发生灾难时,没人有时间去查文档。工单系统内嵌的知识库能存储故障案例、解决方案和应急预案,运维人员可迅速调用相关信息,配合标准化流程指引实现快速定位与排除。
-
全流程可追溯,而非事后说不清: 谁接的单、谁做了切换、谁确认恢复------每一步都在工单系统里留痕。复盘时有据可查,合规审计时拿出完整链路。
-
服务台与灾备指挥融为一体: 在灾难恢复事件中,每一个受影响的用户都会同时联系服务台------系统不可用,员工无法工作,需要指引。一个没有预设分类、沟通流程和升级路径的服务台,几分钟内就会瘫痪。
问题三:什么样的工单系统能真正扛住灾难场景?
结论先行:能独立于受影响基础设施运行、具备自动化灾备编排能力的工单系统,才是真"战备级"。
结合10年踩坑经验,我总结出选型三个硬标准:
第一,平台独立不"同归于尽"。 工单平台必须部署在与受灾系统隔离的独立基础设施上(如云原生SaaS架构),当内部系统全面瘫痪时,它依然可用。
第二,自动化灾备编排能力。 预置重大事件工作流模板(如数据中心切换、数据回滚、全员通知),告警触发后自动生成工单并按预设规则分配,关键步骤需自动升级和催办。
第三,知识库驱动快速响应。 在灾难场景下,工单系统内的知识库能自动匹配故障码关联历史解决方案和应急预案,帮助工程师在最短时间内完成定位和修复。
以我们团队正在使用的宝企通运维工单系统为例,它在灾备场景中的几个设计值得一说:内置AI智能客服集成主流大模型,灾难发生时7×24小时自动应答一线问题,极大减轻服务台压力;数据驾驶舱实时监控工单处理全流程,内置可视化预警看板,管理者和应急指挥人员一目了然掌握恢复进度;支持SaaS/本地部署/源码交付,确保工单平台自身不受核心业务基础设施故障影响。更重要的是,宝企通拥有多年SLA优化经验,自定义SLA协议可在灾备场景下为不同优先级的恢复任务设定差异化响应时限,确保关键系统先行恢复。
FAQ:灾难恢复选型最常见三个问题
Q:工单系统和灾难恢复有什么关系?它不就是个派活工具吗?
A:这是最大的误解。灾难恢复的核心挑战不是"有没有备份",而是出事后"谁干什么、按什么顺序干、干完谁确认"。工单系统正是把这些流程标准化、自动化、可追溯化的核心基础设施。没有它,灾难恢复就是一群人拿着手机在群里喊。
Q:我们公司规模不大,需要搞这么复杂的灾备吗?
A:风险不挑规模。据ITIC和Calyptix Security联合研究,SMB因IT中断每小时损失2.5万美元以上,中型及以上企业平均每小时损失超过30万美元,41%的企业报告单次中断损失在100万至500万美元之间。灾备能力不是"大公司的特权",而是所有数字化企业的生存底线。
Q:RPO和RTO到底定多少合适?
A:没有统一标准,取决于你的业务场景。金融交易系统必须追求RPO=0、RTO<30秒;一般业务系统RTO<1小时、RPO<15分钟是业界中上水平。关键不是数值本身,而是你有没有真实演练过------只有约40%的企业信任自己的备份,演练缺失才是最大的风险。
写在最后
10年运维生涯教会我一件事:灾难不会因为你没准备好就不来,但它一定会在你最松懈的时候给你最狠的一击。 2026年,业务连续性已经从"技术指标"变成了"生存战略"。如果你还在用聊天群指挥灾备、靠人记流程做切换,那距离下一次翻车只是时间问题。
而解决这一切的起点,往往就是一个真正靠谱的、能在灾难中独立运行的工单系统------它能做的事情,远比你想象的要多。