除了针对一张表的操作,还有对两张以上的表进行的操作。多表操作的核心 是把两张或多张表的数据,通过共同的关联字段,按指定的规则合并成一个完整的结果集。
比如你要查「订单的订单号、下单用户的姓名、订单里的商品名称」,这些数据分别在订单表、用户表、商品表、订单商品表,必须用联合查询才能一次性拿到结果,不用多次单表查询拼接数据。
多表查询
联合查询
联合查询时多表查询的一种,把多个 SELECT 语句的结果集,按行合并成一个结果集
# UNION:合并后自动去重
SELECT phone FROM user
UNION
SELECT receiver_phone FROM order;
# UNION ALL:直接合并所有数据,不去重,性能更高
SELECT phone FROM user
UNION ALL
SELECT receiver_phone FROM order;UNION是实现联合查询的关键字,ALL表示合并所有数据,distinct是默认值表示去除完全重复的记录。
核心规则:
-
列数相同:每个SELECT语句中的列数必须相等。
-
数据类型兼容:对应位置的列必须拥有相似的数据类型。
-
顺序一致:每个SELECT语句中的列顺序必须一致
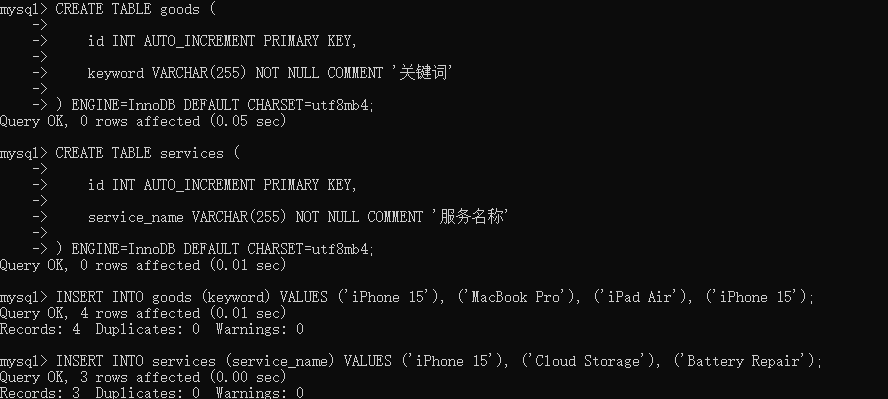
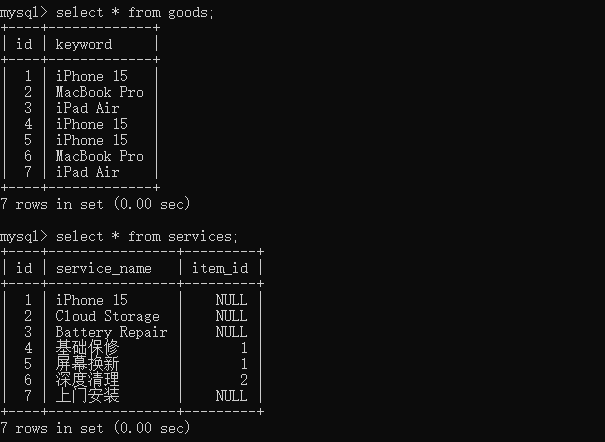
构建商品表与服务表并插入数据
使用UNION联合查询
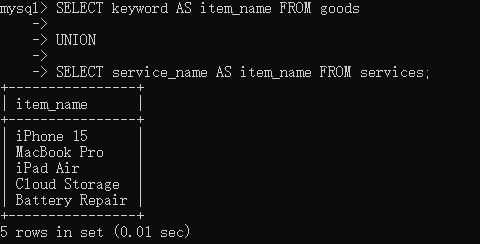
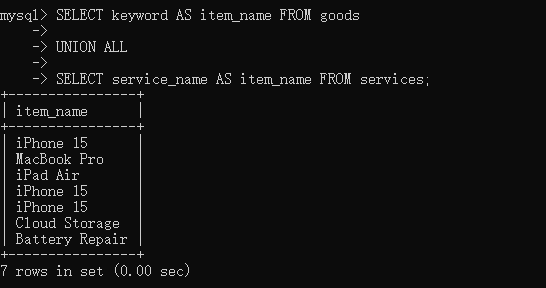
联合查询的结果在只保留第一个select语句对应的字段名称,MySQL仅会根据查询字段出现的顺序对结果进行合并。
连接查询
在实际应用中,可以根据多表之间的关联关系,将多张数据表连到一起,MySQL中常用的连接查询有交叉连接、内连接、左外连接和右外连接
1. 交叉连接
交叉连接 也称为笛卡尔积 ,它的核心逻辑是将左表的每一行 与右表的每一行 进行组合;如果表 A 有 s 字段 n 行,表 B 有 h 字段 m 行,那么执行交叉连接后的结果集将会有(s+h)字段 n*m 行;通过关键字CROSS JOIN实现
select 查询字段 from 表1 cross join 表2;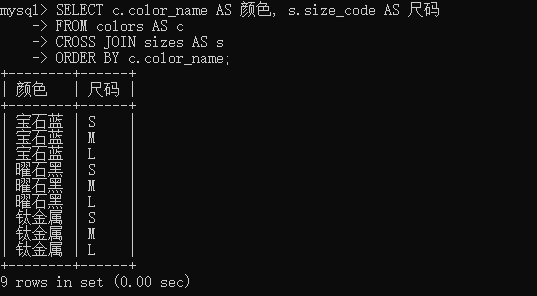
colors数据表中有三种颜色,sizes数据表中有三种尺码,经过连接查询得到9条数据。
-
交叉连接不关心两表之间是否有逻辑关联,只是机械地进行穷举组合
-
在处理大数据量表时要极其小心,因为行数是乘积级增长的。
内连接
内连接是一种非常常见的连接查询,它的核心逻辑是仅返回两个表中满足连接条件的交集部分,如果某行数据在其中一个表中没有匹配的对应项,那么这行数据就不会出现在最终的结果集中。
select 查询字段 from 表1
JOIN 表2 ON 匹配条件;ON用于指定内连接的查询条件,ON与WHERE限定效果一样但ON能节省性能。
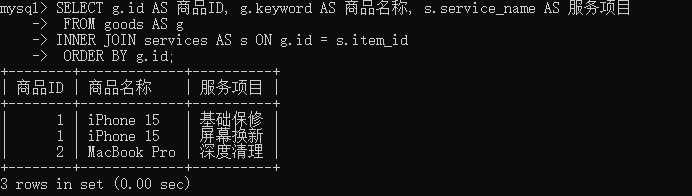
在查询数据时,如果两个表中有同名的字段,为了避免重名出现错误,使用**"数据表.字段名"**的方式进行区分。
左外连接
左外连接的核心 是以左表为基准,返回左表的所有行,以及右表中与之匹配的行,如果左表的某行在右表中没有匹配,结果集中该行对应的右表字段将显示为NULL。
select 查询字段 from 表1
left join 表2 on 匹配条件;关键字left join左边的表被称为左表/主表,右边的表被称为右表/从表
想象你在整理一个清单:
-
左表:你拥有的所有物品。
-
右表:这些物品的保修信息。
-
左连接的结果:你会得到你所有的物品清单。有保修的会显示保修期,没保修的则会留空(NULL)
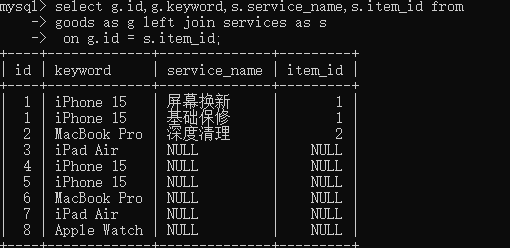
在左连接查询中,即使左表中有的数据跟右表中任何数据都不匹配,也会在查询结果保留该数据。
右外连接
右外连接 的逻辑与左连接正好相反:它以右表为基准,返回右表的所有行,以及左表中与之匹配的行。
select 查询字段
from 表1 right join 表2 on 匹配条件
外连接与内连接的区别:
-
内连接是只有当两边都有对应数据时才返回数据结果
-
外连接至少会完整保留其中一张表的所有行
子查询
通俗来讲,子查询就是嵌套在另一个 SQL 查询内部的查询。你可以把它理解为"查询中的查询",这个子查询语句是一条完整、独立的select语句。
在 SQL 执行时,数据库会先运行子查询,将其结果作为主查询的输入条件或数据源。在含有子查询的语句里,子查询必须书写在括号内 ,然后再将返回的结果作为外层SQL语句的过滤条件;如果一个语句里含有多层子查询,执行顺序是从最里层的子查询开始。
按照返回的内容子查询可以分为标量子查询、行/列子查询、表子查询 ,按照子查询的出现位置可以分为where子查询和from子查询。
标量子查询
标量子查询的结果只返回"一个单元格"的数据(即单行、单列的一个具体数值,如一个数字、一个字符串或一个日期)
-
必须放在括号内
-
结果唯一
where 条件判断 {=|<>}
(select 字段名 from 数据源 [where][group by][having][order by][limit])
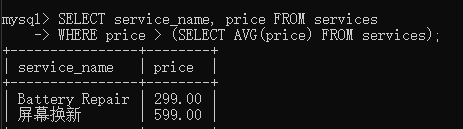
这里有两个过程:
-
子查询运行结果: 数据库先算这一步,它只返回一个数字(服务的平均价格)。因为它是"一行一列",所以它是标量的
-
主查询运行结果: 主查询拿到这个数字后,去执行where price > 判断条件。主查询最后返回多少行、多少列。
如果子查询返回了多行数据,主查询不知道该跟哪一个比,就会发生报错
SELECT service_name
FROM services
WHERE price > (SELECT price FROM services);
#报错!子查询返回了多行价格,主查询不知道该跟哪一个比。列子查询
列子查询 是指子查询的结果返回了一列多行的数据
where 条件判断 (in|not in)
(select 字段名 from 数据源 [where][group by][having][order by][limit])因为它的结果不再是一个单一的数值,而是一个列表 ,所以你不能再使用简单的=或>进行条件判断,需要使用比较函数IN()或者NOT IN()来进行条件判断。
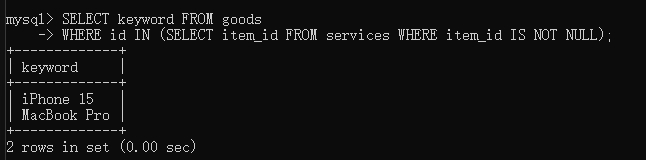
括号里的子查询是一个列子查询,它会返回一串 ID,比如 (1, 1, 2),主查询拿着goods表里面的id一个个匹配是否在列表里面。
行子查询
行子查询是指子查询的结果返回了"一行多列"的数据,行子查询返回一个包含多个属性的元组,它允许你同时比较多个字段的值。
where (字段名...) =
(select 字段名... from 数据源 [where][group by][having][order by][limit])
SELECT service_name, item_id, price
FROM services
WHERE (item_id, price) = (
SELECT item_id, price
FROM services
WHERE service_name = '深度清理'
LIMIT 1
);表子查询
表子查询 返回的结果是一个多行多列的数据集
select 字段 from (select语句) as 别名
[where][group by][having][order by][limit];-
在from子句中使用表子查询时,MySQL 要求必须给这个子查询的结果起一个别名,否则会报错
-
用于对原始数据进行"二次加工"。先通过子查询筛选、聚合出一部分数据,主查询再基于这些数据进行进一步操作
SELECT
temp.item_id,
temp.avg_price
FROM (
SELECT item_id, AVG(price) AS avg_price
FROM services
GROUP BY item_id
) AS temp
#必须起别名,这里叫 temp
WHERE temp.avg_price > 100;总而言之,子查询本质上就是在select语句的where里面再套一个select语句
子查询关键字
-
IN / NOT IN:判断某个值是否在子查询返回的列表中
-
any:只要主查询的值与子查询返回的任何一个值比较结果为true,条件就成立
-
all:主查询的值必须与子查询返回的所有值比较结果都为true,条件才成立
any和all都必须配合比较操作符(>、=、<)才能使用
1. 带有关键字any的子查询
where 表达式 比较运算符 any(子查询语句)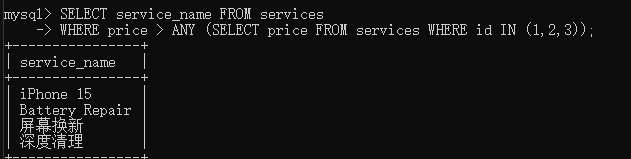
查询价格比任意一个 基础服务(假设 ID 为 1,2,3)贵的服务,只要比这三个里最小的那个大,就会被选中
2. 带有关键字all的子查询
SELECT service_name FROM services
WHERE price > ALL (SELECT price FROM services WHERE item_id = 1);查询比所有服务平均价格都要高的服务。
外键约束
在数据库设计时,为了保证不同表中相同含义的数据的一致性和完整性 ,可以为数据添加外键约束 。简单来说,外键是一个表中的字段,它的值必须匹配另一个表的主键。它就像一条"逻辑绳索",把两张表牢牢地绑在一起。
-
只有InnoDB存储引擎支持外键约束
-
建立外键约束的两个数据表相关字段的数据类型必须相似,也就是要求字段的数据类型可以相互转换
-
主表则必须是有主键约束或unique约束
为什么需要外键约束?
-
保证数据完整性:子表里的数据,必须在主表里存在,防止随便创建一个子表数据(脏数据)
-
防止随意删除主表数据
-
实现级联操作
添加外键约束
1. 在建表时指定外键
CREATE TABLE services (
id INT AUTO_INCREMENT PRIMARY KEY,
service_name VARCHAR(255) NOT NULL,
item_id INT,
# 定义外键约束
CONSTRAINT fk_gooos_item
FOREIGN KEY (item_id) REFERENCES gooos(id)
) ENGINE=InnoDB;-
关键字constraint用于定义外键约束的名称,如果省略,MySQL会自动生成一个名称。
-
关键词foreign key ...references向数据表添加外键约束
2. 为已有表添加外键
ALTER TABLE services
ADD CONSTRAINT fk_gooos_item
FOREIGN KEY (item_id) REFERENCES gooos(id);删除外键约束
ALTER TABLE services DROP FOREIGN KEY fk_gooos_item;MySQL 在创建外键时,通常会同步创建一个同名的索引(Index)。如果你想彻底清理干净,删除外键后还需要手动删除索引
ALTER TABLE services DROP INDEX fk_gooos_item;使用外键约束也有一定的劣势
-
使用外键约束会带来额外开销
-
主表被锁定时,会引发从表也被锁定
-
删除主表的数据时,需要先删除从表的数据