一、vllm的官方链接
https://docs.vllm.ai/en/latest/examples/features/speculative_decoding/?h=speculative+decoding
https://github.com/vllm-project/vllm/tree/main/examples/features/speculative_decoding
服务端启用投机解码:
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Llama-3-70B \
--speculative-model meta-llama/Llama-3-8B
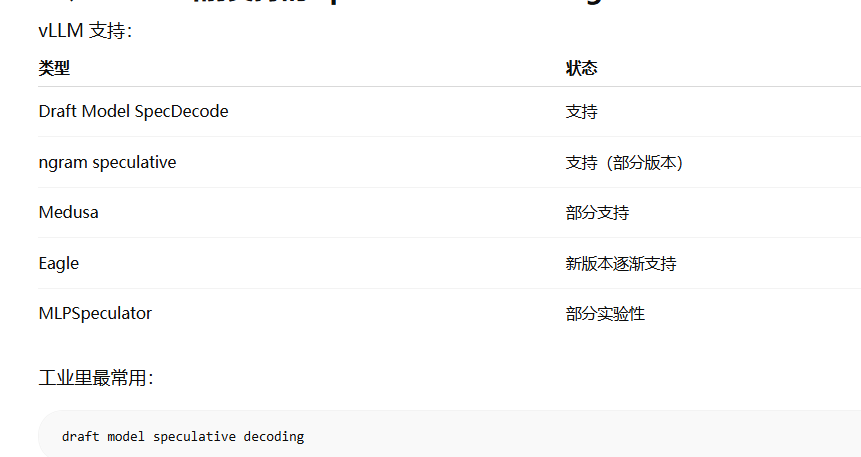
--num-speculative-tokens 4 ## 小模型一次推测几个token , 2-4常用vllm 投机解码支持的范式:
二、客户端访问示例
# Draft Models
The following code configures vLLM in an offline mode to use speculative decoding with a draft model, speculating 5 tokens at a time.
```python
from vllm import LLM, SamplingParams
prompts = ["The future of AI is"]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(
model="Qwen/Qwen3-8B",
tensor_parallel_size=1,
speculative_config={
"model": "Qwen/Qwen3-0.6B",
"num_speculative_tokens": 5,
"method": "draft_model",
},
)
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
To perform the equivalent launch in online mode, use the following server-side code:
```bash
vllm serve Qwen/Qwen3-4B-Thinking-2507 \
--host 0.0.0.0 \
--port 8000 \
--seed 42 \
-tp 1 \
--max_model_len 2048 \
--gpu_memory_utilization 0.8 \
--speculative_config '{"model": "Qwen/Qwen3-0.6B", "num_speculative_tokens": 5, "method": "draft_model"}'
```
The code used to request as completions as a client remains unchanged:
??? code
```python
from openai import OpenAI
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
# defaults to os.environ.get("OPENAI_API_KEY")
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
# Completion API
stream = False
completion = client.completions.create(
model=model,
prompt="The future of AI is",
echo=False,
n=1,
stream=stream,
)
print("Completion results:")
if stream:
for c in completion:
print(c)
else:
print(completion)
```
!!! warning
Note: Please