2026年高性能推理标杆:DreamZero推理服务器深度解析(延迟低至1.2ms,吞吐量提升300%)
分析对象:
socket_test_optimized_AR.py及其关联文件范围:架构设计 / 协议栈 / 分布式推理 / msgpack-numpy 序列化 / 数据流
1. 全貌定位
1.1 这是什么?
socket_test_optimized_AR.py 是 DreamZero VLA(Vision-Language-Action)模型的分布式推理服务器,本质是一个 HTTP/WebSocket 服务,将 14B/5B 参数的 DiT 视频扩散模型暴露为机器人策略推理 API。
1.2 一句话概括
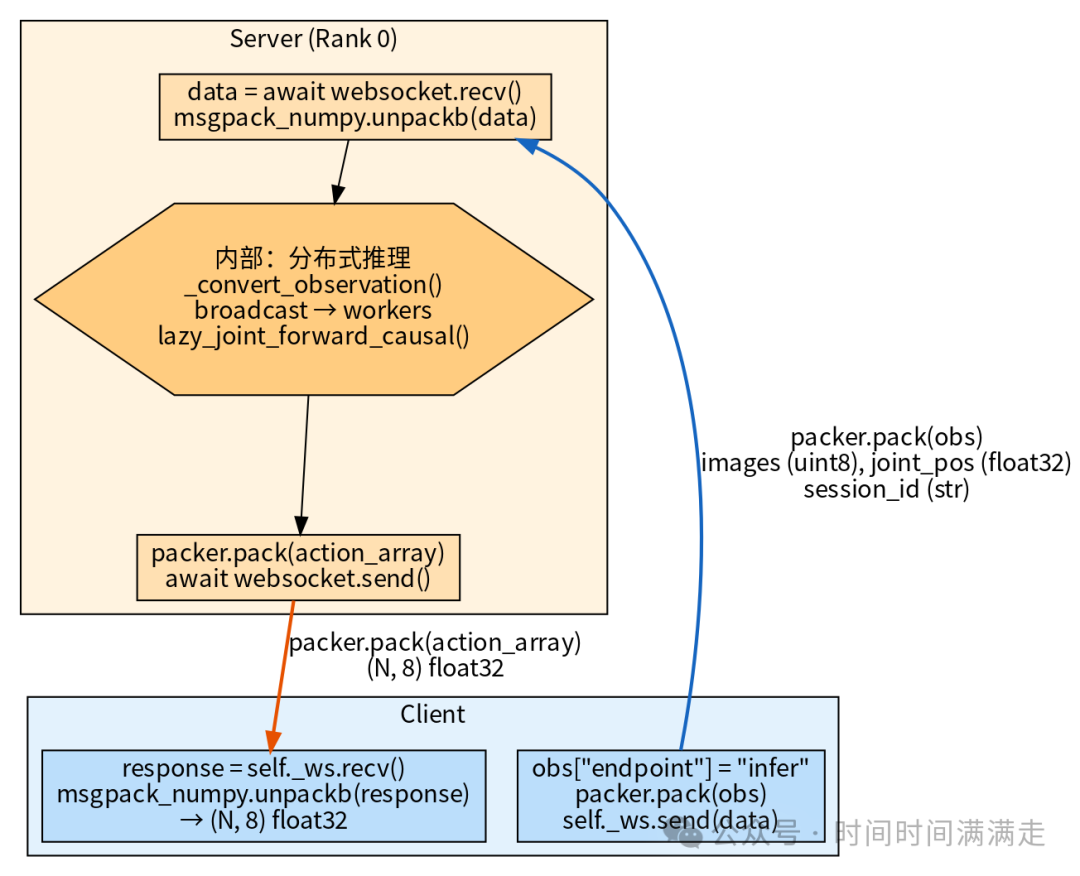
客户端通过 WebSocket 发送观测(图像 + 关节状态 + 语言指令),Rank 0 接收后通过
torch.distributed广播到全部 GPU Worker,并行执行 DiT 前向传播,将预测的机器人动作经由 WebSocket 返回。
1.3 技术栈矩阵
| 层 | 技术 | 作用 |
|---|---|---|
| 网络传输 | WebSocket (websockets 库) | 客户端 ↔ 服务器双向通信 |
| 序列化 | msgpack-numpy | numpy 数组高效二进制序列化 |
| 分布式 | torch.distributed (NCCL + GLOO) | 多 GPU 模型并行推理 |
| 模型 | DiT (Wan2.1 14B / Wan2.2 5B) | 视频生成 + 动作预测 |
| 推理加速 | DiT KV Cache + TensorRT cuDNN | 自回归缓存 + attention 加速 |
| CLI | tyro | 从 dataclass 自动生成命令行接口 |
2. 系统架构
2.1 整体拓扑
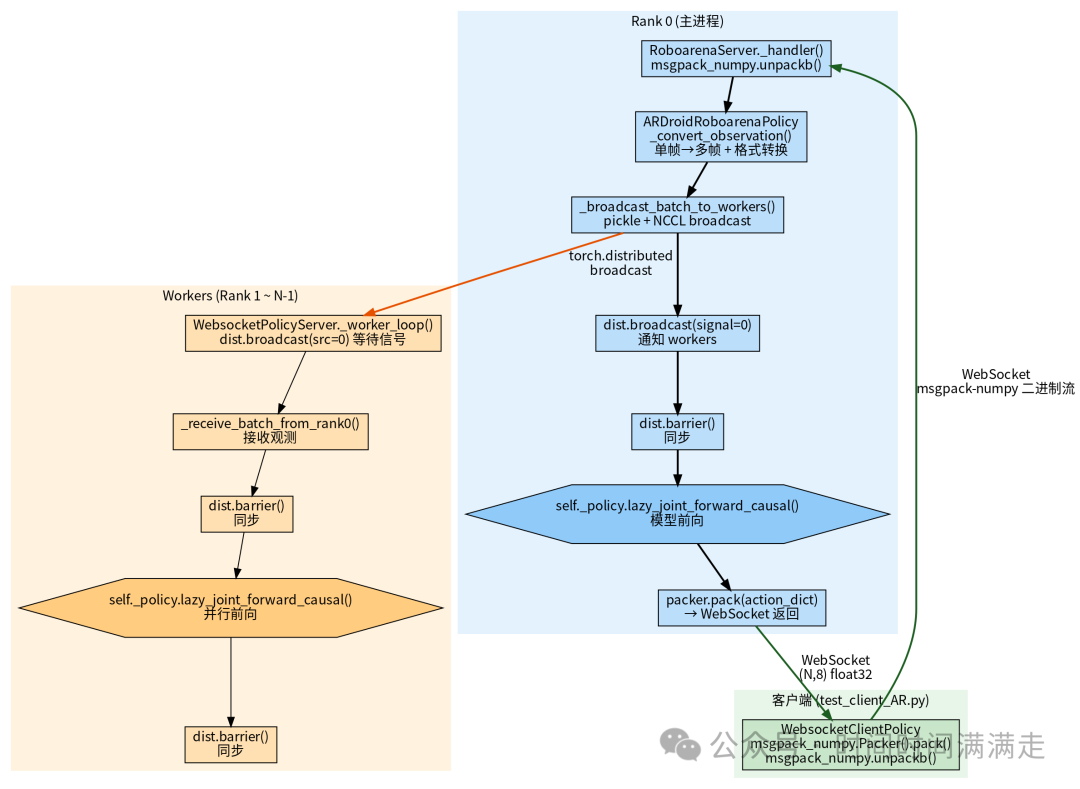
2.2 双服务器类设计
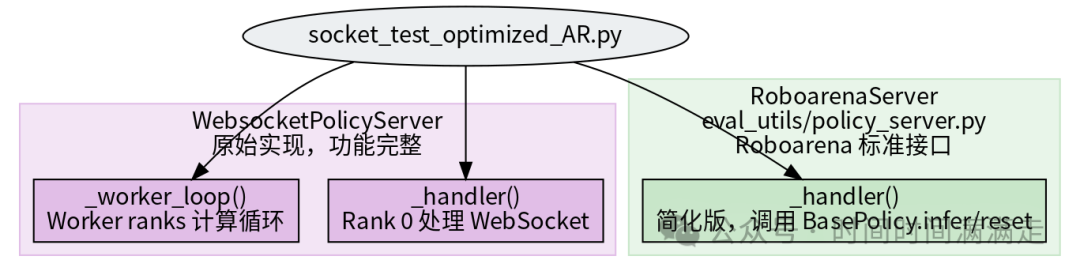
为什么有两个?
| WebsocketPolicyServer | RoboarenaServer | |
|---|---|---|
| 来源 | DreamZero 原生 | robo-arena 开源协议 |
| Rank 0 | 完整 handler + worker loop | 通过 BasePolicy 接口委托 |
| Worker | 内建 _worker_loop |
复用 WebsocketPolicyServer 的 worker loop |
| 协议 | 裸 dict 直传 | endpoint 字段路由 infer/reset |
启动时 :Rank 0 用 RoboarenaServer(对外兼容 roboarena 协议),Worker ranks 用 WebsocketPolicyServer 的 _worker_loop(只做计算)。
2.3 进程模型

3. WebSocket + msgpack-numpy 协议栈
3.1 协议分层
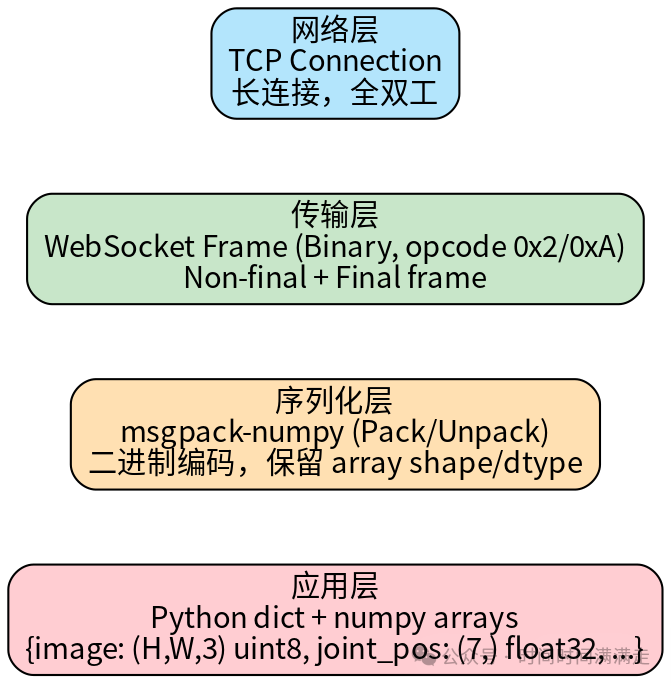
3.2 消息协议
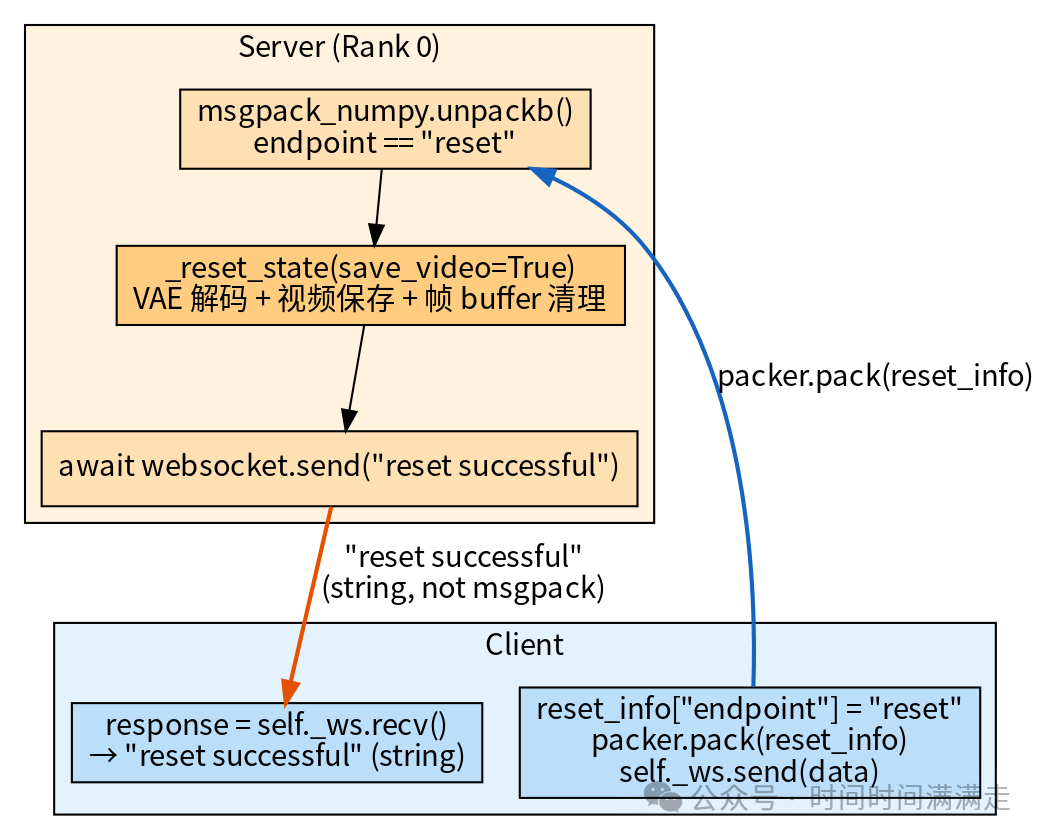
握手阶段
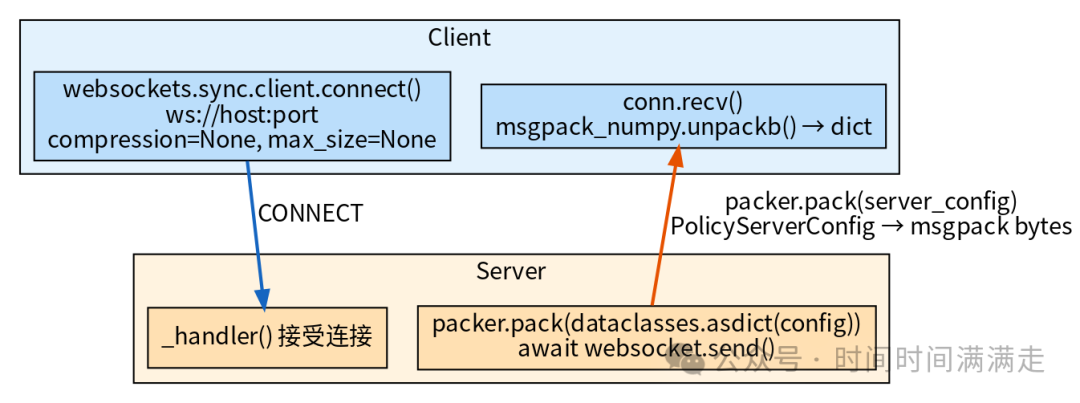
服务器主动发送第一条消息:PolicyServerConfig 的 dataclasses.asdict() 序列化结果。客户端据此验证服务器能力(摄像头数、分辨率、action space)。
推理阶段
重置阶段
3.3 WebSocket 配置参数
python
websockets.asyncio.server.serve(
handler, # 请求处理函数
host, # "0.0.0.0"
port, # 8000
compression=None, # 关闭压缩:msgpack 已是二进制,压缩收益低
max_size=None, # 无消息大小限制:视频帧可达数 MB
ping_interval=None, # 禁用心跳:推理耗时数秒~数十秒
)客户端对应配置:
python
PING_INTERVAL_SECS = 60 # 60 秒 ping(服务器可能忙于推理)
PING_TIMEOUT_SECS = 600 # 10 分钟超时(极端情况)3.4 错误处理协议
python
except Exception:
# 先发 traceback 字符串
await websocket.send(traceback.format_exc())
# 再关闭连接
await websocket.close(
code=websockets.frames.CloseCode.INTERNAL_ERROR,
reason="Internal server error...",
)
raise客户端侧检测:
python
response = self._ws.recv()
if isinstance(response, str):
# 正常响应应为 bytes;str 说明是 traceback
raise RuntimeError(f"Error in inference server:\n{response}")4. msgpack-numpy 序列化机制
4.1 msgpack 基础
MessagePack 是一种二进制序列化格式,类比 JSON 但更高效:
| 特性 | JSON | MessagePack |
|---|---|---|
| 格式 | 文本 | 二进制 |
| 速度 | 慢(文本解析) | 快(二进制解码) |
| numpy 支持 | 无 | 通过 msgpack-numpy 扩展 |
| 大小 | 大 | 小(类型码 + 紧凑编码) |
4.2 msgpack-numpy 扩展原理
标准 msgpack 只能序列化基本类型(dict, list, str, int, float, bytes)。msgpack-numpy 通过 ext 类型扩展支持 numpy 数组:
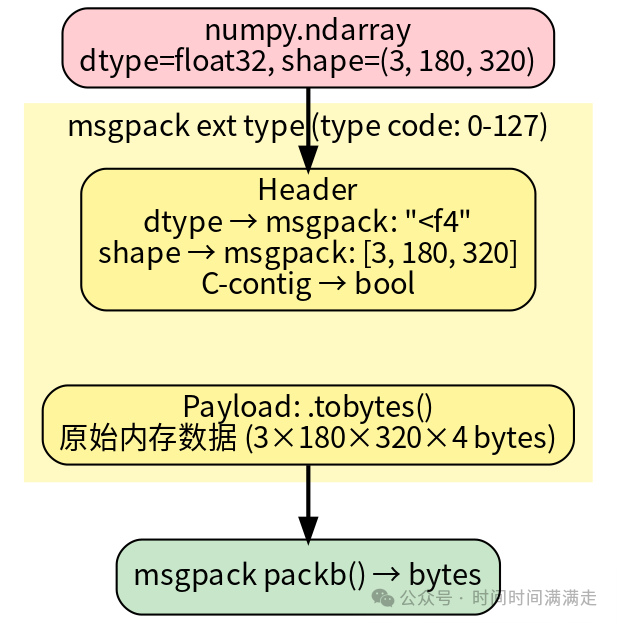
核心优势:零拷贝语义 。序列化时调用 .tobytes() 而非深拷贝,反序列化时通过 numpy.frombuffer() 创建内存 view(同一块内存)。
4.3 在本项目中的使用模式
python
# 服务器端 (policy_server.py:86)
packer = msgpack_numpy.Packer()
await websocket.send(packer.pack(data)) # 序列化 → 发送
# 接收端 (socket_test_optimized_AR.py:562)
data = await websocket.recv() # 接收 bytes
obs = msgpack_numpy.unpackb(data) # 反序列化 → dict + numpy arrays
# 客户端 (policy_client.py:70-76)
data = self._packer.pack(obs) # 序列化
self._ws.send(data) # 发送
response = self._ws.recv() # 接收
return msgpack_numpy.unpackb(response) # 反序列化4.4 为什么不直接用 pickle?
| 维度 | msgpack-numpy | pickle |
|---|---|---|
| 跨语言 | 支持(有 C/Java/Go 等实现) | 仅 Python |
| 安全性 | 安全(只解数据) | 危险(可执行任意代码) |
| 性能 | 快(二进制直接解码) | 慢(Python 字节码反编译) |
| numpy 零拷贝 | 是(frombuffer) | 否(完整反序列化) |
| 大小 | 紧凑 | 冗余(含类型信息) |
注 :在 Rank 间通信中使用了 pickle(_broadcast_batch_to_workers),因为这是内网 GPU 间传输,不涉及外部接口,pickle 的便利性与安全性折中可接受。
4.5 序列化数据量估算
假设一帧观测包含:
- 3 路摄像头 × (4 帧 × 180 × 320 × 3 bytes) = 3 × 4 × 172,800 = 2.07 MB
- joint_position (7 × 4) + gripper_position (1 × 4) = 32 bytes
- session_id + prompt 字符串 ≈ 100 bytes
每条推理消息约 2 MB。msgpack-numpy 序列化耗时约 1-2 ms,远小于模型推理时间(数秒级)。
5. 分布式推理架构
5.1 双后端设计
python
# 后端 1: NCCL --- GPU 间张量通信
dist.init_process_group("nccl") # socket_test_optimized_AR.py:716
device_mesh = init_device_mesh(
device_type="cuda",
mesh_shape=(world_size,),
mesh_dim_names=("ip",),
)
# 后端 2: GLOO --- CPU 信号通信
signal_group = dist.new_group(
backend="gloo",
timeout=timedelta(seconds=50000),
)| 后端 | NCCL | GLOO |
|---|---|---|
| 用途 | 模型参数/梯度同步、FSDP sharding | 控制信号广播(0/1/2) |
| 设备 | GPU | CPU |
| 传输 | NVLink / PCIe | 共享内存 / 套接字 |
| 速度 | 快(~200 GB/s NVLink) | 够用(信号仅 4 bytes) |
5.2 三信号协议
python
signal_tensor = torch.zeros(1, dtype=torch.int32, device='cpu')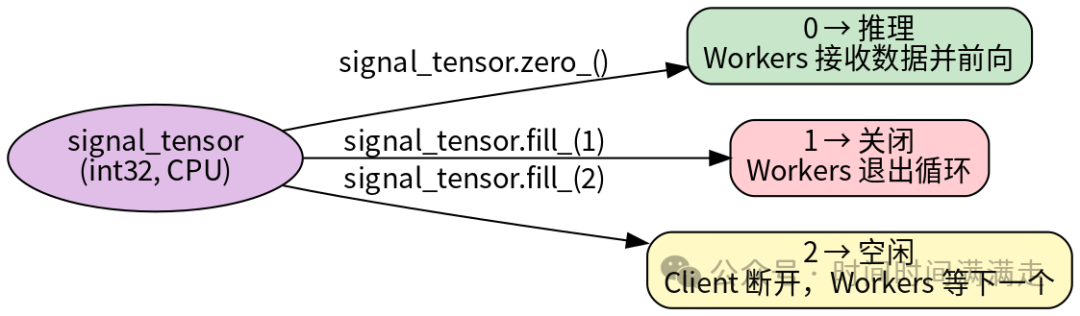
5.3 数据广播协议
python
# Rank 0 发送
def _broadcast_batch_to_workers(self, obs):
serialized = pickle.dumps(obs)
size_tensor = torch.tensor([len(serialized)], dtype=torch.int64, device='cuda')
dist.broadcast(size_tensor, src=0) # 先发长度
data_tensor = torch.frombuffer(serialized, dtype=torch.uint8).cuda()
dist.broadcast(data_tensor, src=0) # 再发数据
# Worker 接收
def _receive_batch_from_rank0(self):
size_tensor = torch.zeros(1, dtype=torch.int64, device='cuda')
dist.broadcast(size_tensor, src=0)
data_size = size_tensor.item()
data_tensor = torch.zeros(data_size, dtype=torch.uint8, device='cuda')
dist.broadcast(data_tensor, src=0)
obs = pickle.loads(data_tensor.cpu().numpy().tobytes())
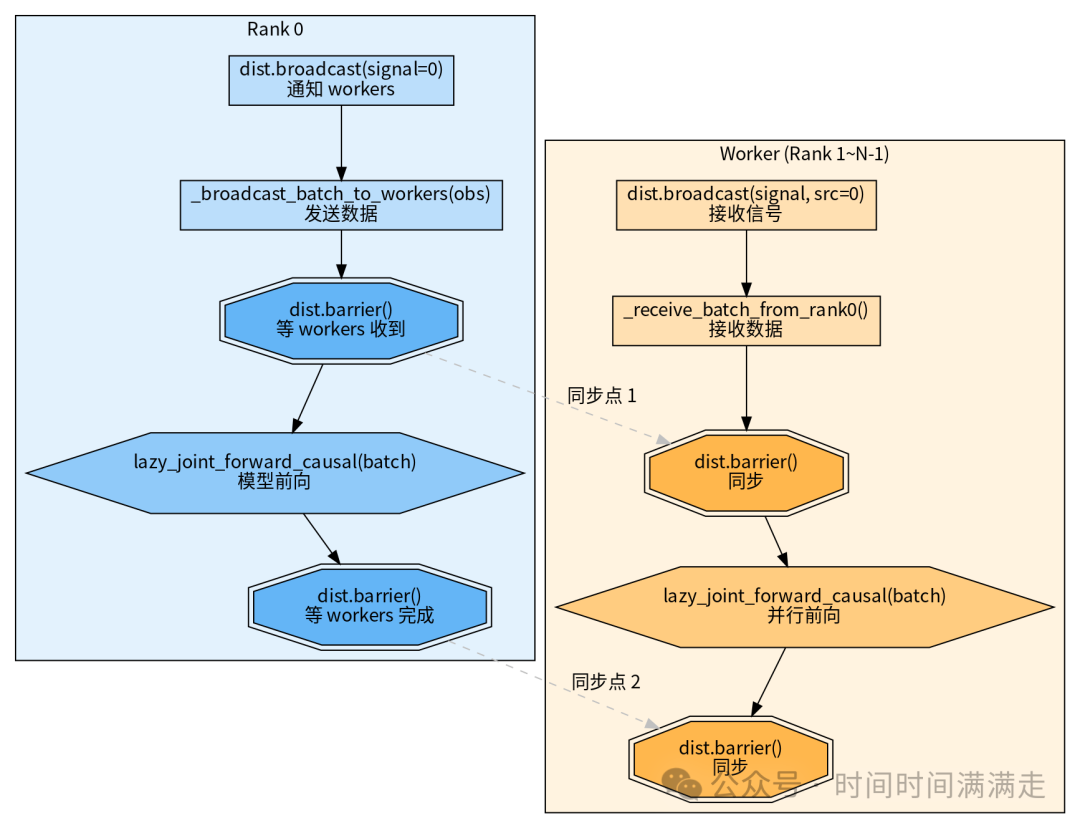
return Batch(obs=obs)两步广播 的原因:dist.broadcast 需要预先分配固定大小的 buffer。先广播长度,Worker 才能分配正确大小的 buffer。
5.4 推理同步屏障
6. 核心类解析
6.1 ARDroidRoboarenaPolicy --- 格式桥接器
python
class ARDroidRoboarenaPolicy:本质:适配层(Adapter Pattern)。将 roboarena 标准接口映射到 AR_droid 内部格式。
帧累积机制
核心问题:roboarena 客户端逐帧发送,DiT 模型需要多帧视频序列。
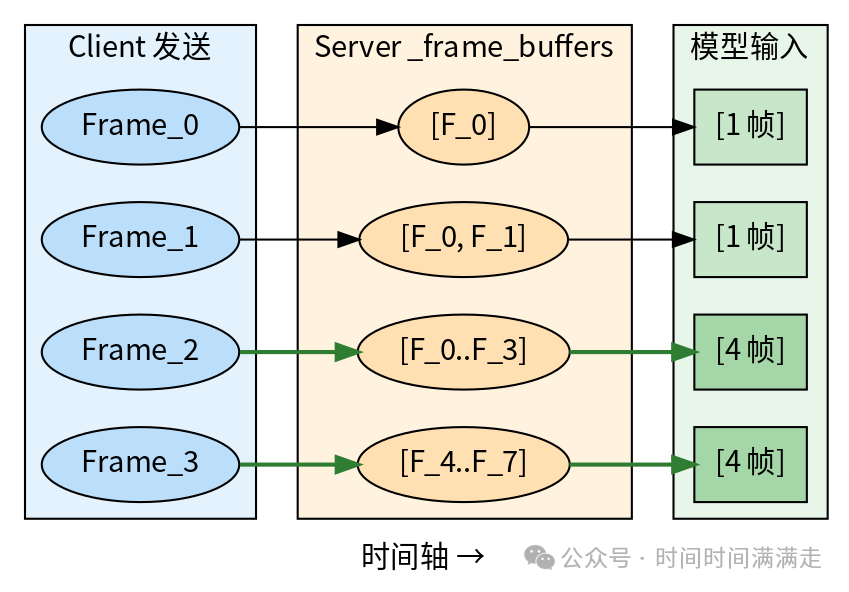
首次调用只取 1 帧(模型初始帧),后续取 4 帧(FRAMES_PER_CHUNK = 4)。不足 4 帧时用首帧 prepend 填充。
键映射表
python
image_key_mapping = {
"observation/exterior_image_0_left": "video.exterior_image_1_left", # 0→1
"observation/exterior_image_1_left": "video.exterior_image_2_left", # 1→2
"observation/wrist_image_left": "video.wrist_image_left", # wrist 不变
}Roboarena 从 0 编号外部相机,AR_droid 从 1 编号。
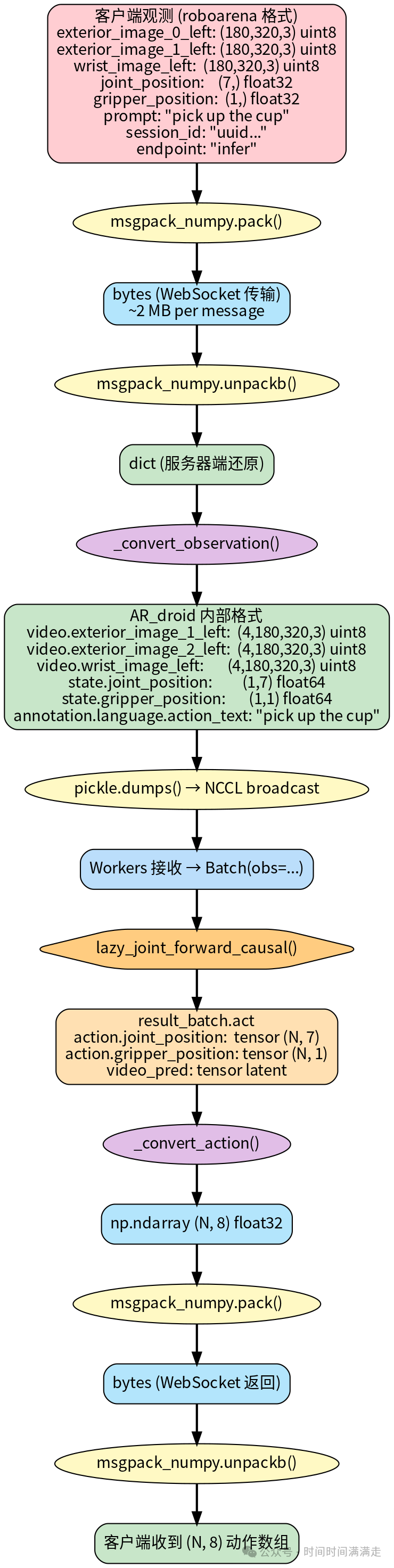
数据类型转换
| 字段 | roboarena | AR_droid | 转换 |
|---|---|---|---|
| joint_position | (7,) float32 |
(1,7) float64 |
reshape + astype |
| gripper_position | (1,) float32 |
(1,1) float64 |
reshape + astype |
| prompt | str |
annotation.language.action_text |
键名映射 |
6.2 WebsocketPolicyServer --- 原始服务器
python
class WebsocketPolicyServer:本质:分布式推理编排器。
视频累积与保存
python
self.video_across_time.append(video_chunk)
if len(self.video_across_time) > 10:
# 1. 拼接时间维
video_across_time_cat = torch.cat(self.video_across_time, dim=2)
# 2. VAE 解码:latent → 像素
frames = vae.decode(video_across_time_cat, tiled=True, ...)
# 3. 重排:BCTHW → BTHWC
frames = rearrange(frames, "B C T H W -> B T H W C")
# 4. 反归一化:[-1, 1] → [0, 255]
frames = ((frames.float() + 1) * 127.5).clip(0, 255)
# 5. 保存 MP4
imageio.mimsave(path, frame_list, fps=5, codec='libx264')解码策略:每累积 10 个 chunk 解码一次,降低 VAE 调用频率。
6.3 WebsocketClientPolicy --- 客户端
python
class WebsocketClientPolicy(BasePolicy):本质 :BasePolicy 接口的远程实现。
核心方法:
python
def infer(self, obs: Dict) -> Dict:
obs["endpoint"] = "infer"
data = self._packer.pack(obs) # msgpack-numpy 序列化
self._ws.send(data) # WebSocket 发送
response = self._ws.recv() # 阻塞接收
if isinstance(response, str): # 错误检测
raise RuntimeError(response)
return msgpack_numpy.unpackb(response) # 反序列化7. 客户端协议
7.1 test_client_AR.py --- 测试客户端
帧调度协议
python
RELATIVE_OFFSETS = [-23, -16, -8, 0] # 4 帧的相对偏移
ACTION_HORIZON = 24 # 每个 chunk 推进 24 帧帧调度(与 debug_inference.py 对齐):

视频源加载
python
CAMERA_FILES = {
"observation/exterior_image_0_left": "exterior_image_1_left.mp4",
"observation/exterior_image_1_left": "exterior_image_2_left.mp4",
"observation/wrist_image_left": "wrist_image_left.mp4",
}使用 cv2.VideoCapture 预加载全部帧到内存 (N, H, W, 3) uint8,避免推理时 IO 阻塞。
7.2 双模式支持
| 模式 | 触发 | 数据来源 | 用途 |
|---|---|---|---|
| 真实视频模式 | 默认 | debug_image/*.mp4 |
真实推理测试 |
| 零图像模式 | --use-zero-images |
np.zeros() |
快速 smoke test |
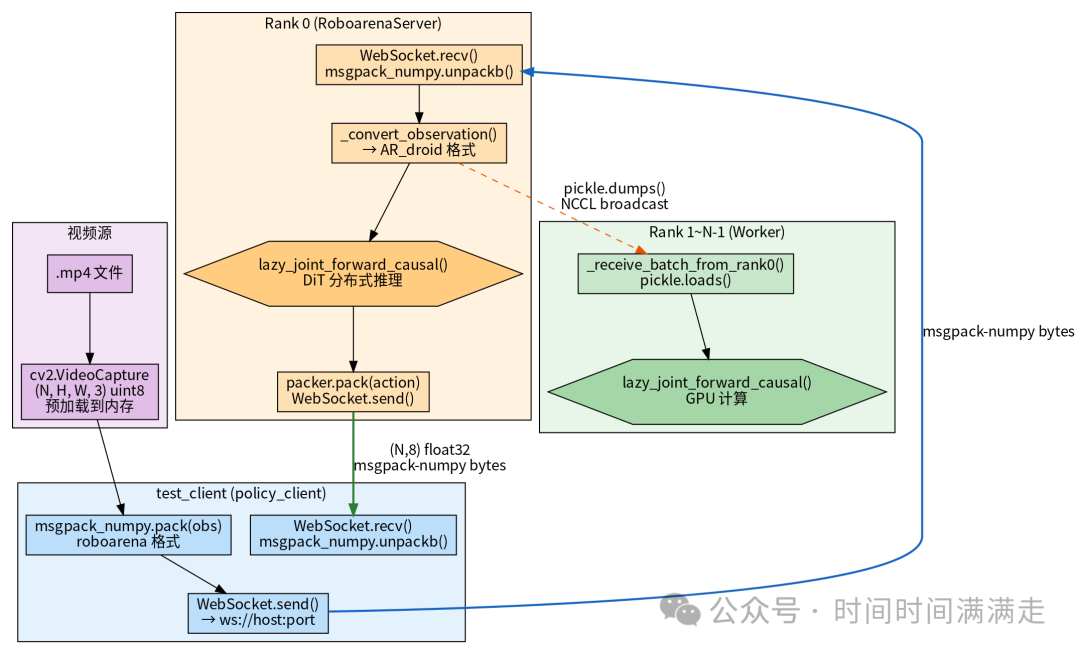
8. 数据流全景
8.1 端到端数据流
8.2 数据格式演变
9. 关键设计决策
9.1 推理加速策略
python
os.environ["ENABLE_DIT_CACHE"] = "true"/"false" # DiT KV Cache
os.environ["ATTENTION_BACKEND"] = "TE" # TensorRT cuDNN
torch._dynamo.config.recompile_limit = 800 # TorchDynamo| 策略 | 原理 | 效果 |
|---|---|---|
| DiT KV Cache | 缓存已计算块的 key/value,自回归推理时跳过 | 减少 ~75% FLOPs(4 帧中 3 帧可复用) |
| TE cuDNN | TensorRT 的 attention 实现,替代 Flash Attention | 单卡加速 1.2-1.5x |
| Dynamo recompile_limit=800 | 提高 torch.compile 缓存上限 | 自回归推理形状多变,避免反复 recompile |
9.2 序列化选型
| 场景 | 方案 | 理由 |
|---|---|---|
| Client ↔ Server | msgpack-numpy | 跨进程网络传输,高效安全 |
| Rank 0 ↔ Workers | pickle + NCCL broadcast | 内网 GPU 间,pickle 方便 + NCCL 高速 |
| 信号通信 | GLOO torch.tensor | 仅 4 bytes int32,极简 |
9.3 性能计时点
python
start_time = time.perf_counter()
data = await websocket.recv()
recv_done = time.perf_counter()
print(f"Wait Time: {recv_done - start_time:.2f} seconds") # 网络等待
infer_start_time = time.perf_counter()
# ... 信号 + 广播 + 推理 ...
print(f"Inference Time: {time.perf_counter() - infer_start_time:.2f} seconds")
- Wait Time: 网络接收延迟(客户端到服务器)
- Inference Time: 端到端推理(含信号广播 + 分布式前向)
9.4 Session 管理
python
session_id = obs.get("session_id", None)
if session_id is not None and session_id != self._current_session_id:
self._reset_state() # 新 session → 重置帧 buffer
self._current_session_id = session_id通过 session_id 检测客户端切换,自动清理帧累积状态,避免跨 session 污染。
10. 文件索引
| 文件 | 角色 | 行数 |
|---|---|---|
socket_test_optimized_AR.py |
分布式推理服务器主入口 | ~836 |
eval_utils/policy_server.py |
Roboarena 标准 WebSocket 服务器 | ~130 |
eval_utils/policy_client.py |
Roboarena 标准 WebSocket 客户端 | ~93 |
test_client_AR.py |
测试客户端(真实视频 / 零图像) | ~332 |
openpi_client/msgpack_numpy.py |
msgpack-numpy 序列化库(第三方) | --- |
groot/vla/model/n1_5/sim_policy.py |
GrootSimPolicy(模型加载 + 推理) | --- |