前提介绍:
(1).o/.obj的名字其实叫可重定位文件
(2)所有的二进制文件(动/静态库,可执行文件,.o文件)都有自己的格式叫EIF,也可以说这些文件都是有一定格式的,或者可以说EIF自身就是二进制文件。
1.对EIF的介绍
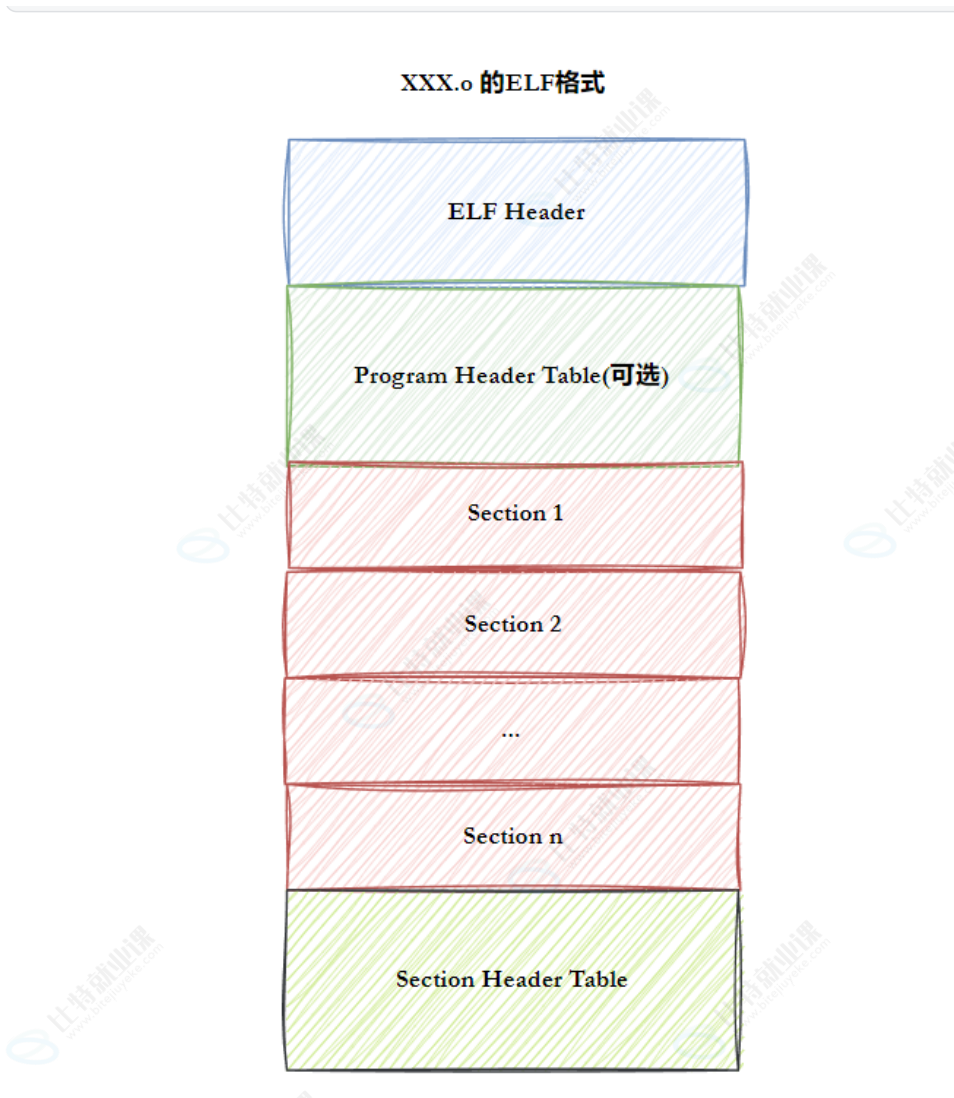
下面通过一些指令来说明这张图的详情
(1)指令size
//size + 二进制文件,查看该文件的EIF属性
size code.o
ubuntu@VM-0-2-ubuntu:~/test$ size code.o
text data bss dec hex filename
32 0 0 32 20 code.o首先介绍:代码节(.text):保存机器指令,数据节(.data):保存变量。这些数据都是属于section区的,且一个section中存的基本是同一个属性的数据。
每一个.o文件的EIF格式是一样的,因此同一个位置的数据能进行合并形成一个更大的可执行文件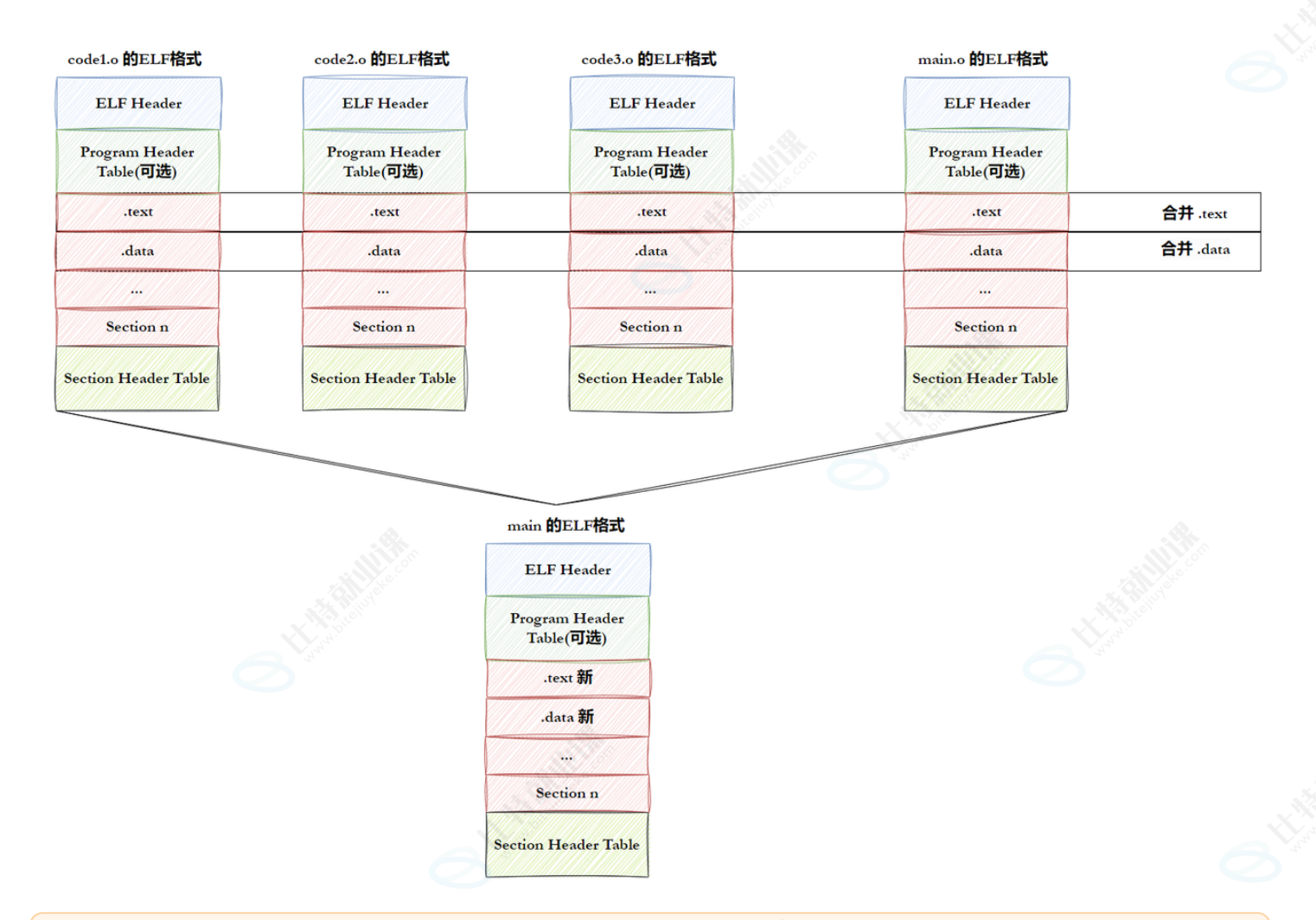
所以.o文件可以直接合并生成.exe,可以说静态库的合并就是这样的(直接与用户的.o文件合并了)
.o的同一个section之间合并后叫segment(section合并的原则是存在program header table中的)
(2)readelf -S
//读取EIF中section header table中的数据
readdlf -S code.o
ubuntu@VM-0-2-ubuntu:~/test$ readelf -S code.o
There are 10 section headers, starting at offset 0x128:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 0000000000000000 00000040
0000000000000000 0000000000000000 AX 0 0 1
[ 2] .data PROGBITS 0000000000000000 00000040
0000000000000000 0000000000000000 WA 0 0 1
[ 3] .bss NOBITS 0000000000000000 00000040
//...每个区域的划分方法:可以将一个文件视为一个一维线性数组,那么每个区域就可以用其相对于起始地址的offset来划分了。
bss区:也是用来存变量的.
全局变量分为已初始化和未初始化的(默认值为0),已初始化的存进.data区中,未初始化的所有变量都只用一个数字记录起来然后存进bss中,然后bss在内存展开时才会给我们的所有未初始化全局变量开辟空间。
一个section是否发生了合并的判断方法
(1)根据可执行文件的section区间与.o文件的section区间在个数,属性上进行比对。
(2)根据program header table中的数据进行合并。
(3)readelf -l
//只能对可执行文件使用,可以说明该文件的segment情况
ubuntu@VM-0-2-ubuntu:~/test$ readelf -l code
Elf file type is DYN (Position-Independent Executable file)
Entry point 0x22c0
There are 13 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
PHDR 0x0000000000000040 0x0000000000000040 0x0000000000000040
0x00000000000002d8 0x00000000000002d8 R 0x8
INTERP 0x0000000000000318 0x0000000000000318 0x0000000000000318
0x000000000000001c 0x000000000000001c R 0x1
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
LOAD 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000001060 0x0000000000001060 R 0x1000
//...加载的本质:可以发现有一段区间为load区(就是会加载到内存的区间)。在.o文件合并成.exe后会更新program header table和section header table中的数据,然后OS根据program header table 中的数据找到load区间,然后将load区间中的数据加载到内存当中。
OS也将内存看作一个线性一维数组,每一个元素的大小为4KB,也就是说OS对内存和对磁盘的操作单元都为4KB,因此内存和磁盘实际上就可以用同一个单位进行交互了。这也说明我们无论向内存申请多少数据(小于4KB),OS也会直节给我们4KB的内存资源造成资源浪费。
其实EIF中的每一部分其实都是彼此相互独立加载到内存中的,因此如果有些section很小,进行合并后就可以提高内存的使用效率。
section header table的数据意义与用途:
(1)是链接器,进行合并操作以及记录合并后每个区间的范围大小(EIF header 中也存储着大部分区间的空间大小)
(2)说明.exe的形成过程
(3)形成program header table
program header table的数据意义与用途:
(1)是加载器的一种,给编译器用的,即用于加载文件到内存,形成进程的初始化(说明能加载进内存的区间和说明不同区间的权限(readelf -l 中的flag 就是说明不同区间的权限))
(2)页表中的权限初始化就是来自于这里
(4)后面直接说明区间:symbol table
//可以查一个.exe的符号表数据
ubuntu@VM-0-2-ubuntu:~/test$ readelf -s code
Symbol table '.dynsym' contains 31 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FUNC GLOBAL DEFAULT UND [...]@GLIBCXX_3.4.21 (3)
Symbol table '.symtab' contains 88 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS Scrt1.o
2: 000000000000038c 32 OBJECT LOCAL DEFAULT 4 __abi_tagsymbol table就是符号表,用于记录函数名,变量名与代码之间的关系。
其的本质就是一个一维的字符数组例:
char arr[] = "hello\0func\0";寻找每个字符串是要记录每一个字符串对起始下标的偏移量,然后根据偏移量在arr\[\](不是真名)中读取数据。
(5)EIF header
//读取该.exe的EIF header数据
readelf -h code
ubuntu@VM-0-2-ubuntu:~/test$ readelf -h code
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
//..
Entry point address: 0x22c0
Start of program headers: 64 (bytes into file)
Start of section headers: 22512 (bytes into file)
//..Magic:一个随机值,用于给OS说明我这个程序格式是EIF,也就是OS是通过Magic来识别一个可执行文件是什么类型的(如区分.mp3,mp4,.txt等,因此上面文章直接使用.exe是不准确的,但图省事我后面依旧有可能使用.exe)
EIF的分区本质就是用偏移量(相对编址)来划分的。
2.objdump
把二进制文件进行反汇编
bash
ubuntu@VM-0-2-ubuntu:~/test$ objdump -d test
//-d使用说明只查看代码段的反汇编
test: file format elf64-x86-64
Disassembly of section .init:
0000000000001000 <_init>:
1000: f3 0f 1e fa endbr64
1004: 48 83 ec 08 sub $0x8,%rsp
1008: 48 8b 05 d9 2f 00 00 mov 0x2fd9(%rip),%rax # 3fe8 <__gmon_start__@Base>
100f: 48 85 c0 test %rax,%rax
1012: 74 02 je 1016 <_init+0x16>
1014: ff d0 call *%rax
1016: 48 83 c4 08 add $0x8,%rsp
101a: c3 ret
//..
ubuntu@VM-0-2-ubuntu:~/test$ objdump -d test.o
test.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # f <main+0xf>
f: 48 89 c7 mov %rax,%rdi
12: e8 00 00 00 00 call 17 <main+0x17>
17: b8 00 00 00 00 mov $0x0,%eax
1c: 5d pop %rbp
1d: c3 ret左边的数字就是汇编指令转换为机器码的情况,如果指令对应的是一个函数的话,机器码的后8位数字就是该函数的地址,如果该函数在当前文件中找不到的话,此处的数字为全0,代表该函数没有被链接(只有.o这种未被链接的文件才有这种函数.exe出现未被链接的函数直接就error不允许生成.exe了)
总结有.o是允许有不认识的函数出现的,只有在链接时才会修正这些函数地址,也就是.o文件彼此之间不认识,链接后才可能认识。